逻辑回归算法
在分类任务中最典型的算法就是逻辑回归算法,主要应用于二分类的场景.
对应sklearn.linear_model.LogisticRegressionAPI
什么是逻辑回归算法呢?
就是将线性回归计算的连续值使用Sigmid函数将其转化成0-1之间的正类概率值.
Sigmoid函数公式: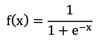
最小化交叉熵损失函数
最小化交叉熵损失函数本质就是伯努利分布函数对其求-对数得到最小化损失.
交叉熵是衡量两个概率分布(真实分布y和预测分布p)差异的指标
最小化交叉熵公式: 
API讲解
sklearn.linear_model.LogisticRegression(solver='liblinear',C=1.0)
- solver损失函数优化方法:
- liblinear对小数据集场景训练速度更快,sag,saga对大数据集更快
- sag,saga支持L2正则化或者没有正则化
- liblinear和saga支持L1正则化
- C 正则化力度,越小正则化越强,惩罚力度也越大.模型更倾向欠拟合
分类问题评估
了解分类问题之前需要学习到什么是混淆矩阵
混淆矩阵
什么是混淆矩阵呢?
混淆矩阵就是对模型的预测结果与实际标签的对比情况

精确率: 是指预测为正例中真正正例的占比
对应sklearn.metrics.precision_score
计算公式: P = TP/(TP+FP)
召回率: 是指真正正例中被预测为正例的占比
对应sklearn.metrics.recall_score
计算公式: P = TP/(TP+FN)
f1-分数: 对精确率和召回率的综合
对应sklearn.metrics.f1_score
计算公式: P = 2 ∗Precision ∗Recall/(Precision+Recall)
ROC曲线和AUC面积
对应sklearn.metrics.roc_auc_score
了解ROC曲线之间需要明白真正率和假正率是什么?
真正率TPR和假正率FPR
- 正样本中被预测为正样本的概率TPR (True Positive Rate)
- 负样本中被预测为正样本的概率FPR (False Positive Rate)
通过这两个指标可以描述模型对正/负样本的分辨能力
什么是ROC曲线呢?
ROC曲线是一种评估分类模型性能的一种可视化工具,他的X轴是FPR,Y轴是TPR,
它可以将模型在不同阈值下的表现以曲线的形式展示.
- 点(0, 0) :所有的负样本都预测正确,所有的正样本都预测错误。相当于点的(FPR值0, TPR值0)
- 点(1, 0) :所有的负样本都预测错误,所有的正样本都预测错误。相当于点的(FPR值1, TPR值0)
(1, 0) - 最不好的效果!!! - 点(1, 1):所有的负样本都预测错误,表示所有的正样本都预测正确。相当于点的(FPR值1,TPR值1)
- 点(0, 1):所有的负样本都预测正确,表示所有的正样本都预测正确。相当于点的(FPR值0,TPR值1)
(0, 1) - 最好的效果!!!
什么是AUC呢?
AUC其实就是ROC曲线与X轴和X=1两条直线相交的面积,
当AUC=0的时候,是模型最差的时候
当AUC=0.5的时候,表示模型现在类似于抛硬币每次都是0.5的概率随机抽样
当AUC=1的时候,是模型最好的时候,此时模型完美判断出正例和假例
分类评估报告
对应sklearn.metrics.classification_report(y_true, y_pred, labels=\[\], target_names=None )
y_true:真实目标值
y_pred:估计器预测目标值
labels:指定类别对应的数字
target_names:目标类别名称
return:每个类别精确率与召回率
它可以直观每个类别的数量以及精确率和召回率还有准确率.
效果如下:
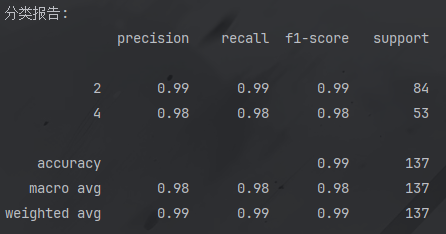
其中macro avg: 宏平均,就是对每个分类指标的简单平均值
weighted avg: 加权平均,考虑类别样本数后的平均值