目录
- [1 背景:为什么我要用 AI 做内容和产品](#1 背景:为什么我要用 AI 做内容和产品)
- [2 从工程思维到产品思维](#2 从工程思维到产品思维)
- [3 我现在的解决方案:AI 内容生产 Pipeline](#3 我现在的解决方案:AI 内容生产 Pipeline)
-
- [3.1 总览](#3.1 总览)
- [3.2 分步骤讲](#3.2 分步骤讲)
-
- [3.2.1 选题(决定80%的效果)](#3.2.1 选题(决定80%的效果))
- [3.2.2 信息收集(保证内容"有依据"且可持续)](#3.2.2 信息收集(保证内容“有依据”且可持续))
- [3.2.3 AI筛选(从"有信息"到"值得做的内容")](#3.2.3 AI筛选(从“有信息”到“值得做的内容”))
- [3.2.4 内容生成(从素材到"可消费内容")](#3.2.4 内容生成(从素材到“可消费内容”))
- [3.2.5 多模态生成(放大内容形态)](#3.2.5 多模态生成(放大内容形态))
- [3.2.6 发布(进入真实用户环境)](#3.2.6 发布(进入真实用户环境))
- [3.2.7 数据反馈(判断内容是否有效)](#3.2.7 数据反馈(判断内容是否有效))
- [3.2.8 再优化(形成闭环)](#3.2.8 再优化(形成闭环))
- [3.3 案例:英语单词视频的AI生产Pipeline拆解](#3.3 案例:英语单词视频的AI生产Pipeline拆解)
-
- [3.3.1 英语单词视频Pipeline(记忆类内容)](#3.3.1 英语单词视频Pipeline(记忆类内容))
- [4 我踩过的坑](#4 我踩过的坑)
-
- [4.1 AI 输出"看起来对,但其实没价值"](#4.1 AI 输出“看起来对,但其实没价值”)
- [4.2. 内容同质化严重](#4.2. 内容同质化严重)
- [4.3 没有闭环(数据反馈)](#4.3 没有闭环(数据反馈))
- [5 我的方法论总结](#5 我的方法论总结)
-
- [5.1 AI 是放大器,不是替代者](#5.1 AI 是放大器,不是替代者)
- [5.2 产品的核心仍然是需求](#5.2 产品的核心仍然是需求)
- [5.3 工作流比工具更重要](#5.3 工作流比工具更重要)
- [5.4 快速试错,比完美更重要](#5.4 快速试错,比完美更重要)
- [6 未来方向](#6 未来方向)
-
- [6.1 进一步自动化(但不过度追求"全自动")](#6.1 进一步自动化(但不过度追求“全自动”))
- [6.2. 从"内容"走向"产品化"](#6.2. 从“内容”走向“产品化”)
- [6.3 找到可持续的商业价值](#6.3 找到可持续的商业价值)
- [6.4 从"使用 AI"到"理解 AI 的边界"](#6.4 从“使用 AI”到“理解 AI 的边界”)
1 背景:为什么我要用 AI 做内容和产品
一开始接触 AI,其实没有想太多,动机很简单:
- AI 能力越来越强
- 会用 AI,明显可以提升效率和竞争力
在做内容和一些小产品的过程中,我很快就感受到一个很直观的变化:
👉 同样一件事情,用不用 AI,效率差别非常明显。
- 做一个简单功能,从几天缩短到几个小时
- 理解一篇最新的学术论文,从1小时缩短到10分钟
所以一开始,我用 AI 的方式其实很"粗暴":
👉 哪里能用,就用哪里。
- 做总结用 AI
- 想点子用 AI
- 写代码用 AI
- 甚至很多原本需要手动完成的事情,也尽量交给 AI
当时我的思路其实很典型的"工程思维":
- 能不能更快?
- 能不能更自动化?
- 能不能把更多事情交给 AI?
