部署需求
使用 Prometheus 抓取数据传给VM 数据库,VM数据库保证数据不丢且好查,用夜莺调用VM数据库,保证能看懂且不被告警烦死。这是目前性价比最高、体验最好的开源监控方案。最主要的原因是因为Alertmanager和Grafana对中文太不友好,而且太麻烦,自定义告警大屏幕,更多是适用于国产化需求比较大的企业。
项目架构图:
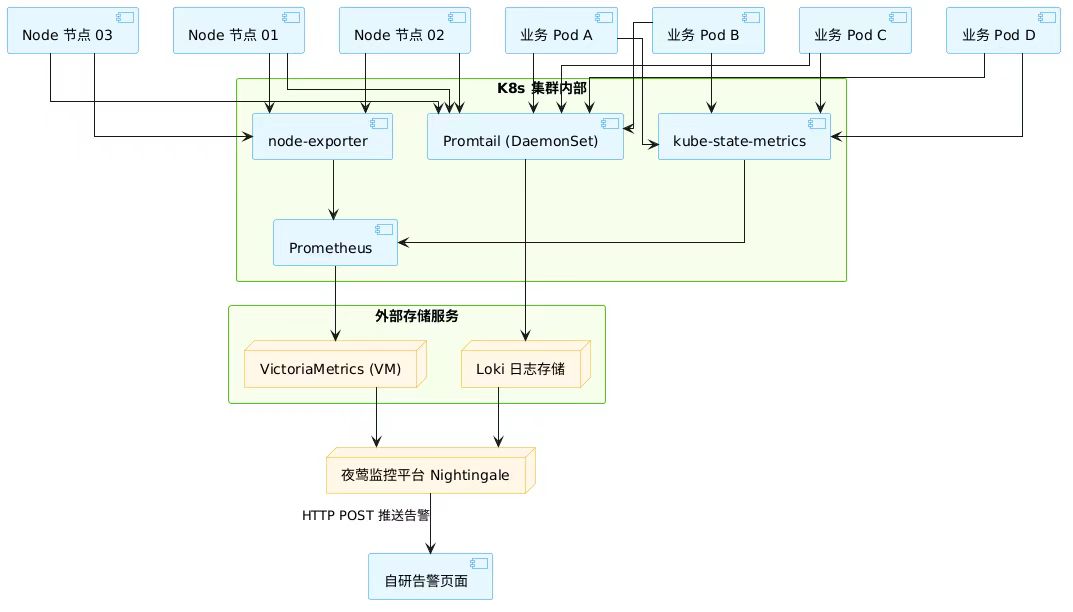
📥 采集 (收集)
指标:Node Exporter (主机) 和 Kube-State-Metrics (容器状态) 收集数据 ➡️ 送给 Prometheus。
日志:Promtail 收集容器日志 ➡️ 送给 Loki。
💾 存储 (存档)
Prometheus 把短期指标转存到 VictoriaMetrics (长期存储)。
Loki 直接存储日志。
🧠 分析 (告警)
夜莺 (Nightingale) 同时连接 VictoriaMetrics 和 Loki。
它负责看数据、跑规则,发现异常(如CPU过高、报错增多)。
🔔 通知 (触达)
夜莺通过 HTTP POST 把告警消息推送到 自研告警页面。
运维人员在页面上看到报警并处理。
Kubernetes 监控栈部署指南
架构组成:
- 采集层 : Prometheus Operator (
kube-prometheus-stack) - 存储层: VictoriaMetrics (单节点)
- 展示/告警层: Nightingale (夜莺)
- 依赖组件: MySQL, Redis (夜莺后端依赖)
📋 前置准备
1. 创建命名空间
kubectl create namespace yeyin2. 准备依赖组件 Helm 包 (可选离线模式)
如果您在离线环境,请先在有网的机器下载 Chart 包并传输到服务器。
🚀 第一步:部署 VictoriaMetrics (存储层)
使用 Docker 快速部署单节点 VictoriaMetrics,用于接收 Prometheus 推送的数据。
执行脚本:
docker run -d --name vm \
--restart=always \
-p 8428:8428 \
-v /data/vm-data:/vm-data \
victoriametrics/victoria-metrics:latest \
-retentionPeriod=3 \
-storageDataPath=/vm-data \
-httpListenAddr=:8428注意 :请确保服务器防火墙已放行 8428 端口,以便集群内的 Prometheus 能够访问。
📦 第二步:部署 Prometheus Operator (采集层)
1. 获取 Helm Chart
可以直接通过上传
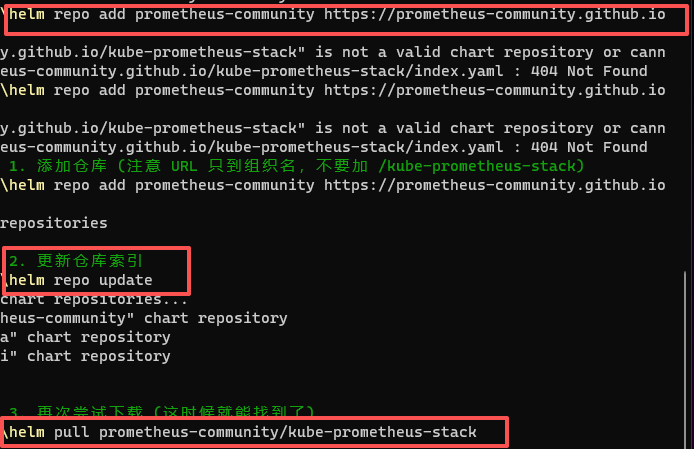
# 添加 Prometheus 社区仓库
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
# 下载 Chart 包 (在线模式)
helm pull prometheus-community/kube-prometheus-stack --destination ./charts
# 解压备用 (如果需要修改默认 values)
# tar -zxvf ./charts/kube-prometheus-stack-*.tgz2. 配置 values.yaml
创建名为 values.yaml 的文件,核心配置是将数据远程写入 (Remote Write) 到 VictoriaMetrics,并关闭不需要的组件以节省资源,不要报警项和granfana。
# ==========================================
# 1. Prometheus 核心配置
# ==========================================
prometheus:
prometheusSpec:
# --- 关键配置:远程写入 VictoriaMetrics ---
remoteWrite:
- url: "http://<YOUR_SERVER_IP>:8428/api/v1/write"
# 如果 VM 和 Prometheus 在同一台机器或内网互通,IP 填宿主机 IP
# 如果在集群内部通过 Service 访问,可改为 http://victoria-metrics.yeyin.svc:8428/api/v1/write
# 优化写入性能配置
queueConfig:
capacity: 10000 # 队列容量
maxShards: 200 # 最大并发分片
maxSamplesPerSend: 5000
batchSendDeadline: 5s
# --- 资源限制 (根据集群实际情况调整) ---
resources:
requests:
memory: 500Mi
cpu: 250m
limits:
memory: 2Gi
cpu: 1000m
# --- 数据保留时间 ---
# 因为数据都推送到 VM 了,本地只需保留少量数据用于缓冲
retention: 2h
# --- 存储配置 ---
# 建议保留少量本地存储以防网络波动,或使用 emptyDir
storageSpec:
volumeClaimTemplate:
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 5Gi
# --- 允许发现所有的 ServiceMonitor/PodMonitor ---
serviceMonitorSelectorNilUsesHelmValues: false
podMonitorSelectorNilUsesHelmValues: false
ruleSelectorNilUsesHelmValues: false
# ==========================================
# 2. 关闭 Alertmanager (由夜莺接管告警)
# ==========================================
alertmanager:
enabled: false
# ==========================================
# 3. 关闭 Grafana (由夜莺接管展示)
# ==========================================
grafana:
enabled: false
# ==========================================
# 4. Node Exporter (采集宿主机指标)
# ==========================================
prometheus-node-exporter:
enabled: true
# ==========================================
# 5. Kube State Metrics (采集 K8s 对象指标)
# ==========================================
kube-state-metrics:
enabled: true⚠️ 重要提示 :请将 url 中的 <YOUR_SERVER_IP> 替换为运行 VictoriaMetrics 的服务器真实 IP 地址。
3. 安装 Helm Chart
helm install k8s-monitor ./kube-prometheus-stack-*.tgz \
-f values.yaml \
-n yeyin \
--create-namespace
