记得不需要旧代码注释掉
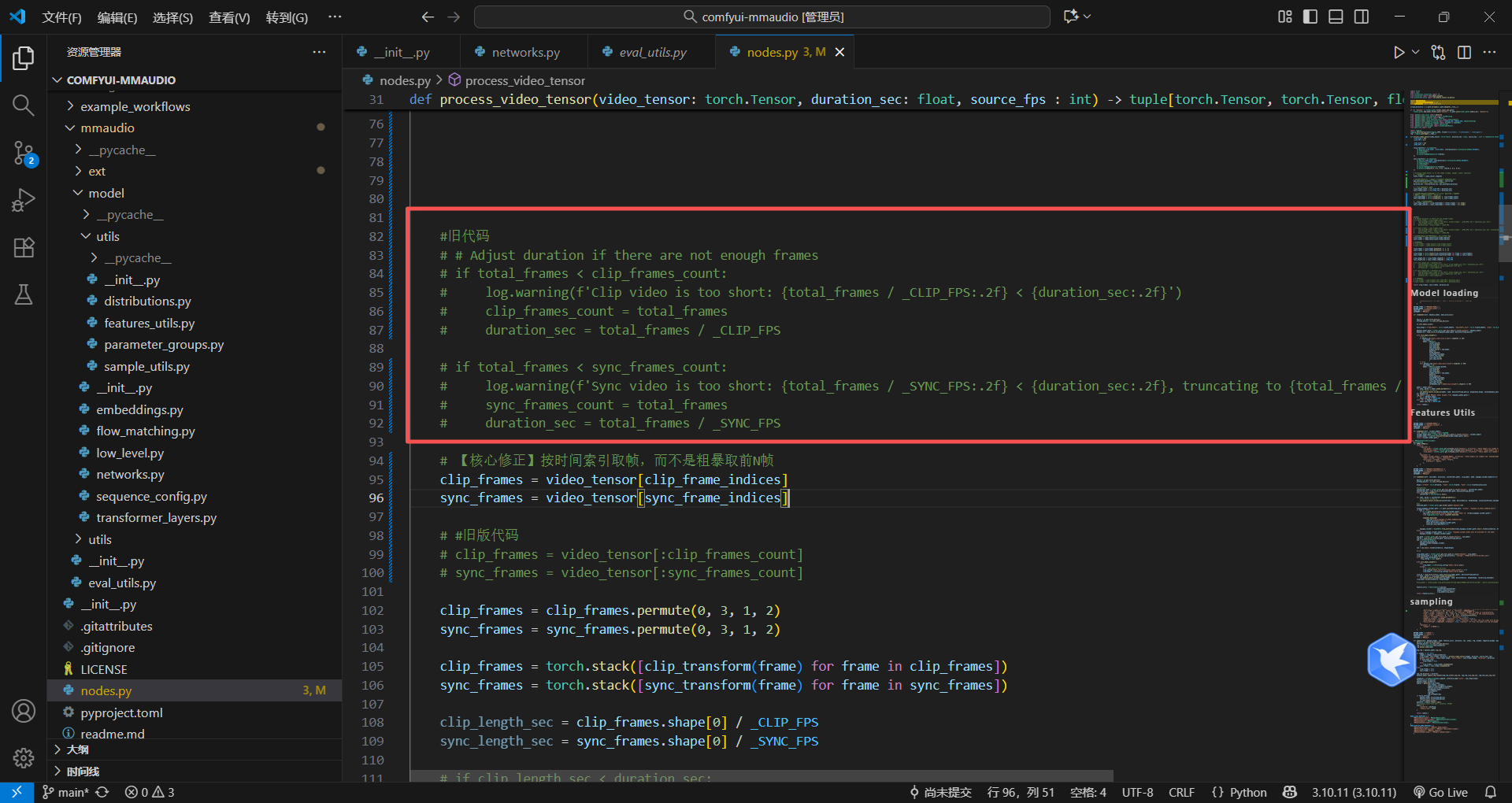
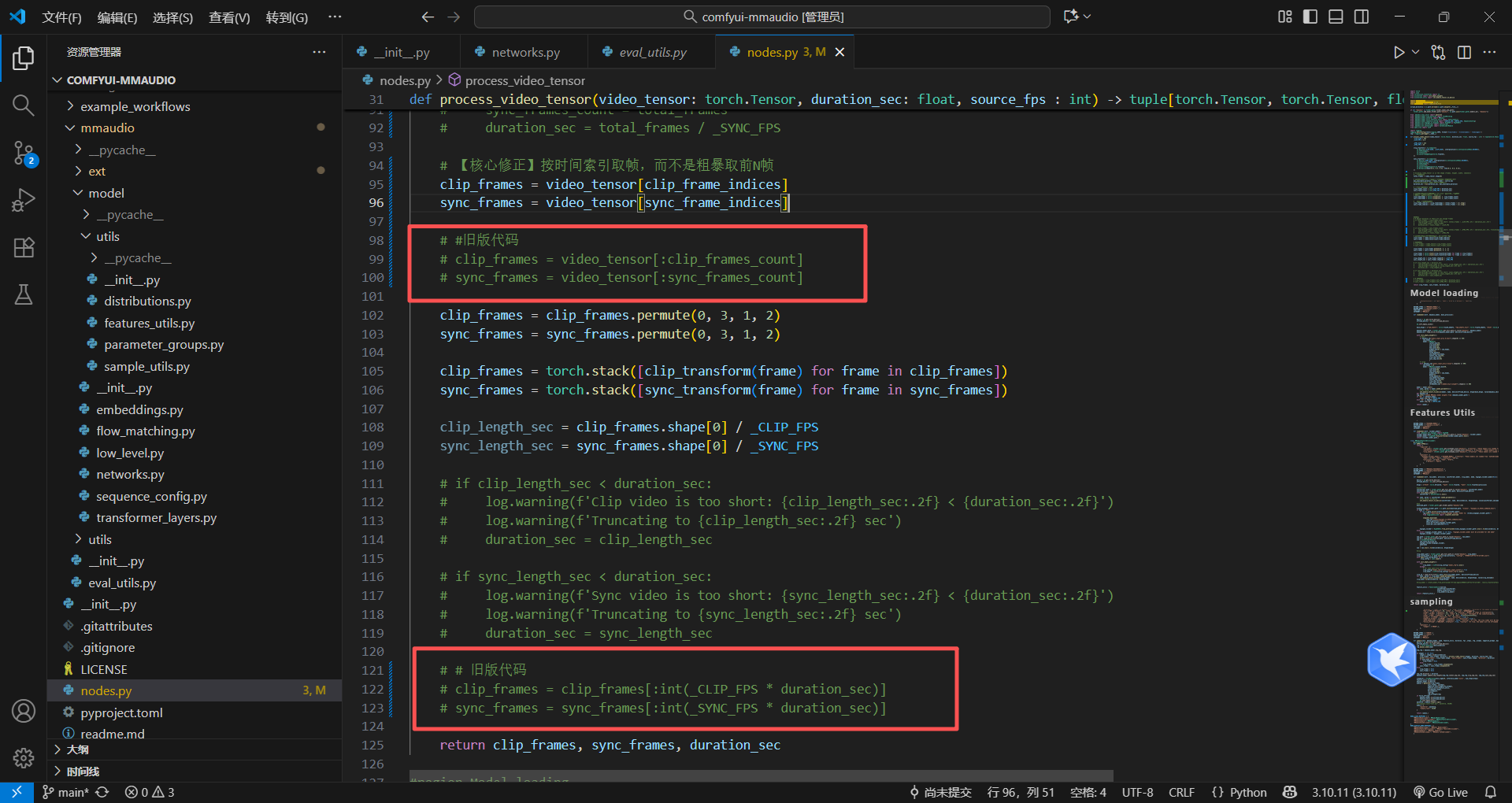
直接尝试运行,竟然成功了
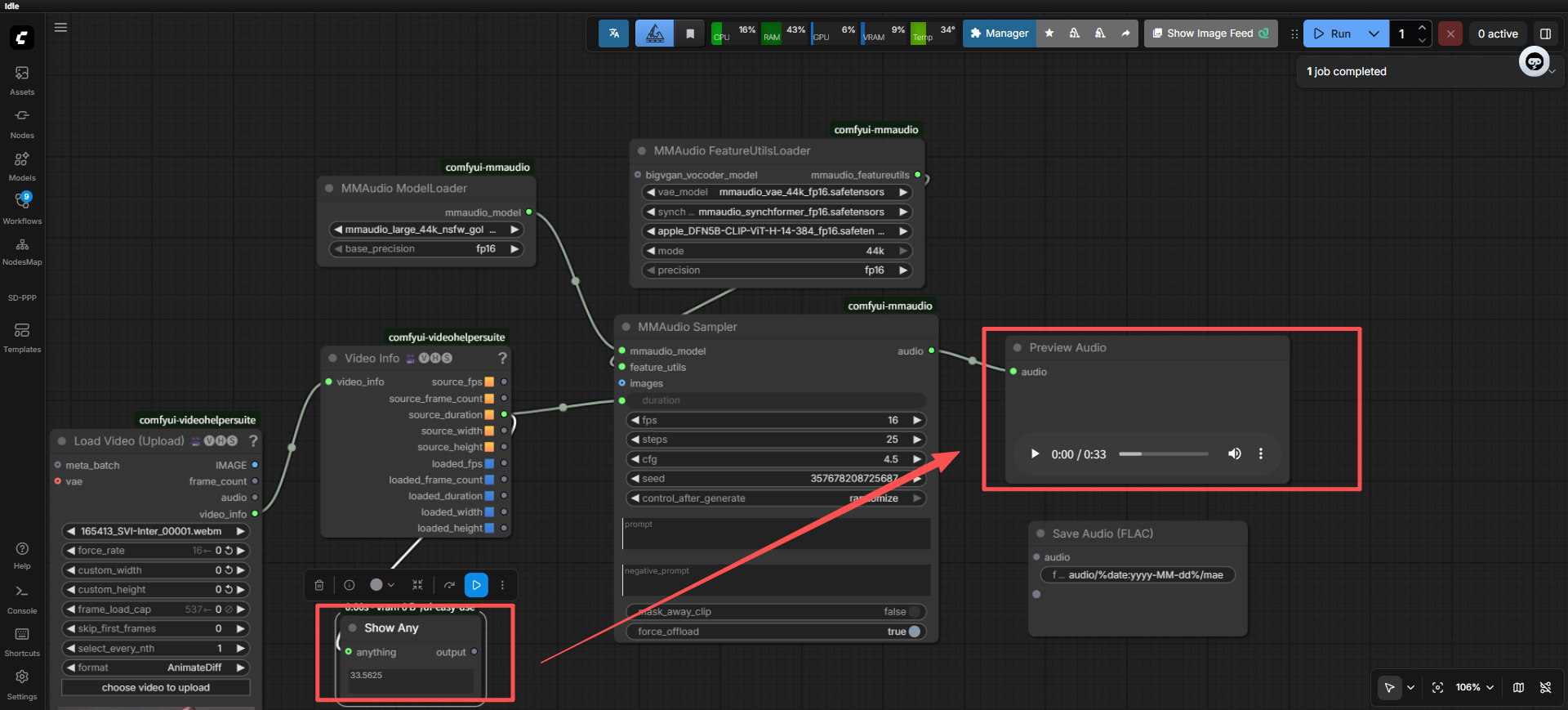
