第一题
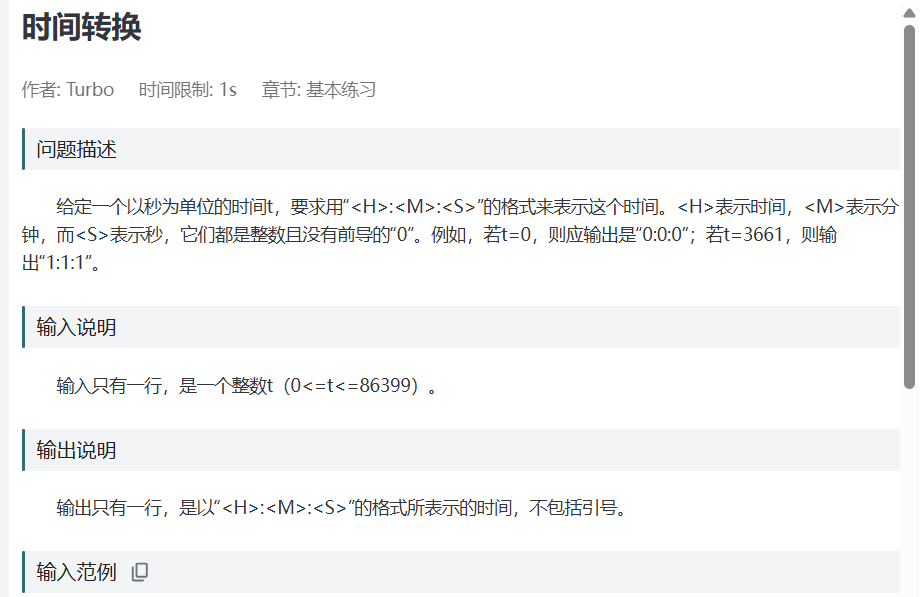
个人总结:直接秒除60得总分,分除60得总时,再秒%60得余数,分%60得余数,输出即可。
代码如下:
#include<stdio.h>
int main(){
int t;
scanf("%d",&t);
int h=0,m=0;
m=t/60;
t=t%60;
h=m/60;
m%=60;
printf("%d:%d:%d\n",h,m,t);
return 0;
}第二题
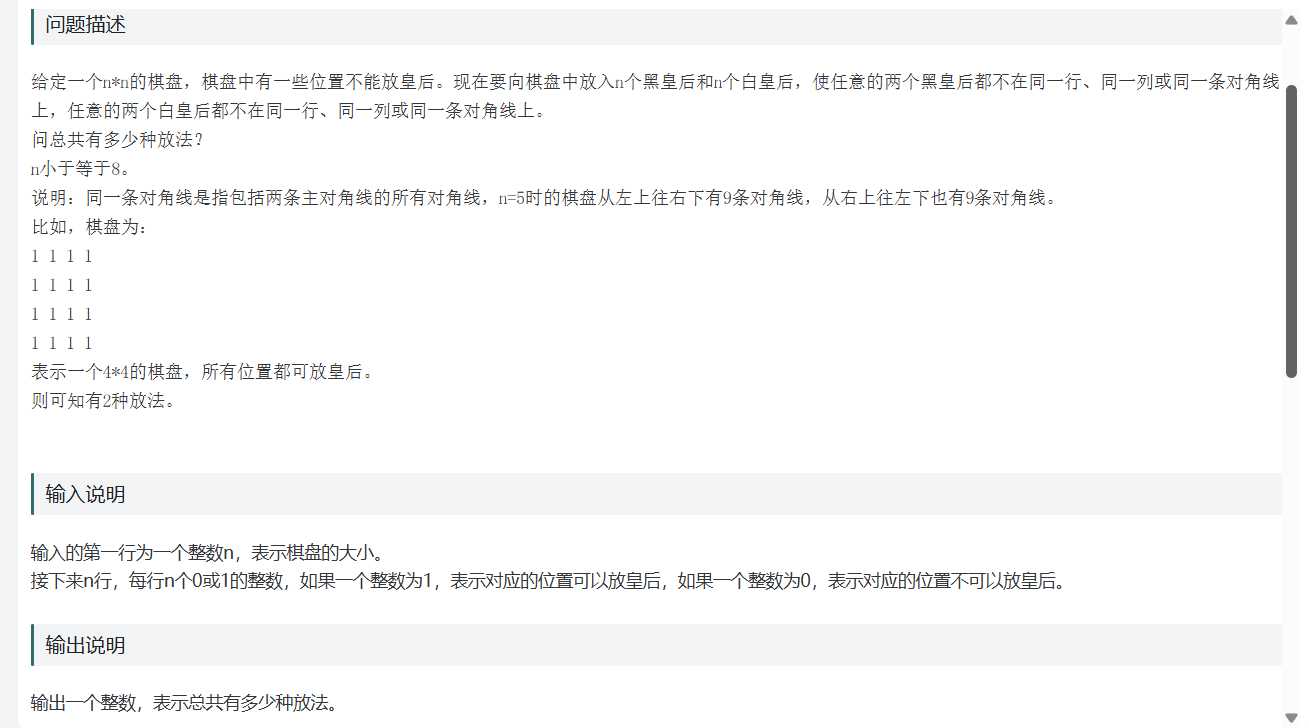
个人总结:利用BFS算法,分别判断出黑和白当前是否能放置此位置,若能则下一行继续判断,直至遍历整个数组,此时总数+1,继续下一个判断,不能则回溯至原位跳过此次判断。
代码如下:
#include <stdio.h>
#include <string.h>
int n;
int board[8][8];
int black_col[8];
int black_diag1[15];
int black_diag2[15];
int white_col[8];
int white_diag1[15];
int white_diag2[15];
int total;
void dfs(int row) {
if (row == n) {
total++;
return;
}
for (int col = 0; col < n; col++) {
if (board[row][col] == 0) continue;
int d1 = row + col;
int d2 = row - col + n - 1;
if (!black_col[col] && !black_diag1[d1] && !black_diag2[d2]) {
black_col[col] = 1;
black_diag1[d1] = 1;
black_diag2[d2] = 1;
for (int wcol = 0; wcol < n; wcol++) {
if (board[row][wcol] == 0 || wcol == col) continue;
int wd1 = row + wcol;
int wd2 = row - wcol + n - 1;
