继续跟进【文档智能】解析进展,小红书今天又开源了一个多模态文档解析模型:基于qwen3-vl-2B参数微调训练的参数量的FireRed-OCR,与paddleocr-vl等不同的是Layout阶段采用的也是2b的模型(整体方式与mineru2.5相似)。下面来看看整体的方法。
方法
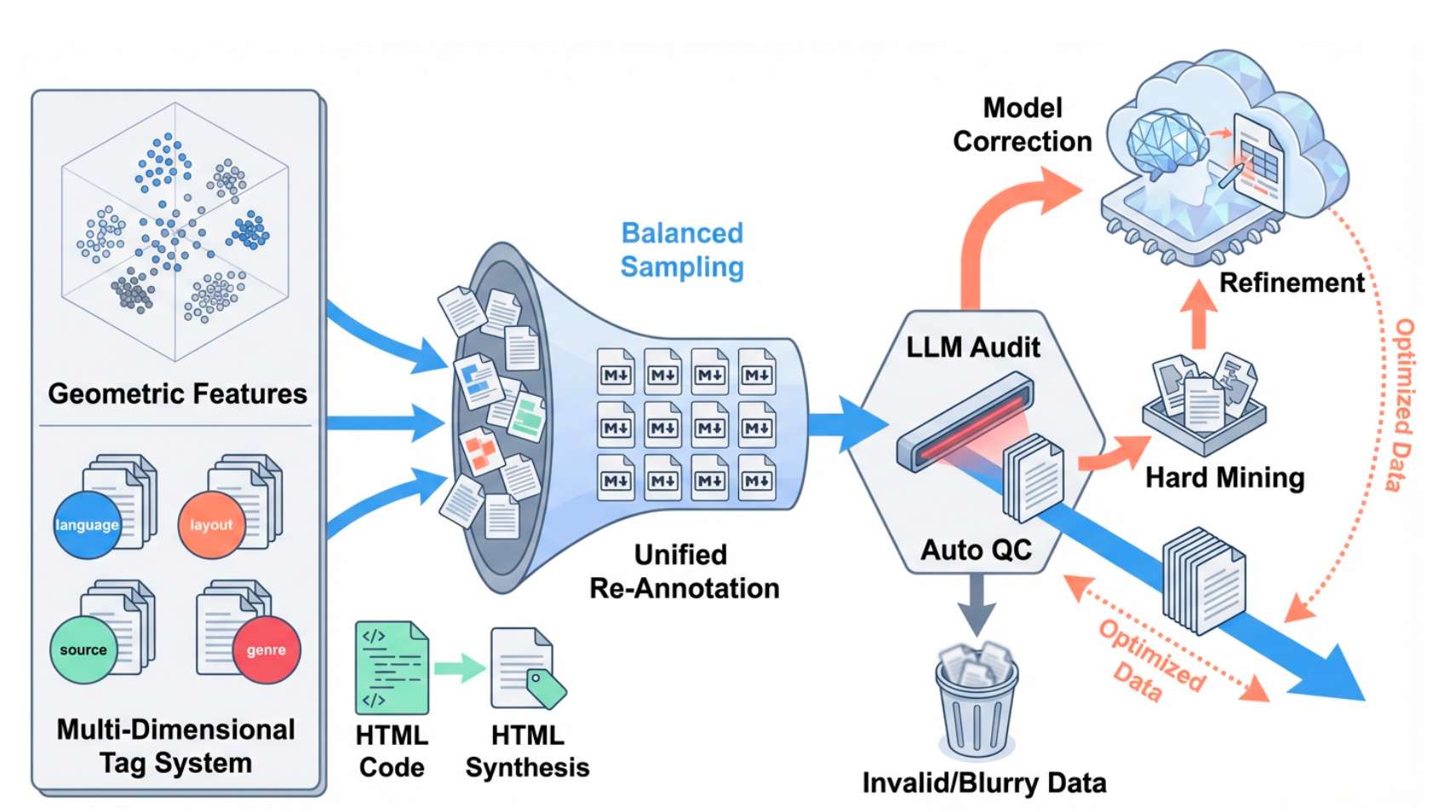
训练分三个阶段:阶段 1(预对齐)用粗标注数据(低成本、大规模)打基础,阶段 2(SFT)用精标注数据(高成本、中规模)提高精度,阶段 3(GRPO)用约束校验数据(无标注、轻量化)增强处理逻辑,如下:
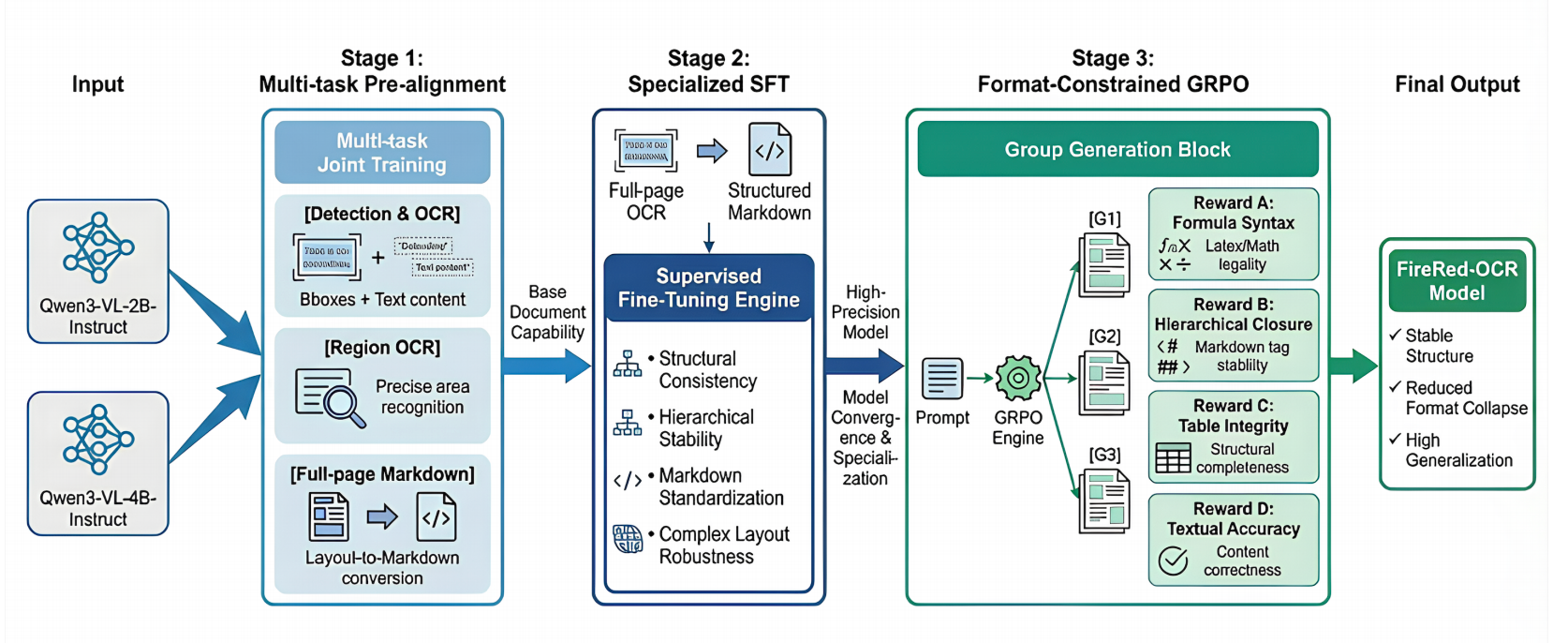
