docker打包本地conda虚拟环境
由于我的实验代码在某些数据集上经常OOM,所以我想把本地环境直接打包为docker,以便在远程服务器上直接运行
将本地复杂的深度学习环境(尤其是涉及 CUDA 的 GS-SLAM 项目)迁移到远程服务器,使用 Docker 是最稳妥的选择。这能避免远程服务器上驱动、库版本不一致导致的"环境地狱"。
为了保证效率,建议遵循以下流程:构建基础镜像 -> 导出 Conda 环境 -> 映射代码与数据。
第一阶段:本地准备(Docker 化)
不要直接把几百 GB 的数据打包进镜像,这样镜像会臃肿且不可移植。我们只把 环境 打包。
1.导出 Conda 环境
bash
conda activate my2dgsslam
conda env export > environment.yml
将environment.yml中的pip部分复制粘贴到requirement.txt
bash
addict
appdirs
argcomplete
attrs
backcall
click
comm
configargparse
cycler
dash
dash-core-components
dash-html-components
dash-table
decorator
docker-pycreds
evo
fastjsonschema
flask
fonttools
gitdb
gitpython
glfw
imageio
imgviz
importlib-metadata
importlib-resources
ipython
ipywidgets
itsdangerous
jedi
jinja2
joblib
jsonschema
jupyter-core
jupyterlab-widgets
kiwisolver
lietorch
lpips
markdown-it-py
markupsafe
matplotlib
matplotlib-inline
mdurl
munch
natsort
nbformat
nest-asyncio
open3d
opencv-python
packaging
pandas
parso
pexpect
pickleshare
pillow
pkgutil-resolve-name
platformdirs
plotly
prompt-toolkit
protobuf
psutil
ptyprocess
pyglm
pygments
pyopengl
pyparsing
pyquaternion
pyrsistent
python-dateutil
pytz
pyyaml
retrying
rich
ruff
scikit-learn
scipy
seaborn
sentry-sdk
setproctitle
smmap
tenacity
threadpoolctl
torchmetrics
traitlets
trimesh
wandb
wcwidth
werkzeug
widgetsnbextension
zipp2.构建dockerfile
bash
# 1. 基础镜像:Ubuntu 22.04 + CUDA 11.8 (完美支持 H20 的 sm_90 架构)
FROM nvidia/cuda:11.8.0-cudnn8-devel-ubuntu22.04
# 2. 避免交互式安装,设置时区为东八区
ENV DEBIAN_FRONTEND=noninteractive
ENV TZ=Asia/Shanghai
# 3. 替换 apt 源为阿里云
RUN sed -i 's/archive.ubuntu.com/mirrors.aliyun.com/g' /etc/apt/sources.list && \
sed -i 's/security.ubuntu.com/mirrors.aliyun.com/g' /etc/apt/sources.list
# 4. 安装基础依赖
RUN apt-get update && apt-get install -y \
wget curl git tzdata build-essential ninja-build \
libgl1-mesa-glx libglib2.0-0 \
&& ln -fs /usr/share/zoneinfo/${TZ} /etc/localtime \
&& dpkg-reconfigure --frontend noninteractive tzdata \
&& rm -rf /var/lib/apt/lists/*
# 5. 安装 Miniconda
RUN wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh -O /tmp/miniconda.sh && \
bash /tmp/miniconda.sh -b -p /opt/conda && \
rm /tmp/miniconda.sh
ENV PATH=/opt/conda/bin:$PATH
# 6. 配置 Conda 和 Pip 国内源
RUN conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ && \
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ && \
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
WORKDIR /workspace
#接受tos条款
RUN conda tos accept
# 7. 创建 Python 3.9 纯净环境
RUN conda create -n 2dgsslam python=3.9 -y && \
conda clean -afy
RUN echo "source /opt/conda/etc/profile.d/conda.sh" >> ~/.bashrc && \
echo "conda activate 2dgsslam" >> ~/.bashrc
# 8. 核心步骤:显式安装 PyTorch 2.1.2 (cu118 版本)
RUN /bin/bash -c "source /opt/conda/etc/profile.d/conda.sh && conda activate 2dgsslam && \
pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu118"
# 9. 复制并安装其他第三方库 (仅复制依赖文件,不包含项目代码)
COPY requirements.txt .
