数据库基础
SQL查询中各个关键字的执行先后顺序 from > on> join > where > group by > with > having > select > distinct > order by > limit
提示:
复杂的SQL语句有其固定的"骨架",即关键字的执行顺序 。可以记忆一个逻辑链,例如 "FWGHSOO" ,它对应着 FROM-> WHERE-> GROUP BY-> HAVING-> SELECT-> ORDER BY-> OFFSET & FETCH。理解了这一点,就能像搭积木一样构建和分解复杂查询。
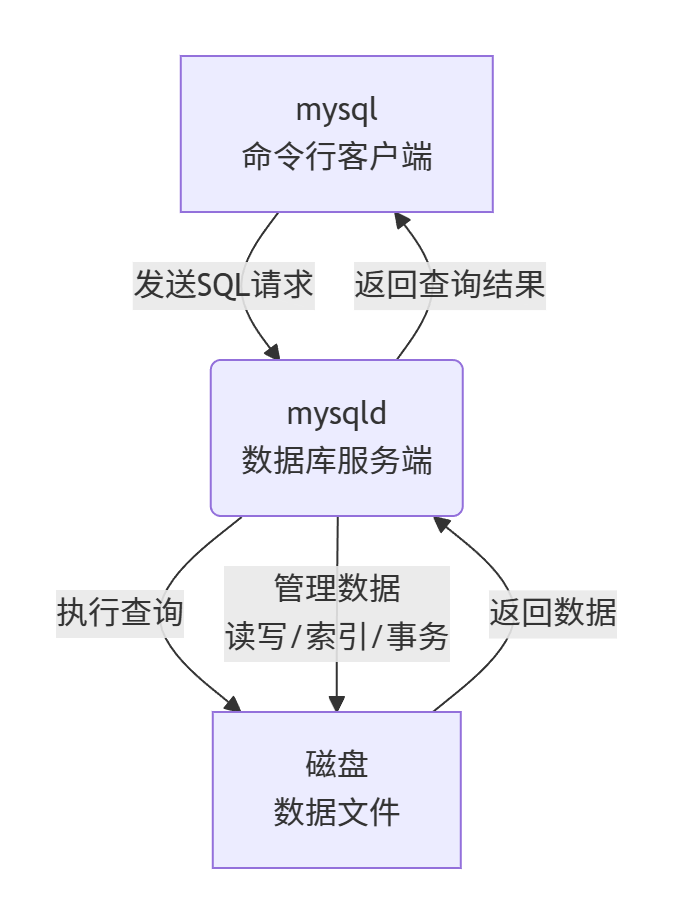
注意区分mysql和mysqld之间的关系;掌握mysql和mysqld以及磁盘这三者的联系
mysqld:数据库的服务端
mysqld是 MySQL 服务的核心守护进程,它直接管理磁盘上的数据文件 。
-
核心功能:它负责解析 SQL 语句、执行数据查询(SELECT)、更新(INSERT/UPDATE/DELETE)、管理事务、维护索引等所有数据操作 。
-
与磁盘的交互 :所有数据库、表最终都以文件形式保存在磁盘上(例如位于
/var/lib/mysql/目录下)。mysqld进程是读写这些文件的唯一正式通道,它通过存储引擎 (如 InnoDB)以特定格式(如.ibd文件)和**页(Page)** 为单位(通常是 16KB)来高效地进行磁盘 I/O 操作,以减少读写次数 。
简单来说,mysqld是连接 mysql客户端和磁盘数据文件的桥梁。
mysql:数据库的客户端
mysql是一个用于连接 mysqld服务的命令行工具 。
核心功能:提供一个界面,让你能够输入 SQL 命令,并将命令发送给 mysqld,然后接收并显示 mysqld返回的结果 。
它与磁盘的关系:是间接的。它不直接操作磁盘上的数据文件,所有请求都必须通过 mysqld服务端处理。
磁盘提供了非易失性存储,确保 MySQL 服务重启或服务器断电后,数据依然存在 。
-
存储内容 :在数据目录(如
/var/lib/mysql/)下,每个数据库对应一个子目录,表对应目录内的文件 。常见的文件包括:-
表结构文件 (
.frm):描述表的结构。 -
数据和索引文件 :取决于存储引擎。例如,InnoDB 引擎使用
.ibd文件,而 MyISAM 引擎使用.MYD(数据)和.MYI(索引)文件 。
-
MySQL架构
先不细说了,后面再说
SQL分类
DDL【data definition language】数据定义语言,用来维护存储数据的结构 代表指令: create, drop, alter
DML【data manipulation language】数据操纵语言,用来对数据进行操作 代表指令: insert,delete,update DML中又单独分了一个DQL,数据查询语言,代表指令: select
DCL【Data Control Language】数据控制语言,主要负责权限管理和事务 代表指令: grant,revoke,commit
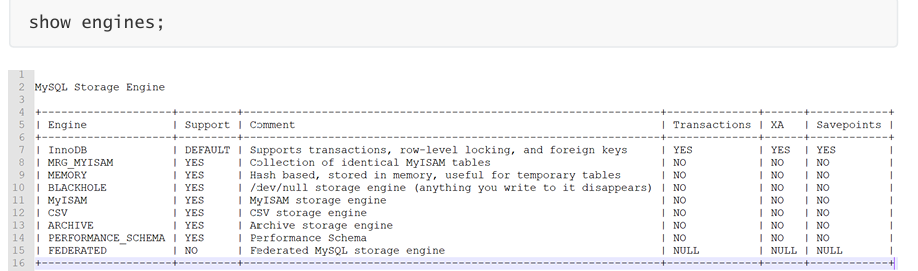
存储引擎
存储引擎是:数据库管理系统如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术 的实现方法。 MySQL的核心就是插件式存储引擎,支持多种存储引擎。
MySQL 的存储引擎是数据库的"心脏",它决定了数据如何存储、索引以及支持哪些功能。简单来说,存储引擎就是表级别的数据处理与存储机制 。
MySQL 中最常见的几种存储引擎的核心特性。
| 存储引擎 | 事务支持 | 锁机制 | 外键支持 | 主要优势 | 典型应用场景 |
|---|---|---|---|---|---|
| InnoDB | ✅ 支持 (ACID) | 行级锁 | ✅ 支持 | 高并发、数据完整性、崩溃恢复 | 金融交易、电商平台、用户中心 |
| MyISAM | ❌ 不支持 | 表级锁 | ❌ 不支持 | 极高的读取速度、全文索引 | 内容管理系统(CMS)、数据仓库、日志分析(读多写少) |
| Memory | ❌ 不支持 | 表级锁 | ❌ 不支持 | 数据存于内存,读写速度极快 | 会话缓存、临时表、高速查询中间结果 |
| Archive | ❌ 不支持 | 行级锁 | ❌ 不支持 | 极高的压缩比,节省存储空间 | 日志归档、历史数据存储(只插不查) |
为什么需要多种引擎
MySQL 采用独特的插件式存储引擎架构 。这意味着你可以根据每张表的具体用途,为它选择最合适的"引擎",就像给汽车换上适合不同地形的轮胎一样。这种灵活性是 MySQL 广受欢迎的重要原因之一 。例如,你可以将核心交易表设为 InnoDB 以保证安全,而将用于全文搜索的日志表设为 MyISAM 以追求速度。
查看存储引擎
库的操作
只写容易忽略忘记的部分,过于基础的不再赘述
关于字符集和校验规则

查看系统默认字符集以及校验规则
show variables like 'character_set_database';
show variables like 'collation_database';
查看数据库支持的字符集 show charset;
查看数据库支持的字符集校验规则 show collation;
校验规则对数据库的影响
校验规则使用utf8_ general_ ci不区分大小写
校验规则使用utf8_ bin区分大小写
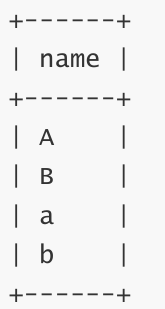
区分大小写排序以及结果:
mysql> use test2;
mysql> select * from person order by name;
操纵数据库
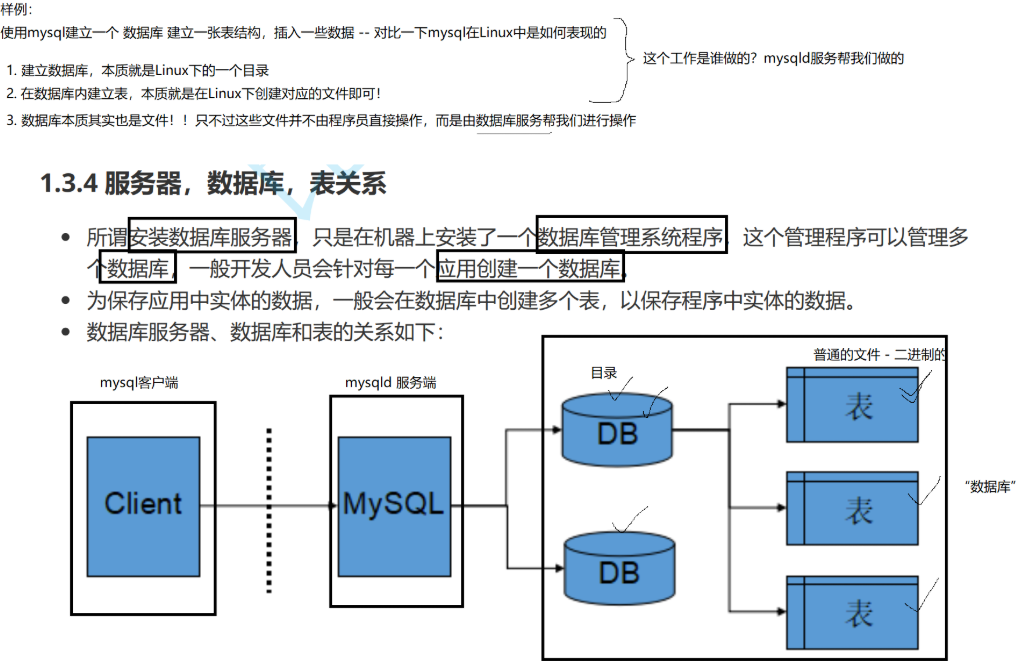
操纵数据库是数据库管理和维护中的一项基本操作。
显示创建语句
show create database 数据库名;
该命令的主要用途是:
获取数据库的创建"元信息" 。它不是用来增删改查数据的,而是用来查看数据库这个"容器"本身的定义和属性 的,主要用于维护、迁移、复制和问题诊断。

-
mytest:反引号 `是MySQL中用于包裹数据库名、表名、字段名的标识符,防止它们与SQL关键字冲突。这里表示数据库名叫mytest。 -
/*!40100 DEFAULT CHARACTER SET utf8 */:这是一个MySQL特有的注释语法,但它会被执行。-
40100表示MySQL服务器版本 >= 4.1.0 时,才执行此语句。 -
DEFAULT CHARACTER SET utf8是这条语句的精髓 ,它指定了这个数据库的默认字符集为utf8。这意味着,如果你在这个数据库里创建新表时没有指定字符集,表就会默认使用utf8字符集,这对于存储中文等多语言文本至关重要。
-
了解数据库的"出生证明":就像查看一个产品的制造规格一样,这个命令能让你看到某个数据库最初被创建时的完整、准确的SQL语句。
关键用途场景:
迁移与备份:当你想在另一台服务器上重建一个一模一样的数据库时,这个创建语句就是最准确的蓝图。你可以直接复制这条语句去执行,确保新数据库的字符集等设置和原库完全一致。
排查问题:例如,当你的数据出现乱码时,首先要检查的就是数据库的字符集设置。这个命令能立刻告诉你当前数据库的字符集(比如图中的 utf8),这是判断编码问题根源的第一步。
学习和审计:作为开发者或管理员,你可能需要了解现有数据库的结构和设置,这个命令提供了最基础的信息。
修改数据库
对数据库的修改主要指的是修改数据库的字符集,校验规则
备份和恢复
-
-P:(可省略) 这是--port的简写,后面接的是 MySQL 服务器的端口号 。如果 MySQL 服务没有使用默认的 3306 端口,就需要通过这个参数来指定。例如-P3307。 -
-B: 这是--databases的简写,后面接一个或多个数据库名 。使用这个参数的关键区别在于,它会在导出的 SQL 文件中包含CREATE DATABASE和USE语句。这意味着在恢复时,如果数据库不存在,它会自动创建 。这在备份多个数据库时尤其方便
备份
备份语法: # mysqldump -P3306 -u root -p 密码 -B 数据库名 > 数据库备份存储的文件路径
备份多个数据库:# mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径
如果备份一个数据库时,没有带上-B参数, 在恢复数据库时,需要先创建空数据库,然后使用数据 库,再使用source来还原。
备份其中一张表:# mysqldump -u root -p 数据库名 表名1 表名2 > D:/mytest.sql
示例:将mytest库备份到文件(退出连接)
mysqldump -P3306 -u root -p123456 -B mytest > D:/mytest.sql
还原
mysql> source D:/mysql-5.7.22/mytest.sql;
查看连接情况
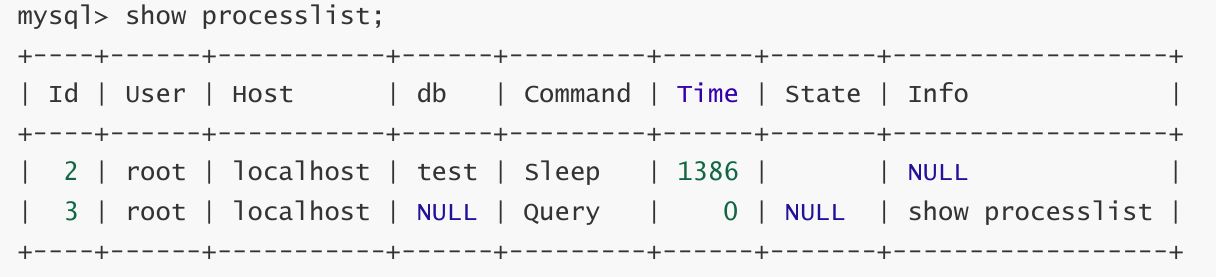
可以告诉我们当前有哪些用户连接到我们的MySQL,如果查出某个用户不是你正常登陆的,很有可能你 的数据库被人入侵了。以后大家发现自己数据库比较慢时,可以用这个指令来查看数据库连接情况。
表的操作
表的创建

