文章目录
- 知识回顾
- [Deepseek V3/R1核心技术](#Deepseek V3/R1核心技术)
-
- [1. 混合专家模型(Mixture of Experts, MoE)](#1. 混合专家模型(Mixture of Experts, MoE))
- [2. 多头潜在注意力(Multi-Head Latent Attention, MLA)](#2. 多头潜在注意力(Multi-Head Latent Attention, MLA))
- [3. 多 Token 预测(Multi-Token Prediction, MTP)](#3. 多 Token 预测(Multi-Token Prediction, MTP))
- 注意力残差
-
- [1. 背景:从残差连接(ResNet)说起](#1. 背景:从残差连接(ResNet)说起)
- [2. 字节 HC / DeepSeek mHC](#2. 字节 HC / DeepSeek mHC)
- [3. Kimi 注意力残差](#3. Kimi 注意力残差)
- [4. 总结](#4. 总结)
知识回顾
首先回顾下之前的知识:
【白话神经网络(一)】从函数到神经网络
【白话神经网络(二)】从CNN、RNN到Transformer
神经网络

- 前向传播:数据在神经网络中从输入到输出的计算过程,是模型预测的核心步骤。前向传播:输入 → 隐藏层 → 输出 → 损失
- 激活函数 : 激活函数
g(wx+b)是一个非线性函数,作用在神经元的线性输出上。它的主要作用是引入非线性变换,使神经网络能够拟合复杂的非线性关系。常见的激活函数:
| 函数 | 公式 | 特点 |
|---|---|---|
| Sigmoid | f ( x ) = 1 1 + e − x f(x) = \frac{1}{1 + e^{-x}} f(x)=1+e−x1 | 输出范围 (0,1),易饱和,易导致梯度消失 |
| Tanh | f ( x ) = e x − e − x e x + e − x f(x) = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}} f(x)=ex+e−xex−e−x | 输出范围 (-1,1),零中心化,但仍存在饱和问题 |
| ReLU | f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x) | 计算简单,缓解梯度消失,但可能导致神经元死亡 |
| Leaky ReLU | f ( x ) = max ( α x , x ) , α = 0.01 f(x) = \max(\alpha x, x),\ \alpha = 0.01 f(x)=max(αx,x), α=0.01 | 解决神经元死亡问题 |
| Swish | f ( x ) = x ⋅ sigmoid ( x ) f(x) = x \cdot \text{sigmoid}(x) f(x)=x⋅sigmoid(x) | 平滑,效果常优于 ReLU |
| Softmax | f ( z i ) = e z i ∑ j e z j f(z_i) = \frac{e^{z_i}}{\sum_j e^{z_j}} f(zi)=∑jezjezi | 用于多分类输出层,输出为概率分布 |
- 损失函数 :损失函数(Loss Function)用于衡量模型预测值与真实值之间的差距。训练神经网络的目标就是最小化这个差距,从而让模型的预测尽可能准确。常见的损失函数:
| 损失函数 | 公式 | 适用场景 | 特点 |
|---|---|---|---|
| 均方误差 (MSE) | L = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 L = \frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2 L=n1∑i=1n(yi−y^i)2 | 回归 | 对异常值敏感,梯度随误差增大而增大 |
