论文:DOVER-Lap: A Method for Combining Overlap-aware Diarization Outputs
作者:Desh Raj, Leibny Paola Garcia-Perera, Zili Huang, Shinji Watanabe, Daniel Povey, Andreas Stolcke, Sanjeev Khudanpur
时间:2020
arXiv:
2011.01997任务:Speaker Diarization Output Combination,把多个 diarization 系统的输出融合成一个更好的结果
前言
我们的目标是将多个 diarization 系统的输出结果进行投票融合。
之前已经有 DOVER 方法了,但它有两个局限:
- 不支持 overlap-aware 输出,默认每个时间区域最多只有一个 speaker;
- label mapping 是 greedy incremental,融合结果强依赖输入顺序。
论文提出 DOVER-Lap 在 DOVER 的基础上改了两件事:用全局 label mapping 替代 pair-wise incremental mapping;用 overlap-aware voting 允许一个区域输出多个 speaker。
一、问题定义
设一共有 K K K 个 diarization hypothesis
H 1 , H 2 , ... , H K H_1,H_2,\ldots,H_K H1,H2,...,HK
第 k k k 个 hypothesis 有 N k N_k Nk 个 speaker
{ H k 1 , H k 2 , ... , H k N k } \{H_k^1,H_k^2,\ldots,H_k^{N_k}\} {Hk1,Hk2,...,HkNk}
每个 hypothesis 可以表示成一组时间区间和 speaker 标签
H k = { ( Δ k , θ , H k n ) : n ∈ { 1 , ... , N k } } H_k=\{(\Delta_{k,\theta},H_k^n):n\in\{1,\ldots,N_k\}\} Hk={(Δk,θ,Hkn):n∈{1,...,Nk}}
其中
Δ k , θ = t k , θ , t k , θ + 1 \Delta_{k,\theta}=t_{k,\\theta},t_{k,\\theta+1} Δk,θ=tk,θ,tk,θ+1
目标是找到一个融合后的 diarization 输出
H ^ = f ( H 1 , H 2 , ... , H K ) \hat{H}=f(H_1,H_2,\ldots,H_K) H^=f(H1,H2,...,HK)
使得它相对未知真实参考标注的 diarization error 尽可能低。
这里有两个子问题:
- label mapping:不同系统的 speaker label 怎么对齐
- label voting:对齐后,每个时间区域应该输出哪些 speaker
DOVER 和 DOVER-Lap 的差异,也体现在这两个阶段。
二、DOVER-Lap label mapping
2.1 用全局 cost tensor 做 label mapping
假设有 K K K 个 hypothesis,第 k k k 个 hypothesis 有 N k N_k Nk 个 speaker。
DOVER-Lap 构造一个 K K K 维 cost tensor:
C ∈ R N 1 × N 2 × ⋯ × N K C\in\mathbb{R}^{N_1\times N_2\times\cdots\times N_K} C∈RN1×N2×⋯×NK
例如:
text
H1 有 2 个 speaker: A1, A2
H2 有 3 个 speaker: B1, B2, B3
H3 有 2 个 speaker: C1, C2那么:
K = 3 K=3 K=3
N 1 = 2 , N 2 = 3 , N 3 = 2 N_1=2,\quad N_2=3,\quad N_3=2 N1=2,N2=3,N3=2
所以 cost tensor 是:
C ∈ R 2 × 3 × 2 C\in\mathbb{R}^{2\times 3\times 2} C∈R2×3×2
它不是二维矩阵,而是三维数组。
可以想象成一个立方体:
text
维度 1:H1 的 speaker 选择,有 2 种
维度 2:H2 的 speaker 选择,有 3 种
维度 3:H3 的 speaker 选择,有 2 种所以这个 tensor 总共有 2 × 3 × 2 = 12 2\times 3\times 2=12 2×3×2=12 个元素。
每个元素都是一个数。
例如:
text
C(1,1,1)
C(1,1,2)
C(1,2,1)
C(1,2,2)
...