RUN /bin/bash -c "source /opt/conda/etc/profile.d/conda.sh && conda activate 2dgsslam && \
pip install -r requirements.txt"
# 10. H20 算力架构声明 (sm_90)
# 虽然这里不编译,但设置这个环境变量可以确保后续你手动编译时,nvcc 编译器直接生成 H20 的原生机器码
ENV TORCH_CUDA_ARCH_LIST="9.0"
# 默认启动 bash
CMD ["/bin/bash"]3.构建docker镜像
我们构建docker时不是用代理,取消一下代理设置
bash
ls /etc/systemd/system/docker.service.d/删除
bash
ls /etc/systemd/system/docker.service.d/删除文件前可以备份,请删除以下文件
bash
http-proxy.conf
https-proxy.conf
bash
sudo rm -rf /etc/systemd/system/docker.service.d/*查看配置文件
bash
cat /etc/docker/daemon.json修改daemon.json为以下内容,注释或删除关于proxy的命令
bash
{
"runtimes": {
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
},
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://mirror.aliyuncs.com"
]
}重载 systemd + 重启 Docker
bash
sudo systemctl daemon-reexec
sudo systemctl daemon-reload
sudo systemctl restart docker确认代理真的消失
bash
docker info | grep -i proxy无任何输出
接下来构建docker
bash
docker build -t 2dgsslam_base:v1 .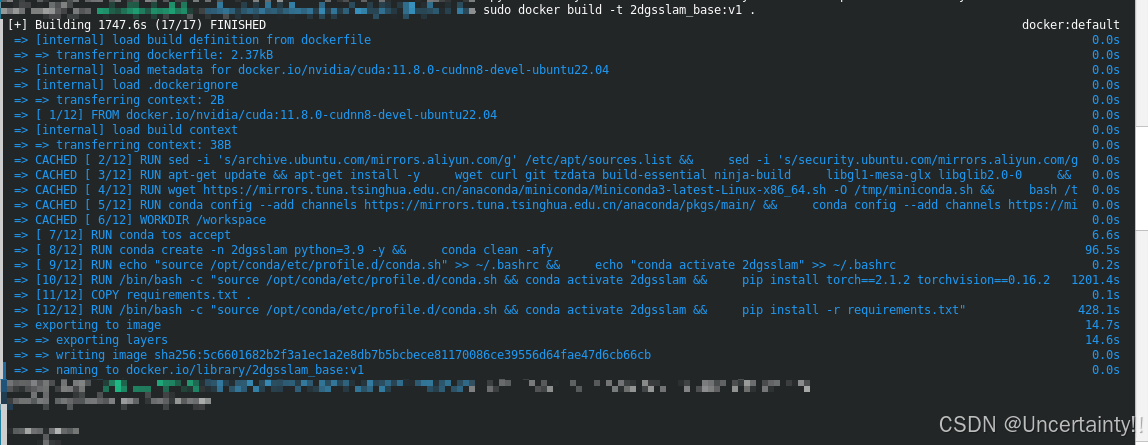
测试一下
先验证 GPU 是否可用(非常重要)
运行容器:
bash
sudo docker run --gpus all -it 2dgsslam_base:v1进入后测试:
bash
nvidia-smi测试 PyTorch GPU
在容器里:
bash
python
bash
import torch
print(torch.cuda.is_available())
print(torch.cuda.get_device_name(0))正常输出应该是:
True
NVIDIA H20 / A100 / etc.
