📖标题:Beyond the Illusion of Consensus: From Surface Heuristics to Knowledge-Grounded Evaluation in LLM-as-a-Judge
🌐来源:arXiv, 2603.11027v1
🌟摘要
LLM-as-a-judge的范式依赖于一个关键假设,即评价者之间的高度一致表明评价是可靠和客观的。我们提出了两个互补的发现来挑战这一假设。首先,我们证明这种共识经常是虚幻的。我们识别并形式化评价幻觉,这是一种现象,LLM法官产生复杂的批评,但将分数锚定在共同的表面启发式而不是实质性质量上。通过对105,600个评估实例(32个LLM×3个前沿法官×100个任务×11个温度)的大规模研究,我们发现模型级协议(Spearmanρ=0.99)掩盖了脆弱的样本级协议(Pearson r=0.72;绝对协议ICC=0.67),仅仅共享规则结构就恢复了总协议的62%,而高质量的输出反而得到了最不一致的评估。其次,我们证明了基于领域知识的动态生成评估规则会产生更有意义的评估。我们引入了MERG(元认知增强规则生成),这是一个知识驱动的规则生成框架,其领域选择效应证实了这一点。在知识将评估者锚定在共享标准上的编纂领域(教育+22%,学术+27%),一致性增加,而在真正的评估多元化出现的主观领域,一致性减少。这些发现表明,评估标准应该用专家知识动态丰富,而不是依赖通用标准,这对RLAIF中的奖励建模有影响。
🛎️文章简介
🔸研究问题:大模型作为裁判时表现出的高一致性,究竟反映了真实的质量共识,还是基于表面启发式规则的虚假幻觉?
🔸主要贡献:论文形式化了"评估幻觉"概念,揭示了现有共识的脆弱性,并提出 MERG 框架证明引入领域知识能产生更具实质意义的评估。
📝重点思路
🔸提出"评估幻觉"理论,指出多个裁判的高分一致往往源于对格式、语气等表面特征的共享偏好,而非对内容实质的共同理解。
🔸设计 MERG(元认知增强评分标准生成)框架,强制裁判在打分前激活领域知识并反思自身偏见,从系统一快思考转向系统二慢思考。
🔸开展大规模实验,涉及 32 个模型、3 个前沿裁判及 10 万多次评估实例,通过对比基线与 MERG 结果来诊断共识的真实来源。
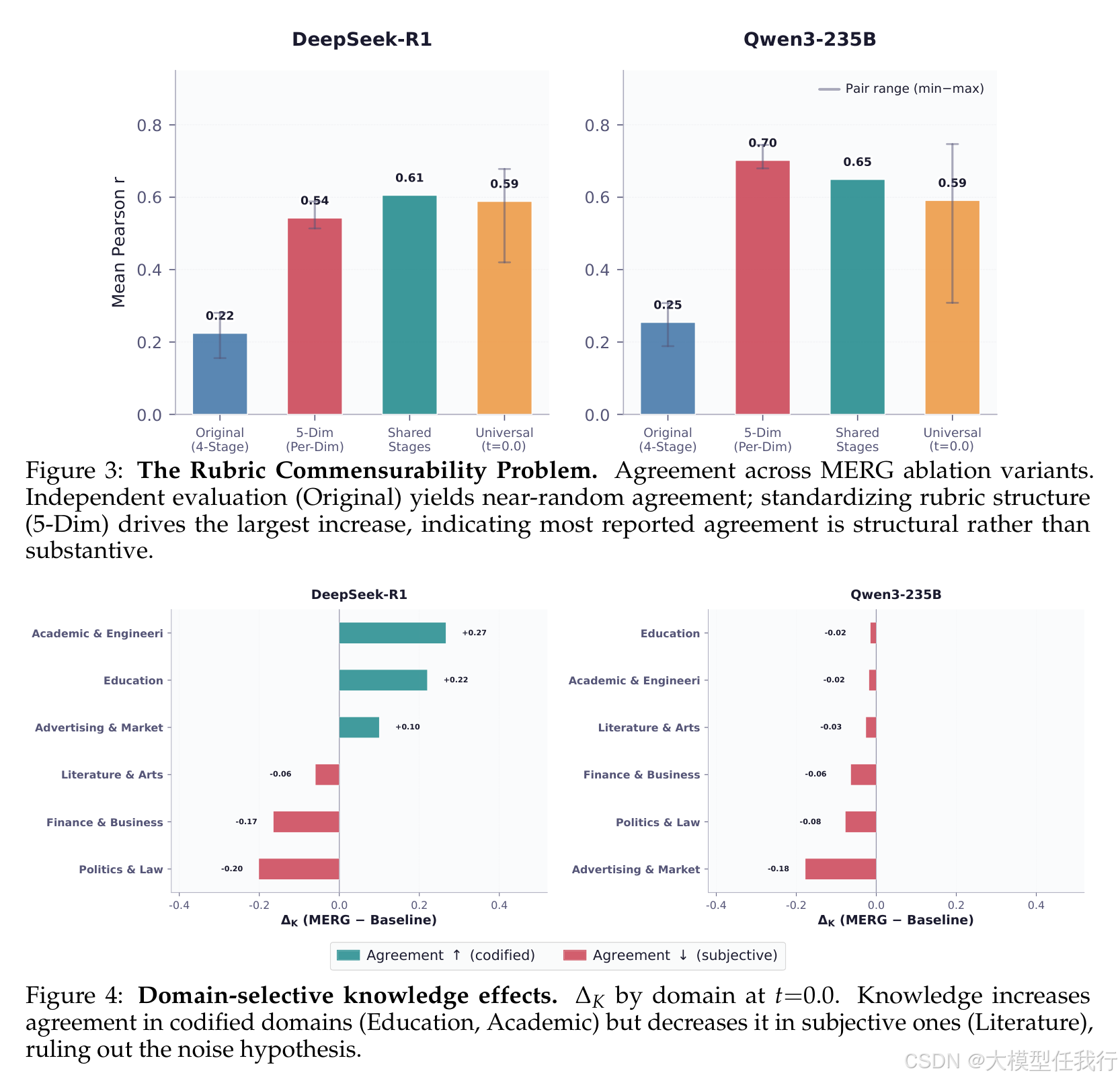
