目录
[1. 整体架构设计](#1. 整体架构设计)
[2. 关键模块代码实现](#2. 关键模块代码实现)
[(2)CSV 数据预处理(鲁棒性设计)](#(2)CSV 数据预处理(鲁棒性设计))
[(3)通义千问 API 调用(带重试机制)](#(3)通义千问 API 调用(带重试机制))
[1. 环境准备](#1. 环境准备)
[2. 通义千问 API 密钥获取](#2. 通义千问 API 密钥获取)
[3. 测试数据准备](#3. 测试数据准备)
[4. 代码运行](#4. 代码运行)
一、背景与需求
在教育数字化转型过程中,课堂话语分析是评估教学质量、优化教学设计的核心环节。传统人工分类课堂话语的方式存在效率低、标准不统一、主观性强等问题。为此,我们基于 Python + 通义千问 API 实现了一套课堂话语智能分类分析工具,可自动读取 CSV 格式的课堂对话文本,按预设的教育维度分类统计,对比优质课堂话语分布基准,为教学评估提供数据支撑。
二、工具核心功能
本工具围绕 "数据加载→精准分割→AI 分类→统计分析" 全流程设计,核心能力包括:
- 兼容多编码(UTF-8/GBK)读取课堂对话 CSV 文件,自动处理空值、无效数据;
- 精准分割中文句子(避免误分割 Dr.Li/Mr.Wang 等英文缩写);
- 对接阿里云通义千问 API,实现课堂话语的智能分类(4 大类 + 12 小类);
- 内置 API 重试机制,保证网络波动下的稳定性;
- 批量分析并输出分类统计结果(大类 / 小类占比、无法分类句子汇总);
- 适配 Matplotlib 中文字体,为后续可视化分析铺路。
三、核心技术实现
1. 整体架构设计
工具以DiscourseAnalyzer类为核心,封装所有逻辑,核心模块包括:分类体系定义、数据预处理、API 调用、批量分析、正则工具类,架构如下:
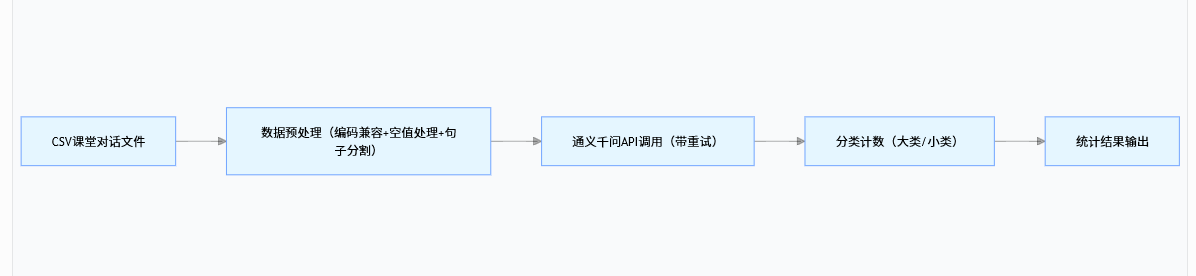
2. 关键模块代码实现
(1)分类体系定义(教育维度定制)
结合优质课堂评估标准,预设 4 个核心大类、12 个细分小类,并定义优质课堂话语占比基准:
SUBCATEGORIES = {
# 知识理解子类
"观察记忆": "知识理解", "概括理解": "知识理解", "说明论证": "知识理解",
# 表达交流子类
"经历经验": "表达交流", "主观看法": "表达交流", "情感态度": "表达交流",
# 实践应用子类
"分析计算": "实践应用", "推测解释": "实践应用", "简单问题解决": "实践应用",
# 创造迁移子类
"综合问题解决": "创造迁移", "猜想探究": "创造迁移", "发现创新": "创造迁移"
}
# 优质课堂话语占比基准(%)
BENCHMARK_RATIOS = {"知识理解": 76, "表达交流": 12, "实践应用": 0, "创造迁移": 12}(2)CSV 数据预处理(鲁棒性设计)
解决 CSV 编码兼容、空值处理、句子精准分割三大问题,是后续分析的基础:
def load_csv_content_with_roles(self):
try:
# 兼容UTF-8/GBK编码(适配不同系统生成的CSV)
try:
df = pd.read_csv(self.csv_path, encoding="utf-8")
except UnicodeDecodeError:
df = pd.read_csv(self.csv_path, encoding="gbk")
# 处理空值,避免生成"nan: 内容"无效数据
df = df.fillna("")
roles = df["角色"].tolist()
contents = df["内容"].tolist()
# 组合角色+内容,过滤空数据
combined = [f"{role}: {content}" for role, content in zip(roles, contents) if
content.strip() and role.strip()]
# 精准分割中文句子(避免误分割英文缩写)
all_sentences = []
# 正则规则:负向后顾断言排除英文缩写,仅分割中文句末标点
sentence_split_pattern = r'(?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=[。!?\n])\s*'