4. 验证数据写入
等待几分钟让 Pod 启动并开始采集,然后检查 VictoriaMetrics 是否收到数据。
# 查询 up 指标的数量,如果大于 0 说明数据写入成功
curl -g 'http://localhost:8428/api/v1/query?query=up' | jq '.data.result | length'
🌙 第三步:部署 Nightingale (夜莺监控平台)
夜莺需要 MySQL 和 Redis 作为后端存储。您可以选择手动部署 DB,或使用 Docker Compose 一键部署全套(含 DB)。此处推荐使用官方提供的 Docker Compose 方式。
1. 克隆代码
cd /root
git clone https://github.com/ccfos/nightingale.git
cd nightingale/docker/compose-bridge2. 启动服务
确保当前目录下有 docker-compose.yml 文件(通常包含 n9e, mysql, redis, prometheus 等容器定义,但我们可以只利用它的 DB 部分,或者全量启动后配置数据源)。
方式 A:全量启动 (推荐新手,包含内置的 MySQL/Redis)
version: '3.8'
# 定义一个独立的网络,确保内部服务互通
networks:
n9e-network:
driver: bridge
services:
# 1. MySQL: 存储夜莺的配置、用户、告警规则等元数据
mysql:
image: mysql:8.0
container_name: n9e-mysql
hostname: mysql
restart: always
environment:
TZ: Asia/Shanghai
MYSQL_ROOT_PASSWORD: 1234
MYSQL_DATABASE: n9e
MYSQL_CHARACTER_SET_SERVER: utf8mb4
MYSQL_COLLATION_SERVER: utf8mb4_unicode_ci
volumes:
- ./mysqldata:/var/lib/mysql
# 确保 ../initsql 目录下有 n9e.sql 初始化脚本
- ../initsql:/docker-entrypoint-initdb.d/
- ./etc-mysql/my.cnf:/etc/my.cnf
networks:
- n9e-network
ports:
- "3306:3306"
command: --default-authentication-plugin=mysql_native_password
# 2. Redis: 存储缓存、会话、临时数据
redis:
image: redis:6.2-alpine
container_name: n9e-redis
hostname: redis
restart: always
environment:
TZ: Asia/Shanghai
networks:
- n9e-network
ports:
- "6379:6379"
command: redis-server --appendonly yes
# 3. Nightingale: 核心 Web 服务
nightingale:
image: flashcatcloud/nightingale:latest
container_name: n9e-server
hostname: nightingale
restart: always
environment:
GIN_MODE: release
TZ: Asia/Shanghai
# 等待 MySQL 和 Redis 启动后再启动夜莺
WAIT_HOSTS: mysql:3306,redis:6379
WAIT_TIMEOUT: 30
volumes:
- ./etc-nightingale:/app/etc
networks:
- n9e-network
ports:
- "17000:17000" # Web 界面端口
- "20090:20090" # 数据接收端口 (虽然你主要用拉取模式,但保留以防万一)
depends_on:
- mysql
- redis
command:
- /app/n9e
docker compose up -d注:全量启动后,夜莺自带了一个内置的 Prometheus,您需要进入夜莺界面,将数据源修改为我们刚才部署的 VictoriaMetrics ( http://
方式 B:仅启动 DB (如果您想单独部署夜莺后端二进制)
如果您只想用 docker 跑 MySQL 和 Redis:
- 编辑
docker-compose.yml,注释掉n9e(夜莺后端) 和10.prometheus相关服务,只保留mysql和redis。 - 执行
docker compose up -d。 - 然后去夜莺官网下载 Linux 二进制包运行
n9e服务。

3. 配置夜莺数据源
- 登录夜莺 Web 界面 (默认端口通常为 17000,账号root,密码root.2020)。
- 进入 系统设置 -> 数据源管理。
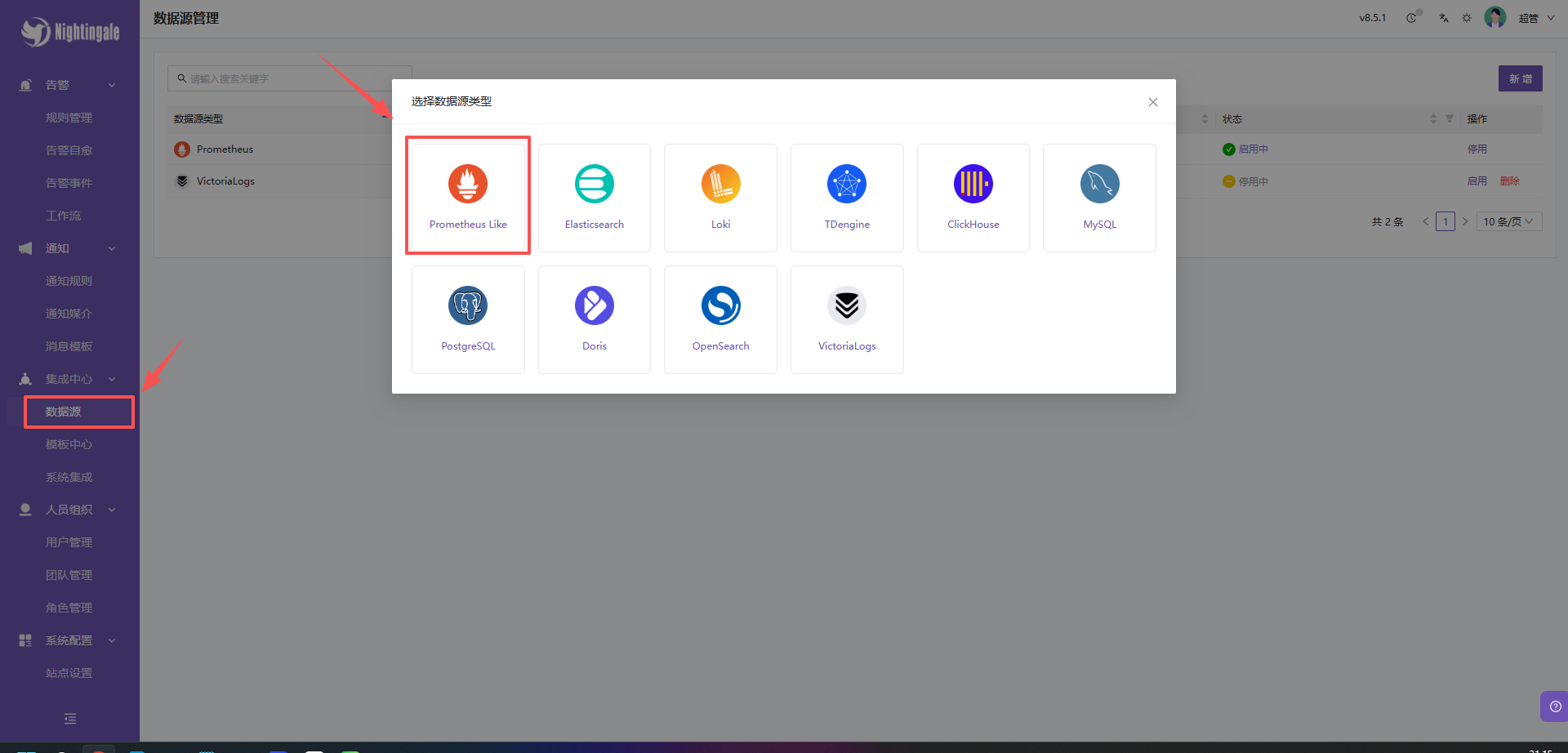
- 添加新数据源:
-
- 类型 :
Prometheus Like - 名称 :
VictoriaMetrics-K8s - URL :
http://<YOUR_SERVER_IP>:8428 - 设为默认: ✅ 勾选
- 类型 :
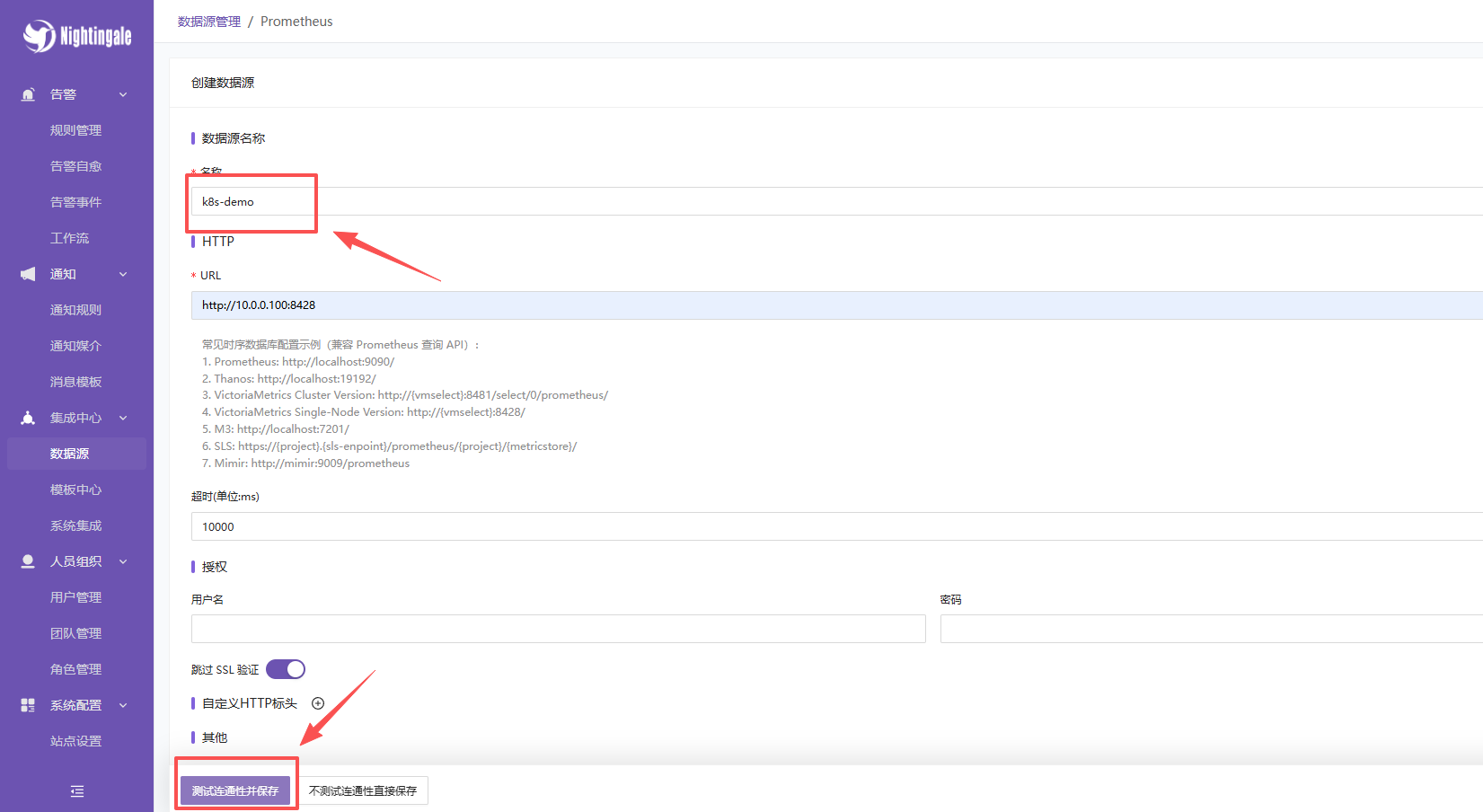
- 保存并测试连接。
4. 配置仪表盘
- 登录夜莺 Web 界面,选择仪表盘。
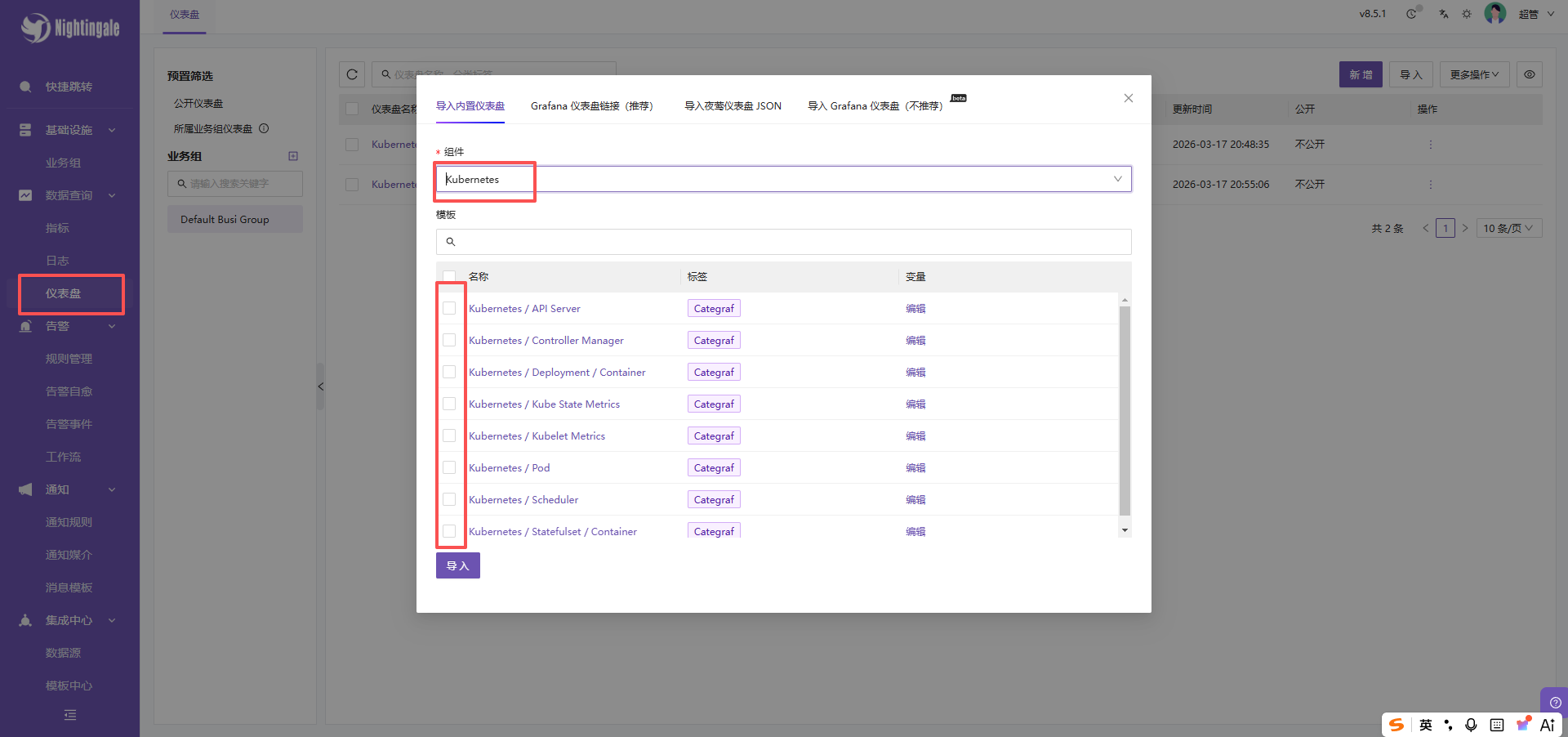
- 导入一个文件 -> 选择k8s->选择模版。
✅ 验证与使用
-
查看 Pod 状态:
kubectl get pods -n yeyin
确保 prometheus-k8s-monitor-prometheus-0, node-exporter-*, kube-state-metrics-* 均为 Running 状态。
- 导入仪表盘:
-
- 在夜莺界面,进入 仪表盘 -> 内置仪表盘。
- 搜索
Kubernetes或Node Exporter。 - 导入模板,选择刚才配置的
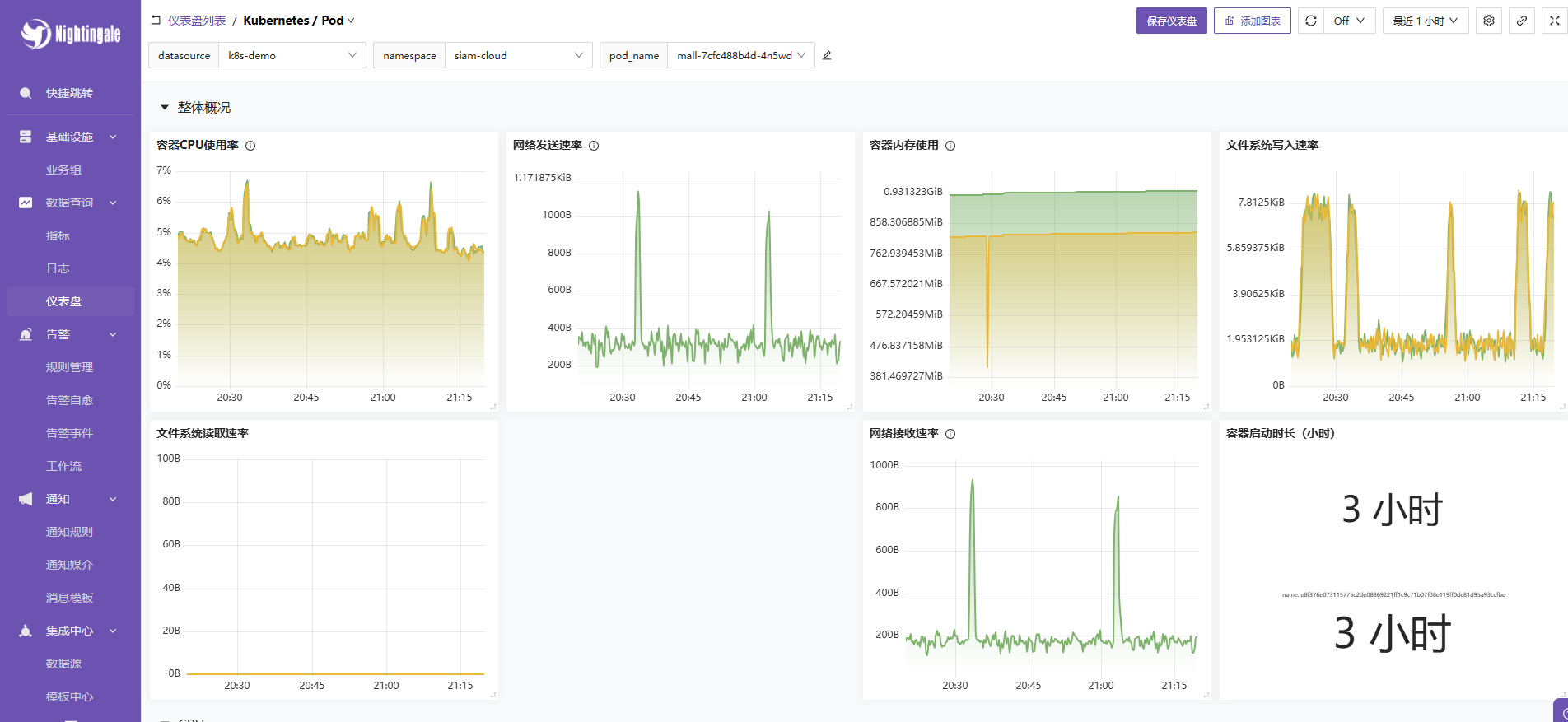
VictoriaMetrics-K8s数据源。 - 现在您应该能看到集群的 CPU、内存、Pod 状态等图表了!
- 解决"看不到主机列表"问题:
-
- 由于未部署 Categraf,夜莺无法自动注册主机。
- 解决方法 :在夜莺中创建一个 自建仪表盘 ,使用 Table (表格) 面板,编写 PromQL (如
up{job="kubernetes-nodes"}) 来展示所有节点的状态列表。
🔧 故障排查小贴士
- 数据不显示?
-
- 检查 Prometheus Pod 日志:
kubectl logs -n yeyin -l app.kubernetes.io/name=prometheus --tail=100,查看是否有remote write相关的错误。 - 检查网络连通性:在 Prometheus Pod 内
curl http://<VM_IP>:8428/api/v1/write。
- 检查 Prometheus Pod 日志:
- 夜莺连不上 VM?
-
- 确认服务器防火墙 (
firewalld/ufw/安全组) 已开放 8428 端口。 - 确认 URL 没有多余的
/api/v1/query后缀,只需写到端口。
- 确认服务器防火墙 (
- 为什么使用夜莺?