🔸利用消融实验分离评分标准结构的影响,量化了仅共享维度名称即可恢复大部分一致性,证明现有可靠性多为仪器 artifacts。
🔎分析总结
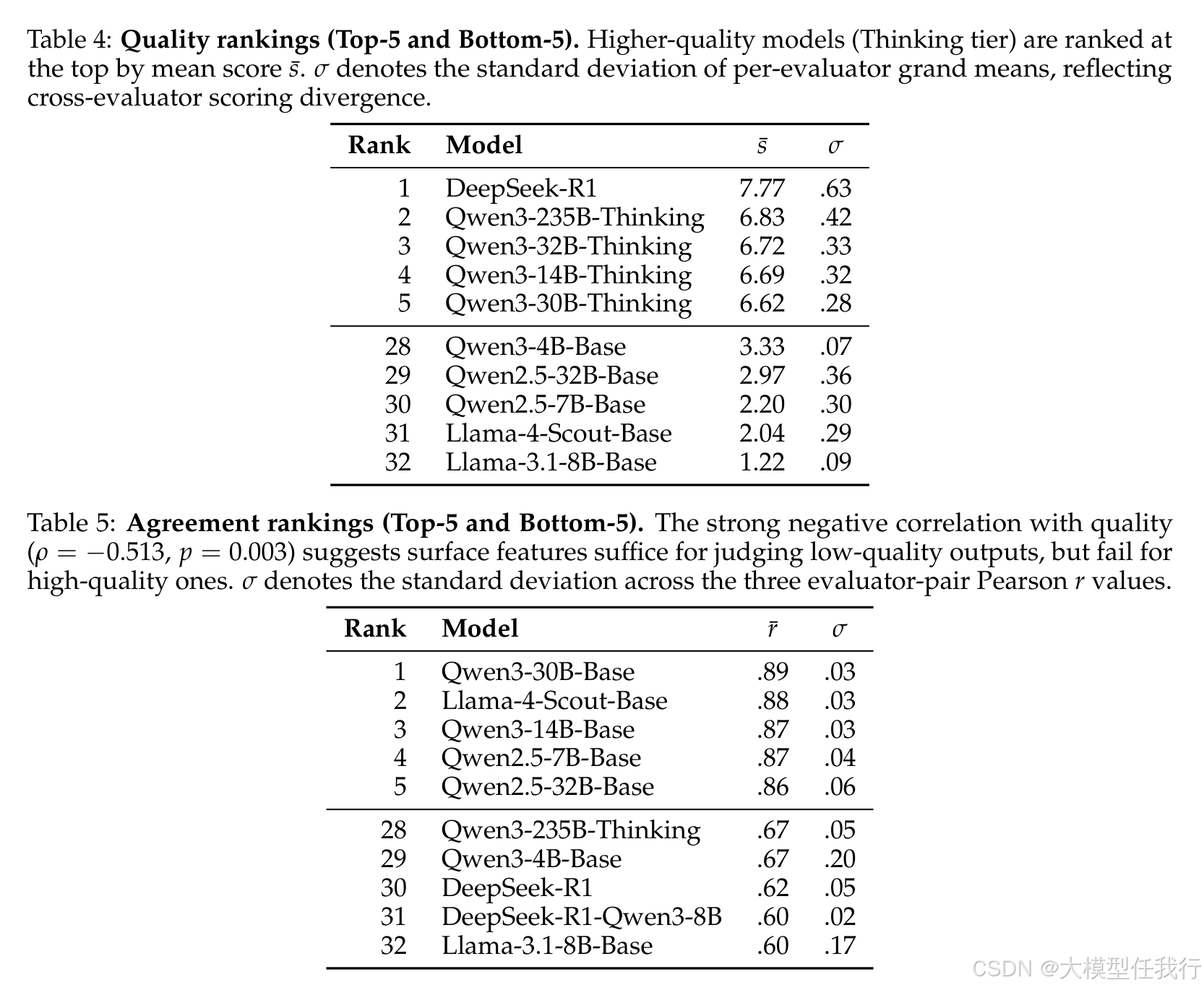
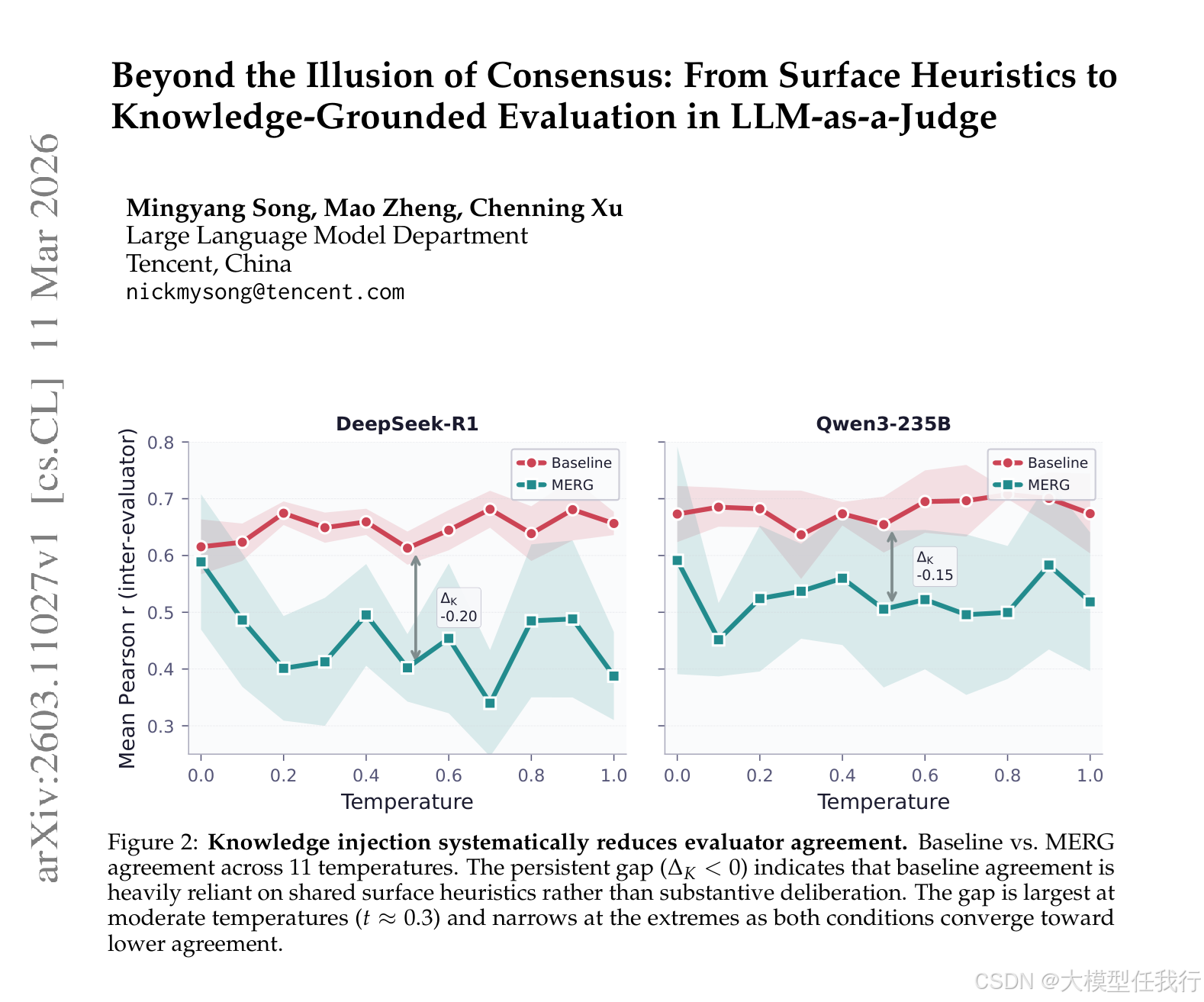
🔸注入领域知识后,裁判间的一致性显著下降(降低 21%-34%),证实基线共识主要由表面启发式驱动而非真实 deliberation。
🔸一致性变化具有领域选择性:在教育和学术等有明确标准的领域,知识注入提升了一致性;而在文学等主观领域则降低了虚假共识。
🔸发现"分辨率悖论",即模型层面的排名相关性极高(0.99),但样本层面的绝对一致性较低(0.72),高分输出反而最难获得一致评价。
🔸评分标准的结构本身解释了约 62% 的一致性,表明文献中报告的高可靠性很大程度上是共享评估工具的人为产物。
💡个人观点
论文颠覆了"高一致性即高可靠性"的传统假设,指出了当前自动化评估中存在的"共谋式浅层共识",发现高质量输出的评估最容易陷入幻觉。
🧩附录