继续,先大概弄懂逻辑再改
transformer_layers.py
基本都是pytorch的处理东西,过一下就行,反正也看不懂,单纯记录一下,以后牛逼了再来看

这是从 DiT(Diffusion Transformer)里继承来的核心操作,作用是:用全局条件(比如时间步、文本 / 视频特征)去「调制」归一化后的输入。
- 先对
x做「缩放(scale)」,再做「平移(shift)」; - 这是让「全局条件」控制「局部特征」的关键,后面所有的 Transformer 块都在用它。
后面都是处理的类和函数,分成这几个
def attention():这个用来修复pytorch的一个bug
这个 Issue 说的是:在 AMP(自动混合精度)模式下,使用 torch.compile 编译数学版 SDP 注意力时会崩溃;
class SelfAttention(nn.Module)
这是 Transformer 的基础单元,处理单个模态的序列特征
class MMDitSingleBlock(nn.Module)
这是 networks.py 里 fused_blocks 用的块,负责深度融合后的单模态处理
JointBlock:多模态联合注意力块(第一阶段融合核心)
这是 networks.py 里 joint_blocks 用的块,最精彩的多模态融合就在这里
FinalBlock:最后的输出层
总结:整个 Transformer 架构的流程
- 第一阶段(JointBlock):音频、视频、文本各自算 QKV,然后拼在一起做联合注意力,互相交换信息;
- 第二阶段(MMDitSingleBlock):把融合后的特征,用卷积 Transformer 做深度处理;
- 输出(FinalBlock):调制后映射回音频潜空间,输出流预测。
其实看到这里很多都是底层的东西了,没什么必要去看了,毕竟是小白,基本上都是对一些包的调用,至于研究其他的,还是算了,基本上这些都可以跳过
主要再看一下跟前面的nodes有关联的eval_utils.py就行
eval_utils.py
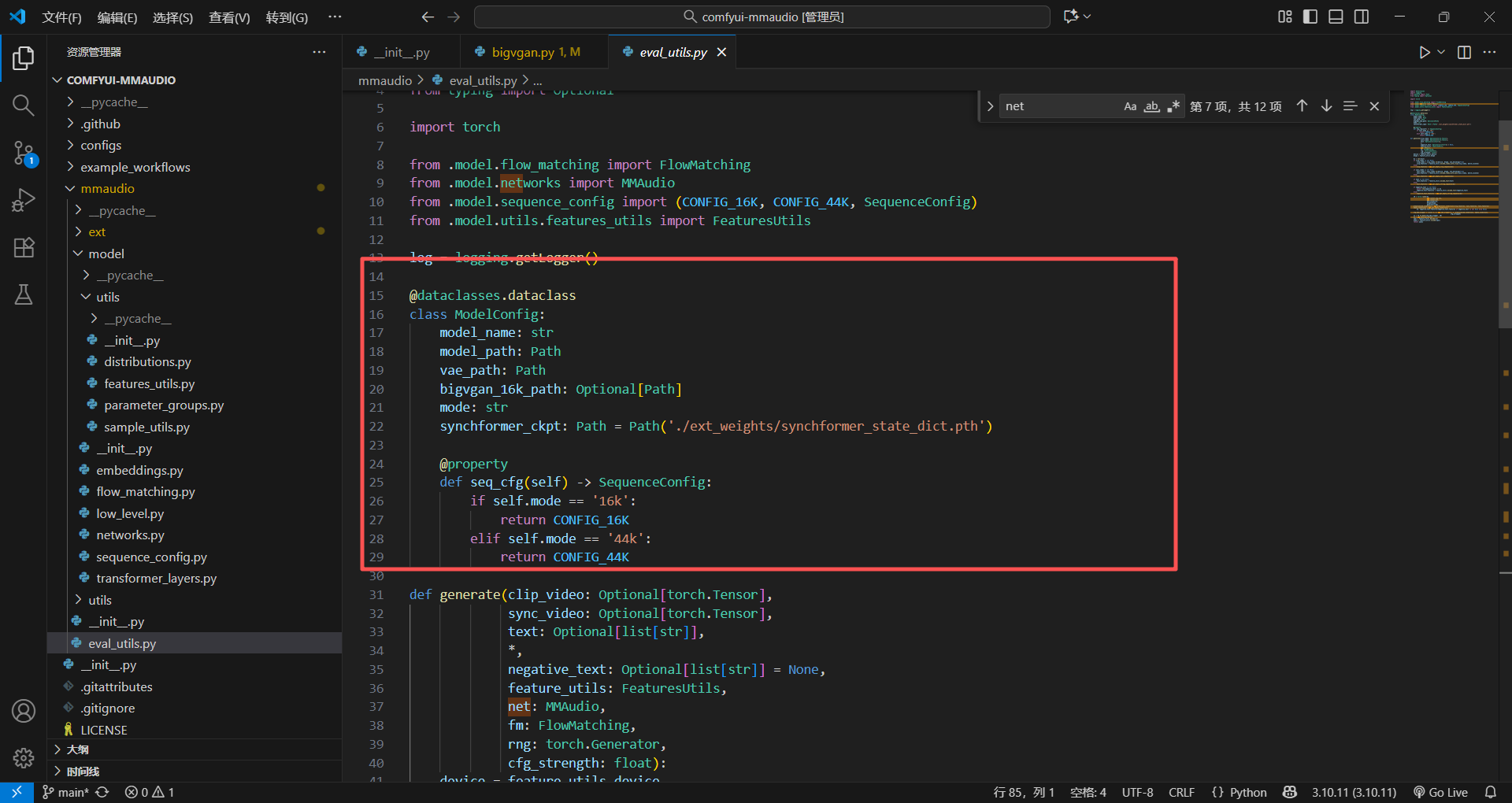
