OpenClaw的出现,直接把Agent开发从"手搓零件拼汽车",变成了"直接开上整车"。它不是又一个套壳的对话机器人,也不是简单的工具调用封装,而是一个完整的、有状态的、Local-First的Agent操作系统。
这篇文章,我会带你从底层拆解OpenClaw的系统架构,从网关到运行时,从工具体系到存储设计,一文吃透,看完你不仅能懂它为什么火,更能直接上手基于它做开发。
一、先搞懂:OpenClaw到底是什么?
一句话给它下定义:OpenClaw = 一个常驻Gateway守护进程 + 内嵌Agent运行时引擎 + 标准化工具体系 + 声明式技能系统 + 全渠道接入能力 + 本地优先的持久化存储。
它和传统Agent框架的核心区别,也是它能爆火的根本原因:
- 不是无状态的一次性脚本,而是Always-On的守护进程,7x24小时在线,能主动执行定时任务;
- 不是单进程的玩具Demo,而是分布式的控制平面,支持多端、多设备、多智能体并行协同;
- 不是臃肿的黑盒框架,而是模块化的分层架构,每一层都可扩展、可替换、可定制;
- 不是云端绑定的SaaS产品,而是Local-First的原生设计,所有会话、状态、数据都存在本地,数据主权完全在自己手里。
二、OpenClaw系统架构全景
OpenClaw采用经典的高内聚低耦合分层设计,从外到内分为四层,整体架构如下:
 整个架构就像一个完整的人体:
整个架构就像一个完整的人体:
- 交互接入层是五官,负责接收外界信号;
- 网关控制平面是心脏,负责全局调度与连通;
- 核心服务层是大脑和手脚,负责思考决策与落地执行;
- 资源与持久化层是海马体和免疫系统,负责记忆存储与安全防护。
接下来,我们逐层拆解,吃透每一个模块的核心原理。
三、核心模块逐层拆解
3.1 网关控制平面 Gateway:OpenClaw的绝对心脏
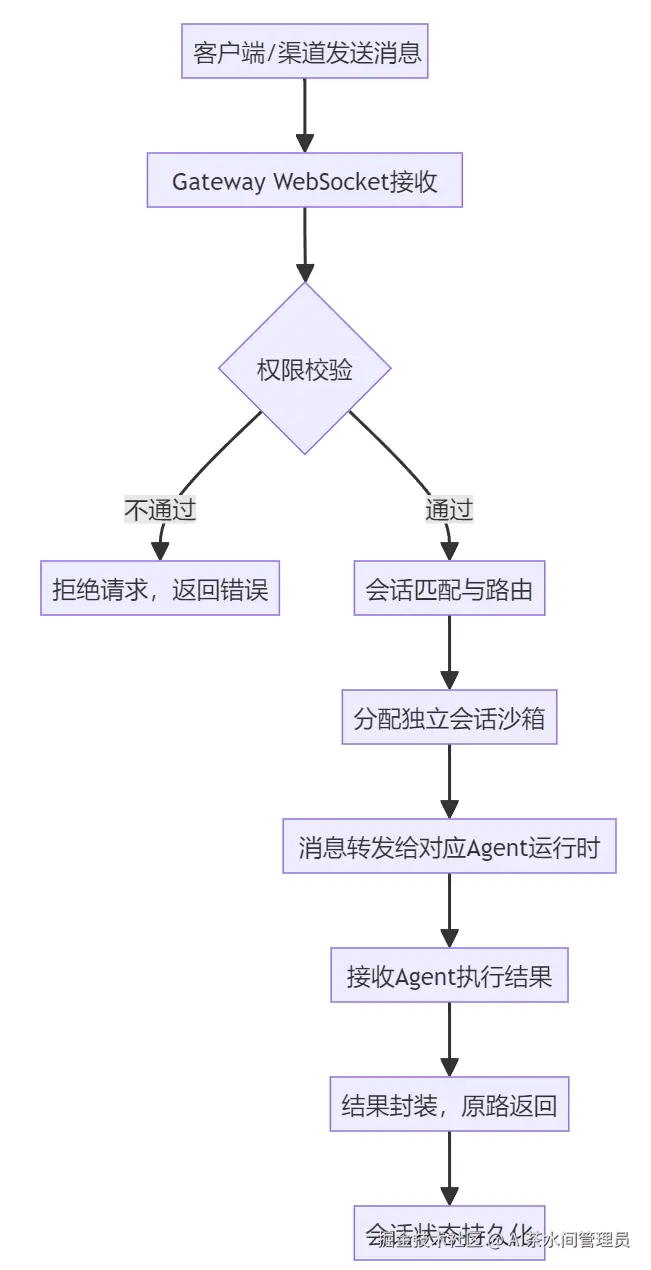
Gateway是整个OpenClaw的核心,当你执行openclaw gateway命令时,启动的就是这个Node.js守护进程,它默认监听在本地18789端口,是整个系统唯一的控制平面。
你可以把它理解成机场的塔台:所有的航班(消息)都要经过塔台调度,分配到正确的跑道(Agent会话),管控所有的起降(任务执行),绝对不会出现"串航班"的情况。
它的核心职责有4个:
- 统一通信枢纽:所有客户端、渠道、设备节点,都通过WebSocket和Gateway建立长连接,它负责统一的消息收发、心跳保活、断线重连;
- 会话管理与路由:给每个用户、每个渠道、每个群聊,分配独立的会话沙箱,确保上下文完全隔离,不会串消息;同时根据消息来源,路由到对应的Agent实例;
- 全局状态管控:管理所有Agent的运行状态、配置信息、定时任务、Webhook,是整个系统的唯一状态源;
- 权限与流量控制:白名单管控、渠道权限隔离、工具调用权限审批、流量整形,避免系统被滥用。
Gateway的核心工作流如下:
3.2 交互接入层 Channels:OpenClaw的"五官"
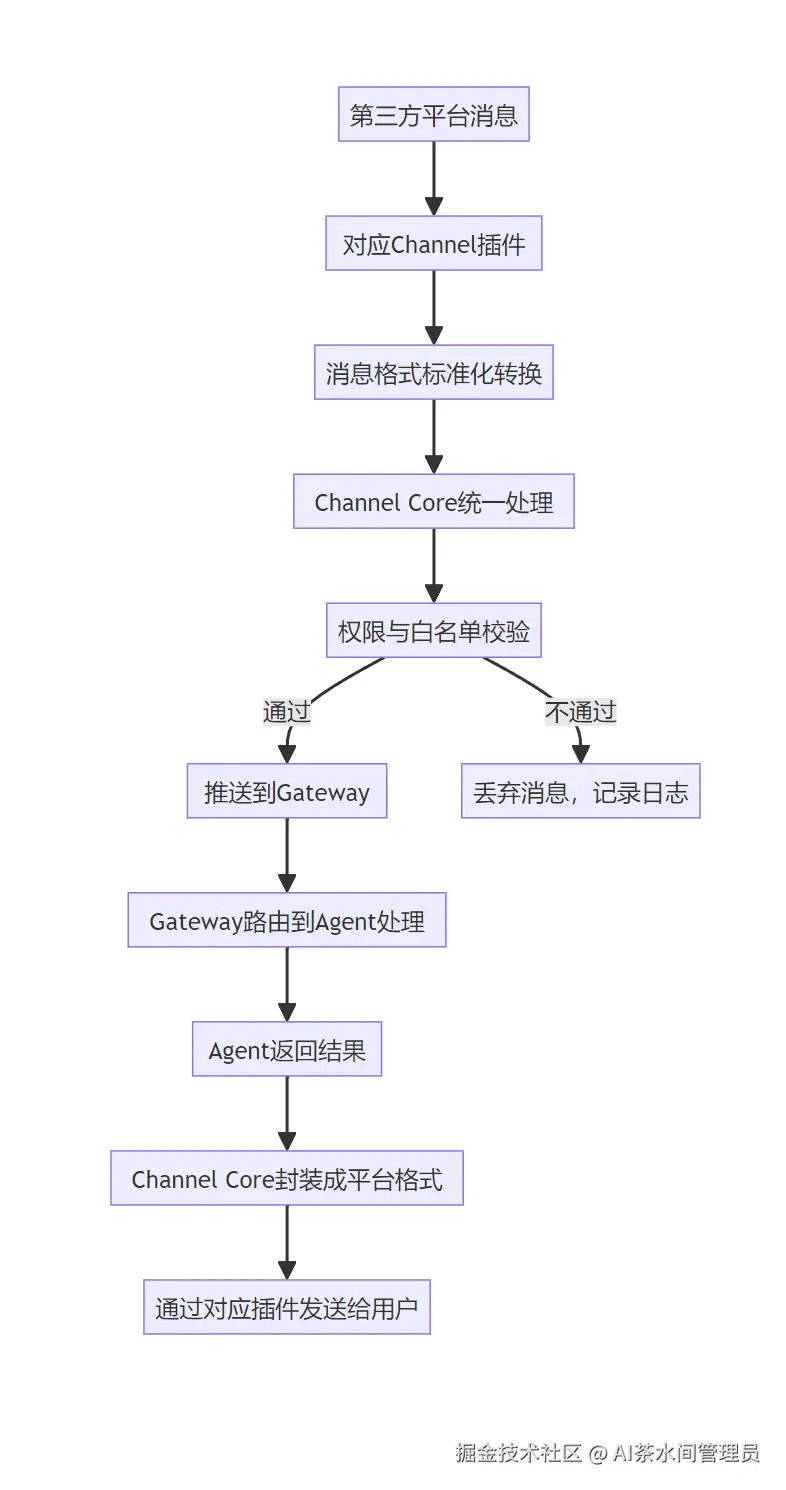
搞定了Gateway,接下来看Channels------这是OpenClaw和外界交互的入口,也就是它的"眼睛和耳朵"。
我们做Agent开发最头疼的一件事,就是适配不同的聊天平台:QQ的API长这样,飞书的API长那样,微信又有另一套规则,每个平台都要写一堆适配代码,烦得要死。
而Channels层,就是帮你把这些脏活累活全干了:它内置了20+主流聊天平台的适配,不管你是用飞书、Discord,还是Web UI、CLI,它都会把不同平台的消息,转换成OpenClaw内部统一的标准化事件格式。
它的核心设计亮点:
- 协议统一 :所有外部消息,都转换成
{sender, channel, content, timestamp, metadata}的标准格式,上层完全不用关心消息来自哪个平台; - 插件化设计:每个渠道都是一个独立的插件,可插拔、可扩展,你想适配新平台,只需要实现一个Channel插件即可;
- 权限隔离:每个渠道可以独立配置白名单、访问权限,绑定不同的Agent实例,比如工作群的渠道绑定工作Agent,私人号绑定生活Agent,完全隔离。
Channels的注册与消息处理流程如下:
3.3 Agent运行时 Pi Agent:OpenClaw的"大脑"
如果说Gateway是心脏,那Pi Agent运行时就是OpenClaw的大脑------所有的思考、推理、决策、任务执行,都在这里发生。
很多人以为Agent就是"调一下LLM API",但真正能落地的Agent,核心是稳定的运行时闭环。OpenClaw的Agent运行时,就是一个经过工业级验证的、稳定的执行闭环,它的核心是Agent Loop,一个无限循环的执行流程。
