
MedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
摘要
本研究发布了MedHELM框架,一个用于评估大语言模型在医疗任务中表现的开源评估套件。研究团队与29名临床医生共同开发了涵盖5个类别、22个子类别、121项任务的临床验证分类法,构建了包含35个基准的全面评估套件,并对9个前沿大语言模型进行了系统比较。研究表明,推理模型(DeepSeek R1和o3-mini)表现最优,但Claude 3.5 Sonnet在成本效益上更具优势。
阅读原文或https://t.zsxq.com/oTb3I获取原文pdf
正文
一、研究背景与意义
尽管大语言模型在医学执照考试上取得了接近完美的成绩(约99%的准确率),但这些评估方式并不能充分反映真实临床实践的复杂性和多样性。 现有医学知识基准存在三个关键局限:首先,问题不符合真实临床环境------现有基准依赖于合成病例或狭隘的考试问题,无法捕捉真实诊断过程中的关键方面,如从患者记录中提取相关细节的能力;其次,实际数据使用有限------只有5%的大语言模型评估使用真实的电子健康记录(EHR)数据,而EHR包含合成数据无法复制的歧义、不一致性和专业术语;第三,任务多样性不足------大约64%的医疗领域大语言模型评估仅关注医学执照考试和诊断任务,忽视了医院运营的关键部分,如行政任务、临床文档和患者沟通。
为解决这些局限性,Stanford Health Care和Stanford医学院的研究团队推出了MedHELM(医疗任务大语言模型的整体评估框架),这是一个可扩展的评估框架,用于评估大语言模型在完成医疗任务中的表现。
二、核心研究贡献
MedHELM框架包含三个主要贡献:
1. 临床验证的任务分类法
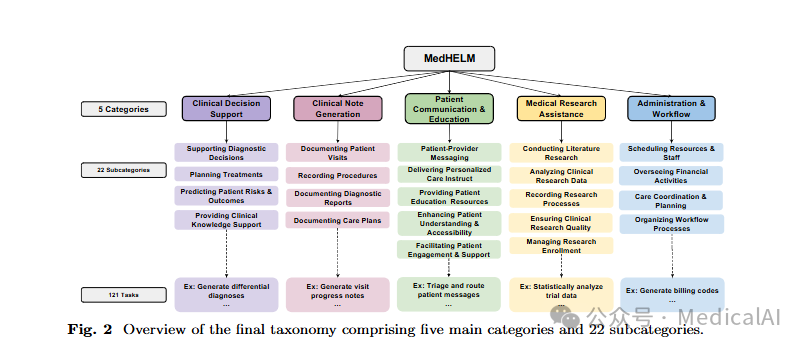
研究团队与29名来自不同医学专科的临床医生合作,开发了一个包含5个主要类别、22个子类别和121项任务的分类法。临床医生在将子类别分配到适当类别时达到了96.7%的一致性,这验证了该分类法的清晰性和实用性。
分类法的五个主要类别包括:
-
临床决策支持
:分析患者特定数据为临床医生提供循证建议
-
临床文档生成
:创建患者护理的结构化记录
-
患者沟通与教育
:传递健康信息以提高患者理解
-
医学研究协助
:分析临床数据和文献以推进医学知识
-
行政与工作流程
:协调从日程安排到计费的临床运营
2. 全面的基准测试套件
MedHELM包含35个基准,涵盖所有22个子类别。该套件包括17个现有基准、5个基于现有数据集重新表述的基准,以及13个新基准,其中12个基于EHR数据。
基准的分布显示:临床决策支持类别最多(10个基准),其次是患者沟通(8个)、临床文档生成和医学研究协助(各6个)、行政与工作流程(5个)。 这35个基准包括13个开放式基准(需要自由文本生成)和22个封闭式基准(有预定义答案选项)。