C(2,3,2)每一个 C ( i 1 , i 2 , i 3 ) C(i_1,i_2,i_3) C(i1,i2,i3) 都是一个 标量 cost。
每个元素 C ( i 1 , ... , i K ) C(i_1,\ldots,i_K) C(i1,...,iK) 表示"如果把第 1 个系统的第 i 1 i_1 i1 个 speaker、第 2 个系统的第 i 2 i_2 i2 个 speaker、......、第 K K K 个系统的第 i K i_K iK 个 speaker 映射成同一个全局 speaker,这个映射组合的代价是多少"。
i k i_k ik:在第 k k k 个 hypothesis 里选择第几个 speaker label。
比如 C ( 2 , 3 , 1 ) C(2,3,1) C(2,3,1) 这个数值表示
text
如果我们把 A2、B3、C1 认为是同一个全局 speaker,这个假设的代价是多少?所以
- ( 2 , 3 , 1 ) (2,3,1) (2,3,1) 是索引 tuple;
- ( A 2 , B 3 , C 1 ) (A2,B3,C1) (A2,B3,C1) 是对应的 speaker label tuple;
- C ( 2 , 3 , 1 ) C(2,3,1) C(2,3,1) 是这个 tuple 的 cost 数值。
给定一个 tuple ( i 1 , i 2 , ... , i K ) (i_1,i_2,\ldots,i_K) (i1,i2,...,iK),DOVER-Lap 把所有 pair-wise similarity 加起来:
C ( i 1 , ... , i K ) = − ∑ 1 ≤ p < q ≤ K M i p , i q C(i_1,\ldots,i_K)=-\sum_{1\le p<q\le K}M_{i_p,i_q} C(i1,...,iK)=−1≤p<q≤K∑Mip,iq
其中, M a b M_{ab} Mab 代表相对重叠
M a b = d u r ( a ∩ b ) d u r ( a ) + d u r ( b ) M_{ab}=\frac{\mathrm{dur}(a\cap b)}{\mathrm{dur}(a)+\mathrm{dur}(b)} Mab=dur(a)+dur(b)dur(a∩b)
这里有一个负号,因为后面要做最小代价匹配。
直觉是:
- 如果这些 speaker 轨迹彼此重叠很多,说明它们可能是同一个真实 speaker;
- 此时 ∑ M \sum M ∑M 很大;
- 加负号后 cost 很小;
- greedy matching 会优先选它们。
2.2 label mapping
DOVER-Lap 的 label mapping 阶段最终要输出的是
M = { ( i 1 , i 2 , ... , i K ) , ... } \mathcal{M}=\{(i_1,i_2,\ldots,i_K),\ldots\} M={(i1,i2,...,iK),...}
也就是一组 speaker tuple。
比如有 3 个 diarization 输出:
text
H1: A1, A2
H2: B1, B2
H3: C1, C2如果算法最终输出
text
M = {
(A1, B2, C1),
(A2, B1, C2)
}它的意思就是
text
global speaker 1 = A1 / B2 / C1
global speaker 2 = A2 / B1 / C2DOVER-Lap 的 label mapping 阶段要解决的问题是
从所有可能的 speaker tuple 中,选出一组不冲突的 tuple,让所有系统里的 speaker label 都被合理对齐到全局 speaker 空间。
这其实是 weighted K K K-partite matching。
当 K = 2 K=2 K=2 时,它退化成普通 bipartite matching,可以用 Hungarian algorithm 多项式求解。
但当 K > 2 K>2 K>2 时,这个问题是 NP-hard。
所以 DOVER-Lap 使用 greedy approximation。
2.3 greedy approximation
