一、Agent 与 LangGraph 概述
1.1 为什么需要 Agent?RAG 的能力边界
1.1.1 RAG 系统的本质局限
经过前边的学习,我们已经搭建了工业级 RAG 系统,但它本质上是一个被动的信息检索与生成系统,存在三个无法突破的边界:
- 知识边界:只能回答知识库中存在的静态信息,无法处理需要计算、推理、实时数据或外部操作的任务
- 能力边界:只能生成文本,无法执行任何实际操作(如调用 API、操作数据库、发送邮件)
- 逻辑边界:只能进行单步推理,无法处理需要多步骤规划、迭代优化的复杂任务
工业级场景对比:
| 任务类型 | RAG 能否完成 | Agent 能否完成 |
|---|---|---|
| "公司的出差补贴标准是什么?" | ✅ | ✅ |
| "我出差 3 天,每天补贴 150 元,能报销多少钱?" | ❌(需要计算) | ✅ |
| "帮我生成这趟出差的报销单并提交审批" | ❌(需要执行操作) | ✅ |
| "分析上季度的销售数据,找出增长最快的产品线" | ❌(需要数据处理 + 分析) | ✅ |
1.1.2 Agent 的核心定义与价值
Agent(智能体)是一种能够自主感知环境、制定计划、执行行动、迭代优化以完成特定目标的智能系统。它的核心价值在于:
- 工具使用能力:通过调用外部工具突破大模型自身的能力边界
- 自主规划能力:将复杂任务分解为可执行的子任务
- 迭代反思能力:根据执行结果调整策略,纠正错误
- 长期记忆能力:记住历史交互和学习经验,实现个性化服务
1.2 Agent 四大核心组件与工作原理
一个工业级 Agent 系统由四个不可缺少的核心组件组成:
| 组件 | 作用 | 工业级要求 |
|---|---|---|
| 规划器(Planner) | 分解任务、制定执行计划、动态调整策略 | 支持多步骤规划、错误修正、任务优先级排序 |
| 工具集(Tools) | Agent 可以调用的外部能力集合 | 标准化接口、权限控制、错误处理、重试机制 |
| 记忆系统(Memory) | 存储对话历史、执行过程、长期知识 | 短期记忆(会话内)、长期记忆(跨会话)、状态持久化 |
| 执行器(Executor) | 执行工具调用、生成最终回答 | 支持并行执行、流式输出、异常处理 |
Agent 标准工作流程:

1.3 为什么选择 LangGraph?从 Legacy Agent 到工业级框架
1.3.1 Legacy Agent 的致命缺陷
LangChain 早期的 Agent 实现(如ZeroShotAgent、ReActAgent)在 2024 年已被完全废弃,因为它们存在以下无法解决的问题:
- 黑盒化:执行过程完全不透明,无法调试和定制
- 灵活性差:只能使用预设的工作流,无法实现循环、分支、并行等复杂逻辑
- 状态管理混乱:没有统一的状态存储机制,无法实现断点续跑和长对话
- 可靠性低:工具调用格式错误率高,容易陷入无限循环
1.3.2 LangGraph 的工业级优势
LangGraph 是 LangChain 团队专为构建生产级 Agent 和复杂工作流设计的声明式框架,解决了 Legacy Agent 的所有问题:
- 声明式设计:用图的方式清晰定义工作流,代码即文档
- 完全可观测:与 LangSmith 深度集成,可追踪每一步执行过程
- 强大的状态管理:原生支持状态持久化、多会话隔离、断点续跑
- 灵活的控制流:支持循环、分支、并行、中断、人类介入等所有控制流
- 原生工具调用:与 LangChain 工具生态无缝集成,支持并行工具调用
- 高性能:原生支持异步和流式输出,满足生产环境性能要求
1.3.3 LangGraph 与传统工作流工具的对比
| 特性 | LangGraph | Airflow/Prefect | 普通编程 |
|---|---|---|---|
| 设计目标 | 大模型 Agent 与动态工作流 | 定时任务与静态工作流 | 通用编程 |
| 状态管理 | 原生支持,自动持久化 | 有限支持 | 需要手动实现 |
| 动态性 | 支持运行时动态调整流程 | 流程固定,编译后无法修改 | 完全灵活 |
| 大模型集成 | 原生深度集成 | 需要手动集成 | 需要手动集成 |
| 可观测性 | 专为大模型设计的追踪 | 通用任务追踪 | 需要手动实现 |
| 适用场景 | Agent、智能工作流、多轮对话 | 数据管道、定时任务 | 所有场景 |
1.4 LangGraph 四大核心概念深度解析
LangGraph 的核心思想是将智能体的执行过程表示为一个有向图,所有逻辑都围绕以下四个概念展开:
1.4.1 State(状态)
- 定义:智能体的全局共享内存,存储所有上下文信息、执行过程、中间结果和最终输出
- 工业级要求:类型安全、可序列化、支持增量更新、可持久化
- 实现方式 :
- 简单场景:
TypedDict(轻量,无验证) - 生产场景:
Pydantic BaseModel(推荐,提供类型安全和数据验证)
- 简单场景:
- 关键特性 :支持增量更新(使用