| 平均绝对误差 (MAE) | L = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ L = \frac{1}{n}\sum_{i=1}^{n}|y_i - \hat{y}_i| L=n1∑i=1n∣yi−y^i∣ | 回归 | 对异常值鲁棒,在零点不可导 |
| 二元交叉熵 (BCE) | L = − 1 n ∑ i = 1 n y i log y \^ i + ( 1 − y i ) log ( 1 − y \^ i ) L = -\frac{1}{n}\sum_{i=1}^{n}y_i\\log\\hat{y}_i + (1-y_i)\\log(1-\\hat{y}_i) L=−n1∑i=1nyilogy\^i+(1−yi)log(1−y\^i) | 二分类 | 输出为概率,配合 Sigmoid 使用 |
| 多分类交叉熵 (CCE) | L = − 1 n ∑ i = 1 n ∑ c = 1 C y i c log y ^ i c L = -\frac{1}{n}\sum_{i=1}^{n}\sum_{c=1}^{C}y_{ic}\log\hat{y}_{ic} L=−n1∑i=1n∑c=1Cyiclogy^ic | 多分类 | 输出为概率分布,配合 Softmax 使用 |
| Hinge Loss | L = 1 n ∑ i = 1 n max ( 0 , 1 − y i y ^ i ) L = \frac{1}{n}\sum_{i=1}^{n}\max(0, 1 - y_i\hat{y}_i) L=n1∑i=1nmax(0,1−yiy^i) | SVM 分类 | 用于最大间隔分类, y i ∈ { − 1 , 1 } y_i \in \{-1,1\} yi∈{−1,1} |
| KL 散度 | L = ∑ i y i log y i y ^ i L = \sum_{i} y_i \log\frac{y_i}{\hat{y}_i} L=∑iyilogy^iyi | 概率分布拟合 | 衡量两个分布的差异,非对称 |
-
梯度 :在求损失函数最小值的过程中,每次调整一点w或b数值,使得损失函数会变化多少,这其实就是损失函数对w或b的偏导数,这些偏导数构成的向量叫做梯度。我们要做的就是不断往偏导数的反方向去变化,具体变化的快慢,用一个系数来控制,叫做学习率。
- 梯度下降:损失函数通常是一个高度非线性的复杂函数,无法直接求解最小值,因此我们采用迭代优化方法:调整w或b数值,让损失函数逐渐减小,最终得到w和b值的过程,就叫做梯度下降。梯度下降法通过反复计算梯度并沿其反方向调整参数,使损失函数逐渐下降。梯度指明了方向,学习率决定了步幅。在损失函数是凸函数的情况下,梯度下降保证能收敛到全局最小值。对于非凸的深度神经网络,梯度下降通常能找到"足够好"的局部最小值(或鞍点附近),这也是深度学习在实践中能够成功的原因之一。
-
链式法则 :链式法则(Chain Rule)是微积分中求复合函数导数的基本法则,也是深度网络中梯度传播的数学基础。
若 y = f ( u ) y = f(u) y=f(u) 且 u = g ( x ) u = g(x) u=g(x),则 y y y 对 x x x 的导数为:
d y d x = d y d u ⋅ d u d x \frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx} dxdy=dudy⋅dxdu
推广到多层复合函数 y = f n ( f n − 1 ( ... f 1 ( x ) ... ) ) y = f_n(f_{n-1}(\dots f_1(x)\dots)) y=fn(fn−1(...f1(x)...)),其导数为各层导数的乘积:
d y d x = d f n d f n − 1 ⋅ d f n − 1 d f n − 2 ⋯ d f 1 d x \frac{dy}{dx} = \frac{df_n}{df_{n-1}} \cdot \frac{df_{n-1}}{df_{n-2}} \cdots \frac{df_1}{dx} dxdy=dfn−1dfn⋅dfn−2dfn−1⋯dxdf1
- 反向传播 :利用链式法则,从输出层向输入层逐层计算损失函数对所有参数的梯度的算法,提供优化方向(告诉参数怎么变) 。 反向传播过程主要包含以下步骤:
- 前向传播计算损失 L L L。
- 从输出层开始,计算损失对各层输出的梯度 ∂ L ∂ 各层输出 \frac{\partial L}{\partial \text{各层输出}} ∂各层输出∂L。
- 通过链式法则反向传播误差,得到各层参数的梯度 ∂ L ∂ W ( l ) \frac{\partial L}{\partial W^{(l)}} ∂W(l)∂L 和 ∂ L ∂ b ( l ) \frac{\partial L}{\partial b^{(l)}} ∂b(l)∂L。
链式法则中多层导数的连乘导致训练中的问题:
- 若每层导数绝对值都小于 1,乘积会指数级缩小 → 梯度消失(浅层参数几乎不更新)-> 模型难以学习到浅层特征,训练停滞。
- 若每层导数绝对值都大于 1,乘积会指数级增大 → 梯度爆炸(参数更新剧烈,训练不稳定)-> 损失震荡或发散,无法收敛
常见缓解方法:
- 使用 ReLU 类激活函数
- 合理的权重初始化(如 He 初始化)
- 批归一化(Batch Normalization)
- 梯度裁剪(Gradient Clipping)
- 残差连接(Residual Connection)
Transformer
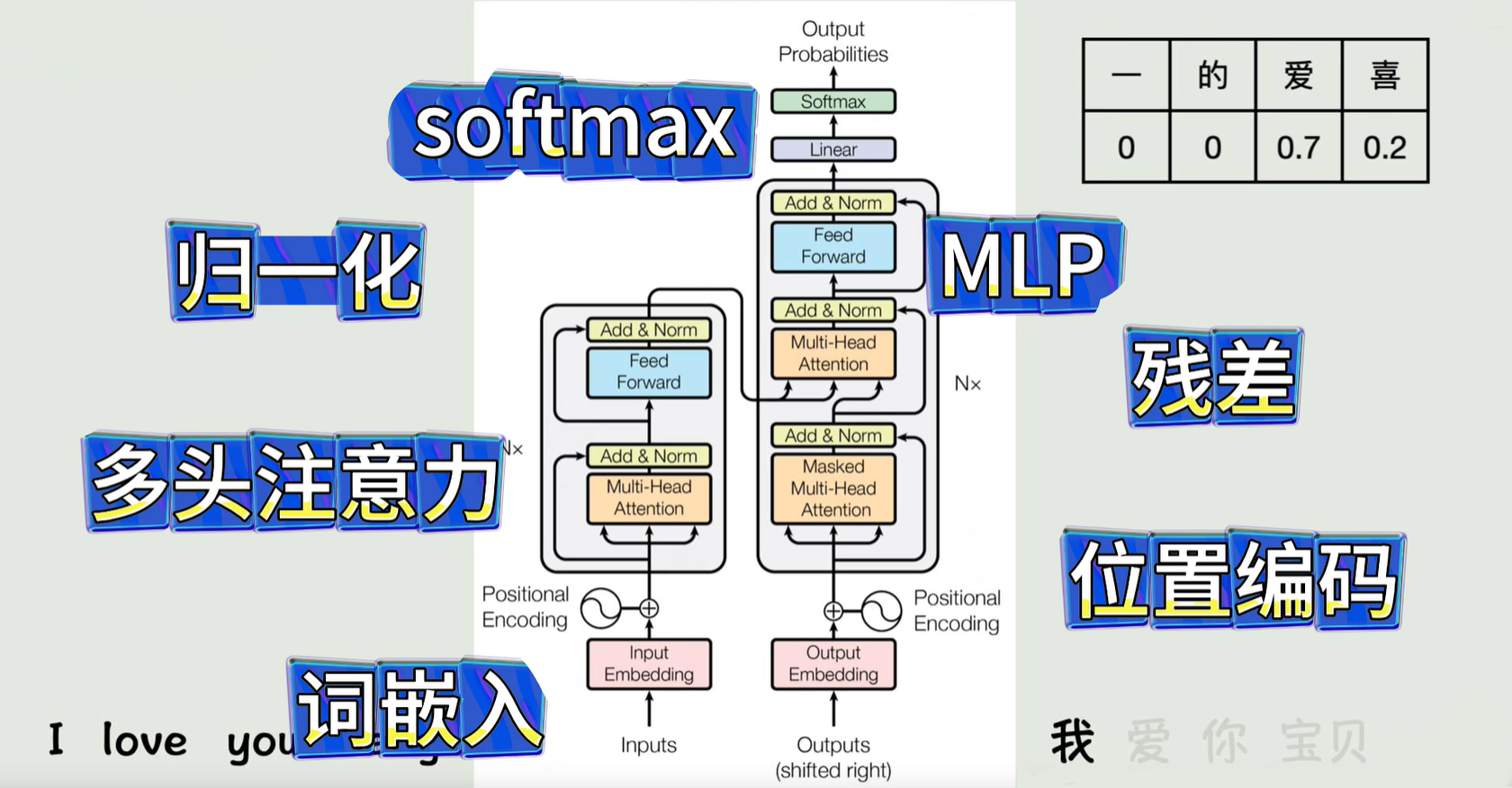
- Embedding: 词嵌入,将文本转成词向量矩阵。最终得到的词嵌入矩阵是一个大小为(词汇量,嵌入维度)的二维数组矩阵。词嵌入矩阵中的向量是通过Word2Vec、GloVe和FastText等训练词嵌入模型生成的。
- Positional Encoding:位置编码,将向量加上位置信息,因为 Transformer 本身没有顺序概念。位置嵌入矩阵也是一个大小为(词汇量,嵌入维度)参数矩阵,通过训练过程优化或固定数学函数生成。词嵌入向量表示词语的语义信息,而位置嵌入向量表示词语在序列中的位置信息。通过将两者相加,最终的输入向量同时包含了词语的语义和位置信息。
- Multi-Headed Self-Attention:多头自注意力机制,通过QKV算出词与词关联度关系,给每个词向量增加了上下文信息 。在self-attention中,每个单词有3个不同的向量,它们分别是Query向量( Q),Key向量( K)和Value向量( V),长度一致,它们是通过词位置嵌入向量X 乘以3个不同的权值矩阵WQ、WK、WV得到,最终基于多头注意力公式得到多头注意力向量。多头指的是使用多个不同的权值矩阵W 获取多组QKV结果后再组成一组向量。核心公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V MultiHead ( Q , K , V ) = Concat ( head 1 , ... , head h ) W O head i = Attention ( Q W i Q , K W i K , V W i V ) \begin{aligned} \text{Attention}(Q, K, V) &= \text{softmax}\left( \frac{Q K^T}{\sqrt{d_k}} \right) V \\ \text{MultiHead}(Q, K, V) &= \text{Concat}(\text{head}_1, \dots, \text{head}_h) W^O \\ \text{head}_i &= \text{Attention}(Q W_i^Q, K W_i^K, V W_i^V) \\ \end{aligned} Attention(Q,K,V)MultiHead(Q,K,V)headi=softmax(dk QKT)V=Concat(head1,...,headh)WO=Attention(QWiQ,KWiK,VWiV)