Agent Loop的完整流程如下:
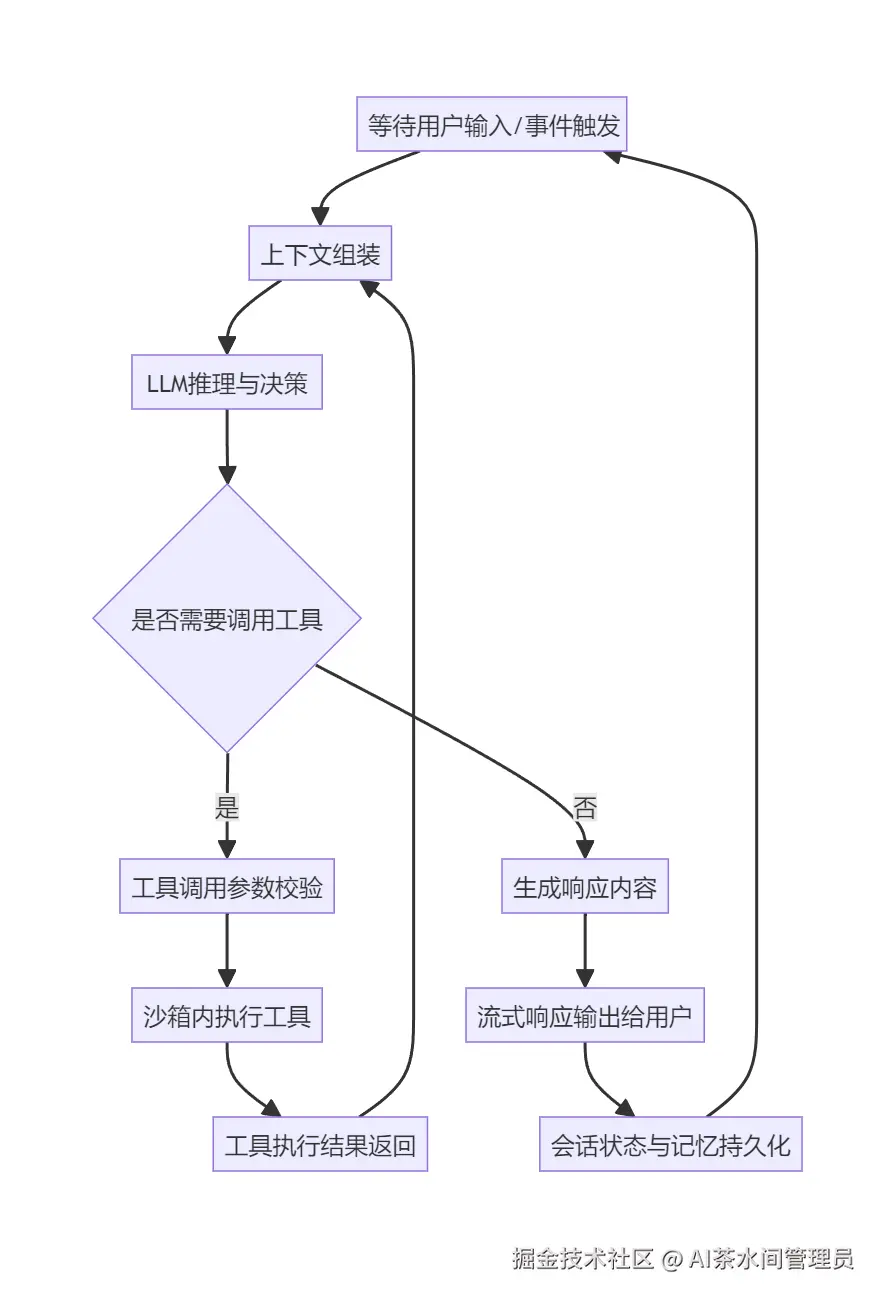
这个循环,就是OpenClaw能稳定执行复杂任务的核心。我们拆解一下每一步的关键细节:
- 上下文组装:这是Agent不"失忆"的关键。OpenClaw会把系统提示词、对话历史、工具调用记录、记忆内容、工作区文件,按照固定格式组装成完整上下文,同时做智能压缩和修剪,避免超出LLM的上下文窗口;
- LLM推理与决策:支持插件化的多模型接入,你可以用GPT-4o做复杂推理,用Claude 3.5做长文本处理,用本地开源模型做隐私任务,甚至可以给不同任务自动切换模型;
- 工具调用与执行:内置了参数校验、错误重试、超时控制,不会出现"参数传错导致工具崩了"的情况,而且所有工具都在独立沙箱中执行,不会影响主进程;
- 流式响应与持久化:支持边生成边输出,不用等完全生成完再给用户,同时每一步的状态、对话、执行结果,都会实时持久化到本地,就算中途断了,重启也能恢复。
下面是Agent Loop的核心Python简化代码:
python
class PiAgent:
def __init__(self, agent_id: str, workspace: str):
self.agent_id = agent_id
self.workspace = workspace
self.llm_client = LLMClient() # 多模型客户端
self.context_builder = ContextBuilder(workspace) # 上下文组装
self.tool_executor = ToolExecutor(workspace) # 工具执行器
self.persistence = PersistenceManager(agent_id) # 持久化管理器
async def loop(self):
"""Agent核心执行循环"""
while True:
# 1. 等待用户输入/事件触发
user_input = await self.wait_for_input()
if not user_input:
await asyncio.sleep(0.1)
continue
# 2. 保存用户输入,初始化上下文
await self.persistence.save_message("user", user_input)