再往后,我开始做一些更"激进"的尝试:
- 用 AI 做完整的内容生产流程
- 搭一些"看起来很强"的功能
- 把多个模型串起来,做成一个完整系统
当时我有一个很强的感觉:
👉 只要把 AI 用好,很多问题好像都可以被解决。
但很快,我就遇到了一个问题:
👉 这些东西确实能做出来,但并没有人真正会用。
甚至更直接一点说:
👉 我做出来的很多东西,并没有解决用户真正的问题。
2 从工程思维到产品思维
在上一阶段,我其实做了不少"看起来很强"的东西:
- 可以自动生成内容的系统
- 把多个模型串起来的完整流程
- 一些自动化程度很高的小工具
从技术角度来看,这些东西都没有太大问题,甚至还挺"酷"。
但问题也很明显:
👉 做出来之后,几乎没有人真正会用。
一开始我其实有点困惑:
- 是不是我做得还不够好?
- 是不是模型还不够强?
- 是不是流程还不够自动化?
所以我下意识的反应是:
👉 继续优化技术。
- 调 prompt
- 换模型
- 提升效果
- 增加功能
但做了一段时间之后,我慢慢意识到一个问题:
👉 问题可能根本不在"做得好不好",而在"做的东西对不对"。
回头看,我当时的思路其实是非常典型的"工程思维":
- 关注的是功能能不能实现
- 关注的是系统是不是完整
- 关注的是技术是不是先进
但很少去问一个更基础的问题:
👉 用户到底需不需要这个东西?
后来我开始刻意去观察一些"用得多的内容"和"没人看的内容",慢慢发现一个很明显的差异:
- 用户不会为"技术先进"买单
- 用户也不关心你用了什么模型
- 用户只关心一件事:
👉 这个东西,能不能解决我的问题?
这其实让我想起《The 7 Habits Of Highly Effective People》里提到的一个习惯:
👉 Begin with the End in Mind(以终为始)
我之前做很多 AI 项目,其实是"从手段出发"的:
- 我能用 AI 做什么?
- 我能把哪些东西自动化?
但更合理的顺序应该是:
- 用户的问题是什么?(End)
- 现在是怎么解决的?
- 我能不能用 AI 把这个过程变得更简单/更高效?
从那之后,我在做任何一个 AI 项目之前,都会先问自己几个问题:
- 用户是谁?
- 他现在最大的痛点是什么?
- 他现在是怎么解决这个问题的?
- 我做的这个东西,能不能让他更省时间/更省钱/更简单?
如果这些问题没有想清楚,我基本不会再往下做。
对我来说,这算是一个比较关键的转变:
👉 从"我能做什么",变成"用户需要什么"。
也正是基于这个转变,我后面才慢慢沉淀出一套更稳定的内容生产方式,而不是一味地堆功能、堆模型。
接下来,我会具体讲一下我现在是怎么用 AI 搭建一套内容生产 Pipeline 的。
3 我现在的解决方案:AI 内容生产 Pipeline
3.1 总览
在经历了前面"只追求功能实现"的阶段之后,我逐渐意识到:
👉 真正有价值的不是某一个 AI 能力,而是一套可以稳定产出内容的流程。
所以我开始把整个内容生产过程拆解,并用 AI 去重构,最终形成了一套相对稳定的 Pipeline。
👉 整体流程如下:
选题 → 信息收集 → AI筛选 → 内容生成 → 多模态生成(图/语音) → 发布 → 数据反馈 → 再优化
每一步在解决什么问题?
