Python语言深度掌握
- 语言核心,深入理解Python运行机制:深入理解Python对象模型、内存管理、GIL机制、解释器工作原理
- 精通Python语法与高级特性:装饰器、元类、上下文管理器、生成器协程、异步编程(asyncio)等
- 性能优化:代码性能分析、内存泄漏排查、C扩展开发
- 熟练使用标准库与常用第三方库:如 requests、pandas、numpy、logging、collections 等。
Python requests
Requests 是一个用于发送 HTTP 请求的 Python 库,广泛应用于网络爬虫、API 调用等场景。它支持多种 HTTP 方法(如 GET、POST 等),并能较为友好地处理请求参数、头信息、Cookies 等。相比于 Python 标准库中的 urllib,requests 更加简洁和人性化,使得编写网络请求代码变得更加容易。
安装与验证
requests 是一个第三方库,需通过 pip 安装。为了确保成功,需正确处理网络代理、镜像源和权限问题。
bash
pip install requests1、创建一个虚拟环境:python -m venv myenv
2、激活虚拟环境:myenv\Scripts\activate
3、在虚拟环境中安装python包:pip install requests
4、导出虚拟环境的依赖:pip freeze > requirements.txt
5、在全局环境中安装依赖:pip install -r requirements.txt

发送 GET 请求
python
import requests
# 基础 GET 请求
response = requests.get('https://httpbin.org/get')
print(f'状态码: {response.status_code}')
print(f'响应文本: {response.text[:200]}') # 打印前200个字符
# 带参数的 GET 请求 (两种方式等效)
params = {'key1': 'value1', 'key2': 'value2'}
# 方式一:手动拼接 URL(不推荐)
# 方式二:使用 `params` 参数(推荐)
response = requests.get('https://httpbin.org/get', params=params)
print(f'最终请求 URL: {response.url}') # 将显示包含参数的完整URL发送 POST 请求
python
import requests
import json
# 提交表单数据 (application/x-www-form-urlencoded)
form_data = {'username': 'admin', 'password': 'secret'}
response = requests.post('https://httpbin.org/post', data=form_data)
print(f'表单提交响应: {response.json()}')
# 提交 JSON 数据 (application/json)
json_data = {'title': 'foo', 'body': 'bar', 'userId': 1}
headers = {'Content-Type': 'application/json'}
response = requests.post('https://httpbin.org/post', json=json_data) # 更简洁的方式,headers 自动设置
# 等价于: response = requests.post('https://httpbin.org/post', data=json.dumps(json_data), headers=headers)
print(f'JSON提交响应: {response.json()}')处理响应对象
python
import requests
response = requests.get('https://api.github.com')
# 1. 状态码与原因
print(f'状态码: {response.status_code}') # 例如 200, 404, 500
print(f'状态原因: {response.reason}') # 例如 OK, Not Found
# 2. 响应头 (字典形式,不区分大小写)
print(f'服务器类型: {response.headers.get("Server")}')
print(f'内容类型: {response.headers["Content-Type"]}')
# 3. 响应内容 (根据类型选择解码方式)
# 文本内容
print(f'文本内容 (自动解码): {response.text[:100]}')
# 指定编码(如遇乱码)
response.encoding = 'gbk' # 手动指定编码格式
# 二进制内容 (用于非文本文件,如图片)
image_content = response.content # 二进制数据
# JSON 内容 (如果响应是JSON格式,requests 能自动解析为字典)
json_data = response.json()
print(f'GitHub API 返回的 JSON 键: {list(json_data.keys())[:5]}')Python pandas
pandas 是一个基于 Python 的、开源的数据分析和数据处理库,它构建在 NumPy 之上,为处理结构化或表格化数据(如 Excel 表格、CSV 文件、SQL 数据库结果)提供了快速、灵活且表达力强的数据结构。它是进行数据清洗、转换、分析和建模的必备工具,尤其适合用于统计分析和机器学习的数据预处理阶段 。
其核心数据结构有二:
- Series:一维数组,可以看作是一个带有标签的列表,标签即为索引。
