一、String底层存放的是字节数组还是字符数组?
结论:要看 JDK 版本
- JDK 8 及之前:
String底层是 字符数组char[] value。 - JDK 9 及之后:
String底层是 字节数组byte[] value,再配合一个编码标识字段coder。
1.JDK 7/8:String底层是 char\[\]
在 JDK 7/8 的java.lang.String源码里可以看到:
java
/** The value is used for character storage. */
private final char value[];这说明每个字符是一个 16 位的char(UTF-16 code unit),所以底层就是字符数组。
2.JDK 9+:String底层改成 byte\[\](Compact Strings紧凑字符串)
从 JDK9 开始,官方通过 JEP 254 把String的内部表示从:
UTF-16
char[]改成byte[] + 编码标志。
在新的String源码中可以看到:
java
@Stable
private final byte[] value;
private final byte coder;工作方式大致是:
- 如果字符串中的每个字符都能用 Latin-1(ISO-8859-1)表示,就 一个字节存一个字符。
- 否则使用 UTF-16,这时每个字符占两个字节(仍按 UTF-16 编码存到
byte[]里)。
coder字段就是用来标记当前使用的是哪种编码,HotSpot 和许多字符串相关 API 都会根据这个标志做相应处理。
3.怎么理解"字节数组还是字符数组"?
从语义层面看:
String始终代表"字符序列",对外 API 都是基于char、int codePoint、CharSequence等。- 底层实现:早期用
char[]直接存 UTF-16 码元;JDK 9 以后为了节省内存,改成用byte[]+编码标识,对用户透明。
所以,如果面试或考试问:
String 底层存放的是字节数组还是字符数组?
比较严谨的回答是:
- JDK 8 及之前:底层是字符数组
char[]。 - JDK 9 及之后:底层是字节数组
byte[],配合编码标记(Compact Strings,紧凑字符串)。
二、字符串常量池的位置
不同JDK版本下字符串常量池的位置:
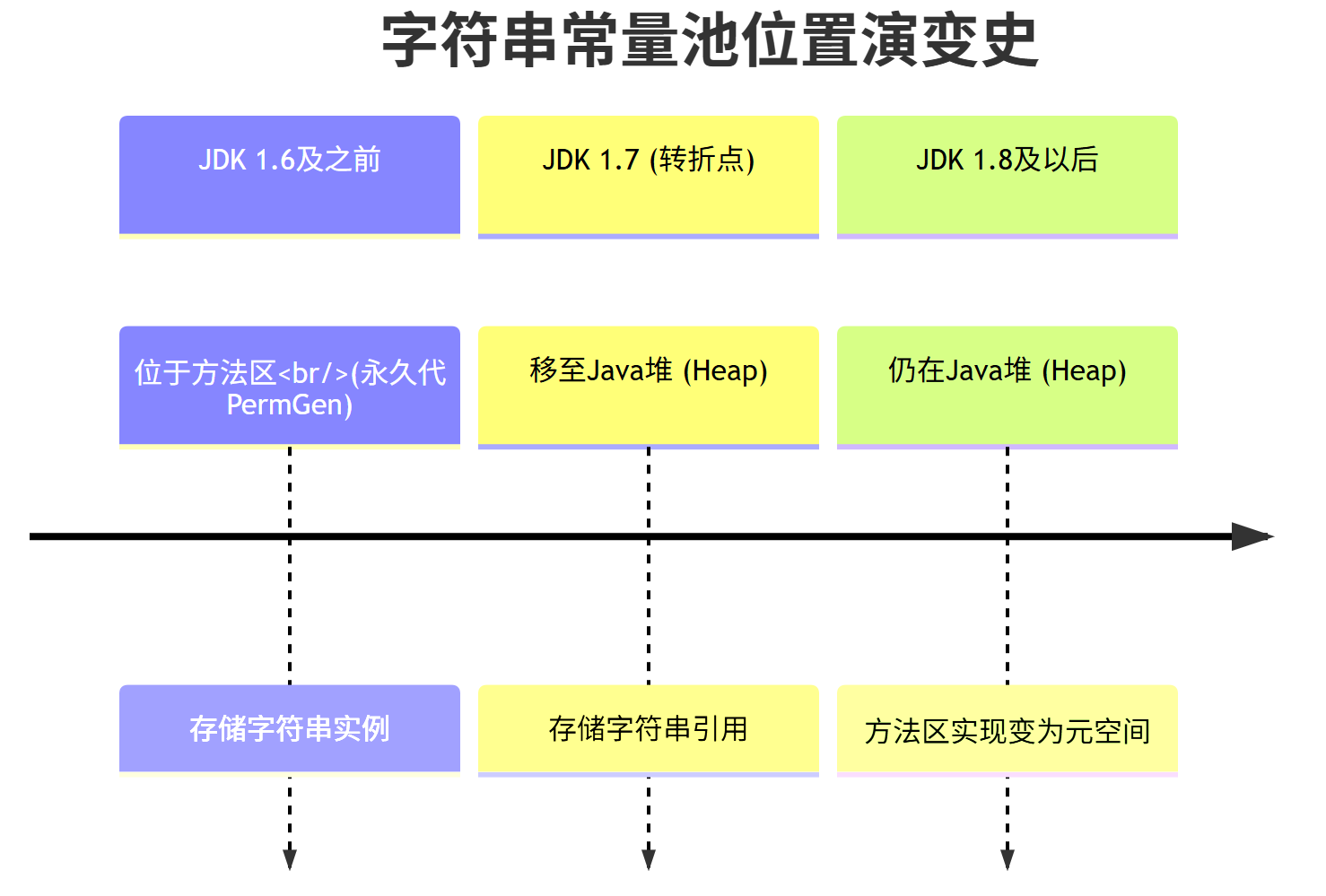
1.详细演变过程与原因
1.JDK 1.6及之前:永久代时期
在这个阶段,字符串常量池位于方法区,在 HotSpot(热点)虚拟机中的具体实现是永久代(PermGen)。
