一、先感受一下问题的严重性
Self-Attention 的计算方式是:每个词的 Q 去和所有词的 K 做点积,然后加权求和。
这个过程里,词的顺序根本没有参与计算。
打个比方:你把一句话的词写在卡片上,打乱顺序扔在桌上,Self-Attention 算出来的结果和没打乱完全一样。
这显然是个大问题:

语言的顺序承载了巨大的语义信息,不能丢。
二、RNN 是怎么处理顺序的?
在 Transformer 出现之前,RNN 天然有顺序感------它一个词一个词地读,前一步的状态传给下一步,顺序是计算过程本身的一部分。
Transformer 为了并行计算,把顺序处理彻底抛弃了。好处是快,坏处是失去了位置信息。
解决方案 :既然计算过程不带位置,那就在输入阶段手动把位置信息塞进去。
这就是 Positional Encoding(位置编码)的由来。
三、最简单的想法:直接编号
最直觉的方案:给每个位置一个编号。

但这有两个问题:
问题一:数值太大,破坏词向量
句子很长时,位置编号会变得很大(比如 500、1000),而词向量的数值通常在 -1 到 1 之间。一个 500 和一个 0.3, -0.7, 0.1... 加在一起,位置信息会淹没词的语义信息。
问题二:无法泛化
训练时见过最长 512 个词的句子,测试时遇到第 600 个位置,模型就不知道怎么处理了。
四、Transformer 的方案:用三角函数编码
原论文用了一个优雅的方案------用正弦和余弦函数生成位置编码:
看起来很复杂,我们一点点拆解。
五、用"音乐节拍"来理解
不要被公式吓到,先感受一下它的思想。
想象一首乐曲有多个声部,每个声部的频率不同:
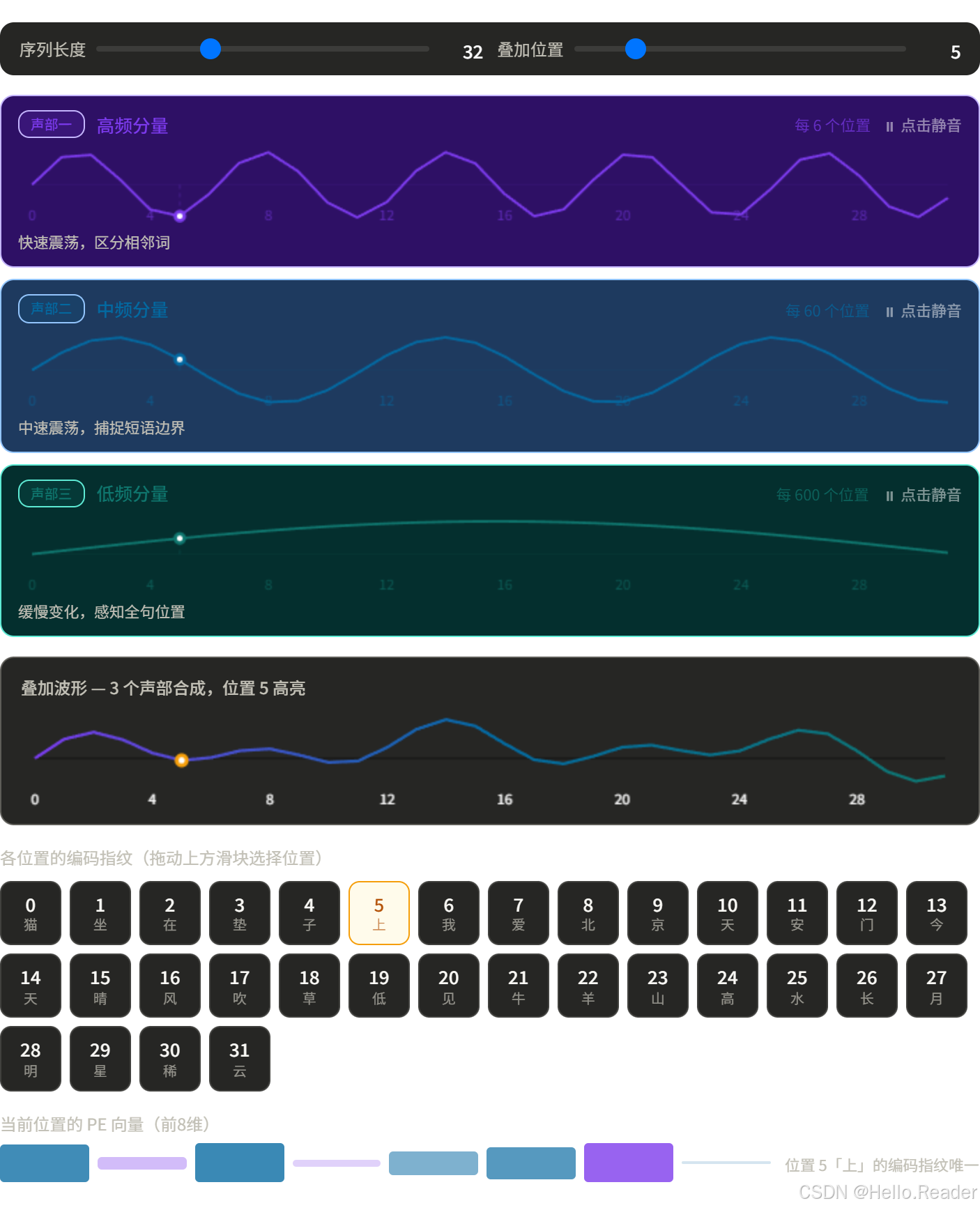
每个位置 = 所有声部在该时刻的"音量叠加"。
不同位置的叠加结果是独一无二的 ,就像每个时刻的和弦都不同。这就是位置编码的核心:用多个不同频率的信号叠加,为每个位置生成一个独特的指纹。
六、逐层拆解公式
6.1 pos 是什么?
就是词在句子里的位置:第 0 个词、第 1 个词......
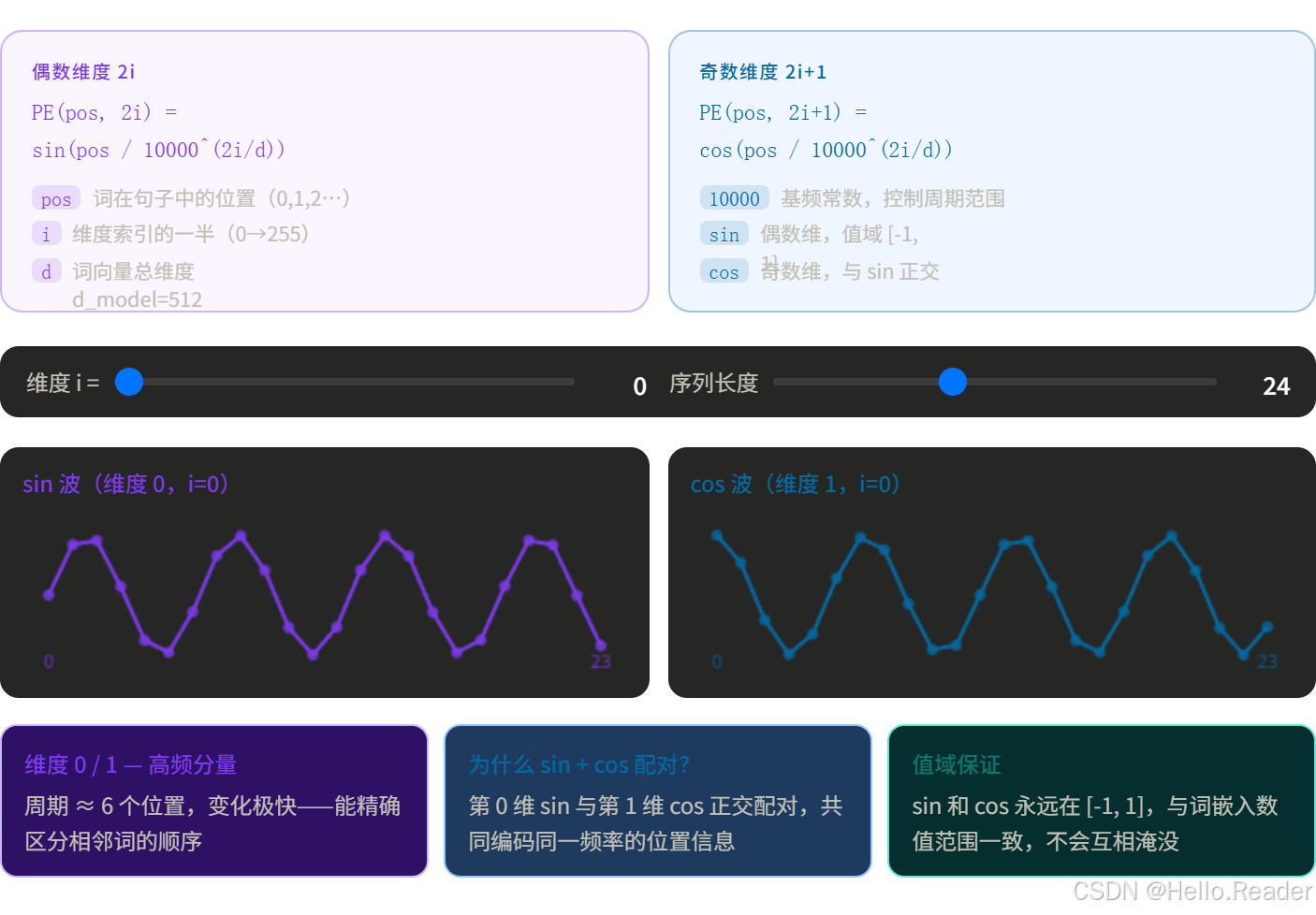
6.2 i 是什么?