- DataFrame:二维表格型数据结构,是 pandas 中最常用的对象。可以将其理解为一个 Excel 工作表或 SQL 数据库表,它由行索引(index)、列索引(columns)和数据值组成,每一列的数据类型可以不同 。
安装与导入
通常使用 pip 进行安装:pip install pandas
数据读取与写入
pandas 支持读取多种格式的数据,最常用的是读取 Excel 和 CSV 文件 。
python
import pandas as pd
# 读取 CSV 文件
df_csv = pd.read_csv('data.csv')
# 读取 Excel 文件, 需要安装 `openpyxl` 或 `xlrd` 引擎
df_excel = pd.read_excel('data.xlsx', sheet_name='Sheet1')
# 将 DataFrame 写入到 CSV 或 Excel 文件
df_csv.to_csv('output.csv', index=False) # index=False 表示不写入行索引
df_excel.to_excel('output.xlsx', sheet_name='Result')数据查看与基本信息
python
# 在数据处理前,通常需要先了解数据的整体情况。
# 假设 df 是一个已加载的 DataFrame
print(df.head()) # 查看前5行
print(df.tail()) # 查看后5行
print(df.shape) # 查看行数和列数
print(df.info()) # 查看列的数据类型和非空值统计
print(df.describe()) # 查看数值型列的统计摘要 (计数、均值、标准差、最小值、四分位数等)数据筛选与操作
python
# 选择列
single_column = df['column_name'] # 返回一个 Series
multiple_columns = df[['column_A', 'column_B']] # 返回一个 DataFrame
# 选择行 (按索引标签或位置)
rows_by_label = df.loc[0:5] # 选择索引标签为0到5的行
rows_by_position = df.iloc[0:5] # 选择位置为0到4的行(前5行)
# 条件筛选
filtered_df = df[df['score'] > 60] # 筛选出分数大于60的行
# 添加/删除列
df['new_column'] = df['column_A'] + df['column_B'] # 创建新列
df.drop(columns=['column_to_drop'], inplace=True) # 删除列,inplace=True 表示直接修改原df数据清洗技巧
python
# 处理缺失值
print(df.isnull().sum()) # 统计每列的缺失值数量
df_cleaned = df.dropna() # 删除包含缺失值的行
df_filled = df.fillna(0) # 用0填充所有缺失值,也可以用列均值 df['column'].fillna(df['column'].mean())
# 处理重复值
duplicates = df.duplicated().sum() # 统计重复行数量
df_unique = df.drop_duplicates() # 删除重复行
# 更改数据类型
df['column_name'] = df['column_name'].astype('int') # 转换为整数类型
# 重命名列
df.rename(columns={'old_name': 'new_name'}, inplace=True)数据聚合与合并
python
# 分组聚合
group_result = df.groupby('category_column')['value_column'].sum()
# 例如,按部门统计销售额总和
# 更复杂的聚合可以使用 `.agg()` 函数
agg_result = df.groupby('category').agg({'value1': 'mean', 'value2': 'max'})
# 合并多个 DataFrame (常用于合并多个表格)
df1 = pd.read_excel('sales_01.xlsx')
df2 = pd.read_excel('sales_02.xlsx')
df_merged = pd.concat([df1, df2], ignore_index=True) # 纵向堆叠(追加行)
# 横向合并,类似于 SQL JOIN
df_left = pd.DataFrame({'key': ['A', 'B', 'C'], 'value_left': [1, 2, 3]})
df_right = pd.DataFrame({'key': ['B', 'C', 'D'], 'value_right': [4, 5, 6]})
merged_df = pd.merge(df_left, df_right, on='key', how='inner') # 内连接Python numpy
Python NumPy(Numerical Python)是Python生态系统中进行科学计算和数据分析的基石库。它提供了一个高性能的多维数组对象ndarray,以及用于处理这些数组的大量函数。NumPy的核心在于其高效的数组运算能力,这使得它在机器学习、图像处理、金融建模等领域不可或缺。
NumPy 核心:ndarray数组
ndarray是NumPy的灵魂。它是一个多维、同质的(所有元素类型相同)数据容器,支持高效的向量化运算。
python
import numpy as np
# 从Python列表创建
arr1 = np.array([1, 2, 3, 4, 5])
print(arr1) # 输出: [1 2 3 4 5]
# 创建指定形状的全0数组
zeros_arr = np.zeros((2, 3)) # 2行3列的二维数组
print(zeros_arr)