3.2 分步骤讲
3.2.1 选题(决定80%的效果)
做什么内容,本质上决定了有没有人看。
在做英语视频时,我一开始也是从"兴趣出发",但很快发现,仅仅做自己觉得有意思的内容,很难获得稳定反馈。
后来我逐渐把选题拆成两个层面:
👉 赛道选择(做哪一类内容)
👉 具体选题(这一条视频讲什么)
目前我主要在做两类英语内容:
1)帮助记忆单词的视频
-
本质是在解决:用户**"记不住单词"的问题**
-
选题会围绕:雅思考试/高频实用词等
-
有场景的表达(比如职场/日常)
2)名人名句类视频
-
本质是在解决:用户**"想学地道表达 + 智慧情感感染"的需求**
-
选题会围绕:
-
有情绪共鸣的句子
-
简短有力、容易传播的表达
-
有人物背景加持的内容
在具体选题上,我会结合三类信息来源:
- 用户真实需求(比如:记不住单词 / 不会表达)
- 内容传播属性(是否有共鸣/是否容易分享)
- AI扩展能力(同一个主题生成多个角度)
👉 AI 在这一环节主要做两件事:
- 扩展选题:比如围绕一个单词,生成不同记忆方式或表达场景
- 优化表达:把一个普通句子,改写成更有传播力的内容
这一步我最大的变化是:
👉 从=="做我觉得有用的内容"==
👉 到=="做用户更容易理解和传播的内容"==
3.2.2 信息收集(保证内容"有依据"且可持续)
在确定选题之后,下一步就是信息收集。
这一步的目标很明确:
👉 让内容"有来源、有质量",同时可以长期稳定获取素材
在实际操作中,我主要通过两种方式来获取数据:
1️⃣ 结构化数据来源(GitHub / API)
主要用于获取"可批量处理"的内容,比如:
- 单词库
- 名人名言数据集
- 开源语料数据
这些数据通常来自:
- GitHub 开源项目
- 公共 API
- 一些词典或语料库接口
👉 优点是:
- 可规模化(适合批量生产内容)
- 结构清晰(方便后续 AI 处理)
2️⃣ 非结构化内容(文本 / 图片 / 视频)
主要用于补充"表达效果"和"语境信息",例如:
- 单词或句子的真实使用场景
- 名人名句的背景故事
- 情绪衬托的视频素材(用于增强表达)
- 人物肖像 / 相关图片(用于视觉呈现)
👉 这部分我通常结合 AI 来处理:
- 快速总结信息
- 提取关键信息
- 降低阅读和整理成本
这一层解决的问题是:
👉 从"原始素材" → 到"可用于内容生产的数据输入"
同时也是整个 AI 内容生产 Pipeline 的"数据基础层"。
3.2.3 AI筛选(从"有信息"到"值得做的内容")
在信息收集之后,并不是所有内容都适合直接进入生产环节。
这时候就需要一个非常关键的步骤:
👉 AI筛选
很多人在做内容时,往往会忽略这一层,直接用 AI 生成内容,结果就是:
- 内容"看起来对",但没人看
- 信息很多,但没有传播力
- 做了很多,但没有反馈
本质原因是:
👉 缺少"内容价值判断"这一层
👉 我是怎么用 AI 做筛选的?
我会让 AI 做三件事情:
1️⃣ 判断:这个内容是否值得做?
核心问题是:
👉 有没有用户需求?有没有传播潜力?
👉 AI 可以帮助我:
- 从大量素材中筛选出"更有价值"的部分
- 给出优先级排序
2️⃣ 判断:是否有"表达空间"?
不是所有内容都适合做视频。
我会让 AI 判断:
👉 这个内容是否可以被"讲清楚 + 讲有趣"
例如:
- 是否可以讲成一个小故事?
- 是否可以用对比/反常识表达?
- 是否可以引发共鸣?
如果不能"被讲出来",就不进入下一步
👉 在不同内容类型中的筛选重点
在健康内容中(核心筛选场景):
我会重点让 AI 判断:
-
这个问题是否是"用户真实在关心的健康问题"?
(比如:脱发、睡眠、疲劳、减肥、血糖等)
-
是否具有"感知明显"的特征?
(用户能否在日常生活中感受到,例如:经常困、掉头发、睡不好)
-
是否存在"认知偏差"或"误区"?
(例如:很多人以为对,但其实不一定对)
-
是否有"行动价值"?
(用户看完之后,是否可以做出一些调整)
👉 这一类内容更容易产生:
- 点击(因为和自己有关)
- 停留(因为想知道答案)
- 转发(因为适合分享给家人)
在英语单词视频中(轻筛选):
- 是否是高频单词?
- 是否容易被记错或用错?
- 是否可以用简单方法记住?
