示例代码
python
from mmengine.visualization import Visualizer
# 1.import swanlab module
custom_imports = dict(
imports=["swanlab.integration.mmengine"],
allow_failed_imports=False
)
# 2.config swanlabbackend
vis_backends = [
dict(
type="SwanlabVisBackend",
init_kwargs={
"project":"projectName",
"experiment_name":"develop-train-task-speed-vis03",
"description":"visualize train task speed (samples/s),int value",
# "config":{ # 额外需要加的配置写在这里,默认mmengine实现了很多config会自动上传到swanlab
# "train/batch_size_per_gpu":batch_size_per_gpu,
# "test/batch_size_per_gpu_test":batch_size_per_gpu_test
# },
# "mode":"disabled"
}
)
]
visualizer = dict(
type="Visualizer",
vis_backends=vis_backends
)swanlab和mmengine集成的核心机制
简单来说,集成是通过Swanlab实现了一个符合mmengine接口规范的可视化后端SwanlabVisBackend,并将其挂载到MMengine的Visualizer组件上实现的。
python
from mmengine.visualization import Visualizer # 导入mmengine的可视化器
from swanlab.integration.mmengine import SwanlabVisBackend # 这个是swanlab集成mmengine的核心实现,下面会先分析这个类是如何实现与mmengine交互,如何将指标带入到swanlab
...
# 初始化SwanLab
swanlab_vis_backend = SwanlabVisBackend(init_kwargs={})
# 初始化mmegine的Visulizer,并引入SwanLab作为Visual Backend
visualizer = Visualizer(
vis_backends=swanlab_vis_backend
) 集成核心:SwanlabVisBackend类的实现
源码:https://github.com/SwanHubX/SwanLab/blob/main/swanlab/integration/mmengine.py#L169
集成最关键的部分是swanlab.integration.mmengine模块提供的SwanlabVisBackend类。它扮演了一个**"桥接器"**的角色。
-
遵循标准 :它继承自或遵循MMEngine定义的**
BaseVisBackend** 接口规范。这意味着MMEngine的Visualizer可以像调用本地存储或TensorBoard后端一样,无缝地调用SwanlabVisBackend。 -
实现转换 :
SwanlabVisBackend内部将MMEngine的标准可视化方法(如add_scalars,add_config,add_image等)转换为对SwanLab Python SDK 的调用(如swanlab.log,swanlab.config等)。
代码整体分析
1.类的定义与注册
python
from mmengine.registry import VISBACKENDS # mmengine用于管理可视化存储后端的注册器
from mmengine.visualization.vis_backend import BaseVisBackend, force_init_env
from mmengine.config import Config
@VISBACKENDS.register_module()
class SwanlabVisBackend(BaseVisBackend):
-
继承
BaseVisBackend:这是 MMEngine 所有可视化后端的基类,定义了统一的接口规范 -
@VISBACKENDS.register_module():将SwanlabVisBackend注册到 MMEngine 的VISBACKENDS注册表中,使得可以通过配置文件的type='SwanlabVisBackend'来动态创建实例
2.初始化方法__init__
python
def __init__(self, save_dir: str = None, init_kwargs: Optional[dict] = None):
self._save_dir = save_dir
self._env_initialized = False
self._init_kwargs = init_kwargs-
save_dir:保存目录,用于 SwanLab 日志文件的本地存储位置 -
init_kwargs:核心参数!这是一个字典 ,用于传递 SwanLab 初始化所需的所有参数(如project、experiment_name、description等) -
_env_initialized:标志位,用于延迟初始化,避免重复创建连接
- 环境初始化
_init_env
python
def _init_env(self) -> Any:
"""Setup env for swanlab."""