明显伪造视频(25帧),时长是对的,看来按照时间轴的插帧是没问题的
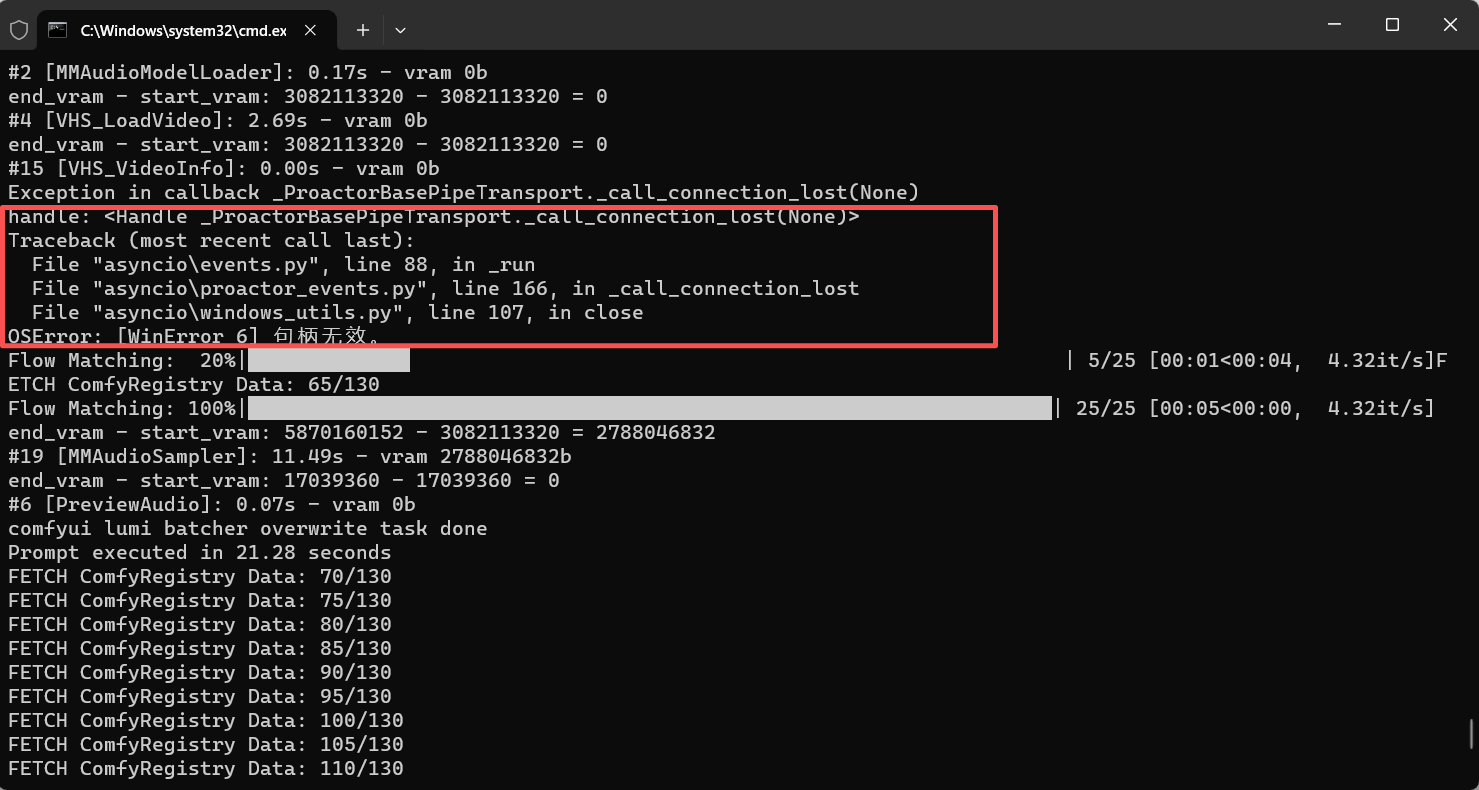
就是出现了报错,我看看啥原因
查了一下,这个是ComfyUI 后台的异步通信线程, 是comfyui后台与前端的通信问题,OSError: [WinError 6] 句柄无效 是 ComfyUI 在 Windows 环境下的高频小问题
不关事就对了,看来成功,听听音频有没有太多影响
听了一下,效果还不错,音频没有停顿那些
真正25帧视频
既然一定得用25帧的,那我就想办法把视频变成25帧,听起来简单,但是一开始我的思路有问题
首先,我喜欢把视频看成一张张的图片,然后通过连续播放,在视觉里面就动起来了...
