1.基础查询
去重关键字DISTINCT
需要从 user_profile 表中获取所有不同的大学名称
sql
select distinct university
from user_profile;SELECTDISTINCTuniversity: 选择university列,并去除重复的值。FROM user_profile: 从user_profile表中获取数据。
查询结果限制返回行数
需要从 user_profile 表中选择 device_id 列,并只返回前两个用户的设备ID。
sql
select device_id
from user_profile
limit 2;LIMIT子句用于限制查询结果的行数。LIMIT 2: 限制返回的结果为前两行。
将查询后的列重新命名
从 user_profile 表中选择 device_id 列,并只返回前两个用户的设备ID,同时将结果列名更改为 user_infos_example。
sql
select device_id as user_infos_example
from user_profile
limit 2;SELECT device_id AS user_infos_example: 选择device_id列,并将其重命名为user_infos_example。FROM user_profile: 从user_profile表中获取数据。LIMIT 2: 限制返回的结果为前两行。
2.条件查询
查找后排序
从 user_profile 表中选择 device_id 和 age 列,并将结果按照 age 升序排列。
sql
select device_id,age
from user_profile
order by age;SELECT device_id, age: 选择device_id和age列。FROM user_profile: 从user_profile表中获取数据。ORDER BY age ASC: 按照age升序排列结果。默认是升序
查找后多列排序
从 user_profile 表中选择 device_id、age 和 gpa 列,并将结果按照 gpa 升序排序,如果 gpa 相同,则再按照 age 升序排序。
sql
select device_id,gpa,age
from user_profile
order by gpa,age;SELECT device_id, gpa, age: 选择device_id、gpa和age列。FROM user_profile: 从user_profile表中获取数据。ORDER BY gpa ASC, age ASC: 先按照gpa升序排序,再按照age升序排序。
查找后降序排列
从 user_profile 表中选择 device_id、gpa 和 age 列,并将结果按照 gpa 降序排序,如果 gpa 相同,则再按照 age 降序排序。
sql
select device_id,gpa,age
from user_profile
order by gpa desc,age desc;SELECT device_id, gpa, age: 选择device_id、gpa和age列。FROM user_profile: 从user_profile表中获取数据。ORDER BY gpa DESC, age DESC: 先按照gpa降序排序,再按照age降序排序。
简单条件查找
sql
select device_id,university
from user_profile
where university='北京大学';
sql
select device_id,gender,age,university
from user_profile
where age>24;查找某个年龄段的用户信息
sql
select device_id,gender,age
from user_profile
where age between 20 and 23;查找除复旦大学的用户信息
sql
select device_id,gender,age,university
from user_profile
where university!='复旦大学';找到male且GPA在3.5以上(不包括3.5)的用户
sql
select device_id,gender,age,university,gpa
from user_profile
where gender = 'male' and gpa>3.5;找到学校为北大或GPA在3.7以上(不包括3.7)的用户
sql
select device_id,gender,age,university,gpa
from user_profile
where university='北京大学' or gpa>3.7;找到gpa在3.5以上(不包括3.5)的山东大学用户 或 gpa在3.8以上(不包括3.8)的复旦大学同学进行用户调研,请你取出相应数据,取出的数据按照device_id升序排列
sql
select device_id,gender,age,university,gpa
from user_profile
where (gpa > 3.5 and university = '山东大学')
or (gpa > 3.8 and university = '复旦大学')
order by device_id;where过滤空值
从 user_profile 表中选择 device_id、gender、age 和 university 列,并且只返回 age 不为空的记录。
sql
select device_id,gender,age,university