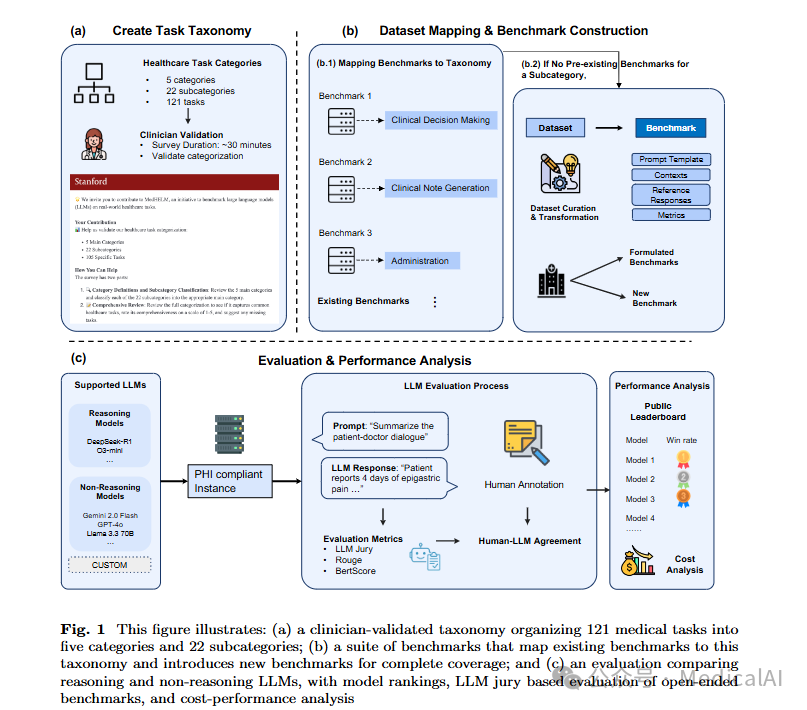
3. 模型比较与成本效益分析
研究团队对包括DeepSeek R1、o3-mini、Claude系列、GPT系列、Gemini系列和Llama系列在内的9个前沿大语言模型进行了系统评估。
三、评估方法与指标
3.1 性能评估指标
研究采用了多种评估方法来衡量模型性能:
-
成对胜率
:在35个基准中,每个基准比较各模型的相对表现。胜率表示模型在两两比较中超越对手的比例。
-
宏平均评分
:所有35个基准的平均性能评分,每个基准权重相等。
-
基准特定指标
:对于不同类型的任务采用相应的评估指标。
3.2 开放式基准评估:LLM评审团
对于13个开放式基准(需要自由文本生成),研究采用了创新的"LLM评审团"评估方法。该方法使用三个不同的大语言模型(GPT-4o、Claude 3.7 Sonnet、LLaMA 3.3 70B)组成评审团,这样可以代表不同的模型架构和训练方法,最小化任何单一提供商的系统偏差。
每个评审成员根据三个标准对生成的响应进行1-5李克特量表评分:
-
准确性
:事实正确性和对医学指南的遵守
-
完整性
:对查询所有方面的全面性
-
清晰度
:组织、可读性和易理解的语言
最终的LLM评审团评分是所有9个评分(3个评审×3个标准)的平均值。
3.3 与临床医生评分的验证
为验证LLM评审团方法的有效性,研究在两个开放式基准(MEDIQA和ACI-Bench)的子集上收集了临床医生的独立评分。结果显示,LLM评审团与临床医生评分的类内相关系数(ICC)为0.47,超过了临床医生之间的平均一致性(ICC=0.43),也优于自动化基线,包括ROUGE-L(0.36)和BERTScore-F1(0.44)。
四、主要研究发现
4.1 整体性能排名
根据成对胜率,模型排名如下:
| 模型 | 胜率 | 宏平均评分 | 评分方差 |
|---|---|---|---|
| DeepSeek R1 | 0.66 | 0.75 | 0.10 |
| o3-mini | 0.64 | 0.77 | 0.18 |
| Claude 3.7 Sonnet | 0.64 | 0.73 | 0.21 |
| Claude 3.5 Sonnet | 0.63 | 0.73 | 0.21 |
| GPT-4o | 0.57 | 0.73 | 0.18 |
| Gemini 2.0 Flash | 0.42 | 0.70 | 0.21 |
| GPT-4o mini | 0.39 | 0.71 | 0.20 |
| Llama 3.3 Instruct (70B) | 0.30 | 0.69 | 0.22 |