character set 字符集,如果没有指定字符集,则以所在数据库的字符集为准 collate 校验规则,如果没有指定校验规则,则以所在数据库的校验规则为准
create table users (
id int,
name varchar(20) comment '用户名',
password char(32) comment '密码是32位的md5值',
birthday date comment '生日'
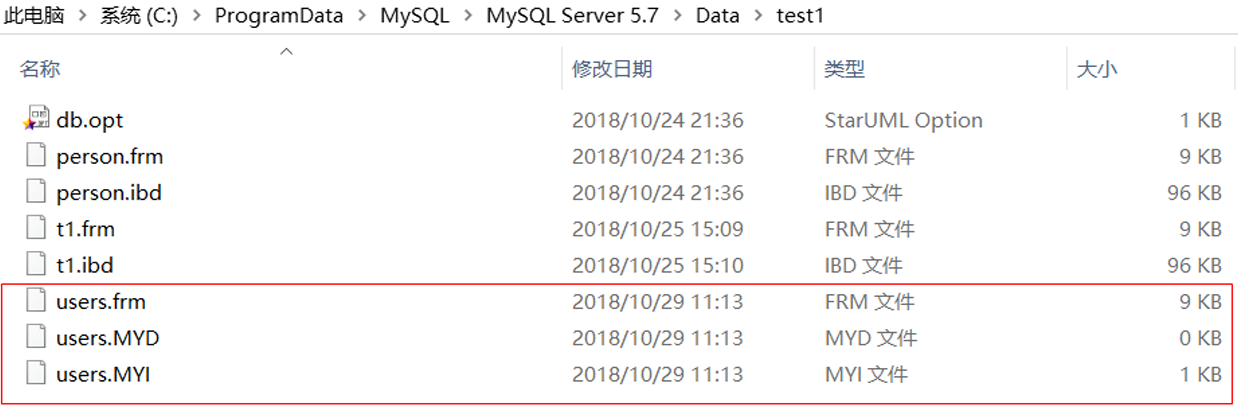
) character set utf8 engine MyISAM;说明: 不同的存储引擎,创建表的文件不一样。
users 表存储引擎是 MyISAM ,在数据目中有三个不同的文件,分别是:
users.frm:表结构
users.MYD:表数据
users.MYI:表索引
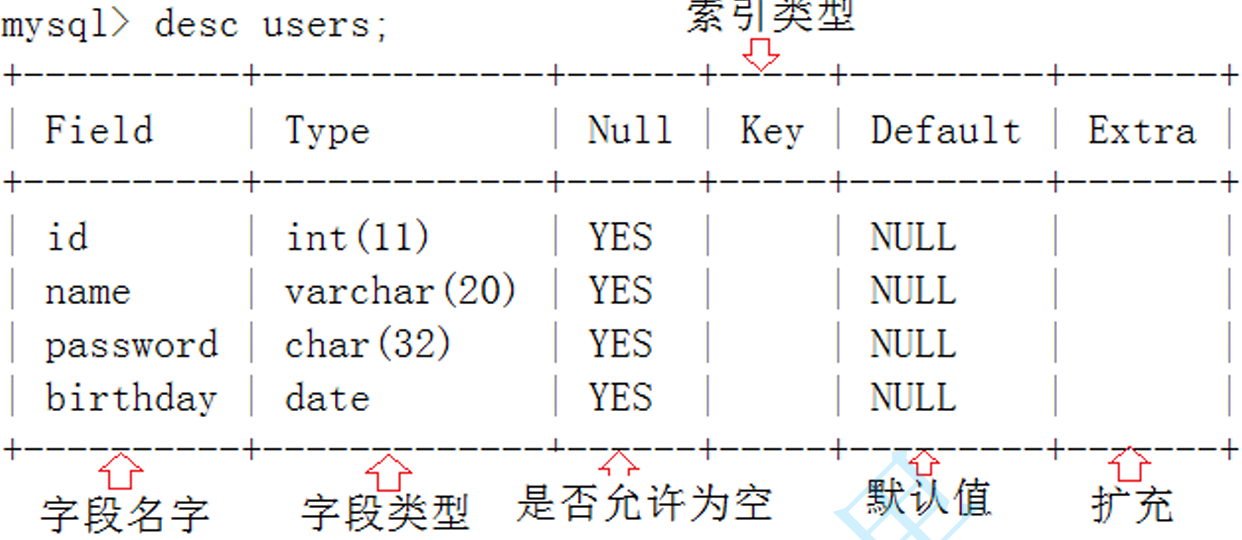
查看表结构
desc 表名;
修改表
其中删除表:drop table 表名;
在项目实际开发中,经常修改某个表的结构,比如字段名字,字段大小,字段类型,表的字符集类型, 表的存储引擎等等。我们还有需求,添加字段,删除字段等等。这时我们就需要修改表。
关于表的各种修改(表格)
| 操作类别 | 具体操作 | 基本SQL语法示例 | 关键说明 |
|---|---|---|---|
| 🔧 字段操作 | 添加字段 | ALTER TABLE 表名 ADD 字段名 数据类型 [约束]; |
可使用 FIRST/AFTER指定位置 |
| 删除字段 | ALTER TABLE 表名 DROP 字段名; |
数据将永久丢失,需提前备份 | |
| 修改字段名 | ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型; |
必须指定新数据类型,即使不修改 | |
| 修改字段类型/约束 | ALTER TABLE 表名 MODIFY 字段名 新数据类型 [约束]; |
更改类型时需注意数据兼容性 | |
| 🔄 表级属性 | 修改表名 | ALTER TABLE 旧表名 RENAME TO 新表名;或 RENAME TABLE 旧表名 TO 新表名; |
|
| 修改字符集 | ALTER TABLE 表名 CONVERT TO CHARACTER SET 字符集名; |
可转换整张表及所有字符型字段的字符集 | |
| 修改存储引擎 | ALTER TABLE 表名 ENGINE = 存储引擎名; |
如将引擎从 MyISAM 改为 InnoDB | |
| 📑 索引与约束 | 添加主键/索引 | ALTER TABLE 表名 ADD PRIMARY KEY (字段名);``ALTER TABLE 表名 ADD INDEX 索引名 (字段名); |
|
| 删除主键/索引 | ALTER TABLE 表名 DROP PRIMARY KEY;``ALTER TABLE 表名 DROP INDEX 索引名; |
数据类型
数据类型分类
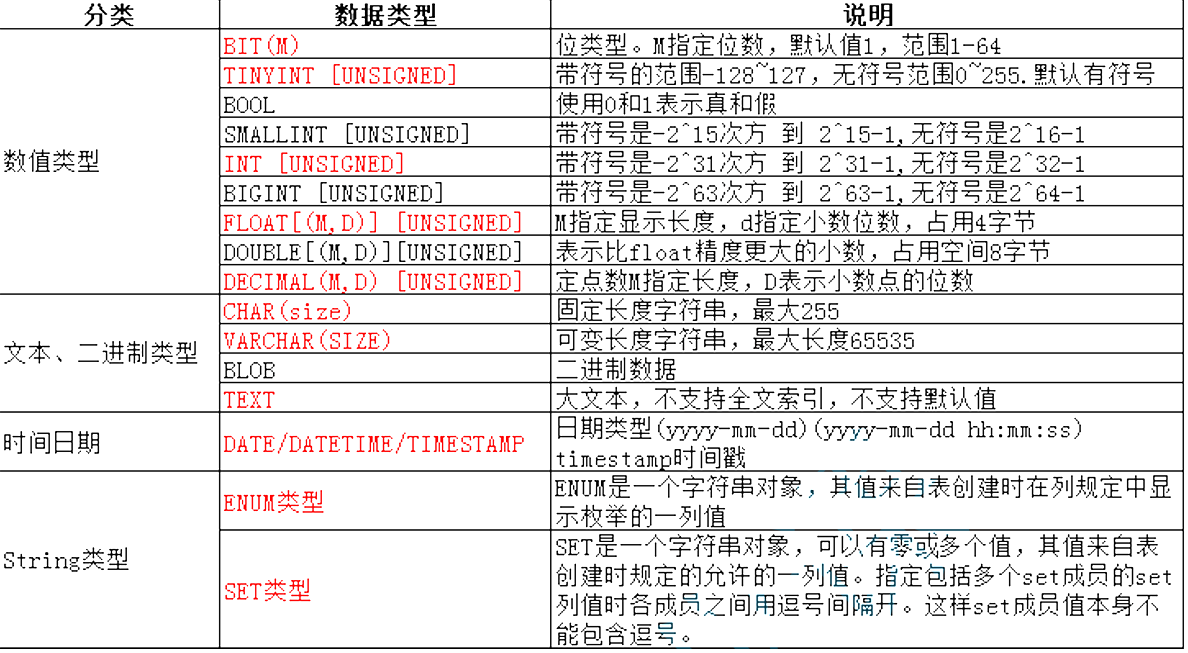
数值类型
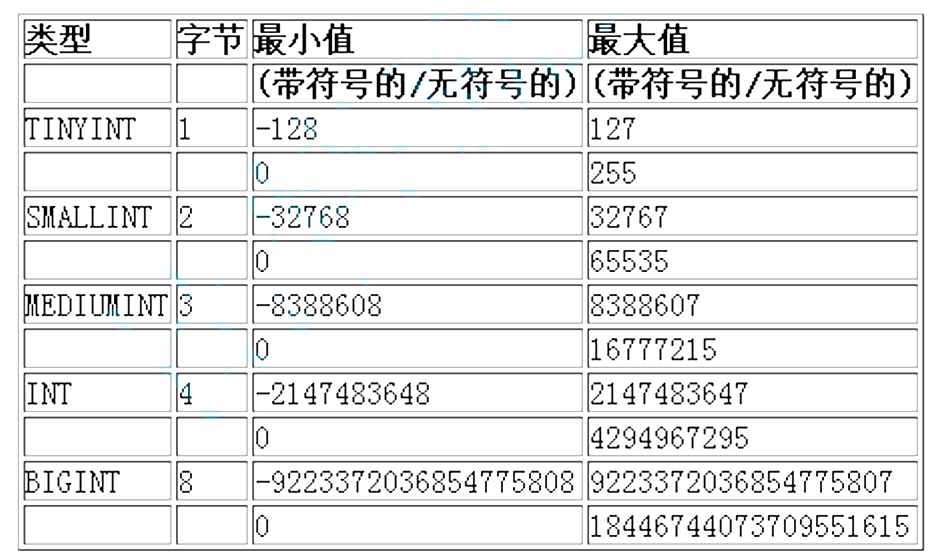
bit类型
bit(M) : 位字段类型。M表示每个值的位数,范围从1到64。如果M被忽略,默认为1。
注意:bit字段在显示时,是按照ASCII码对应的值显示。
如果我们有这样的值,只存放0或1,这时可以定义bit(1)。这样可以节省空间
小数类型:
float(m, d) unsigned : m指定显示长度,d指定小数位数,占用空间4个字节
decimal(m, d) unsigned : 定点数m指定长度,d表示小数点的位数
说明:float表示的精度大约是7位。 decimal整数最大位数m为65。支持小数最大位数d是30。如果d被省略,默认为0.如果m被省略, 默认是10。
字符串类型
char(L): 固定长度字符串,L是可以存储的长度,单位为字符,最大长度值可以为255
varchar(L): 可变长度字符串,L表示字符长度,最大长度65535个字节
关于varchar(len),len到底是多大,这个len值,和表的编码密切相关:
varchar长度可以指定为0到65535之间的值,但是有1 - 3 个字节用于记录数据大小,所以说有效字 节数是65532。 当我们的表的编码是utf8时,varchar(n)的参数n最大值是65532/3=21844因为utf中,一个字符占 用3个字节,如果编码是gbk,varchar(n)的参数n最大是65532/2=32766(因为gbk中,一个字符 占用2字节)。