context = await self.context_builder.build(self.agent_id)
while True:
# 3. 调用LLM进行推理决策
llm_response = await self.llm_client.chat(context)
tool_calls = llm_response.get("tool_calls", [])
content = llm_response.get("content", "")
# 4. 判断是否需要调用工具
if not tool_calls:
# 不需要工具,直接返回响应
await self.send_response(content)
await self.persistence.save_message("assistant", content)
break
# 5. 执行工具调用
for tool_call in tool_calls:
tool_name = tool_call["name"]
tool_args = tool_call["arguments"]
# 工具执行,带沙箱、超时、重试
tool_result = await self.tool_executor.execute(
tool_name, tool_args, self.agent_id
)
# 保存工具调用结果
await self.persistence.save_tool_call(tool_call, tool_result)
# 把工具结果加入上下文,进入下一轮推理
context = await self.context_builder.build(self.agent_id)
async def wait_for_input(self):
"""等待Gateway转发的用户输入"""
return await self.message_queue.get()
async def send_response(self, content: str):
"""把响应发送给Gateway,原路返回给用户"""
await self.gateway_conn.send(content)除了核心循环,OpenClaw的Agent运行时还有一个杀手锏:SubAgent子智能体机制。比如你让主Agent做一个"分析10个竞品网站,生成一份竞品分析报告"的任务,主Agent不用自己一步步干,它可以生成10个SubAgent,每个SubAgent负责分析一个网站,并行执行,执行完之后把结果返回给主Agent,主Agent汇总生成报告。每个SubAgent都有独立的会话、独立的上下文、独立的运行时,完全隔离,不会互相干扰。
3.4 工具与技能体系 Tools & Skills:OpenClaw的"手脚"
大脑再聪明,没有手脚也干不了活。OpenClaw的工具与技能体系,就是它的"手脚",让它能真正落地执行任务,而不是只会嘴炮。
这里要先分清两个核心概念:
- Tools(工具) :原子级的执行能力,是最小的执行单元,比如"读取文件"、"执行Shell命令"、"打开浏览器",每个Tool只干一件事,内置了6大类50+核心工具;
- Skills(技能) :组合式的任务流程,是把多个Tool组合起来,完成一个复杂的特定任务,比如"写一个Python爬虫"、"优化这段代码"、"生成周报",每个Skill都是一个可复用的任务模板。
它的核心设计亮点:
- 声明式注册:不管是Tool还是Skill,都用YAML/Markdown声明式定义,不用写复杂的代码,OpenClaw会自动把它注入到Agent的上下文里;
- 渐进式披露:Agent不会一开始就加载所有Tool的完整定义,只会先给名称和描述,当Agent决定要用某个Tool的时候,才会读取完整定义,极大节省上下文占用;
- 沙箱执行:所有的Tool执行,都在独立的沙箱进程中,有严格的权限控制,就算Tool执行出错,也不会崩掉主进程;
- 可扩展:你可以自己写Tool和Skill,打包成插件,分享给社区,也可以直接用社区里的上千个插件。
下面是一个最简单的Skill定义示例,OpenClaw原生支持:
markdown
# Skill: 代码优化专家
## 描述
帮用户优化Python代码,提升性能、可读性、规范性,自动添加注释和类型提示
## 依赖工具
- read_file: 读取代码文件
- write_file: 写入优化后的代码
- explain_code: 解释代码逻辑
- clean_code: 代码格式化
## 执行流程
1. 读取用户指定的代码文件,获取原始代码
2. 分析代码的问题:性能瓶颈、语法不规范、缺少注释、类型缺失
3. 生成优化后的代码,添加完整的注释和类型提示
4. 把优化后的代码写入新的文件,避免覆盖原文件