| Gemini 1.5 Pro | 0.24 | 0.67 | 0.21 |
DeepSeek R1表现最佳,胜率为66%,宏平均评分为0.75;o3-mini紧随其后,胜率为64%,但宏平均评分最高(0.77),在临床决策支持类别上表现突出。Claude系列模型取得了63-64%的胜率,宏平均评分为0.73。GPT-4o达到57%的胜率,而Gemini 2.0 Flash(42%)和GPT-4o mini(39%)表现较低。开源的Llama 3.3 Instruct仅达到30%的胜率。
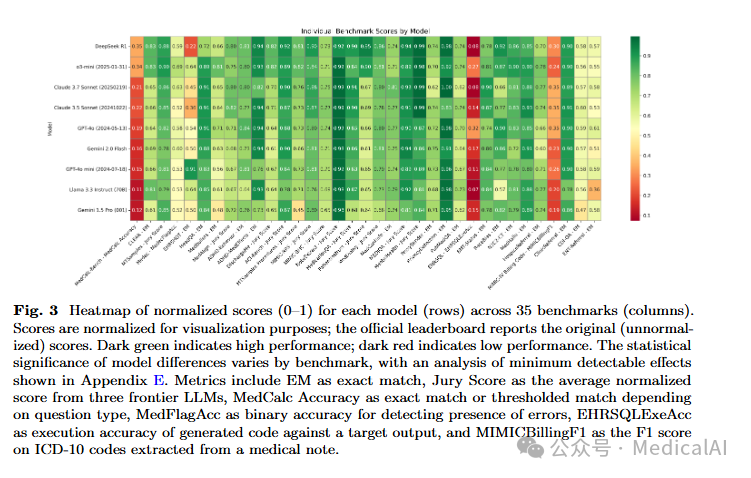
4.2 按类别的性能分析
不同类别任务的性能表现差异显著:
性能最优的类别:
-
临床文档生成
:0.74-0.85的标准化准确率
-
患者沟通与教育
:0.76-0.89的标准化准确率
这两个类别的高性能源于模型的自然语言生成能力------它们本身就是文本生成模型的核心优势。
性能中等的类别:
-
医学研究协助
:0.65-0.75的标准化准确率
-
临床决策支持
:0.61-0.76的标准化准确率
这些类别需要较强的推理能力和对医学知识的整合。
性能较低的类别:
-
行政与工作流程
:0.53-0.63的标准化准确率
行政工作流程类别的性能较低是一个重要发现,可能反映了模型在处理医疗系统中真实操作细节方面的局限性。
具体而言,DeepSeek R1在临床文档生成(0.85)和患者沟通与教育(0.89)中表现卓越,而o3-mini则在临床决策支持(0.76)和医学研究协助(0.75)中领先。Claude Sonnet系列在临床文档生成(0.82-0.83)和患者沟通与教育(0.83-0.84)上表现一致且强劲。
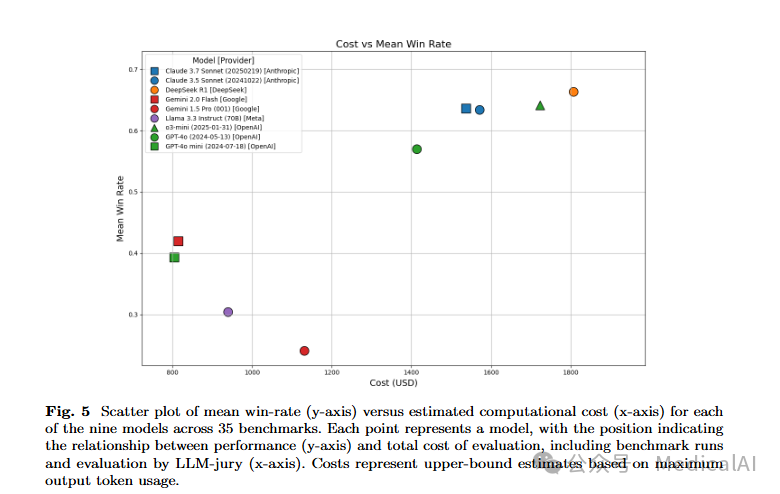
五、成本效益分析
这是MedHELM研究的一个关键亮点------它不仅评估模型性能,还分析了部署成本。
研究团队基于2025年5月12日的公开定价,估算了每个模型的评估成本,包括基准运行和LLM评审团评估所消耗的输入和输出令牌数。这些成本被绘制在二维图表上,横轴为估计计算成本,纵轴为平均胜率。
关键发现包括:
成本最低的模型:
-
GPT-4o mini:805美元,胜率39%
-
Gemini 2.0 Flash:815美元,胜率42%
这两个模型提供了最低的评估成本,但性能相对较低。
推理模型:
-
DeepSeek R1:1,806美元,胜率66%
-
o3-mini:1,722美元,胜率64%
推理模型虽然成本最高,但性能最优,对于需要最高准确率的关键医疗应用可能是合理的选择。
成本效益最优的选择:
-
Claude 3.5 Sonnet:1,571美元,胜率63%
-
Claude 3.7 Sonnet:1,537美元,胜率64%
