目录

1.摘要
针对污水处理过程(WWTP)中进水波动大、传统进化算法难以利用预估信息进行长期优化的问题,本文提出了一种强化学习辅助粒子群算法(RLA-PSO),该框架通过集成管网与厂站系统实现进水预估,并利用深度Q网络(DQN)在长尺度上学习状态、动作与奖励的关联,弥补了传统算法在长期调度决策上的局限性,同时引入基于集合粒子群算法(S-PSO)进行精细化搜索进一步提升强化学习的收敛效果。
2.问题描述
污水处理厂进水调度
当前污水处理厂主要采用 A 2 O A^{2}O A2O工艺,由五个连续阶段的反应器组成。调度核心在于调节反应器两侧的闸门开度,决策变量为离散的闸门开度等级 k ∈ { 1 , 2 , ... , 5 } k\in\{1,2,\ldots,5\} k∈{1,2,...,5}。在每个检测周期 Δ t \Delta t Δt时刻, 需确定一个 5 维动作向量:
K = k 1 , k 2 , k 3 , k 4 , k 5 K=k_{1},k_{2},k_{3},k_{4},k_{5} K=k1,k2,k3,k4,k5
在建模层面,研究假设进水预测精确、闸门切换瞬时且检测间隔恒定,其目标是通过优化该向量序列提升出水质量表现。
数学模型
针对污水处理过程中的水质达标要求,本文构建了以出水总氮(TN)最小化为目标的离散时间调度模型。由于污水处理涉及复杂的非线性生化反应,传统的机理模型难以精确描述,本文采用径向基函数(RBF)神经网络建立数据驱动模型,将闸门开度 K K K、进水流量 F l 0 Fl_{0} Fl0、第五阶段溶解氧 S O 5 SO_{5} SO5以及第二阶段硝态氮 S N O 2 SNO_{2} SNO2作为核心决策变量。
min T N ( t ) = f ( K ( t ) , F l 0 ( t ) , S O 5 ( t ) , S N O 2 ( t ) ) \min TN(t)=f(K(t),Fl_0(t),SO_5(t),SNO_2(t)) minTN(t)=f(K(t),Fl0(t),SO5(t),SNO2(t))