if self._save_dir is not None:
if not os.path.exists(self._save_dir):
os.makedirs(self._save_dir, exist_ok=True)
if self._init_kwargs is None:
self._init_kwargs = {"logdir": self._save_dir}
else:
self._init_kwargs.setdefault("logdir", self._save_dir)
try:
import swanlab
except ImportError:
raise ImportError('Please run "pip install swanlab" to install swanlab')
swanlab.config["FRAMEWORK"] = "mmengine"
swanlab.init(**self._init_kwargs)
self._swanlab = swanlab这是集成的核心:
-
目录处理:确保保存目录存在
-
参数合并 :将
save_dir自动添加到init_kwargs的logdir字段中(如果用户没指定的话) -
动态导入 :在使用时 才导入
swanlab,而不是在文件顶部导入。这样即使没有安装 SwanLab,也不会影响其他功能 -
标记框架 :
swanlab.config["FRAMEWORK"] = "mmengine"告诉 SwanLab 这是来自 MMEngine 的集成 -
初始化 SwanLab :调用
swanlab.init(**self._init_kwargs)真正创建 SwanLab 实验
4.expreiment属性
python
@force_init_env
def experiment(self) -> Any:
return self._swanlab-
@force_init_env装饰器 :确保在访问experiment前,_init_env()已经被调用 -
返回底层的 SwanLab 对象,允许用户在标准接口之外进行更高级的操作(如直接调用 SwanLab API)
5.配置上传add_config
python
@force_init_env
def add_config(self, config: Config, **kwargs) -> None:
"""Record the config to swanlab."""
def repack_dict(a, prefix=""):
"""将嵌套字典展平为 SwanLab 可接受的格式"""
new_dict = dict()
for key, value in a.items():
key = str(key)
if isinstance(value, dict):
# 递归处理嵌套字典
if prefix != "":
new_dict.update(repack_dict(value, f"{prefix}/{key}"))
else:
new_dict.update(repack_dict(value, key))
elif isinstance(value, list) or isinstance(value, tuple):
# 处理列表/元组
if all(not isinstance(element, dict) for element in value):
new_dict[key] = value
else:
for i, item in enumerate(value):
new_dict.update(repack_dict(item, f"{key}[{i}]"))
elif prefix != "":
new_dict[f"{prefix}/{key}"] = value
else:
new_dict[key] = value
return new_dict
config_dict = config.to_dict()
self._swanlab.config.update(repack_dict(config_dict))这个方法的巧妙之处 在于 repack_dict 函数:
-
问题 :MMEngine 的
Config可能是深度嵌套的字典,而 SwanLab 的config通常期望是扁平的结构 -
解决 :递归地将嵌套字典展平为
parent/child格式的键值对 -
例如 :
{'a': {'b': 1, 'c': 2}}变为{'a/b': 1, 'a/c': 2}
6.核心记录方法
python
@force_init_env
def add_image(self, name: str, image: np.ndarray, step: int = 0, **kwargs) -> None:
image = self._swanlab.Image(image)
self._swanlab.log({name: image}, step=step)
@force_init_env
def add_scalar(self, name: str, value: Union[int, float], step: int = 0, **kwargs) -> None:
self._swanlab.log({name: value}, step=step)
@force_init_env
def add_scalars(self, scalar_dict: dict, step: int = 0, **kwargs) -> None:
self._swanlab.log(scalar_dict, step=step)这些方法的逻辑非常简单:
-
输入 :接收 MMEngine 标准格式的数据(
name,value,step) -
转换 :将数据封装为 SwanLab 可接受的格式(如
swanlab.Image) -
输出 :调用
self._swanlab.log()将数据发送到 SwanLab
这正是桥接器模式的完美体现!
7.资源释放close
python
def close(self) -> None:
"""close an opened swanlab object."""
if hasattr(self, "_swanlab"):
self._swanlab.finish()确保训练结束时正确关闭 SwanLab 连接,完成数据上传。
核心设计模式
1.延迟初始化
python
@force_init_env
def add_scalar(self, name: str, value: Union[int, float], step: int = 0, **kwargs) -> None:
# 如果 _init_env 还没调用,@force_init_env 会自动调用
self._swanlab.log({name: value}, step=step)-
只有在第一次真正需要与 SwanLab 交互时,才会初始化环境
-
避免创建不必要的 SwanLab 连接
2.参数透传
python
# 用户代码
swanlab_backend = SwanlabVisBackend(init_kwargs={
"project": "my-project",
"experiment_name": "resnet50"
})
# 最终调用
swanlab.init(project="my-project", experiment_name="resnet50", logdir=save_dir)代码层面mmengine与swanlab的关系--职责分离
python
# MMEngine 负责统计
message_hub.update_scalar('train/loss', 0.5) # 统计完成
# LogProcessor 负责处理
processed = log_processor.process(all_scalars) # 平滑、聚合
# LoggerHook 负责分发
runner.visualizer.add_scalars('train', processed, step)
# SwanlabVisBackend 只负责上传
class SwanlabVisBackend(BaseVisBackend):
def add_scalars(self, scalar_dict, step):
# 直接上传,不做任何统计
self._swanlab.log(scalar_dict, step=step)mmengine底层如何统计loss等metrics?可否自定义增删改?
