🤖 浏览器自动化变天了!从 Playwright 到 PageAgent,CSDN/掘金编辑器为何成了"拦路虎"?
摘要:浏览器自动化正在经历从"脚本执行"到"智能代理"的范式转移。阿里开源的 PageAgent 让 AI"住进"网页,但面对 CSDN 的换行陷阱和掘金的 CodeMirror 黑盒,纯 DOM 自动化为何频频碰壁?本文深度解析技术演进与实战破局方案。
01 技术演进:三代浏览器自动化方案对比
浏览器自动化技术,正在经历一场从"机械执行"到"智能理解"的革命。
| 方案 | 核心原理 | 优势 | 局限 |
|---|---|---|---|
| Playwright/Selenium | 基于 DOM 选择器 + 预定义指令 | 稳定、成熟、生态完善 | 页面结构变化即失效,无法理解语义 |
| PageAgent | LLM + 页面内嵌 JS 框架 | 自然语言交互、纯前端、免部署 | 依赖 LLM、Token 成本 |
| OCBot | 视觉识别 + 多模态理解 | 不依赖 DOM 结构、鲁棒性强 | 计算资源消耗大、推理速度慢 |
📌 关键差异
传统方案(Playwright) 像是一个"盲眼执行者"------它能精准点击坐标,但不知道点击的是什么。
PageAgent 则像是一个"住在你网页里的智能助手"------它理解页面语义,能用自然语言对话,自主规划操作路径。
OCBot 更像是"视觉驱动的操作员"------通过截图和图像识别来定位元素,不依赖 DOM 结构。
02 PageAgent 深度解析:浏览器交互的新形态
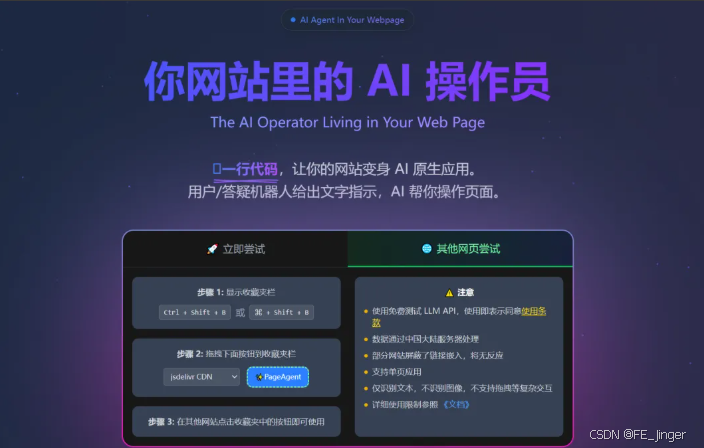
🌐 什么是 PageAgent?
PageAgent 是阿里开源的纯前端 JavaScript GUI 智能体框架,核心理念用一句话概括:
The GUI Agent Living in Your Webpage(住在你网页里的 GUI 智能体)
GitHub 地址:alibaba/page-agent
🔌 新载体:标签页/浏览器插件
PageAgent 不再是一个独立的黑盒程序,它化身为两种形态:
-
Side Panel(侧边栏)
- 在浏览器一侧常驻
- 实时感知当前标签页内容
- 实现"所见即所得"的辅助
-
Browser Extension(插件)
- 注入页面上下文
- 直接操作 DOM 或调用页面内部 JS 实例
- 打破沙箱限制
⚙️ 工作原理