开局就是熟悉的数据装饰器,里面好多伙计都挺熟的,都是各种模型的路径,还有队列文件里面的16K还是44K,都是定义过的
核心 generate 函数:完整的生成流水线(逐段对应)
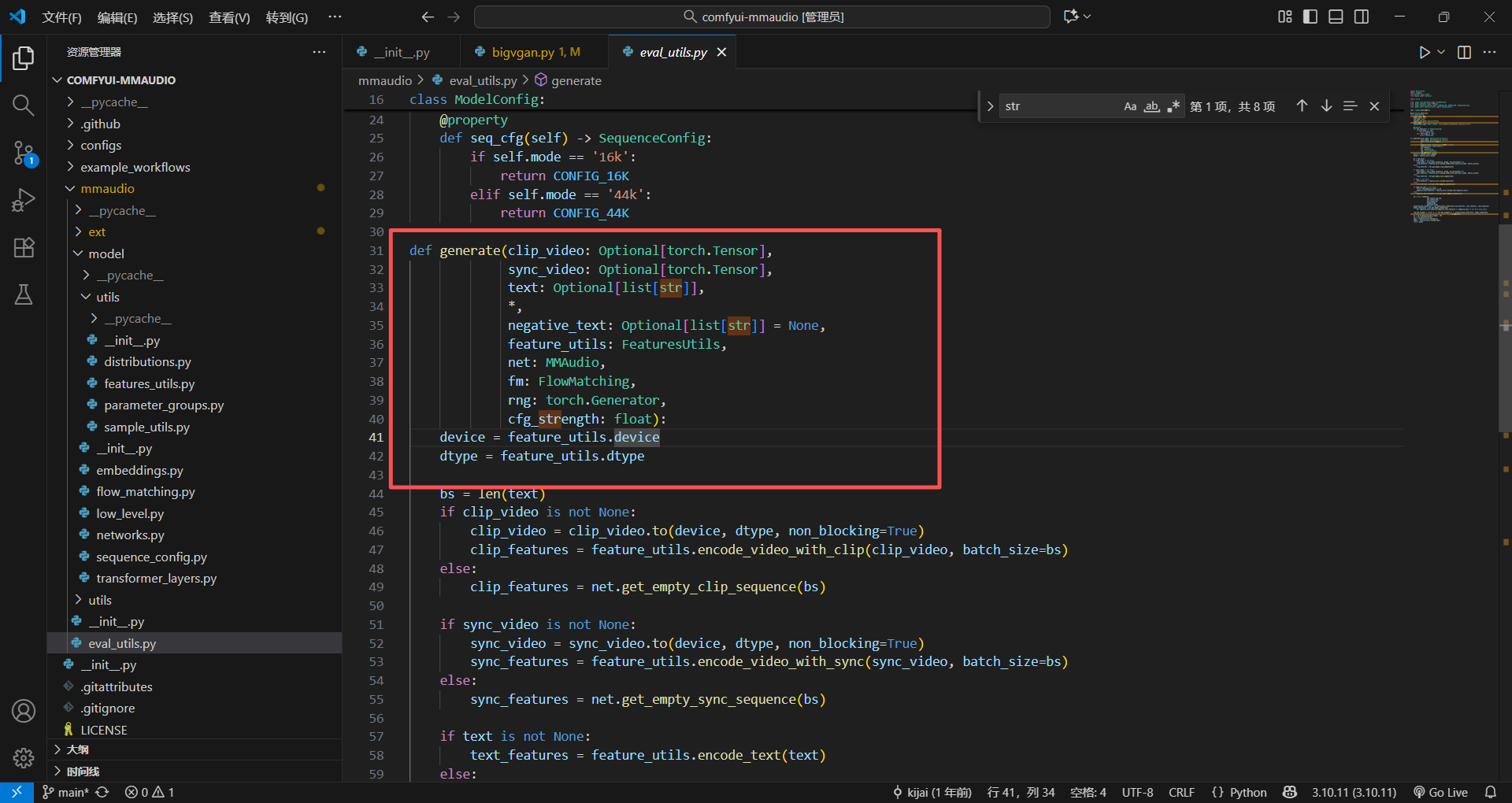
初始化就已经看到很多熟悉的人了,flow-matching,mmaudio等等
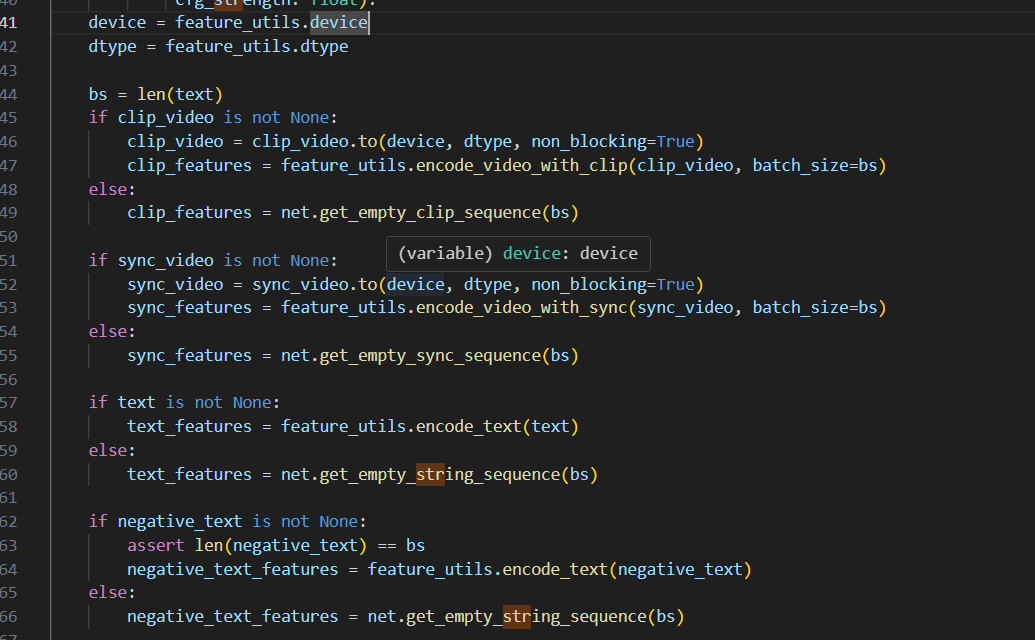
这一段就是用这些定义好的类里面的方法来提取各种特征
处理clip特征,sync特征,文本特征等,还用了判断,如果是none有一个空方法,找了一下在network文件里面
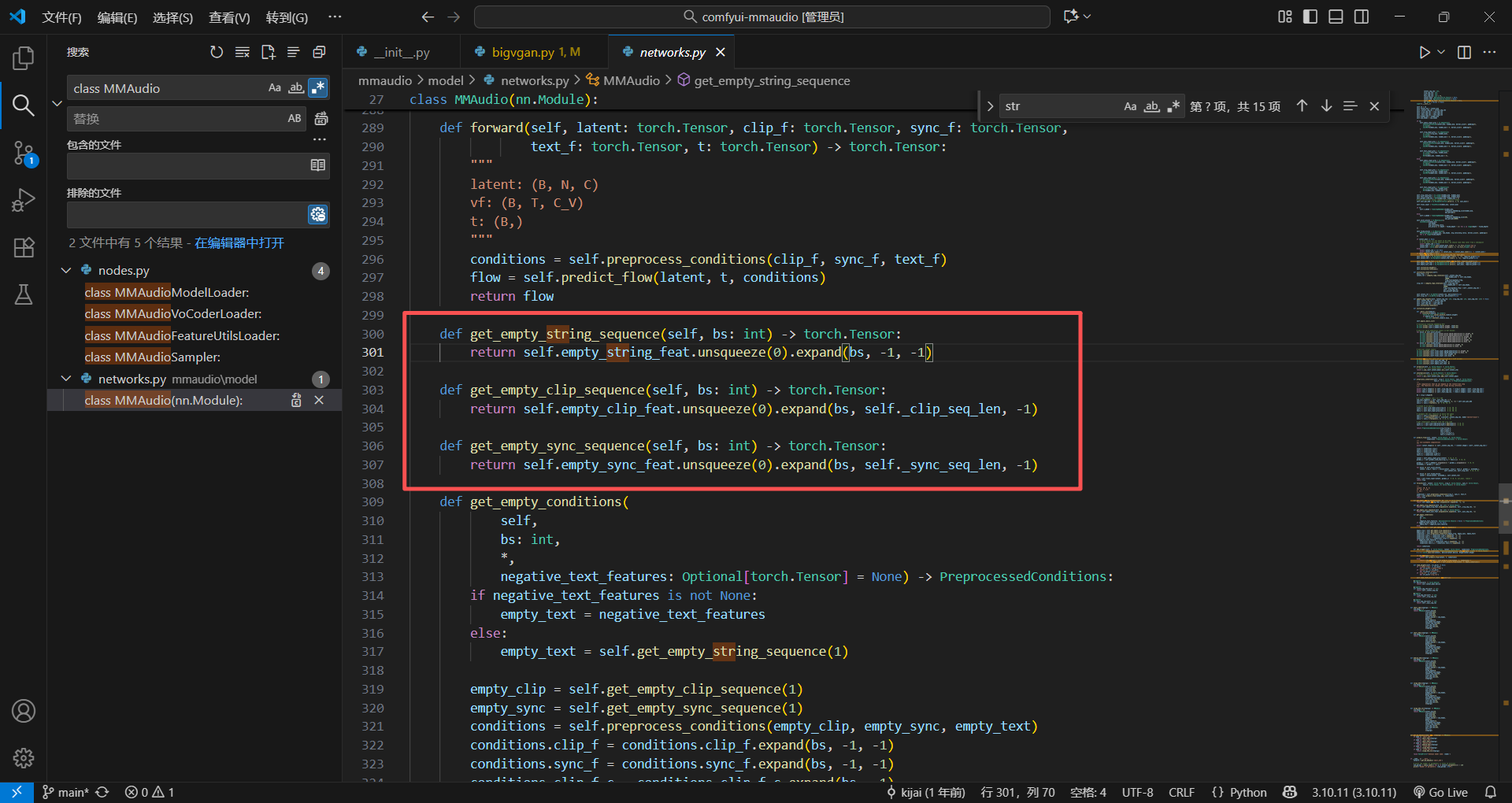
这一段就是最重要的,前面那么多底层的东西,就是为了弄到这个x1的音频的潜空间数据,然后给他转成音频就可以了
终于搞完了,接下来就是试试能不能改需求了
开始修改
暂时的需求是,搞一个可以输入的帧率,然后让sync等模型去按照这个帧率生成视频,不行我在回来加,先开始动手先
节点加帧率输入
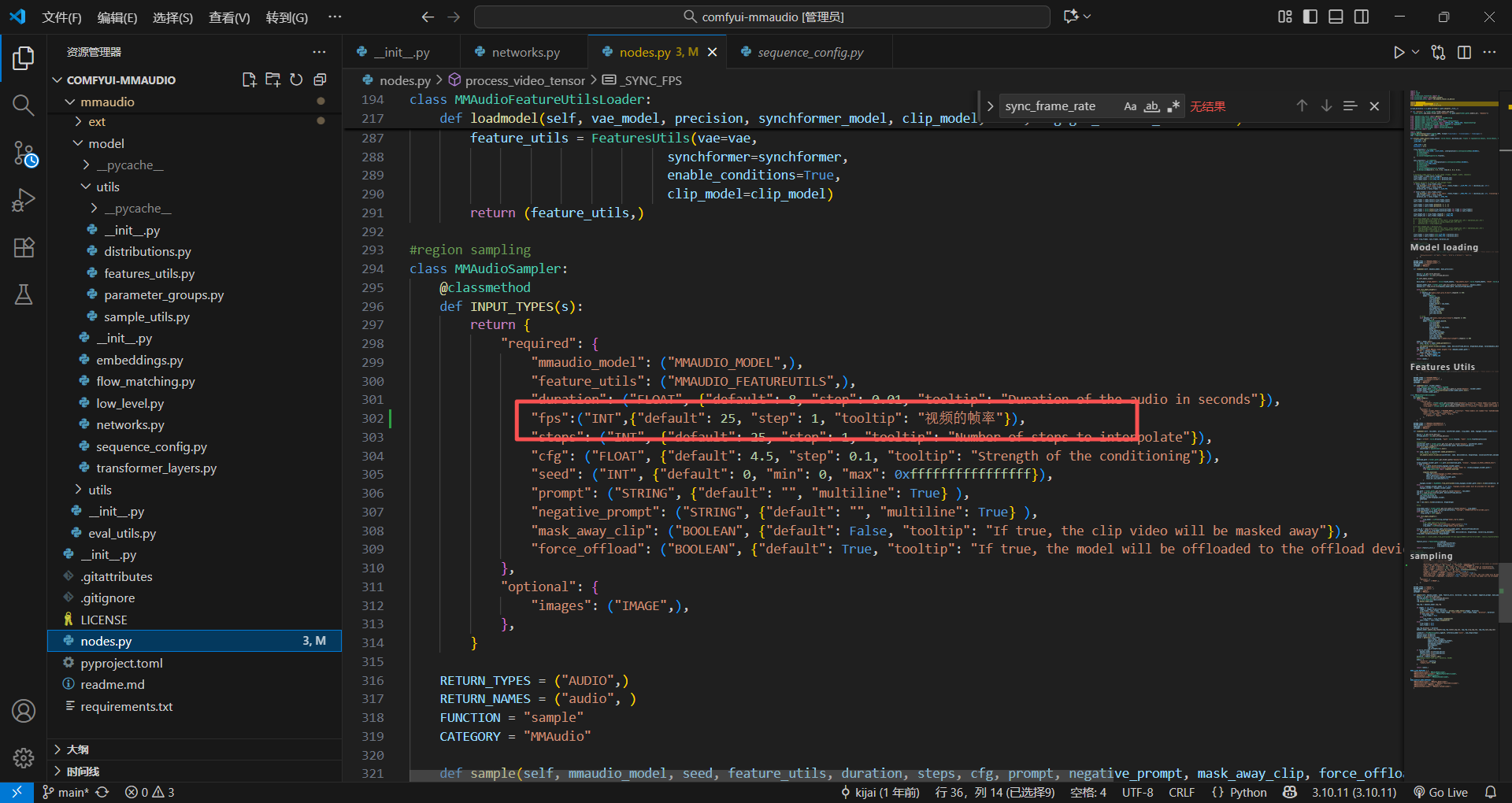
直接给节点加一个整数输入,就是可以传进来视频的帧率,看一下成功没有
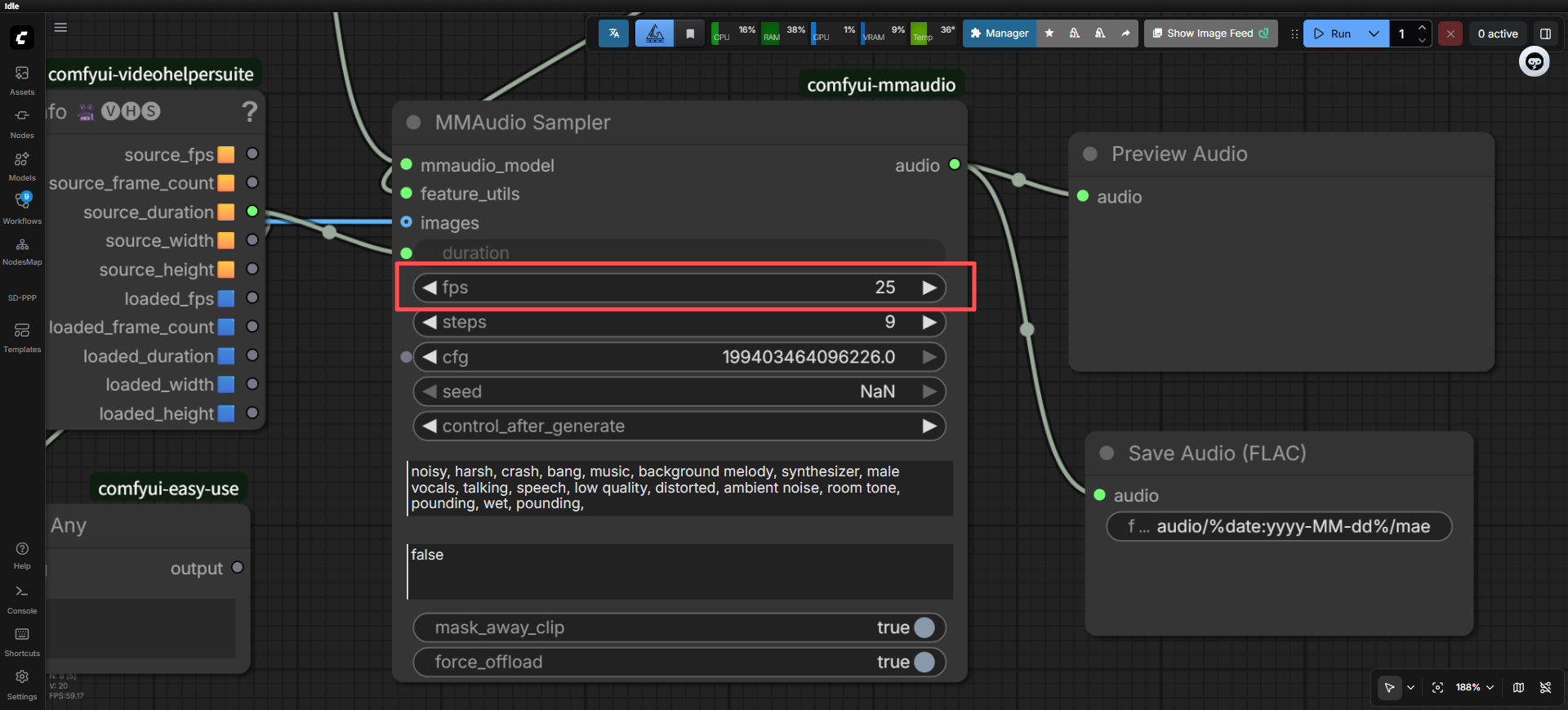
看来成功加进UI界面了,接下来就是代码帧率的处理
修改帧率
先找到那个报错的地方,就是限制时长的那个,一眼就看到了,那个说我视频时长不对的后台日志,直接搜索什么is to short或者搜索log或者print之类的输出就行了,不过都把整个插件的代码大致浏览一遍了,应该找到没啥问题
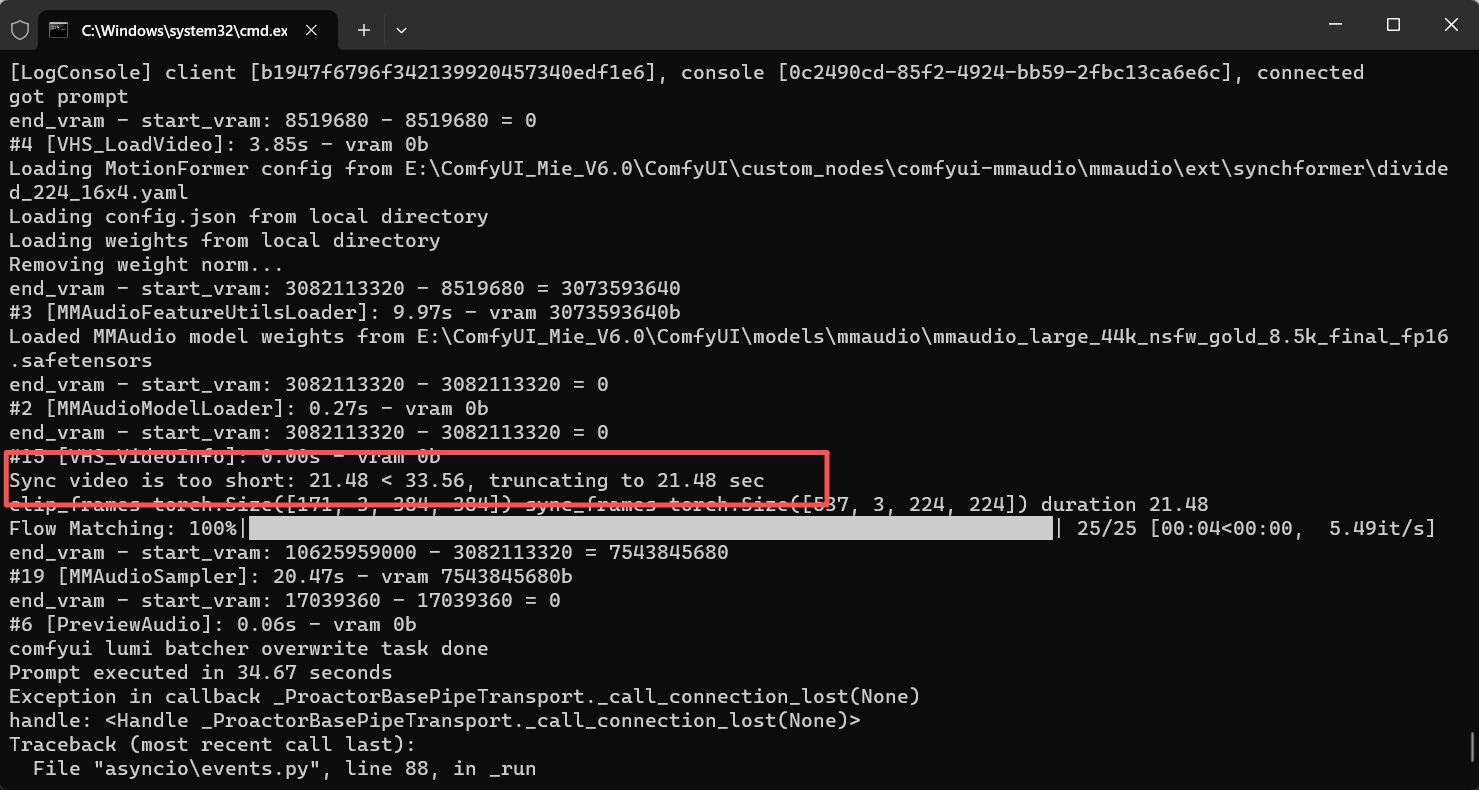
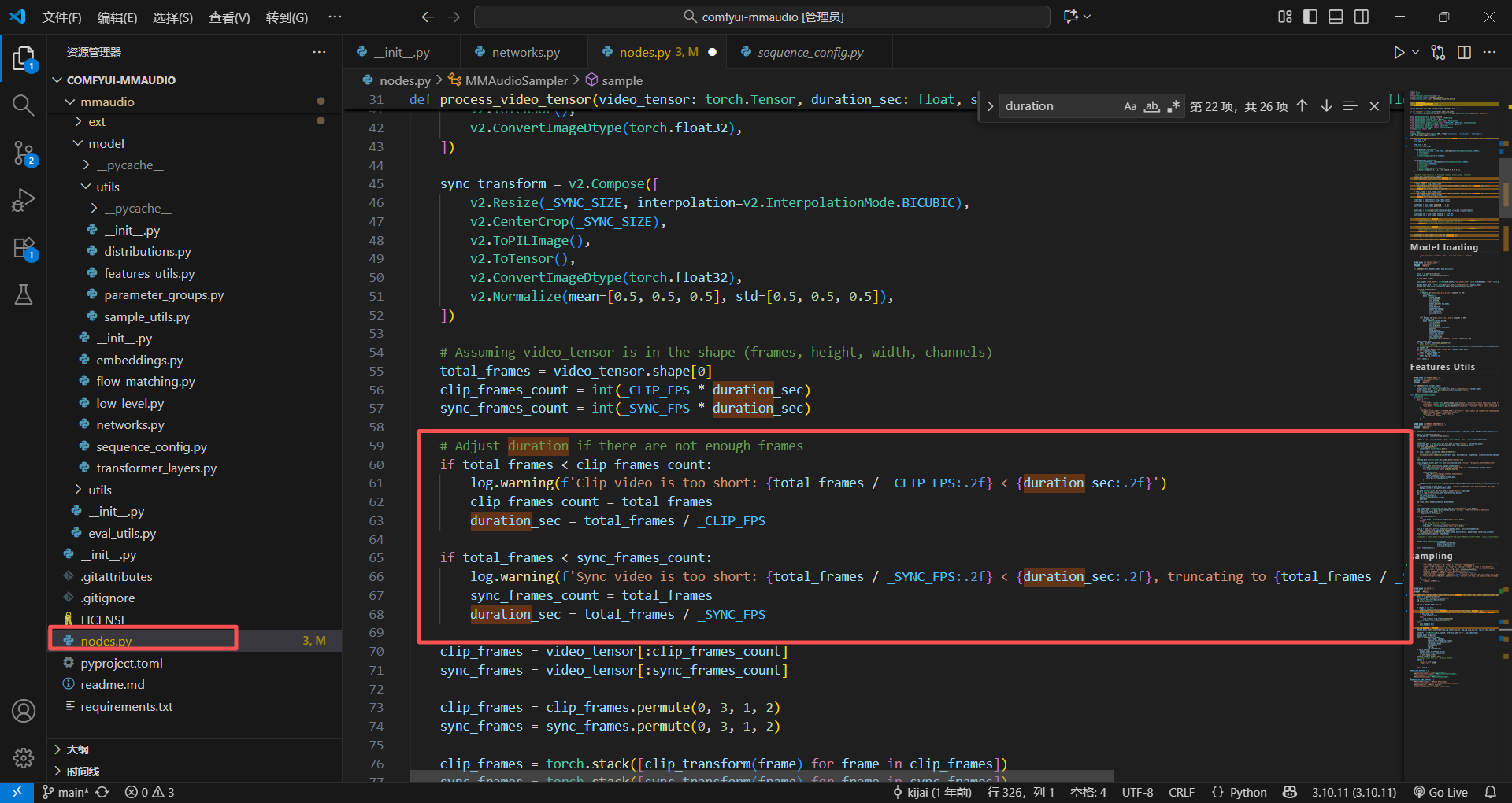
找到固定的25FPS的参数,一眼就i看到了
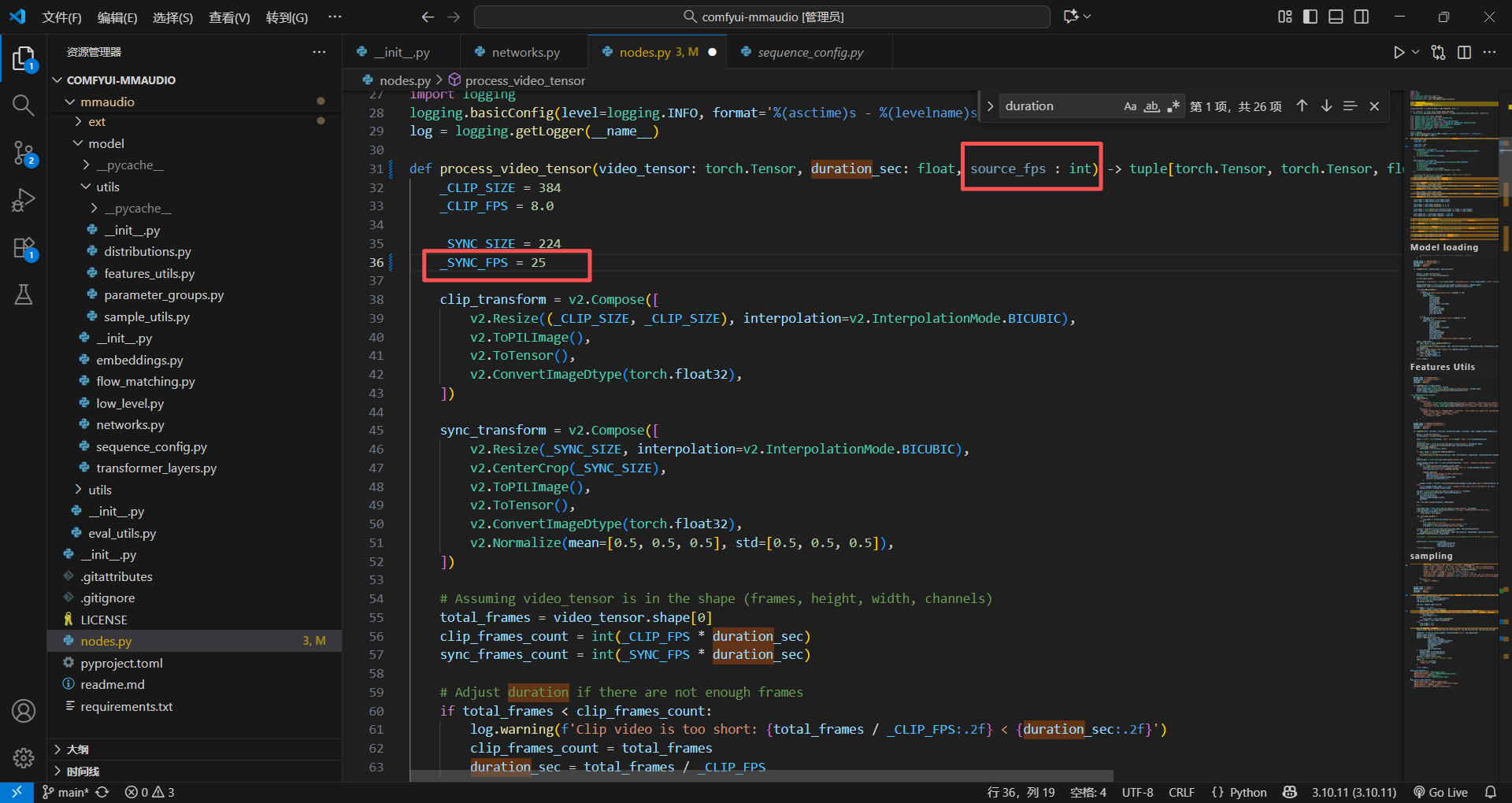
给上面的函数加入一个参数就行,然后赋值给他
