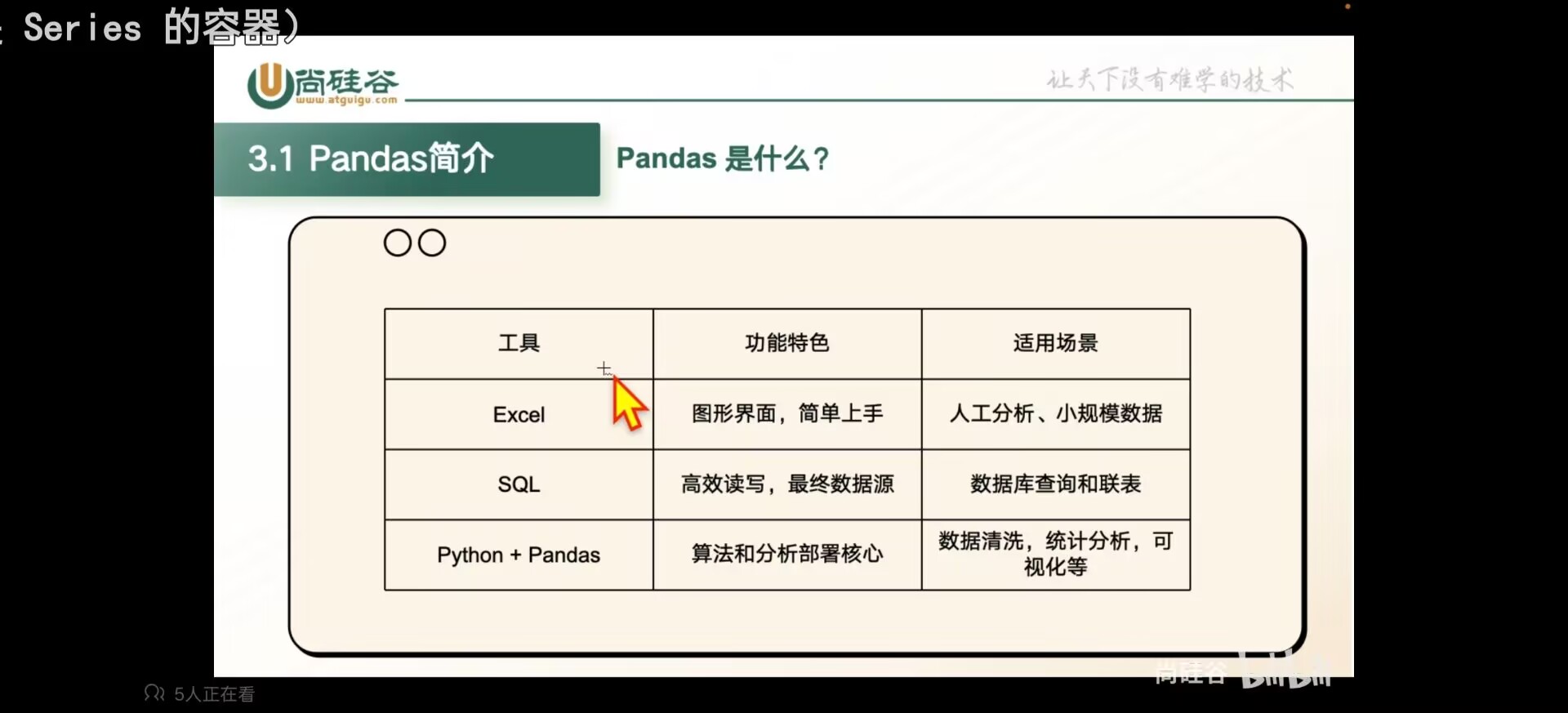
Pandas数据处理
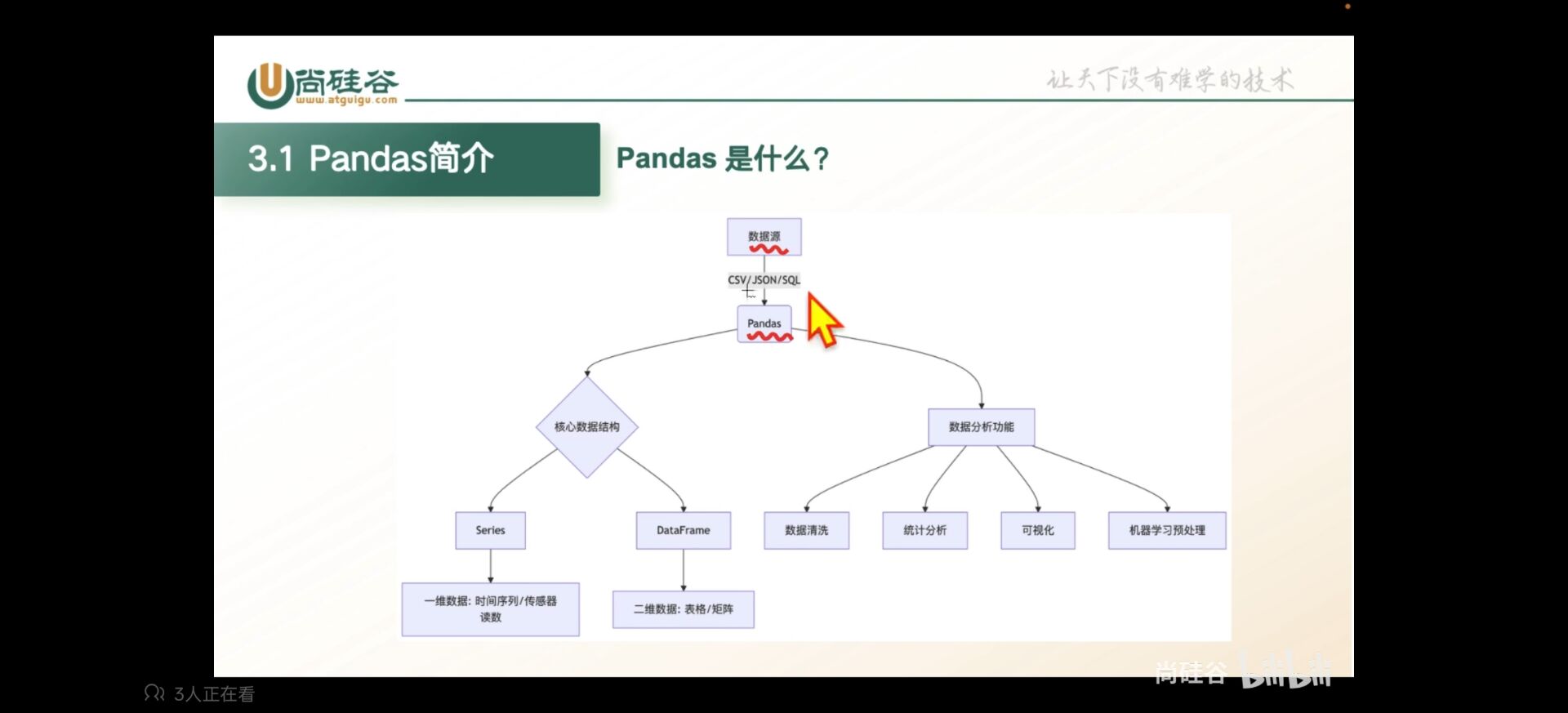
pandas是专门为了处理表格和混杂数据设计的python库


2.series
1.series的创建
python
import pandas as pd
s = pd.Series([1,2,3,4,5])
左边一列为数据值索引,右边才是数据
自定义索引:
python
x = pd.Series(range(4),index=['a','b','c','d'])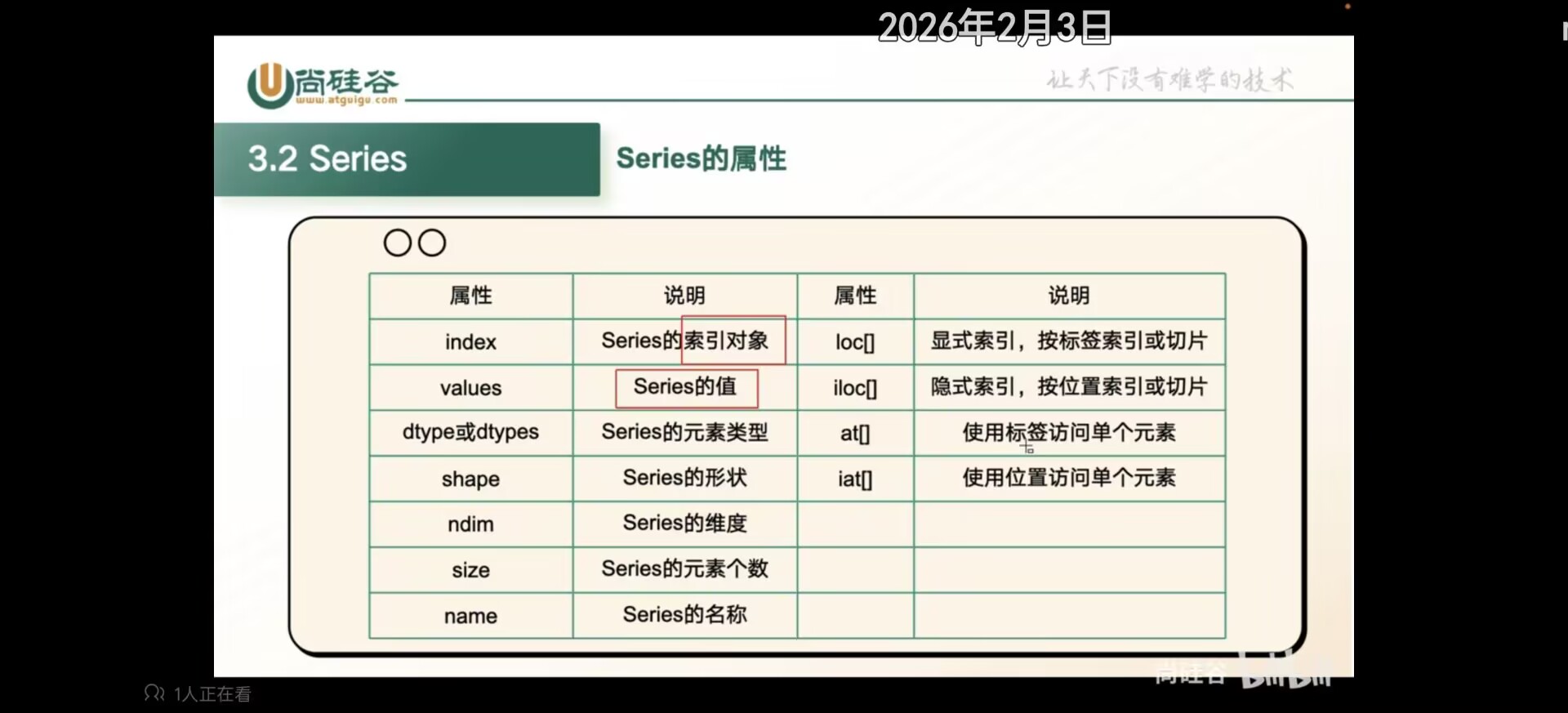
3.Series里访问数据
4.Series的常用方法
python
import numpy as np
import pandas as pd
# 1.series的创建
s = pd.Series(range(10))
print(s)
# 自定义索引
x = pd.Series(range(4),index=['a','b','c','d'])
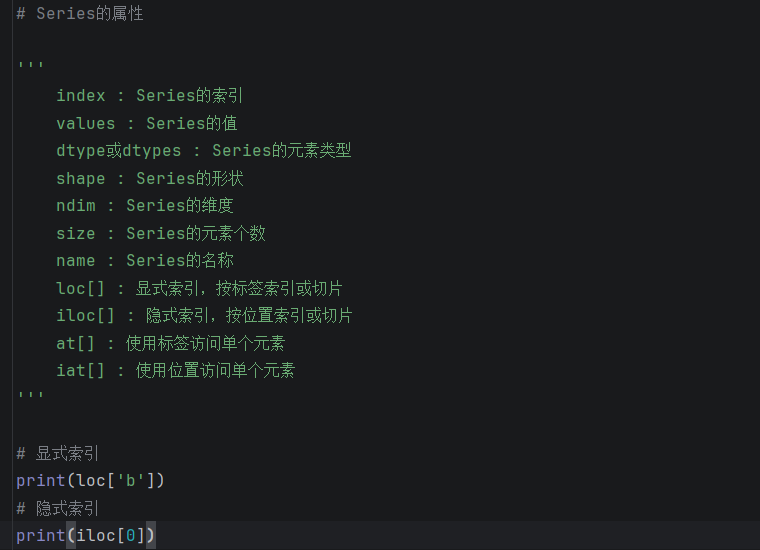
# Series的属性
'''
index : Series的索引
values : Series的值
dtype或dtypes : Series的元素类型
shape : Series的形状
ndim : Series的维度
size : Series的元素个数
name : Series的名称
loc[] : 显式索引,按标签索引或切片
iloc[] : 隐式索引,按位置索引或切片
at[] : 使用标签访问单个元素