这两个模型提供了一个很好的平衡点,以相对较低的成本(比推理模型低约15-20%)实现了接近顶级模型的性能。Claude 3.5 Sonnet尤其值得关注,它以40%更低的估计计算成本实现了与顶级模型可比的性能。
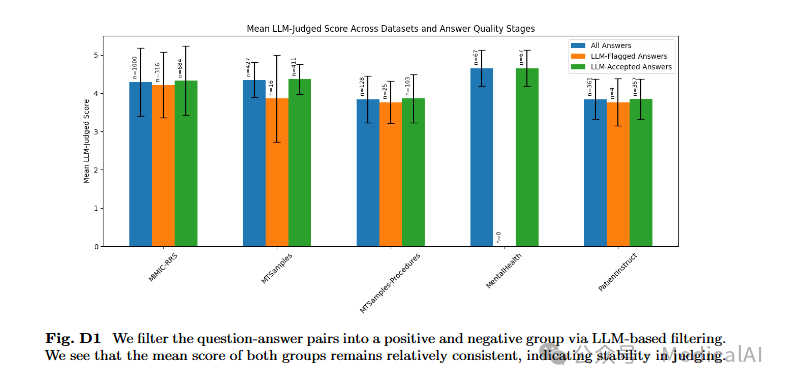
六、具体基准表现分析
在35个具体基准中,模型表现存在显著差异:
表现最差的基准:
-
MedCalc-Bench
:从患者笔记中计算医学数值------这类任务需要精确的数值计算和医学知识的结合
-
EHRSQL
:从自然语言说明生成SQL查询进行临床研究------这是一个代码生成任务,原本设计为代码生成数据集
-
MIMIC-IV Billing Code
:给临床笔记分配ICD-10编码------这需要详细的医学知识和编码标准的掌握
表现最佳的基准:
-
NoteExtract
:从临床笔记中提取特定信息------这类任务相对直接,利用了模型的文本理解能力
这些结果突出了不同任务类型对模型能力的不同要求。
七、LLM评审团方法的创新之处
MedHELM采用的LLM评审团评估方法代表了医疗AI评估领域的一个重要创新。
传统方法存在两个问题:单个LLM作为评判者会产生高方差和偏差,而人工临床医生评估非常耗时且成本高昂。LLM评审团通过聚合多个不同模型的判断来解决这些问题。
选择三个评审团成员的决定基于先前的研究,表明奇数评审团可以减少平局情况,同时保持可靠性。 评审团成员的选择(GPT-4o、Claude 3.7 Sonnet、LLaMA 3.3 70B)旨在代表不同的模型架构和训练方法,最小化任何单一提供商的系统偏差。
该方法实现了ICC=0.47的协议,超过了平均临床医生之间的协议(ICC=0.43),表明LLM评审团可以有效地取代人工评价者,同时大大降低成本和时间投入。这对于医疗AI的大规模评估具有重大意义,因为临床医生的时间非常有限且成本高昂。
八、质量保证措施
研究团队对金标准响应的质量进行了详细的评估和验证。
对于基于改述基准的数据集,他们发现了一些金标准响应中的质量问题。例如,某些MIMIC-RRS基准中的金标准响应包含了未在模型输入中提供的患者EHR信息。为评估这些低质量金标准响应的影响,研究团队进行了敏感性分析,使用LLM评判器过滤"有问题的"金标准响应,然后重新计算指标。
结果表明,模型排名保持不变,因为带有"有问题的"和"无问题的"金标准响应的实例收到了相似的评审评分。这种稳定性存在是因为LLM评审团的设计只在必要时使用金标准响应。
九、MedHELM框架的应用价值
MedHELM框架为医疗AI的测试和评估解决了一个关键需求,通过为医疗和医疗保健应用提供一致的、真实世界的评估标准。
该框架主要惠及三个关键利益相关者群体:
-
医疗保健系统
:可以为特定任务评估大语言模型