-
- 第一点肯定是中文,比granfan要操作,但是每个granfan好看,可以玩性低。
- 国产化,支持国产化。
- 最重要的一点就是强大的告警系统,这篇文章没有讲解,下期单独出一期。
📚 Loki + Promtail 日志系统部署与夜莺查询指南
本文档记录了从单机 Loki 部署、K8s Promtail 采集配置到夜莺(Nightingale)数据源接入及查询的完整流程。
1. 🐳 Loki 服务端部署 (Docker Compose)
在宿主机(如 10.0.0.100)上创建配置文件并启动 Loki 服务。
1.1 创建配置文件 loki-config.yaml
cat > loki-config.yaml << 'EOF'
auth_enabled: false
server:
http_listen_port: 3100
grpc_listen_port: 9096
common:
instance_addr: 127.0.0.1
path_prefix: /tmp/loki
storage:
filesystem:
chunks_directory: /tmp/loki/chunks
rules_directory: /tmp/loki/rules
replication_factor: 1
ring:
kvstore:
store: inmemory
query_range:
results_cache:
cache:
embedded_cache:
enabled: true
max_size_mb: 100
schema_config:
configs:
- from: 2020-10-24
store: tsdb
object_store: filesystem
schema: v13
index:
prefix: index_
period: 24h
# 【可选】防止磁盘爆满,设置保留时间 (例如保留 7 天)
# compactor:
# working_directory: /tmp/loki/compactor
# shared_store: filesystem
# limits_config:
# retention_period: 168h
EOF1.2 创建 docker-compose.yml
version: "3.8"
services:
loki:
image: grafana/loki:2.9.3
container_name: loki
ports:
- "3100:3100"
volumes:
- ./loki-config.yaml:/etc/loki/local-config.yaml:ro
# 【重要】将数据挂载到宿主机目录,防止容器删除后数据丢失
- /data/loki:/tmp/loki
command: -config.file=/etc/loki/local-config.yaml
restart: unless-stopped
# 如果宿主机内存紧张,可以限制容器内存
# deploy:
# resources:
# limits:
# memory: 2G1.3 启动服务
mkdir -p /data/loki
docker-compose up -d2. ☸️ Promtail 采集端部署 (Helm)
在 K8s 集群中部署 Promtail DaemonSet,负责采集各节点日志并发送给 Loki。
2.1 准备 Helm Chart
上传并解压 Promtail Helm Chart 包:
# 假设 chart 包已上传至 /opt/loki/
cd /opt/loki/helm-charts-promtail-6.17.12.2 自定义配置文件 my-values.yaml