数据确定长度,使用定长(char)
数据长度有变化,就使用变长(varchar),但要保证最长的能存的进去。
定长的磁盘空间比较浪费,但是效率高。 变长的磁盘空间比较节省,但是效率低。
定长的意义是,直接开辟好对应的空间 变长的意义是,在不超过自定义范围的情况下,用多少,开辟多少。
日期和时间类型
date :日期 'yyyy-mm-dd' ,占用三字节
datetime 时间日期格式 'yyyy-mm-dd HH:ii:ss' 表示范围从1000 到 9999 ,占用八字节
timestamp :时间戳,从1970年开始的 yyyy-mm-dd HH:ii:ss 格式和 datetime 完全一致,四字节
enum 和set
ENUM 是一种枚举类型,用于实现"单选"功能。
-
核心特性 :在一个ENUM字段中,你只能从预定义的选项中选择一个 值。例如,表示性别的字段 (
ENUM('男', '女')) 或订单状态 (ENUM('待支付', '已发货', '已完成')) 。 -
存储原理 :出于效率考虑,MySQL并非直接存储字符串,而是在内部将每个选项映射为一个整数索引(从1开始)。
'选项1'对应1,'选项2'对应2,以此类推 。正因为如此,ENUM类型非常节省存储空间。对于1-255个选项,仅需1个字节;256-65535个选项,需要2个字节 。 -
默认值 :如果字段被定义为
NOT NULL,其默认值将是选项列表中的第一个值。如果允许NULL,则默认值为NULL。 -
排序规则 :ENUM类型的值是按照其定义的顺序(即整数索引)进行排序的,而非字母顺序 。
SET 是一种集合类型,用于实现"多选"功能。
-
核心特性 :在一个SET字段中,可以从预定义的选项中选择零个、一个或多个值 。多个值之间用逗号分隔,例如兴趣爱好字段 (
SET('读书', '音乐', '运动')) 或用户权限 。 -
存储原理:SET类型在内部使用位图(bitmap)方式存储。每个选项代表一个二进制位(1, 2, 4, 8...),选中的选项其对应位被置为1 。这种机制也决定了其存储空间是固定的,根据选项的数量(1-8个成员占1字节,9-16占2字节,最多64个成员占8字节) 。
-
输入与显示:插入数据时,可以按任意顺序书写选项,MySQL在存储时会自动按照定义时的顺序进行规范化和去重 。
| 特性 | ENUM (枚举) | SET (集合) |
|---|---|---|
| 选择方式 | 单选 | 多选 |
| 设计目的 | 从多个值中选取一个 | 从多个值中选取多个 |
| 内部存储 | 整数索引(1, 2, 3...) | 位图(1, 2, 4, 8...) |
| 最大成员数 | 65,535 | 64 |
| 典型用例 | 性别、状态、分类 | 标签、权限、兴趣爱好 |
表的约束
真正约束字段的是数据类型,但是数据类型约束很单一,需要有一些额外的约束,更好的保证数据的合 法性,从业务逻辑角度保证数据的正确性。比如有一个字段是email,要求是唯一的。
表的约束很多,这里主要介绍如下几个: null/not null,default, comment, zerofill,primary key,auto_increment,unique key。
注意:not null和defalut一般不需要同时出现,因为default本身有默认值,不会为空
列描述
列描述:comment,没有实际含义,专门用来描述字段,会根据表创建语句保存,用来给程序员或DBA 来进行了解。通过show可以看到
zerofill
MySQL 中的 ZEROFILL属性主要用于格式化数值字段的显示效果。
| 特性维度 | 说明与要点 |
|---|---|
| 本质 | 一种显示格式化属性,不影响实际存储的数值本身。 |
| 显示规则 | 显示数值时,若实际位数小于指定显示宽度,左侧用零填充至该宽度。 |
| 自动 UNSIGNED | 一旦为字段设置 ZEROFILL,该字段会自动变为无符号类型,不能存储负数。 |
| 显示宽度作用 | 仅影响在特定客户端下的显示格式,不决定存储范围或输入值的长度限制。 |
| 适用数据类型 | 整数类型(如 INT, SMALLINT)和浮点数类型(如 DECIMAL)。 |
在创建表或修改表结构时,可以在数值类型的字段定义后加上 ZEROFILL关键字。显示宽度在括号内指定。
cpp
-- 创建表时指定
create table example_table (
id int(5) zerofill,
account_number int(8) zerofill
);
-- 修改现有表字段
alter table example_table modify account_number int(10) zerofill;插入数据时,如果数值的位数小于指定的显示宽度,查询结果中就会看到补零的效果。例如,向 int(5) zerofill字段插入数字 42,查询结果会显示为 00042。
如果插入的数值实际位数大于指定的显示宽度,MySQL 会直接显示完整的数值,不会进行截断或补零 。
注意:
-
自动设置为无符号 :为字段设置
zerofill属性后,该字段会自动变为unsigned,这意味着你不能在该字段中存储负数 。 -
仅影响显示 :
zerofill只影响查询结果在特定数据库客户端下的显示格式,并不会改变数据在磁盘上的存储方式。当你进行数值计算时,补零效果通常会消失。例如,对zerofill字段进行+1操作,结果将是一个普通的整数,没有补零 。 -
客户端依赖性:补零效果在某些数据库客户端工具中可能不会显示,这与工具的数据呈现方式有关 。
-
显示宽度非存储限制 :指定的显示宽度(如
int(5)中的 5)仅仅是提示性的,用于格式化显示,并不限制你能存储的数值的实际范围。一个int(5)字段仍然可以存储-2147483648到2147483647(有符号时)或0到4294967295(无符号时)范围内的值。
主键
主键:primary key用来唯一的约束该字段里面的数据 ,不能重复,不能为空,一张表中最多只能有一个 主键;主键所在的列通常是整数类型。主键约束:主键对应的字段中不能重复,一旦重复,操作失败。
创建表的时候直接在字段上指定主键

当表创建好以后但是没有主键的时候,可以再次追加主键:alter table 表名 add primary key(字段列表)
删除主键 alter table 表名 drop primary key;
区别:
| 特性 | 单列主键 | 复合主键 |
|---|---|---|
| 定义 | 用一个列做主键 | 用多个列的组合做主键 |
| 数量 | 只有一个主键 | 也只有一个主键(但由多列组成) |
| 示例 | id INT PRIMARY KEY |
PRIMARY KEY(col1, col2) |
| 索引 | 自动创建唯一索引 | 自动创建复合唯一索引 |
| 查询 | 按主键列查最快 | 按最左前缀查最快 |
复合主键
在创建表的时候,在所有字段之后,使用primary key(主键字段列表)来创建主键,如果有多个字段 作为主键,可以使用复合主键。
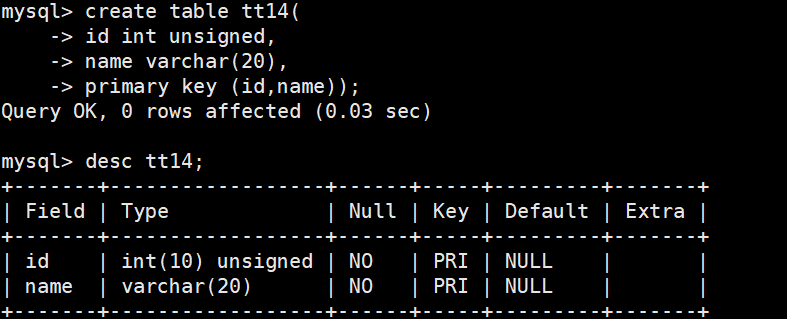
自增长
在MySQL中,自增长(AUTO_INCREMENT)是一个非常有用的特性,它能自动为字段(通常是主键)生成唯一的递增值,简化了数据插入操作。
auto_increment:当对应的字段,不给值,会自动的被系统触发,系统会从当前字段中已经有的最大值 +1操作,得到一个新的不同的值。通常和主键搭配使用,作为逻辑主键。
自增长的特点:
任何一个字段要做自增长,前提是本身是一个索引(key一栏有值);m 自增长字段必须是整数
一张表最多只能有一个自增长
唯一键
在 mysql 中,唯一键(unique key)是一种重要的约束,用于确保表中某个字段或字段组合的值是唯一的。虽然它和主键都能保证唯一性,但两者在使用上有所不同。
一张表中有往往有很多字段需要唯一性,数据不能重复,但是一张表中只能有一个主键:唯一键就可以 解决表中有多个字段需要唯一性约束的问题。
我们可以简单理解成,主键更多的是标识唯一性 的。而唯一键更多的是保证在业务上,不要和别的信息 出现重复。
| 特性 | 主键 (primary key) | 唯一键 (unique key) |
|---|---|---|
| 数量限制 | 每张表只能有 1个 | 每张表可以有 多个 |
| 是否允许为空 | 不允许 (not null) | 允许,且多个空值(null)不视为重复 |
| 核心作用 | 唯一标识每一行记录 | 确保业务数据的唯一性(如用户名、邮箱) |
创建方法:
1. 建表时在字段后直接指定
2. 建表时在所有字段后统一指定
这种方法更清晰,尤其适合设置复合唯一键(多个字段组合唯一)或为约束命名。
cpp
create table classroom (
id int primary key,
class_id int not null,
seat_number int not null,
student_name varchar(50),
unique key uk_class_seat (class_id, seat_number) -- 复合唯一键:同一班级内座位号唯一
);注意 :复合唯一键要求的是几个字段的组合值不能重复,但单个字段的值是可以重复的
3. 表已存在时使用 alter table添加
cpp
-- 为已存在的 products 表的 product_code 字段添加唯一键
alter table products add unique key (product_code);
-- 也可以为约束命名,便于后续管理
alter table employees add constraint uk_employee_id unique (employee_id);-
查看唯一键 :使用
show index from命令可以查看表中的索引信息,包括唯一键。 -
删除唯一键 :通过
drop index命令删除唯一键。删除时需要指定创建时生成的索引名。 -
alter table users drop index username;
在实际数据库设计中,一个常见的做法是:
-
使用一个与业务无关的自增id字段作为主键,用于唯一标识记录。
-
将业务上要求唯一的字段(如工号、身份证号、邮箱等)设置为唯一键,以保证业务逻辑的正确性。
cpp
create table students (
id int auto_increment primary key, -- 逻辑主键
student_number char(10) not null unique key, -- 学号,业务上唯一
name varchar(20) not null,
id_card char(18) unique key, -- 身份证号,唯一但允许暂未登记(null)
unique key uk_number (student_number) -- 另一种写法,效果同上行
);外键
外键是数据库设计中用于建立表间关联、保证数据完整性的重要约束。
1. 什么是外键
外键是表中的一个字段(或字段组),其值必须匹配另一个表的主键或唯一键的值。它创建了表之间的"从属"关系 。外键约束主要定义在从表上,主表则必须是有主键约束或unique 约束。当定义外键后,要求外键列数据必须在主表的主键列存在或为null。
语法;foreign key (字段名) references 主表(列)
-
主表与被参照表:被外键引用的表称为主表或被参照表。
-
从表与参照表:包含外键的表称为从表或参照表 。
-
核心作用:确保只能向从表插入在主表中存在对应值的数据,防止出现"孤儿记录",从而维护数据的一致性和完整性 。
2. 外键的作用
外键约束主要通过以下方式保障数据关系 :
-
阻止非法操作:
-
禁止在从表中插入外键值在主表中不存在的数据。
-
禁止删除主表中已被从表记录引用的行(取决于约束规则)。
-
禁止修改主表中已被引用的主键值(取决于约束规则)。
-
-
启用级联操作:可以设置当主表数据变更时,自动更新或删除从表中的相关数据。
核心区别。
| 特征 | 主表 (父表) | 从表 (子表) |
|---|---|---|
| 角色 | 被引用的核心实体 | 引用主表,存储扩展或关联信息 |
| 键约束 | 必须包含**主键 (Primary Key)** 或唯一键 | 包含外键 (Foreign Key),引用主表主键 |
| 数据依赖性 | 独立存在,不依赖于从表 | 数据依赖于主表,要求外键值必须在主表中存在 |
| 操作限制 | 受保护(如被引用的记录可能无法直接删除) | 受约束(如插入数据时外键值必须有效) |
基本查询
CRUD:create创建 retrieve读取 update更新 delete删除
只记录忘记或者模糊的地方
create
多行数据 + 指定列插入
插入两条记录,value_list 数量必须和指定列数量及顺序一致