词向量有 d_model 个维度(比如 512 维),i 是维度的索引(0, 1, 2 ... 255)。
偶数维度用 sin,奇数维度用 cos。
6.3 10000 ( 2 i / d m o d e l ) 10000^(2i/d_model) 10000(2i/dmodel) 是什么?
这是控制频率的分母。当 i 很小时,分母小,频率高(变化快);当 i 很大时,分母大,频率低(变化慢)。
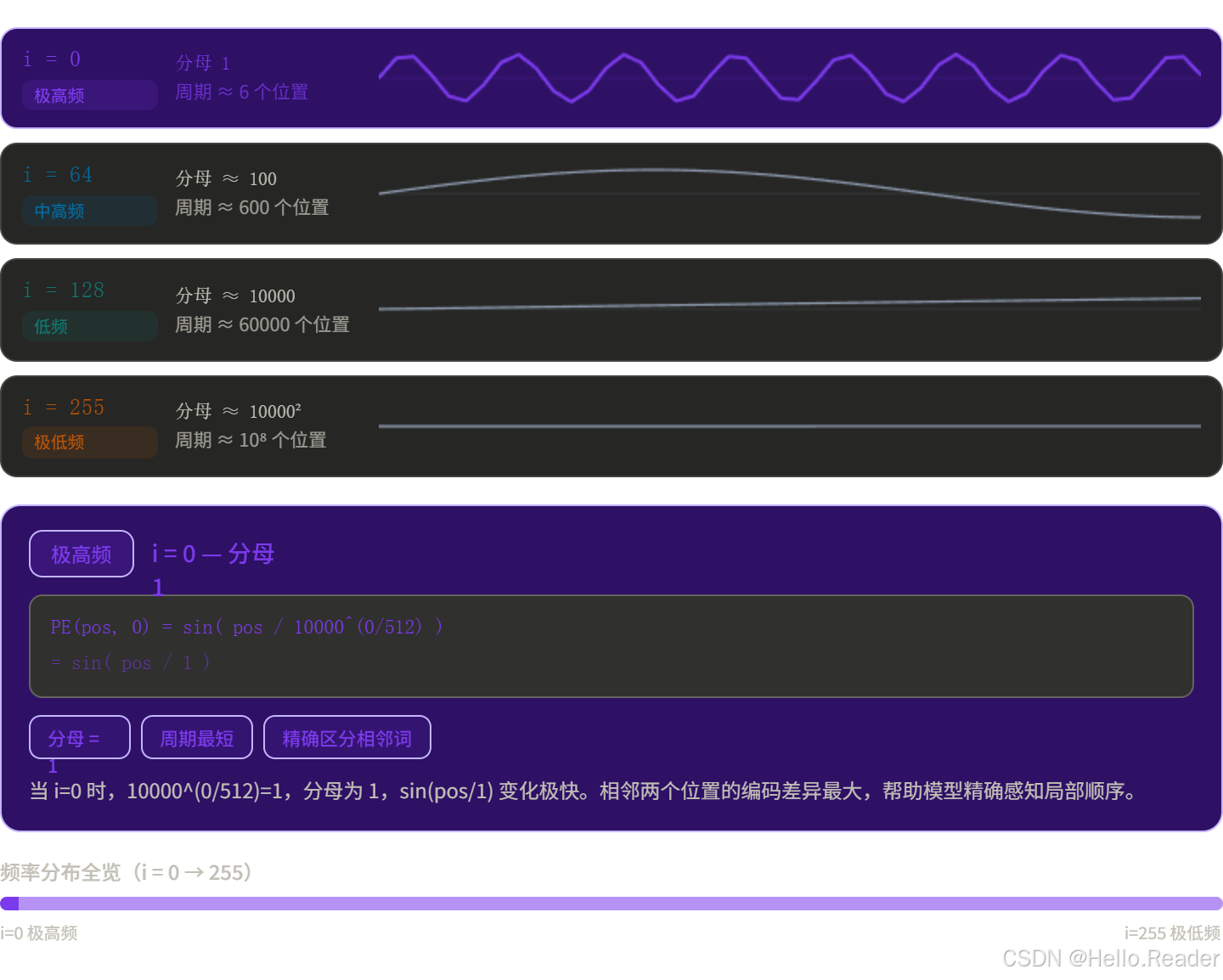
6.4 整体感受
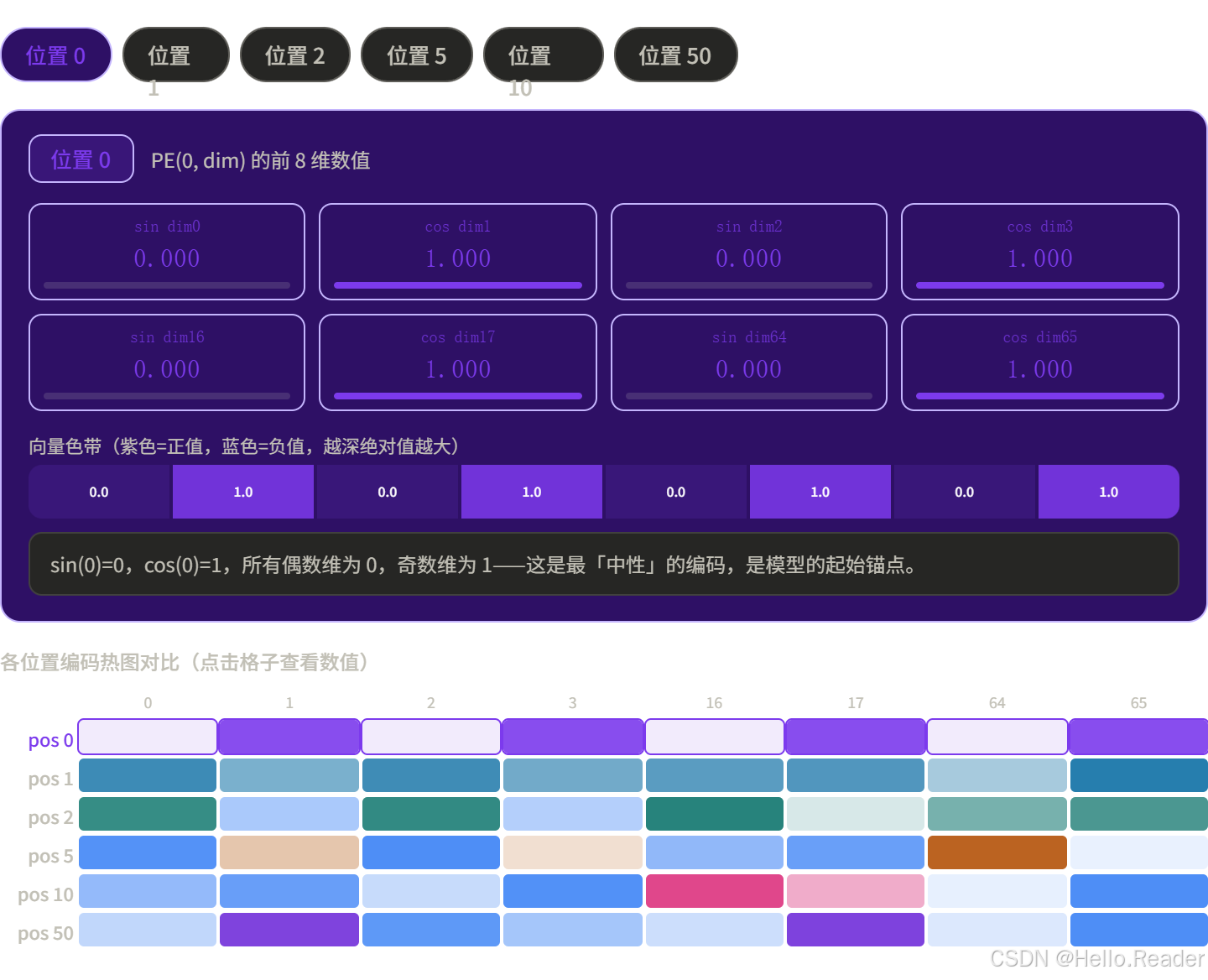
每个位置的编码都是一个独特的"条纹图案",低维变化快,高维变化慢。
七、为什么用三角函数而不是别的?