所以我一直理解的是,要弄一个25帧的视频,就得压缩时长,因为同样数量的图片,帧率提高,那肯定时长不一样了,这也是一开始mmaudio生成视频的处理方法,会导致时长变短
不压缩时长(RIFE)
好不容易生成5秒的视频,你就这样压缩了?那我生成的时间成本呢?所以第一想法就是补帧
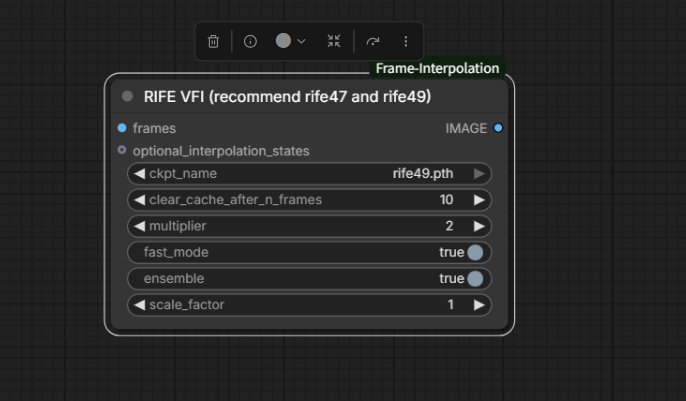
看了很多类似的补帧节点,基本都是翻倍,因为这个补帧的技术是这样的
RIFE 的核心原理,是在相邻的 2 张原生帧之间,生成 1 张符合运动逻辑的过渡帧,天生就是「2 倍倍率」的最小单位。每多补一次,就是在已有的帧之间再插一次,所以只能是 2/4/8 倍的翻倍逻辑。
所以我只能补帧出来32帧的视频,但是这样视频会很大,相当于图片多了两倍
这个补帧的技术会好一些,基本上就是不会有什么拖影
load video (upload)
突然发现这个节点竟然可以调节帧率,所以我花了一点时间了解了一下这个节点的参数和作用
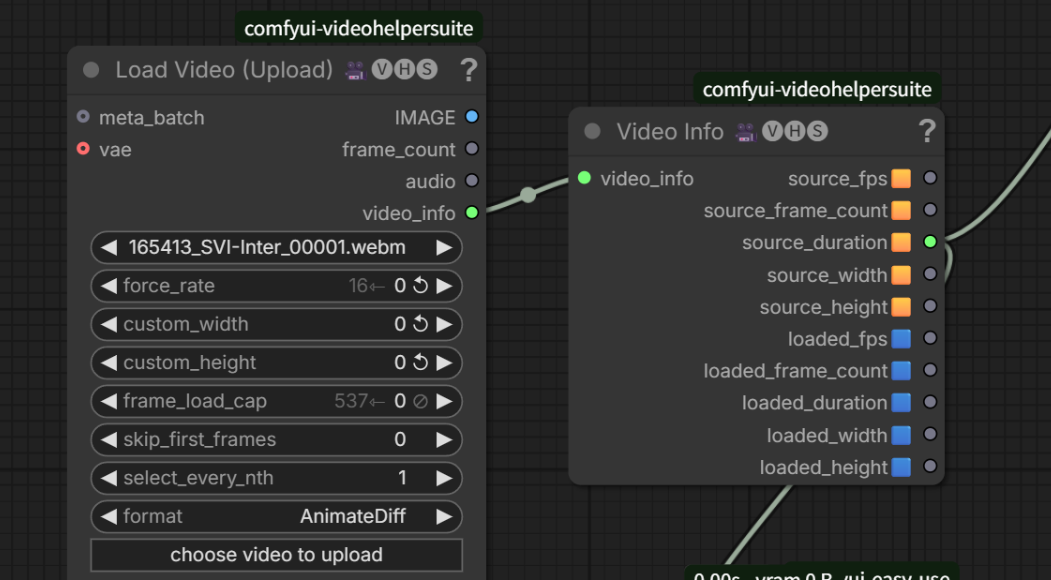
| 端口名 | 端口类型 | 核心作用 | 详细说明 |
|---|---|---|---|
IMAGE |
蓝色(主输出) | 输出解码后的视频帧序列 | 输出 ComfyUI 标准的 IMAGE 张量,格式为[帧数, 高度, 宽度, 3](RGB 通道),是后续 AnimateDiff、视频重绘、帧编辑等所有视频类节点的核心输入,也是这个节点最核心的输出。 |
frame_count |
灰色(数值输出) | 输出本次最终加载的视频总帧数 | 输出 int 类型的数字,对应最终输出的帧序列的总长度,可用于下游节点做时长控制、循环次数、帧选择等逻辑。 |
audio |
灰色(音频输出) | 输出视频里的原生音频流 | 输出 VHS 标准的 AUDIO 张量,保留原视频的声音,后续可直接接入 VHS 的Video Combine等导出节点,实现 "处理完视频还能保留原音",无需额外合成音频。 |
video_info |
绿色(元数据输出) | 输出视频的完整元数据字典 | 包含原视频的原生帧率、分辨率、时长、编码格式、总帧数等所有底层信息,仅用于高级批量处理、流程自动化的控制节点,普通单视频流程无需使用。 |
输出简单说法:
image就是视频的图片
frame_count就是图片数量
audio就是视频的声音
video_info就是视频的信息,连接到右边的节点,source-xxx就是视频的原本信息,loaded-xxx就是你修改之后的视频信息
左边的输入基本用不到的,不讲,就是我看到视频有一个修改的信息loaded-xxx之后,我就发现这个节点是可以直接改视频的信息的
调节参数了解(重点)
- 视频文件选择栏(< > 包裹的文件名,如
165413_SVI-Inter_00001.webm)
- 核心作用:选择已经上传到 ComfyUI 的视频文件,左右箭头可切换所有已上传的视频。
- 补充说明:视频通过下方的
choose video to upload按钮上传,上传后会永久保存在 ComfyUI 的input目录下,重启软件不会消失。
force_rate(强制帧率)
- 核心作用:无视原视频的原生帧率,强制把视频重采样到你设定的目标帧率(FPS)。
- 详细规则:
- 数值为
0:禁用强制帧率,完全沿用原视频的原生帧率加载;- 数值 > 0(比如你图中的 16):会对原视频做帧重采样,通过插帧 / 丢帧,把视频转换成目标 FPS,最终输出的
frame_count、播放速度都会同步适配。- 典型场景:AnimateDiff 等视频模型大多有固定的训练帧率(8/16/24FPS),用这个参数可以直接把素材统一到模型要求的帧率,无需提前用剪辑软件转码。
- 关键区别:这个参数是平滑重采样,不是硬丢帧,不会出现画面跳变,适合做帧率转换。
custom_width/custom_height(自定义宽 / 高)
- 核心作用:强制缩放加载的视频到指定分辨率,适配 AI 模型的尺寸要求,同时降低显存占用。
- 详细规则:
- 两个都设为
0(默认):完全保留原视频的原生分辨率,不做任何缩放;- 一个设数值、另一个设 0:按原视频的宽高比,自动计算另一个维度的数值,等比例缩放,不会拉伸变形。比如原视频 1920x1080,宽设 960、高设 0,会自动缩放到 960x540;
- 两个都设数值:强制缩放到你设定的宽高,无视原比例,可能导致画面拉伸变形。
- 注意事项:建议分辨率设置为 64/32 的整数倍,符合 SD 类 AI 模型的输入要求,避免报错。
frame_load_cap(加载帧数上限)
- 核心作用:硬限制本次加载的最大帧数,只加载视频开头的 N 帧,超过的部分直接丢弃,不加载、不处理。
- 详细规则:
- 数值为
0(默认):加载视频的全部帧,无上限;- 数值 > 0(比如你图中的 537):只加载视频的前 537 帧,后续所有帧直接丢弃,最终输出的
frame_count不会超过这个数值。- 典型场景:长视频只取开头片段做测试;避免长视频加载过多帧导致显存 / 内存溢出;精准控制输出视频的时长(比如 16FPS 下,32 帧就是 2 秒)。
skip_first_frames(跳过开头帧数)