┌─────────────────────────────────────────────────┐
│ 用户自然语言指令 │
│ "帮我把这篇文章发布到掘金" │
└─────────────────┬───────────────────────────────┘
▼
┌─────────────────────────────────────────────────┐
│ PageAgent 感知层 │
│ • DOM 树文本化 │
│ • Accessibility Tree 解析 │
│ • (可选)视觉截图 │
└─────────────────┬───────────────────────────────┘
▼
┌─────────────────────────────────────────────────┐
│ LLM 决策层 │
│ • 理解页面结构 │
│ • 规划操作序列 │
│ • 生成执行代码 │
└─────────────────┬───────────────────────────────┘
▼
┌─────────────────────────────────────────────────┐
│ 执行层 │
│ • 调用页面 JS 实例 │
│ • 模拟用户交互 │
│ • 观察反馈并自我修正 │
└─────────────────────────────────────────────────┘💡 核心优势
| 特性 | 传统方案 | PageAgent |
|---|---|---|
| 部署方式 | 需配服务器/无头浏览器 | 一行 script 标签 |
| 交互方式 | 编写代码 | 自然语言对话 |
| DOM 依赖 | 强依赖选择器 | 语义理解 + 实例调用 |
| 视觉识别 | 不支持 | 可选(但推荐跳过 OCR 省 Token) |
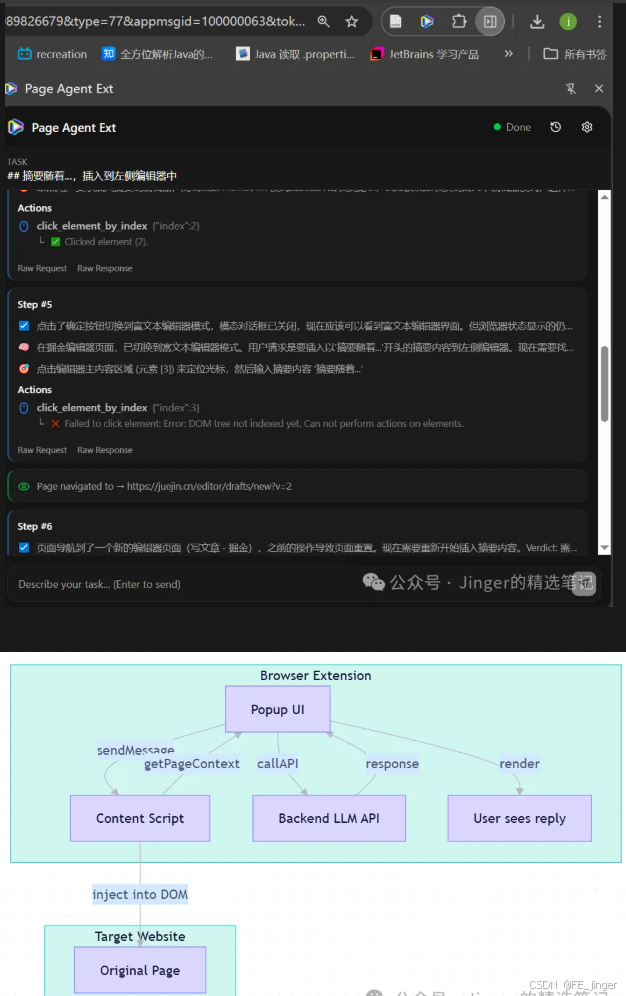
03 实战痛点:当 PageAgent 遇上"顽固"编辑器
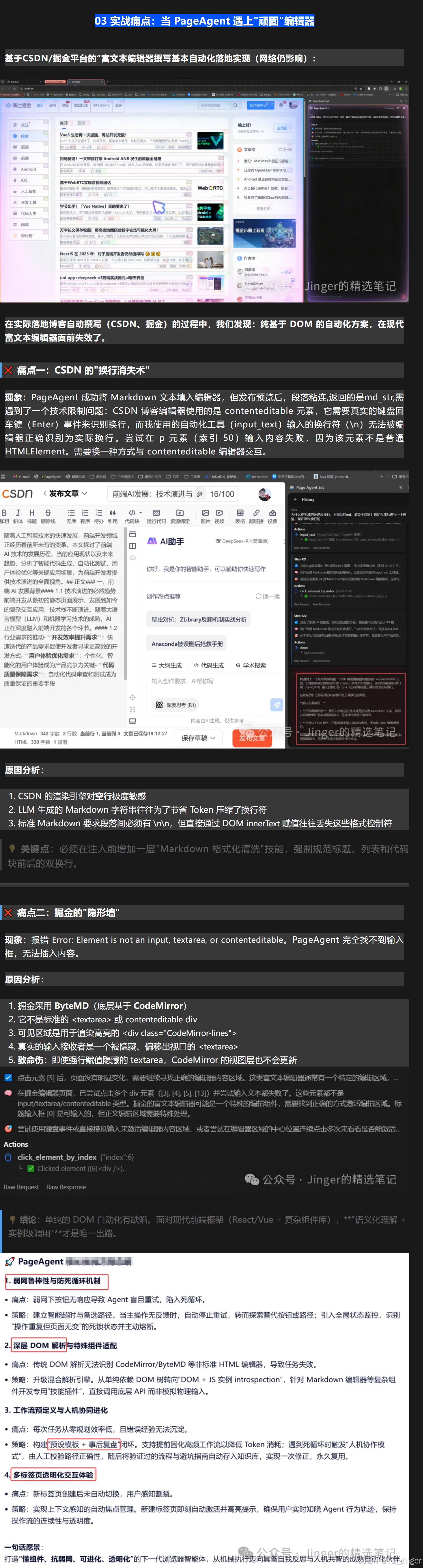
在实际落地博客自动撰写(CSDN、掘金)的过程中,我们发现:纯基于 DOM 的自动化方案,在现代富文本编辑器面前失效了。
❌ 痛点一:CSDN 的"换行消失术"
现象:PageAgent 成功将 Markdown 文本填入编辑器,但发布预览后,段落粘连,标题失效。
原因分析:
- CSDN 的渲染引擎对空行极度敏感