# 输出:
# [[0. 0. 0.]
# [0. 0. 0.]]
# 创建指定形状的全1数组
ones_arr = np.ones((3, 2), dtype=int) # 指定数据类型为int
print(ones_arr)
# 输出:
# [[1 1]
# [1 1]
# [1 1]]
# 创建等差数列数组
range_arr = np.arange(0, 10, 2) # 从0开始,到10结束(不包含),步长为2
print(range_arr) # 输出: [0 2 4 6 8]
# 创建线性间隔数组
lin_arr = np.linspace(0, 1, 5) # 在0到1之间均匀生成5个数字
print(lin_arr) # 输出: [0. 0.25 0.5 0.75 1. ]
arr = np.array([[1, 2, 3], [4, 5, 6]])
print('数组维度 ndim:', arr.ndim) # 输出: 2
print('数组形状 shape:', arr.shape) # 输出: (2, 3)
print('元素总数 size:', arr.size) # 输出: 6
print('元素数据类型 dtype:', arr.dtype) # 输出: int64 (取决于系统)
arr = np.array([[10, 20, 30], [40, 50, 60], [70, 80, 90]])
# 索引单个元素
print(arr[0, 1]) # 第0行第1列,输出: 20
# 切片(行)
print(arr[1:]) # 获取第1行及之后的所有行
# 输出:
# [[40 50 60]
# [70 80 90]]
# 切片(行列组合)
print(arr[:, :2]) # 所有行,但只取每行的前两列
# 输出:
# [[10 20]
# [40 50]
# [70 80]]
# 布尔索引
mask = arr > 50
print(mask) # 输出布尔数组
# 输出:
# [[False False False]
# [False False True]
# [ True True True]]
print(arr[mask]) # 输出满足条件的元素: [60 70 80 90]NumPy 的核心运算:广播与向量化
NumPy的核心优势在于其向量化运算和广播机制,这使得我们可以避免使用低效的Python循环。
python
#向量化运算
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print('加法:', a + b) # 输出: [5 7 9]
print('乘法:', a * b) # 输出: [4 10 18]
print('平方:', a ** 2) # 输出: [1 4 9]
#广播:广播是一种强大的机制,它允许NumPy在不同形状的数组之间执行算术运算。
# 标量与数组运算
arr = np.array([[1, 2, 3], [4, 5, 6]])
print(arr + 10) # 数组每个元素都加10
# 输出:
# [[11 12 13]
# [14 15 16]]
# 不同形状数组间的运算(广播)
row = np.array([10, 20, 30])
print(arr + row) # row被广播,加到arr的每一行上
# 输出:
# [[11 22 33]
# [14 25 36]]
#聚合函数
arr = np.array([[1, 2], [3, 4], [5, 6]])
print('总和:', np.sum(arr)) # 输出: 21
print('每列均值:', np.mean(arr, axis=0)) # 沿着第0轴(行)聚合,求每列均值。输出: [3. 4.]
