自回归大模型是什么 简介
- AI 解释
这是一个非常核心的架构认知问题。简单来说,"自回归大模型"是"怎么用" (一种生成策略),"Transformer"是"用什么"(一种底层架构)。它们共同构成了现代端到端自动驾驶的"大脑"。
为了让你一眼看清全貌,我们先通过一个表格快速对比,再深入拆解。
🧩 核心概念关系表
| 维度 | Transformer(架构) | 自回归大模型(策略) |
|---|---|---|
| 本质 | 一种神经网络结构(基于注意力机制) | 一种序列生成策略(预测下一个 Token) |
| 角色 | "硬件"/"发动机" | "软件"/"驾驶逻辑" |
| 关系 | 自回归大模型通常基于 Transformer 构建 | 它需要 Transformer 作为其计算核心 |
| 类比 | 就像汽车的底盘和引擎 | 就像自动驾驶算法(是急刹还是绕行) |
一、自回归大模型(Autoregressive Large Model)
- 是什么?
"自回归" 的核心思想是:下一步的预测,依赖于之前所有已生成的结果。
- 通俗理解 :像说话 或打字 一样。
- 你写第一个字"我",然后根据"我"写第二个字"是",再根据"我是"写第三个字"元",最后生成"我是元宝"。
- 驾驶场景 :
- 模型先预测 0.1 秒后的位置,再根据这个位置预测 0.2 秒后的位置,以此类推,串行地生成整条轨迹。
- 在自动驾驶中的特点
- 优点 :
- 灵活性强:能应对突发状况,生成复杂的、长距离的轨迹。
- 多模态:容易生成多种可能的未来(比如"加速超车"或"减速让行")。
- 致命缺点 :
- 推理慢 :必须一步一步算,不能并行,导致延迟高。
- 误差累积:前一步预测错了,后面会步步错("雪崩效应")。
三、与"之前架构"的根本区别
你提到的"之前的架构",通常指 CNN + RNN 或 纯规则/优化 的方案。区别主要体现在信息流 和决策逻辑上。
| 范式 | 之前的主流架构 | Transformer + 自回归 |
|---|---|---|
| 感知方式 | 局部+序列(CNN 看局部,RNN 串行记忆) | 全局+并行(Attention 一眼看全图) |
| 规划逻辑 | 模块化(感知→预测→规划,各干各的) | 端到端(输入图像/点云,直接输出轨迹,中间无隔阂) |
| 决策方式 | 规则/优化驱动(QP 求解器,if-else 规则) | 数据/概率驱动(模仿学习,预测下一个 Token) |
| 可解释性 | 高(知道是哪个规则触发的) | 低(黑盒模型,难解释"为什么这么开") |
在 VAD、DriveGPT 等模型中,两者是结合使用的:
架构 = Transformer(处理感知和上下文)
策略 = 自回归(生成轨迹序列)
目前的趋势是:
- 训练时:用自回归,让模型学会复杂的驾驶逻辑。
- 部署时 :为了降低延迟,往往采用 Non-Autoregressive(非自回归) 或 Teacher Forcing 的方式,让模型一次性(One-shot)输出轨迹,牺牲部分灵活性来换取实时性。
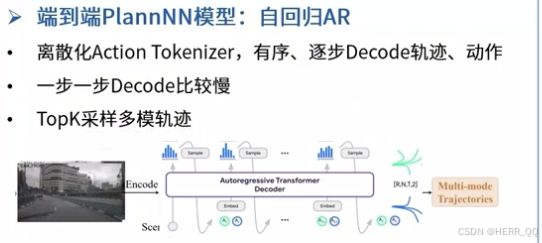
. 离散化 Action Tokenizer(动作分词器)
含义:把连续的驾驶动作(如方向盘转多少度、踩多少油门)变成了离散的符号(Token),就像自然语言处理中的单词一样。
作用:这让模型可以使用 Transformer 这种擅长处理离散序列的架构来"说话"------也就是输出驾驶指令。
- 有序、逐步 Decode(逐步解码)
含义:模型不是一次性算出整条轨迹,而是像接龙一样,先算第 1 秒怎么走,再算第 2 秒怎么走,直到第 N 秒。
缺点(图中的"比较慢"):因为是串行计算,必须等前一步算完才能算下一步,所以速度较慢。
- TopK 采样多模轨迹(多模态输出)
含义:由于自回归的特性,如果随机性设置得好,模型可以生成多条不同的合理轨迹(比如一条左转避让、一条直行加速、一条右转绕行),而不是只有一条固定的路。
作用:增加了方案的多样性,避免"死脑筋",能应对复杂路况。
- 组件和分类