Annotated[Type, operator.add]),避免覆盖历史数据
1.4.2 Node(节点)
- 定义:图中的可执行单元,对应一个具体的操作(思考、调用工具、生成回答等)
- 输入:当前的 State
- 输出:State 的更新部分(不需要返回完整 State,LangGraph 会自动合并)
- 类型 :
- 普通节点:自定义 Python 函数
- 工具节点:
ToolNode(LangGraph 内置,专门处理工具调用) - 条件节点:根据 State 值决定下一个执行节点
1.4.3 Edge(边)
- 定义:连接节点的有向边,定义执行流程和控制逻辑
- 类型 :
- 普通边:顺序执行,从一个节点直接跳转到下一个节点
- 条件边:根据 State 中的值动态决定下一个执行节点(实现分支和循环)
- 入口边:定义图的起始节点
- 结束边 :指向
END,表示图执行结束
1.4.4 Graph(图)
- 定义:由节点和边组成的有向图,是 LangGraph 的最高层抽象
- 编译:将图定义编译为可执行对象,同时可以配置检查点、中断等高级功能
- 运行方式 :
invoke():同步运行,返回最终结果stream():流式运行,返回中间结果和最终结果ainvoke()/astream():异步运行,适合生产环境
1.5 ReAct 框架原理解析
ReAct(Reasoning + Acting)是目前工业界应用最广泛的 Agent 框架,由 Google Research 在 2022 年提出。它的核心思想是让大模型交替进行思考和行动,通过工具调用获取外部信息,然后基于新的信息继续思考,直到完成任务。
ReAct 标准提示词模板:
bash
你是一个有用的AI助手,能够使用工具来完成任务。
你可以使用以下工具:
{tools}
使用工具时,请按照以下格式:
Thought: 我需要使用工具来解决这个问题
Action: 工具名称
Action Input: 工具参数
Observation: 工具返回的结果
当你获得足够的信息后,直接回答用户的问题。
不要编造信息,所有回答必须基于观察结果。二、LangGraph 工业级 API 详解
2.1 环境准备
首先更新requirements.txt,添加 LangGraph 1.2 + 和相关依赖:
python
langgraph>=1.2.0
pydantic>=2.0.02.2 状态定义:Pydantic vs TypedDict
工业级推荐使用 Pydantic BaseModel 定义状态,提供更强的类型安全和数据验证:
python
from typing import List, Annotated
from pydantic import BaseModel, Field
from langchain_core.messages import BaseMessage
import operator
class AgentState(BaseModel):
"""Agent状态定义(工业级标准)"""
# 对话历史:使用operator.add实现增量更新,不会覆盖历史消息
messages: Annotated[List[BaseMessage], operator.add] = Field(default_factory=list, description="对话历史")
# 迭代次数:用于防止无限循环
iteration_count: int = Field(default=0, description="当前迭代次数")
# 最大迭代次数:安全限制
max_iterations: int = Field(default=5, description="最大迭代次数")2.3 原生工具调用:bind_tools + ToolNode
LangGraph 1.2 + 原生支持 LangChain 工具调用,完全不需要手动解析 JSON,这是工业级开发的标准方式:
python
from langgraph.graph import StateGraph, END
from langgraph.prebuilt import ToolNode
from core.llm_factory import LLMFactory
# 1. 定义工具
@tool
def add(a: int, b: int) -> int:
"""加法工具,计算两个数的和"""
return a + b
tools = [add]
# 2. 将工具绑定到LLM
llm = LLMFactory.get_llm()
llm_with_tools = llm.bind_tools(tools)
# 3. 定义思考节点
def agent_node(state: AgentState) -> dict:
"""思考节点:调用LLM生成回答或工具调用"""
response = llm_with_tools.invoke(state.messages)