阶段1:多任务预对齐
包含三个互补子任务,采用异质数据集 D p r e D_{pre} Dpre,联合训练:
- 检测与OCR( T d e t T_{det} Tdet) :输入文档图像,模型需同时输出文本的边界框坐标( b i b_i bi)和对应识别文本( t i t_i ti)。
- 区域OCR( T r e g T_{reg} Treg):输入图像局部裁剪区域或坐标提示(如"识别图像左上角100×100像素区域的文本"),模型输出该区域内的文本内容。该任务提升模型对局部高分辨率文本的敏感程度,解决密集文本区域的识别模糊问题。
- 全页Markdown转换(初始版):简单的布局直接生成Markdown格式。
交叉熵损失函数:
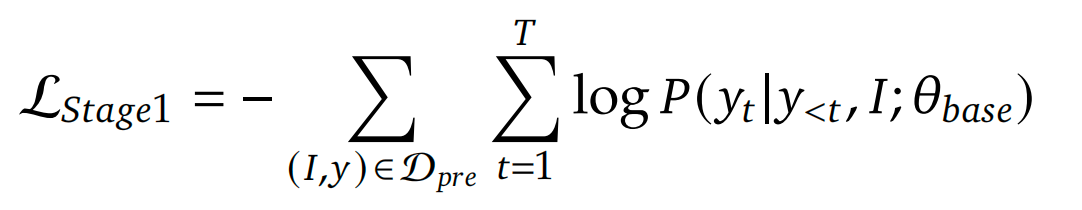
这一阶段识别文本内容和位置,初步理解简单布局,但结构输出缺乏一致性和规范性(如表格列数混乱、标题层级错乱)。
阶段2:SFT
基于 curated 高质量数据集 D s f t D_{sft} Dsft(400k 文档-Markdown 对齐对)训练:
- 结构一致性:确保长文本生成中逻辑连贯,例如长文档的章节层级不中断、多页表格的列数保持一致,避免"碎片化输出"。
- 层级表达稳定性:严格区分语义层级,例如 Markdown 中"# 一级标题""## 二级标题"的嵌套关系、有序列表与无序列表的区分,还原原始文档的视觉层级。