👉 本质是提高学习效率,而不是做复杂筛选
👉 在 Pipeline 中的作用
这一层的作用可以理解为:
信息 →(AI筛选)→ 内容素材
3.2.4 内容生成(从素材到"可消费内容")
在通过 AI 筛选出"值得做的内容"之后,才进入内容生成阶段。
这一层的核心不是"让 AI 写",而是:
👉 让 AI 按结构、按目标去生成内容
在实际操作中,我会通过 Prompt 约束 AI:
- 内容结构(开头吸引 + 中间解释 + 结尾总结)
- 表达风格(口语化 / 易理解 / 有画面感)
- 目标导向(是否有记忆点 / 是否有传播性)
例如:
- 健康内容 → 强调"误区 + 解释 + 建议"
- 英语内容 → 强调"简单 + 好记 + 可复用"
👉 本质是:
从"信息" → 转换成"用户愿意看/愿意听的内容"
3.2.5 多模态生成(放大内容形态)
有了文本之后,我会进一步做多模态扩展:
- 图像(封面 / 插图)
- 语音(TTS)
- 简单视频(字幕 + 背景素材)
👉 AI 在这里的作用是:
- 降低制作成本
- 提高生产效率
- 支持多平台分发
👉 本质是:
一份内容 → 多种表达形式
3.2.6 发布(进入真实用户环境)
内容生产完成之后,才真正进入"市场验证"阶段。
发布时我会关注:
- 标题是否有吸引力
- 封面是否清晰表达主题
- 是否符合平台风格
👉 这一层的关键不是"发出去",而是:
让用户愿意点开
3.2.7 数据反馈(判断内容是否有效)
发布之后,我会重点关注几个核心指标:
- 点击率(选题是否有效)
- 完读率/播放完成率(内容是否有吸引力)
- 转发/收藏(是否有价值)
👉 这一层的意义在于:
用数据判断:内容到底有没有解决用户问题
3.2.8 再优化(形成闭环)
基于数据反馈,我会反向调整:
- 哪些选题更受欢迎
- 哪种表达方式更有效
- 哪类内容更容易传播
👉 最终形成一个循环:
本质是:
让内容生产从"拍脑袋",变成"有反馈驱动的系统"
在实际探索过程中,我并不只做单一方向的内容。
我也在尝试用 AI 做多个赛道的内容和产品,包括:
- 健康类内容(视频号 + 公众号)
- 英语学习类内容(单词记忆 / 表达)
- 基于模型的股票分析等工具探索
👉 本质上,这些方向看起来不同,但底层逻辑是类似的:
都是围绕==「选题 → 数据 → AI生成 → 多模态 → 发布 → 反馈」==这一套流程在做。
由于时间和篇幅有限,下面我会选择「英语单词视频」这一条线,作为一个完整案例进行拆解。
👉 一方面,这个场景结构更简单,便于说明
👉 另一方面,其中的方法论,同样可以复用到健康内容、以及其他AI应用中
3.3 案例:英语单词视频的AI生产Pipeline拆解
下面我以英语单词视频为例,完整拆解这套Pipeline是如何落地的。
3.3.1 英语单词视频Pipeline(记忆类内容)
在实际做英语单词视频时,整体流程虽然和前面的通用 Pipeline 一致,但我会进一步抽象为四个核心问题:
1️⃣ 解决什么用户问题?
本质是:用户为什么要看这个视频
👉 用户记不住单词、不会用、容易混淆
2️⃣ 如何持续稳定获取素材?
👉 是否有可规模化的数据来源(单词库 / 语料 / API)
3️⃣ 如何用 AI 生成"更容易记住"的内容?
👉 不只是生成解释,而是生成"有记忆点"的表达方式
4️⃣ 如何让整个流程可复用甚至自动化?
👉 从单条内容生产,变成批量化内容生成
从这个角度来看,英语单词视频的核心并不是"教单词",而是:
👉 用更低成本,持续生产"更容易被记住"的内容
在做英语单词类视频时,一个非常现实的问题是:
👉 素材从哪里来?能不能持续获取?
如果只是手动找单词,很快就会遇到两个问题:
- 不可持续(很耗时间)
- 难以规模化(无法批量生产)
因此,我在这一层的目标是:
👉 构建一个"稳定 + 可扩展"的单词数据来源
在具体实现上,我主要采用两种方式:
- 开源数据(GitHub / 词库)
- 本地可调用的语言库
最终我选择使用 (Natural Language Toolkit)来获取基础词汇数据。
👉 为什么选择 NLTK?