- LLM 生成的 Markdown 字符串往往为了节省 Token 压缩了换行符
- 标准 Markdown 要求段落间必须有
\n\n,但直接通过 DOMinnerText赋值往往丢失这些格式控制符
解决方案:
javascript
// Markdown 格式化清洗函数
function fixCsdnMarkdown(text) {
// 标题前后加空行
content = content.replace(/([^\n])(#{1,6}\s)/g, '$1\n\n$2');
// 代码块前后加空行
content = content.replace(/([^\n])(```)/g, '$1\n\n$2');
// 合并多余空行
content = content.replace(/\n{3,}/g, '\n\n');
return content;
}💡 关键点:必须在注入前增加一层"Markdown 格式化清洗"技能,强制规范标题、列表和代码块前后的双换行。
❌ 痛点二:掘金的"隐形墙"
现象 :报错 Error: Element is not an input, textarea, or contenteditable。PageAgent 完全找不到输入框,无法插入内容。
原因分析:
- 掘金采用 ByteMD (底层基于 CodeMirror)
- 它不是标准的
<textarea>或contenteditablediv - 可见区域是用于渲染高亮的
<div class="CodeMirror-lines"> - 真实的输入接收者是一个被隐藏、偏移出视口的
<textarea> - 致命伤:即使强行赋值隐藏的 textarea,CodeMirror 的视图层也不会更新
DOM 结构示意:
html
解决方案 :放弃 DOM 模拟打字,侵入式调用 JS 实例
javascript
// 获取 CodeMirror 实例并调用 API
const editorRoot = document.querySelector('.bytemd-editor .CodeMirror');
const cmInstance = editorRoot.CodeMirror; // 关键:获取实例
// 直接调用实例 API,而非操作 DOM
cmInstance.replaceRange(content, { line: lastLine, ch: 0 });