比喻理解:想象你在一个图书馆(输入序列)找书:Query:是你脑子里的需求("我想找关于机器学习的书")。Key:是书架上的标签("计算机"、"文学"、"历史")。Value:是书本身的内容。只有 Query 和 Key 匹配上了(点积计算相似度),我们才会把对应的 Value(书的内容)取出来作为输出。 - Add & Norm:残差链接和层归一化 。这两个动作关乎的是训练过程,是为了让反向传播梯度下降,去寻找上面那一堆参数最优解的过程,更稳定。残差连接就是将多头向量与QKV操作前的原始向量直接相加 ,获得一个新的512维的向量,至少原始数据信息还在:Add=x+Sublayer(x)。层归一化有归一化公式可以操作,主要用于解决深度神经网络训练中的梯度不稳定、收敛速度慢等问题,其实都是重复的做简单的数学题。
- Feed-Forward Network:前馈神经网络 。前面步骤要不直接线性变换,要么就是直接的相加,将向量送入前馈神经网络,可以更精细化处理。首先连接到一个拥有更多神经元的全连接层,比如将512升为到2048维对应的权重矩阵,同时应用激活函数引入非线性,也就是以更高级的方式处理数据了。接下来再加一层,将2048维降回512继续的使用。此时的数据已经被重新精细处理过,同样是为了反向传播梯度下降,训练过程更稳定。总结来说,前馈神经网络通过其多层结构和非线性变换能力,能够有效地处理各种任务,帮助模型学习到有用的特征,并提高模型的性能。以下是将 Transformer 编码器层的完整定义:
输入: X ∈ R n × d model 1. 多头注意力 (Multi-Head Attention) head i = Attention ( X W i Q , X W i K , X W i V ) , i = 1 , ... , h Attention ( Q , K , V ) = softmax ( Q K ⊤ d k ) V 其中 W i Q , W i K ∈ R d model × d k , W i V ∈ R d model × d v , d k = d v = d model / h MultiHead ( X ) = Concat ( head 1 , ... , head h ) W O , W O ∈ R h d v × d model 2. 第一个 Add & Norm (残差 + 层归一化) X attn = LayerNorm ( X + MultiHead ( X ) ) 3. 前馈网络 (MLP) FFN ( x ) = Activation ( x W 1 + b 1 ) W 2 + b 2 其中 W 1 ∈ R d model × d ff , b 1 ∈ R d ff , W 2 ∈ R d ff × d model , b 2 ∈ R d model Activation 通常为 ReLU ( z ) = max ( 0 , z ) 或 GELU ( z ) d ff 常取 4 × d model 4. 第二个 Add & Norm Output = LayerNorm ( X attn + FFN ( X attn ) ) \begin{aligned} &\textbf{输入: } X \in \mathbb{R}^{n \times d_{\text{model}}} \\ &\\ &\text{1. 多头注意力 (Multi-Head Attention)} \\ &\quad \text{head}i = \text{Attention}\big(X W_i^Q,\; X W_i^K,\; X W_i^V\big), \quad i=1,\dots,h \\2pt &\quad \text{Attention}(Q,K,V) = \text{softmax}\!