print('每行最大值:', np.max(arr, axis=1)) # 沿着第1轴(列)聚合,求每行最大值。输出: [2 4 6]
print('标准差:', np.std(arr)) # 输出: 1.707825127659933
#矩阵运算
# 矩阵乘法
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
print('矩阵乘法(使用@运算符):\n', A @ B)
# 输出:
# [[19 22]
# [43 50]]
# 矩阵转置
print('A的转置:\n', A.T)
# 输出:
# [[1 3]
# [2 4]]与其他库的集成
NumPy数组是许多高级科学计算库(如Pandas、Scikit-learn、Matplotlib)的通用数据交换格式。Pandas的DataFrame和Series在底层大量使用NumPy数组,可以轻松地进行转换。
python
import pandas as pd
# 将Pandas Series转换为NumPy数组
s = pd.Series([1, 2, 3])
np_array = s.values
print(type(np_array)) # 输出: <class 'numpy.ndarray'>Python logging
Python的logging模块是标准库中用于生成应用程序运行日志的核心工具。它提供了一个灵活的事件记录系统,能够帮助开发者进行调试、监控和诊断。
logging模块的核心架构基于四个关键类,它们协同工作以完成日志信息的记录和输出。
logging模块的核心架构基于四个关键类,它们协同工作以完成日志信息的记录和输出。日志级别定义了事件的重要性,从低到高依次为:DEBUG、INFO、WARNING、ERROR、CRITICAL。Logger和Handler可以设置各自的级别,只有当日志事件的级别不低于二者的级别时,该日志才会被处理。

基础使用方法
python
import logging
# 1. 创建记录器 (Logger)
logger = logging.getLogger(__name__) # 通常以模块名命名,便于追溯来源[ref_3]
logger.setLevel(logging.DEBUG) # 设置记录器级别
# 2. 创建控制台处理器 (Handler)
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO) # 处理器级别,可以不同于记录器级别
# 3. 创建格式器 (Formatter)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
console_handler.setFormatter(formatter)
# 4. 将处理器添加到记录器
logger.addHandler(console_handler)
# 5. 记录日志
logger.debug("这是一条调试信息,通常看不到,因为处理器级别是INFO")
logger.info("程序正常运行。")
logger.warning("出现潜在问题。")
logger.error("发生了一个错误。")
logger.critical("发生了一个严重错误,程序可能无法继续运行。")高级配置:使用配置文件
对于复杂的生产环境,通过代码配置日志系统会显得笨重且难以维护。logging模块支持从字典或配置文件(如JSON、YAML、.conf)加载配置,这提供了极大的灵活性,且可以在不修改代码的情况下调整日志行为。
下面是一个使用字典配置的示例:
python
import logging
import logging.config
LOGGING_CONFIG = {
"version": 1, # 配置字典版本号,必须为1
"disable_existing_loggers": False, # 不禁用已存在的记录器
"formatters": {
"detailed": {
"format": "%(asctime)s - %(name)s - %(levelname)s - %(module)s:%(lineno)d - %(message)s"
},
"simple": {
"format": "%(levelname)-8s - %(message)s"
}
},
"handlers": {
"console": {
"class": "logging.StreamHandler",
"level": "INFO",
"formatter": "simple",
"stream": "ext://sys.stdout"
},
"file": {
"class": "logging.handlers.RotatingFileHandler", # 使用轮转文件处理器,防止单个文件过大[ref_1]
"level": "DEBUG",
"formatter": "detailed",
"filename": "app.log",
"maxBytes": 10485760, # 10MB
"backupCount": 5,
"encoding": "utf8"
}
},
"loggers": {
"__main__": { # 为主模块配置
"level": "DEBUG",