原论文的选择有两个精妙的数学性质:
性质一:值域固定在 -1, 1
sin 和 cos 的输出永远在 -1 到 1 之间,和词向量的数值范围一致,不会互相淹没。
性质二:可以表达相对位置
这是最神奇的地方。对于任意固定的偏移量 k,位置 pos+k 的编码可以用位置 pos 的编码线性变换 得到:
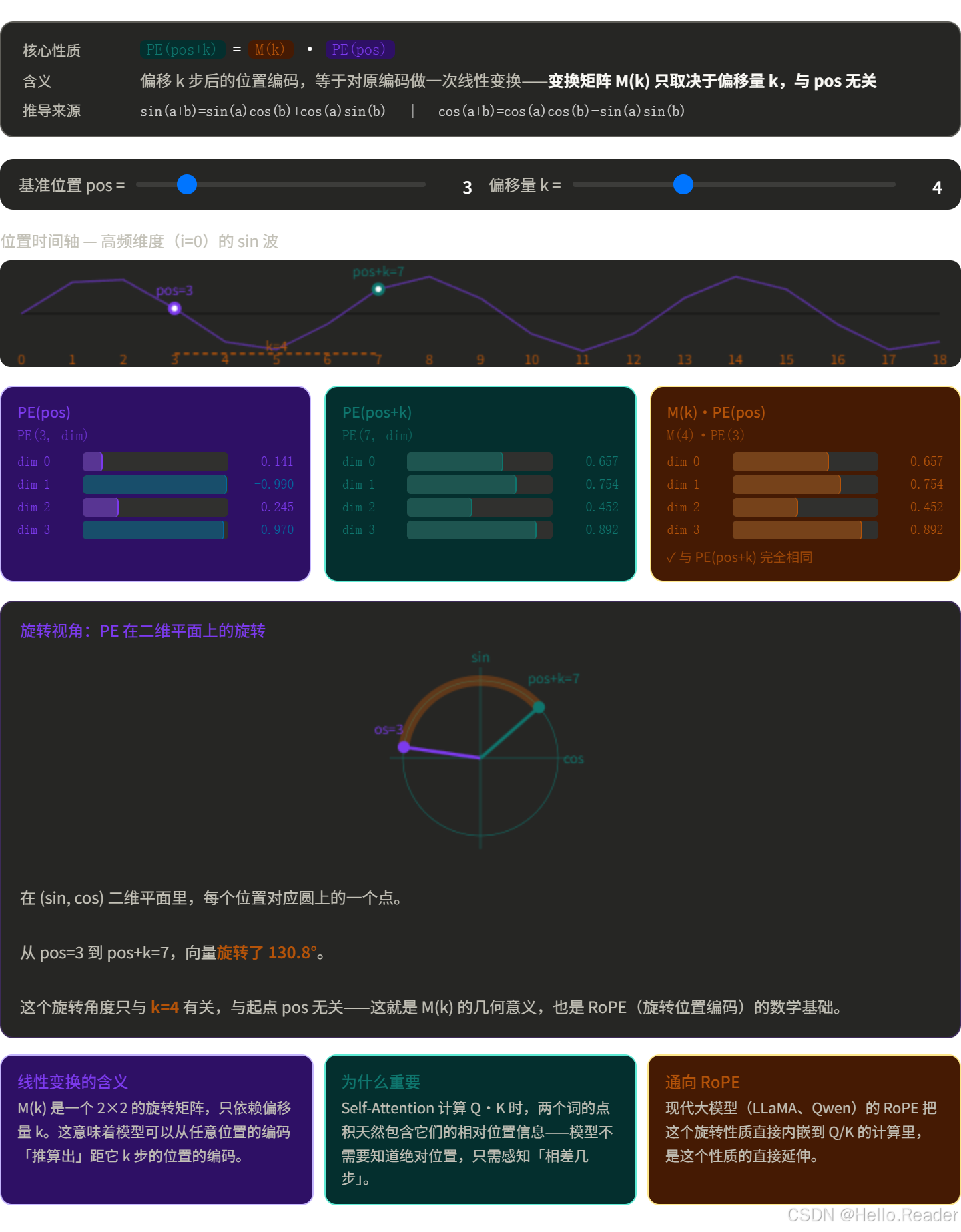
这意味着模型可以从编码里推断两词之间的距离,而不只是知道绝对位置。
比如"前3个词"这种相对位置关系,模型同样能感知到。
性质三:可以泛化到更长的句子
sin/cos 函数定义在所有实数上,不管句子多长,每个位置都能算出一个合法的编码,不会像编号方案那样"超出范围"。
八、位置编码怎么加进去?