\left(\frac{Q K^\top}{\sqrt{d_k}}\right) V \\2pt &\quad \text{其中 } W_i^Q,W_i^K \in \mathbb{R}^{d{\text{model}} \times d_k},\; W_i^V \in \mathbb{R}^{d_{\text{model}} \times d_v},\; d_k = d_v = d_{\text{model}}/h \\2pt &\quad \text{MultiHead}(X) = \text{Concat}(\text{head}1,\dots,\text{head}h) \, W^O,\quad W^O \in \mathbb{R}^{h d_v \times d{\text{model}}} \\4pt &\text{2. 第一个 Add \& Norm (残差 + 层归一化)} \\ &\quad X{\text{attn}} = \text{LayerNorm}\big(X + \text{MultiHead}(X)\big) \\4pt &\text{3. 前馈网络 (MLP)} \\ &\quad \text{FFN}(x) = \text{Activation}(x W_1 + b_1) \, W_2 + b_2 \\2pt &\quad \text{其中 } W_1 \in \mathbb{R}^{d_{\text{model}} \times d_{\text{ff}}},\; b_1 \in \mathbb{R}^{d_{\text{ff}}},\; W_2 \in \mathbb{R}^{d_{\text{ff}} \times d_{\text{model}}},\; b_2 \in \mathbb{R}^{d_{\text{model}}} \\2pt &\quad \text{Activation 通常为 } \text{ReLU}(z)=\max(0,z) \text{ 或 } \text{GELU}(z) \\2pt &\quad d_{\text{ff}} \text{ 常取 } 4 \times d_{\text{model}} \\4pt &\text{4. 第二个 Add \& Norm} \\ &\quad \text{Output} = \text{LayerNorm}\big(X_{\text{attn}} + \text{FFN}(X_{\text{attn}})\big) \end{aligned} 输入: X∈Rn×dmodel1. 多头注意力 (Multi-Head Attention)headi=Attention(XWiQ,XWiK,XWiV),i=1,...,hAttention(Q,K,V)=softmax(dk QK⊤)V其中 WiQ,WiK∈Rdmodel×dk,WiV∈Rdmodel×dv,dk=dv=dmodel/hMultiHead(X)=Concat(head1,...,headh)WO,WO∈Rhdv×dmodel2. 第一个 Add & Norm (残差 + 层归一化)Xattn=LayerNorm(X+MultiHead(X))3. 前馈网络 (MLP)FFN(x)=Activation(xW1+b1)W2+b2其中 W1∈Rdmodel×dff,b1∈Rdff,W2∈Rdff×dmodel,b2∈RdmodelActivation 通常为 ReLU(z)=max(0,z) 或 GELU(z)dff 常取 4×dmodel4. 第二个 Add & NormOutput=LayerNorm(Xattn+FFN(Xattn))