"handlers": ["console", "file"]
},
"my_module": { # 为特定模块配置
"level": "INFO",
"handlers": ["file"],
"propagate": False # 是否向上(根记录器)传播日志记录
}
},
"root": { # 根记录器的配置
"level": "WARNING",
"handlers": ["console"]
}
}
# 应用配置
logging.config.dictConfig(LOGGING_CONFIG)
# 获取记录器并记录日志
logger = logging.getLogger(__name__)
logger.info("应用程序启动,日志系统已通过字典配置完成。")多模块项目中的最佳实践
- 使用 name 获取 Logger:这是最佳实践。__name__变量会反映模块的层次结构(如package.submodule),使得日志来源一目了然,也便于对不同模块进行差异化配置。
- 区分库日志和应用日志:作为库开发者,不应直接配置Handler,而应只创建Logger。配置应由最终使用该库的应用程序来完成。这可以通过将库的Logger级别设置为WARNING及以上,或将propagate设为True(默认)让日志向上传播给应用级记录器处理。
- 记录异常信息:使用logger.exception()方法或在记录错误时传入exc_info=True参数,可以自动捕获并记录异常的堆栈跟踪信息,这对于排查错误至关重要。
python
# 在模块 mylib/processor.py 中
import logging
logger = logging.getLogger(__name__) # Logger名称将为 'mylib.processor'
def process_data(data):
try:
# ... 处理逻辑
logger.debug(f"正在处理数据: {data}")
result = 1 / 0 # 故意制造一个除零错误
except ZeroDivisionError:
# 方式一:使用exception方法,会自动记录堆栈信息(级别为ERROR)
logger.exception("处理数据时发生除零错误")
# 方式二:等价于 logger.error('xxx', exc_info=True)
# logger.error("处理数据时发生除零错误", exc_info=True)
raise工程化实践与注意事项
- 敏感信息脱敏:日志中切忌记录密码、密钥、完整Token等敏感信息。在记录前应对此类数据进行处理或脱敏。
- 考虑异步日志:对于I/O密集型(如写入网络或大文件)或高并发场景,同步日志可能成为性能瓶颈。可以考虑使用logging.handlers.QueueHandler和logging.handlers.QueueListener实现异步日志,或将日志输出到标准输出(stdout),由外部的日志收集系统(如Docker日志驱动、systemd-journald)处理。
- 环境隔离配置:在不同环境(开发、测试、生产)中,日志的详细程度和输出目的地通常不同。可以通过环境变量来动态加载不同的日志配置文件。
- 结构化日志:为便于后续使用ELK(Elasticsearch, Logstash, Kibana)等日志分析系统进行检索和分析,应输出结构化的日志(如JSON格式)。这可以通过自定义Formatter来实现。
- 性能考量:logging模块本身是高性能的,因为级别检查非常快。但要避免在日志调用中执行昂贵的操作。例如,使用logger.debug("Result: %s", expensive_function())而不是logger.debug("Result: " + expensive_function())。前者只有在日志级别为DEBUG时才会调用expensive_function(),而后者在任何级别下都会先执行字符串拼接和函数调用。
Python collections
Python 的 collections 模块是标准库中用于提供高级数据容器的模块,它扩展了内置数据类型(如 list、tuple、dict、set)的功能,为特定场景提供了更高效、更易用的数据结构。
核心数据结构概览
collections 模块提供了一系列专用容器,其核心功能及替代关系如下表所示:
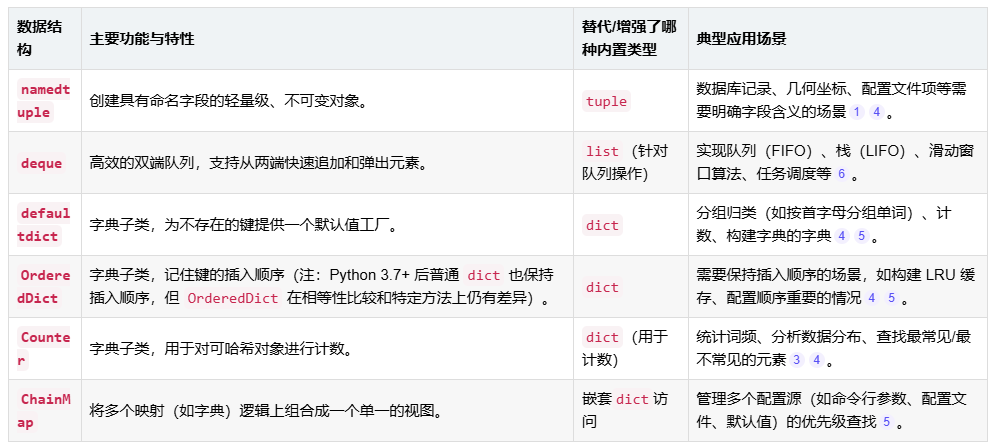
namedtuple
namedtuple 用于创建具有字段名的元组子类,它让元组中每个位置的意义变得清晰,可以通过属性访问而非索引。
python
from collections import namedtuple
# 定义命名元组类型
Point = namedtuple('Point', ['x', 'y'])
Circle = namedtuple('Circle', ['x', 'y', 'radius'])
# 创建实例
p1 = Point(10, 20)
c1 = Circle(0, 0, 5)
# 通过属性访问
print(f"Point: x={p1.x}, y={p1.y}") # 输出: Point: x=10, y=20