非常简单------直接相加:
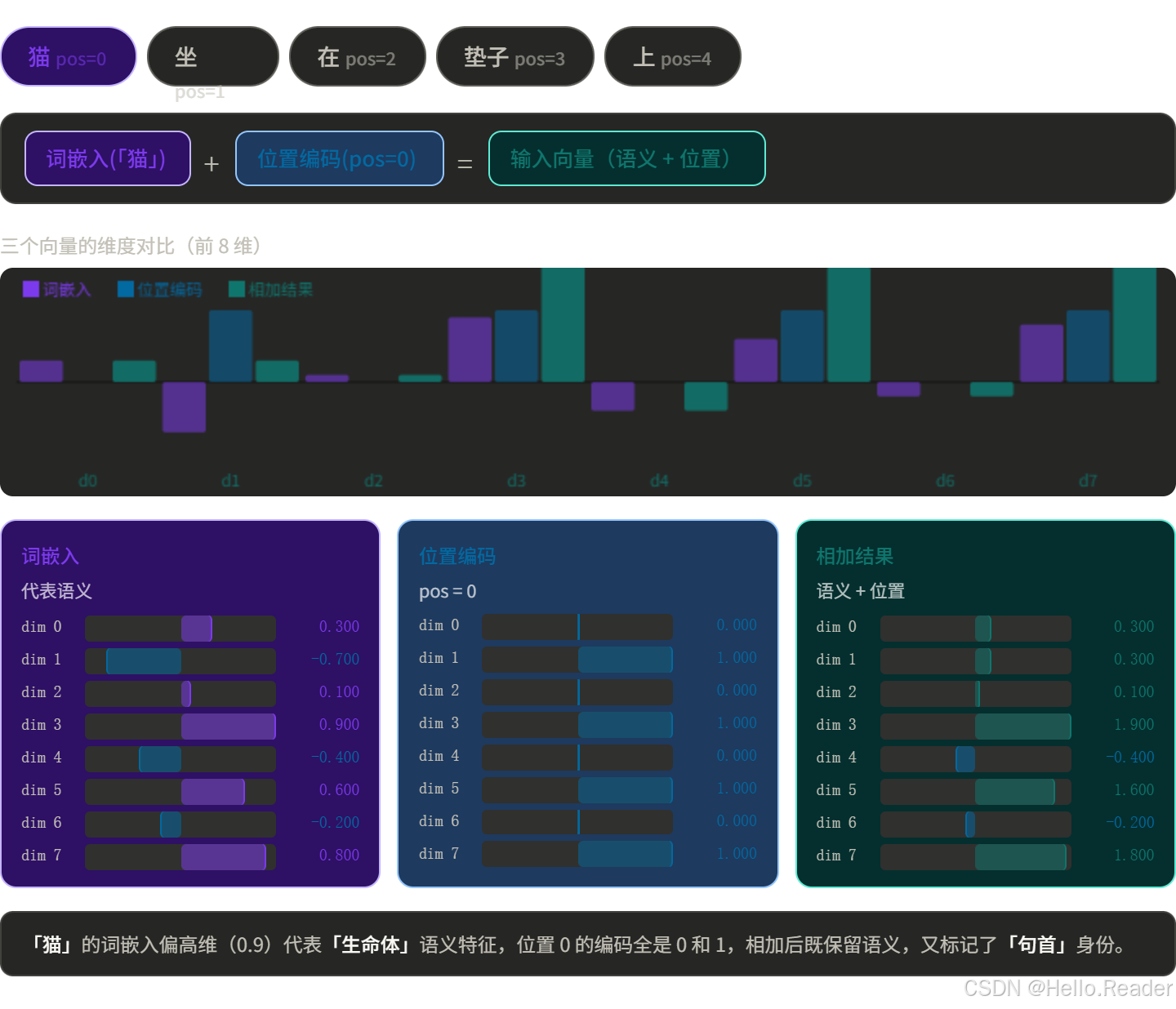
两者维度相同(都是 d_model),直接按元素加。简单粗暴,但有效。
九、可学习的位置编码 vs 固定的位置编码
原版 Transformer 用的是上面这种固定的三角函数编码,不需要训练。
但后来的模型(BERT、GPT 等)大多改用了可学习的位置编码:
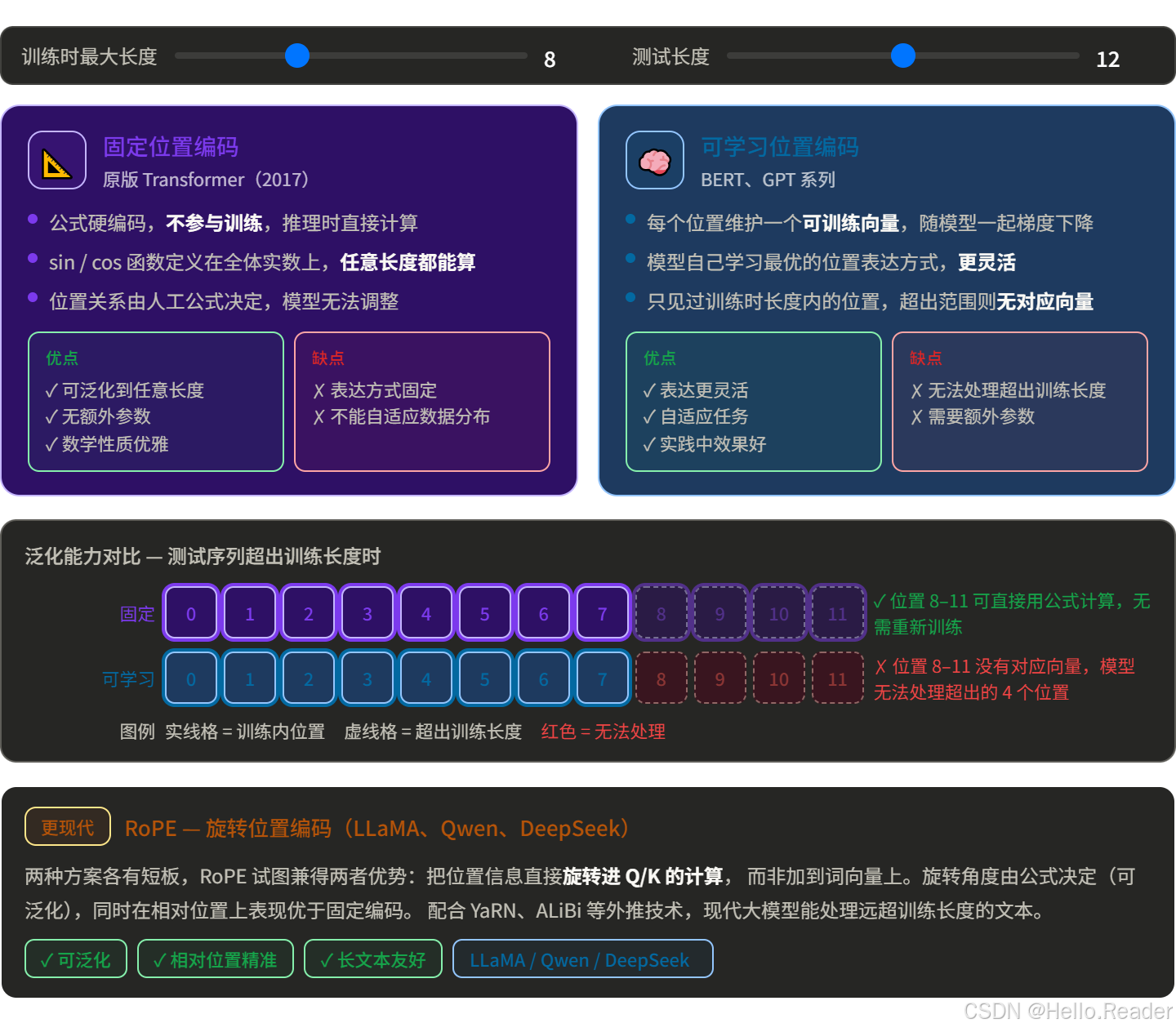
两种方案在实践中效果相近,可学习的更主流,但原版的数学更优雅。
十、更现代的方案:RoPE