第二阶段:保存docker镜像上传到远程服务器
先将镜像导出为tar文件
bash
docker save -o 2dgsslam_base_v1.tar 2dgsslam_base:v1
目前远程服务器只接收tar.gz 压缩包
要将 Docker 镜像保存为 tar.gz 压缩包,核心是先将镜像导出为 tar 文件,再用压缩工具打包成 tar.gz
查看要保存的镜像名称 / ID
先确认镜像的准确标识(名称 + 标签 或 ID)
bash
docker images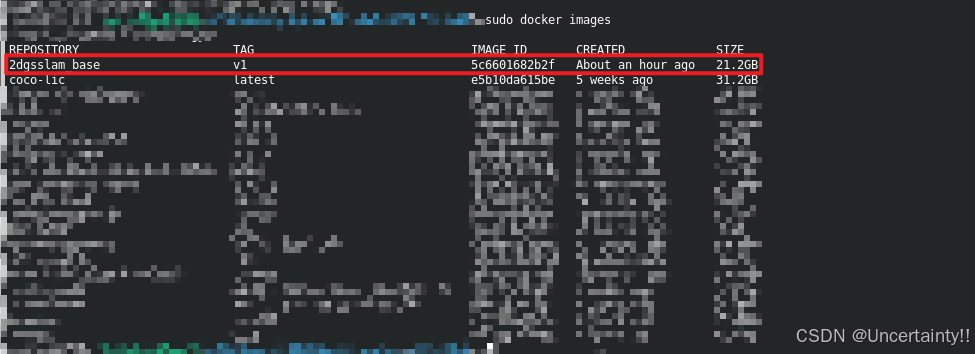