- 核心作用:跳过视频开头的 N 帧,从第 N+1 帧开始加载,直接丢弃不需要的开头内容。
- 详细规则:
- 数值为
0(默认):从视频第 1 帧开始加载,不跳过任何内容;- 数值 > 0:直接丢弃开头的 N 帧,从后续内容开始加载。比如设 10,就会跳过前 10 帧,从第 11 帧开始加载。
- 典型场景:跳过视频开头的黑场、片头、无效内容;配合
frame_load_cap,可以精准截取视频的任意片段(比如 skip 100 帧、cap 50 帧,就是截取 101-150 帧的内容)。
select_every_nth(每 N 帧选 1 帧)
- 核心作用:帧采样步长,每隔 N 帧取 1 帧加载,是硬抽帧、快速降帧、减少总帧数的核心参数。
- 详细规则:
- 数值为
1(默认):加载所有帧,不做抽帧;- 数值为
2:每 2 帧取 1 帧,只加载 1、3、5、7... 帧,总帧数直接减半;- 数值为
N:每 N 帧取 1 帧,最终总帧数变为原来的 1/N。- 关键区别:和
force_rate不同,这个参数是硬丢帧,无插帧,画面会有跳变,适合快速降帧、降低显存占用,不适合做平滑的帧率转换。
format(格式)
- 核心作用:设置输出帧序列的张量格式、数据排布,适配不同的下游模型 / 节点,避免格式不兼容报错。
- 详细说明:
- 默认选项
AnimateDiff:适配绝大多数 AnimateDiff 系列视频生成模型,99% 的常规场景都选这个;- 其他可选值(如 ModelScope、Deforum、Native):仅当你使用对应插件 / 模型时,才需要切换,用来统一帧的维度顺序、数据范围,避免下游节点出现画面异常、报错。
choose video to upload(选择视频上传)按钮
- 核心作用:打开本地文件浏览器,选择你电脑上的视频文件,上传到 ComfyUI 的
input目录。- 补充说明:内置 ffmpeg 解码,兼容 mp4、webm、mov、avi、mkv 等绝大多数主流视频格式;大视频上传需要等待完成,才会出现在上方的文件选择列表中。
简单的了解:
基本上有用的就这几个
force_rate
强制调节视频的帧率,太爽了卧槽,但是时长不会降低吗?赶紧尝试了一下
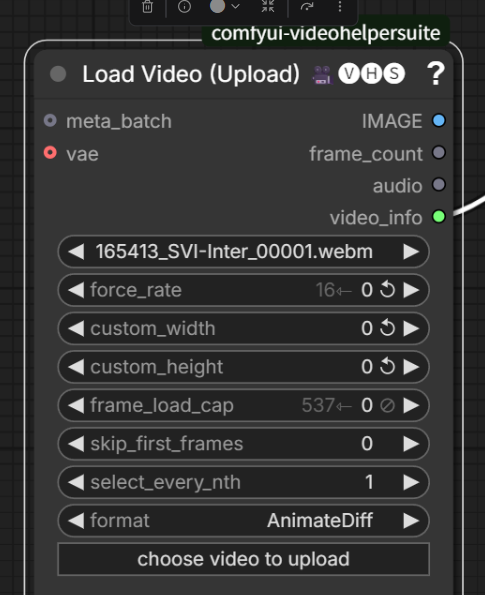
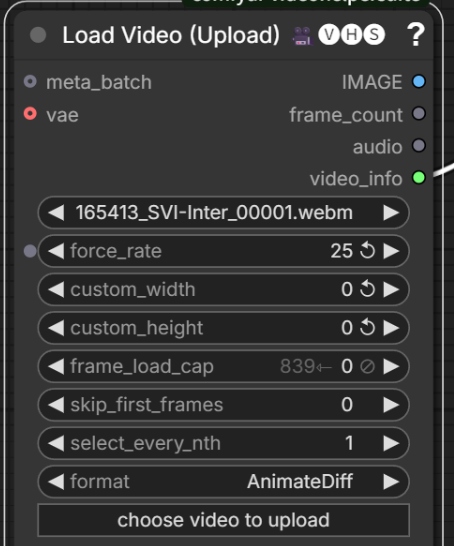
发现我调节了帧率之后,图片数量从537直接变成了839,也就是说它自动给你补全了图片,那么时长肯定是一样的
于是我想?这是ai生成的?还是什么东东,查了一下
这些新增的帧,是 VHS 节点底层调用的
ffmpeg(行业通用的视频解码工具),通过帧插值算法 生成的过渡帧,和 AI 生图没有任何关系,是传统视频编码的像素级插值算法VHS 的
force_rate参数,底层通过 ffmpeg 的fps滤镜实现帧率转换,默认采用线性帧融合(Frame Blending) 算法,属于传统视频插值技术,仅基于已有两帧的像素 RGB 值做加权平均计算,无任何 AI 生成逻辑,也不会对画面内容做任何修改。
可以理解成,对相邻两张图片进行像素融合,弄出一张介于A和B之间的图像
我也怀疑这样会不会对视频的质量有所下降,于是又查了一下
- 你当前的场景(16FPS→25FPS,小幅升帧)
几乎无负面影响,观感反而会提升:
- 画质损失微乎其微,肉眼几乎看不到锐度、细节的下降,AI 生成的人物、场景、纹理细节会完全保留;
- 不会出现任何画面崩坏、畸形、穿模、颜色错乱的问题,因为它根本不创造新内容,只是混合已有画面;
- 反而会解决 AI 生成视频常见的轻微卡顿、跳帧问题,让动作过渡更顺滑,整体观感更好。
- 极端大幅升帧(比如 16FPS→60FPS,翻 3 倍以上)
只有轻微的画质下降,无内容错误:
- 唯一的负面影响是:相邻原生帧的动作差异较大时,混合后的过渡帧会出现轻微的边缘拖影、画面模糊,AI 生成的精细细节(比如发丝、文字、纹理)会有可感知的锐度下降;
- 但最坏的结果也只是「画面变糊」,绝对不会出现低质量的崩坏图,更不会出现 AI 生成常见的内容错误。
- 降帧场景(比如 30FPS→16FPS)
完全无损,只是丢弃多余的原生帧,不会对画面质量有任何影响。
也就是说只会有轻微的边缘拖影,只要提升的帧率不是很夸张一般没什么问题的
但是第三个降帧就是完全没有影响了
参数顺序
帧控制参数的生效顺序(优先级从高到低):
skip_first_frames→select_every_nth→frame_load_cap→force_rate简单说:先跳过开头,再抽帧,再限制最大帧数,最后重采样帧率,多个参数会叠加生效,设置前要注意顺序。显存优化优先级:视频加载报错 / 显存不足时,优先调整:
custom_width/custom_height(缩小分辨率)→select_every_nth(抽帧降总帧数)→frame_load_cap(限制最大帧数),这三个是降显存最有效的参数。
最佳25帧方案
先用RIFE进行插针(翻倍到32),然后再使用load video把帧数降到25就行了
这样是最舒服的,而且最好是先高清放大再补帧,这样会省很多时间,具体原因如下:
图片越清晰,补帧的时候效果越好(太糊它都分不清动作轨迹),而且又是根据像素来的....