- 内置常用英文词库(无需额外维护数据)
- 调用简单,适合快速集成
- 可以作为"基础词汇池",支持后续筛选和加工
具体获取如下:
python
import json
from wordfreq import top_n_list, zipf_frequency
from nltk.corpus import wordnet as wn
import nltk
import os
# ===== 初始化 =====
nltk.download("wordnet")
nltk.download("omw-1.4")
# ===== 参数=====
TOP_N_FREQ = 12000 # 高频词规模(太大会引入抽象词)
MIN_ZIPF = 2 # 低于这个频率的词直接不要
MAX_WORD_LEN = 16 # 太长的一般不可视觉化
# ===== 1️⃣ 高频词=====
high_freq_words = set(top_n_list("en", TOP_N_FREQ))
def is_high_quality_visual_word(word: str) -> bool:
# 基础过滤
if not word.isalpha():
return False
if len(word) < 3 or len(word) > MAX_WORD_LEN:
return False
# 频率过滤(避免冷门、书面、学术词)
if zipf_frequency(word, "en") < MIN_ZIPF:
print(f"过滤低频词: {word}")
return False
# WordNet 校验
synsets = wn.synsets(word)
if not synsets:
return False
return True
# ===== 2️⃣ 精选 WordNet =====
visual_words = set()
for syn in wn.all_synsets():
for lemma in syn.lemmas():
word = lemma.name().lower().replace("_", " ")
# 不要短语
if " " in word:
continue
# 只保留高质量词
if is_high_quality_visual_word(word):
visual_words.add(word)
# ===== 3️⃣ 与高频词交集=====
final_words = sorted(visual_words & high_freq_words)
print(f"最终高质量视觉词数量: {len(final_words)}")
# ===== 4️⃣ 保存 =====
output_path = "words.json"
#获取当前脚本目录
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
output_path = os.path.join(BASE_DIR, f"data/{output_path}")
with open(output_path, "w", encoding="utf-8") as f:
json.dump(final_words, f, ensure_ascii=False, indent=2)
print(f"已保存高质量词库到: {output_path}")如何生成一个"更容易记住"的单词视频(内容生成)
在解决了数据来源问题之后,下一步就是:
👉 如何把一个"单词",转化成一个"用户更容易记住的视频内容"
这一步,也是大模型真正发挥价值的地方。
从内容结构来看,一个完整的单词视频通常包含三类信息:
- 文本信息(解释 + 记忆点)
- 图片信息(视觉辅助理解)
- 语音信息(发音 + 听觉强化)
👉 本质是通过多模态,让用户"多通道记忆"。
👉 为什么需要多模态?
如果只是给出:
- 单词 + 释义
👉 用户很难记住
但如果同时提供:
- 场景化解释(文本)
- 相关画面(图像)
- 标准发音(语音)
👉 会明显提升记忆效果
👉 在我的实现中,主要分三步:
1️⃣ 文本生成(核心)
通过大模型生成:
- 简单解释(通俗易懂)
- 使用场景(帮助理解)
- 记忆方法(联想 / 对比 / 拆解)
👉 重点不是"解释",而是:
👉 让用户更容易记住
在模型选择上,目前市场上已经有很多可用的大模型,例如:
- OpenAI GPT 系列
- Google Gemini 系列
- 阿里 Qwen 系列
- DeepSeek 系列
👉 模型选择思路
在实际使用中,我主要考虑三个因素:
1️⃣ 生成质量(是否自然、易理解)
2️⃣ 成本(是否支持批量生产)
3️⃣ 稳定性(接口是否稳定)
基于以上考虑,我目前主要使用的是 DeepSeek 模型。
👉 原因是:
- 性价比较高(适合高频调用)
- 中文和中英混合能力较好
- 在结构化生成任务中表现稳定
👉 对于内容生产来说,本质是:
不是追求"最强模型",而是"最适合当前场景的模型"
核心调用模型的代码如下:
python
client = OpenAI(
api_key=api_key,
base_url="https://api.deepseek.com",
timeout=120,
max_retries=3
)
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=[{"role": "user", "content": prompt}]
)
content = response.choices[0].message.content.strip()
data = safe_parse_json(content)重点在prompt的设计,根据自己的任务目标决定产出什么内容输出,一般是json格式数据输出:
python
{
"visual_text": {
...
},
"memory_hook": {
...
},
"scene_prompt": ...,
"voiceover_script": [{
...