- 存储内容:池中存储的是字符串对象实例本身。
- 痛点 :永久代大小固定(通过
-XX:MaxPermSize设定),且垃圾回收频率极低(通常只在Full GC时回收)。而程序中字符串的创建和销毁非常频繁,极易导致java.lang.OutOfMemoryError: PermGen space错误。
2.JDK 7:关键转折点
从 JDK 7 开始,字符串常量池被移动到了 Java 堆(Heap)中。这是一个重要的优化。
- 存储内容变化:池中不再存储对象实例,而是存储字符串对象的引用。实际的字符串对象仍然在堆中分配。
- 移动原因:堆的空间更大,且垃圾回收(尤其是新生代)非常频繁。将字符串常量池移入堆中,可以极大提升无用字符串的回收效率,有效缓解了永久代溢出的问题。
3.JDK 8及以后:元空间时期
在 JDK 8 中,永久代被彻底废除,取而代之的是使用本地内存的元空间(Metaspace)。但字符串常量池的位置没有改变,仍然在 Java 堆中。
- 逻辑与物理的区分:这是一个容易混淆的地方。根据《Java虚拟机规范》,方法区是一个逻辑概念。在 JDK 8 中,字符串常量池在逻辑上属于方法区,但在物理实现上位于 Java 堆中。因此,"在堆中"和"在方法区"两种说法,它们从不同角度描述都是对的,这需要我们区分逻辑规范与具体实现。
2.核心结论与对比
| 特性 | JDK 1.6及之前 | JDK 7 | JDK 8 |
|---|---|---|---|
| 位置 | 方法区(永久代) | Java堆 | Java堆 |
| 存储内容 | 字符串对象实例 | 字符串对象的引用 | 字符串对象的引用 |
| 方法区实现 | 永久代(JVM内存) | 永久代(JVM内存) | 元空间(本地内存) |
| 主要优势 | - | 回收效率高,避免PermGen OOM | 堆空间更灵活,元空间不受JVM堆限制 |
❓延伸理解:运行时常量池 vs 字符串常量池
- 运行时常量池:是方法区的一部分。它用于存放编译期生成的各种字面量和符号引用。每个类加载后,都会有一个运行时常量池。
- 字符串常量池:是 JVM 专门为字符串优化提供的独立区域。它全局唯一,所有类共享。
在 JDK 1.6 及之前,字符串常量池是运行时常量池的一部分。从 JDK 7 开始,字符串常量池被独立出来并移到堆中,而运行时常量池仍然留在方法区(JDK 8 后是元空间)。
3.JDK字符串内存管理的核心设计
字符串常量池和字符串对象实例都位于 Java 堆中,但它们是堆中两个不同区域的概念。
JDK 7及以后版本中,一个字符串字面量如何被创建和引用的完整过程:

详细解读这个流程中的每一个环节。
🔍核心解答:实例在哪里?
