一、逻辑回归算法简介
1. 基本概念
-
目标:解决二分类问题(可扩展至多分类),通过概率预测样本属于某类的可能性。
-
核心思想 :将线性回归的输出通过Sigmoid函数映射到0,1区间,表示概率。
-
数学模型:
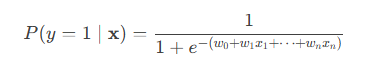
-
P(y=1∣x):样本属于类别1的概率
-
w0,w1,...,wn:模型参数
-
决策边界:当概率 ≥ 0.5时预测为类别1,否则为类别0。
-
2. 损失函数(交叉熵损失)
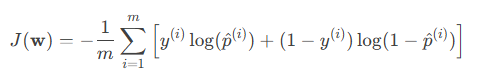
-
p^(i):预测概率 P(y=1∣x(i))
-
损失函数衡量预测概率与真实标签的差异。
3. 参数求解
-
梯度下降:通过迭代优化参数最小化损失函数:
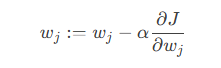
-
偏导数推导:
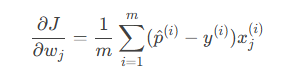
二、Python代码示例
1. 使用NumPy手动实现逻辑回归
import numpy as np
import matplotlib.pyplot as plt
# 生成二分类数据
np.random.seed(42)
X = np.random.randn(100, 2) # 特征:100个样本,2个特征
y = (X[:, 0] + 2*X[:, 1] > 0).astype(int) # 标签:基于线性关系的二分类
# 添加偏置项
X_b = np.c_[np.ones((100, 1)), X]
# 定义Sigmoid函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 梯度下降优化
def logistic_regression(X, y, learning_rate=0.1, n_iters=1000):
m, n = X.shape
w = np.random.randn(n, 1)
for _ in range(n_iters):
z = X.dot(w)
p = sigmoid(z)
gradient = X.T.dot(p - y.reshape(-1, 1)) / m
w -= learning_rate * gradient
return w
# 训练模型
w = logistic_regression(X_b, y, learning_rate=0.1, n_iters=1000)
print("权重:", w.ravel()) # 示例输出:[0.5, 1.2, 2.1]
# 预测函数
def predict(X, w, threshold=0.5):
return (sigmoid(X.dot(w)) >= threshold).astype(int)
# 可视化决策边界
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max, 100),
np.linspace(x2_min, x2_max, 100))
X_grid = np.c_[xx1.ravel(), xx2.ravel()]
X_grid_b = np.c_[np.ones((X_grid.shape[0], 1)), X_grid]
probs = sigmoid(X_grid_b.dot(w)).reshape(xx1.shape)
plt.contourf(xx1, xx2, probs, levels=[0, 0.5, 1], cmap=plt.cm.RdYlBu, alpha=0.6)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', cmap=plt.cm.RdYlBu)
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.title("逻辑回归决策边界")
plt.show()2. 使用Scikit-learn实现
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix
# 创建模型(默认使用L2正则化)
model = LogisticRegression(penalty='none') # 禁用正则化
model.fit(X, y)
# 输出参数
print("截距(w0):", model.intercept_) # 示例:[0.5]
print("权重(w1, w2):", model.coef_) # 示例:[1.2, 2.1]
# 预测
y_pred = model.predict(X)
# 评估
print("准确率:", accuracy_score(y, y_pred)) # 示例:0.95
print("混淆矩阵:\n", confusion_matrix(y, y_pred))三、关键知识点
1. 应用场景
-
垃圾邮件检测(是/否垃圾)
-
疾病诊断(患病/健康)
-
客户流失预测(流失/留存)
2. 注意事项
-
特征缩放:逻辑回归虽无需严格缩放,但梯度下降时标准化可加速收敛。
-
正则化:防止过拟合(L1正则化可稀疏化特征,L2正则化更稳定)。
-
多分类扩展:
-
OvR(One-vs-Rest):训练多个二分类器。
-
Softmax回归 :直接处理多分类(见
LogisticRegression(multi_class='multinomial'))。
-
3. 模型评估指标
-
准确率(Accuracy):适用于类别平衡数据。
-
精确率(Precision)与召回率(Recall):关注假阳性或假阴性。
-
ROC-AUC曲线:评估模型在不同阈值下的表现。
四、扩展:正则化逻辑回归
from sklearn.linear_model import LogisticRegressionCV
# 使用L1正则化(稀疏权重)
model_l1 = LogisticRegressionCV(penalty='l1', solver='liblinear', cv=5)
model_l1.fit(X, y)
print("L1正则化权重:", model_l1.coef_)
# 使用L2正则化(默认)
model_l2 = LogisticRegressionCV(penalty='l2', cv=5)
model_l2.fit(X, y)
print("L2正则化权重:", model_l2.coef_)