print(f"Circle center: ({c1.x}, {c1.y}), radius={c1.radius}") # 输出: Circle center: (0, 0), radius=5
# 支持元组的所有操作
x, y = p1 # 解构赋值
print(f"Unpacked: {x}, {y}") # 输出: Unpacked: 10, 20
print(f"Index access: p1[0] = {p1[0]}") # 输出: Index access: p1[0] = 10
# _asdict()方法将命名元组转换为有序字典
print(p1._asdict()) # 输出: {'x': 10, 'y': 20}deque
deque(双端队列)是列表的替代品,当需要在序列两端进行频繁的插入和删除操作时,其性能远优于列表(list),因为列表在头部操作的时间复杂度是 O(n),而 deque 在两端操作的时间复杂度是 O(1)。
python
from collections import deque
# 创建双端队列
d = deque([1, 2, 3])
print(f"Initial deque: {d}") # 输出: Initial deque: deque([1, 2, 3])
# 在右侧(尾部)追加元素
d.append(4)
d.append(5)
print(f"After append: {d}") # 输出: After append: deque([1, 2, 3, 4, 5])
# 在左侧(头部)追加元素
d.appendleft(0)
print(f"After appendleft: {d}") # 输出: After appendleft: deque([0, 1, 2, 3, 4, 5])
# 从右侧弹出元素
right_pop = d.pop()
print(f"Popped from right: {right_pop}, deque: {d}") # 输出: Popped from right: 5, deque: deque([0, 1, 2, 3, 4])
# 从左侧弹出元素
left_pop = d.popleft()
print(f"Popped from left: {left_pop}, deque: {d}") # 输出: Popped from left: 0, deque: deque([1, 2, 3, 4])
# 旋转操作:正数向右旋转,负数向左旋转
d.rotate(2)
print(f"After rotate(2): {d}") # 输出: After rotate(2): deque([3, 4, 1, 2])
# 应用:实现固定长度队列(滑动窗口)
window = deque(maxlen=3)
for i in range(5):
window.append(i)
print(f"Current window: {list(window)}")
# 输出:
# Current window: [0]
# Current window: [0, 1]
# Current window: [0, 1, 2]
# Current window: [1, 2, 3] # 达到最大长度后,新元素加入,最老的元素被自动挤出
# Current window: [2, 3, 4]defaultdict
defaultdict 是 dict 的子类,它接受一个可调用对象(工厂函数)作为参数,当访问不存在的键时,会自动调用该工厂函数生成默认值,而不会抛出 KeyError。
python
from collections import defaultdict
# 使用list作为默认工厂,常用于分组
group_by_first_letter = defaultdict(list)
words = ['apple', 'bat', 'bar', 'atom', 'book']
for word in words:
group_by_first_letter[word[0]].append(word)
print(dict(group_by_first_letter))
# 输出: {'a': ['apple', 'atom'], 'b': ['bat', 'bar', 'book']}
# 使用int作为默认工厂,常用于计数(效果类似Counter,但更基础)
counts = defaultdict(int)
for char in "mississippi":
counts[char] += 1 # 首次访问不存在的键时,int()返回0,然后加1
print(dict(counts)) # 输出: {'m': 1, 'i': 4, 's': 4, 'p': 2}
# 使用lambda自定义复杂默认值
default_scores = defaultdict(lambda: {'math': 0, 'english': 0})
scores = default_scores
scores['Alice']['math'] = 95
scores['Bob']['english'] = 88
print(scores['Alice']) # 输出: {'math': 95, 'english': 0}
print(scores['Charlie']) # 访问不存在的键,返回lambda定义的默认字典