1、底层统计loss等指标的实现机制
这些指标由mmengine底层统计,通过SwanlabVisBackend上传到SwanLab.
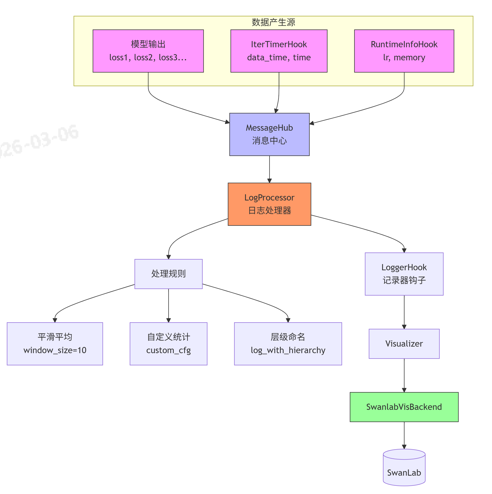
2.核心组件
(1)LogProcessor - 日志处理核心
- 代码路径 :
mmengine/runner/log_processor.py
LogProcessor 是统计逻辑的核心,它负责:
-
从
MessageHub获取原始数据 -
按照配置规则进行统计(平均、平滑等)
-
格式化后传递给
LoggerHook
python
class LogProcessor:
def __init__(self,
window_size=10, # 平滑窗口大小
by_epoch=True, # 是否按epoch统计
custom_cfg=None, # 自定义统计规则
log_with_hierarchy=False, # 是否启用层级命名
mean_pattern='.*(loss|time|data_time|grad_norm).*'): # 正则匹配需要平滑的指标(2)BaseMetric - 评估指标基类
- 代码路径 :
mmengine/evaluator/metric.py
BaseMetric 负责模型评估指标(如 accuracy、mAP 等)的统计
python
class BaseMetric(metaclass=ABCMeta):
def process(self, data_batch, data_samples):
"""处理每个batch的数据"""
# 1. 提取预测结果和标签
# 2. 计算当前batch的统计值
# 3. 存入 self.results
pass
def compute_metrics(self, results):
"""计算最终指标"""
# 1. 汇总所有batch的结果
# 2. 计算最终指标
# 3. 返回指标字典
pass
def evaluate(self, size):
"""分布式环境下的评估"""
# 1. 收集所有rank的结果
# 2. 只在主进程计算指标
# 3. 广播结果
pass3.不同指标的统计机制/工作原理
LogProcessor 的正则匹配
从 MMEngine 的 LogProcessor 源码中可以看到,它使用正则表达式来匹配需要自动统计的指标
python
class LogProcessor:
def __init__(self,
window_size=10,
by_epoch=True,
# 默认的正则匹配模式:匹配 loss/time/data_time/grad_norm
mean_pattern='.*(loss|time|data_time|grad_norm).*'):
self.mean_pattern = re.compile(mean_pattern)这个 mean_pattern 就是用来匹配需要自动进行平滑统计的字段。默认情况下,它会匹配:
-
所有包含
loss的字段(如loss、loss1、loss_cls、loss_bbox等) -
所有包含
time的字段 -
所有包含
data_time的字段 -
所有包含
grad_norm的字段
数据的完整流向是:
-
模型 forward 返回字典 :包含
loss1、loss2等字段 -
MessageHub 收集:这些值被更新到消息枢纽的历史缓冲区中
-
LogProcessor 处理:按照配置进行统计(平滑平均、最大值、最小值等)
-
LoggerHook 分发:将处理后的数据发送到 Visualizer
-
Visualizer 输出:通过各个 VisBackend(包括 SwanlabVisBackend)展示
一个表格归纳:
| 指标 | 统计组件 | 代码位置 | 统计方式 |
|---|---|---|---|
| loss | 模型 + LogProcessor |
模型代码 + mmengine/runner/log_processor.py |
平滑平均(默认window=10) |
| data_time | IterTimerHook |
mmengine/hooks/iter_timer_hook.py |
实时值 + 平滑平均 |
| time | IterTimerHook |
mmengine/hooks/iter_timer_hook.py |
实时值 + 平滑平均 |
| lr | RuntimeInfoHook |
mmengine/hooks/runtime_info_hook.py |
实时值 |
| accuracy | BaseMetric 子类 |
mmengine/evaluator/metric.py |
全局平均 |
4.如何只保留需要的指标,屏蔽不需要的
MMEngine提供了灵活的配置方式来选择性记录指标,主要通过LogProcessor的custom_cfg参数控制。
方法1:使用method='ignore'屏蔽不需要的指标
python
# config.py
log_processor = dict(
window_size=10,
by_epoch=True,
custom_cfg=[
# 屏蔽 data_time 指标(完全不被记录)
dict(data_src='data_time', method='ignore'),
# 屏蔽 time 指标
dict(data_src='time', method='ignore'),
# 可以继续添加其他想屏蔽的指标
# dict(data_src='loss_cls', method='ignore'),
]
)方法2:完全自定义需要记录的指标列表