# 增加迭代次数
return {"messages": [response], "iteration_count": state.iteration_count + 1}
# 4. 使用内置ToolNode处理工具调用
tool_node = ToolNode(tools)
# 5. 定义路由函数
def router(state: AgentState) -> str:
"""路由函数:决定下一步是调用工具还是结束"""
last_message = state.messages[-1]
# 检查是否有工具调用
if last_message.tool_calls:
# 检查是否超过最大迭代次数
if state.iteration_count >= state.max_iterations:
return END
return "tools"
return END
# 6. 构建图(使用StateGraph,这是唯一正确的方式)
builder = StateGraph(AgentState)
builder.add_node("agent", agent_node)
builder.add_node("tools", tool_node)
builder.add_edge("tools", "agent")
builder.add_conditional_edges("agent", router)
builder.set_entry_point("agent")
graph = builder.compile()2.4 Checkpoint 机制:状态持久化与断点续跑
Checkpoint 是 LangGraph 最重要的生产级特性,它可以自动保存 Agent 的执行状态,实现:
- 断点续跑:程序中断后可以从上次中断的地方继续执行
- 多会话隔离:不同用户的会话状态互不干扰
- 历史回溯:查看 Agent 的完整执行历史
- 人类介入:在执行过程中暂停,等待人类确认后继续
python
from langgraph.checkpoint.sqlite import SqliteSaver
# 使用SQLite作为Checkpoint存储(生产环境可替换为PostgreSQL)
checkpointer = SqliteSaver.from_conn_string("./data/agent_checkpoints.db")
# 编译图时添加checkpointer
graph = builder.compile(checkpointer=checkpointer)
# 运行时指定thread_id,实现多会话隔离
config = {"configurable": {"thread_id": "user_123"}}
# 第一次运行
result = graph.invoke(
{"messages": [HumanMessage(content="计算2+3*4")]},
config=config
)
print(result["messages"][-1].content)
# 同一个thread_id可以继续对话
result = graph.invoke(
{"messages": [HumanMessage(content="再乘以5等于多少?")]},
config=config
)
print(result["messages"][-1].content)三、核心实战:工业级 ReAct Agent 实现
3.1 第一步:工具定义与工业级最佳实践
工具是 Agent 能力的延伸,定义良好的工具是 Agent 成功的关键。
代码位置 :core/tools.py(完全重写,符合工业级标准)
python
from typing import Optional, Type
from langchain.tools import tool
from pydantic import BaseModel, Field
from core.rag_retriever import RAGRetriever
from core.llm_factory import LLMFactory
from utils.logger import logger
import datetime
# ===================== 工具输入参数定义 =====================
class CalculatorInput(BaseModel):
expression: str = Field(description="要计算的数学表达式,仅支持加减乘除和括号,例如:'2 + 3 * (4 - 1)'")
class RAGInput(BaseModel):
query: str = Field(description="要检索的问题,必须是清晰、具体的问题")
class CurrentTimeInput(BaseModel):
format: str = Field(default="%Y-%m-%d %H:%M:%S", description="时间格式,默认为'YYYY-MM-DD HH:MM:SS'")