由于 主键 或者 唯一键 对应的值已经存在而导致插入失败,可以选择性的进行同步更新操作
语法:
cpp
INSERT ... ON DUPLICATE KEY UPDATE
column = value [, column = value] ...
cpp
INSERT INTO students (id, sn, name) VALUES (100, 10010, '唐大师')
ON DUPLICATE KEY UPDATE sn = 10010, name = '唐大师';
Query OK, 2 rows affected (0.47 sec)替换
-- 主键 或者 唯一键 没有冲突,则直接插入;
-- 主键 或者 唯一键 如果冲突,则删除后再插

retrieve

-- 通常情况下不建议使用 * 进行全列查询
-- 1. 查询的列越多,意味着需要传输的数据量越大;
-- 2. 可能会影响到索引的使用。
指定列查询 -- 指定列的顺序不需要按定义表的顺序来
查询字段为表达式
-- 表达式不包含字段
--表达式包含一个或者多个字段
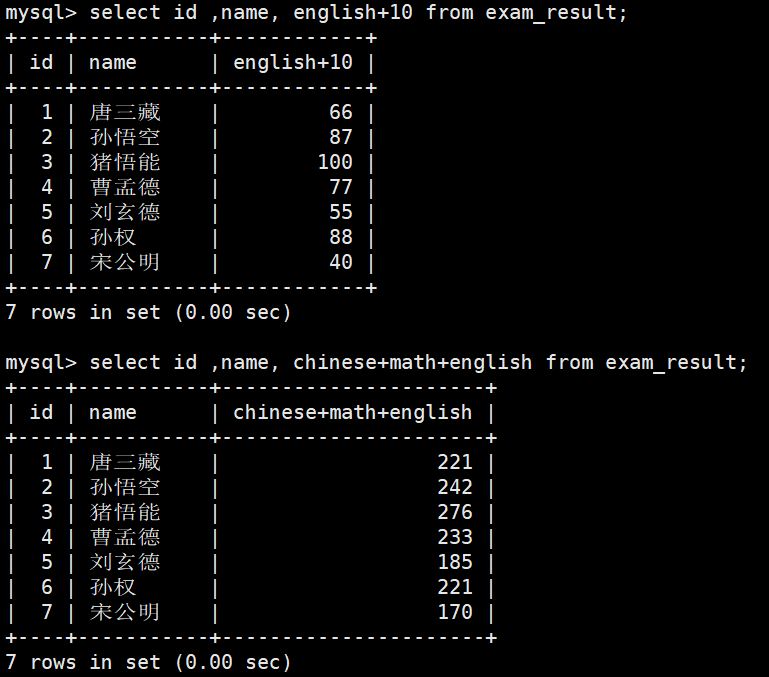
为查询结果指定别名
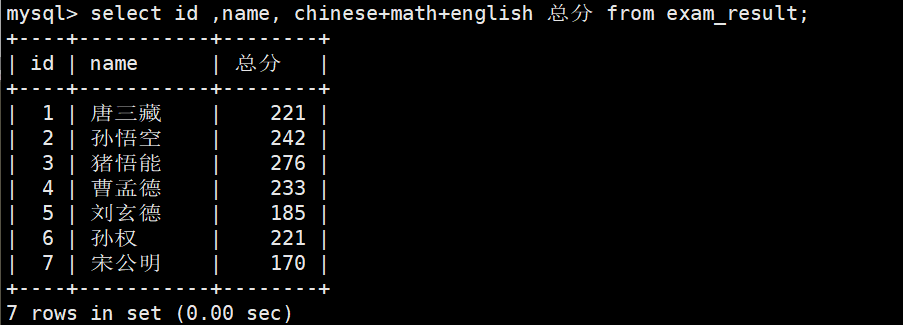
结果去重
-- 98 分重复了 select distinct math from exam_result;
where条件
比较运算符:

逻辑运算符:

-- 基本比较 SELECT name, english FROM exam_result WHERE english < 60;
-- 使用 AND 进行条件连接 SELECT name, chinese FROM exam_result WHERE chinese >= 80 AND chinese <= 90;
-- 使用 BETWEEN ... AND ... 条件 SELECT name, chinese FROM exam_result WHERE chinese BETWEEN 80 AND 90;
-- 使用 OR 进行条件连接 SELECT name, math FROM exam_result WHERE math = 58 OR math = 59 OR math = 98 OR math = 99;
-- 使用 IN 条件 SELECT name, math FROM exam_result WHERE math IN (58, 59, 98, 99);
% 匹配任意多个(包括 0 个)任意字符 SELECT name FROM exam_result WHERE name LIKE '孙%';

_ 匹配严格的一个任意字符 SELECT name FROM exam_result WHERE name LIKE '孙_';
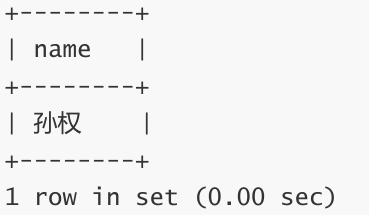
语文成绩好于英语成绩的同学
WHERE 条件中比较运算符两侧都是字段
SELECT name, chinese, english FROM exam_result WHERE chinese > english;
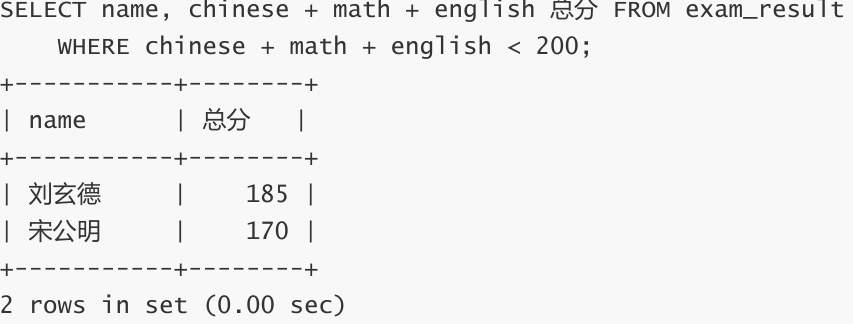
总分在 200 分以下的同学
WHERE 条件中使用表达式 ,别名不能用在 WHERE 条件中
-- AND 与 NOT 的使用
SELECT name, chinese FROM exam_result WHERE chinese > 80 AND name NOT LIKE '孙%';
孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
综合性查询 SELECT name, chinese, math, english, chinese + math + english 总分 FROM exam_result WHERE name LIKE '孙_' OR ( chinese + math + english > 200 AND chinese < math AND english > 80 );
结果排序

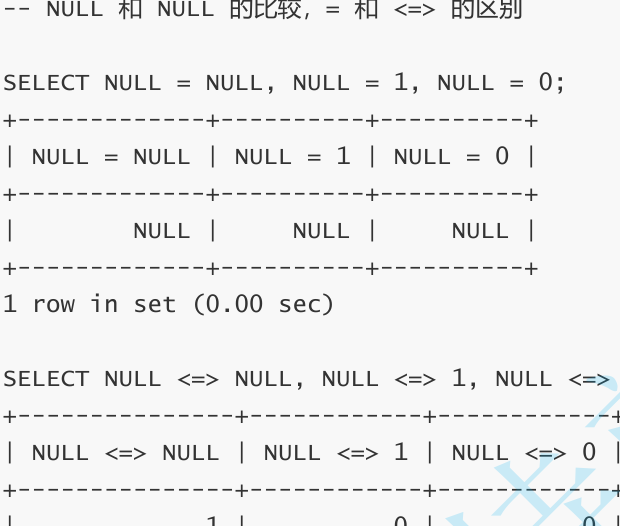
注意:当你的查询语句中没有明确使用 ORDER BY指定排序方式时,数据库返回给你的行的顺序是完全不可预测、不保证的。
-- NULL 视为比任何值都小,降序出现在最下面
SELECT name, qq FROM students ORDER BY qq DESC;
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
-- 多字段排序,排序优先级随书写顺序:
SELECT name, math, english, chinese FROM exam_result ORDER BY math DESC, english, chinese;
查询同学及总分,由高到低
-- ORDER BY 中可以使用表达式
SELECT name, chinese + english + math FROM exam_result ORDER BY chinese + english + math DESC;
-- ORDER BY 子句中可以使用列别名
SELECT name, chinese + english + math 总分 FROM exam_result ORDER BY 总分 DESC;
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
-- 结合 WHERE 子句 和 ORDER BY 子句
SELECT name, math FROM exam_result WHERE name LIKE '孙%' OR name LIKE '曹%' ORDER BY math DESC;
查询分页结果
语法:
-- 起始下标为 0
-- 从 0 开始,筛选 n 条结果 SELECT ... FROM table_name WHERE ... ORDER BY ... LIMIT n;
-- 从 s 开始,筛选 n 条结果 SELECT ... FROM table_name WHERE ... ORDER BY ... LIMIT s, n ;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确:SELECT ... FROM table_name WHERE ... ORDER BY ... LIMIT n OFFSET s;
建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死
举例:
按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页


update
语法:
UPDATE table_name SET column = expr , column = expr ... WHERE ... ORDER BY ... LIMIT ...
一次更新多个列:
UPDATE exam_result SET math = 60, chinese = 70 WHERE name = '曹孟德';
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
-- 更新值为原值基础上变更 -- 查看原数据 -- 别名可以在ORDER BY中使用
SELECT name, math, chinese + math + english 总分 FROM exam_result ORDER BY 总分 LIMIT 3;
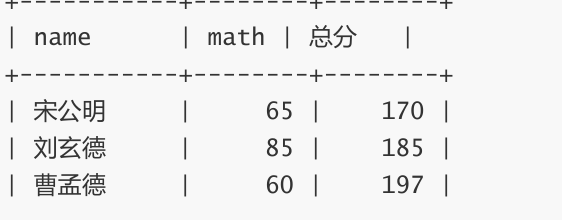
-- 数据更新,不支持 math += 30 这种语法 :
UPDATE exam_result SET math = math + 30 ORDER BY chinese + math + english LIMIT 3;
delete
语法: DELETE FROM table_name WHERE ... ORDER BY ... LIMIT ...
我们先创建一个名为for_delete的测试表格
-- 删除整表数据 :DELETE FROM for_delete;
-- 再插入一条数据,自增 id 在原值上增长 INSERT INTO for_delete (name) VALUES ('D');
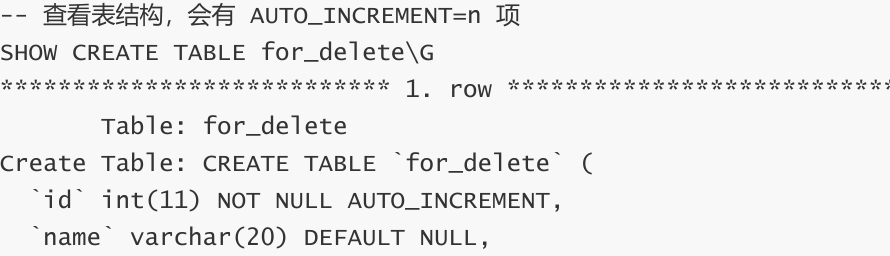