s . t . { k i ( t ) ∈ { 1 , 2 , 3 , 4 , 5 } , i = 1 , ... , 5 S O 5 min ≤ S O 5 ( t ) ≤ S O 5 max S N O 2 min ≤ S N O 2 ( t ) ≤ S N O 2 max V min ≤ V i ( t ) ≤ V max , i = 1 , ... , 5 V i ( t ) = ∑ t = 1 T F l i − 1 ( t ) ⋅ k i − 1 ( t ) − F l i ( t ) ⋅ k i ( t ) 4 \begin{aligned}&s.t.\begin{cases}k_i(t)\in\{1,2,3,4,5\},\quad i=1,\ldots,5\\SO_{5\min}\leq SO_5(t)\leq SO_{5\max}\\SNO_{2\min}\leq SNO_2(t)\leq SNO_{2\max}\\V_{\min}\leq V_i(t)\leq V_{\max},\quad i=1,\ldots,5\\V_i(t)=\sum_{t=1}^T\frac{Fl_{i-1}(t)\cdot k_{i-1}(t)-Fl_i(t)\cdot k_i(t)}4&\end{cases}\end{aligned} s.t.⎩ ⎨ ⎧ki(t)∈{1,2,3,4,5},i=1,...,5SO5min≤SO5(t)≤SO5maxSNO2min≤SNO2(t)≤SNO2maxVmin≤Vi(t)≤Vmax,i=1,...,5Vi(t)=∑t=1T4Fli−1(t)⋅ki−1(t)−Fli(t)⋅ki(t)
3.求解算法
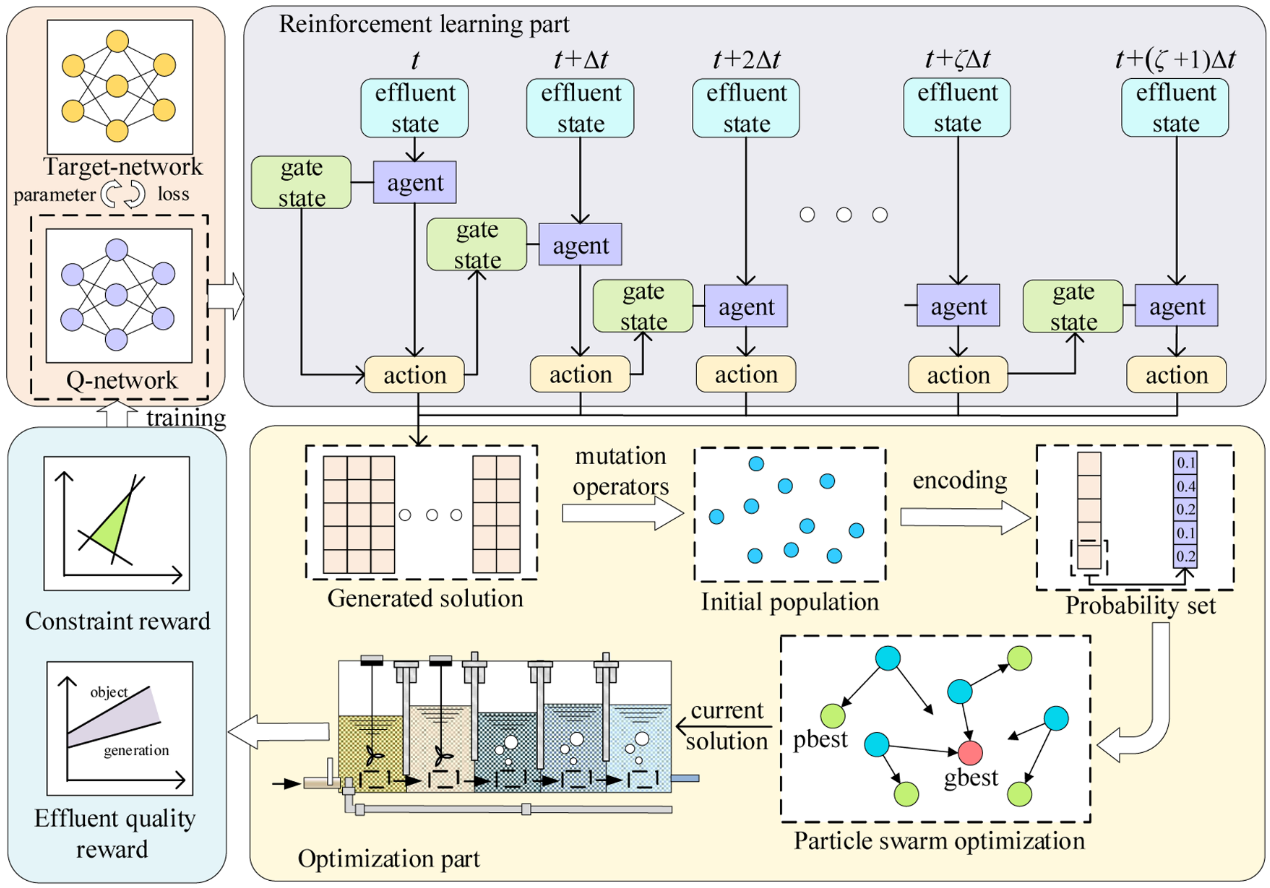