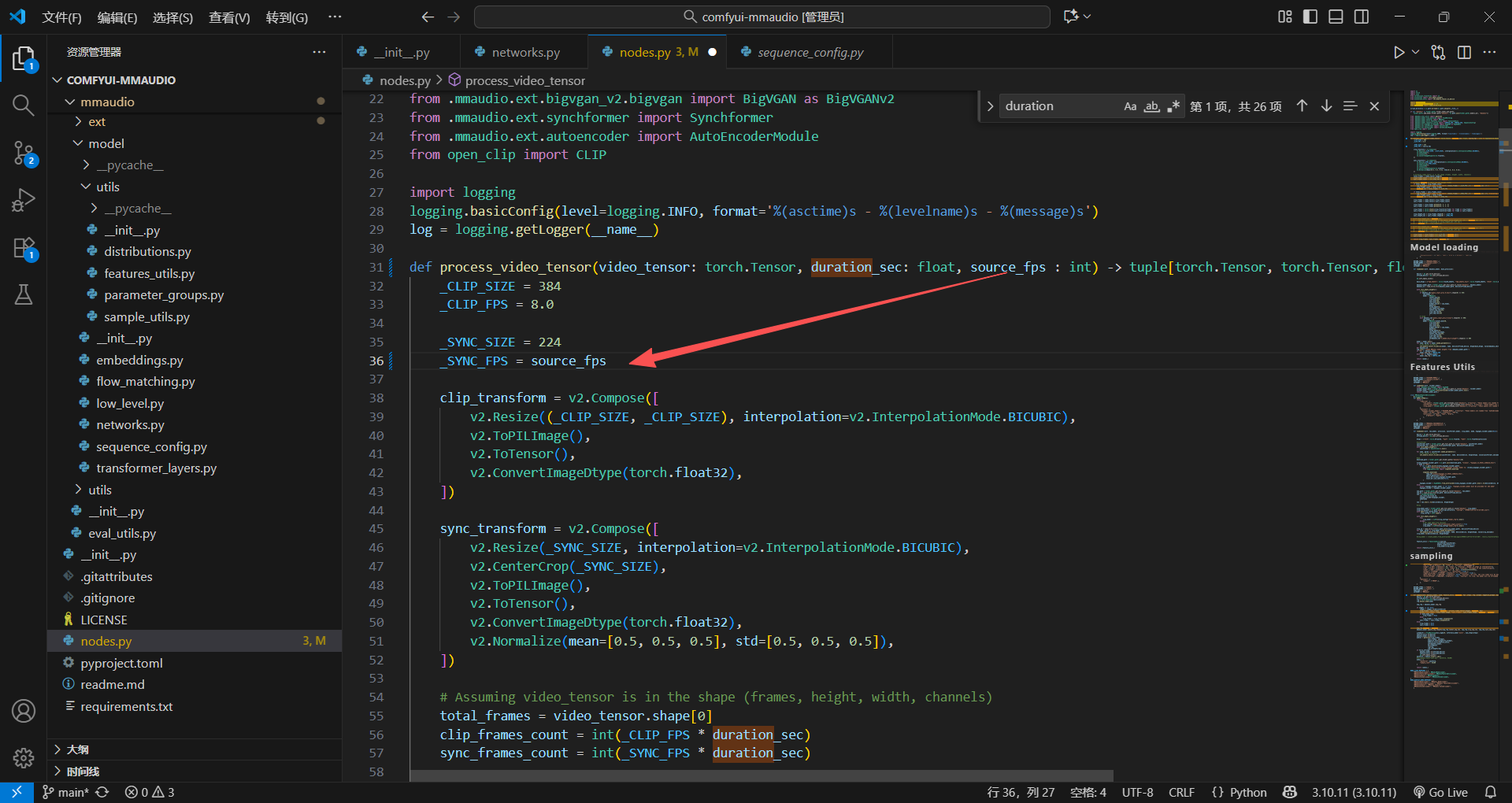
重新回到节点处,把前面设置的fps,传到函数里面,肯定会用到这个函数的
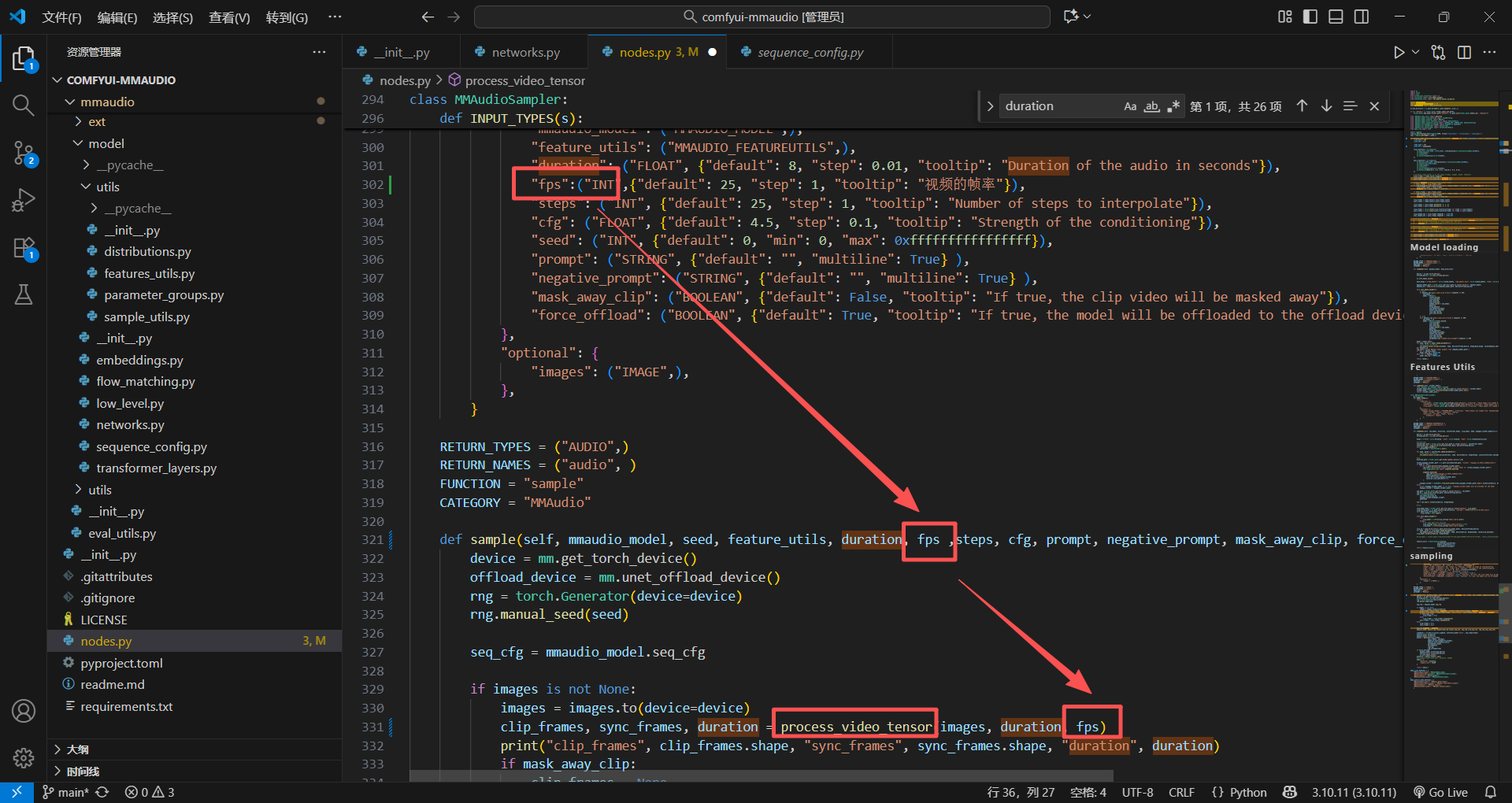
记得好像里面的文件还有校验,就那个什么assert,我找一找,这个参数叫_SYNC_FPS,那肯定就跟sync音频同步的包有关,去找一找
记得好像这些包的参数,大部分再队列设置里面有,果真再sequence_config文件里
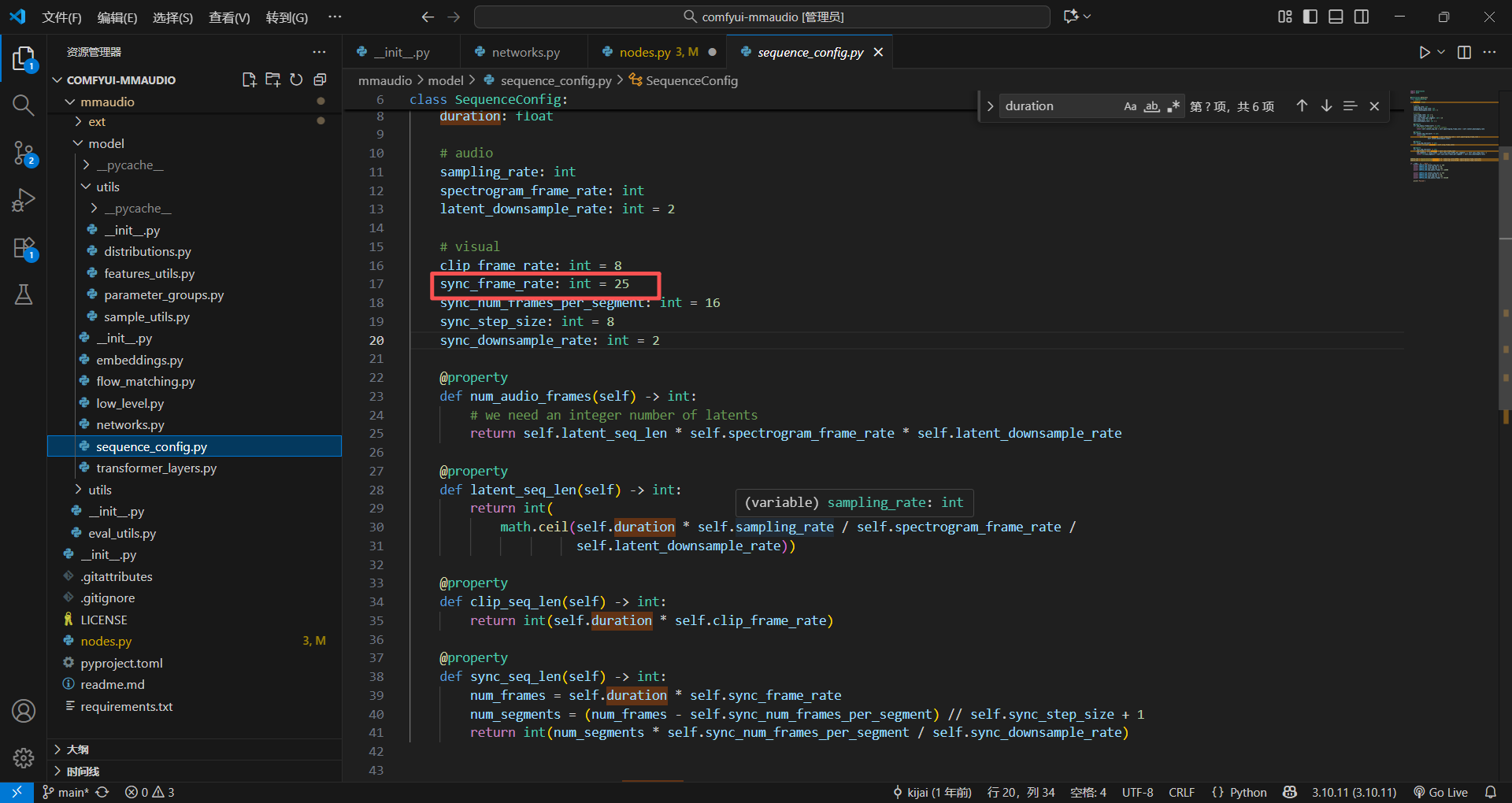
不过我记得这个包的东西最好别动,因为他可能训练的视频就是25帧的,所以先不改动这个代码,直接尝试一下,运行会不会报错,或者音频会不会有问题
继续修改sync代码的帧率
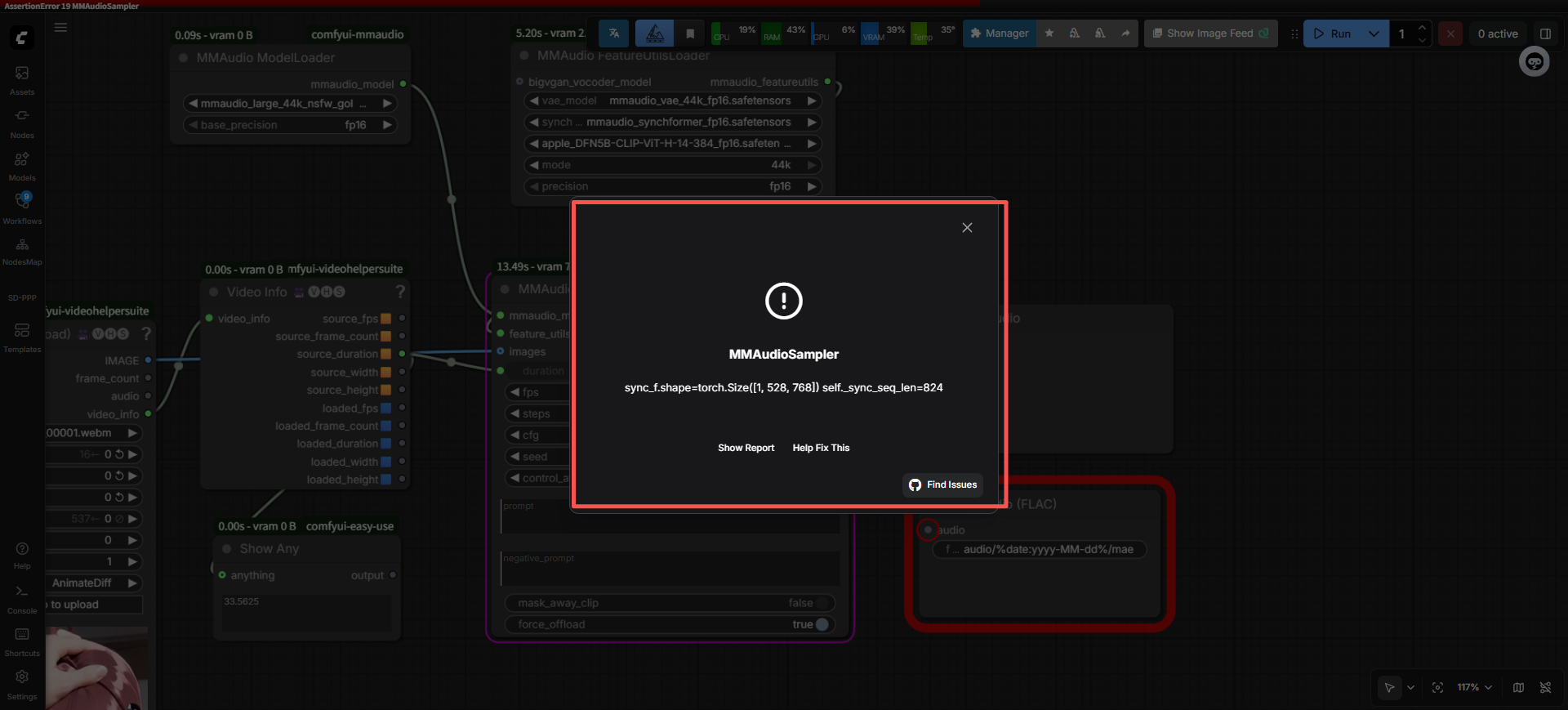
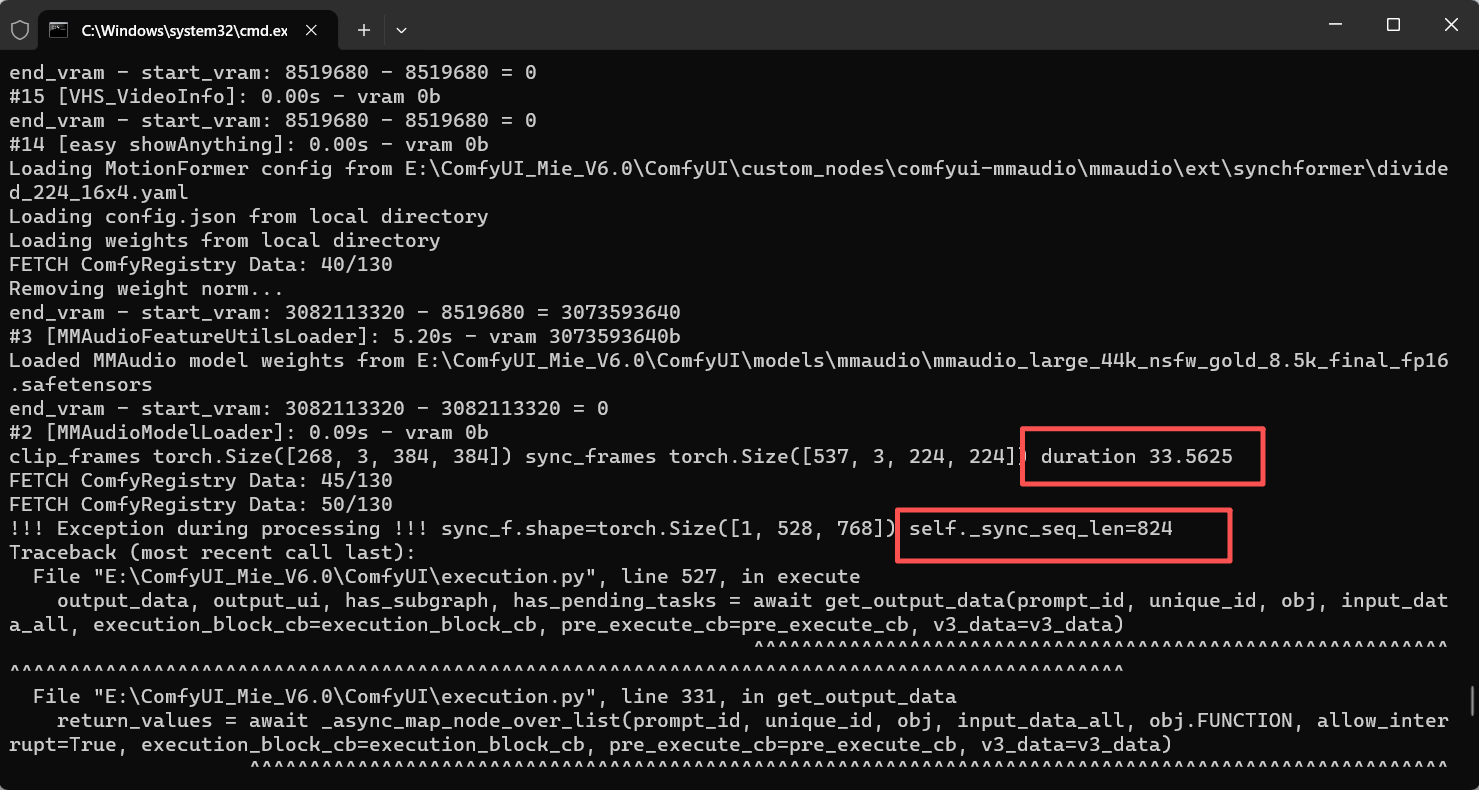
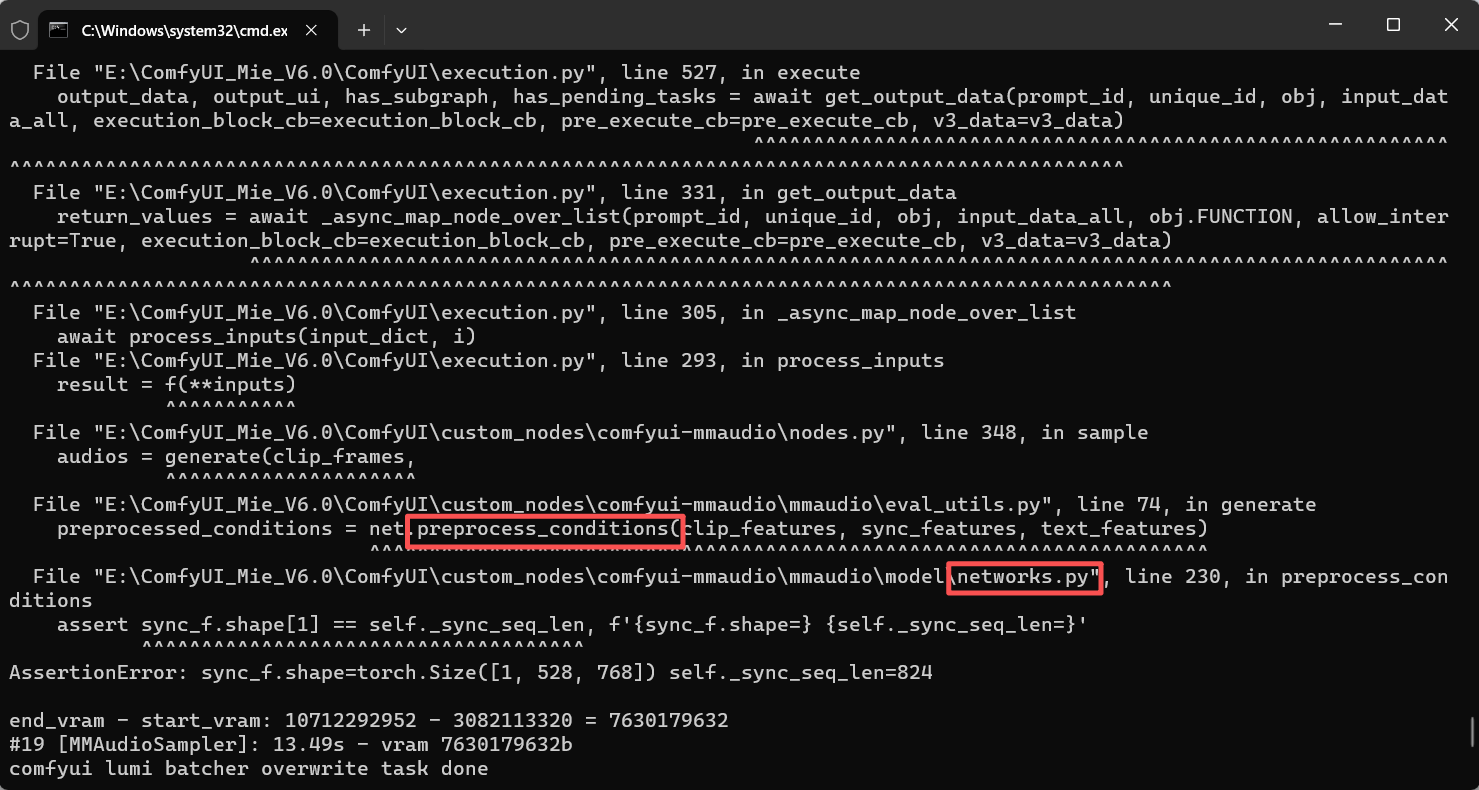
跟预料的差不多,只不过这一次时间是对的,但是self._sync_seq_len=824应该不符合,那个校验的问题
查了一下怎么改,发现需要改的地方太多了,甚至涉及到那些我看不懂的底层

虽然我还是想作践尝试一下,但是看到步骤直接蒙了,直接看步骤把,需要改的太多了,还涉及到了JointBlock
第一步:把
sequence_config.py里的sync_frame_rate改成可动态配置第二步:修改
eval_utils.py的ModelConfig,支持动态帧率第三步:在节点里动态更新模型的序列长度和位置编码
第四步:修复 Synchformer 的特征长度匹配
第五步:修复多模态联合注意力的时序对齐
简单说,前面三步还行,就是一个动态传参,然后修改一些参数配置的问题
四五没办法,涉及到底层了,什么Synchformer 对输入的视频帧有固定的下采样规则,需要自己匹配改,然后JointBlock,会把「音频、CLIP、Sync」三个模态的特征拼在一起做联合注意力。你改了 Sync 特征的长度后,必须保证三个模态的时间轴比例完全对齐,否则多模态融合会完全失效,生成的音频和画面完全错位