截断表
truncate table table_name
- 只能对整表操作,不能像 DELETE 一样针对部分数据操作; 2. 实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事 物,所以无法回滚 3. 会重置 AUTO_INCREMENT 项
插入查询结果
INSERT INTO table_name (column \[, column ...)] SELECT ...
聚合函数
COUNT(DISTINCT expr) 返回查询到的数据的 数量
SUM(DISTINCT expr 返回查询到的数据的 总和,不是数字没有意义
AVG(DISTINCT expr) 返回查询到的数据的 平均值,不是数字没有意义
MAX(DISTINCT expr) 返回查询到的数据的 最大值,不是数字没有意义
MIN(DISTINCT expr) 返回查询到的数据的 最小值,不是数字没有意义
-- 使用 * 做统计,不受 NULL 影响 SELECT COUNT(*) FROM students;
-- 使用表达式做统计 SELECT COUNT(1) FROM students;
-- NULL 不会计入结果 SELECT COUNT(qq) FROM students;
-- COUNT(math) 统计的是全部成绩 SELECT COUNT(math) FROM exam_result;
-- COUNT(DISTINCT math) 统计的是去重成绩数量 SELECT COUNT(DISTINCT math) FROM exam_result;
统计数学成绩总分
SELECT SUM(math) FROM exam_result;
-- 不及格 < 60 的总分,没有结果,返回 NULL SELECT SUM(math) FROM exam_result WHERE math < 60;
统计平均总分 SELECT AVG(chinese + math + english) 平均总分 FROM exam_result;
返回英语最高分 SELECT MAX(english) FROM exam_result;
group by子句的使用
在select中使用group by 子句可以对指定列进行分组查询 select column1, column2, .. from table group by column;
显示每个部门的每种岗位的平均工资和最低工资 select avg(sal),min(sal),job, deptno from EMP group by deptno, job;
显示平均工资低于2000的部门和它的平均工资
统计各个部门的平均工资 select avg(sal) from EMP group by deptno
having和group by配合使用,对group by结果进行过滤 select avg(sal) as myavg from EMP group by deptno having myavg<2000;
--having经常和group by搭配使用,作用是对分组进行筛选,作用有些像where。
面试题:SQL查询中各个关键字的执行先后顺序 from > on> join > where > group by > with > having > select > distinct > order by > limit
函数
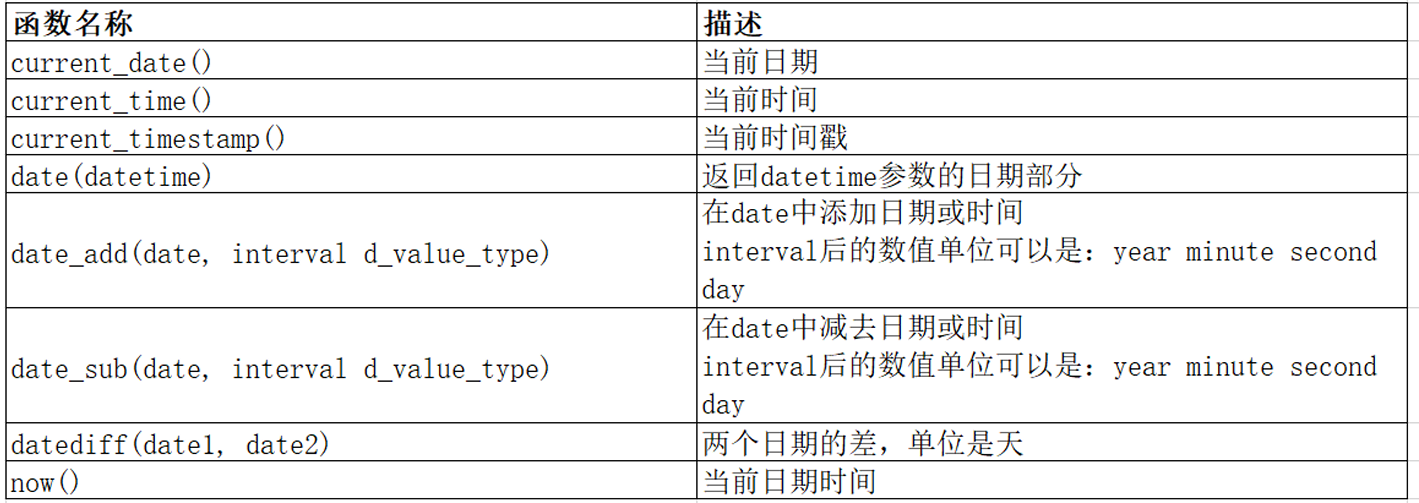
日期函数
字符串函数
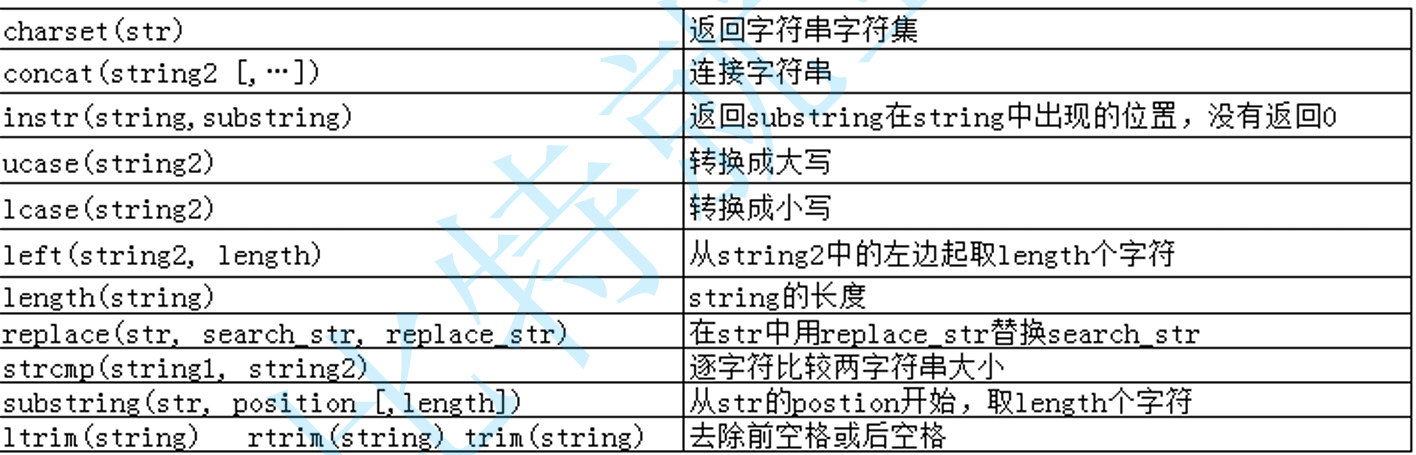
数学函数
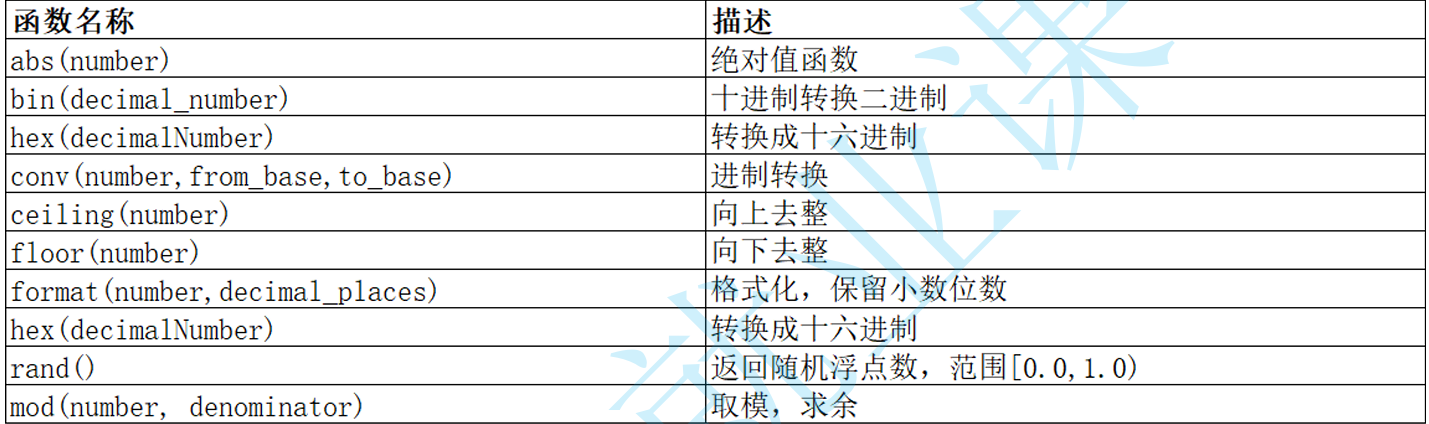
其他函数
user() 查询当前用户 select user();
md5(str)对一个字符串进行md5摘要,摘要后得到一个32位字符串: select md5('admin')

database()显示当前正在使用的数据库 select database();
password()函数,MySQL数据库使用该函数对用户加密 select password('root');
ifnull(val1, val2) 如果val1为null,返回val2,否则返回val1的值 select ifnull('abc', '123');
复合查询
查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的 J
select * from EMP where (sal>500 or job ='MANAGER') and ename like 'J%';
按照部门号升序而雇员的工资降序排序
select * from EMP order by deptno,sal desc;
表的内连和外连
内连接
内连接实际上就是利用where子句对两种表形成的笛卡儿积进行筛选,我们前面学习的查询都是内连 接,也是在开发过程中使用的最多的连接查询。
语法: select 字段 from 表1 inner join 表2 on 连接条件 and 其他条件;
显示SMITH的名字和部门名称
-- 用前面的写法
select ename, dname from EMP, DEPT where EMP.deptno=DEPT.deptno and ename='SMITH';
-- 用标准的内连接写法
select ename, dname from EMP inner join DEPT on EMP.deptno=DEPT.deptno and ename='SMITH';
外连接
外连接分为左外连接和右外连接
左外连接:如果联合查询,左侧的表完全显示我们就说是左外连接。
语法:select 字段名 from 表名1 left join 表名2 on 连接条件
右外连接:如果联合查询,右侧的表完全显示我们就说是右外连接。
语法: select 字段 from 表名1 right join 表名2 on 连接条件;
索引特性
索引:提高数据库的性能,索引是物美价廉的东西了。不用加内存,不用改程序,不用调sql,只要执行 正确的 create index,查询速度就可能提高成百上千倍。但是天下没有免费的午餐,查询速度的提高 是以插入、更新、删除的速度为代价的,这些写操作,增加了大量的IO。所以它的价值,在于提高一个 海量数据的检索速度。
常见索引分为: 主键索引(primary key) 唯一索引(unique) 普通索引(index)
全文索引(fulltext)--解决中子文索引问题。
认识磁盘
MySQL 给用户提供存储服务,而存储的都是数据,数据在磁盘这个外设当中。

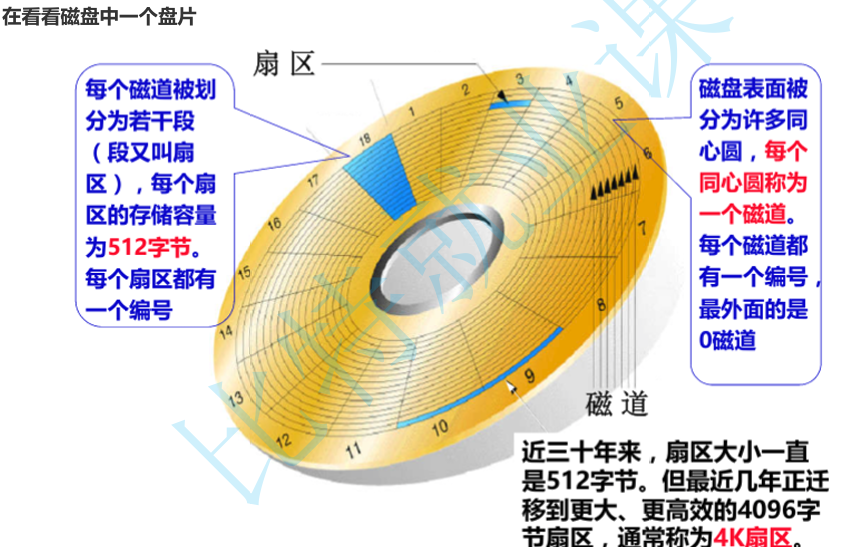
数据库文件,本质其实就是保存在磁盘的盘片当中。也就是上面的一个个小格子中,就是我们经常所说 的扇区。当然,数据库文件很大,也很多,一定需要占据多个扇区。
最基本的,找到一个文件的全部,本质,就是在磁盘找到所有保存文件的扇区。 而我们能够定位任何一个扇区,那么便能找到所有扇区,因为查找方式是一样的。
定位扇区
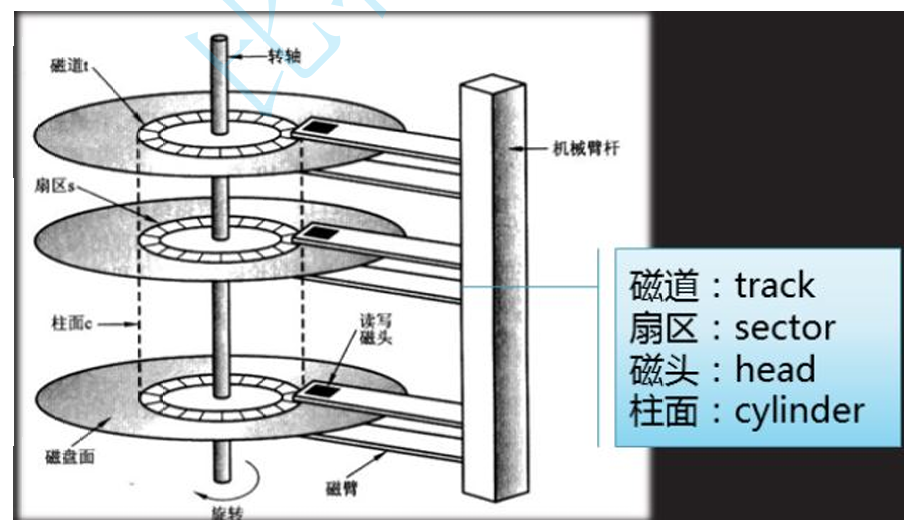
柱面(磁道): 多盘磁盘,每盘都是双面,大小完全相等。那么同半径的磁道,整体上便构成了一个柱 面
每个盘面都有一个磁头,那么磁头和盘面的对应关系便是1对1的
所以,我们只需要知道,磁头(Heads)、柱面(Cylinder)(等价于磁道)、扇区(Sector)对应的编 号。即可在磁盘上定位所要访问的扇区。这种磁盘数据定位方式叫做CHS 。不过实际系统软件使用的并不是CHS(但是硬件是),而是 LBA ,一种线性地址,可以想象成虚拟地址与物理地址。系统 将LBA地址最后会转化成为 CHS ,交给磁盘去进行数据读取。不过,我们现在不关心转化细节,知 道这个东西,让我们逻辑自洽起来即可。
总结:
-
数据最终存储在磁盘的扇区中。
-
操作系统与磁盘交互的基本单位是数据块(通常为4KB),而非单个扇区,以减少I/O次数、降低对硬件的依赖。
-
MySQL(InnoDB引擎) 与磁盘交互的基本单位是 Page(页) ,大小为 16KB。所有数据文件在磁盘中都以Page形式保存。
-
MySQL在内存中申请 Buffer Pool 来缓存磁盘的Page数据,以减少实际的磁盘I/O操作。
MySQL 与磁盘交互基本单位
而MySQL作为一款应用软件,可以想象成一种特殊的文件系统。它有着更高的IO场景,所以,为了提高 基本的IO效率, MySQL 进行IO的基本单位是 16KB