for item in combined:
sentences_in_item = re.split(pattern=sentence_split_pattern, string=item)
valid_sentences = [s.strip() for s in sentences_in_item if s.strip()]
all_sentences.extend(valid_sentences)
print(f"CSV加载完成,共处理出 {len(all_sentences)} 个带角色的有效句子")
return all_sentences
except Exception as e:
print(f"读取/处理CSV文件时出错:{str(e)}")
return []核心亮点 :正则表达式(?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=[。!?\n])\s*通过 "负向后顾断言" 排除 Dr.Li/Mr.Wang 等英文缩写的误分割,仅按中文句末标点(。!?)分割,保证句子完整性。
(3)通义千问 API 调用(带重试机制)
对接阿里云通义千问兼容 OpenAI 的 API,内置重试机制解决网络波动 / 超时问题:
@retry(
stop=stop_after_attempt(3), # 最多重试3次
wait=wait_exponential(multiplier=1, min=2, max=10), # 指数退避等待(2s→4s→8s)
retry=retry_if_exception_type((requests.exceptions.RequestException, TimeoutError))
)
def analyze_sentence(self, sentence):
try:
prompt = f"""
请将以下课堂话语句子分类到指定子类中,仅返回子类名称(如"观察记忆"),无需额外解释:
可选子类:{list(self.SUBCATEGORIES.keys())}
句子:{sentence}
"""
response = self.client.chat.completions.create(
model="qwen-turbo", # 通义千问标准版
messages=[{"role": "user", "content": prompt}],
temperature=0.1 # 低随机性,保证分类稳定
)
subcategory = response.choices[0].message.content.strip()
# 统计分类结果
if subcategory in self.subcategory_counts:
self.subcategory_counts[subcategory] += 1
main_category = self.SUBCATEGORIES[subcategory]
self.main_category_counts[main_category] += 1
self.output_lines.append(f"{sentence}\t{main_category}\t{subcategory}")
print(f"句子:{sentence[:30]}... → 大类:{main_category},小类:{subcategory}")
else:
self.unknown_lines.append(sentence)
print(f"句子:{sentence[:30]}... → 无法分类")
return subcategory
except Exception as e:
print(f"分析句子[{sentence[:20]}...]时出错:{str(e)}")
self.unknown_lines.append(sentence)
return None核心亮点 :使用tenacity库实现 API 重试,避免单次网络波动导致分析失败;temperature=0.1降低 AI 回答的随机性,保证分类结果稳定。
(4)批量分析与统计
封装batch_analyze方法,批量处理所有句子并输出统计结果:
def batch_analyze(self):
"""批量分析所有句子,并输出统计结果"""
print("\n=== 开始批量分析课堂话语 ===")
for idx, sentence in enumerate(self.sentences):