没听懂,就这样吧,换方案,不改帧率了
更换方案
既然一定得固定25帧,那是真的没什么办法了啊,人家的模型就是根据25帧的视频去训练的,你要是不是25帧的视频那根本就不可靠啊
我本来想的是先把视频弄成25帧,毕竟load video节点可以换帧率,然后相应的生成音频,然后再转成16帧的(不然时长少太多了)
不管怎么搞,就是限制了一定得是25帧的视频,这是肯定的
ai给我提供了一个办法,挺牛逼的,叫做伪装成25帧的视频
我自己的想法就是有什么方便的办法可以把视频弄成25帧的同时不会减少时间还有质量
都试试再说
伪装25帧视频
我一开始还以为它又再瞎说,然后发现他竟然使用537张(16帧)图片,把固定时序(33秒),然后把这537张图片直接放在25帧的时序里面
有点牛逼啊,简单说举个例子
假设视频只有2秒,那么只有32张图片,就是本来16帧是这样的
时间轴是
[0.00s, 0.0625s, 0.125s, ..., 1.9375s](每帧间隔 1/16 秒)
2 秒、25帧,一共50张图片的视频是这样的
时间轴是
[0.00s, 0.04s, 0.08s, ..., 1.96s](每帧间隔 1/25 秒)
然后我们不是去把32张图片补帧成50张,而是把这32张图片放到这个25帧视频对应的时间节点里面
总结就是做三件事
- 先在模型需要的 25fps 时间轴上,标出 50 个时间点;
- 对于每个时间点(比如 0.04s),去原始视频里找 "最接近这个时间点的那一帧"(比如原始视频的第 1 帧是 0.0625s,最接近 0.04s);
- 把这些帧取出来,拼成一个新的 "伪 25fps" 视频。
但是我觉得这样强行伪装25帧,可能画面不会那么流畅的说,但是我们的重点是音频,并不是要这个视频,而是要生成一个对应时间的音频
所以轻微的卡顿(甚至可能不会,因为16到25帧的提升真的不大),对音频的影响也应该不会很大,我去查了一下,音频不会卡顿的,流畅性不会有问题,资料如下:
1. 音频生成的核心是「连续的时序建模」,不是 "逐帧对应"