MLP 指的是 多层感知机(Multi-Layer Perceptron),更准确地说是 前馈网络(Feed-Forward Network, FFN) 部分。它在每个编码器和解码器层中,紧跟在多头注意力(Multi-Head Attention)和 Add & Norm 之后。前馈网络(FFN)的公式说明:- 第一层将维度从 d model d_{\text{model}} dmodel 扩展到 d ff d_{\text{ff}} dff(通常是 4 倍,如 512 → 2048 512 \to 2048 512→2048)
- 激活函数最早使用 ReLU,后来也常用 GELU、Swish 等
- 第二层将维度从 d ff d_{\text{ff}} dff 压缩回 d model d_{\text{model}} dmodel
- Masked Multi-Headed Self-Attention:掩码多头自注意力机制。解码器掩掉句子后面的信息,与编码器整个输出交互, 不断预测训练,寻找整个模型的最佳参数组合,逼近人类语言。比如翻译训练过程,左边输入"我爱学习", 右边对应输入"I like learning",但是我们希望右边的句子是一个个基于前一个词推理输出的。因此右侧的过程是先"Shifed Target Sequence",送入时多加了一个词:"start I like learning",然后一样的处理:词嵌入、位置编码加入位置信息,进入掩码多头注意力操作,会将"start"后面的全遮盖住,数学上是将遮盖部分设为一个很大的负数,这样通过soflermax函数就直接忽略掉了后面这些信息。
Transformer算法相较于传统神经网络算法(如RNN、CNN等)具有以下显著优势:
-
并行计算能力
Transformer通过自注意力机制(Self-Attention)能够并行处理序列中的所有单词,而传统RNN需要逐个处理序列,导致计算速度较慢。这种并行性使得Transformer在训练和推理速度上具有显著优势。
-
处理长距离依赖关系
Transformer能够有效捕捉序列中单词之间的长距离依赖关系,而传统RNN在处理长序列时容易出现梯度消失或梯度爆炸问题,导致对长距离依赖的建模能力较弱。
-
模块化架构
Transformer由编码器(Encoder)和解码器(Decoder)组成,每个部分包含多个相同的模块(Block),这种模块化设计使得模型结构清晰且易于扩展。
-
全局特征提取能力
Transformer通过自注意力机制能够关注序列中的全局信息,而传统CNN主要关注局部特征。这种全局特征提取能力使得Transformer在自然语言处理等任务中表现更优。
-
与CNN结合的潜力
Transformer可以与CNN结合,如苹果的FastViT架构,将CNN的局部特征提取能力与Transformer的全局特征提取能力相结合,实现性能和准确率的平衡。
-
硬件加速支持
Transformer架构可以通过硬件加速(如NeuroBoost 9000)进一步优化性能,支持更大规模的模型和更复杂的任务。
Deepseek V3/R1核心技术
| 技术 | 核心作用 | 主要收益 |
|---|---|---|
| MoE | 稀疏激活专家 | 扩大模型容量,控制计算成本 |
| MLA | KV 缓存压缩 | 降低推理显存,支持超长上下文 |
| MTP | 多位置联合预测 | 提升训练效率与模型性能 |
详见 DeepSeek专题
1. 混合专家模型(Mixture of Experts, MoE)
核心思想:将模型中的前馈网络(FFN)替换为多个"专家",每次推理只激活其中一小部分专家,而非全部。
特点:
- 稀疏激活:虽然模型总参数量很大(如数千亿),但每个 token 只激活少数专家(如 8 个中的 2 个),实际计算量远小于总参数量。
- 动态路由:通过一个可学习的门控网络,为每个 token 动态选择最合适的专家。
- 优势:在保持推理成本可控的前提下,极大扩展了模型容量,使模型能够学习更丰富、更专业的知识。
DeepSeek 的改进:采用细粒度专家划分和负载均衡策略,避免专家"闲置"或"过载",提升了 MoE 的训练稳定性和专家利用效率。