- Markdown 格式标准化:统一格式表达规范,例如公式用 LaTeX、表格用标准 Markdown、加粗/斜体的符号使用一致。
- 跨语言与复杂布局:主要考虑训练数据的多样性(多语言文本等)、复杂几何布局(多列学术论文、图文混合文档、扭曲扫描件)。
其他细节:阶段1使用较粗标注(PaddleOCR-VL v1)训练通用能力,阶段2切换为精细标注(PaddleOCR-VL v1.5)优化细节。
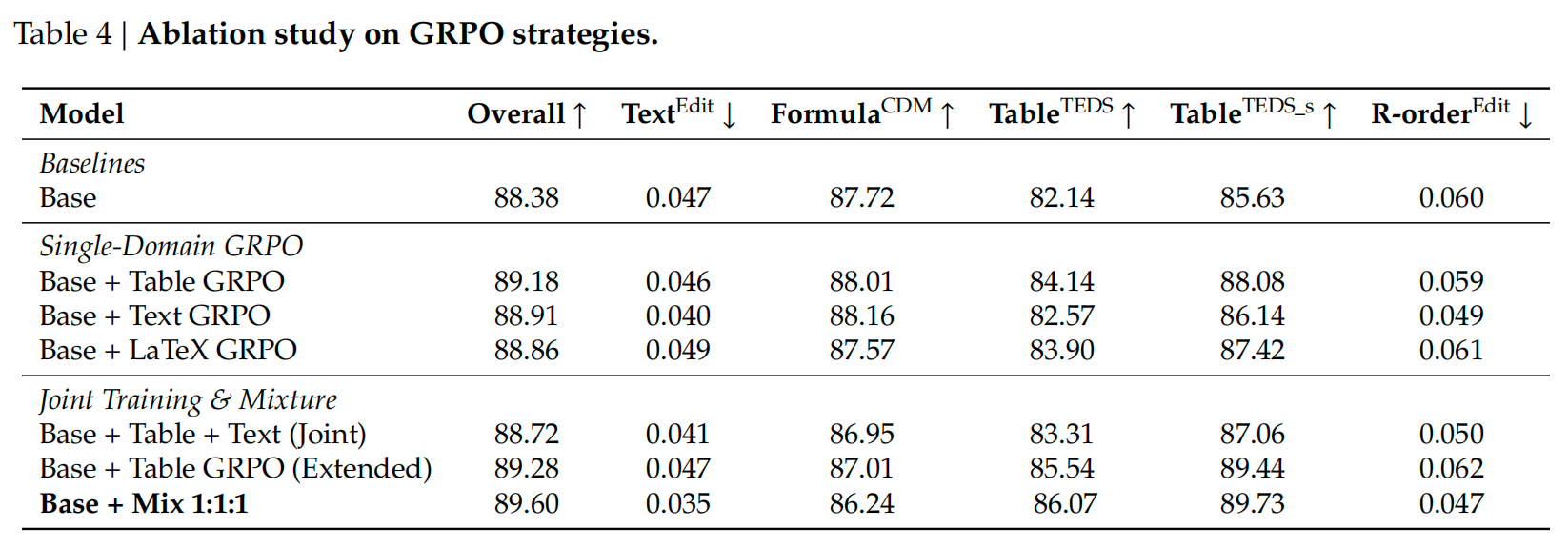
阶段3:GRPO格式约束优化
通过RL强制约束输出结构语法,解决如未闭合的标签、无法编译的公式。
-