MMAudio 模型的本质是:
- 输入:25fps 视频的时序特征序列(不管帧是不是重复,特征都是连续的时间轴);
- 模型内部:Transformer 通过旋转位置编码(RoPE) 理解 "时间先后",通过卷积 FFN 捕捉音频的连续时序特征;
- 输出:连续的音频潜空间流(是一个光滑的向量场,不是 "逐帧跳变" 的)。
简单说:模型看的是 "视频的时间轴趋势",不是 "单帧画面",哪怕视频帧有重复,模型也能从连续的时间轴里学到 "动作是连续的",生成的音频流也是连续光滑的。
2. 音频的生成粒度远细于视频帧
- 视频是 "帧级" 的(25fps=40ms / 帧);
- 音频是 "采样点级" 的(16K 采样率 = 62.5μs / 采样点,44K=22.7μs / 采样点)。
模型生成的音频潜空间,最终会通过 BigVGAN 声码器转成连续的音频波形,哪怕视频帧有轻微卡顿,音频的采样点也是连续的,人耳完全听不出任何卡顿。
3. 流匹配的积分过程保证了音频的连续性
我们用欧拉法积分 25 步生成音频,每一步的 "流" 都是模型预测的 "连续方向",积分后的结果是一个光滑的曲线,不是 "阶梯状的跳变",这从数学上保证了音频的流畅性。
虽然说音频不会卡,但是如果说对画面的识别不够准,就有可能出现音频不太对的情况,不过主要16到25真改变不是很大,所以我感觉应该不会,先尝试一下,然后试试情况,反正可以使用相同种子测试
添加代码(伪装)
1.计算数值
Assuming video_tensor is in the shape (frames, height, width, channels)
原始视频信息
total_frames = video_tensor.shape0
【核心修正】根据原始帧率,计算视频的实际最大可用时长
max_available_duration = total_frames / source_fps
限制duration不超过视频实际时长,避免越界
duration_sec = min(duration_sec, max_available_duration)