5. 给用户生成一份优化说明,讲清楚改了什么,为什么这么改
## 触发关键词
优化代码、代码重构、提升代码性能、代码规范检查就这么简单,你写好这个Skill文件,放到OpenClaw的skills目录里,它就会自动加载,Agent就能直接用这个技能了,完全不用写一行Python代码。
3.5 存储与记忆系统:OpenClaw的"海马体"
很多Agent用着用着就"失忆",核心原因就是存储和记忆系统没做好。OpenClaw在这一点上,做了一个非常大胆的设计:完全抛弃传统的关系型数据库和向量数据库,采用纯文本的持久化存储。
什么意思?所有的对话历史、会话状态、Agent配置、技能、记忆,全部以Markdown和YAML格式,保存在你本地的工作区目录里。比如对话历史存在history.md里,Agent的配置存在AGENTS.md里,长期记忆存在MEMORY.md里,你可以直接用文本编辑器打开看,甚至手动修改。
这个设计的优势太明显了:
- 完全可控:所有数据都在你本地,纯文本格式,不会被锁在某个数据库里,你可以随时备份、迁移、修改、用Git做版本控制;
- 零依赖:不用装PostgreSQL、MySQL、Redis,不用部署向量数据库,解压就能用,启动速度极快;
- 极致透明:你能完全看到Agent记住了什么,用了什么上下文,没有任何黑盒;
- 兼容性极强:纯文本格式,任何设备、任何系统都能打开,不会出现数据库版本不兼容的问题。
同时,OpenClaw的记忆系统,还做了上下文的智能管理:短期记忆完整保留,保证上下文连贯;长期记忆自动提取,永久保存;历史对话自动压缩摘要,减少上下文占用;冗余信息自动修剪,避免上下文污染。
OpenClaw的上下文窗口结构如下:
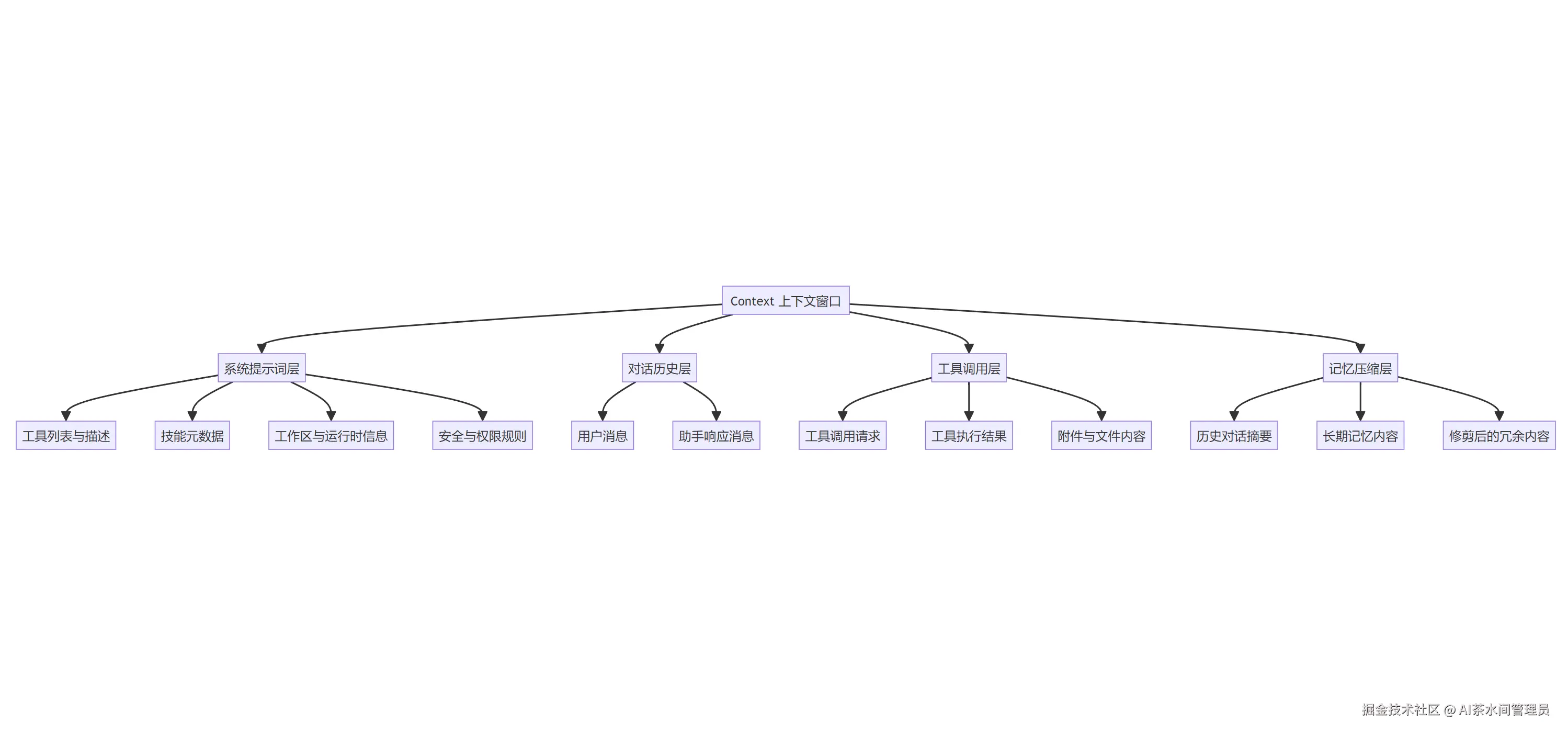
3.6 安全与隔离机制:OpenClaw的"免疫系统"
Agent能操作你的本地文件、执行Shell命令、控制浏览器,安全是绝对的底线。OpenClaw在架构设计上,就把安全放在了第一位,做了多层的安全隔离机制:
- 会话沙箱隔离:每个Agent、每个会话,都有独立的工作目录、独立的运行环境,完全隔离,不会出现A会话的Agent访问到B会话的文件的情况;
- 工具权限白名单:默认关闭所有高危工具,你需要手动开启,而且可以给每个Agent、每个渠道,设置独立的工具权限;