将 tar 压缩为 tar.gz
用 gzip 命令压缩(压缩后体积更小,便于传输 / 存储):
bash
# 格式:gzip 要压缩的tar文件
gzip my_image.tar
# 执行后会生成 my_image.tar.gz,原 tar 文件会被删除
# 若想保留原 tar 文件,加 -k 参数:gzip -k my_image.tar文件权限不够,导致无法上传至远程服务器
bash
-rw------- 1 root root 12400622118 Mar 21 13:03 2dgsslam_base_v1.tar.gz修改文件权限
bash
sudo chmod 644 2dgsslam_base_v1.tar.gz使用sftp连接服务器
bash
sftp 用户名@yourIP上传镜像
bash
put -r 本地文件路径 远程路径镜像已经上传到服务器上
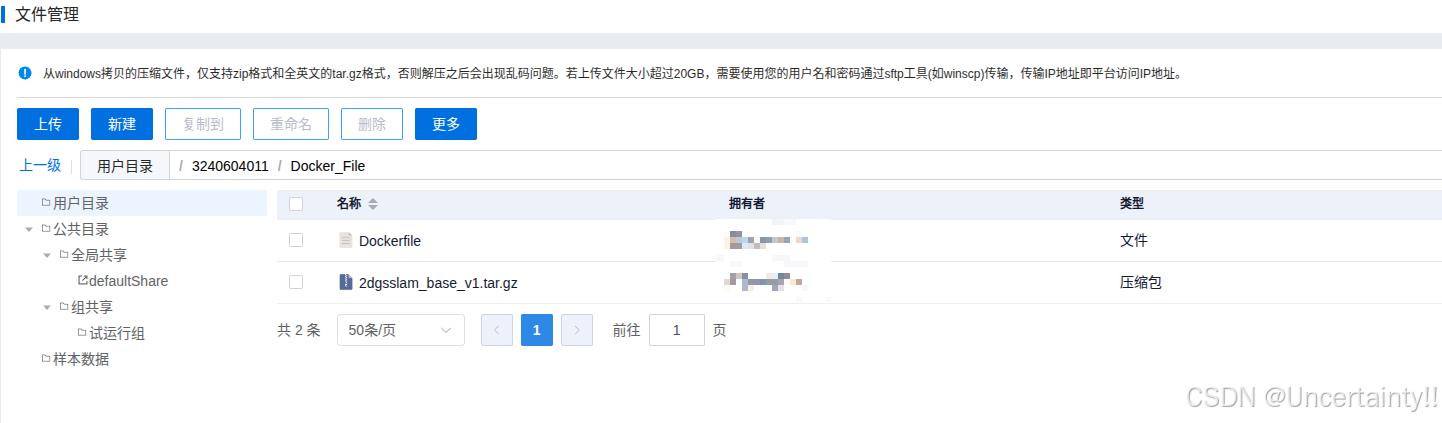
在服务器网页控制页面导入镜像
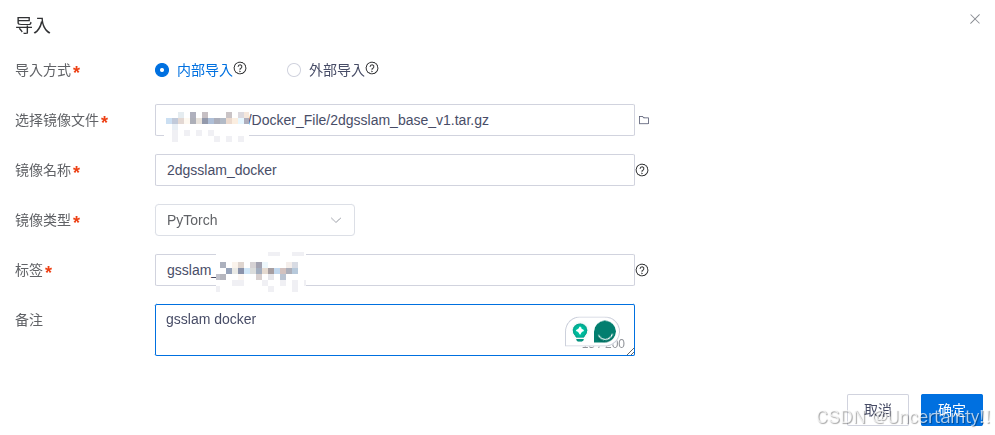
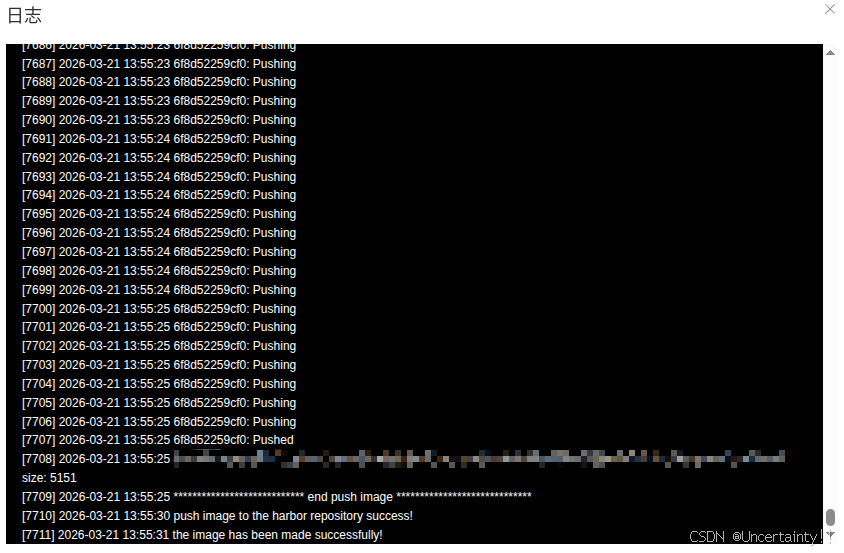
