摘要
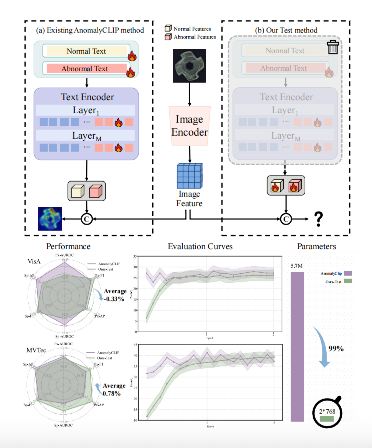
零样本异常检测(ZSAD)要求在无法获取目标类别异常样本的情况下检测并定位异常 。主流方法依赖于视觉-语言模型(VLM,例如 CLIP):它们为正常和异常语义构建手工设计或可学习的提示(Prompt)集,然后计算图像-文本的相似度以进行开集判别 。虽然这种范式很有效,但它依赖于文本编码器和跨模态对齐,这可能会导致训练不稳定和参数冗余 。本研究重新审视了 ZSAD 中文本分支的必要性,并提出了 VisualAD,这是一个建立在视觉 Transformer(ViT)基础上的纯视觉框架 。我们在冻结的主干网络中引入了两个可学习的 Token,直接对正常和异常进行编码 。通过多层自注意力机制,这些 Token 与图像块(Patch)Token 进行交互,在引导图像块突出异常相关线索的同时,逐渐获得关于正常和异常的高级概念 。此外,我们还结合了空间感知交叉注意力(SCA)模块和轻量级的自对齐函数(SAF):SCA 将细粒度的空间信息注入到 Token 中,而 SAF 则在进行异常评分之前对图像块特征进行重新校准 。VisualAD 在横跨工业和医疗领域的 13 个零样本异常检测基准数据集上均取得了最先进(SOTA)的性能,并且能够无缝适配预训练的视觉主干网络,如 CLIP 图像编码器和 DINOv2 。
she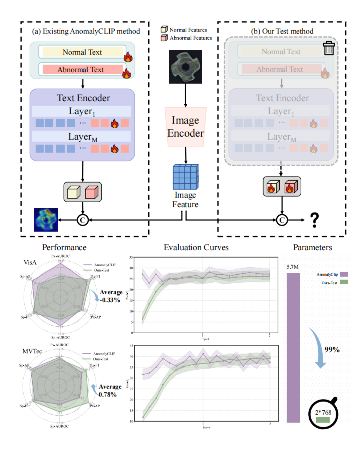
设计了两个token 用来计算异常和正常的相似度。