如果你想完全掌控,可以创建一个自定义的Hook来选择性记录:
python
@HOOKS.register_module()
class SelectiveLogHook(Hook):
"""选择性记录日志的Hook"""
def __init__(self, keep_metrics=None, interval=10):
self.keep_metrics = keep_metrics or ['loss', 'lr']
self.interval = interval
def after_train_iter(self, runner, batch_idx, data_batch=None, outputs=None):
if not self.every_n_train_iters(runner, self.interval):
return
if not is_main_process():
return
# 从message_hub获取所有指标
all_scalars = runner.message_hub.log_scalars
# 只记录需要的指标
for name in self.keep_metrics:
if name in all_scalars:
history = all_scalars[name]
if history:
value = history[-1] # 取最新值
runner.message_hub.update_scalar(f'train/{name}', value)
# 其他指标不会被记录详解custome_cfg自定义需要统计的指标
python
classmmengine.runner.LogProcessor(window_size=10, by_epoch=True, custom_cfg=None, num_digits=4)
A log processor used to format log information collected from runner.message_hub.log_scalars.
LogProcessor instance is built by runner and will format runner.message_hub.log_scalars to tag and log_str, which can directly used by LoggerHook and MMLogger. Besides, the argument custom_cfg of constructor can control the statistics method of logs.
参数
1.window_size (int) -- default smooth interval Defaults to 10.
2.by_epoch (bool) -- Whether to format logs with epoch stype. Defaults to True.
3.custom_cfg (list[dict], optional) --
Contains multiple log config dict, in which key means the data source name of log and value means the statistic method and corresponding arguments used to count the data source. Defaults to None.
(1)If custom_cfg is None, all logs will be formatted via default methods, such as smoothing loss by default window_size. If custom_cfg is defined as a list of config dict, for example: [dict(data_src=loss, method='mean', log_name='global_loss', window_size='global')]. It means the log item loss will be counted as global mean and additionally logged as global_loss (defined by log_name). If log_name is not defined in config dict, the original logged key will be overwritten.
(2)The original log item cannot be overwritten twice. Here is an error example: [dict(data_src=loss, method='mean', window_size='global'), dict(data_src=loss, method='mean', window_size='epoch')]. Both log config dict in custom_cfg do not have log_name key, which means the loss item will be overwritten twice.
(3)For those statistic methods with the window_size argument, if by_epoch is set to False, windows_size should not be epoch to statistics log value by epoch.