- 沙箱执行环境:所有的工具执行、代码运行,都在独立的沙箱进程中,有严格的系统调用限制,就算执行了恶意代码,也不会影响你的主系统;
- 人机审核机制:对于高危操作,比如删除文件、执行Shell命令,你可以设置必须经过人工审核确认,Agent才能执行;
- 本地优先设计:所有数据都存在本地,不会上传到任何云端,除非你主动配置了云端模型,而且只会把推理需要的上下文发给模型。
四、一条消息的完整旅行------全链路流程拆解
讲完了所有模块,我们用一个完整的例子,把整个链路串起来,让你彻底搞懂OpenClaw是怎么工作的。
场景:你在飞书上给OpenClaw发了一条消息:"帮我优化当前目录下的main.py代码,生成优化说明"。
完整链路:
- 你在飞书发送消息,飞书的服务器把消息推送给OpenClaw的飞书Channel插件;
- Channel插件把飞书的消息格式,转换成OpenClaw内部的标准化事件格式,校验你的白名单权限,通过后推送给Gateway;
- Gateway收到消息,匹配到对应的会话,分配给绑定的Agent实例,把消息转发给Agent运行时;
- Agent运行时收到消息,保存用户输入,组装上下文,调用LLM进行推理;
- LLM判断需要调用工具,先调用
read_file工具读取main.py的内容; - 工具执行器在沙箱中执行
read_file,读取到代码内容,返回给Agent; - Agent把代码内容加入上下文,再次调用LLM,生成优化后的代码和说明;
- LLM判断需要调用
write_file工具,把优化后的代码写入main_optimized.py,再把优化说明写入optimize_report.md; - 工具执行器完成两个文件的写入,返回执行结果给Agent;
- Agent生成最终的响应消息,告诉用户优化完成,两个文件已经生成;
- Gateway把响应消息转发给飞书Channel插件,插件转换成飞书的消息格式,发送给你;
- Agent把整个对话历史、工具调用记录、执行结果,持久化到本地的history.md文件里,同时把你的代码优化偏好,提取到长期记忆MEMORY.md里。
整个流程,完全自动化,你只需要发一句话,剩下的全交给OpenClaw,这就是它的魅力所在。
以上就是OpenClaw系统架构的完整拆解,从底层网关到上层应用,从核心原理到代码示例,一文给你讲透。
如果你觉得这篇文章对你有帮助,欢迎点赞、收藏、评论,你的支持是我更新的最大动力。