iat[] : 使用位置访问单个元素
'''
# 显式索引
print(x.loc['b'])
# 隐式索引
print(x.iloc[0])
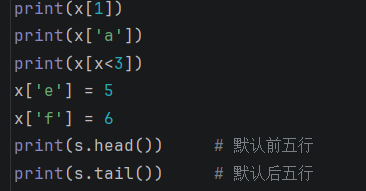
# 访问Series数据
print(x.iat[1])
print(x['a'])
print(x[x<3])
x['e'] = 5
x['f'] = 6
print(s.head()) # 默认前五行
print(s.tail()) # 默认后五行
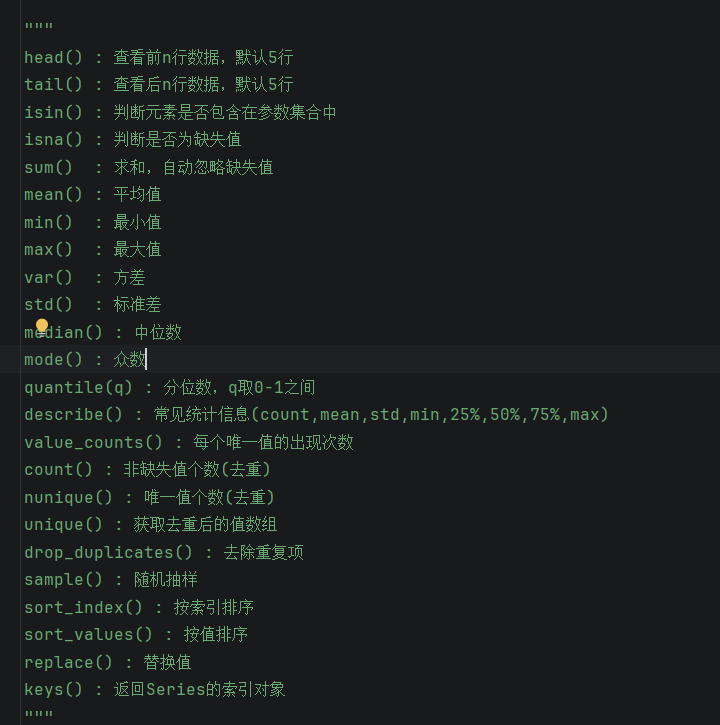
# Series常用方法
"""
head() : 查看前n行数据,默认5行
tail() : 查看后n行数据,默认5行
isin() : 判断元素是否包含在参数集合中
isna() : 判断是否为缺失值
sum() : 求和,自动忽略缺失值
mean() : 平均值
min() : 最小值
max() : 最大值
var() : 方差
std() : 标准差
median() : 中位数
mode() : 众数
quantile(q) : 分位数,q取0-1之间
describe() : 常见统计信息(count,mean,std,min,25%,50%,75%,max)
value_counts() : 每个唯一值的出现次数
count() : 非缺失值个数(去重)
nunique() : 唯一值个数(去重)
unique() : 获取去重后的值数组
drop_duplicates() : 去除重复项
sample() : 随机抽样
sort_index() : 按索引排序
sort_values() : 按值排序