省时间,高清放大的时间可不是补帧可以比的,在帧数少的时候放大最舒服
尝试效果
先还原节点的代码,然后处理视频,这里就不进行放大了,反正只是测试音频,先给视频补帧,然后做两个测试对比
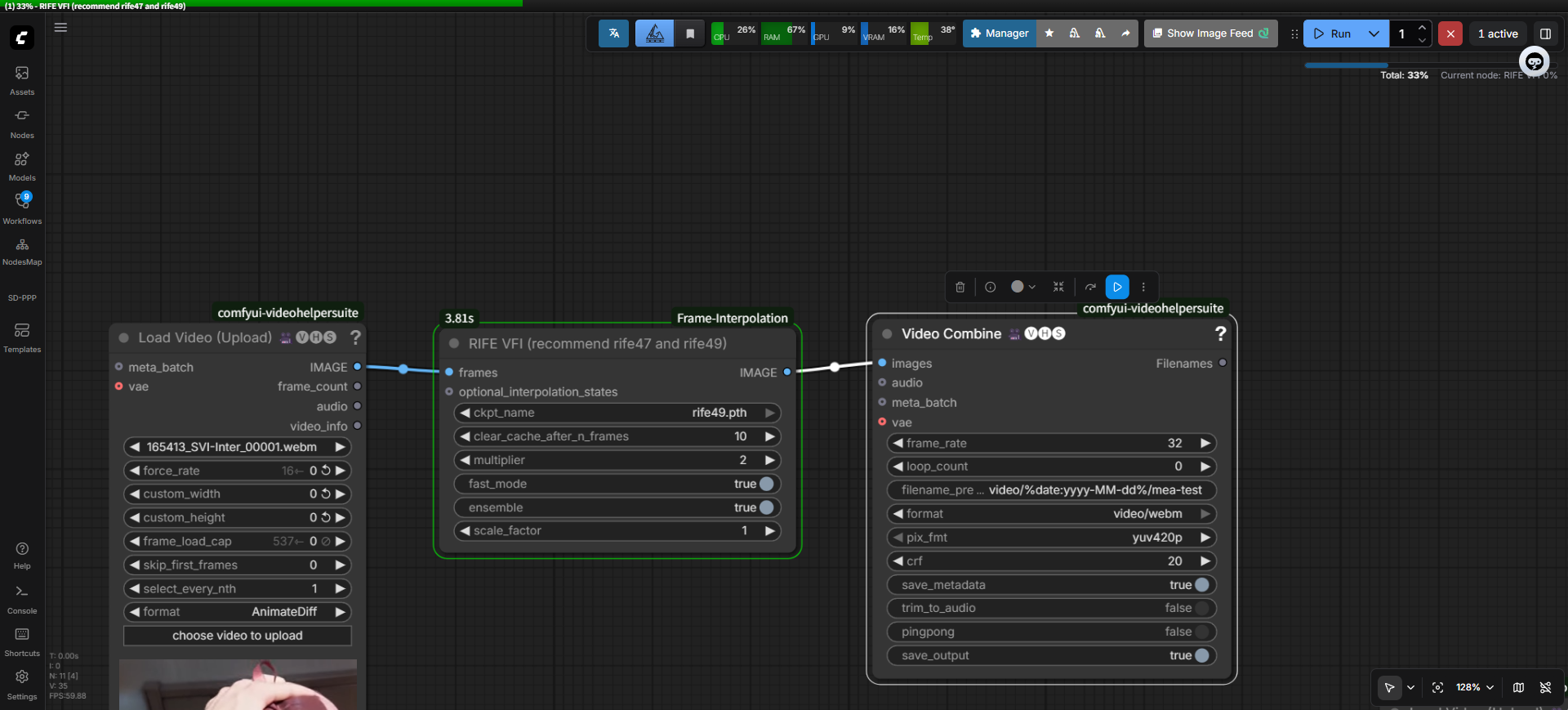
我只把代码处理代码改回来,界面上的fps没删掉,可以看到我还是选16帧,但是这个参数已经没啥用了,处理出来的音频还是33秒(因为视频已经变成25帧了)