print(f"\n[{idx + 1}/{len(self.sentences)}] 分析中:")
self.analyze_sentence(sentence)
# 输出最终统计结果
print("\n=== 分类统计结果 ===")
print("【大类统计】")
for main_cat, count in self.main_category_counts.items():
print(f"{main_cat}:{count} 句(占比:{count / len(self.sentences) * 100:.1f}%)")
print("\n【小类统计(仅显示有数据的)】")
for sub_cat, count in self.subcategory_counts.items():
if count > 0:
print(f"{sub_cat}:{count} 句")
if self.unknown_lines:
print(f"\n【无法分类的句子】共 {len(self.unknown_lines)} 句:")
for line in self.unknown_lines:
print(f"- {line}")四、快速使用教程
1. 环境准备
安装依赖包:
pip install pandas matplotlib openai tenacity requests2. 通义千问 API 密钥获取
- 访问阿里云通义千问控制台,完成实名认证;
- 创建 API-KEY,记录密钥(后续替换代码中的
API_KEY)。
3. 测试数据准备
新建test.csv文件,内容如下(UTF-8 编码):
csv
角色,内容
老师,请同学们观察并记住这个公式的形式
学生,我觉得这个解题方法比之前的更简单
老师,请分析这道题的计算步骤,解释为什么这么算
学生,我猜想如果改变参数,结果可能会不一样4. 代码运行
替换代码中的API_KEY为自己的密钥,直接运行 Python 脚本即可。
五、运行效果展示
plaintext
CSV加载完成,共处理出 4 个带角色的有效句子
=== 开始批量分析课堂话语 ===
[1/4] 分析中:
句子:老师:请同学们观察并记住这个公式的形式... → 大类:知识理解,小类:观察记忆
[2/4] 分析中:
句子:学生:我觉得这个解题方法比之前的更简单... → 大类:表达交流,小类:主观看法
[3/4] 分析中:
句子:老师:请分析这道题的计算步骤,解释为什么这么算... → 大类:实践应用,小类:分析计算
[4/4] 分析中:
句子:学生:我猜想如果改变参数,结果可能会不一样... → 大类:创造迁移,小类:猜想探究
=== 分类统计结果 ===
【大类统计】
知识理解:1 句(占比:25.0%)
表达交流:1 句(占比:25.0%)
实践应用:1 句(占比:25.0%)
创造迁移:1 句(占比:25.0%)
【小类统计(仅显示有数据的)】
观察记忆:1 句
主观看法:1 句
分析计算:1 句
猜想探究:1 句
=== 句子分割测试 ===
原始文本:老师:Dr.Li你好!今天天气很好?
分割结果:['老师:Dr.Li你好!', '今天天气很好?']
=== 金额提取测试 ===
原始文本:苹果¥99 香蕉¥19.9 橙子50(无符号)
提取结果:['99', '19.9']六、核心技术亮点
- 正则精准分割:通过负向后顾断言解决中文句子分割时的英文缩写误判问题;
- 鲁棒的 CSV 处理:兼容 UTF-8/GBK 编码,自动处理空值,保证数据清洁;
- 稳定的 API 调用:内置重试机制,指数退避等待,适配网络波动;
- 教育维度定制:贴合课堂评估场景的分类体系,可直接落地教育领域;
- 中文字体适配:提前配置 Matplotlib 中文字体,为后续可视化分析扫清障碍。
七、总结与扩展方向
本工具实现了课堂话语从 "原始文本" 到 "结构化分类统计" 的自动化,大幅提升课堂评估效率。后续可扩展方向:
- 可视化升级:基于 Matplotlib 生成大类 / 小类占比饼图、对比优质课堂基准的柱状图;
- 结果持久化:将分类结果保存为 CSV/JSON 文件,方便后续报表生成;
- 多维度分析:增加 "师生话语占比""不同环节话语分布" 等维度;
- 本地模型适配:支持对接本地部署的 LLM 模型,降低 API 调用成本。
该工具不仅适用于课堂话语分析,也可迁移至客服对话分类、访谈文本分析等场景,具备较强的通用性和扩展性。