磁盘这个硬件设备的基本单位是 512 字节,而 即,M ySQL 和磁盘进行数据交互的基本单位是 MySQL InnoDB引擎使用 16KB 进行IO交互。 16KB 。这个基本数据单元,在 MySQL 这里叫做page(注 意和系统的page区分)
建立共识
MySQL 中的数据文件,是以page为单位保存在磁盘当中的。
MySQL 的 CURD 操作,都需要通过计算,找到对应的插入位置,或者找到对应要修改或者查询的数 据。
而只要涉及计算,就需要CPU参与,而为了便于CPU参与,一定要能够先将数据移动到内存当中。 所以在特定时间内,数据一定是磁盘中有,内存中也有。后续操作完内存数据之后,以特定的刷新 策略,刷新到磁盘。而这时,就涉及到磁盘和内存的数据交互,也就是IO了。而此时IO的基本单位 就是Page。
为了更好的进行上面的操作, MySQL 服务器在内存中运行的时候,在服务器内部,就申请了被称 Buffer Pool的的大内存空间,来进行各种缓存。其实就是很大的内存空间,来和磁盘数据进 行IO交互。 为何更高的效率,一定要尽可能的减少系统和磁盘IO的次数
索引的理解
- 单Page结构:内部使用目录优化查找
MySQL 中要管理很多数据表文件,而要管理好这些文件,就需要先描述,在组织,我们目前可以简单理解成一个个独立文件是有一个或者多个Page构成的。
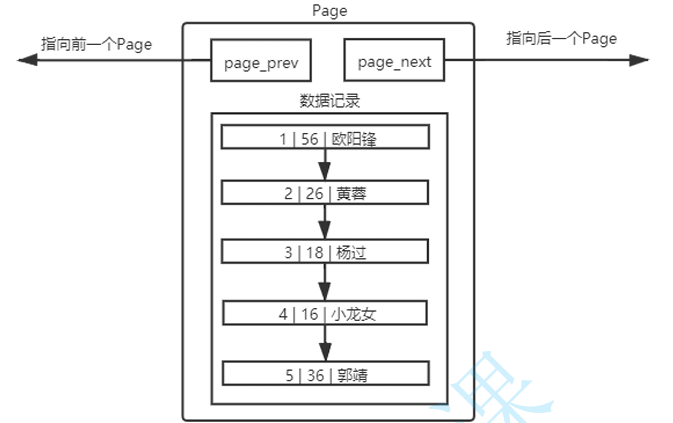
不同的Page,在 MySQL 中,都是 16KB ,使用 因为有主键的问题, prev 和 next 构成双向链表 MySQL 会默认按照主键给我们的数据进行排序,从上面的Page内数据记录可以看 出,数据是有序且彼此关联的。
- 多Page结构:通过B+树组织多个Page
- 为什么选择B+树而不是其他数据结构 :
- 链表:线性遍历效率低
- 二叉搜索树:可能退化为链表
- AVL/红黑树:树高过高,IO次数多
- Hash:不支持范围查询
- B树 vs B+树:B+树更矮,叶子节点相连便于范围查询
重点掌握原因:这是MySQL索引的核心实现原理,面试和实际优化都必须掌握。
聚簇索引 vs 非聚簇索引
核心对比:
| 特性 | InnoDB(聚簇索引) | MyISAM(非聚簇索引) |
|---|---|---|
| 数据存储 | 索引和数据在一起 | 索引和数据分离 |
| 主键索引 | 叶子节点包含完整数据 | 叶子节点只包含数据地址 |
| 辅助索引 | 需要回表查询 | 直接指向数据地址 |
不同存储引擎的索引实现差异直接影响查询性能和设计决策。
索引操作
创建索引的三种方式:
- 主键索引:
sql
-- 方式1:字段后直接指定
create table user1(id int primary key, name varchar(30));
-- 方式2:表定义最后指定
create table user2(id int, name varchar(30), primary key(id));
-- 方式3:创建表后添加
alter table user3 add primary key(id);2、唯一索引
sql
-- 方式1:字段后指定unique
create table user4(id int primary key, name varchar(30) unique);
-- 方式2:表定义最后指定
create table user5(id int primary key, name varchar(30), unique(name));
-- 方式3:创建表后添加
alter table user6 add unique(name);3、普通索引
sql
-- 方式1:表定义中指定
create table user8(id int primary key, name varchar(20), index(name));
-- 方式2:创建表后添加
alter table user9 add index(name);
-- 方式3:单独创建索引
create index idx_name on user10(name);4、全文索引
sql
-- 方式1:表定义中指定
create table user8(id int primary key, name varchar(20), index(name));
-- 方式2:创建表后添加
alter table user9 add index(name);
-- 方式3:单独创建索引
create index idx_name on user10(name);索引管理命令:
- 查看索引:
show keys from 表名或show index from 表名 - 删除索引:
alter table 表名 drop index 索引名或drop index 索引名 on 表名
事务管理
CURD不加控制,会有什么问题?
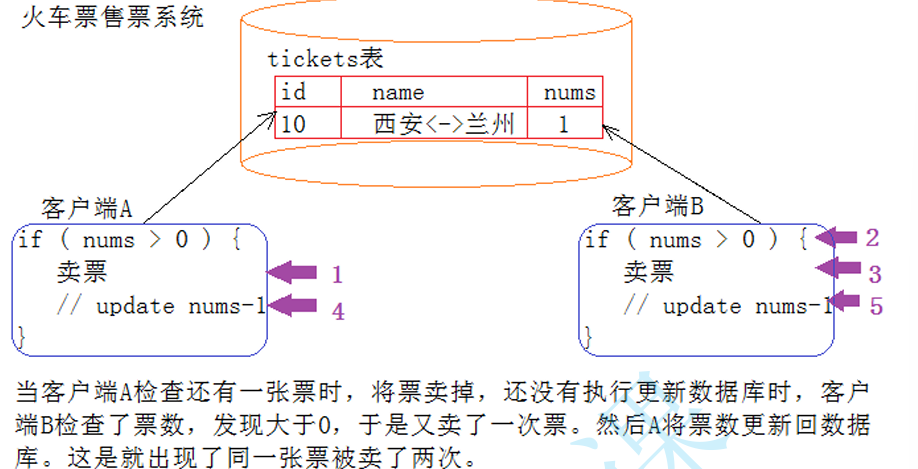
CURD满足什么属性,能解决上述问题? 1. 买票的过程得是原子 2. 买票互相应该不能影响 3. 买完票应该要永久有效 4. 买前,和买后都要是确定的状态
什么是事务?
**事务就是一组DML语句组成,这些语句在逻辑上存在相关性,这一组DML语句要么全部成功,要么全部 失败,是一个整体。**MySQL提供一种机制,保证我们达到这样的效果。事务还规定不同的客户端看到的 数据是不相同的。事务就是要做的或所做的事情,主要用于处理操作量大,复杂度高的数据。
- InnoDB 支持事务、行级锁、外键
- MyISAM 不支持事务
- Savepoint 也要引擎支持,InnoDB 支持,MyISAM 不支持。
ACID
- 原子性:要么全成功,要么全失败
- 一致性:开始前和结束后数据库状态要正确
- 隔离性:并发事务之间尽量互不干扰
- 持久性:提交后结果永久有效
一个完整的事务,绝对不是简单的 sql 集合,还需要满足如下四个属性:
原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中 间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个 事务从来没有执行过一样。
**一致性:**在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完 全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工 作。
**隔离性:**数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务 并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交( Read (Suncommitted )、读提交( read committed)、可重复读( erializable ) repeatable read)和串行化
**持久性:**事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失
上面四个属性,可以简称为 ACID 。 原子性(Atomicity,或称不可分割性) 一致性(Consistency) 隔离性(Isolation,又称独立性) 持久性(Durability)。
事务提交方式
事务的提交方式常见的有两种: 自动提交 手动提交
查看事务提交方式 mysql> show variables like 'autocommit';
用 SET 来改变 MySQL 的自动提交模式: mysql> SET AUTOCOMMIT=0; #禁止自动提交;=1 开启自动提交
事务常见操作方式
| 语句 | 描述 | 示例 |
|---|---|---|
begin;或 start transaction; |
显式地开始一个新事务。这会暂时禁用自动提交模式,直到事务被提交或回滚。 | begin; start transaction; |
commit; |
提交当前事务,使事务中的所有更改永久生效。 | commit; |
rollback; |
回滚当前事务,撤销该事务中进行的所有更改。 | rollback; |
savepoint savepoint_name; |
在当前事务内创建一个名为 savepoint_name的保存点。 |
savepoint sp1; |
rollback to savepoint savepoint_name; |
将事务回滚到之前定义的特定保存点,而不是回滚整个事务。 | rollback to savepoint sp1; |
release savepoint savepoint_name; |
从当前事务中移除指定的保存点。 | release savepoint sp1; |
set autocommit = 0; |
关闭当前会话的自动提交模式。之后的所有语句将在同一个事务中,直到显式执行 commit或 rollback。 |
set autocommit = 0; |
set autocommit = 1; |
开启当前会话的自动提交模式(mysql 默认状态)。每一条 sql 语句都会被视为一个独立的事务并立即提交。 |
结论: 只要输入begin或者start transaction,事务便必须要通过commit提交,才会持久化,与是 否设置set autocommit无关。
容易混淆的点:
autocommit=ON:每条 SQL 默认自己就是一个小事务,执行完自动提交- 但只要你
begin了,就进入"手动事务"模式,后续不再自动提交,直到commit/rollback
事务可以手动回滚,同时,当操作异常,MySQL会自动回滚
对于I nnoDB 每一条 SQL 语言都默认封装成事务,自动提交。(select有特殊情况,因为 MySQL 有 MVCC )
事务操作注意事项
如果没有设置保存点,也可以回滚,只能回滚到事务的开始。直接使用 rollback(前提是事务 还没有提交)
如果一个事务被提交了(commit),则不可以回退(rollback) 可以选择回退到哪个保存点
InnoDB 支持事务, MyISAM 不支持事务
开始事务可以使 start transaction 或者
事务隔离级别
隔离性本质是什么
隔离级别的本质,就是规定一个事务在执行过程中,能看到别的事务的哪一部分结果。
- 一个事务不是瞬间完成的,而是经历"执行前、执行中、执行后"
- 单个事务从用户视角看,要么看到执行前,要么看到执行后,这体现原子性
- 但多个事务并发执行时,它们的 SQL 可能交错,于是会互相影响
- 所以就需要"隔离性"与"隔离级别"来控制"谁该看到谁的数据"。
mysql 的事务隔离级别定义了多个并发事务在访问和修改相同数据时,彼此之间的可见性和影响规则。它核心解决的是数据库在高并发环境下可能出现的数据一致性问题。
一个事务从 begin -> CURD -> commit 中间是有执行过程的。原子性只保证"从事务自己视角看,最终结果要么全有,要么全无";但是多个事务同时执行时,它们的操作会交错,所以还会互相影响。隔离性的作用,就是让事务在执行过程中尽量不被别的事务干扰。
mysql 的默认事务隔离级别是 repeatable read(可重复读)。这是由 innodb 存储引擎实现的。
隔离级别与并发问题
| 隔离级别 | 脏读 (dirty read) | 不可重复读 (non-repeatable read) | 幻读 (phantom read) | 加锁读 |
|---|---|---|---|---|
| **读未提交 (read uncommitted)** | 可能 (√) | 可能 (√) | 可能 (√) | 不加锁 |
| **读已提交 (read committed)** | 不可能 | 可能 (√)原因是:每次读都可能基于最新提交结果 | 可能 (√) | 不加锁 |
| **可重复读 (repeatable read)** | 不可能 | 不可能 | 可能 (√) / 不可能 (x)* | 不加锁 |
| **串行化 (serializable)** | 不可能 | 不可能 | 不可能 | 加锁 |
各级别特性总结
| 隔离级别 | 核心描述与特点 | 性能与并发 | 备注 |
|---|---|---|---|
| 读未提交 | 事务可以读取其他未提交事务的数据。几乎无隔离性,会引发所有并发问题。 | 最高(几乎不加锁) | 严重不建议使用。 |
| 读已提交 | 一个事务只能看到其他已提交事务所做的改变。 | 较高 | 许多数据库(如oracle)的默认级别。会引起不可重复读和幻读。 |
| **可重复读 (mysql默认)** | 确保同一事务中,多次读取同一条数据会看到同样的结果。 | 良好 | mysql的默认隔离级别。通过mvcc机制实现。在innodb中解决了幻读。 |
| 串行化 | 最高隔离级别,把事务尽量排队串行执行。强制事务排序,使之不可能相互冲突。所有读操作都会加共享锁。 | 最低(大量锁等待) | 事务最高隔离级别,实际生产基本不使用。性能低、锁竞争强、容易阻塞。 |
并发问题定义
- 脏读:在 RU 下,一个事务可以读到另一个事务"还在执行中、还没 commit"的修改。如事务b读到了事务a未提交的更新。
终端 A:
sql
begin;
update account set blance=123.0 where id=1;
-- 不 commit终端 B:
sql
begin;
select * from account;-
不可重复读 :在同一个事务内,对同一条记录 的两次读取结果不同(因为其他事务修改并提交了该记录)。如"读已提交"实验所示。
-
终端 A:
sqlbegin; update account set blance=321.0 where id=1; -- 后面 commit终端 B:
sqlbegin; select * from account; -- A commit 前,看到旧值 123 select * from account; -- A commit 后,再看变成 321在 B 同一个事务里 ,两次 select 读到了不同结果。这就叫 不可重复读 non-repeatable read。
-
幻读 :在同一个事务内,两次执行相同条件 的查询,返回的结果集行数 不同(因为其他事务插入或删除了记录并提交)。insert操作可能引发此现象,mysql通过Next-Key Lock(间隙锁 + 行锁)解决了该问题。
-
串行化 Serializable:
两个终端都
begin: -
终端 A 先
select -
终端 B 也
select -
A 或 B 再去
update -
更新操作会被阻塞,直到另一边事务提交。材料里有一个更新耗时 18.19 秒,就是等待对方释放。
Serializable 基本靠加锁把并发尽量"串成队列",安全性最高,但并发性能很差。
结论:Serializable 不是"更聪明地并发",而是"尽量不要并发"。
- 所有操作都加锁
- 不会有并发异常
- 但效率很低,几乎不会采用。
查看与设置语法
- 改 session 只影响当前连接
- 改 global 会影响后续新连接
sql
select @@global.tx_isolation;
select @@session.tx_isolation;
set [session | global] transaction isolation level ...
sql
-- 查看当前会话隔离级别
select @@tx_isolation;
-- 设置当前会话隔离级别
set session transaction isolation level read committed;
-- 设置全局隔离级别
set global transaction isolation level repeatable read;mysql事务隔离级别查看与设置操作
| 操作类型 | 语句 | 描述与示例 |
|---|---|---|
| 查看隔离级别 | select @@global.tx_isolation; |
查看全局 事务隔离级别。 示例:mysql> select @@global.tx_isolation; |
select @@session.tx_isolation; |
查看当前会话 的事务隔离级别。 示例:mysql> select @@session.tx_isolation; |
|
select @@tx_isolation; |
查看当前隔离级别(默认同@@session.tx_isolation)。 示例:mysql> select @@tx_isolation; |
|
| 设置隔离级别 | set [session] transaction isolation level {level}; |
设置当前会话 的隔离级别,仅影响后续事务。 可选级别 :read uncommitted, read committed, repeatable read, serializable。 示例1:set session transaction isolation level read committed; 示例2:set transaction isolation level serializable; |
set global transaction isolation level {level}; |
设置全局 事务隔离级别,影响所有新连接的会话。 示例:set global transaction isolation level repeatable read; 注意:文档中指出,设置全局级别后,可能需要关闭并重新连接mysql客户端才能在新会话中生效。 |
总结:
-
RU:可能有脏读、不可重复读、幻读
-
RC:解决脏读,但仍可能不可重复读、幻读
-
RR:解决脏读、不可重复读;课件结合 InnoDB 说明实际还能处理幻读
-
Serializable:都解决,但靠重锁和阻塞换来的
-
两个区分点:
-
不可重复读重点是"修改/删除":同样条件,再读值变了
-