先用16帧直接变25帧
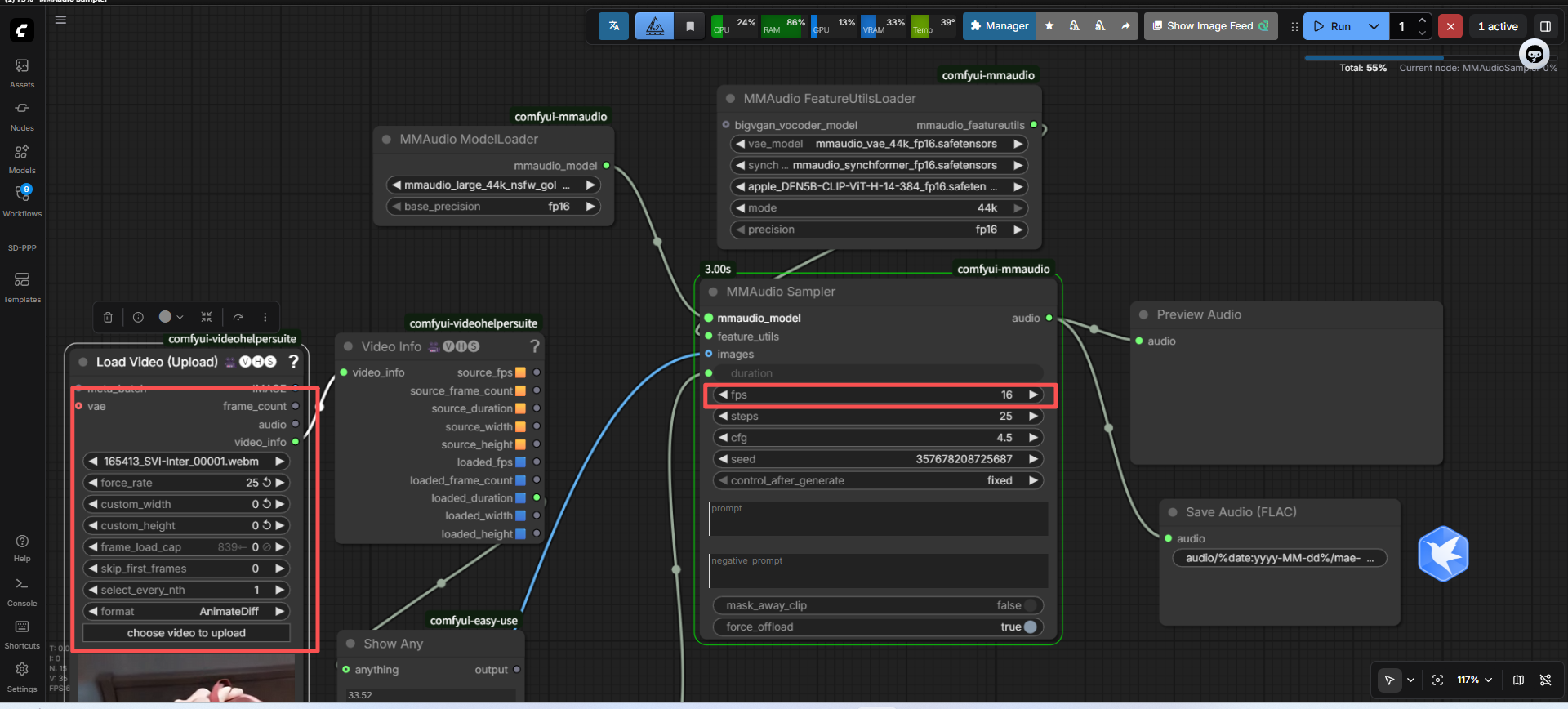
然后用32帧变25帧
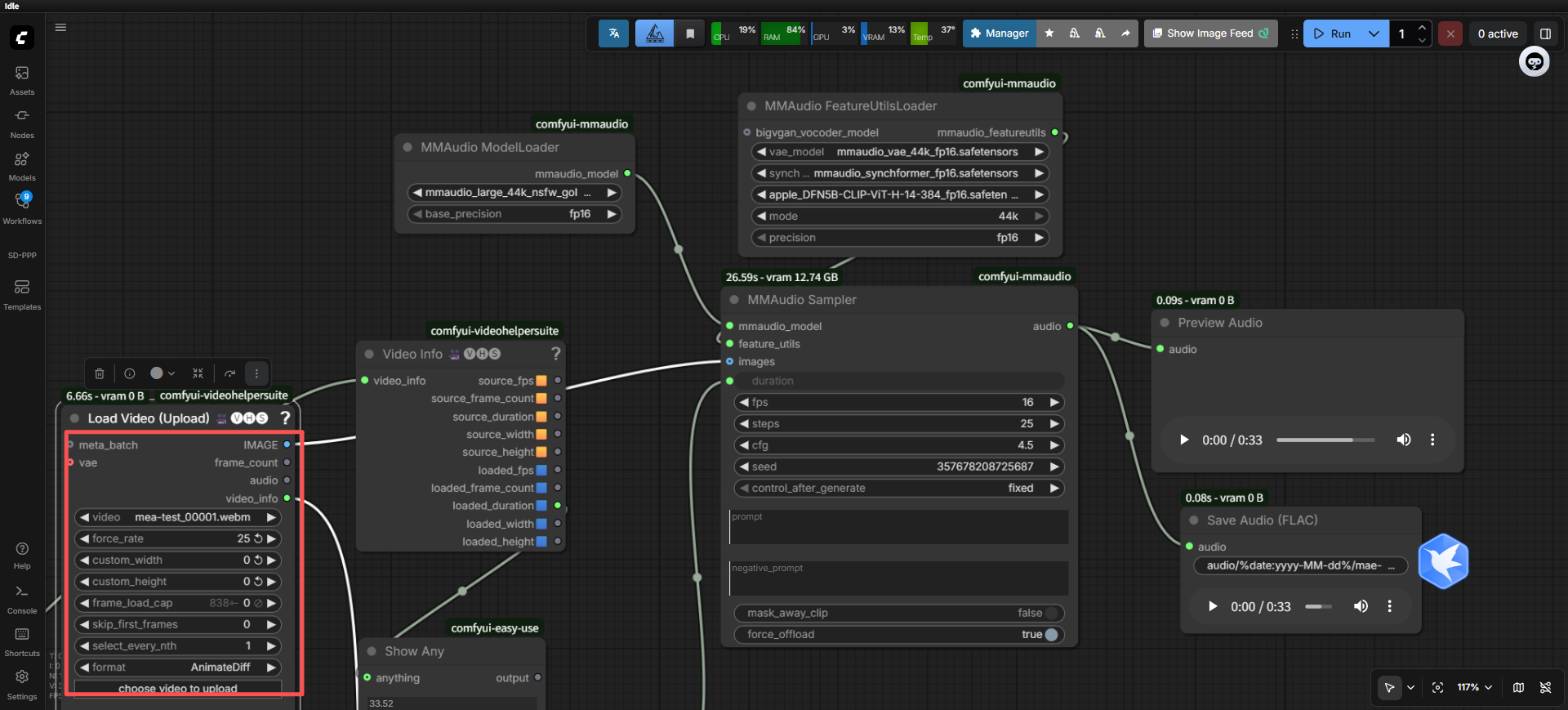 这里可以看到32帧变成25帧的图片数量比16的要少一张,本来没想通的,但是我突然想到,好像进行wan视频生成的时候,是要多给一张的哈哈
这里可以看到32帧变成25帧的图片数量比16的要少一张,本来没想通的,但是我突然想到,好像进行wan视频生成的时候,是要多给一张的哈哈