组生成模块 :对每个输入(图像-指令对),模型通过采样生成 G 个输出( o 1 , o 2 , . . . , o G o_1, o_2, ..., o_G o1,o2,...,oG),形成候选输出组。
-
复合奖励函数设计( R ( o ) R(o) R(o)) :通过四部分加权奖励引导模型生成"结构合规+内容准确"的结果,权重 λ A , λ B , λ C , λ D \lambda_A, \lambda_B, \lambda_C, \lambda_D λA,λB,λC,λD 经实验优化确定:
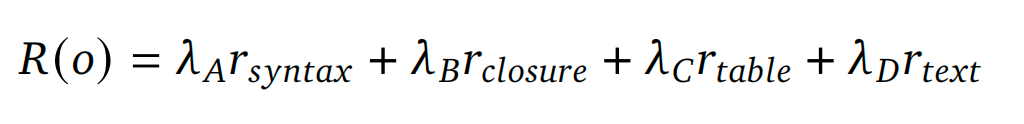
- 公式语法奖励( r s y n t a x r_{syntax} rsyntax):用轻量级 LaTeX 解析器验证公式合法性,无法编译或含非法符号则得 -1 分,合法公式按复杂度给予正分。
- 层级闭合奖励( r c l o s u r e r_{closure} rclosure):检查 Markdown/HTML 类标签的闭合情况(如 ** 加粗符号、table 表格标签),未闭合节点数量与惩罚正相关。
- 表格完整性奖励( r t a b l e r_{table} rtable):验证表格列数是否全局一致,结构为矩形且无缺失行/列得 1 分,否则得 0 分(表格是 OCR 中最易出错的结构)。
- 文本准确性奖励( r t e x t r_{text} rtext):计算生成文本与 SFT 阶段伪真值的归一化负编辑距离(Levenshtein Distance)。