近两年的大模型(LLaMA、Qwen、DeepSeek 等)普遍采用了 RoPE(旋转位置编码)。
它不是把位置编码加 到词向量上,而是在计算 Q·K 点积时,把位置信息旋转进去:
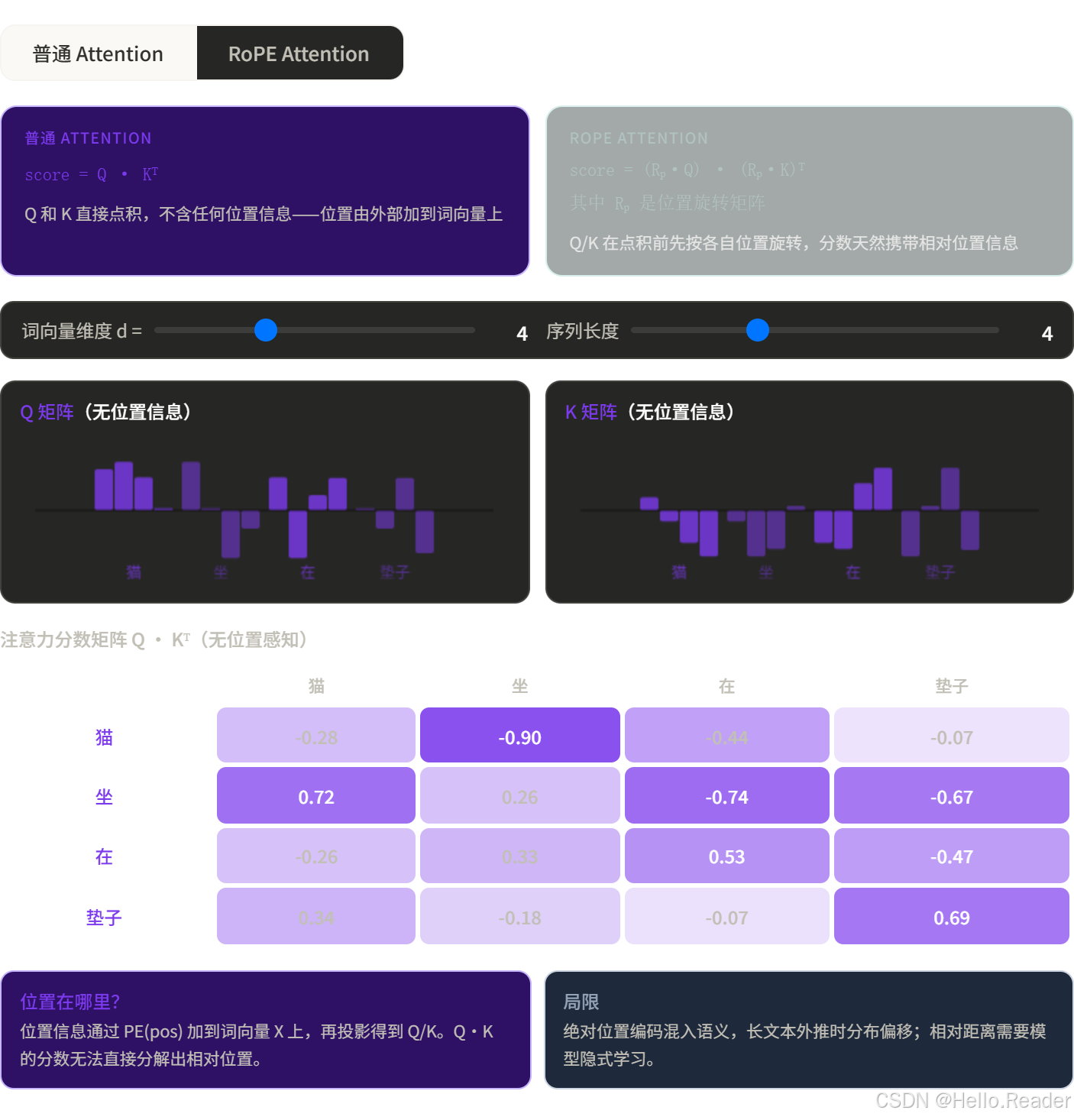
好处是:两个词的点积天然包含了它们的相对位置差,而不只是绝对位置。
这让模型在处理超长文本时更稳定,也是目前最主流的方案。
十一、三句话总结
-
问题:Self-Attention 不感知顺序,需要手动注入位置信息。
-
原版方案:用多个不同频率的 sin/cos 函数生成位置编码,直接加到词向量上。低维高频捕捉局部顺序,高维低频捕捉全局位置。
-
现代方案:可学习编码(BERT/GPT)和旋转编码 RoPE(LLaMA/Qwen)更主流,但思想一脉相承------让模型感知"谁在哪里"。
延伸阅读
- 📄 原论文:Attention Is All You Need --- Section 3.5
- 📝 RoPE 论文:RoFormer: Enhanced Transformer with Rotary Position Embedding(2021)
- 🔬 可视化:The Illustrated Transformer --- 有精美的位置编码热图