测试hdfs上传文件
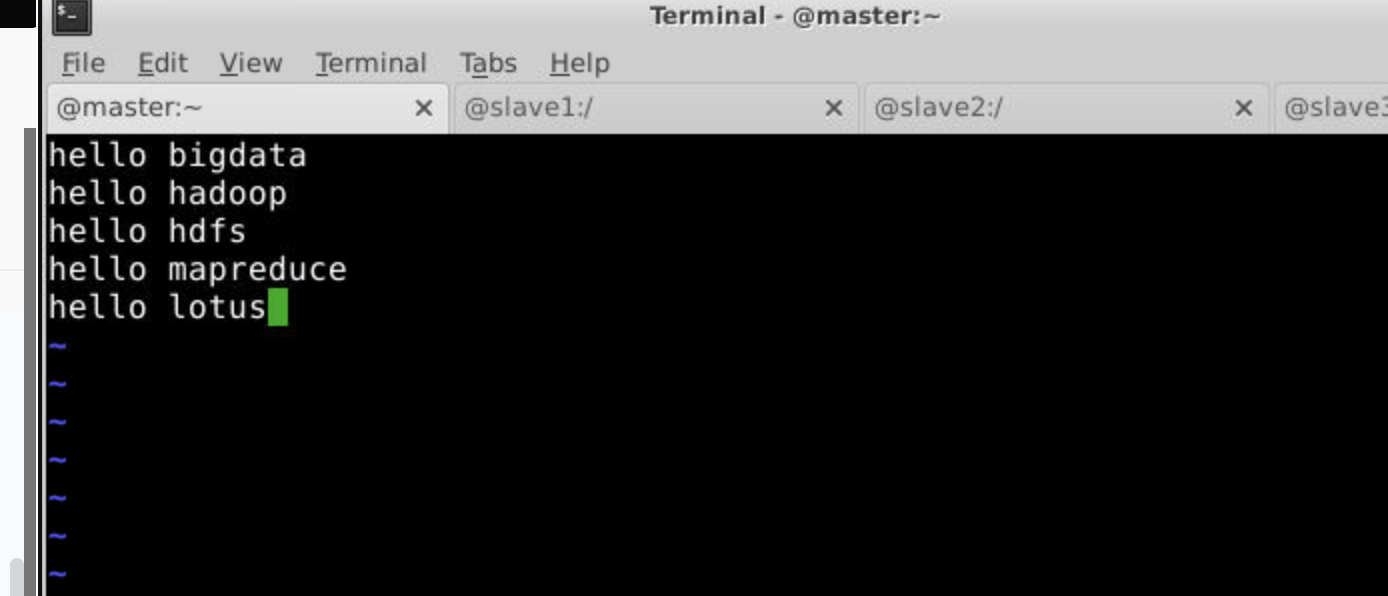
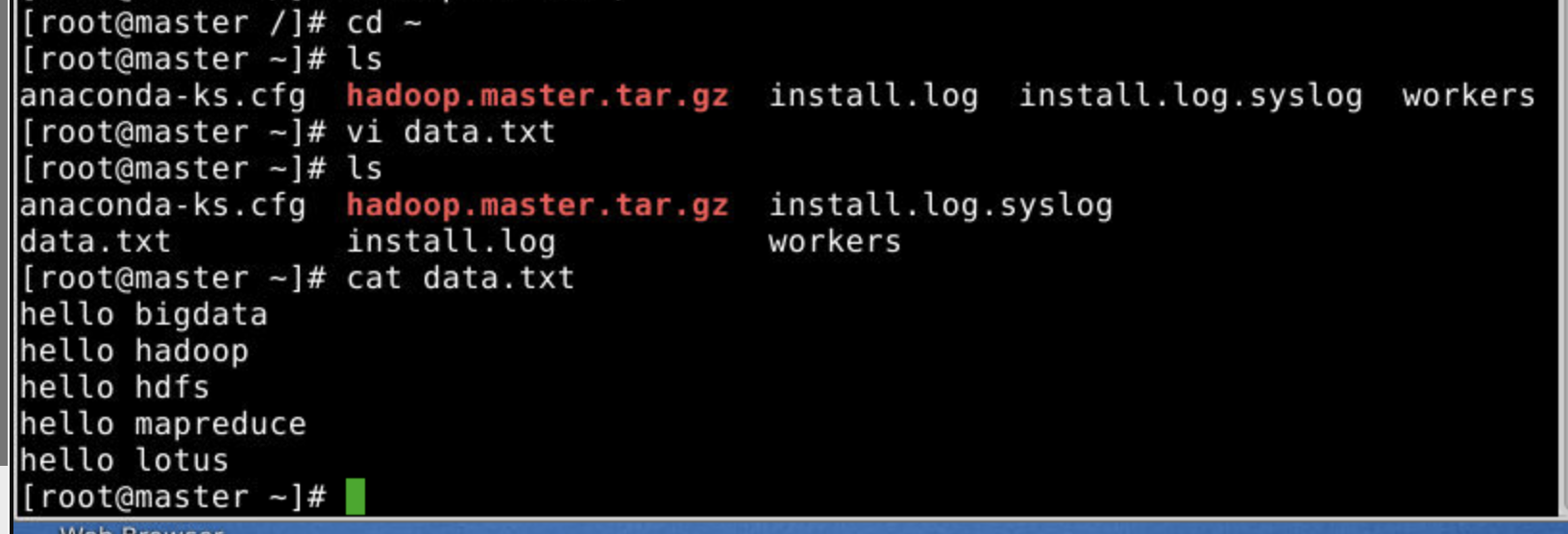
1.创建一个data.txt文件