4.num_digits (int) -- The number of significant digit shown in the logging message.由注释可以理解:
custom_cfg 的三种核心用途
| 用途 | 说明 | 代码示例 |
|---|---|---|
| 1. 新增统计方式 | 为指标添加额外的统计方式(保留原指标) | dict(data_src='loss', log_name='loss_global', method_name='mean', window_size='global') |
| 2. 覆盖统计方式 | 改变指标的默认统计方式(不指定 log_name) |
dict(data_src='loss', method_name='max', window_size=100) |
| 3. 组合多个统计 | 同时使用多种统计方法 | 可以同时添加均值、最大值、最小值等多个统计 |
如果你想统计其他自定义指标,可以通过 custom_cfg 配置。默认情况下,所有指标都会被记录 ,custom_cfg 是用来改变这些指标的统计方式(如均值、最大值、最小值)
python
log_processor = dict(
type='LogProcessor',
window_size=10,
by_epoch=True,
custom_cfg=[
# 统计 accuracy(默认不会被捕获),这里新增一个指标
dict(
data_src='accuracy', # 数据源
method_name='mean', # 统计方法
window_size=20 # 平滑窗口
),
# 为 loss 添加全局平均统计(同时保留原 loss)
dict(
data_src='loss',
log_name='loss_global', # 有log_name,新增一个指标,在loss表上展示两条曲线
method_name='mean',
window_size='global'
),
]
)5.LogProcessor 捕获指标汇总
根据 MMEngine 的设计,LogProcessor 默认捕获的不仅仅是 loss,而是以下几类:
| 指标类型 | 捕获方式 | 来源 | 是否自动捕获 |
|---|---|---|---|
loss* 字段 |
从模型返回值 | model.forward 返回的字典 |
✅ 是 |
time |
IterTimerHook |
message_hub |
✅ 是 |
data_time |
IterTimerHook |
message_hub |
✅ 是 |
lr |
RuntimeInfoHook |
message_hub |
✅ 是 |
| 其他字段 | 需通过 custom_cfg 配置 |
message_hub |
❌ 否 |
记住:SwanLab本身不产生指标,只负责展示!
python
需要明确:SwanLab的SwanlabVisBackend只是一个可视化后端,它本身不产生任何指标。所有展示的指标(loss、accuracy、mAP等)都是由:
MMEngine的Hook自动统计(如IterTimerHook统计data_time/time)
用户模型的返回值(如loss、accuracy)
用户配置的Evaluator(如Accuracy、mAP)
例如:
accuracy指标是通过自定义BaseMetric子类实现的。这意味着:
不是默认自动出现的
用户需要在配置文件中设置val_evaluator或test_evaluator
如果是分类任务,MMDetection等框架会预置Accuracy类mmengine底层是如何上传config?可否自定义增删改?
init_kwargs 中的 config 参数
基本用法
python
vis_backends = [
dict(
type="SwanlabVisBackend",
init_kwargs={
"project": "my-project",
"experiment_name": "resnet50-exp",
"config": {
"model": "ResNet50",
"dataset": "CIFAR10",
"batch_size": 128,
"learning_rate": 0.01,
"optimizer": "SGD",
"epochs": 100,
"backbone": {
"depth": 50,
"pretrained": True
}
}
}
)
]config 参数的作用和实现机制
作用:记录实验的超参数和配置
这个 config 字典会被 SwanLab 记录,并在 Web 界面上展示,用于:
-
复现实验:记录所有超参数
-
对比实验:不同实验的配置对比
-
实验管理:快速查看实验设置
设置实验配置
在代码中定义:
python
#========(1)在init中设置========
import swanlab
# 定义一个config字典
config = {
"hidden_layer_sizes": [64, 128],
"activation": "ELU",
"dropout": 0.5,
"num_classes": 10,
"optimizer": "Adam",
"batch_normalization": True,
"seq_length": 100,
}
# 在你初始化SwanLab时传递config字典
run = swanlab.init(project="config_example", config=config)
#=========(2)用argparse设置========
import argparse
import swanlab
# 初始化Argparse
parser = argparse.ArgumentParser()
parser.add_argument('--epochs', default=20)
parser.add_argument('--learning-rate', default=0.001)
args = parser.parse_args()
swanlab.init(config=args)
等同于 swanlab.init(config={"epochs": 20, "learning-rate": 0.001})
#=========(3)在脚本的不同位置设置========
#可以在整个脚本的不同位置向 config 对象添加更多参数.
import swanlab
# 定义一个config字典
config = {
"hidden_layer_sizes": [64, 128],
"activation": "ELU",
"dropout": 0.5,
# ... 其他配置项
}
# 在你初始化SwanLab时传递config字典
run = swanlab.init(project="config_example", config=config)
# 在你初始化SwanLab之后,更新config
swanlab.config["dropout"] = 0.8
swanlab.config.epochs = 20
swanlab.config.set["batch_size", 32]
#=========(4)用配置文件设置========
可以用json和yaml配置文件初始化 config.