此配置启用了静态文件扫描,并通过正则从文件路径中提取 namespace, pod, container 标签。
# my-values.yaml
config:
# 禁用自动生成的默认客户端配置,使用自定义地址
clients:
- url: http://10.0.0.100:3100/loki/api/v1/push
tenant_id: default
# 【关键】开启宿主机根文件系统挂载,并设置双向传播,确保能读取 /var/log/pods
hostRootFsMount:
enabled: true
mountPropagation: Bidirectional
snippets:
scrapeConfigs: |
# 使用静态配置扫描所有 Pod 日志
- job_name: kubernetes-pods-static
static_configs:
- targets:
- localhost
labels:
job: varlogs
__path__: /var/log/pods/*/*/*.log
pipeline_stages:
- cri: {} # 自动处理容器运行时日志格式 (CRI)
relabel_configs:
# 从路径提取 Namespace (格式: /var/log/pods/<ns>_<pod>_<uid>/<container>/...)
- source_labels: [__path__]
regex: '/var/log/pods/([^_]+)_([^_]+)_([^/]+)/([^/]+)/[^/]+\.log'
replacement: '${1}'
target_label: namespace
# 从路径提取 Pod Name
- source_labels: [__path__]
regex: '/var/log/pods/([^_]+)_([^_]+)_([^/]+)/([^/]+)/[^/]+\.log'
replacement: '${2}'
target_label: pod
# 从路径提取 Container Name
- source_labels: [__path__]
regex: '/var/log/pods/([^_]+)_([^_]+)_([^/]+)/([^/]+)/[^/]+\.log'
replacement: '${4}'
target_label: container
# 提取流名称 (通常用 container 名)
- source_labels: [__path__]
regex: '/var/log/pods/([^_]+)_([^_]+)_([^/]+)/([^/]+)/[^/]+\.log'
replacement: '${4}'
target_label: stream2.3 安装 Promtail
helm install promtail ./charts/promtail -n logging -f my-values.yaml --create-namespace注意 :请确保 ./charts/promtail 是解压后的正确目录路径。
3. 🔭 夜莺 (Nightingale) 配置与查询
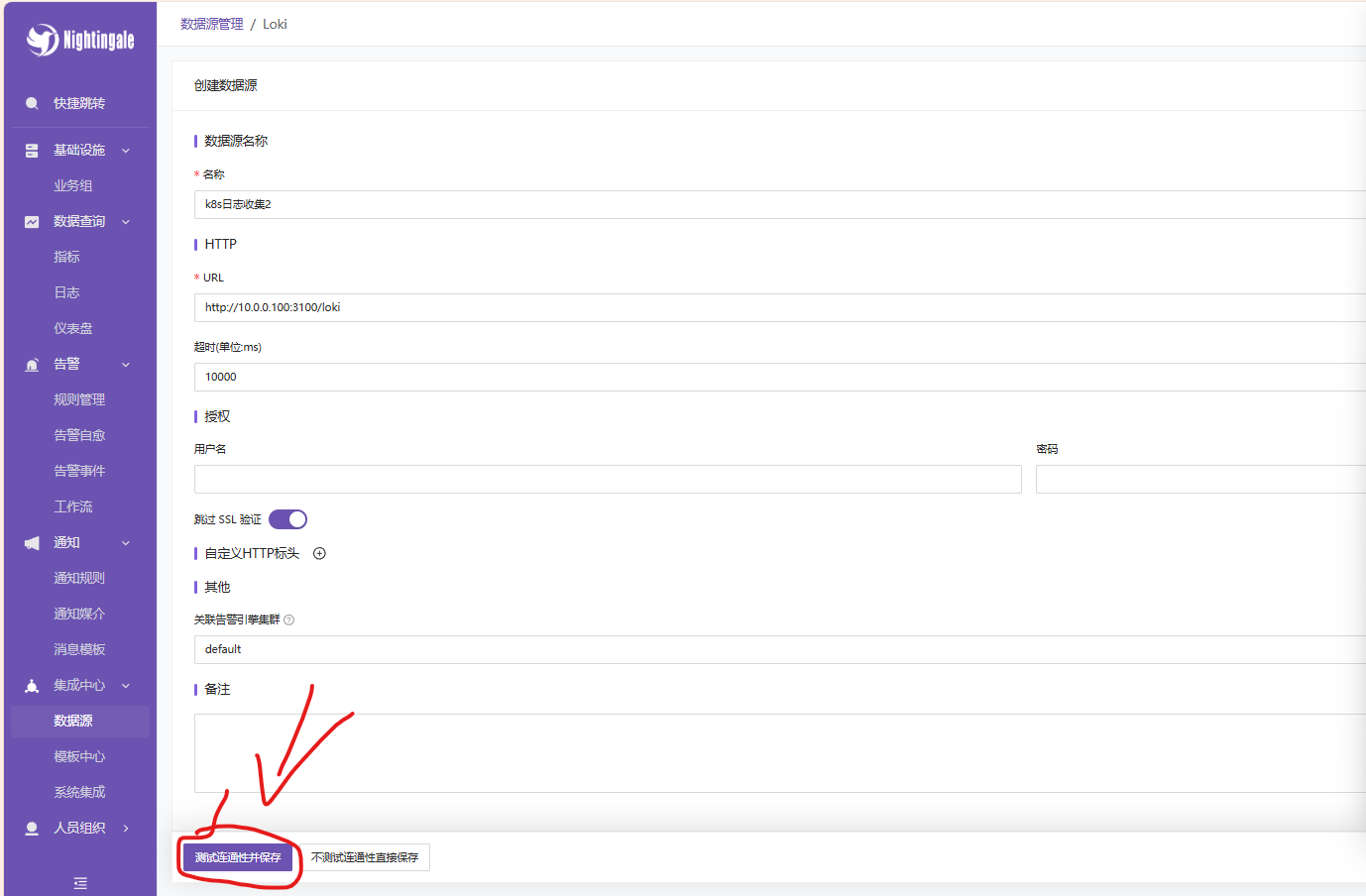
3.1 添加数据源
- 登录夜莺控制台。
- 进入 数据源管理 -> 新增数据源。
- 选择类型:Loki。
- 填写信息:
-
- 名称 :
Loki-Prod(自定义) - URL : http://10.0.0.100:3100/loki (确保夜莺服务器能网络通达此地址)
- 认证 : 无 (根据
loki-config.yaml中auth_enabled: false)
- 名称 :
- 点击 测试连接,显示成功后保存。