初始化
设所有还没有被 mapping 的 speaker label 集合为:
R = { ( H k , n ) : k ∈ { 1 , ... , K } , n ∈ { 1 , ... , N k } } R=\{(H_k,n):k\in\{1,\ldots,K\},n\in\{1,\ldots,N_k\}\} R={(Hk,n):k∈{1,...,K},n∈{1,...,Nk}}
最终 mapping 结果为:
M = ∅ \mathcal{M}=\varnothing M=∅
只要 R R R 还不为空,就重复:
- 从 cost tensor 中找出至少包含一个未映射 label 的 tuple;
- 按 cost 从小到大排序;
- 依次扫描这些 tuple;
- 如果当前 tuple 与本轮已选 tuple 不冲突,就加入本轮 matching;
- 一轮结束后,把本轮选中的 tuple 加入最终 mapping;
- 从 R R R 中移除这些已经覆盖的 speaker label。
不冲突是指当前 tuple 中的 speaker label 不能已经出现在本轮已选 tuple 里。
用伪代码表示:
text
输入:cost tensor C
输出:mapping tuple 集合 M
R = 所有 speaker labels
M = 空集
while R 非空:
S = 所有至少包含一个 R 中 label 的 tuple
S = 按 C(tuple) 从小到大排序
M0 = 空集
for tuple in S:
if tuple 与 M0 不冲突:
M0 = M0 ∪ {tuple}
M = M ∪ M0
R = R \ M0这个算法不是精确最优,但它有两个明显优势:
- 比 DOVER 的 pair-wise incremental mapping 更全局;
- 实际运行很快,论文中 i7 CPU 上几秒即可完成。
举个例子
假设有 3 个系统:
text
H1: A1, A2
H2: B1, B2
H3: C1, C2真实情况假设是:
text
global speaker X = A1 / B2 / C1
global speaker Y = A2 / B1 / C2也就是说正确 mapping 应该是:
text
(A1, B2, C1)
(A2, B1, C2)现在我们根据 pairwise overlap 算出每个 tuple 的 cost。
假设 cost 如下,越小越好:
| tuple | cost | 解释 |
|---|---|---|
| ( A 1 , B 2 , C 1 ) (A1,B2,C1) (A1,B2,C1) | -2.63 | 三者高度重叠,很可能同一人 |
| ( A 2 , B 1 , C 2 ) (A2,B1,C2) (A2,B1,C2) | -2.60 | 三者高度重叠,很可能同一人 |
| ( A 1 , B 1 , C 1 ) (A1,B1,C1) (A1,B1,C1) | -1.20 | 有部分重叠,但不够好 |
| ( A 2 , B 2 , C 2 ) (A2,B2,C2) (A2,B2,C2) | -1.10 | 有部分重叠,但不够好 |
| ( A 1 , B 2 , C 2 ) (A1,B2,C2) (A1,B2,C2) | -0.80 | 不太像同一人 |
| ( A 1 , B 1 , C 2 ) (A1,B1,C2) (A1,B1,C2) | -0.50 | 不太像同一人 |
| ( A 2 , B 1 , C 1 ) (A2,B1,C1) (A2,B1,C1) | -0.40 | 不太像同一人 |
| ( A 2 , B 2 , C 1 ) (A2,B2,C1) (A2,B2,C1) | -0.20 | 不太像同一人 |
贪心算法第一步:
按 cost 从小到大排序。
排序后最靠前的是:
text
1. (A1, B2, C1), cost = -2.63
2. (A2, B1, C2), cost = -2.60
3. (A1, B1, C1), cost = -1.20
...然后开始扫描。
第一个 tuple
看到:
text
(A1, B2, C1)当前 matching 为空,所以没有冲突。
加入:
text
M0 = {(A1, B2, C1)}它占用了:
text
A1, B2, C1第二个 tuple
看到:
text
(A2, B1, C2)它占用:
text
A2, B1, C2和已有的:
text
A1, B2, C1没有任何重复 label。
所以也加入:
text
M0 = {
(A1, B2, C1),
(A2, B1, C2)
}现在所有 speaker label 都覆盖了:
text
A1, A2
B1, B2
C1, C2最终 mapping 就是:
text
global speaker 1 = A1 / B2 / C1
global speaker 2 = A2 / B1 / C2这个例子里,贪心算法得到了正确结果。
需要注意不同 hypothesis 里的 speaker 数可能不一样。
例如:
text
H1: A1, A2
H2: B1, B2, B3
H3: C1, C2这里 H 2 H2 H2 多了一个 speaker B3。
第一轮可能选出:
text
(A1, B2, C1)
(A2, B1, C2)这时:
text
A1, A2, B1, B2, C1, C2都覆盖了,但:
text
B3还没覆盖。
所以 R R R 还不为空。
下一轮要继续找至少包含 B3 的 tuple。
比如可能选:
text
(A1, B3, C1)这表示:
text
B3 可能是一个额外/不稳定的 speaker label,它被并入 A1/C1 对应的全局 speaker或者如果它确实是新 speaker,也可能会形成新的全局映射关系,具体取决于候选 cost。
所以多轮机制主要是为了处理:
- 各系统 speaker 数不一样;
- 有些系统 split 了某个 speaker;
- 有些系统 merge 了某些 speaker;
- 某些 speaker 只在部分系统中出现。
2.4 和 DOVER mapping 的区别
DOVER:
text
只看当前两个 hypothesis
一步一步向后合并DOVER-Lap:
text
同时利用所有 hypothesis 之间的 pair-wise overlap
构造全局 cost tensor
再做 greedy K-partite matchingDOVER-Lap 对输入顺序不那么敏感,也不容易被最开始的一次错误 mapping 带偏。
它不保证数学上全局最优,但在 diarization 场景里通常有效。
三、DOVER-Lap 的 overlap-aware label voting
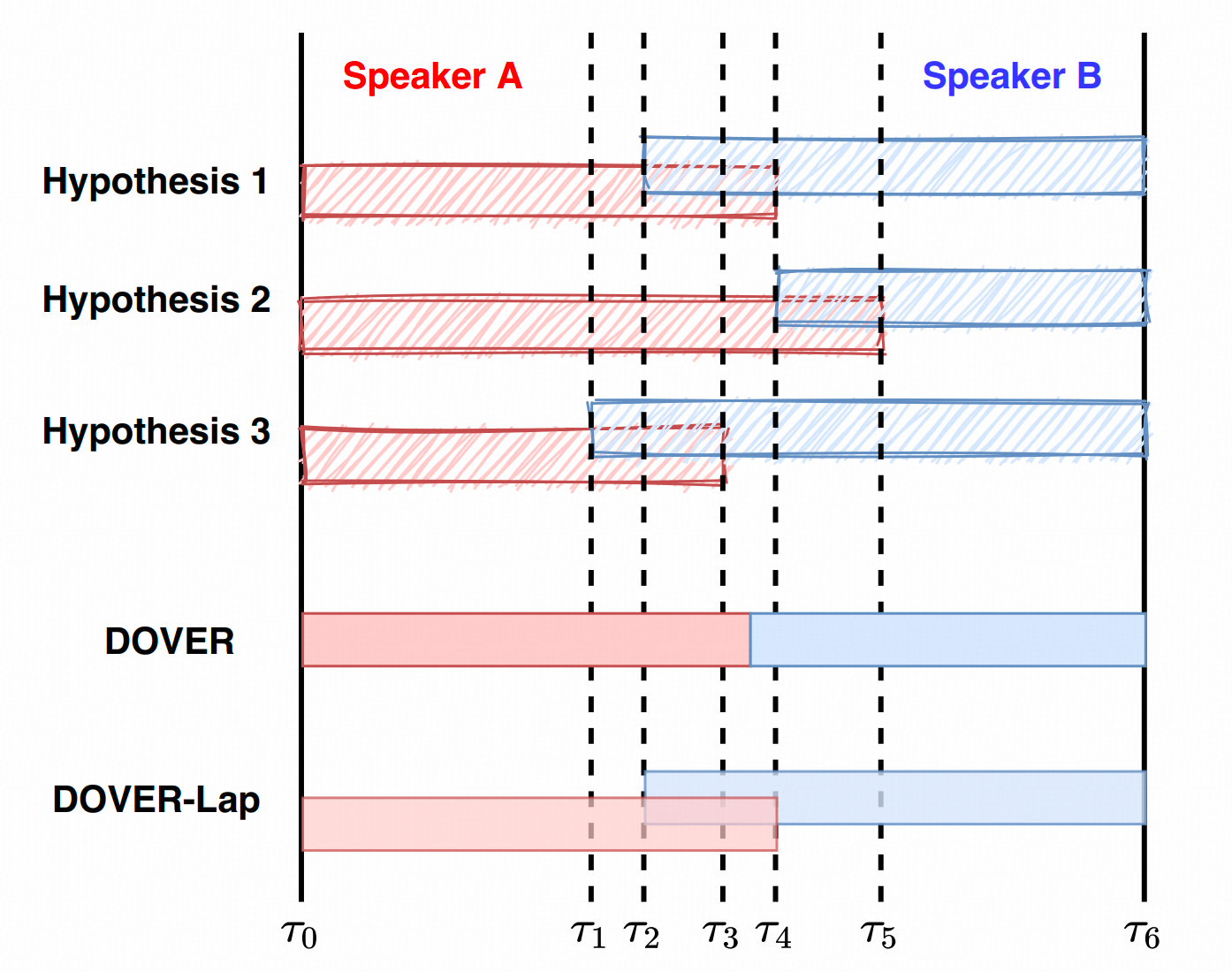
图1 DOVER-Lap 流程图
完成 label mapping 后,所有 hypothesis 的 speaker label 已经在同一个全局空间里。
接下来要做 voting。
3.1 先把时间切成最小区域
如图 1 所示,和 DOVER 一样,DOVER-Lap 会用所有输入 hypothesis 的 speaker 边界切分音频。
例如所有边界合起来是:
text
τ0, τ1, τ2, ..., τT那么就得到很多小区域:
text
[τ0,τ1], [τ1,τ2], ..., [τT-1,τT]每个区域内部,各 hypothesis 的 speaker 活动集合不变。
3.2 估计该区域应该有几个 speaker
设某个区域为 T T T。
第 k k k 个 hypothesis 在该区域预测了 n T k n_T^k nTk 个 speaker。
例如:
text
系统 1: A + B -> n_T^1 = 2
系统 2: A + B -> n_T^2 = 2
系统 3: A -> n_T^3 = 1DOVER-Lap 先估计融合结果中这个区域应该有几个 speaker:
n ^ T = ⌊ ∑ k = 1 K α k n T k ⌉ \hat{n}T=\left\lfloor\sum{k=1}^{K}\alpha_k n_T^k\right\rceil n^T=⌊k=1∑KαknTk⌉
其中:
- α k \alpha_k αk 是归一化后的系统权重;
- ∑ k α k = 1 \sum_k\alpha_k=1 ∑kαk=1;