2. 多头潜在注意力(Multi-Head Latent Attention, MLA)
核心思想:对标准的注意力机制进行压缩优化,通过低秩分解将键值(Key-Value, KV)缓存压缩为潜在向量,大幅降低推理时的内存占用。
特点:
- KV 压缩:传统 Transformer 在推理时需要缓存所有历史 token 的 Key 和 Value,随着序列长度线性增长,内存开销巨大。MLA 通过低秩投影将 KV 压缩成更紧凑的潜在表示。
- 推理加速:显著减少了 KV 缓存大小,使长上下文推理(如 128K tokens)在显存受限的设备上成为可能。
- 性能保持:压缩过程经过精心设计,在压缩率高达数倍的情况下,模型性能几乎无损。
优势:使 DeepSeek 能够以极低的推理成本支持超长上下文,同时保持高效的生成速度。
3. 多 Token 预测(Multi-Token Prediction, MTP)
核心思想:在训练时,让模型不仅预测下一个 token,还同时预测后续多个位置的 token(如同时预测第 t+1、t+2、t+3 个 token)。
特点:
- 训练目标扩展:传统语言模型只优化下一个 token 的预测损失,MTP 将多个未来位置的损失加权求和作为训练目标。
- 更强的监督信号:迫使模型学习更长距离的依赖关系和更全局的语义结构。
- 推理不变:推理时仍然采用标准的自回归生成(逐个 token 预测),不增加推理开销。
优势:实验表明,MTP 能够提升模型的样本效率和最终性能,尤其在代码生成、数学推理等需要长程规划的任务上效果明显。
注意力残差
1. 背景:从残差连接(ResNet)说起
传统残差连接(Residual Connection)自 2015 年 ResNet 提出以来,公式一直是:
x l + 1 = x l + F ( x l ) x_{l+1} = x_l + \mathcal{F}(x_l) xl+1=xl+F(xl)
即每一层的输出都按固定权重 1 累加到主干道上。这个设计在大模型时代暴露了两个严重副作用 :
- 信息稀释:随着层数加深,浅层特征被后续几十层的信息层层冲淡。用开会来类比------每个发言人说完都不关麦,后面的人只能把嗓门越提越高,才能盖过前面的背景噪音。
- 隐藏状态爆炸:深层网络为了维持影响力,被迫输出越来越大的激活值,导致数值不稳定、梯度分布不均。
2. 字节 HC / DeepSeek mHC
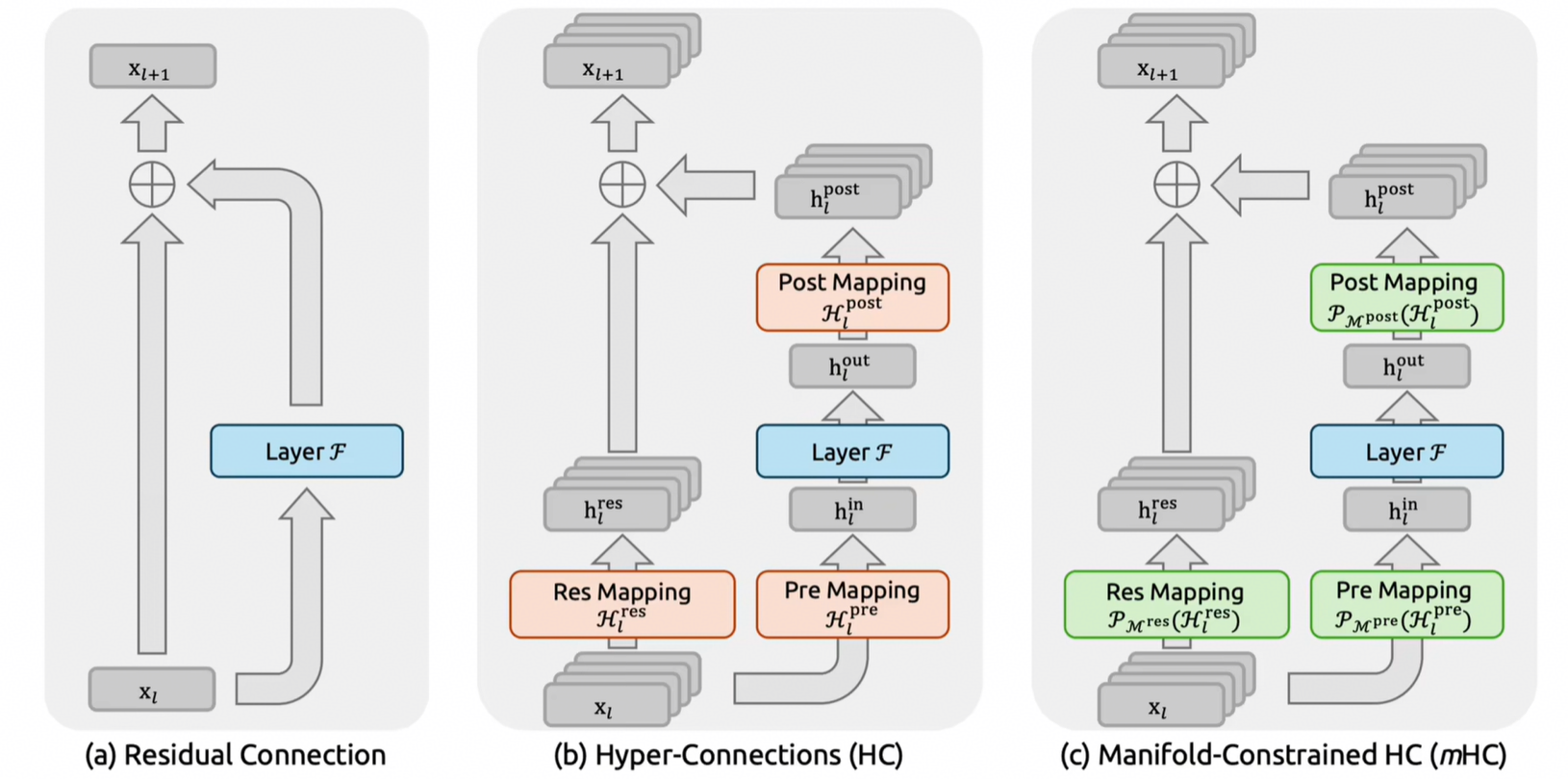
2024年9月,字节 Seed 团队提出 Hyper-Connections(HC),做了两件事:
- 宽度扩展:将单路残差扩展为多路并行通道(如扩展到4倍)
- 可学习连接 :引入可学习的权重矩阵 H l res \mathcal{H}_l^{\text{res}} Hlres,让模型自己学习如何混合不同通道的信息
公式表达:
x l + 1 = H l res x l + H l post ⊤ F ( H l pre x l ) \mathbf{x}_{l+1} = \mathcal{H}_l^{\text{res}} \mathbf{x}_l + {\mathcal{H}_l^{\text{post}}}^\top \mathcal{F}(\mathcal{H}_l^{\text{pre}} \mathbf{x}_l) xl+1=Hlresxl+Hlpost⊤F(Hlprexl)
- 优势:在不增加核心计算量(FLOPs)的前提下,显著提升模型表达能力。
- 问题 :HC 破坏了残差连接的"恒等映射"特性。当跨越多层时,复合映射 ∏ H res \prod \mathcal{H}^{\text{res}} ∏Hres可能失控------在270亿参数模型训练中,信号在第60层被放大约 3000倍,导致训练崩溃。
2026年1月1日,DeepSeek发布论文提出 mHC (梁文锋署名),核心创新是将 HC 中无约束的矩阵 H l res \mathcal{H}_l^{\text{res}} Hlres 约束在双随机矩阵流形上。