实验结果
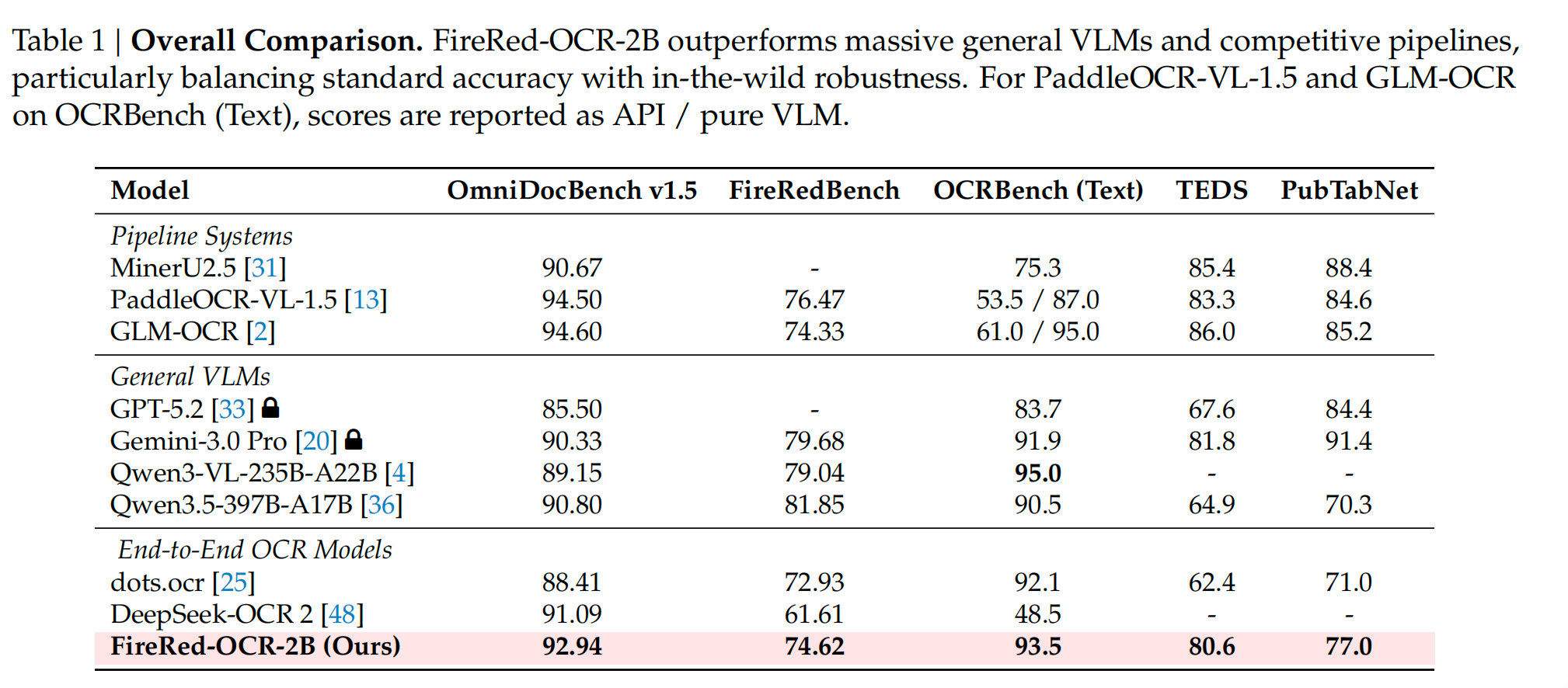
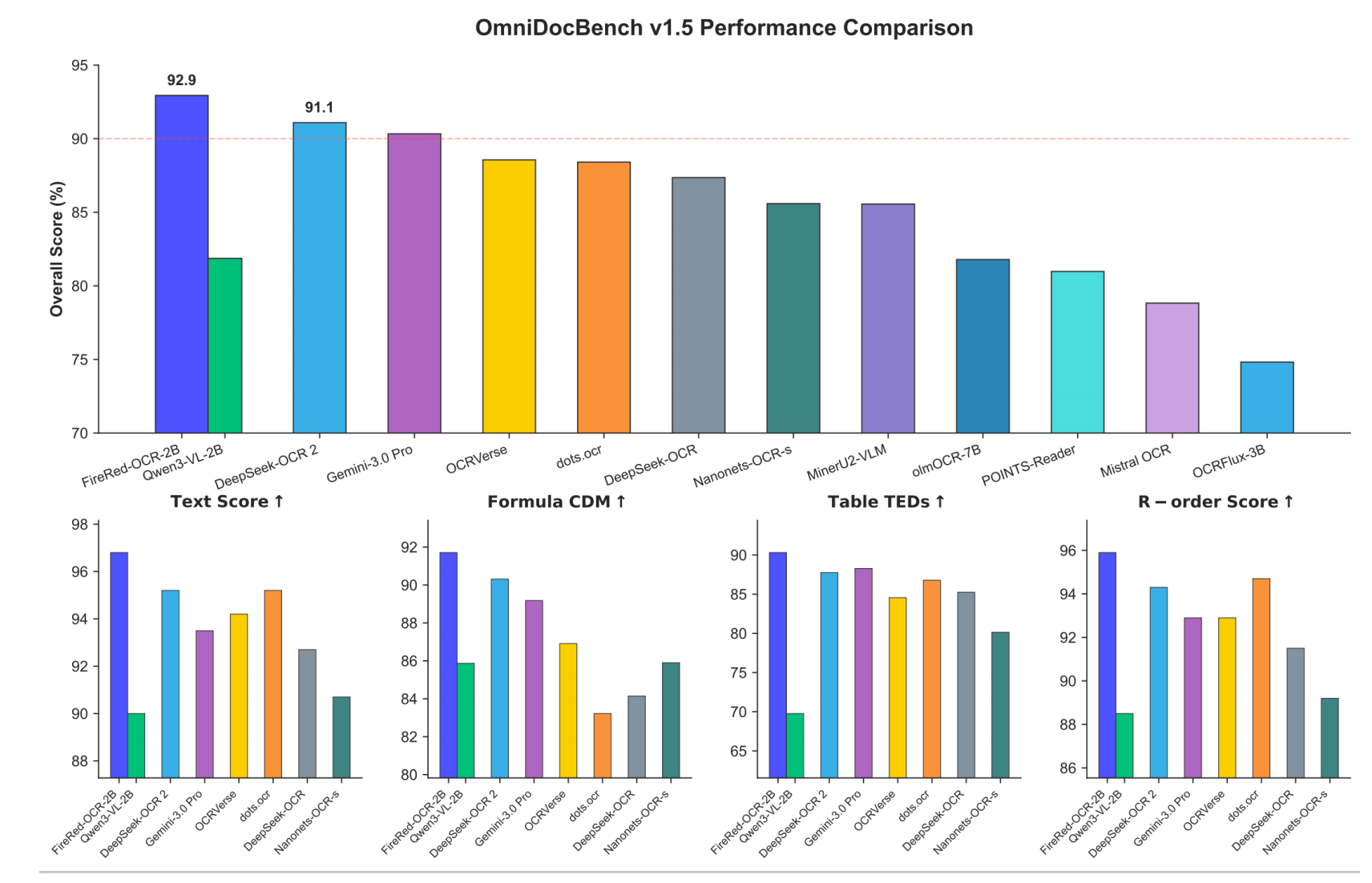
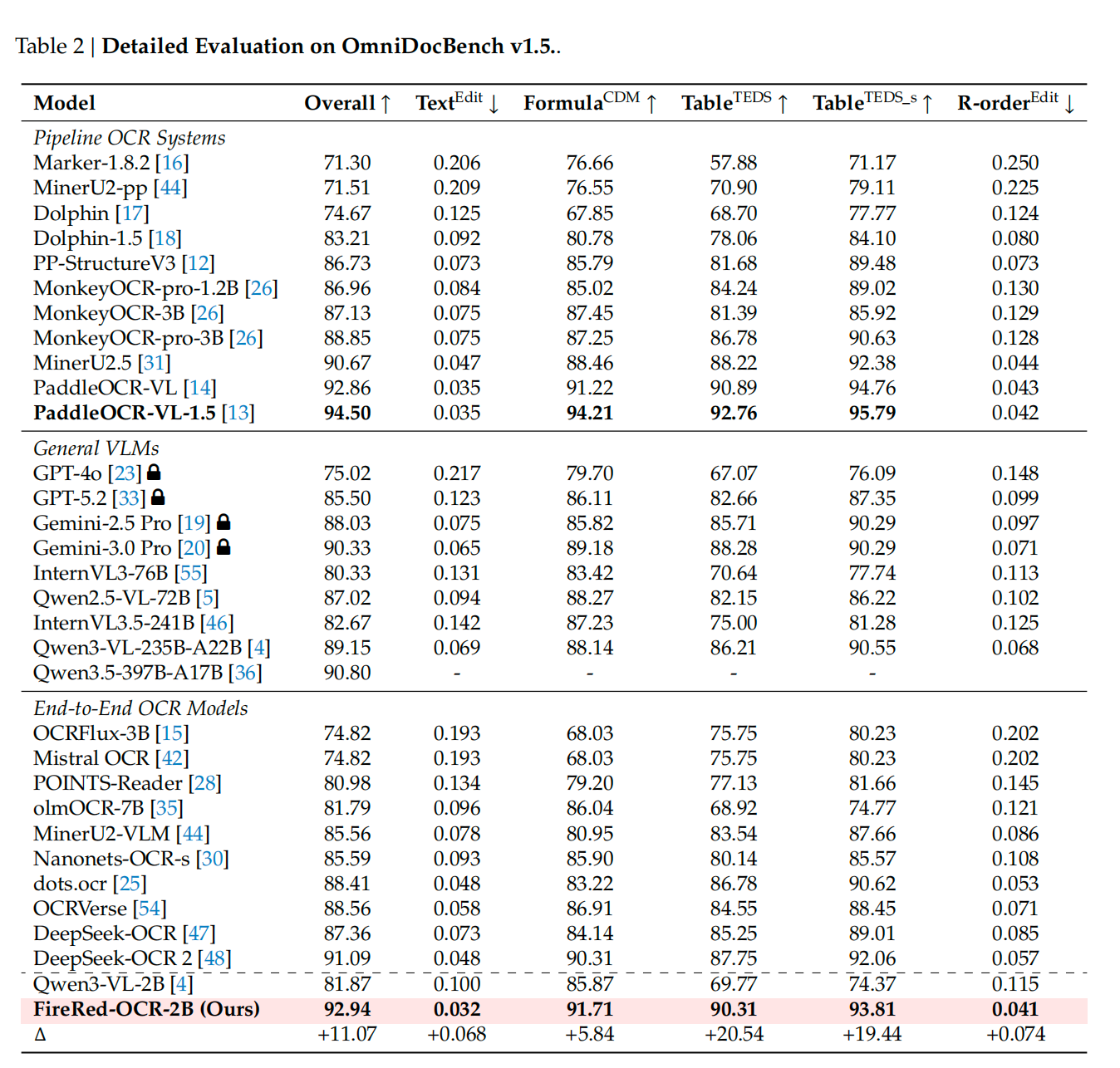
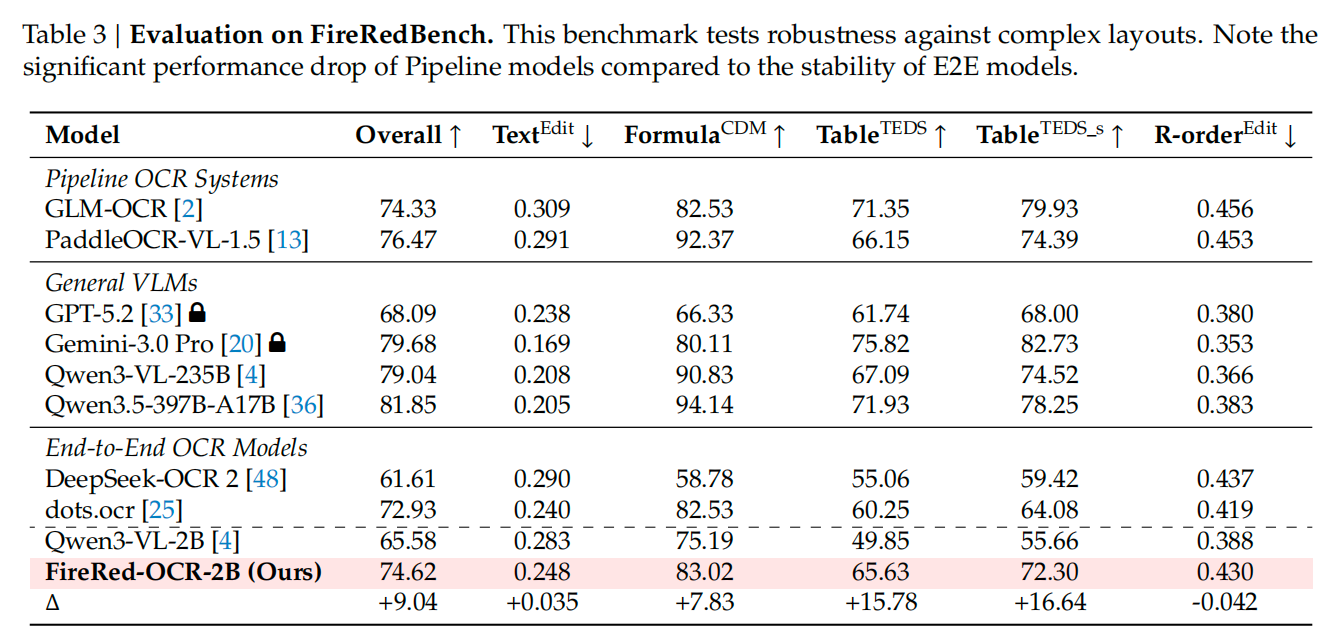
参考文献:Technical report:https://github.com/FireRedTeam/FireRed-OCR/blob/main/assets/FireRed_OCR_Technical_Report.pdf
往期相关
多模态文档解析的开源项目模型技术方案都在《文档智能专栏》,如:
...