# ===================== 工具实现 =====================
@tool(args_schema=CalculatorInput, handle_tool_error=True)
def calculator(expression: str) -> str:
"""
数学计算器工具,用于执行基本的数学计算。
仅支持加减乘除(+、-、*、/)和括号运算。
所有数学问题都必须使用此工具,不要自己计算。
"""
try:
# 安全计算:只允许基本数学运算,禁止执行任意代码
allowed_chars = set("0123456789+-*/(). ")
if not all(c in allowed_chars for c in expression):
return "错误:表达式包含非法字符,仅支持数字和加减乘除括号"
# 使用eval但限制命名空间,防止代码注入
result = eval(expression, {"__builtins__": None}, {})
return f"计算结果:{expression} = {result}"
except Exception as e:
logger.error(f"计算器工具执行失败:{e}")
return f"计算错误:{str(e)},请检查表达式是否正确"
@tool(args_schema=RAGInput, handle_tool_error=True)
def enterprise_knowledge_base(query: str) -> str:
"""
企业知识库检索工具,用于获取企业内部的规章制度、产品信息、流程规范等知识。
当用户的问题与企业内部信息相关时,必须使用此工具。
"""
try:
retriever = RAGRetriever()
docs = retriever.retrieve(query, top_k=3)
if not docs:
return "知识库中没有找到相关信息,请尝试换一种问法"
# 格式化检索结果
result = "从知识库中检索到以下信息:\n"
for i, doc in enumerate(docs):
result += f"[{i+1}] {doc.page_content}\n\n"
return result.strip()
except Exception as e:
logger.error(f"知识库检索失败:{e}")
return f"知识库检索失败:{str(e)}"
@tool(args_schema=CurrentTimeInput, handle_tool_error=True)
def get_current_time(format: str = "%Y-%m-%d %H:%M:%S") -> str:
"""
获取当前时间的工具。
当用户询问当前时间、日期或需要时间相关的信息时使用此工具。
"""
try:
current_time = datetime.datetime.now().strftime(format)
return f"当前时间:{current_time}"
except Exception as e:
logger.error(f"获取当前时间失败:{e}")
return f"获取时间失败:{str(e)}"
# ===================== 工具集合 =====================
# 生产环境工具集合,只包含经过安全审核的工具
PRODUCTION_TOOLS = [calculator, enterprise_knowledge_base, get_current_time]
# 工具名称到工具对象的映射
TOOL_MAP = {tool.name: tool for tool in PRODUCTION_TOOLS}工业级工具定义最佳实践:
- 强制使用 Pydantic 定义输入参数:提供类型安全和自动验证,减少工具调用错误
- 编写详细的工具描述:明确告诉大模型工具的作用、使用场景和参数要求
- 开启 handle_tool_error:工具内部异常会被自动捕获并返回给大模型,让它尝试修正
- 严格的安全限制:禁止工具执行任意代码、访问敏感资源
- 完善的日志记录:记录所有工具调用和结果,便于调试和审计
- 输入输出过滤:过滤敏感信息,防止数据泄露
3.2 第二步:Agent 状态与系统提示词
代码位置 :core/react_agent.py(新建文件)
python
from typing import List, Annotated
from pydantic import BaseModel, Field
from langchain_core.messages import BaseMessage
from langgraph.graph import MessageGraph, END
from langgraph.prebuilt import ToolNode