双随机矩阵的条件:所有元素非负; 每行之和 = 1; 每列之和 = 1
这意味着 H res \mathcal{H}^{\text{res}} Hres的作用是重新分配已有信息,而不是放大或衰减信号。
3. Kimi 注意力残差
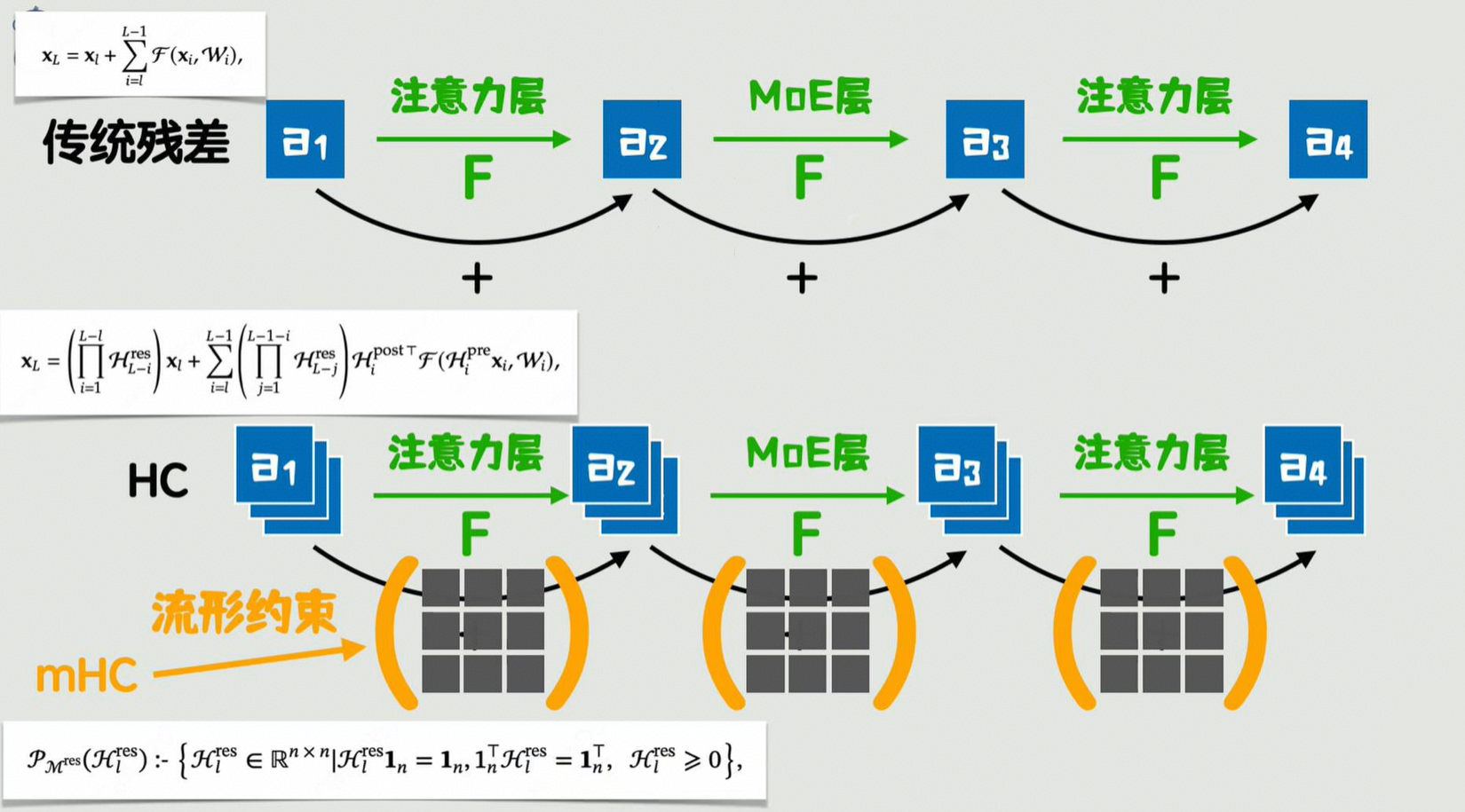
前面的理论介绍我们可以简单这样理解:
标准残差,就是每层经过一个函数变换时先把之前的值加过来,导致的问题就是太死板了。a1的信息传递到a4的时候,可能已经扭曲的不成样子了。
所以字节的HC提出了个方案,就是拓宽通道数。简单说就是把a1复制多份,同时往后也不再是单纯的加过去,而是乘上一个可学习的矩阵,这样信息的传递就有更多机会被保留下来。那这个学习矩阵如果不加任何的约束,那么连乘起来可能就又失控了,又产生了梯度爆炸的风险。
所以deepseek的MHC就对这些学习矩阵加了流行约束,简单说就是让这些学习矩阵不论怎么乘,都在一个可控的范围内。实际上不是个新的残差方案,而是对hc的一种改良。
但是从更宏观的视角看,其实不论怎么优化,这几个方法都是把残差流从左到右一层一层的加过去。之前不论是RNN还是LSTM,让每个词都包含上下文信息的办法,就是这样从头到尾的不断加过去,让最后一个词包含了前面的全部信息。正是因为这样的效率实在是太低了,所以才有了后来的transformer架构。它就一步到位,同时把各个位置的词都拿出来进行加权求和。
传统 RNN 按时间压缩信息,Transformer 用注意力机制取代了它,让每个 token 能直接访问历史 token。那么在深度维度上,残差连接不也是在用固定加法"压缩"所有历史层吗?于是,Kimi 团队提出:用 Softmax 加权求和 替代固定累加,让每一层学会"按需回看"历史层。
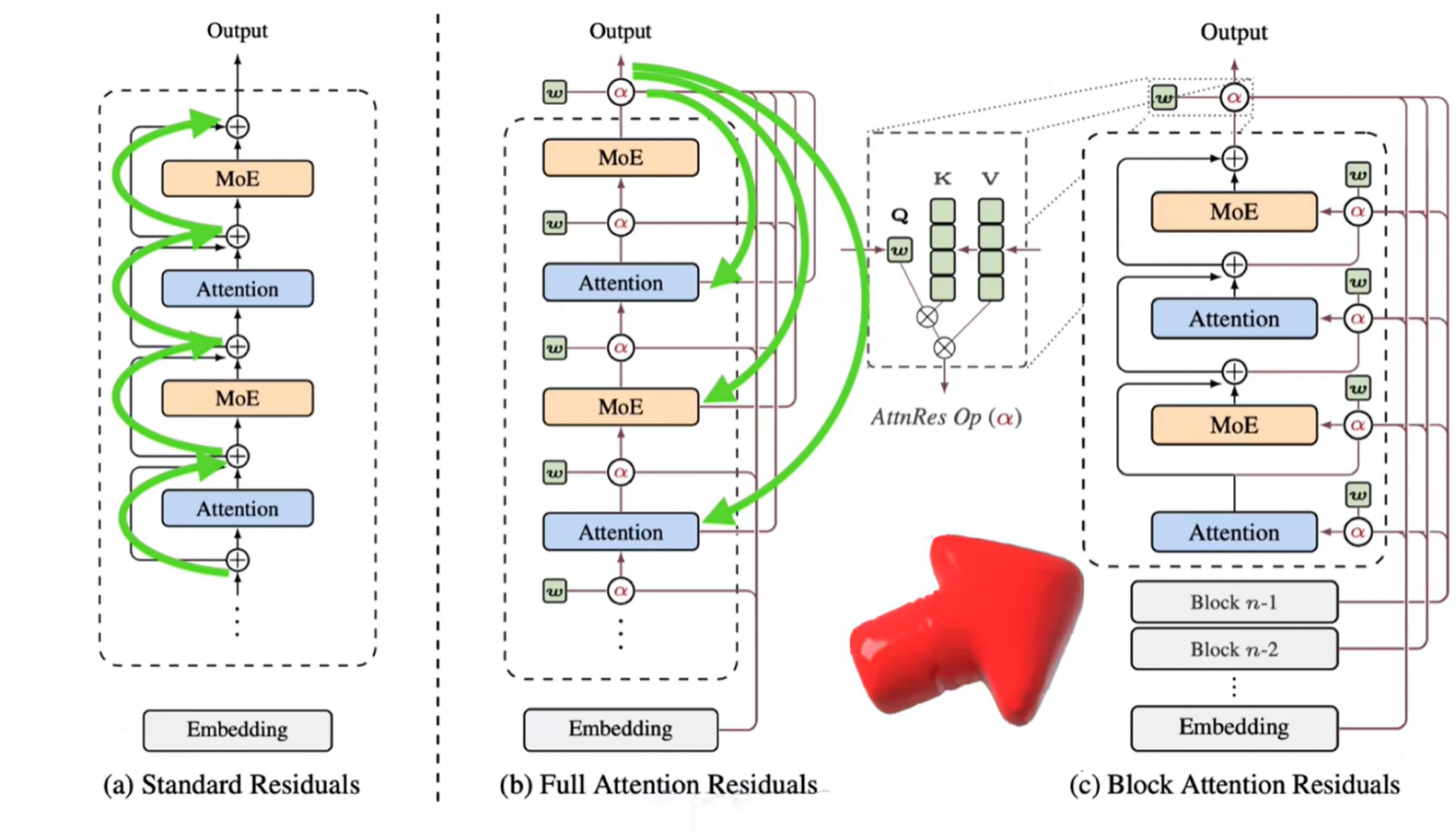
具体来说,传统残差思路就是最左边的图,一层一层加过去。
注意力残差就是直接一眼看向全部,选择性的加权聚合和所有前一层的输出:
hₗ = Σ α_{i→l} · f_i(h_i),其中 Σα = 1,α ≥ 0
每个 α 是通过可学习的注意力权重计算的------当前层就像一个"智能筛选器",可以决定更信任第 2 层的特征还是第 48 层的特征,权重可以高达 0.8,而不必被中间层稀释。
而最右边是为了缓解层数太多导导致的注意力计算消耗过大,而采用的分化思想,和QKV分组等思想有异曲同工之妙。
4. 总结
| 技术 | 提出方 | 发布时间 | 核心思想 | 技术特点 | 解决的问题 |
|---|---|---|---|---|---|
| Hyper-Connections (HC,超连接) | 字节跳动 Seed 团队 | 2024年9月 | 将单通道残差流扩展为多通道并行,引入可学习连接 | 拓宽残差流宽度(如4倍),用三个可学习矩阵动态控制信息聚合 | 提升模型表达能力,打破残差连接的容量瓶颈 |
| mHC (Manifold-Constrained HC,流形约束超连接) | DeepSeek | 2025年12月 | 对HC的可学习矩阵施加双随机矩阵流形约束 | 强制矩阵行和、列和均为1且非负,通过Sinkhorn-Knopp迭代投影 | 解决HC在大规模训练中的信号爆炸(3000倍→1.6倍)和不稳定问题 |
| Attention Residuals (AttnRes) | Kimi(月之暗面) | 2026年3月 | 用Softmax注意力机制替代固定的残差加法 | 每层发出Query,从所有历史层中按需加权聚合特征 | 解决信息稀释和隐藏状态爆炸,提升深层网络表达能力 |
这项工作的意义在于:它不是在已有的注意力机制上小修小补,而是回到 Transformer 最底层的"残差连接"动刀------一个从 2015 年就没变过的设计 。中国 AI 公司开始从应用层竞争迈向底层架构创新的"深水区"。