好像是推荐的规定,总帧数是16倍数+1(我是16帧5秒,但是总帧数给了81张)
所以从32降到25的时候,就会把这一张删掉了
用剪映试试,直接把三个音频贴上,分别听听区别(用的是同样的种子和提示词)
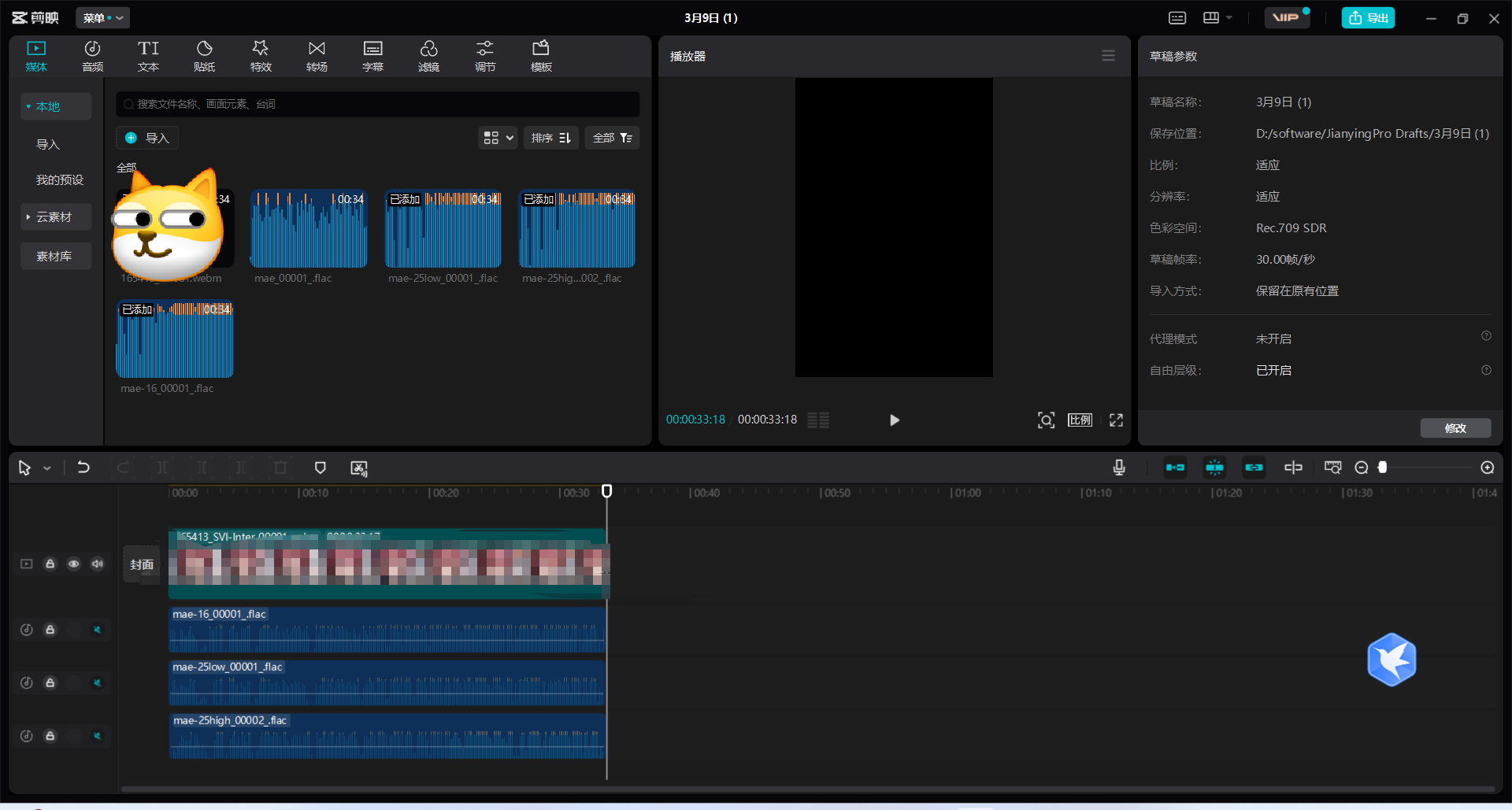
感觉效果差不多,不过还是感觉直接25帧视频的效果是最好的,因为原来的模型使用的就是25帧的训练数据