from langgraph.checkpoint.sqlite import SqliteSaver
from core.llm_factory import LLMFactory
from core.tools import PRODUCTION_TOOLS
from utils.logger import logger
import operator
class AgentState(BaseModel):
"""ReAct Agent状态"""
messages: Annotated[List[BaseMessage], operator.add] = Field(default_factory=list)
iteration_count: int = Field(default=0)
max_iterations: int = Field(default=5)
# 系统提示词(工业级优化版)
SYSTEM_PROMPT = """
你是企业内部智能助手,只能使用提供的工具来回答问题。
你必须严格遵守以下规则:
1. 所有回答必须基于工具返回的结果,绝对不能编造信息
2. 当需要计算、获取企业内部信息或当前时间时,必须使用对应的工具
3. 每次只能调用一个工具,不要同时调用多个工具
4. 如果工具返回的信息不足以回答问题,可以尝试换一种方式调用工具
5. 如果多次调用工具仍然无法获得答案,直接告诉用户无法回答
6. 回答要简洁、准确、专业,符合企业内部沟通规范
你可以使用以下工具:
{tools_description}
"""
# 生成工具描述
tools_description = "\n".join([f"- {tool.name}: {tool.description}" for tool in PRODUCTION_TOOLS])
system_message = SystemMessage(content=SYSTEM_PROMPT.format(tools_description=tools_description))3.3 第三步:思考节点与路由函数
python
# 初始化LLM并绑定工具
llm = LLMFactory.get_llm()
llm_with_tools = llm.bind_tools(PRODUCTION_TOOLS)
def agent_think(state: AgentState) -> dict:
"""思考节点:分析问题,决定下一步行动"""
logger.info(f"Agent思考中,迭代次数:{state.iteration_count}/{state.max_iterations}")
# 构建消息列表:系统提示词 + 对话历史
messages = [system_message] + state.messages
# 调用LLM
response = llm_with_tools.invoke(messages)
# 检查是否超过最大迭代次数
if state.iteration_count >= state.max_iterations:
logger.warning("Agent超过最大迭代次数,强制结束")
return {
"messages": [AIMessage(content="抱歉,我无法在有限步骤内完成你的请求,请尝试简化问题。")],
"iteration_count": state.iteration_count + 1
}
return {
"messages": [response],
"iteration_count": state.iteration_count + 1
}
def router(state: AgentState) -> str:
"""路由函数:决定下一步是调用工具还是结束"""
last_message = state.messages[-1]
# 如果有工具调用,跳转到工具节点
if last_message.tool_calls:
logger.info(f"Agent决定调用工具:{[tc['name'] for tc in last_message.tool_calls]}")
return "tools"
# 否则直接结束
logger.info("Agent决定直接回答")
return END3.4 第四步:构建与编译 Agent 图
python
def build_react_agent() -> StateGraph:
"""构建工业级ReAct Agent(使用StateGraph标准API)"""
builder = StateGraph(AgentState)
# 添加节点
builder.add_node("agent", agent_think)
builder.add_node("tools", ToolNode(PRODUCTION_TOOLS))
# 添加边
builder.add_edge("tools", "agent")
builder.add_conditional_edges("agent", router)