if (!white_col[wcol] && !white_diag1[wd1] && !white_diag2[wd2]) {
white_col[wcol] = 1;
white_diag1[wd1] = 1;
white_diag2[wd2] = 1;
dfs(row + 1);
white_col[wcol] = 0;
white_diag1[wd1] = 0;
white_diag2[wd2] = 0;
}
}
black_col[col] = 0;
black_diag1[d1] = 0;
black_diag2[d2] = 0;
}
}
}
int main() {
scanf("%d", &n);
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
scanf("%d", &board[i][j]);
}
}
memset(black_col, 0, sizeof(black_col));
memset(black_diag1, 0, sizeof(black_diag1));
memset(black_diag2, 0, sizeof(black_diag2));
memset(white_col, 0, sizeof(white_col));
memset(white_diag1, 0, sizeof(white_diag1));
memset(white_diag2, 0, sizeof(white_diag2));
total = 0;
dfs(0);
printf("%d\n", total);
return 0;
}翻译
过拟合是机器学习模型训练过程中常见的一个问题。当模型在训练数据上表现极为出色但在测试数据上表现欠佳时,就被认为出现了过拟合现象。这通常发生在模型过于复杂或训练数据量不足的情况下。为了减少过拟合,研究人员提出了多种技术,如正则化、数据增强和交叉验证。正则化方法在损失函数中引入惩罚项,以限制模型参数的值,从而使得模型更加简单且更稳定。数据增强通过应用旋转、裁剪或添加噪声等操作来增加训练数据的多样性。此外,交叉验证通过反复将数据集划分为训练集和验证集来评估模型的泛化能力。这些技术能够有效提高机器学习模型在实际应用中的性能。
单词打卡