幻读重点是"新增":同样条件,再读记录数变了
如何理解隔离性2
后面还要更新,先不讲
视图特性
视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。视图的数据变化会影响到基表,基表的数据变化也会影响到视图。
它和真正的表不同:
- 真实表:数据真的存储在磁盘里
- 视图 :通常只是保存了一条
select查询逻辑
也就是说:你看到的视图,本质上像是一个"保存下来的查询结果入口"
基本使用:
sql
create view 视图名 as select语句;as 后面:定义这个视图的数据来源,也就是查询语句
sql
create view v_ename_dname as
select ename, dname
from EMP, DEPT
where EMP.deptno=DEPT.deptno;视图可以像普通表一样被 select 查询。
也就是说,对于使用者来说,你不需要每次都写:
sql
select ename, dname
from EMP, DEPT
where EMP.deptno=DEPT.deptno;你只需要写:
sql
select * from v_ename_dname;这就是视图的便利性。
删除视图
sql
drop view 视图名;删除视图删掉的是:
- 这个"虚拟表"的定义
- 这个封装好的查询入口
删除视图会不会删除基表数据
视图规则和限制
与表一样,必须唯一命名(不能出现同名视图或表名)
创建视图数目无限制,但要考虑复杂查询创建为视图之后的性能影响
视图不能添加索引,也不能有关联的触发器或者默认值。因为视图通常不是物理存储表。
视图可以提高安全性,必须具有足够的访问权限。为什么视图能提高安全性?因为你可以只把一部分列、一部分行开放给别人看。
order by 可以用在视图中,但是如果从该视图检索数据 select 中也含有 order by,那么该视图中的 order by 将被覆盖
解释:
情况 A:视图里写了 order by。此时这个视图定义里已经有排序了。
sql
create view v1 as
select ename, sal
from emp
order by sal desc;情况 B:外面再查视图时也写 order by
sql
select * from v1 order by ename asc;这时最终**按外层 select 的order by**排序
视图可以和表一起使用
视图不是孤立的,它可以像普通表一样参与 SQL。
比如:
- 视图和表做连接
- 视图和视图做连接
- 在复杂查询里把视图当成一个数据源
例如:
sql
select *
from v_ename_dname v, bonus b
where v.ename = b.ename;这说明在 SQL 语义上,视图可以像表一样参与运算。
用户管理
用户信息
MySQL 中的用户信息,存储在系统数据库 mysql 的 user 表中。
sql
use mysql;
select host,user,authentication_string from user;这里几个字段要理解透
host:表示这个用户允许从哪个主机登录。
例如:
'localhost':只能从本机登录'%':表示可以从任意主机登录
这个字段非常关键,因为 MySQL 里的用户不是单纯按用户名区分,而是按:**'用户名'@'主机'**一起区分。也就是说:
'whb'@'localhost''whb'@'%'就表示这个用户可以从任意主机 登录。这在生产环境通常要非常谨慎,
不要轻易添加一个可以从任意地方登录的 user。
这是两个不同的用户身份。
user用户名。
这个很好理解,就是登录 MySQL 时用的账号名。
authentication_string用户密码加密后保存的内容。
通过 password 函数加密后的值。
*_priv表示该用户拥有的权限。
Select_privInsert_privUpdate_priv
这些字段本质上描述的是:这个用户可以干什么。
用户操作
创建用户。MySQL 里的用户不是单纯按用户名区分,而是按:**'用户名'@'主机'**一起区分。
- 用户名:
whb - 允许登录的位置:
localhost
sql
create user '用户名'@'登陆主机/ip' identified by '密码';
create user 'whb'@'localhost' identified by '12345678';删除用户
sql
drop user '用户名'@'主机名';
drop user 'whb'@'localhost';要建立这个意识:
MySQL 用户不是只有用户名,真正唯一定位一个用户的是
'user'@'host'
所以以后你做这些操作时:
- 删除用户
- 改密码
- 授权
- 回收权限
- 查看 grants
都要带上 host。
修改用户密码
1)自己改自己的密码
sql
set password=password('新的密码');2)root 修改指定用户的密码
sql
set password for '用户名'@'主机名'=password('新的密码');
示例:
set password for 'whb'@'localhost'=password('87654321');执行后再查询 mysql.user,你会发现 authentication_string 变了。
数据库的权限
mysql 权限详解与操作速查表
| 类别 | 权限 | 对应系统字段 (列) | 上下文/适用层级 | 授权语句示例 (以用户 'user'@'host' 为例) | 说明与常见场景 |
|---|---|---|---|---|---|
| **数据定义 (ddl)** | create | create_priv | 数据库、表、索引 | grant create on db_name.* to 'user'@'host'; |
允许创建新数据库和表。 |
| alter | alter_priv | 表 | grant alter on db_name.table_name to 'user'@'host'; |
允许修改表结构(如添加/删除列)。 | |
| drop | drop_priv | 数据库、表 | grant drop on db_name.* to 'user'@'host'; |
允许删除数据库和表,慎用。 | |
| index | index_priv | 表 | grant index on db_name.* to 'user'@'host'; |
允许创建或删除索引。 | |
| create view | create_view_priv | 视图 | grant create view on db_name.* to 'user'@'host'; |
允许创建视图。通常需要相应的select权限。 |
|
| show view | show_view_priv | 视图 | grant show view on db_name.* to 'user'@'host'; |
允许查看视图的定义(如show create view)。 |
|
| **数据操作 (dml)** | select | select_priv | 表 | grant select on db_name.* to 'user'@'host'; |
最常用的权限,允许查询数据。 |
| insert | insert_priv | 表 | grant insert on db_name.table_name to 'user'@'host'; |
允许插入数据。 | |
| update | update_priv | 表 | grant update on db_name.table_name to 'user'@'host'; |
允许更新现有数据。可细化到列:grant update(col1) on ... |
|
| delete | delete_priv | 表 | grant delete on db_name.table_name to 'user'@'host'; |
允许删除数据行,慎用。 | |
| 存储过程/函数 | create routine | create_routine_priv | 保存的程序 | grant create routine on db_name.* to 'user'@'host'; |
允许创建存储过程和函数。 |
| alter routine | alter_routine_priv | 保存的程序 | grant alter routine on db_name.* to 'user'@'host'; |
允许修改或删除已有的存储过程和函数。 | |
| execute | execute_priv | 保存的程序 | grant execute on procedure db_name.proc_name to 'user'@'host'; |
允许执行存储过程或函数。 | |
| 管理类 | grant option | grant_priv | 数据库、表等 | grant all on db_name.* to 'user'@'host' with grant option; |
超级权限。允许用户将自己拥有的权限授予他人。 |
| super | super_priv | 服务器管理 | grant super on *.* to 'user'@'host'; |
允许执行管理操作,如修改全局系统变量、kill线程、配置复制等。仅限高级dba。 | |
| process | process_priv | 服务器管理 | grant process on *.* to 'user'@'host'; |
允许查看所有正在执行的线程(show processlist)。 |
|
| reload | reload_priv | 服务器管理 | grant reload on *.* to 'user'@'host'; |
允许执行flush命令重新加载权限表、日志等。 |
|
| shutdown | shutdown_priv | 服务器管理 | grant shutdown on *.* to 'user'@'host'; |
允许关闭mysql服务器,极高风险权限。 | |
| file | file_priv | 文件访问 | grant file on *.* to 'user'@'host'; |
允许通过mysql读取/写入服务器上的文件(如load data, select ... into outfile)。存在安全风险。 |
|
| 服务器与复制 | replication client | repl_client_priv | 服务器管理 | grant replication client on *.* to 'user'@'host'; |
允许用户查询主/从服务器的状态(show master status, show slave status)。 |
| replication slave | repl_slave_priv | 服务器管理 | grant replication slave on *.* to 'user'@'host'; |
允许从库线程从主库读取二进制日志(用于复制)。 | |
| 其他 | create temporary tables | create_tmp_table_priv | 服务器管理 | grant create temporary tables on db_name.* to 'user'@'host'; |
允许在操作中创建临时表。 |
| lock tables | lock_tables_priv | 服务器管理 | grant lock tables on db_name.* to 'user'@'host'; |
允许使用lock tables语句显式锁定表。 |
|
| create user | create_user_priv | 服务器管理 | grant create user on *.* to 'user'@'host'; |
允许执行create user, rename user, drop user等账户管理语句。 |
|
| show databases | show_db_priv | 服务器管理 | grant show databases on *.* to 'user'@'host'; |
允许用户执行show databases查看所有数据库列表。无此权限则只看到有权限的库。 |
|
| references | references_priv | 数据库、表 | 目前未使用,为未来预留。 | 理论上用于外键约束,但mysql中尚未实现其实际作用。 |
-
授权原则 :遵循最小权限原则,只授予完成工作所必需的最小权限。
-
权限层级:
-
*.*:全局权限(所有数据库的所有对象) -
database_name.*:数据库级权限(指定库的所有表) -
database_name.table_name:表级权限(指定库的指定表) -
database_name.routine_name:存储过程/函数权限
-
-
关键命令:
sql-- 1. 授予权限 grant 权限列表 on 层级 to '用户名'@'主机' [identified by '密码']; -- 2. 查看用户权限 show grants for '用户名'@'主机'; -- 3. 撤销权限 revoke 权限列表 on 层级 from '用户名'@'主机'; -- 4. 刷新权限(授权后执行) flush privileges; -
with grant option:授予此选项需极其谨慎,获得该权限的用户可以扩散其权限。
用户授权
注意:show grants:查看一个用户当前有哪些权限
sql
grant 权限列表 on 库.对象名 to '用户名'@'登陆位置' [identified by '密码']权限列表,多个权限用逗号分开
sql
grant select on ...
grant select, delete, create on ....
grant all [privileges] on ... -- 表示赋予该用户在该对象上的所有权限*.*: 代表本系统中的所有数据库的所有对象(表,视图,存储过程等)
sql
grant all on *.* to ...库.* : 表示某个数据库中的所有数据对象(表,视图,存储过程等)
**to '用户名'@'登录位置'**表示把权限赋给谁。再次强调:这里也必须写完整用户身份。
**identified by '密码'**如果用户存在,赋予权限的同时修改密码,如果该用户不存在,就是创建用户
回收权限
sql
revoke 权限列表 on 库.对象名 from '用户名'@'登陆位置';回收 whb 对 test 库的所有权限
sql
revoke all on test.* from 'whb'@'localhost';总结:
"从零到完整"的标准操作流程
假设你要给一个新同事开账号,最标准的步骤应该是:
sql
-- 1. 创建用户
create user 'whb'@'localhost' identified by '12345678';
-- 2. 授权
grant select on test.* to 'whb'@'localhost';
-- 3. 查看授权结果
show grants for 'whb'@'localhost';
-- 4. 如果要改密码
set password for 'whb'@'localhost' = password('87654321');
-- 5. 如果要回收权限
revoke select on test.* from 'whb'@'localhost';
-- 6. 如果用户不用了,删除
drop user 'whb'@'localhost';使用c语言链接
怎么用 C 语言去连接 MySQL,并执行 SQL,再把结果取回来。
也就是从"会写 SQL"进入到"在程序里操作数据库"的第一步。整章的核心主线其实非常清晰:
准备库 → 初始化连接对象 → 连接数据库 → 发送 SQL → 取结果 → 处理结果 → 关闭连接。
前面你学的 MySQL,更多是在命令行里直接敲 SQL。
而这一章开始,进入的是:让 C 程序自己去连 MySQL 服务器。也就是说,以后不是你手动在 mysql 客户端里写:
sql
select * from student;而是你的 C 程序里写代码,让程序自动完成:
- 连接 MySQL
- 发 SQL
- 拿返回结果
- 打印/处理这些数据
- 要使用 C 语言连接 MySQL,需要使用官网提供的 Connector/C 库,并且要先保证 MySQL 服务是可用的,还要下载适合自己平台的连接库
Connector/C
下载下来的目录结构,大致分成两部分:
include:头文件,里面是各种方法声明lib:库文件,里面是方法实现,已经被打包好了
你可以把它理解成:
include告诉编译器:有哪些函数可以用lib真正提供这些函数的实现
sql
#include <mysql.h>这只是"看见声明"。但你最后编译链接时,还必须把 libmysqlclient 链接进来,否则只有声明,没有实现,程序没法真正运行。
先验证库有没有引入成功
sql
#include <stdio.h>
#include <mysql.h>
int main()
{
printf("mysql client Version: %s\n", mysql_get_client_info());
return 0;
}这个程序没有连接数据库,它只是调用:mysql_get_client_info() 来看看 MySQL 客户端库是否已经被正确引入了
它返回当前链接到的 MySQL client library 的版本字符串。比如可能输出:
mysql client Version: 6.1.6
这说明:
- 头文件找到了
- 库也链接上了
- 程序能调用 MySQL C API 里的函数了
也就是说,这是一个"环境自检函数"。