根据多个权威资料,结论非常明确:
- 字符串常量池的位置:从 JDK 7 开始,字符串常量池被从方法区(永久代)移动到了 Java 堆中。
- 常量池中存储的内容:在 JDK 7 及之后,字符串常量池中存储的是字符串对象的引用,而不是对象实例本身。
- 字符串对象实例的位置 :真正的字符串对象实例(即
String对象,包含字符数组等数据)同样存储在 Java 堆中。
因此,可以这样理解:字符串常量池是堆中的一个"引用列表",它指向了堆中其他位置实际存在的字符串对象实例。
📊演进对比:JDK版本差异
| 特性 | JDK 1.6及之前 | JDK 7 | JDK 8及之后 |
|---|---|---|---|
| 字符串常量池位置 | 方法区(永久代) | Java堆 | Java堆 |
| 常量池存储内容 | 字符串对象实例 | 字符串对象的引用 | 字符串对象的引用 |
| 字符串对象实例位置 | 在常量池(永久代)中 | 在Java堆中 | 在Java堆中 |
| 方法区实现 | 永久代(PermGen) | 永久代 | 元空间(Metaspace) |
| intern()行为 | 若池中无,则复制对象实例到池中 | 若池中无,则将堆中对象的引用存入池中 | 与JDK 7相同 |
💡设计初衷:为何要移动?
将字符串常量池从永久代移至堆,并非简单的位置调整,而是为了解决根本性问题:
- 解决永久代溢出 :永久代大小固定(由
-XX:MaxPermSize设定),且垃圾回收效率极低。而程序中字符串极其常见,大量使用intern()或字面量容易导致java.lang.OutOfMemoryError: PermGen space。移至堆后,其大小仅受堆内存限制,极大降低了此风险。 - 提升垃圾回收效率:堆是垃圾回收的主要区域,拥有成熟的分代回收算法。将字符串常量池移至堆,使得池中引用的字符串对象可以被更高效地回收,优化了内存管理。
🧠深入理解:创建与引用过程
通过两种常见创建方式来彻底理解对象实例与引用的关系:
1.字面量方式创建
java
String s1 = "abc";
String s2 = "abc";执行流程如下:
- JVM 解析到字面量
"abc",首先检查字符串常量池。 - 若池中不存在
"abc"的引用,则在堆中创建一个字符串对象实例,其内容为"abc"。 - 将这个对象实例的引用存入字符串常量池。
- 将这个引用返回给变量
s1。 - 当创建
s2时,常量池中已存在"abc"的引用,因此直接将该引用返回给s2。 - 结果:
s1和s2指向堆中同一个字符串对象实例。
2.new关键字创建
java
String s3 = new String("abc");执行流程如下:
- JVM 同样会先检查常量池中是否有
"abc"的引用。如果没有,会按照上述流程在堆中创建一个对象实例,并将引用存入池中。 - 关键在于,
new关键字会在堆中单独创建一个新的、内容相同(this.value = original.value,和常量池对象共享同一份底层数组)的字符串对象实例。 - 将这个新对象实例的引用返回给变量
s3。 - 结果:
s3指向堆中一个新创建的对象实例,而常量池中的引用指向另一个实例。s1 == s3的结果为false。
✅总结
总而言之,在 JDK 7 及之后的版本中:
- 字符串常量池是 Java 堆中一个用于存储字符串对象引用的哈希表。
- 字符串对象实例同样是存储在 Java 堆中,它们被常量池中的引用所指向。
- 这种设计将容易导致内存溢出的常量池从空间受限的永久代解放出来,并利用了堆更高效的垃圾回收机制,是 JVM 内部优化的重要一环。
理解这个区别,对于排查内存溢出问题以及优化字符串使用(如合理使用intern()方法)至关重要。
4.面试题:创建了几个对象?