cmInstance.refresh(); // 强制刷新视图💡 结论:单纯的 DOM 自动化已死。面对现代前端框架(React/Vue + 复杂组件库),**"语义化理解 + 实例级调用"**才是唯一出路。
04 未来展望:小龙虾 + 飞书,打通最后一公里
🦞 "小龙虾"Agent 的跨界调用
我们计划将 PageAgent 的能力封装为"小龙虾"智能助手,不仅局限于浏览器,更要打通 IM 软件:
场景构想:
用户在飞书/微信中对"小龙虾"说:
"写一篇关于浏览器自动化的文章,发到掘金"
↓
1. 飞书/微信接收指令
2. 唤醒后端 PageAgent 服务
3. Agent 无头浏览器运行,完成撰写与发布
4. 结果回推至 IM 对话框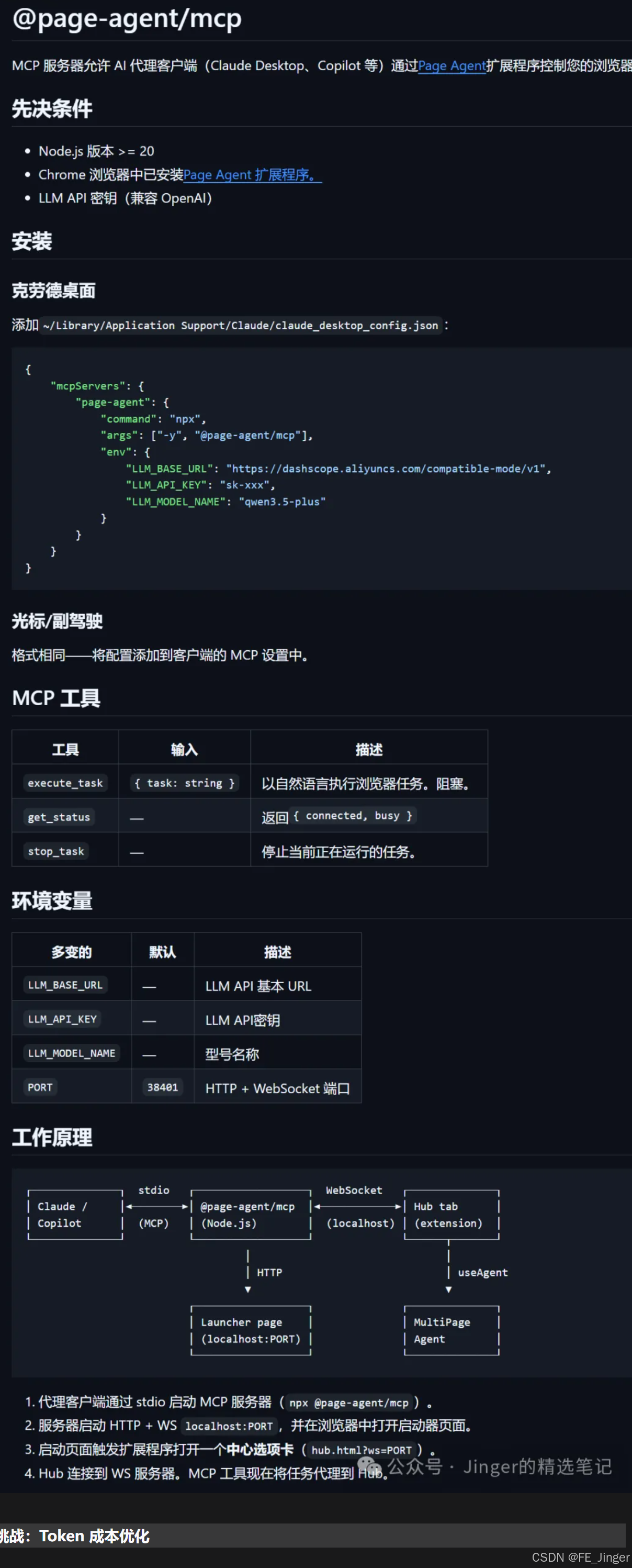
💰 挑战:Token 成本优化
全链路使用大模型(LLM)进行页面理解和操作,Token 消耗巨大,难以规模化。
待探索方向:
| 优化策略 | 说明 | 预期效果 |
|---|---|---|
| 小模型蒸馏 | 对于固定的 DOM 操作,训练专门的微小模型替代通用 LLM | 降低 70%+ Token |
| 规则 + AI 混合 | 已知站点使用硬编码"技能脚本",未知站点才启用 LLM 推理 | 降低 50%+ Token |
| 上下文压缩 | 仅向 LLM 传递关键的 DOM 片段,而非整页源码 | 降低 30%+ Token |
| 缓存复用 | 相同页面的操作序列缓存复用 | 降低 40%+ Token |
05 总结与建议
📊 技术选型建议
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 标准化测试 | Playwright | 稳定、成熟、生态完善 |
| 复杂网页交互 | PageAgent | 语义理解、自然语言交互 |
| 动态渲染页面 | OCBot | 视觉识别、不依赖 DOM |
| 已知站点自动化 | 混合方案 | 规则 + AI,成本最优 |
🎯 核心结论
- 纯 DOM 自动化已不足以应对现代前端框架
- PageAgent 代表了"浏览器内嵌 Agent"的新方向
- CSDN/掘金等编辑器的痛点需要"实例级调用"解决
- Token 成本是规模化的关键瓶颈,需混合方案优化
参考资料:
- PageAgent 官方文档:alibaba.github.io/page-agent
- GitHub:github.com/alibaba/page-agent
- OCBot:github.com/instry/ocbot