from user_profile
where age is not NULL;WHERE age IS NOT NULL: 只返回age不为空的记录。
Where in 和Not in
只返回 university 为"北京大学"、"复旦大学"或"山东大学"的记录。
sql
select device_id,gender,age,university,gpa
from user_profile
where university in ('北京大学', '复旦大学', '山东大学');WHERE university IN ('北京大学', '复旦大学', '山东大学'): 使用IN运算符筛选出满足任一条件的记录。
查看学校名称中含北京的用户
只返回 university 列中包含"北京"字样的记录。
sql
select device_id,age,university
from user_profile
where university like '%北京%';3.高级查询
查找GPA最高值
只返回 university 为"复旦大学"的记录中的最高 GPA 值
sql
select format(gpa,1) as gpa
from user_profile
where university='复旦大学'
order by gpa desc
limit 1;
sql
select format(max(gpa),1) as gpa
from user_profile
where university='复旦大学';SELECT FORMAT(MAX(gpa), 1) AS gpa: 选择gpa的最大值,并使用FORMAT()函数将其格式化为小数点后1位。
计算男生人数以及平均GPA
从 user_profile 表中选择 gender 为"male"的记录,并计算这些记录的数量和 GPA 的平均值。
sql
select count(*) as male_num,
format(avg(gpa),1) as avg_gpa
from user_profile
where gender = 'male';SELECT COUNT(*) AS male_num: 计算gender为"male"的记录数量,并将结果命名为male_num。ROUND(AVG(gpa), 1) AS avg_gpa: 计算gpa的平均值,并使用ROUND()函数保留到小数点后1位,结果命名为avg_gpa。FROM user_profile: 从user_profile表中获取数据。WHERE gender = 'male': 只返回gender为"male"的记录。
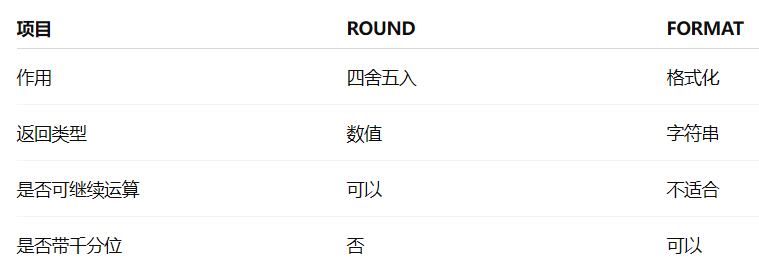
分组过滤
现在运营想查看每个学校用户的平均发贴和回帖情况,寻找低活跃度学校进行重点运营,请取出平均发贴数低于5的学校或平均回帖数小于20的学校。
sql
select
university,
round(avg(question_cnt), 3) as avg_question_cnt,
round(avg(answer_cnt), 3) as avg_answer_cnt
from
user_profile
group by
university
having
avg(answer_cnt) < 20
or avg(question_cnt) < 5;选择_从什么表,按照学校分组,选择不用where语句而是having
分组排序练习题
题目:现在运营想要查看不同大学的用户平均发帖情况,并期望结果按照平均发帖情况进行升序排列,请你取出相应数据。
sql
select university,
round(avg(question_cnt),4) as avg_question_cnt
from user_profile
group by university
order by avg(question_cnt);多表查询
设有两张表:
A 表:user_profile
| device_id | university |
|---|---|
| 2138 | 北京大学 |
| 2315 | 浙江大学 |
| 4321 | 复旦大学 |
B 表:question_practice_detail
| device_id | question_id | result |
|---|---|---|
| 2138 | 111 | wrong |
| 2315 | 115 | right |
| 2315 | 116 | right |
| 9999 | 120 | wrong |
我们通常按 device_id 连接。
1. 内连接 INNER JOIN(只保留两张表中能够匹配上的记录)
含义:只保留两张表中能够匹配上的记录。
sql
SELECT *
FROM user_profile u
INNER JOIN question_practice_detail q
ON u.device_id = q.device_id;结果只会保留:
-
2138能匹配 -
2315能匹配
4321 在答题表里没有,不要
9999 在用户表里没有,也不要
特点
内连接取的是两表的交集。
考试里怎么理解
就是"有对应关系的才留下"。
2. 左外连接 LEFT JOIN(左表所有记录都保留,右表匹配不上就补 NULL)
含义:以左表为主,左表所有记录都保留,右表匹配不上就补 NULL。
sql
SELECT *
FROM user_profile u
LEFT JOIN question_practice_detail q
ON u.device_id = q.device_id;结果会保留 user_profile 的所有用户:
-
2138匹配上,显示题目数据 -
2315匹配上,显示题目数据 -
4321匹配不上,但这一行仍然保留,question_id、result为NULL
特点
左连接取的是:
左表全部 + 右表中能匹配上的部分
适用场景
比如要查:
-
所有用户及其答题情况
-
即使没答题的用户也要显示出来
3. 右外连接 RIGHT JOIN(右表所有记录都保留,左表匹配不上就补 NULL)
含义:以右表为主,右表所有记录都保留,左表匹配不上就补 NULL。
sql
SELECT *
FROM user_profile u
RIGHT JOIN question_practice_detail q
ON u.device_id = q.device_id;结果会保留 question_practice_detail 的所有答题记录:
-
2138、2315能匹配上 -
9999匹配不上用户信息,但仍会保留,用户表那边字段为NULL
特点
右连接取的是:
右表全部 + 左表中能匹配上的部分
说明
实际开发里,右连接用得比左连接少。
因为把表顺序交换一下,很多右连接都能改写成左连接。
4. 全外连接 FULL OUTER JOIN(两边的记录都保留,匹配上的合并,匹配不上的补 NULL)
含义:两边的记录都保留,匹配上的合并,匹配不上的补 NULL。
sql
SELECT *
FROM user_profile u
FULL OUTER JOIN question_practice_detail q
ON u.device_id = q.device_id;结果会保留:
-
2138、2315这种匹配上的 -
4321这种左边独有的 -
9999这种右边独有的
特点
全外连接取的是两表的并集。
注意
有些数据库系统对 FULL OUTER JOIN 支持不好,比如 MySQL 早期版本不直接支持。
5. 交叉连接 CROSS JOIN(两张表做笛卡尔积)
含义:两张表做笛卡尔积。
sql
SELECT *
FROM user_profile
CROSS JOIN question_practice_detail;如果 A 表有 3 行,B 表有 4 行,结果就是 3 × 4 = 12 行。
特点
不需要连接条件,所有行两两配对。
适用场景
一般不常直接用,除非题目明确要求笛卡尔积,或者某些特殊组合场景。
危险点
如果忘了写连接条件,有时就会意外得到笛卡尔积,结果数量暴增。
子查询
sql
SELECT u.device_id,q.question_id,q.result
from question_practice_detail q
inner join user_profile u
where university = '浙江大学'and q.device_id=u.device_id
order by question_id;链接查询
统计每个学校的答过题的用户的平均答题数
sql
select u.university,
round(count(q.question_id)/ count(distinct(u.device_id)),4) as avg_answer_cnt
from user_profile u
inner join question_practice_detail q
on u.device_id = q.device_id
group by u.university;
# 该学校用户答题总次数除以答过题的不同用户个数组合查询
现在运营想要分别查看学校为山东大学或者性别为男性的用户的device_id、gender、age和gpa数据,请取出相应结果,结果不去重。
(注意输出的顺序,先输出学校为山东大学再输出性别为男生的信息)
sql
select device_id,gender,age,gpa
from user_profile
where university='山东大学'
union all
select device_id,gender,age,gpa
from user_profile
where gender = 'male';case函数
sql
CASE 测试表达式
WHEN 简单表达式1 THEN 结果表达式1
WHEN 简单表达式2 THEN 结果表达式2 ...
WHEN 简单表达式n THEN 结果表达式n
[ ELSE 结果表达式n+1 ]
END题目:现在运营想要将用户划分为25岁以下和25岁及以上两个年龄段,分别查看这两个年龄段用户数量
本题注意:age为null 也记为 25岁以下
根据示例,你的查询应返回以下结果:
|---------|--------|
| age_cut | number |
| 25岁以下 | 4 |
| 25岁及以上 | 3 |
sql
select
case when age < 25 or age is NULL then '25岁以下'
else '25岁及以上'
end as age_cut,
count(*) as number
from user_profile
group by age_cut;题目:现在运营想要将用户划分为20岁以下,20-24岁,25岁及以上 三个年龄段,分别查看不同年龄段用户的明细情况,请取出相应数据。(注:若年龄为空 请返回其他。)
sql
select device_id,gender,
case when age < 20 then '20岁以下'
when age between 20 and 24 then '20-24岁'
when age >= 25 then '25岁及以上'
else '其他'
end as age_cut
from user_profile;