解释一下核心机制:编译器优化与常量池的写入规则。
核心机制:Class 文件常量池
Java 源代码经过编译生成.class文件时,编译器不仅会将代码翻译成字节码,还会在.class文件中生成一个常量池。这个常量池类似于一个"资源清单",里面记录了代码中用到的所有字面量和符号引用。
关键规则:
如果编译器判断某个字符串字面量只是中间产物(仅用于拼接),且后续代码中没有独立使用它,编译器会优化掉它,不会把它写入.class文件的常量池中。
面试题一
java
String a = "abc" + "bcd";- 编译期分析:编译器发现
"abc"和"bcd"是字面量拼接,直接计算出结果"abcbcd"。 - 写入常量池:编译器将最终结果
"abcbcd"写入.class文件常量池。 - 中间产物处理:由于
"abc"和"bcd"在代码其他地方没有被使用,编译器认为它们是临时变量,不写入常量池。 - 运行期:JVM 加载类时,只看到常量池里有
"abcbcd",于是只在堆中创建了 1 个对象。
结论:只创建 1 个对象。
面试题二
java
String s1 = "abcdef";
String s2 = "abcdef" + "xy";- 第一行
String s1 = "abcdef";:- 字面量
"abcdef"被写入.class常量池。 - 运行时创建对象
"abcdef"。
- 字面量
- 第二行
String s2 = "abcdef" + "xy";:- 编译期优化:编译器识别出这是两个常量的拼接,直接计算结果
"abcdefxy"。 - 写入常量池:编译器将最终结果
"abcdefxy"写入.class常量池。 - 中间产物处理:这里的
"abcdef"虽然在代码里出现了两次(第1行和第2行),但第2行中是作为拼接操作的一部分。关键点在于:因为第1行已经强制使用了"abcdef",所以常量池里一定会有。但是,"xy"作为拼接的中间部分,且代码中没有独立使用它,编译器不会将其写入常量池。
- 编译期优化:编译器识别出这是两个常量的拼接,直接计算结果
- 运行期:
- JVM 加载类,解析常量池。
- 创建对象
"abcdef"(对应 s1)。 - 创建对象
"abcdefxy"(对应 s2)。 - 不存在
"xy"对象。
结论:总共创建了 2 个对象。
面试题三
java
String b = "abc";
String a = b + "bcd";在这段代码中,内存中总共创建了 4 个对象。
详细解析过程
第 1 行 :String b = "abc";
- JVM 检查字符串常量池,发现没有
"abc"。 - 在字符串常量池中创建对象
"abc"。 - 变量
b指向池中的"abc"。
当前对象数:1 个(常量池中的"abc")
第 2 行 :String a = b + "bcd";
这里是问题的关键!因为b是一个变量(即使它的值没有变,但在编译器眼里它是变量),编译器无法在编译期确定最终的结果,因此无法进行常量折叠优化。
Java 会将其转换为StringBuilder进行处理。代码在底层执行逻辑等价于:
java
// 伪代码演示底层逻辑
StringBuilder temp = new StringBuilder(); // 创建对象2
temp.append(b); // 使用已有的"abc"
temp.append("bcd"); // 这里的"bcd"是常量,需要加载,对象3
String a = temp.toString(); // 创建对象4细究这一步创建的对象:
- 对象2:
"bcd"- 代码中出现了字面量
"bcd"。因为是运行时需要使用它,所以它会作为类常量池的一部分,在类加载或执行时被解析并创建在字符串常量池中。
- 代码中出现了字面量
- 对象3:
StringBuilder对象- 这是在堆中创建的一个普通对象,用于拼接字符串。
- 对象4:
String对象"abcbcd"StringBuilder调用toString()方法时,底层是调用new String(char value[], int offset, int count)。- 这个对象存放在堆中(注意:它不在字符串常量池中)。
- 变量
a指向这个堆中的对象。
总结与对比
总共 4 个对象,位置和类型如下:
| 序号 | 对象值 | 位置 | 说明 |