}
],
}这一层的核心不是"调用模型",而是:
👉 通过设计合适的 Prompt,让模型输出"更适合传播和记忆的内容"
这也是我从"用AI写内容",转向"用AI设计内容结构"的一个关键转变。
2️⃣ 图片生成(让内容"看得见")
在完成文本生成之后,下一步就是将抽象的内容转化为"可视化信息"。
👉 通过图像,让用户更容易理解和记住内容
在单词视频中,我通常会生成两类图片:
- 场景图(帮助理解语境)
- 联想图(强化记忆)
👉 本质是:
👉 让抽象信息变得具体
实现方式
在具体实现上,我会复用前面文本生成阶段的结果,让大模型生成对应的图像 Prompt,然后再调用图像模型生成图片。
整体流程如下:
单词 → 文本生成(DeepSeek)→ 图像Prompt → 图像模型 → 图片
👉 图像模型选择
在图像生成阶段,我会使用类似 Nano Banana Pro 或者Stability.ai 这样的图像大模型。
👉 Prompt设计(这一点非常关键)
相比模型本身,图像质量更依赖 Prompt 的设计。
我在实践中的一个经验是:
👉 Prompt 越具体,生成的图片越稳定、细节越丰富
例如,不推荐:
a man learning english
而更推荐:
a young man studying English in a cozy room, books on the desk, warm lighting, focused expression, realistic style
👉 在实际使用中,我会让文本模型(DeepSeek)直接生成:
场景描述
画面细节
情绪氛围
然后再传给图像模型生成图片。
基于Abyss这个单词,图像生成prompt如下:
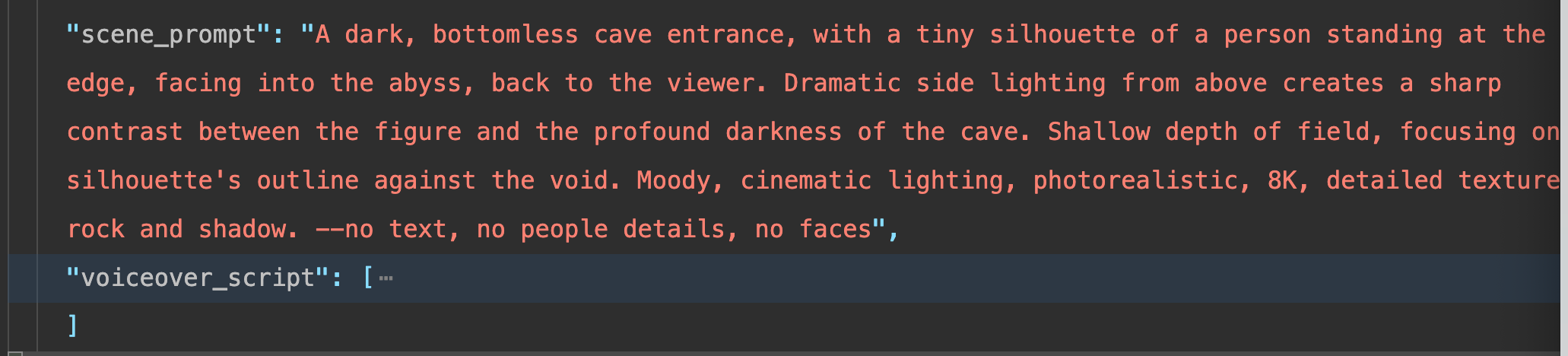
👉 这一类模型的优势是:
生成速度快
成本相对可控
能满足内容生产的基本质量需求
调用nano banna pro生成图片的代码如下:
python
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=roter_key,
)
response = client.chat.completions.create(
model="google/gemini-3-pro-image-preview",
messages=[
{
"role": "user",
"content": f'{prompt}'
}
],
extra_body={
"modalities": ["image", "text"],
}
)
message = response.choices[0].message
if hasattr(message, "images") and message.images:
for idx, image in enumerate(message.images):
data_url = image["image_url"]["url"]