计算模型需要的目标帧数
clip_frames_count = int(_CLIP_FPS * duration_sec)
sync_frames_count = int(_SYNC_FPS * duration_sec)
第一个就是pytorch的图片张量(tensor),是一个数组,里面有四个值shape (frames, height, width, channels)
| 维度顺序 | 含义 | 举个你的 16fps 视频的例子 |
|---|---|---|
shape[0] |
视频的总帧数 | 你的视频是 16fps、2 秒,总帧数就是 32,shape[0] = 32 |
shape[1] |
视频画面的高度(单位:像素) | 1080P 视频就是 1080,shape[1] = 1080 |
shape[2] |
视频画面的宽度(单位:像素) | 1080P 视频就是 1920,shape[2] = 1920 |
shape[3] |
视频的颜色通道数 | 彩色视频是 RGB 三通道,shape[3] = 3 |
所以video_tensor.shape0 就是拿到总帧数(图片数量)
接下来就是计算时长,还有对时长取最小值min(duration_sec, max_available_duration)
为什么取最小,因为这个节点是可以让你选择时长的,向下取整就不会越界错误
2.时间轴采样
【核心修正】时间轴重采样:计算每个目标帧对应的原始帧索引
生成目标帧的时间点(归一化到0-1)
clip_timestamps = torch.linspace(0, 1, clip_frames_count)
sync_timestamps = torch.linspace(0, 1, sync_frames_count)
映射到原始视频的帧索引
clip_frame_indices = (clip_timestamps * (total_frames - 1)).long()
sync_frame_indices = (sync_timestamps * (total_frames - 1)).long()