replace() : 替换值
keys() : 返回Series的索引对象
"""
# 案例1:创建一个包含10名学生成绩的Series,成绩范围在50-100之间,计算平均分,最高分,最低分,并找出高于平均分的学生人数
np.random.seed(42)
scores = pd.Series(np.random.randint(50,101,10),index = ['学生' + str(i) for i in range(1,11)])
print(scores)
# 得到数据
mean = scores.mean()
max = scores.max()
min = scores.min()
print(mean)
print(max)
print(min)
scores[scores > mean].count()
'''
案例二:给定某城市一周每天的最高温度Series,完成以下任务:
找出温度超过30度的天数
计算平均温度
将温度从高到低排序
找出温度变化最大的两天
'''
tem = pd.Series([28,31,29,32,30,27,33],index = ['周一','周二','周三','周四','周五','周六','周日'])
print(f'温度超过30度的天数是${tem[tem>30]}')
print(f'平均气温是${tem.mean()}')
print('从高到低排序')
print(tem.sort_values())
t = tem.diff().abs() # diff()算逐差
print(f'温度变化最大的两天是:${tem[t.sort_values(ascending = False).head(2).keys()]}')
'''
案例三:股票价格分析
给定某股票连续10个交易日的收盘价Series:
计算每日收益率(当日收盘价/前日收盘价 - 1)
找出收益率最高和最低的日期
计算波动率(收益率的标准差)
'''
prices = pd.Series([102.3,103.5,105.1,104.8,106.2,107.0,106.5,108.1,109.3,110.2],index=pd.date_range('2023-01-01',periods=10))
print(prices)
p1 = prices.pct_change() # pct_change() 算收益率
maxday = p1.idxmax() # idxmax 最大值对应的索引
minday = p1.idxmin() # idxmin 最小值对应的索引
p2 = p1.std()
print(f'收益率是{p1}')
print(f'收益率最高的一天是{maxday}')
print(f'收益率最低的一天是{minday}')
print(f'波动率是{p2}')
'''
销售数据分析
某产品过去12个月的销售量Series:
计算季度平均销量(每3个月为一个季度)
找出销量最高的月份
计算月环比增长率
找出连续增长超过2个月的月份
'''
# 数据
sales = pd.Series([120,135,145,160,155,170,180,175,190,200,210,220],index=pd.date_range('2022-01-01',periods=12,freq='MS'))
# 季度的平均销量
sales.resample('QS').mean() # 重新采样
# 最大销量对应月份
s_max = sales.max()
# 增长率
s1 = sales.pct_change()
# 连续增长超过2个月的月份
s = s1 > 0
print(s[s.rolling(3).sum()==3].keys().tolist())
'''
每小时销售数据分析
某商店每小时销售额Series:
按天重采样计算每日销售额
计算每天营业时间(8:00-22:00)和非盈利时间的销售额比例
找出销售额最高的3个小时
'''
np.random.seed(42)
hours_sales = pd.Series(np.random.randint(0,100,24),index = pd.date_range('2022-01-01',periods=24,freq='h'))
print(hours_sales)
# 重采样
day_sales = hours_sales.resample('D').sum()
print(day_sales)
# 计算每天营业时间和非营业时间的比例
hours_sales.between_time('8:00','22:00') # 筛选一段时间内的
business_hours_sales = hours_sales[(hours_sales.index.hour>=8) & ((hours_sales.index.hour<=22))].sum()
print(business_hours_sales)
print(business_hours_sales / (day_sales - business_hours_sales))
# 营业额最高的三小时
print(hours_sales.nlargest(3))