
"大模型能聊天、能写作,但能'干活'吗?"
这是当前AI应用落地的核心痛点。当用户说"帮我查一下北京天气"或"搜索最新关于蛋白质折叠的论文",大模型本身无法直接执行这些操作------它需要"工具",更需要一套智能调度机制 。
近期爆火的 Skill(技能)机制 正是解决这一问题的关键突破。本文将带你从原理到实战,彻底搞懂:
Skill到底是什么?它和Function Call、MCP、Work Flow Agent有何区别?更重要的是------如何用 Spring AI + 阿里巴巴,让任意大模型都具备"技能调用"能力?
一、Skill的本质:不是新能力,而是智能编排
很多人误以为Skill是大模型的新功能,其实不然。Skill本质上是对Function Call(函数调用)机制的高级封装。
回想一下经典场景:你问大模型"北京今天天气如何?"。由于模型没有实时数据,它会返回一段结构化JSON:
json
{
"tool": "get_weather",
"arguments": { "location": "北京" }
}你的程序识别后,调用get_weather("北京"),再把结果喂回模型生成回答。
这就是Function Call------将自然语言转化为可执行指令。
而Skill在此基础上更进一步:它不仅调用单个函数,还能编排多个步骤、调用脚本、处理复杂工作流,形成一个完整的"子任务单元"。
✅ 关键认知:Skill ≠ 大模型原生能力,而是Agent框架层的业务抽象。模型只负责推理"要不要用Skill"和"用哪个Skill",具体执行由外部系统完成。

二、为什么需要Skill?传统Agent的三大痛点
在Skill出现前,开发者常用Work Flow Agent模式,但面临严重问题:
| 问题 | 说明 |
|---|---|
| 提示词爆炸 | 所有能力描述一次性塞进上下文,Token消耗巨大 |
| 维护困难 | 每新增一个功能,就要修改主Prompt,耦合度高 |
| 无法共享 | 不同项目重复造轮子,工具不能复用 |
而Skill采用 "渐进式披露"(Progressive Disclosure) 策略:
- 启动时:仅加载所有Skill的元数据(名称+简短描述),约100 Token/个;
- 匹配时:当用户请求命中某Skill,才加载其完整Markdown指令;
- 执行时:按需调用脚本或外部工具。
🌰 举例:搜索"蛋白质折叠预测论文"时,模型先看到"有'学术搜索'Skill可用",再加载该Skill的详细步骤(如:启动浏览器 → 调用Python脚本 → 解析arXiv页面),而非一开始就背诵整套流程。
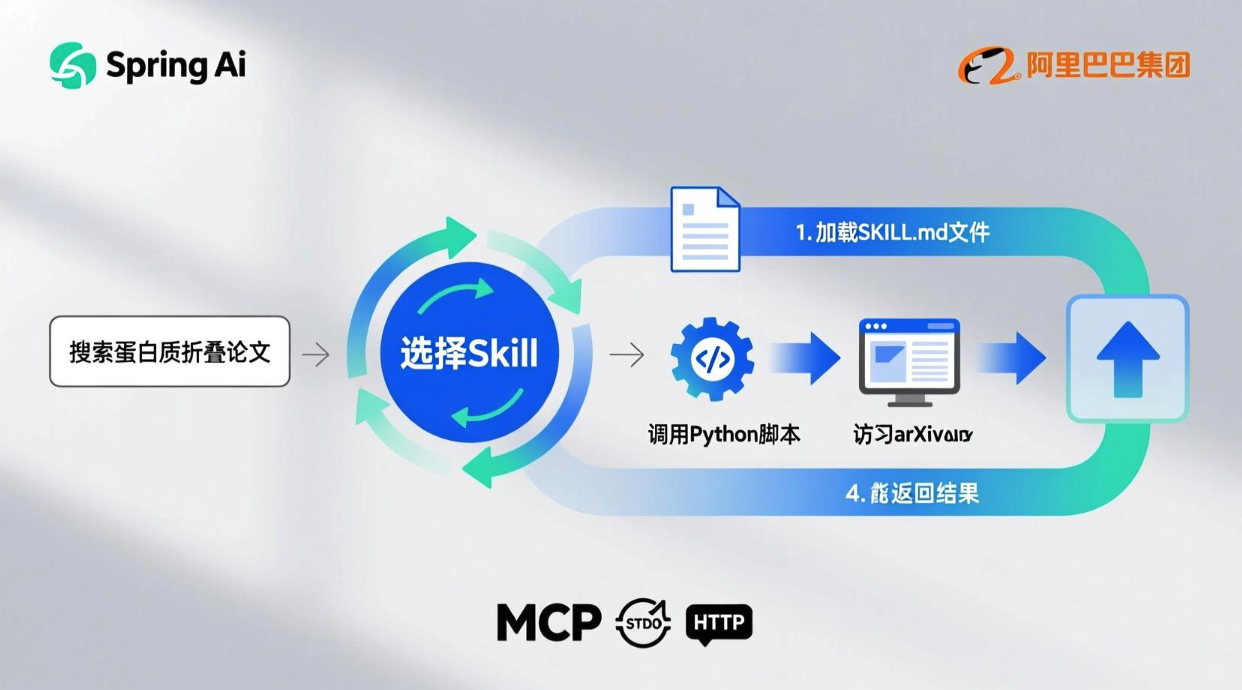
三、MCP协议:打通第三方服务的"通用接口"
当Skill需要调用GitHub、地图、数据库等外部服务时,又该如何统一管理?