# 设置入口点
builder.set_entry_point("agent")
# 配置Checkpoint持久化
checkpointer = SqliteSaver.from_conn_string("./data/agent_checkpoints.db")
# 编译图
graph = builder.compile(checkpointer=checkpointer)
logger.info("✅ ReAct Agent构建完成(LangGraph 1.0+ 标准API)")
return graph
# 全局单例Agent实例
react_agent = build_react_agent()3.5 第五步:LangSmith 集成调试
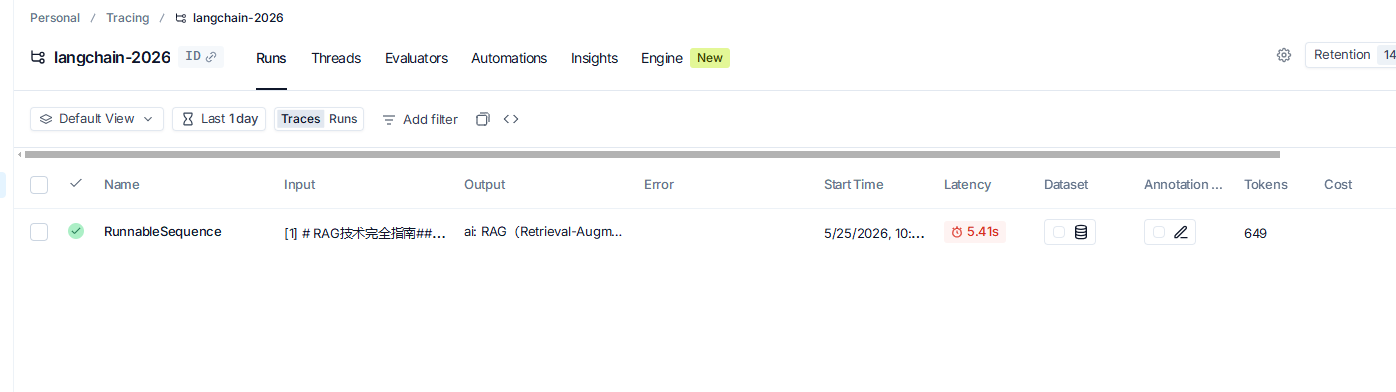
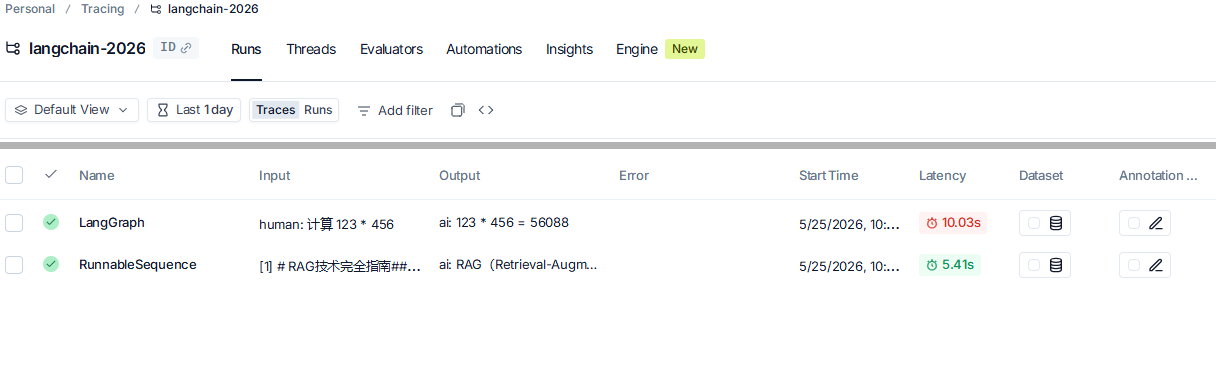
Agent 的调试难度远高于普通程序,LangSmith 是目前最好的 Agent 调试工具。在你的.env文件中添加以下配置:
bash
LANGCHAIN_TRACING_V2=true
LANGCHAIN_API_KEY=你的LangSmith API密钥
LANGCHAIN_PROJECT=langchain-2026-agent现在所有 Agent 的执行过程都会自动追踪到 LangSmith,你可以:
- 查看每一步的输入输出
- 查看工具调用的详细信息
- 查看状态的变化过程
- 调试错误和异常
3.6 第六步:测试 Agent
python
def test_react_agent():
"""测试工业级ReAct Agent"""
print("🚀 测试工业级ReAct Agent\n")
# 配置:每个用户一个独立的thread_id
config = {"configurable": {"thread_id": "test_user_001"}}
# 测试用例1:需要计算
print("测试1:数学计算")
result = react_agent.invoke(
{"messages": [HumanMessage(content="计算(123 + 456) * 789")]},
config=config
)
print(f"回答:{result['messages'][-1].content}\n")
# 测试用例2:需要检索知识库
print("测试2:企业知识库检索")
result = react_agent.invoke(
{"messages": [HumanMessage(content="公司的出差补贴标准是什么?")]},
config=config
)
print(f"回答:{result['messages'][-1].content}\n")
# 测试用例3:需要获取当前时间
print("测试3:获取当前时间")
result = react_agent.invoke(
{"messages": [HumanMessage(content="现在几点了?")]},
config=config
)
print(f"回答:{result['messages'][-1].content}\n")
# 测试用例4:多轮对话
print("测试4:多轮对话")
result = react_agent.invoke(
{"messages": [HumanMessage(content="我刚才问了你什么问题?")]},
config=config
)
print(f"回答:{result['messages'][-1].content}\n")
if __name__ == "__main__":
test_react_agent()四、项目整合:Agent 与 RAG 系统无缝集成
4.1 升级 RAGService,支持双模式切换
代码位置 :core/rag_service.py
python
from typing import Iterator
from core.rag_retriever import RAGRetriever
from core.prompt_service import PromptService
from core.react_agent import react_agent
from langchain_core.messages import HumanMessage
from config.settings import settings
from utils.logger import logger
class RAGService:
"""完整的RAG+Agent问答服务(第7天工业级版)"""
def __init__(self):
self.retriever = RAGRetriever()
self.prompt = PromptService()
logger.info("✅ RAG+Agent问答服务初始化完成")
def query(
self,