# 1️⃣ 拆分 data:image/png;base64,...
header, base64_data = data_url.split(",", 1)
# 2️⃣ Base64 解码
image_bytes = base64.b64decode(base64_data)
# 3️⃣ 保存为文件
with open(save_path, "wb") as f:
f.write(image_bytes)
print(f"✅ 图片已保存:{save_path}")
else:
print("❌ 没有生成图片")在这里是用OpenRouter,生成图片如下:

生成效果整体还是很不错的,尤其是在细节表现上,已经接近真实场景。具体视频如下:
abyss
这里也顺带提一下我在使用的 nano banana pro 模型,在图像生成的稳定性和细节丰富度上表现都比较突出。
下面是我实际测试生成的一些图片,包含不同风格和场景,抽取了几张供大家参考👇
可爱😊的puppy

下雨天睡觉的小猫咪😁

这张是描述李白的经典诗
《静夜思》
床前明月光,
疑是地上霜。
举头望明月,
低头思故乡。

看繁星享受安静的👩🏻

给人宁静温馨的道路早晨阳光

冰川上的一个湖泊

镜头聚焦场景下的小男孩看向道路远方在等妈妈

生成的图片整体细节还是很不错的,而且有一个很明显的体感:
👉 效果好不好,很大程度取决于 Prompt
同一个模型,不同的描述方式,生成出来的画面风格和细节差异会非常明显。
==补充:OpenRouter(多模型统一调用方案) ==
在实际使用过程中,如果同时接入多个大模型(如 GPT、DeepSeek、Claude、Gemini),会遇到一个问题:
👉 不同模型有不同的 API、调用方式和计费体系
这时候,可以使用 OpenRouter 来做统一管理。
什么是 OpenRouter?
OpenRouter 是一个"模型聚合平台",可以理解为:
👉 用一个统一的接口,调用多个大模型
👉 把"模型选择"变成一个可配置的能力,而不是写死在代码里
3️⃣ 语音生成(强化输入与记忆)
在完成文本和图像之后,最后一步是将内容转化为语音。
- 标准发音(保证准确性)
- 可重复播放(方便用户强化记忆)
👉 为什么语音很重要?
在英语学习场景中,仅靠"看"是不够的:
- 只看文本 → 容易理解但难记住
- 加入语音 → 可以形成"听觉记忆"
本质是:
👉 增加一个记忆通道,让用户从"理解"变成"熟悉"
👉 实现方式
这一层通常比较简单,可以直接调用现有的 TTS 模型或接口:
文本 → TTS模型 → 语音文件
实现代码如下:
python
client = OpenAI(
base_url="https://api.gptsapi.net/v1",
api_key=wildcard_key
)
response = client.audio.speech.create(
model="tts-1",
voice=voice,
speed=speed,
instructions=instructions,
response_format="mp3",
input=text,
timeout=120
)
with open("temp.wav", "wb") as f:
f.write(response.read())
print(f"✅ TTS 完成,已保存到 {output_path}")通过WildCard进行模型选择和调用,其中WildCar降低使用门槛(不用折腾海外卡), 支持更多 AI 工具,对个人开发者比较友好, 支持的模型具体如下:
 👉 小结
👉 小结
这一层的核心不是"把内容做出来",而是:
👉 用多模态方式,提升用户记住信息的概率
也是我从"做功能"转向"做效果"的一个重要变化。
3️⃣ 视频生成(让内容"真正可消费")
在完成文本、图片和语音生成之后,最后一步就是:
👉 将这些信息组合成一个完整的视频内容
这一步,本质上是一个"多模态内容组装"的过程。
👉 输入结构
在这一阶段,我们已经有了三类内容:
- 文本(字幕 / 核心表达)
- 图片(场景图 / 联想图)
- 语音(讲解 / 发音)
👉 生成流程
整体流程可以抽象为:
文本 + 图片 + 语音 → 时间轴编排 → 视频合成 → 输出视频
👉 实际效果
上面这套流程不是Demo,而是我目前在真实使用的一套内容生产系统,
已经在持续生成英语学习视频。
如果你想看"AI生成内容实际长什么样",可以扫码关注我的视频号👇
里面都是这套流程跑出来的真实结果。也欢迎交流一起优化这套内容生产流程。

4 我踩过的坑
在这段时间用 AI 做内容和产品的过程中,其实踩了不少坑,有些甚至是反复踩。
这里总结几个我觉得比较典型的:
4.1 AI 输出"看起来对,但其实没价值"
一开始我很容易被 AI 的输出"骗到"。
很多内容:
- 逻辑是通顺的
- 表达是流畅的
- 甚至看起来还挺"专业"
但仔细一看会发现:
👉 没有信息增量
👉 没有观点
👉 对用户没有实际帮助
本质上只是"把正确的废话说得更顺"。
后来我会更刻意去判断一件事:
👉 这段内容,用户看完之后,有没有获得新的东西?