答案是 MCP(Model-Cloud Protocol)。
MCP定义了大模型调用远程工具的标准方式,支持:
- STDIO:通过标准输入输出通信(适合本地进程)
- HTTP:通过RESTful API调用(适合云服务)
🔑 核心思想:对大模型而言,无论是你写的内部函数,还是GitHub提供的API,统统都是"Tool"。MCP只是让这些Tool能被远程调用。
四、Spring AI + 阿里巴巴:让Skill落地生产环境
好消息是,阿里巴巴已在Spring AI Alibaba 1.1.2.0版本中内置Skill支持!开发者只需三步:
步骤1:准备Skill文件
每个Skill是一个目录,结构如下:
academic-search/
├── SKILL.md # 元数据 + 指令编排
└── scripts/
└── search_papers.py # Python脚本SKILL.md 示例:
markdown
---
name: academic-search
description: 搜索物理、数学、计算机等领域最新论文
---
1. 使用Python脚本访问arXiv API
2. 根据关键词过滤结果
3. 返回前5篇相关论文标题与摘要步骤2:注册Skill Hook
java
@Bean
public SkillRegistry skillRegistry() {
return new SkillRegistry("classpath:/skills"); // 指向Skill目录
}步骤3:启用脚本执行能力
java
@Bean
public ScriptExecutor scriptExecutor() {
return new PythonScriptExecutor(); // 支持Python执行
}💡 阿里巴巴已封装好
call_skill这个内置Tool,自动处理Skill加载与调用逻辑。
五、真实案例:一键搜索学术论文
当你发送请求:"帮我找关于蛋白质折叠预测的最新论文",系统会:
- 模型识别需调用
academic-searchSkill; - 加载
SKILL.md,发现需执行search_papers.py; - 检测Python环境 → 执行脚本 → 获取结果;
- 若结果不相关,模型还会自主优化查询关键词并重试!
整个过程无需人工干预,且Token消耗仅为传统Agent的1/3。
六、Skill生态:4万+现成技能任你调用
目前已有超 40,000个开源Skill 可用!涵盖:
- 网络搜索(Google/Bing/arXiv)
- 文件处理(PDF/Excel/PPT解析)
- 数据库查询
- 代码生成与审查
访问 skills.sh 即可搜索下载,直接集成到你的项目中。
结语
Skill的出现,标志着大模型从"对话助手"向"智能执行体"的关键跃迁。它通过模块化、懒加载、可共享的设计,解决了AI落地中最棘手的"执行能力"问题。
而借助 Spring AI + 阿里巴巴,你无需等待特定模型支持,即可在现有系统中快速集成Skill机制,让你的大模型真正"能理解、能执行、能进化"。
🚀 行动建议:
- 升级至 Spring AI Alibaba 1.1.2.0+
- 从 skills.sh 下载一个Skill试试
- 尝试封装你业务中的重复流程为Skill
未来已来,只是尚未流行。而你,可以成为第一批构建智能Agent生态的开发者。
欢迎留言讨论:你在项目中遇到过哪些"大模型想干但干不了"的场景?是否考虑用Skill来解决?
🎁 福利时间
如果你正在备战大厂面试,我整理了一个 开发者的知识库 涵盖 Java 程序员需要掌握的核心知识。
知识库地址:https://farerboy.com/