针对进水预估场景下的污水处理调度,本文提出了 RLA-PSO 算法框架,通过强化学习与进化计算的解空间耦合实现动态寻优。
强化学习引导阶段,在 t t t 时刻,Agent将未来 ζ Δ t \zeta \Delta t ζΔt 窗口内的进水预估信息作为状态输入,利用 Q-Network 决策生成该时段内的初始动作序列。
粒子群算法模块以强化学习生成的解矩阵为基础,通过变异算子构建初始种群。针对闸门开度的离散特性,采用基于集合粒子群算法(S-PSO),利用概率集编码在目标空间内进行深度搜索。
闭环反馈与滚动机制,系统根据出水水质和约束合规性计算总奖励:
R t o t a l = R q u a l i t y + R c o n s t r a i n t s R_{total} = R_{quality} + R_{constraints} Rtotal=Rquality+Rconstraints
深度 Q 网络方法
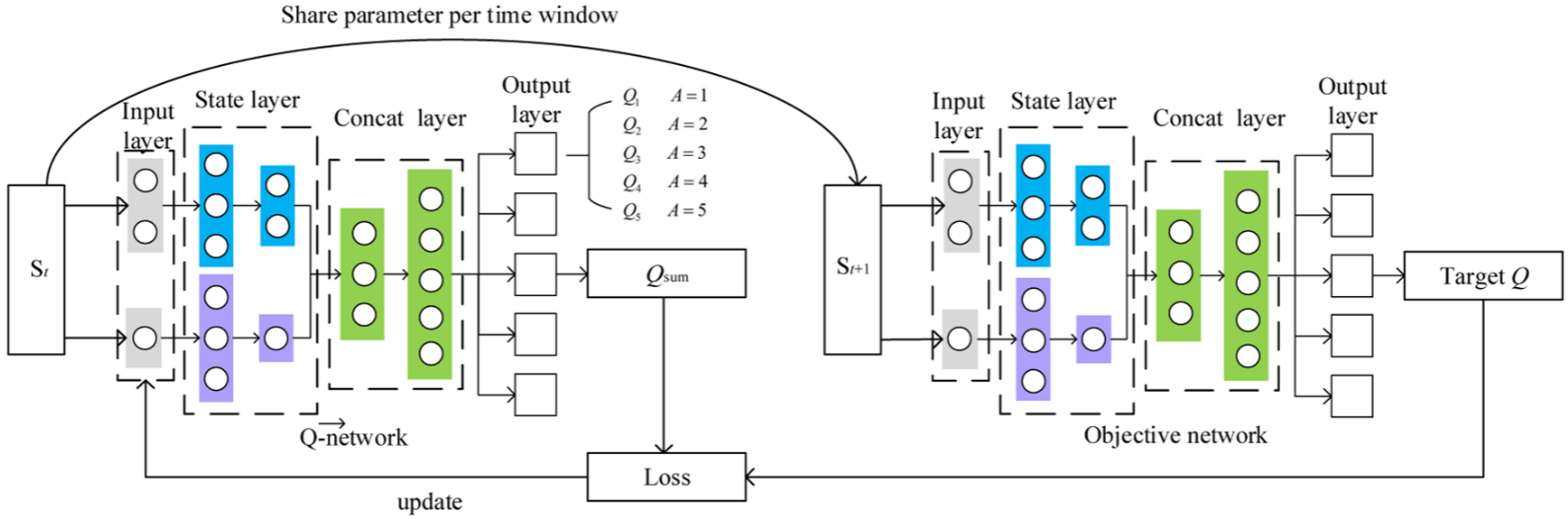
Q网络状态与动作空间定义
- 状态 ( S S S): 分为环境状态 S c S_c Sc (进水流量 F l Fl Fl、反应器5溶解氧 S O 5 SO_5 SO5、反应器2硝态氮 S N O 2 SNO_2 SNO2) 和内部状态 S r e S_{re} Sre (五个反应器的实时储水状态)。
- 动作 ( A A A): 五个闸门的开度向量 K = k 1 , k 2 , k 3 , k 4 , k 5 K = k_1, k_2, k_3, k_4, k_5 K=k1,k2,k3,k4,k5,每个维度取值范围为 { 1 , 2 , 3 , 4 , 5 } \{1, 2, 3, 4, 5\} {1,2,3,4,5}。
奖励函数设计
- 水质奖励:通过计算 DQN 动作与优化算法所得最优动作接近程度定义:
r e = ∑ i = 1 5 ∑ j = 1 ζ 1 ( k i , j ∗ − k i , j ) 2 + 1 r_e=\sum_{i=1}^5\sum_{j=1}^\zeta\frac1{\sqrt{(k_{i,j}^*-k_{i,j})^2}+1} re=i=1∑5j=1∑ζ(ki,j∗−ki,j)2 +11
- 约束惩罚:基于约束违反程度 C ( x ) C(x) C(x)计算:
p c = 0.5 ∑ h = 1 H C h ( x ) I max , h − I min , h p_c=0.5\sum_{h=1}^H\frac{C_h(x)}{I_{\max,h}-I_{\min,h}} pc=0.5h=1∑HImax,h−Imin,hCh(x)
- 总奖励: r t = r e − p c r_t=r_e-p_c rt=re−pc
网络结构与学习流程
为提高训练精度,模型采用了多状态并行特征提取架构。
- 架构:两个独立的隐藏层分别处理环境状态与内部状态,随后通过 Concat 层进行特征融合,最后输出各动作对应的 Q 值。
- 更新机制:采用 ε-greedy 策略选择动作,利用目标网络计算目标值 y t y_t yt 以稳定训练:
y t = r t + γ ∑ i = 1 5 max A i Q ( ( S c , t + 1 , S k , t + 1 ) , A i , θ o ) y_t = r_t + \gamma \sum_{i=1}^{5} \max_{A_i} Q((S_{c,t+1}, S_{k,t+1}), A_i, \theta_o) yt=rt+γi=1∑5AimaxQ((Sc,t+1,Sk,t+1),Ai,θo) - 损失函数:基于均方误差通过梯度下降更新网络参数 θ \theta θ:
L = ( y t − ∑ i = 1 5 max A i Q ( S c , t , S k , t , A i , θ ) ) 2 L = \left( y_t - \sum_{i=1}^{5} \max_{A_i} Q(S_{c,t}, S_{k,t}, A_i, \theta) \right)^2 L=(yt−i=1∑5AimaxQ(Sc,t,Sk,t,Ai,θ))2
基于集合的粒子群算法
为提高搜索效率,S-PSO 的初始种群以DQN方案为基础,通过变异率 R R R对解矩阵进行交换,延迟,列交换等操作。
为了在离散空间内实现类连续的优化,算法引入了概率集 编码机制。每个闸门开度等级 i ∈ { 1 , ... , 5 } i\in\{1,\ldots,5\} i∈{1,...,5}对应一个权重 q i q_i qi,所有权重经归一化处理:
q i ∗ = q i ∑ j = 1 5 q j q_i^*=\frac{q_i}{\sum_{j=1}^5q_j} qi∗=∑j=15qjqi
粒子根据个体最优 p b e s t p_{best} pbest 和全局最优 g b e s t g_{best} gbest 调整速度向量 v v v:
v i , j , p o p ( t + 1 ) = ω v i , j , p o p ( t ) + c 1 r 1 ( p i , j , p o p ( t ) − x i , j ( t ) ) + c 2 r 2 ( g i , j ( t ) − x i , j , p o p ( t ) ) v_{i,j,pop}(t + 1) = \omega v_{i,j,pop}(t) + c_1 r_1 (p_{i,j,pop}(t) - x_{i,j}(t)) + c_2 r_2 (g_{i,j}(t) - x_{i,j,pop}(t)) vi,j,pop(t+1)=ωvi,j,pop(t)+c1r1(pi,j,pop(t)−xi,j(t))+c2r2(gi,j(t)−xi,j,pop(t))