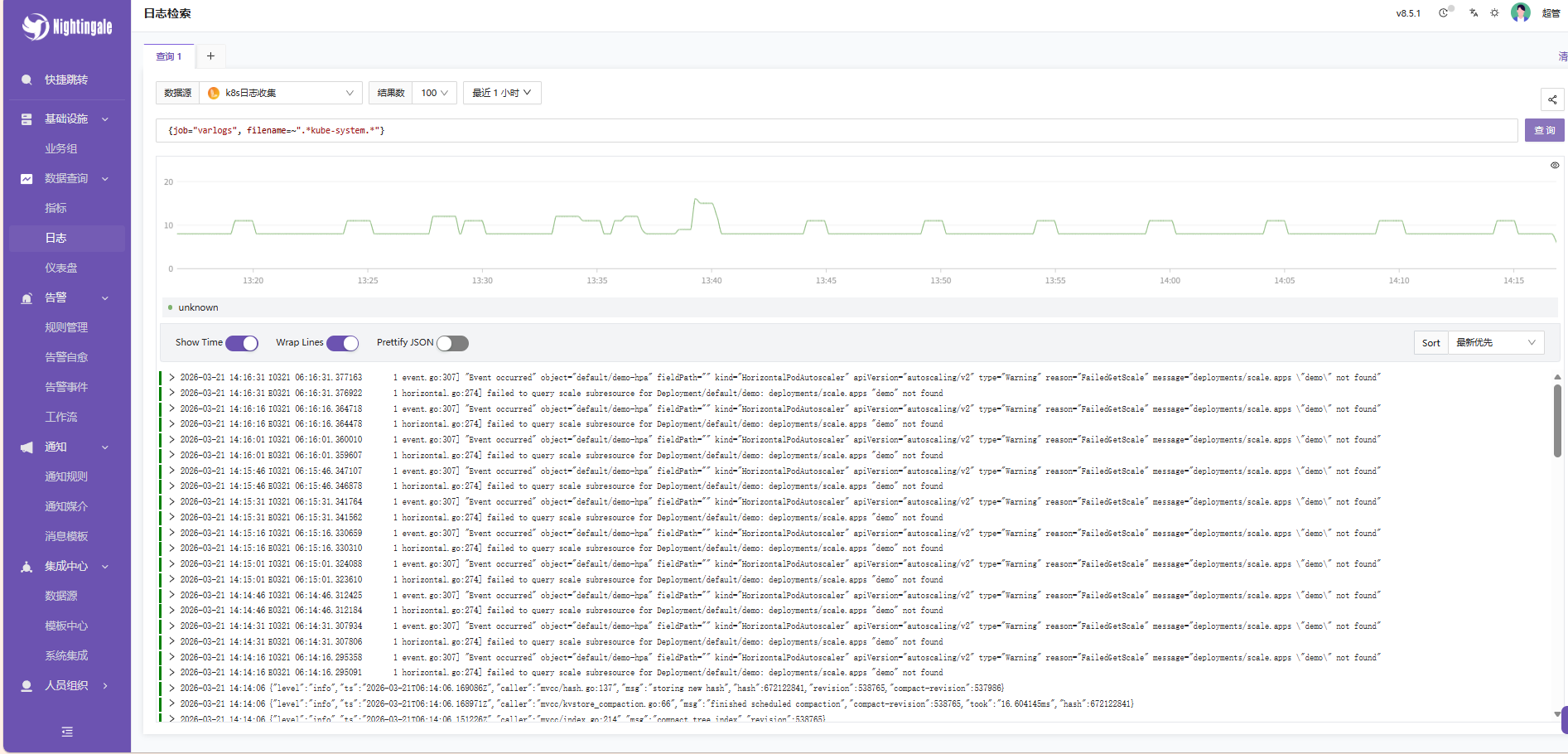
3.2 日志查询示例
进入 可观测性 -> 日志探索 ,选择刚才添加的 Loki-Prod 数据源。
场景:查询 kube-system 命名空间的日志
由于我们在 Promtail 配置中通过正则提取了 namespace 标签,现在可以直接使用该标签进行高效过滤。
LogQL 查询语句:
{job="varlogs", namespace="kube-system"}或者,如果你想模糊匹配文件名(如果 filename 标签也被保留了):
{job="varlogs", filename=~".*kube-system.*"}操作步骤:
- 在查询框输入上述语句。
- 右上角时间范围选择 最近 1 小时 或 最近 24 小时。
- 点击 运行 (Run)。
- 下方将展示日志列表,支持关键字高亮和上下文查看。
自定义告警大屏与通知网关部署指南
本方案通过 python语言编写了一套轻量级的告警规则管理与可视化平台。该平台暴露 5000 端口,作为 夜莺 (Nightingale) 的自定义通知媒介(Webhook),实现告警信息的统一接收、大屏展示及规则管理。
1. 📦 部署方式
1.1 准备环境
确保服务器(10.0.0.100)已安装 Docker 和 Docker Compose。
1.2 上传代码
将 Codex AI 生成的项目代码包上传至服务器指定目录(例如 /opt/alert-dashboard)。
cd /opt1.3 启动服务
使用 Docker Compose 一键启动应用。
docker compose up -d1.4 访问验证
启动完成后,通过浏览器访问:
地址 : http://10.0.0.100:5000
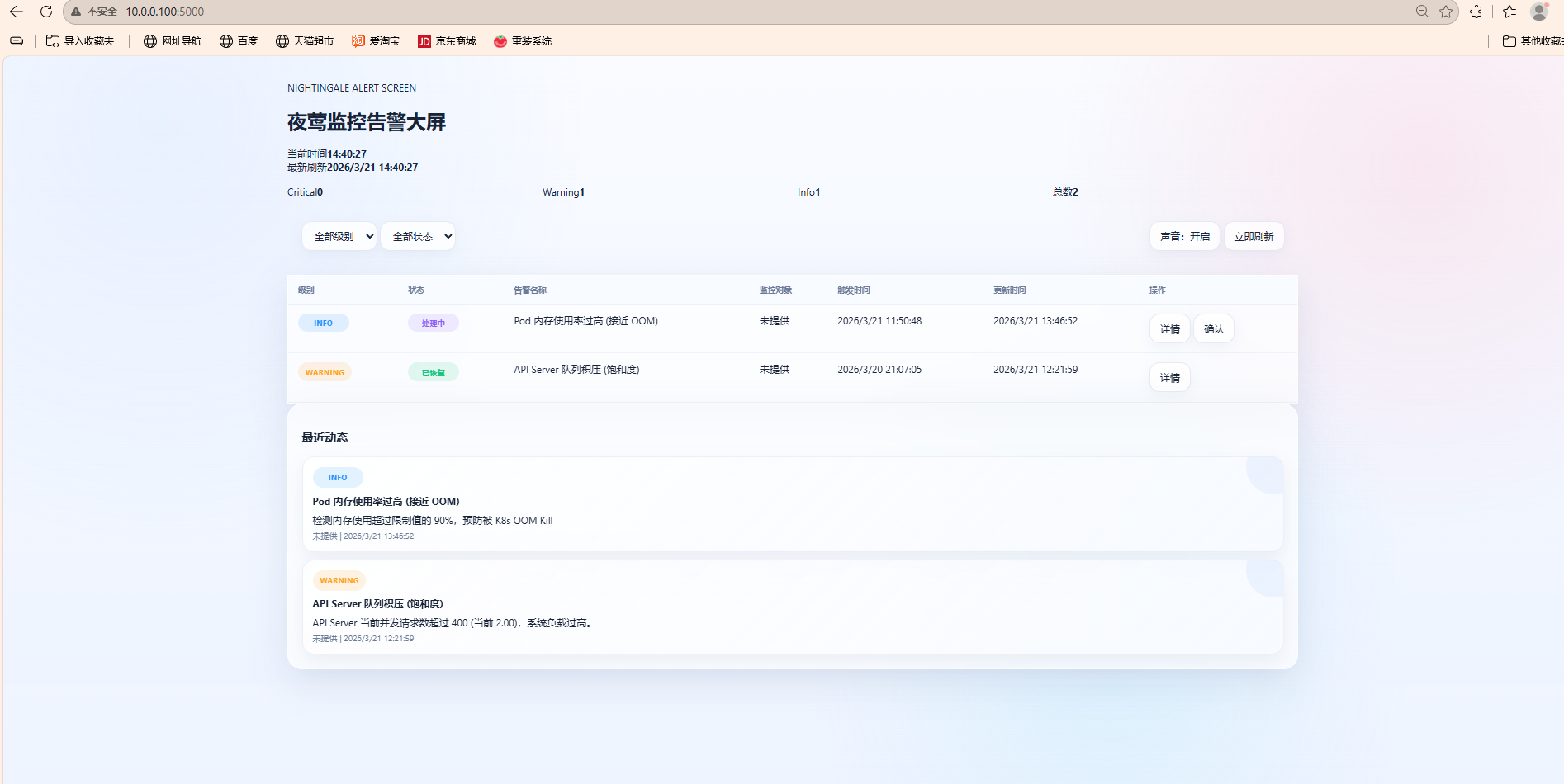
您将看到包含以下核心模块的告警大屏:
- 实时告警列表
- 规则管理中心
- 通知媒介配置
- 统计图表
2. 🏗️ 核心概念与架构逻辑
本平台在夜莺告警体系中扮演 "通知网关" 的角色,其核心逻辑分层如下:
|-------------------------------------|-----------------------------------------|----------------------------------------------------------|
| 层级 | 概念定义 | 本平台中的作用 |
| L1: 通知媒介 (Notification Channel) | 发送通道 。 定义告警通过何种工具(钉钉、飞书、邮件、HTTP)送达。 | 提供一个标准的 HTTP Webhook 接口,接收夜莺推送的告警 JSON 数据,并在大屏上实时展示。 |
| L2: 通知规则 (Notification Rule) | 路由与模板 。 定义"谁"在"什么条件"下收到"什么样"的告警。 | 在夜莺中配置,将告警事件绑定到本平台的 HTTP 媒介,并设定接收团队。 |
| L3: 规则管理 (Rule Management) | 触发条件 。 定义监控指标何时被视为异常(PromQL/LogQL)。 | 在本平台大屏上查看规则状态,或在夜莺中创建/导入具体的 PromQL 告警规则。 |
3. ⚙️ 配置流程详解
第一步:创建通知媒介 (在夜莺中配置)
此步骤告诉夜莺:"当告警触发时,请把数据发给我们的自定义大屏"。
- 登录 夜莺控制台 -> 告警管理 -> 通知媒介。
- 点击 新增媒介 ,选择类型:HTTP/Webhook。
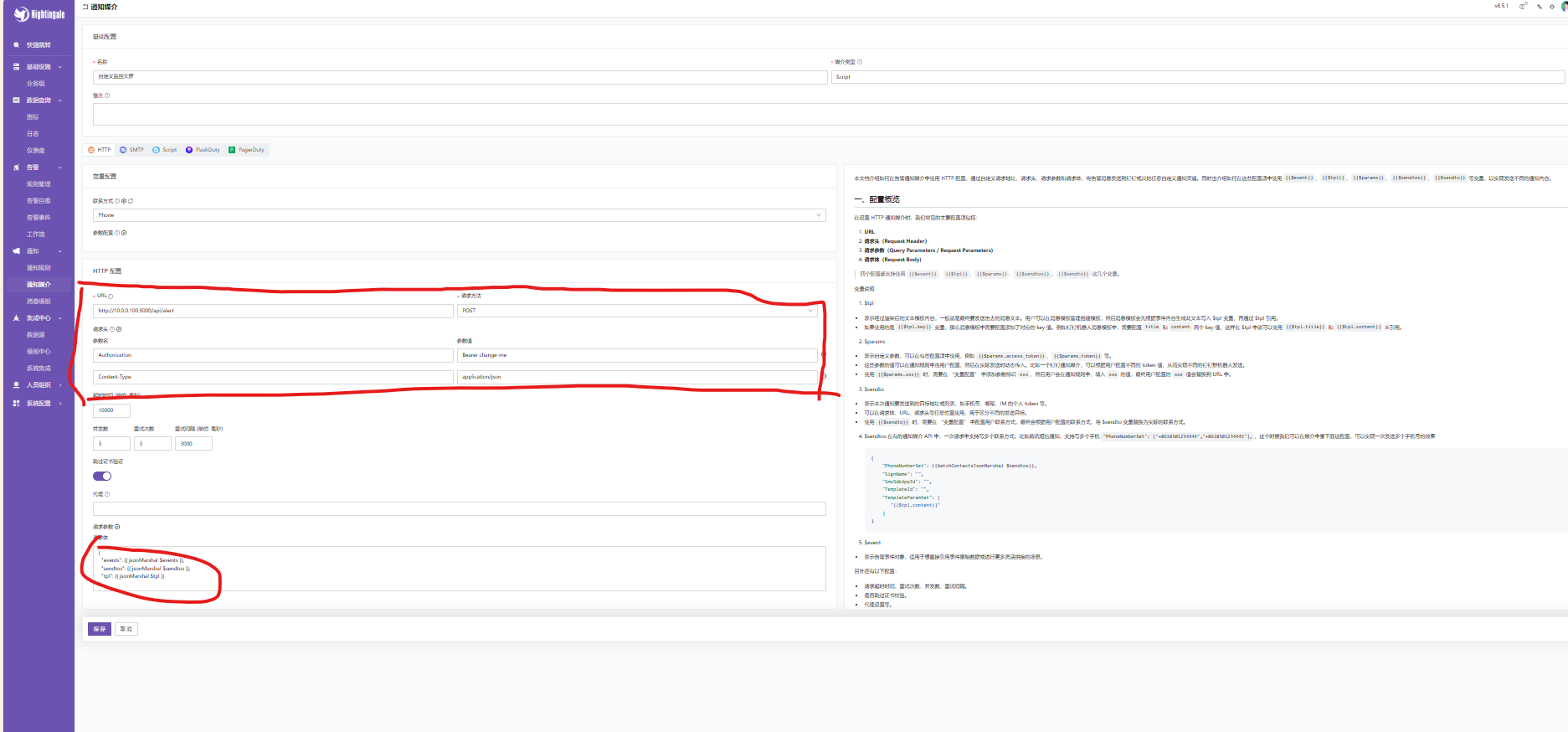
- 填写配置信息:
-
- 名称 :
Custom Alert Dashboard - 请求 URL :