attention 设计方式
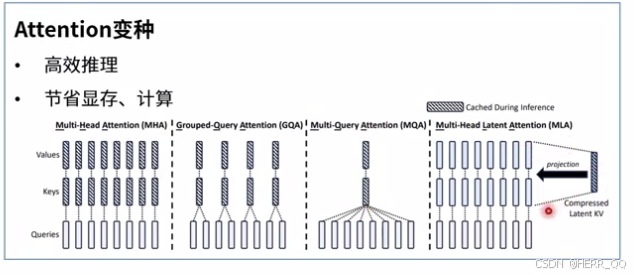
标准的 Transformer(最左边 MHA)在计算时,Queries、Keys、Values 都是全部展开计算的,复杂度很高(O(N^2))。右边的几种变体通过共享或压缩这些矩阵,实现了提速和显存节省。
四种 Attention 变种对比
- Multi-Head Attention (MHA) - 标准版
• 特点:最原始的全连接模式。
• 问题:计算量大,显存占用高,因为每一个 Head 都有独立的 K/V 矩阵。
- Grouped-Query Attention (GQA) - 分组查询
• 特点:K 和 V 被"分组共享"了。
• 原理:多个 Queries 共享同一组 Keys 和 Values。就像把一个大班组变成几个小组,小组内共用资料。
• 优势:大幅减少了 K/V 的参数量和计算量,显存减半,但保留了较好的精度。
- Multi-Query Attention (MQA) - 多查询
• 特点:所有 Queries 共享同一组 K 和 V。
• 原理:不管有多少个头,大家看的是同一个 Key/Value 池子。
• 优势:极致的速度和显存节省,常用于对速度要求极高的场景(如推理阶段)。
- Multi-Head Latent Attention (MLA) - 潜在多头注意力
• 特点:引入低维 Latent(潜在变量)进行压缩。
• 原理:把庞大的 K/V 映射到一个紧凑的 Latent 空间中去交互,然后再投影回来。
• 优势:通过"降维打击",极大降低了计算复杂度,同时保持了多头注意力的表达能力。
总结
这张图展示了 Transformer 优化的"瘦身"过程:
• GQA/MQA 是通过减少重复计算(共享 K/V)来提速。
• MLA 是通过压缩数据维度(Latent 空间)来提速。
它们的目标只有一个:让大模型推理更快,更省显存。
最后一个减少的不是KV的数量 而减少的是维度
FFN设计方式
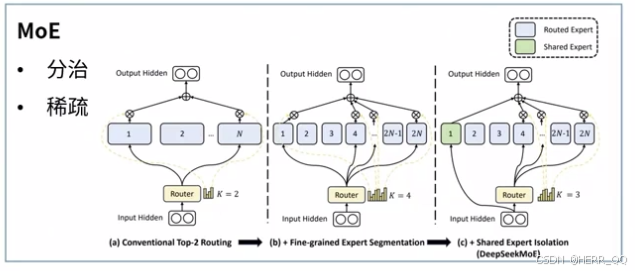
这展示的是 MoE(Mixture of Experts,混合专家模型) 的架构演进。它的核心思想是**"分治"与"稀疏激活"**,即用多个专家网络分工合作,而不是靠一个巨大的"通才"网络来解决所有问题。
核心概念解释
-
分治(Divide and Conquer)
- 把一个复杂的任务拆解成多个子任务,每个"专家(Expert)"只擅长处理其中一类特定场景(比如有的专家专攻直行,有的专攻转弯,有的专攻避让)。
- 这样每个专家不用学得太"大而全",训练更快,也更专业。
-
稀疏(Sparse)
- 对于一个具体的输入,不需要让所有专家都参与计算,只需要**"Router(路由器)"**挑选出最相关的几个专家(比如 K=2K=2K=2)来干活。
- 这就是所谓的"稀疏激活",大大节省了计算资源。
架构演进(从左到右)
(a) 传统 Top-2 Routing(基础版 MoE)
- 做法:输入进来后,Router 选出 Top-2 个专家,只有这 2 个专家进行计算,其他专家"偷懒"。
- 特点:简单直接,但可能存在专家负载不均衡(比如某些专家总是被选中,某些总是闲置)。
(b) Fine-grained Expert Segmentation(细粒度专家分割)
- 做法:将专家拆分成更多的"小组"(比如从 4 个专家变成 8 个小组)。
- 特点:粒度更细,能更精准地匹配特定子任务,提升专业性。
© Shared Expert Isolation(共享专家隔离)
- 做法 :引入绿色的"Shared Experts(共享专家)"。这些专家是所有输入都会经过的,负责处理通用特征;而蓝色的"Routed Experts"则像 (a) 一样被 Router 稀疏选中,处理特定特征。
- 特点:结合了"通用知识"和"专业知识"。共享专家保证了模型的基础能力,路由专家提供了灵活性和多模态处理能力。这也是目前大模型中非常流行的一种范式(如 DeepSeek 等模型常用)。
总结:为什么要用 MoE?