-
AI开发者
:可以识别医疗任务中的性能差距
-
研究人员
:可以开发可重现的方法来测量大语言模型在医疗任务上的能力
为了促进AI评估的持续改进,研究团队提供了一个开源的基准排行榜和代码库,带有详细的文档,供贡献新的数据集、评估指标和基准定制模型。通过标准化任务分类法中的术语和评估方法,MedHELM为医学AI能力的可重现和真实世界评估奠定了基础。
十、研究的局限性与未来方向
尽管MedHELM是一项全面的工作,但研究团队也坦诚地列出了几个局限性:
-
LLM评审团验证范围有限:虽然LLM评审团方法在两个基准上验证了有良好的协议,但在更多基准上扩展临床医生注释会加强这些协议估计。
-
基准分布不均:22个子类别中有15个仅包含一个基准,而其他7个包含2-5个基准。这种不均匀的分布限制了在代表性不足领域得出有力性能结论的能力。
-
评估方法的改进空间:目前的评估指标在基准级别运作,但实例级别的指标可能提供更好的评估,特别是对于主观或上下文相关的医学任务,其中可能不存在金标准响应。
-
行政与工作流程任务的性能不足:所有模型在这个类别中的性能都较低。理解这种性能不足的根本原因------无论是训练数据的局限性、任务复杂性,还是分布转移------对于安全部署在医疗保健运营中至关重要。
十一、后续研究建议
研究团队指出了几个后续研究的方向:
-
在更多开放式基准上扩展临床医生注释,以更全面地验证LLM评审团方法
-
为代表性不足的子类别开发更多基准,特别是在行政与工作流程领域
-
开发实例级别的评估指标,以更准确地捕捉医学任务的细微差别
-
对性能不足的根本原因进行深入分析,特别是在行政与工作流程任务中
十二、结论与启示
MedHELM通过其临床验证的分类法、全面的基准套件和创新的评估方法,为医疗大语言模型的评估设立了新的标准。
主要发现总结如下:
-
性能存在显著差异:不同模型在医疗任务上的表现差异很大,最好的模型(DeepSeek R1)的胜率是最差模型(Gemini 1.5 Pro)的近3倍。
-
任务类型影响性能:文本生成任务(临床文档、患者沟通)的性能最高,而需要结构化推理的任务(临床决策、行政工作流)的性能较低。
-
推理能力的重要性:推理模型(DeepSeek R1、o3-mini)在整体上表现最好,表明复杂的推理能力对医疗应用至关重要。
-
成本效益平衡的重要性:Claude 3.5 Sonnet的出现表明,最昂贵的模型不一定是最佳选择;成本效益考虑对于医疗部署至关重要。
-
实际应用的选择性部署:不同的医疗机构应根据其特定需求和资源预算选择不同的模型。对于需要最高准确性的关键任务,推理模型可能是必要的;对于常见任务,成本更低的选项可能就足够了。
-
LLM评审团方法的潜力:新的评估方法可以以成本更低的方式替代人工临床评估,这对大规模医疗AI评估具有重大意义。