question: str,
user_id: str = "default_user",
top_k: int = None,
similarity_threshold: float = None,
use_anti_hallucination: bool = True,
use_agent: bool = False
) -> str:
"""
同步问答
:param user_id: 用户ID,用于隔离不同用户的会话状态
:param use_agent: 是否使用Agent模式(支持工具调用)
"""
try:
if use_agent:
logger.info(f"用户[{user_id}]使用Agent模式提问:{question}")
config = {"configurable": {"thread_id": user_id}}
result = react_agent.invoke(
{"messages": [HumanMessage(content=question)]},
config=config
)
return result["messages"][-1].content
# 原RAG逻辑完全保留,不做任何修改
logger.info(f"用户[{user_id}]使用RAG模式提问:{question}")
docs = self.retriever.retrieve(question, top_k, similarity_threshold)
if not docs:
return "抱歉,知识库中没有找到相关信息,无法回答您的问题。"
context = "\n\n".join([f"[{i+1}] {doc.page_content}" for i, doc in enumerate(docs)])
template_version = "v2.0" if use_anti_hallucination else "v1.0"
answer = self.prompt.generate(
template_name="rag_answer",
version=template_version,
inputs={"context": context, "question": question}
)
logger.info(f"生成回答完成:{answer[:200]}...")
return answer
except Exception as e:
logger.error(f"问答失败:{str(e)}", exc_info=True)
return "抱歉,回答生成时发生错误,请稍后重试。"
def stream_query(
self,
question: str,
user_id: str = "default_user",
top_k: int = None,
similarity_threshold: float = None,
use_anti_hallucination: bool = True,
use_agent: bool = False
) -> Iterator[str]:
"""流式问答(增强版,支持Agent流式输出)"""
try:
if use_agent:
logger.info(f"用户[{user_id}]使用Agent模式流式提问:{question}")
config = {"configurable": {"thread_id": user_id}}
# 流式输出Agent执行过程
for step in react_agent.stream(
{"messages": [HumanMessage(content=question)]},
config=config
):
if "agent" in step:
yield "🤔 思考中...\n"
# 流式输出思考内容
if hasattr(step["agent"]["messages"][-1], "content"):
yield step["agent"]["messages"][-1].content + "\n"
elif "tools" in step:
yield "🔧 正在执行工具...\n"
# 流式输出工具结果
for tool_result in step["tools"]["messages"]:
yield f"工具返回:{tool_result.content[:200]}...\n"
elif "__end__" in step:
yield "\n✅ 最终回答:\n"
yield step["__end__"]["messages"][-1].content
return
# 原RAG流式逻辑完全保留
logger.info(f"用户[{user_id}]使用RAG模式流式提问:{question}")
docs = self.retriever.retrieve(question, top_k, similarity_threshold)
if not docs:
yield "抱歉,知识库中没有找到相关信息,无法回答您的问题。"