- ⌊ ⋅ ⌉ \lfloor\cdot\rceil ⌊⋅⌉ 表示四舍五入到最近整数。
论文中的权重来自 DOVER 类似的 rank-based weighting。
可以先给每个系统一个 rank weight
w k = 1 k 0.1 w_k=\frac{1}{k^{0.1}} wk=k0.11
再归一化
α k = w k ∑ j = 1 K w j \alpha_k=\frac{w_k}{\sum_{j=1}^{K}w_j} αk=∑j=1Kwjwk
3.3 再选出票数最高的 speaker
估计出 n ^ T \hat{n}_T n^T 后,DOVER-Lap 对每个 speaker 计算加权票数
v T ( s ) = ∑ k = 1 K α k 1 ( s ∈ A T k ) v_T(s)=\sum_{k=1}^{K}\alpha_k\mathbb{1}(s\in A_T^k) vT(s)=k=1∑Kαk1(s∈ATk)
其中
| 符号 | 含义 |
|---|---|
| v T ( s ) v_T(s) vT(s) | speaker s s s 在区域 T T T 的加权票数 |
| A T k A_T^k ATk | 第 k k k 个 hypothesis 在区域 T T T 预测的 speaker 集合 |
| 1 ( s ∈ A T k ) \mathbb{1}(s\in A_T^k) 1(s∈ATk) | 如果系统 k k k 在区域 T T T 预测 speaker s s s 活跃,则为 1 |
然后选择票数最高的 n ^ T \hat{n}_T n^T 个 speaker
A ^ T = T o p K s ( v T ( s ) , n ^ T ) \hat{A}T=\mathrm{TopK}{s}(v_T(s),\hat{n}_T) A^T=TopKs(vT(s),n^T)
最终,区域 T T T 的输出 speaker 集合就是 A ^ T \hat{A}_T A^T。
回到刚才的例子
text
系统 1: A + B
系统 2: A + B
系统 3: A假设三个系统权重差不多,那么
n ^ T = r o u n d ( 2 + 2 + 1 3 ) = 2 \hat{n}_T=\mathrm{round}\left(\frac{2+2+1}{3}\right)=2 n^T=round(32+2+1)=2
然后 speaker 票数大致是
text
A: 3 票
B: 2 票DOVER-Lap 会选择 top-2
text
A + B而原始 DOVER 只能输出一个 speaker,可能只输出
text
A四、复杂度分析
设有 K K K 个 hypothesis,每个 hypothesis 平均有 N N N 个 speaker。
DOVER 的 label mapping 使用 Hungarian algorithm 逐步两两匹配。
复杂度大致为
O ( K N 3 ) O(KN^3) O(KN3)
DOVER-Lap 需要先计算 cost tensor,再做 greedy matching。
cost tensor 的 pair-wise overlap 计算复杂度约为
O ( K 2 N 2 ) O(K^2N^2) O(K2N2)
greedy matching 需要排序所有 N K N^K NK 个 tuple,摊还复杂度约为
O ( K N K log N ) O(KN^K\log N) O(KNKlogN)
一般实际 diarization 融合里:
- 系统数量 K K K 通常不大;
- 每个 session 的 speaker 数 N N N 通常也不大;
- 论文实现中几秒内可以跑完。
因此它适合作为 offline diarization 系统的后处理融合模块。
五、实验结果
论文在两个数据集上验证 DOVER-Lap:
AMI mix-headsetLibriCSS
还展示了它可以用于多通道后融合。
5.1 AMI:DOVER-Lap 能超过单个最好系统
AMI mix-headset 的 dev/test overlap 比例大约都是 20 % 20\% 20%。
论文融合了三个 overlap-aware diarization 系统:
- VB-based overlap assignment
- overlap-aware spectral clustering
- region proposal network
结果如下:
| 方法 | Dev DER | Test DER |
|---|---|---|
| VB-based overlap assignment | 22.0 | 21.5 |
| Overlap-aware spectral clustering | 24.5 | 23.6 |
| Region proposal network | 35.3 | 25.5 |
| 输入系统平均 | 27.3 | 23.5 |
| DOVER | 36.5 | 30.5 |
| DOVER + global mapping | 26.0 | 25.0 |
| DOVER-Lap,不带 rank weighting | 24.1 | 22.8 |
| DOVER-Lap,带 rank weighting | 21.6 | 20.5 |
结论
-
原始 DOVER 在 overlap 场景下反而很差。
它只能输出单 speaker,overlap 区域会产生大量 missed speech。
-
只把 mapping 改成 global mapping,就能明显降低 confusion。
-
完整 DOVER-Lap 加 rank weighting 后,在 dev/test 上超过单个最好系统。
5.2 LibriCSS:不同系统优势互补
LibriCSS 是模拟会议数据,overlap 条件从 0 % 0\% 0% 到 40 % 40\% 40%。
论文融合了:
- VB
- overlap-aware SC
- RPN
- TS-VAD
平均 DER 结果:
| 方法 | Average DER |
|---|---|
| VB | 8.6 |
| SC | 9.3 |
| RPN | 9.5 |
| TS-VAD | 7.4 |
| DOVER-Lap | 5.4 |
分解错误如下:
| 方法 | Miss | FA | Confusion | DER |
|---|---|---|---|---|
| VB | 1.7 | 0.5 | 6.4 | 8.6 |
| SC | 2.5 | 1.1 | 5.7 | 9.3 |
| RPN | 2.9 | 3.3 | 3.3 | 9.5 |
| TS-VAD | 3.2 | 1.3 | 2.9 | 7.4 |
| DOVER-Lap | 2.7 | 0.7 | 2.0 | 5.4 |
结论
- VB / SC 的 detection 更好,Miss 和 FA 较低;
- RPN / TS-VAD 的 speaker confusion 更低;
- DOVER-Lap 把两类系统的优点结合起来,最终 DER 最低。
5.3 多通道后融合:不做 beamforming 也能融合
DOVER-Lap 不只可以融合不同系统,也可以融合不同通道。
text
7 个麦克风通道
-> 每个通道单独跑 diarization
-> 得到 7 个 hypothesis
-> 用 DOVER-Lap 后融合在 LibriCSS 7 通道实验中:
| 方法 | Miss | FA | Confusion | DER |
|---|---|---|---|---|
| 7-channel average | 2.58 | 0.96 | 5.86 | 9.40 |
| 7-channel best | 2.59 | 0.99 | 5.53 | 9.11 |
| WPE + Beamforming | 2.91 | 0.96 | 5.86 | 9.33 |
| DOVER-Lap late fusion | 3.60 | 0.66 | 4.76 | 9.02 |
结论
- 可以不做 beamforming;
- 不依赖前端增强;
- 可以直接融合每个通道的 diarization 输出;
- 对 ad-hoc microphone array 有潜在价值。
六、总结
DOVER-Lap 将 DOVER 推广到了重叠场景,适合多个不同 diarization 系统、同一个系统有多个配置、或是多通道 diarization 输出,是一种强有力的后融合算法。