更新后的位置 x x x 需经过 N o r ( ⋅ ) Nor(\cdot) Nor(⋅) 函数处理,以确保权重符合概率分布要求:
x i , j ( t + 1 ) = N o r ( x i , j ( t ) + v i , j ( t ) ) x_{i,j}(t + 1) = Nor(x_{i,j}(t) + v_{i,j}(t)) xi,j(t+1)=Nor(xi,j(t)+vi,j(t))
N o r ( x i , j ( t ) ) = x i , j ( t ) − min x ( t ) i , j , k ∑ z = 1 5 ( x i , j , z ( t ) − min x ( t ) i , j , k ) Nor(x_{i,j}(t)) = \frac{x_{i,j}(t) - \min x(t){i,j,k}}{\sum{z=1}^5 (x_{i,j,z}(t) - \min x(t)_{i,j,k})} Nor(xi,j(t))=∑z=15(xi,j,z(t)−minx(t)i,j,k)xi,j(t)−minx(t)i,j,k
4.结果展示
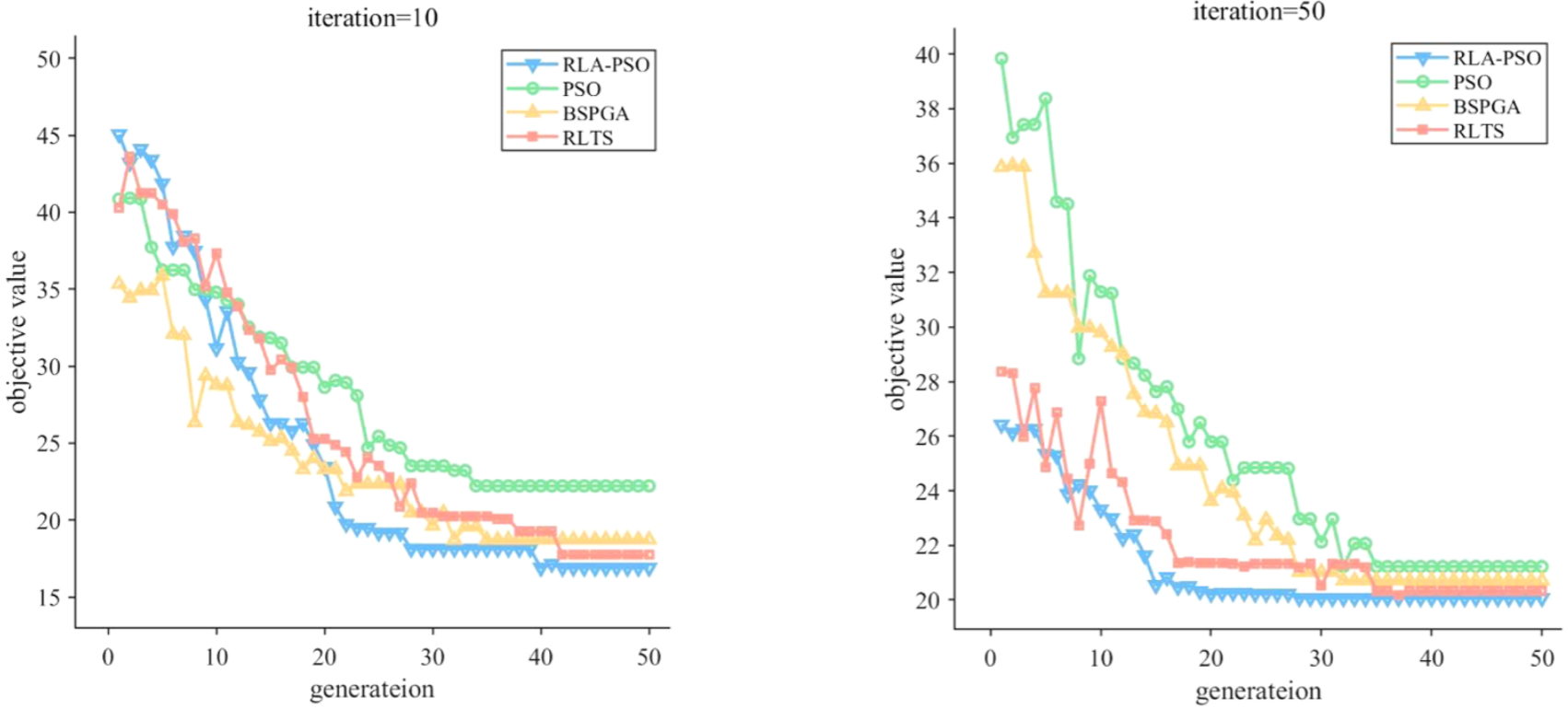
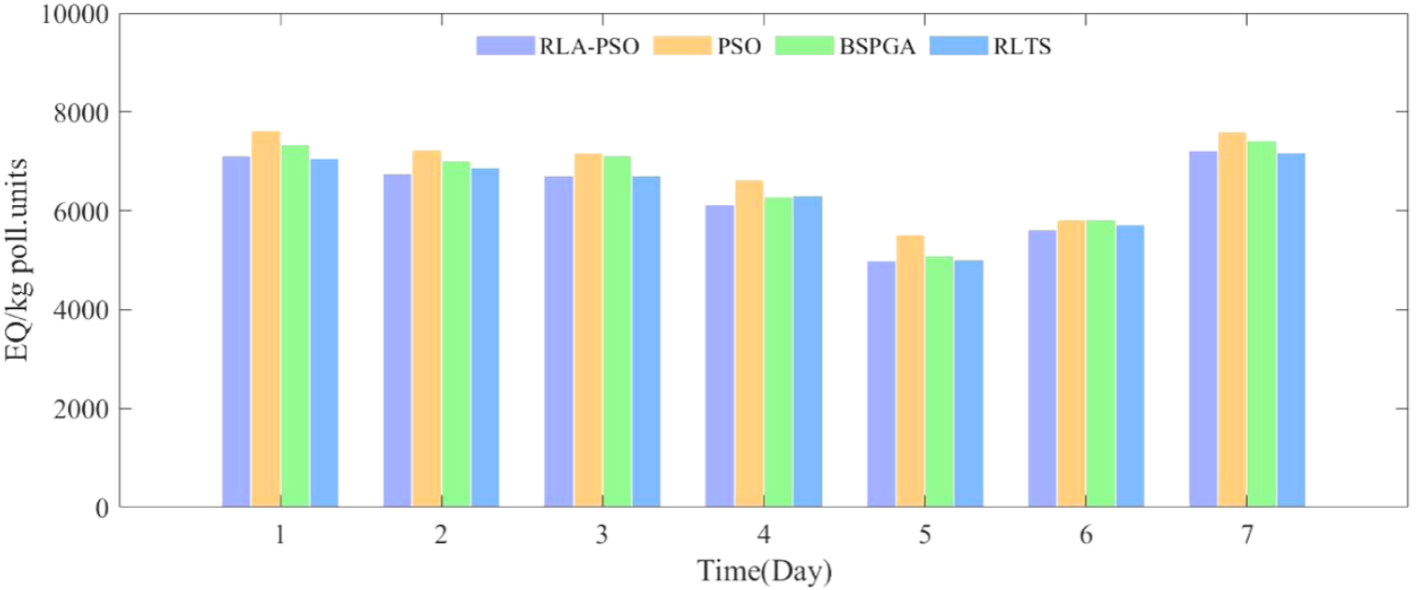
5.参考文献
1 HongGui H A N, ZiAng X U, JingJing W. Reinforcement learning-assisted particle swarm algorithm for effluent scheduling problem with an influent estimation of WWTPJ. Swarm and Evolutionary Computation, 2025, 94: 101871.
6.代码获取
xx
7.算法辅导·应用定制·读者交流
xx