http://10.0.0.100:5000/api/alert - 请求方式 :
POST - 请求头 (Headers):
- 名称 :
|-----------------|--------------------|
| 参数名 (Key) | 参数值 (Value) |
| Authorization | Bearer change-me |
| Content-Type | application/json |
-
-
请求体 (Body) (选择
JSON或Raw, 填入以下模板):{
"events": {{ jsonMarshal events }}, "sendtos": {{ jsonMarshal sendtos }},
"tpl": {{ jsonMarshal $tpl }}
}
-
(注: *{{ ... }}*是夜莺的模板语法,会在发送时自动渲染为实际数据)
- 点击 测试连接 ,确保返回
200 OK。 - 保存配置。
第二步:配置通知规则 (在夜莺中配置)
此步骤定义告警的流转逻辑。
- 进入 告警管理 -> 通知规则 (或订阅规则)。
- 点击 新建规则。
- 配置内容:
-
- 规则名称 :
生产环境核心告警通知 - 适用团队 : 选择对应的运维或开发团队(如
SRE-Team)。 - 绑定媒介 : 勾选上一步创建的
Custom Alert Dashboard。 - 生效时间 :
7x24h(或自定义)。 - 屏蔽设置: (可选) 设置维护期屏蔽。
- 规则名称 :
- 保存规则。

第三步:创建/导入告警规则 (在夜莺中配置)
定义具体的监控指标阈值。
方式 A:手动创建
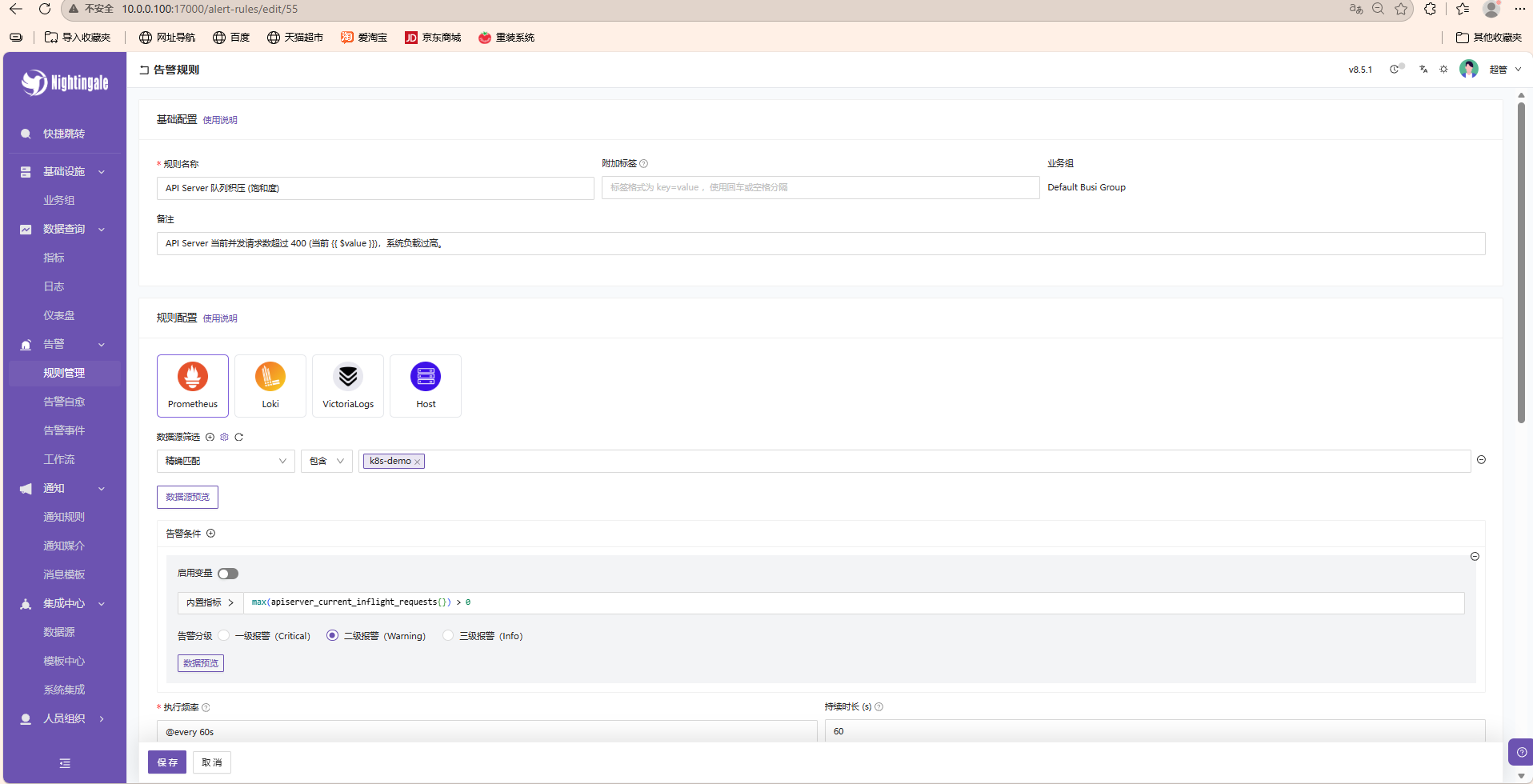
-
进入 告警管理 -> 告警规则 -> 新建规则。
-
数据源: 选择对应的 Prometheus 或 Loki 数据源。
-
查询语句 (PromQL):
max(apiserver_current_inflight_requests{}) > 400
(示例:监控 API Server 是否有积压请求)
- 触发条件:
-
- 持续时间:
1m(持续 1 分钟超过阈值才报警) - 严重等级:
Critical
- 持续时间:
- 关联通知规则 : 选择第二步创建的
生产环境核心告警通知。 - 测试 : 点击"立即测试"或"模拟触发",观察
10.0.0.100:5000大屏是否收到数据。
方式 B:导入现有规则 (推荐)
如果您已有成熟的规则配置文件(YAML/JSON):
- 进入 告警规则 列表页。
- 点击 导入 按钮。
- 上传文件或粘贴内容。
- 系统会自动解析并批量创建规则,请检查绑定的 通知规则 是否正确指向了新的大屏媒介。
4. 🔍 验证与运维
验证链路
- 触发: 手动制造一个异常(或等待自然触发)。
- 夜莺: 确认夜莺告警事件列表中产生了新事件。
- 传输 : 确认夜莺执行了通知动作,日志显示
POST http://10.0.0.100:5000/api/alert成功。 - 展示 : 刷新
http://10.0.0.100:5000大屏,确认:
-
- 告警卡片出现。
- 告警内容(指标值、时间、标签)显示正确。
- 颜色/等级标识符合预期。
安全提示
- Token 修改 : 部署后,建议修改代码中的默认 Token (
change-me),并在夜莺的通知媒介配置中同步更新,以防未授权访问。 - 网络策略 : 确保夜莺服务器到
10.0.0.100:5000的网络连通性。
通过以上步骤,您已成功构建了一个闭环的告警系统:从底层的指标采集 (Prometheus/Loki) -> 告警判断 (夜莺) -> 通知分发 (自定义 HTTP 媒介) -> 最终可视化展示 (自研大屏)。