|---|---|---|---|
| 1 | "abc" |
字符串常量池 | 第1行代码创建 |
| 2 | "bcd" |
字符串常量池 | 第2行代码中的字面量 |
| 3 | StringBuilder实例 |
堆 | 用于拼接的中间工具对象 |
| 4 | "abcbcd" |
堆 | 最终拼接结果(toString产生),不在常量池 |
核心考点
- 常量折叠 vs 动态拼接:
"a" + "b"(常量+常量)-> 编译期优化 -> 结果在常量池。变量 + "b"(变量+常量)-> 运行时处理 -> 结果在堆。
StringBuilder.toString():- 通过
StringBuilder生成的 String 对象,默认是在堆内存中,不会自动放入常量池。
- 通过
- 字面量的加载:
- 只要代码里写了
"bcd",运行时需要用它,它就会在常量池里(不管是否被优化掉,取决于它是否参与运行)。在这个例子中,"bcd"是append的参数,必须存在,所以常量池里会有它。
- 只要代码里写了
new String() 和 StringBuilder.toString() 的实现原理
1.显式调用new String()
java
String a = new String("abcbcd");这会创建 2 个对象:
- 堆对象:
new关键字在堆上创建的对象。 - 常量池对象:构造函数
new String(String s)接收一个字符串参数。如果常量池里没有"abcbcd",JVM 会解析这个字面量并将其放入常量池(或者作为参数传入时已经确认常量池存在)。
2.StringBuilder.toString()的源码
java
String b = "abc";
String a = b + "bcd";编译器将其转换为StringBuilder,最后调用的是toString()方法。
请看 JDK 中StringBuilder.toString()的源码(JDK 8 及之后):
java
@Override
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}关键点来了:
这里调用的new String(value, 0, count)构造函数,并不是我们常用的new String(String str)构造函数。
它调用的是下面这个构造函数(接收一个char[]数组):
java
public String(char value[], int offset, int count) {
// ... 省略边界检查 ...
this.value = Arrays.copyOfRange(value, offset, offset+count);
}3.为什么不会在常量池创建对象?
这个构造函数的逻辑非常简单:
- 接收一个字符数组(
value)。 - 把这个数组复制一份,赋值给当前 String 对象的内部属性
this.value。
注意,在这个过程中:
- 它接收的参数是 字符数组,而不是 字符串字面量。
- 它的内部逻辑没有任何代码去检查或操作字符串常量池。
- 它仅仅是堆内存上的对象实例化。
因此,StringBuilder.toString()产生的"abcbcd"对象,纯粹是一个堆上的对象,它不会自动在常量池里创建对应的字符串。只有当你显式调用intern()方法时,它才会去常量池排队。
总结对比
| 场景 | 代码示例 | 涉及常量池吗? | 创建对象数 |
|---|---|---|---|
| 显式 new String(字面量) | new String("xyz") |
是。构造函数需要解析字面量"xyz"。 | 2个(堆 + 池) |
| StringBuilder.toString() | new StringBuilder().append("x")...toString() |
否。底层调用new String(char[], ...) |
1个(仅堆) |
所以:
在String a = b + "bcd";这一步中,StringBuilder生成的"abcbcd"只创建了 1 个对象(位于堆,不在常量池)。
加上前面的"abc"、"bcd"和StringBuilder实例,总共 4 个对象。
对这两方法的底层原理进行学习,这正是区分"语法糖"和"底层实现"的关键所在!