编译成功了,但运行时报错:
sql
./test: error while loading shared libraries: libmysqlclient.so.18: cannot open shared object file: No such file or directory错误本质是什么?
编译阶段找到了库,运行阶段没找到动态库。
你要区分两个阶段:编译/链接阶段和运行阶段。
编译/链接阶段靠的是:
-L./lib -lmysqlclient 这让 gcc 知道去哪里找库做链接运行阶段 。程序启动后,操作系统要去找:libmysqlclient.so.18 这个动态库文件。但系统默认搜索路径里没有你的 ./lib,所以就报错了。
解决方法
export LD_LIBRARY_PATH=./lib:告诉系统:运行程序时,也去 ./lib 目录找动态库
这样再执行:./test 就能正常输出客户端版本。
理解:
-L./lib:是给 编译器/链接器 看的LD_LIBRARY_PATH=./lib:是给 操作系统加载器 看的
正式进入MySQL C API
第一步:mysql_init() 初始化
后面的很多函数都需要一个合法的 MYSQL*。你连"连接对象"都没有,后面当然没法连接数据库,也没法执行 SQL。
cpp
MYSQL *mysql_init(MYSQL *mysql);
示例:
MYSQL *mfp = mysql_init(NULL);它会创建/初始化一个 MYSQL 对象。这个 MYSQL 对象非常重要,你可以把它理解成:
"MySQL 连接句柄" / "连接控制对象"
后面所有操作几乎都围绕它展开。比如:
- 主机地址
- 用户名
- 端口
- 字符集
- 连接状态
- 底层方法表
这些信息都会和这个对象关联。
第二步:mysql_real_connect() 建立连接
初始化完成后,必须先连接数据库,才能做后续操作。 MySQL 网络部分基于 TCP/IP
cpp
MYSQL *mysql_real_connect(MYSQL *mysql,
const char *host,
const char *user,
const char *passwd,
const char *db,
unsigned int port,
const char *unix_socket,
unsigned long clientflag);unix_socket 本地 socket 文件,通常填 NULL
clientflag 客户端标志位,初学一般填 0
第三步:字符集问题
如果建立连接后,英文没问题,但中文乱码,可以设置默认字符集为 utf8,因为原始默认是 latin1:
cpp
mysql_set_character_set(myfd, "utf8");为什么会乱码?
因为客户端和服务器之间传输字符串时,双方要对字符编码有一致认知。
如果:
- 你的程序认为是 UTF-8
- 连接默认按 latin1 解码
那中文肯定乱
第四步:mysql_query() 发送 SQL
把你的 SQL 字符串发给 MySQL 服务器执行。
例如:
cpp
mysql_query(conn, "select * from student");服务器收到后就会解析、优化、执行,然后准备结果返回给客户端。
cpp
int mysql_query(MYSQL *mysql, const char *q);
第一个参数是连接对象,第二个参数是要执行的 SQL,比如:
select * from table返回值怎么看?
一般:
0:成功- 非
0:失败
所以通常会写:
cpp
if (mysql_query(conn, sql) != 0) {
// 错误处理
}第五步:mysql_store_result() 取查询结果
SQL 执行完以后,如果是查询语句,就要读取数据;如果是 update、insert 之类,那主要看执行成功与否。
如果 mysql_query 返回成功,那么可以通过下面代码读取结果:
cpp
MYSQL_RES *mysql_store_result(MYSQL *mysql);它会把查询结果从 MySQL 服务器读到客户端内存里,并返回一个 MYSQL_RES*。你可以把 MYSQL_RES 理解成:
"结果集对象"
它里面保存了一整张查询结果表。比如你查:
select id, name from student;
返回三行:1 张三
2 李四
3 王五那么这些行列数据,都会被装进 MYSQL_RES 里。
为什么不是所有 SQL 都要 mysql_store_result()
因为只有 查询类 SQL 才有结果集。比如:
select * from student;有很多行数据返回,所以要 mysql_store_result()
但如果你执行:
update student set name='abc' where id=1;这类语句没有结果表返回,你就没必要去取结果集。你只需要看 mysql_query() 是否成功即可。
所以你以后脑子里要有这个分流:
查询语句 mysql_query() → mysql_store_result() → 读行读列
非查询语句 mysql_query() → 看执行结果即可
第六步:读取结果总行数 mysql_num_rows()
cpp
my_ulonglong mysql_num_rows(MYSQL_RES *res);第七步:读取结果列数 mysql_num_fields()
cpp
unsigned int mysql_num_fields(MYSQL_RES *res);第八步:读取列名 mysql_fetch_fields()
cpp
MYSQL_FIELD *mysql_fetch_fields(MYSQL_RES *res);代码:
cpp
int fields = mysql_num_fields(res);
MYSQL_FIELD *field = mysql_fetch_fields(res);
int i = 0;
for(; i < fields; i++){
cout << field[i].name << " ";
}
cout << endl;MYSQL_FIELD* 可以怎么理解?
它是"字段描述信息数组"。每个元素描述一列,比如:
- 列名
- 类型
- 长度
- 其他元数据
第九步:读取每一行数据 mysql_fetch_row()
cpp
MYSQL_ROW mysql_fetch_row(MYSQL_RES *result);MYSQL_ROW 其实就是 char **,可以当二维数组来用。注意:即使数据库里是整数,取出来通常也是字符串形式来处理。
行遍历代码
cpp
i = 0;
MYSQL_ROW line;
for(; i < nums; i++){
line = mysql_fetch_row(res);//外层循环,从结果集里取出下一行
int j = 0;
for(; j < fields; j++){
cout << line[j] << " ";//按"列"循环,把这一行的每个字段都打印出来
}
cout << endl;
}第十步:关闭连接 mysql_close()
如果程序结束前不关闭,虽然操作系统最终可能帮你回收,但这是不规范的。而且在真实项目里,一个程序可能长时间运行,如果连接不及时释放,会造成:
- 连接泄漏
- 连接数耗尽
- 服务端压力增大
所以规范流程一定是:用完就关。
关于事务接口(前面学的)
前面学的事务知识,不只是 mysql 命令行里能用,在 C 程序里同样能用。也就是说,程序可以自己控制:
- 开始事务
- 执行多条 SQL
- 失败就回滚
- 成功就提交
总结
这章主要讲了 3 件事。
第一件:怎么把 MySQL 的 C 库接进你的程序
- 下载 Connector/C
- 认识
include和lib - 用
gcc -I -L -l编译链接 - 解决动态库找不到的问题
第二件:怎么建立 MySQL 连接
mysql_init()初始化连接对象mysql_real_connect()连接服务器mysql_set_character_set()处理中文乱码
第三件:怎么执行 SQL 并读取结果
mysql_query()发 SQLmysql_store_result()拿结果集mysql_num_rows()、mysql_num_fields()、mysql_fetch_fields()、mysql_fetch_row()读取表数据mysql_close()关闭连接- 还能用
mysql_commit()、mysql_rollback()做事务控制