在端到端自动驾驶中,路况千变万化(直行、加塞、红绿灯、无保护左转等)。如果用单一模型处理所有情况,模型会变得极其庞大且难以收敛。
MoE 的好处:
- 省钱(省算力):一次推理只激活部分专家,计算量小。
- 高效(并行):不同的专家可以同时训练和学习不同的场景。
- 能力强:通过堆叠大量细分领域的专家,整体模型的泛化能力和上限更高。
- 问 解释一下什么是 特殊专家和共享专家
在 MoE(混合专家)架构中,**特殊专家(Routed Expert)和共享专家(Shared Expert)**是两种分工不同的子网络。它们一个负责"特事特办",一个负责"兜底通用"。
- 角色定义:谁干什么?
| 角色 | 特殊专家 (Routed Expert) | 共享专家 (Shared Expert) |
|---|---|---|
| 别名 | Routed / Sparse Expert | Shared / Common Expert |
| 职责 | 处理特定模式(如急刹、变道、路口博弈) | 处理基础特征(如车道保持、跟车、通用推理) |
| 激活方式 | 稀疏激活(Router 路由选择,每次只选 K 个) | 强制激活(所有 Token 必经之路) |
| 类比 | 专科医生(只治心脏病) | 全科医生(看所有基础病) |
- 如何挑选专家?(Router 机制)
你不需要手动挑选,这是由 Router(路由器) 自动完成的。流程如下:
- 输入特征:对于输入的 Token(如自车状态、周围车辆特征),提取其表征。
- 计算得分 :Router(一个小的线性层)计算该 Token 与所有特殊专家的匹配分数。
- Top-K 选择 :选取分数最高的 K 个特殊专家(通常 K=1 或 2)。
- 必经共享 :共享专家是强制通过的,不参与路由选择。
最终路径 :输入 → [共享专家] → [选中的 K 个特殊专家] → 输出
- 在自动驾驶中的直观理解
假设你的车正在处理一个**"无保护左转"**场景:
- 共享专家:负责基础操作,比如"保持车道居中"、"监测对向来车"。
- 特殊专家 :Router 可能会选中 #3号专家(擅长路口博弈) 和 #7号专家(擅长激进决策)。这两个专家会给出具体的"抢行"或"等待"建议。
如果 Router 选错了专家怎么办?
例如在左转时选中了"擅长高速巡航"的专家,模型输出会变得不合理。这需要通过 Auxiliary Loss(辅助损失) 和 Load Balancing(负载均衡) 在训练中解决,惩罚那些总是被误选的专家,鼓励 Router 学习正确的映射。
- 为什么需要这种设计?
- 共享专家 :保证模型有基础驾驶能力,防止稀疏激活时出现"常识性错误"。
- 特殊专家 :让模型具备多模态能力,能应对极端或复杂的 corner case。
一句话总结 :共享专家是"必修课",特殊专家是"选修课"。Router 就是那个根据你的情况(输入)帮你选课的系统。
预训练

过滤 去重 隐私 增强 token化
后训练
这展示的是 RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习) 的完整流程。这是目前大语言模型(如 ChatGPT)对齐人类价值观、提升回答质量的核心技术。
整个流程分为三个关键步骤,解决了模型"能做什么 "到"该做什么"的问题:
Step 1:监督微调 (Supervised Fine-Tuning, SFT)
- 目标 :让模型学会"正确地做事"(模仿)。
- 过程 :
- 给模型一个提示(Prompt),比如"向 6 岁小孩解释登月"。
- 人类标注员写下标准的、高质量的答案(Demonstration)。
- 用这些"标准答案"去微调预训练模型(如 GPT-3)。
- 结果:模型不再胡言乱语,能输出符合语法和基本逻辑的内容。
Step 2:训练奖励模型 (Reward Model, RM)
- 目标 :让模型学会判断"什么更好"(排序)。
- 痛点:SFT 阶段依赖人工标注,成本高且慢。RLHF 想通过"比较"来代替"写答案"。
- 过程 :
- 给模型同一个提示,让它生成多个不同的回答(比如 A, B, C, D)。
- 人类标注员不对回答打分,而是排序(比如 B > A > D > C)。
- 用这些排序数据训练一个"奖励模型(RM)"。这个 RM 的任务是预测哪个回答人类更喜欢。
- 结果:RM 成为了一个"裁判",能给任何回答打出一个代表人类偏好的分数。
Step 3:强化学习优化 (Reinforcement Learning, PPO)
- 目标:让模型自己生成高质量回答(优化)。
- 过程 :
- 给模型一个新提示(比如"写一个关于青蛙的故事")。
- 模型(Policy)生成一个回答。
- 把回答交给 Step 2 训练好的 奖励模型 (RM) 打分。
- 根据分数,使用 PPO (Proximal Policy Optimization) 算法更新模型参数。
- 核心逻辑:模型会倾向于生成那些能让 RM 给出高分的回答。
- 结果:模型在不需要人类实时干预的情况下,自我进化,输出更符合人类期望的内容。
总结对比
| 阶段 | 核心动作 | 人类参与程度 | 解决的问题 |
|---|---|---|---|
| SFT | 教模型写作业 | 高(写答案) | 基础能力、语法正确 |
| RM | 教模型当裁判 | 中(排顺序) | 建立偏好标准 |
| RLHF | 模型自己练习 | 低(只打分) | 自我优化、对齐人类价值观 |
这个流程使得模型不仅能生成连贯的文本,还能生成有用、诚实、无害的文本,是通往 AGI(通用人工智能)的关键一步。
inference
重点关注 采样策略 prefill decode kv cache