# 输出: {'math': 0, 'english': 0}Counter
Counter 是 dict 的子类,专门用于对可哈希对象进行计数。它提供了便捷的方法来统计频率、查找最常见元素等。
python
from collections import Counter
# 从可迭代对象创建Counter
words = ['red', 'blue', 'red', 'green', 'blue', 'blue']
color_counts = Counter(words)
print(f"Color counts: {color_counts}") # 输出: Color counts: Counter({'blue': 3, 'red': 2, 'green': 1})
# 从字符串创建(统计字符频率)
char_counts = Counter("abracadabra")
print(f"Char counts: {char_counts}") # 输出: Char counts: Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
# 手动更新计数
color_counts.update(['red', 'yellow'])
print(f"After update: {color_counts}") # 输出: After update: Counter({'blue': 3, 'red': 3, 'green': 1, 'yellow': 1})
# 获取最常见的n个元素
print(f"Top 2 colors: {color_counts.most_common(2)}") # 输出: Top 2 colors: [('blue', 3), ('red', 3)]
# Counter支持数学运算(集合运算)
c1 = Counter(a=3, b=1)
c2 = Counter(a=1, b=2)
print(f"c1 + c2: {c1 + c2}") # 加法: Counter({'a': 4, 'b': 3})
print(f"c1 - c2: {c1 - c2}") # 减法(只保留正数计数): Counter({'a': 2})
print(f"c1 & c2: {c1 & c2}") # 交集(取最小计数): Counter({'a': 1, 'b': 1})
print(f"c1 | c2: {c1 | c2}") # 并集(取最大计数): Counter({'a': 3, 'b': 2})OrderedDict 与 ChainMap
尽管 Python 3.7+ 的普通字典保持了插入顺序,但 OrderedDict 在比较相等性时考虑顺序(OrderedDict(('a', 1), ('b', 2)) != OrderedDict(('b', 2), ('a', 1))),并且有 move_to_end(key) 和 popitem(last=True/False) 等方法,适合实现 LRU 缓存等结构。
ChainMap 将多个字典逻辑链接成一个映射,查找时按顺序检查每个字典,直到找到键为止,非常适合管理具有优先级的多层配置。
python
from collections import OrderedDict, ChainMap
# OrderedDict示例:保持插入顺序(Python 3.6+普通dict也有此特性,但OrderedDict提供额外方法)
od = OrderedDict()
od['z'] = 1
od['y'] = 2
od['x'] = 3
print(f"Keys in insertion order: {list(od.keys())}") # 输出: ['z', 'y', 'x']
od.move_to_end('z') # 将键'z'移动到末尾
print(f"After moving 'z' to end: {list(od.keys())}") # 输出: ['y', 'x', 'z']
# ChainMap示例:多层配置查找
defaults = {'theme': 'light', 'language': 'en'}
user_prefs = {'theme': 'dark'}
system_env = {'language': 'zh-CN'}
# 创建ChainMap,查找顺序:user_prefs -> defaults -> system_env
# 但实际上,ChainMap构造时第一个参数是最高优先级,所以更常见的用法是:用户设置 > 环境变量 > 默认值
config = ChainMap(user_prefs, system_env, defaults) # 查找顺序:user_prefs -> system_env -> defaults
print(f"theme: {config['theme']}") # 从user_prefs中找到 'dark' [ref_5]
print(f"language: {config['language']}") # 从system_env中找到 'zh-CN' [ref_5]
print(f"non_existent: {config.get('non_existent', 'not found')}") # 所有字典中都没有,返回默认值 'not found'