参考链接:https://docs.swanlab.cn/guide_cloud/experiment_track/create-experiment-by-configfile.html
Note:脚本内参数的优先级大于配置文件,即脚本内参数会覆盖配置文件参数config参数的两种来源
- 来源1:手动指定(如上例)
- 来源2:mmengine配置自动生成
如何关闭系统硬件监控?
python
swanlab.init(
settings=swanlab.Settings(
hardware_monitor=False,
)
)更多
python
# config.py
vis_backends = [
dict(
type="SwanlabVisBackend",
init_kwargs={
"project": "my-project",
"experiment_name": "controlled-config-exp",
"config": { # 这里只放你想显示的配置
"model": "ResNet50",
"batch_size": 128,
"learning_rate": 0.01,
"optimizer": "SGD",
},
"settings": { # 关闭自动采集
"metadata_collect": False,
"collect_hardware": False,
"requirements_collect": False,
}
}
)
]mmengine底层展示系统级指标如何实现?可否自定义增删改?
指标数量对训练速度和SwanLab的影响
根据SwanLab官方文档,有明确的性能优化建议:
python
# 1. 控制指标总数(建议<10,000)
# ❌ 不推荐:创建过多不同的metric名
for i, param in enumerate(model.parameters()):
swanlab.log({f'param_grad_{i}': grad_norm}) # 如果参数很多,会创建大量metric
# ✅ 推荐:合并同类指标
grad_norms = {'layer1': 0.5, 'layer2': 0.3, 'layer3': 0.2}
swanlab.log(grad_norms) # 一次性记录多个
# 2. 控制记录频率(建议<50k数据点/metric)
# ✅ 推荐:每N个iter记录一次
log_interval = 100 # 每100个iter记录一次
if step % log_interval == 0:
swanlab.log({"loss": loss})
# 3. 控制metric宽度(建议<10M)
# metric宽度 = max(step) - min(step)
# 如果训练100万iter,每iter都记录,宽度=1,000,000 ✅
# 如果训练1亿iter,每iter都记录,宽度=100,000,000 ⚠️ 建议降低频率🚀 两种集成使用方式
文档中提供了两种灵活的使用方式,适应不同的开发习惯:
直接传入(脚本方式)
这种方式更直观,适合在自定义训练脚本中快速集成。核心就是创建SwanlabVisBackend实例,并用它来初始化MMEngine的Visualizer,最后将这个Visualizer传给Runner。
python
# 关键代码片段
from swanlab.integration.mmengine import SwanlabVisBackend
from mmengine.visualization import Visualizer
# 1. 创建 SwanLab 后端实例(以字典形式传入初始化参数)
swanlab_backend = SwanlabVisBackend(init_kwargs={
"project": "my-project",
"experiment_name": "resnet50-cifar10"
})
# 2. 初始化 Visualizer 并挂载 SwanLab 后端
visualizer = Visualizer(vis_backends=swanlab_backend)
# 3. 构建 Runner 时传入 visualizer
runner = Runner(visualizer=visualizer, ...)配置声明(Config方式)
这种方式深度融入了OpenMMLab系列的配置文化,非常适合基于MMEngine的成熟框架(如MMDetection)。
python
# 配置文件片段
custom_imports = dict(imports=["swanlab.integration.mmengine"]) # 关键:动态导入
vis_backends = [
dict(
type="SwanlabVisBackend", # 根据type在VISUALIZERS注册表中找到类
init_kwargs={
"project": "swanlab-mmengine",
"experiment_name": "Your exp",
}
)
]
visualizer = dict(type="Visualizer", vis_backends=vis_backends)配置方式的巧妙之处在于:
-
custom_imports:告诉MMEngine在运行时动态导入swanlab.integration.mmengine模块,从而将SwanlabVisBackend类注册到MMEngine的注册表中。 -
type='SwanlabVisBackend':MMEngine根据这个type,从注册表中找到对应的类并实例化。