如果没有,那写得再好也没有意义。
4.2. 内容同质化严重
当我开始大量使用 AI 生成内容之后,很快遇到一个问题:
👉 内容开始变得"越来越像"。
原因其实很简单:
- 大模型的训练数据是相似的
- prompt 写法也在收敛
- 很多选题本身就是热点复用
结果就是:
👉 很容易做出"看起来还行,但不出彩"的内容。
后来我做的调整是:
- 尽量加入自己的理解和取舍
- 控制 AI 生成的比例(不是100%依赖)
- 在选题和结构上做差异,而不是只改措辞
4.3 没有闭环(数据反馈)
这是我觉得最关键的一个坑。
一开始我更多关注的是:
- 内容有没有生成出来
- 功能有没有跑通
但忽略了一点:
👉 用户是否真的在用?效果怎么样?
如果没有数据反馈,其实很容易陷入:
- 自己觉得不错
- 但实际没有任何结果
后来我开始更关注:
- 点击率
- 完播率
- 用户反馈
并且会把这些数据反向用来:
👉 调整选题、优化 prompt、改内容结构
这时候,整个流程才算真正"跑起来"。
5 我的方法论总结
回头看这一段时间的尝试,我自己总结了几条比较重要的原则:
5.1 AI 是放大器,不是替代者
AI 确实可以大幅提升效率,但它放大的不仅是能力,也会放大问题。
- 方向对 → 放大收益
- 方向错 → 放大浪费
👉 AI 不会帮你做判断,它只会放大你的判断。
5.2 产品的核心仍然是需求
无论技术怎么变化,这一点其实没有变:
👉 用户不会为"技术先进"买单,只会为"问题被解决"买单。
很多时候:
- 功能做得再复杂
- 模型用得再好
如果没有解决实际问题,最终也很难被接受。
5.3 工作流比工具更重要
一开始我也比较关注:
- 用哪个模型
- 哪个工具效果更好
但后来发现:
👉 决定效率上限的,其实是工作流,而不是单个工具。
- 有没有清晰的流程
- 各个环节是否可复用
- 是否可以持续优化
这些比"用哪个模型"更重要。
5.4 快速试错,比完美更重要
在 AI 的加持下,试错成本其实已经很低了。
相比于:
- 一开始就设计一个"很完美"的方案
我现在更倾向于:
👉 先跑起来,再不断优化。
- 先验证有没有人看
- 再优化内容质量
- 再考虑规模化
6 未来方向
接下来,我自己大概会往几个方向继续探索:
6.1 进一步自动化(但不过度追求"全自动")
之前我比较倾向于做"全自动系统",
但现在更偏向于:
👉 半自动 + 人在关键节点参与
- AI 负责效率
- 人负责判断
在效率和质量之间做一个平衡。
6.2. 从"内容"走向"产品化"
目前做的很多事情,本质还是内容驱动。
后面会更关注:
👉 这些内容,是否可以进一步沉淀为可复用的产品形态?
比如:
- 工具类产品
- 系列化的内容(自媒体)
- 独立 App
6.3 找到可持续的商业价值
单纯做内容其实比较容易,但要长期做下去,一定要有商业闭环。
后面我会更关注:
- 哪些方向有付费意愿
- 哪些内容可以转化
- 如何从"流量"走向"价值"
6.4 从"使用 AI"到"理解 AI 的边界"
一开始更多是"怎么用 AI",
但后面我会更关注:
👉 AI 能做什么,不能做什么。
- 哪些适合交给 AI
- 哪些必须人来做
- 如何设计更合理的人机协作方式
对我来说,这一阶段更像是一个开始。
AI 确实带来了很多新的可能性,但真正有价值的,还是:
👉 在这些能力之上,你选择解决什么问题。