return
context = "\n\n".join([f"[{i+1}] {doc.page_content}" for i, doc in enumerate(docs)])
template_version = "v2.0" if use_anti_hallucination else "v1.0"
yield from self.prompt.stream_generate(
template_name="rag_answer",
version=template_version,
inputs={"context": context, "question": question}
)
except Exception as e:
logger.error(f"流式问答失败:{str(e)}", exc_info=True)
yield "抱歉,回答生成时发生错误,请稍后重试。"4.2 新增 Agent API 接口
代码位置 :main7.py
python
from dotenv import load_dotenv
load_dotenv()
from core.rag_service import RAGService
from fastapi import FastAPI, HTTPException, Depends
from pydantic import BaseModel
import uvicorn
app = FastAPI(title="企业级RAG+Agent API", version="1.0.0")
rag_service = RAGService()
class QueryRequest(BaseModel):
question: str
user_id: str = "default_user"
use_agent: bool = False
class QueryResponse(BaseModel):
answer: str
mode: str
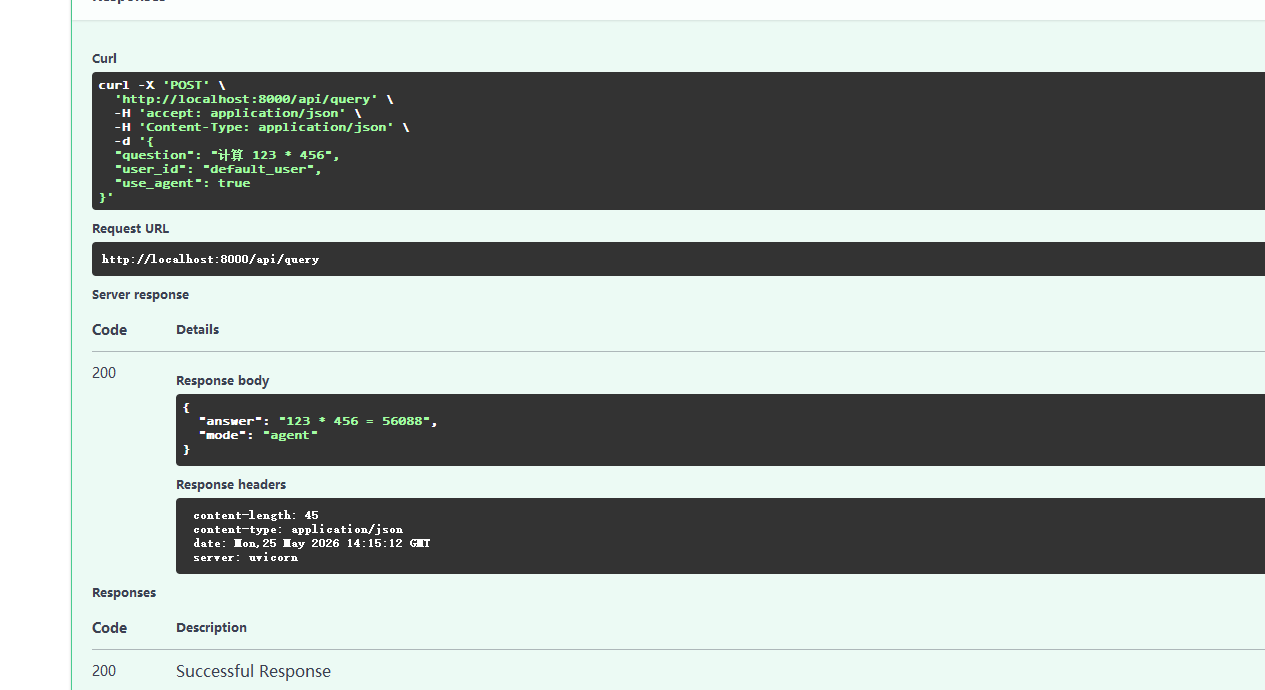
@app.post("/api/query", response_model=QueryResponse)
async def query(request: QueryRequest):
"""通用问答接口,支持RAG和Agent两种模式"""
try:
answer = rag_service.query(
question=request.question,
user_id=request.user_id,
use_agent=request.use_agent
)
return QueryResponse(
answer=answer,
mode="agent" if request.use_agent else "rag"
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/api/agent/stream")
async def agent_stream_query(request: QueryRequest):
"""Agent流式问答接口"""
try:
return rag_service.stream_query(
question=request.question,
user_id=request.user_id,
use_agent=True
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/api/health")
async def health_check():
"""健康检查接口"""
return {"status": "healthy", "service": "rag-agent-api"}
if __name__ == "__main__":
print("🚀 第7天:工业级ReAct Agent开发")
print("📡 API服务启动中,访问 http://localhost:8000/docs 查看接口文档")
uvicorn.run(app, host="0.0.0.0", port=8000)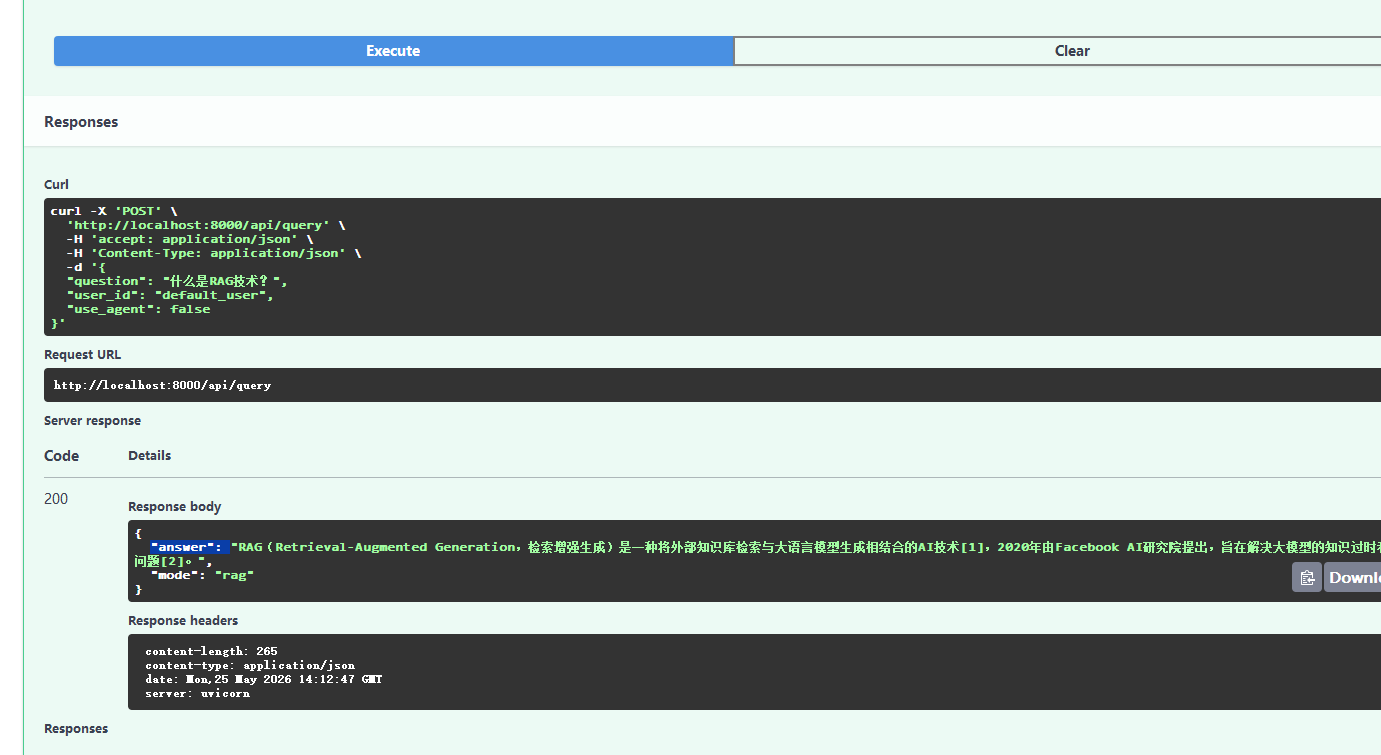
4.3工业级 Agent 开发最佳实践
- 工具最小权限原则:只给 Agent 必要的工具权限,禁止给 Agent 执行任意代码、修改系统配置等高风险权限
- 输入输出过滤:在调用工具前过滤用户输入中的敏感信息,在返回结果前过滤工具输出中的敏感信息
- 最大迭代次数限制:必须设置最大迭代次数,防止 Agent 陷入无限循环
- 完善的日志记录:记录所有用户请求、Agent 思考过程、工具调用和结果,便于审计和调试
- 异常处理与降级:当工具调用失败或 LLM 出错时,要有优雅的降级策略,不要直接抛出异常
- 安全审核:所有工具必须经过安全审核,确保没有安全漏洞
- 监控与告警:监控 Agent 的调用量、错误率、平均响应时间等指标,设置告警阈值