一个个来torch.linspace(起点, 终点, 生成多少个数字),这是一个均匀等差数列生成函数
直接举例子
torch.linspace(0, 1, 5) → 生成 [0.0, 0.25, 0.5, 0.75, 1.0],5 个数字均匀分布在 0 到 1 之间。
就是生成一个数组,然后里面数字的范围还有个数,当然是平均的
这里生成两个0-1的数组,然后再把它映射到原始视频帧clip_frame_indices /sync_frame_indices
就是直接把数组里面的数字乘以要处理的视频的帧数-1(记得减一,因为索引是从0开始),然后.long就是取整
这样就会得到一个正常视频的时间轴
为啥不直接写视频的帧数
一开始我想为啥要先生成0-1再去相乘,直接输入动态参数,就原始视频的帧数不就行了?
这样好像是一种规定,这样写解耦会简单很多,就是如果你不想生成0-1,只想要生成一个中间视频段的时间轴,直接改0-1就行(例如0.1-0.6)
为啥数组可以直接相乘
查了一下,怎么clip_timestamps * (total_frames - 1)可以直接相乘啊?我怎么记得数组是得一个个拿出来,然后相乘之后再一个个放回去(使用循环)
还以为是python的语法,原来这就是pytorch的优势,这也是深度学习的东东
PyTorch(以及所有深度学习框架)的核心灵魂:「向量化操作(Vectorization)」
当你写
clip_timestamps * 31时,PyTorch 底层做的是:
- 把
clip_timestamps这个数组,一次性送到 GPU(或者 CPU)的并行计算单元;- GPU 有几千个核心,同时对数组里的每一个数字做乘法;
- 一瞬间,所有数字都算完了,返回一个新的数组。
这就是为什么深度学习必须用 PyTorch/TensorFlow:因为整个模型的计算量是天文数字,手写循环根本跑不出来,必须靠向量化并行计算。
3.取帧处理
【核心修正】按时间索引取帧,而不是粗暴取前N帧
clip_frames = video_tensorclip_frame_indices