导入完成
第三阶段:挂载项目目录运行
在服务器控制页面创建开发环境选择刚刚导入的镜像

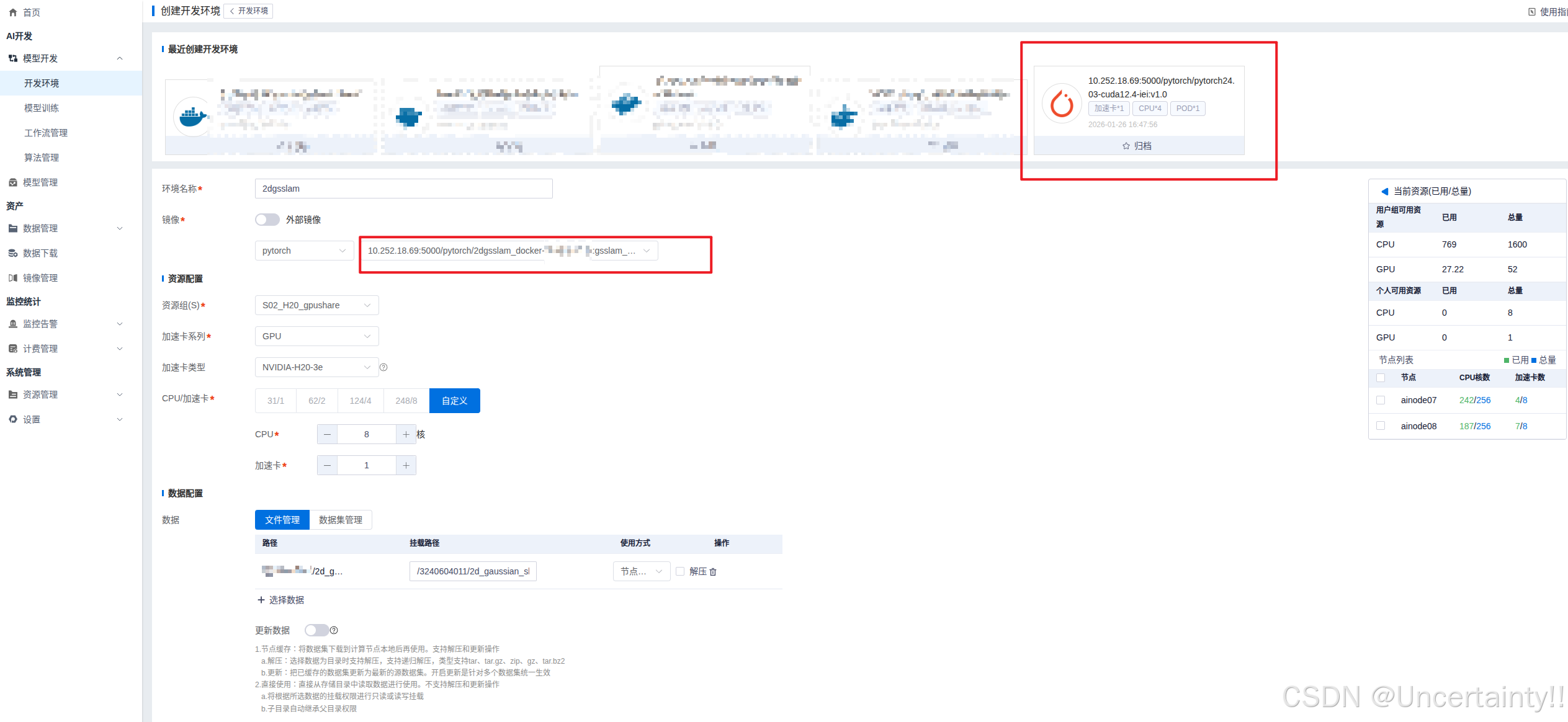
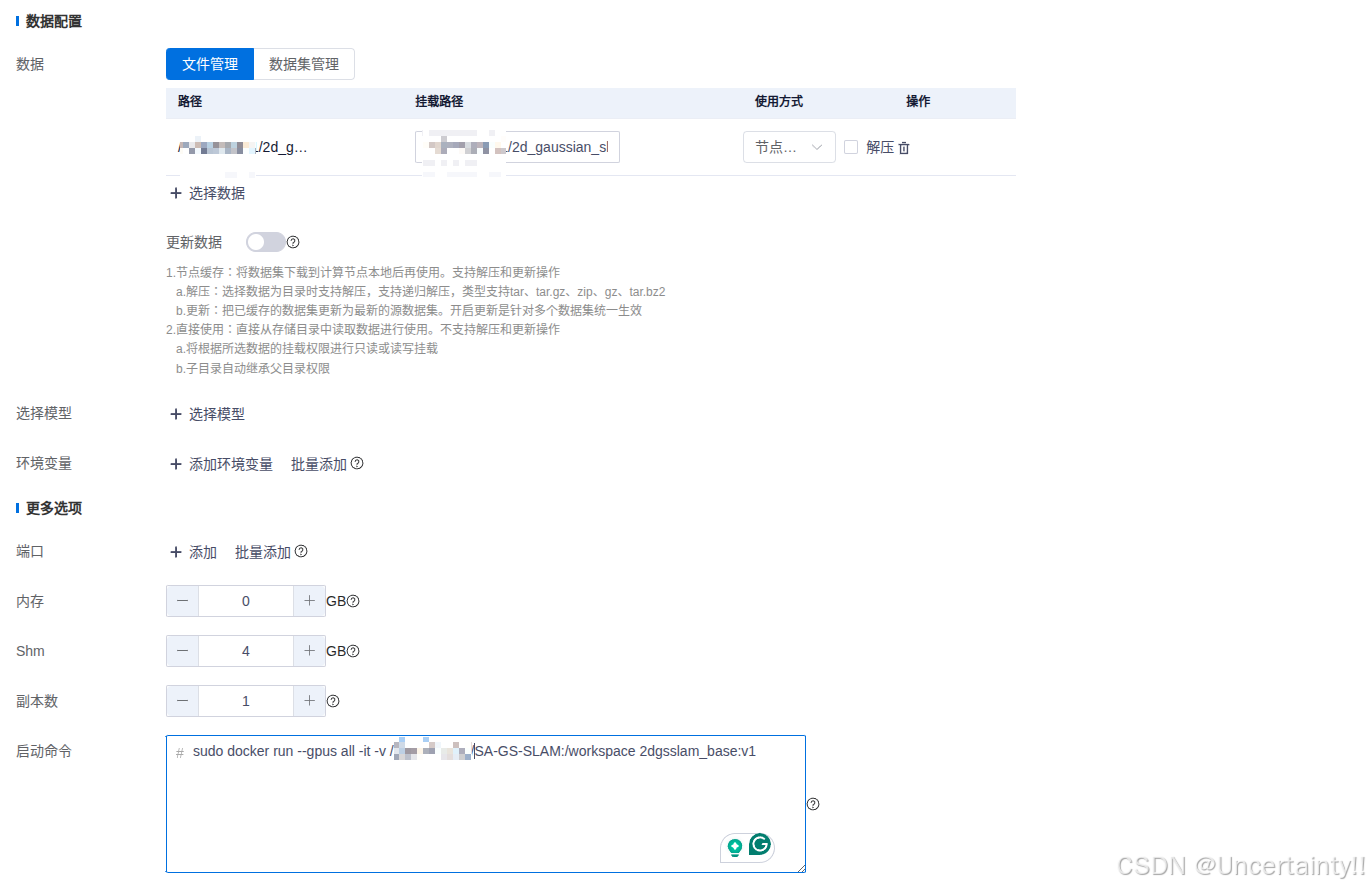
启动命令
bash
sudo docker run --gpus all -it -v /服务器上项目路径/SA-GS-SLAM:/workspace 2dgsslam_base:v1
bash
cd /workspace第四阶段:vscode远程连接
ssh连接远程服务器docker