sync_frames = video_tensorsync_frame_indices
#旧代码
clip_frames = video_tensor:clip_frames_count
sync_frames = video_tensor:sync_frames_count
clip_frame_indices是我们处理好的时间对应值(都取整了),然后直接video_tensor数组对应的值取出来
假设数组里面【0,2,4】那么clip_frames = video_tensor\[0, video_tensor2, video_tensor4]
当然这个也是pytorch里面的写法,正常还是得用循环的....
至于旧代码前面加了个冒号,遵循左闭右开,所以就是直接暴力截取前几帧,所以生成的音频时长就是不太对的
4.维度处理
下面这些本来就有,我顺便查了一下
clip_frames = clip_frames.permute(0, 3, 1, 2)
sync_frames = sync_frames.permute(0, 3, 1, 2)
permute 是 PyTorch 张量的维度重排函数 ,作用是:把张量的维度顺序,按你指定的顺序重新排列
clip_frames 原始维度:(帧数, 高, 宽, 通道) → (T, H, W, C)
结果维度变成:(帧数, 通道, 高, 宽) → (T, C, H, W),这是 PyTorch 卷积层要求的输入格式
反正就是处理需要的转换
clip_frames = torch.stack(clip_transform(frame) for frame in clip_frames)
sync_frames = torch.stack(sync_transform(frame) for frame in sync_frames)
torch.stack(列表):把列表里的多个单帧张量,沿着第 0 维(帧数)堆叠起来 ,拼成一个完整的视频张量 (T, C, H, W)。
至于里面的clip_transform()一看就是写的方法,是吧图片进行裁剪之类的处理,并且用列表推导式(循环)处理
代码先改到这里,下次继续