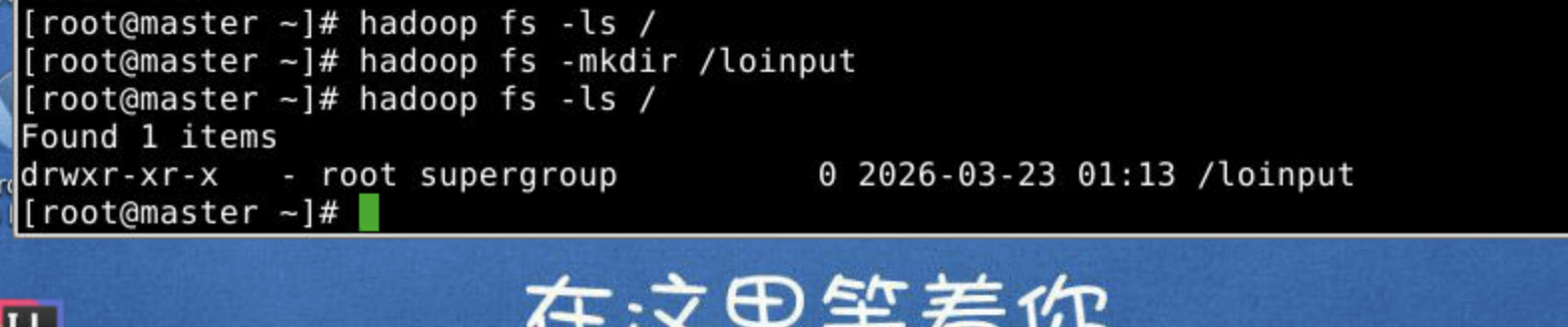
2.创建一个hdfs的文件夹

3.将本地文件上传到hdfs系统
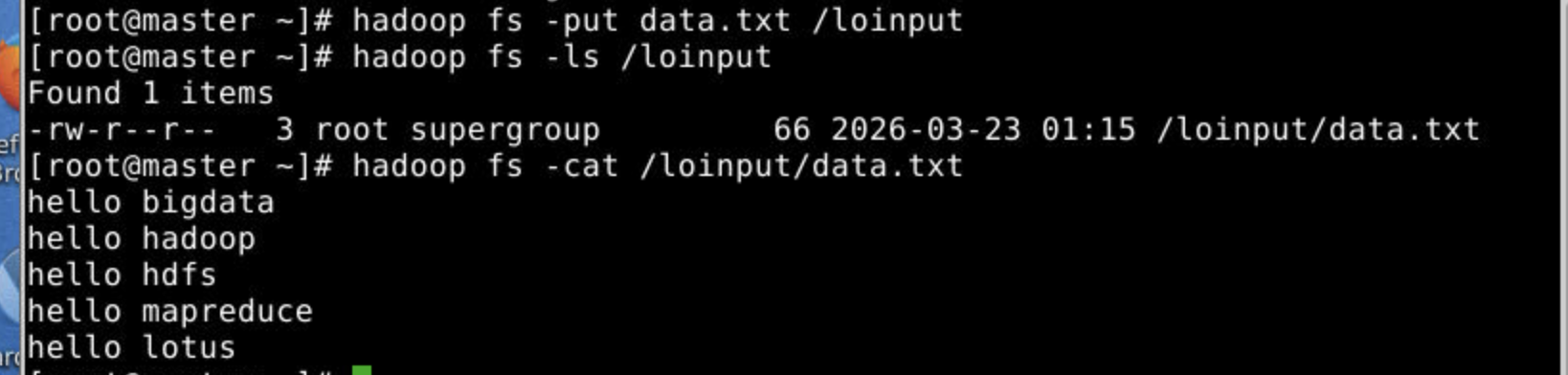
4.查看文件上传
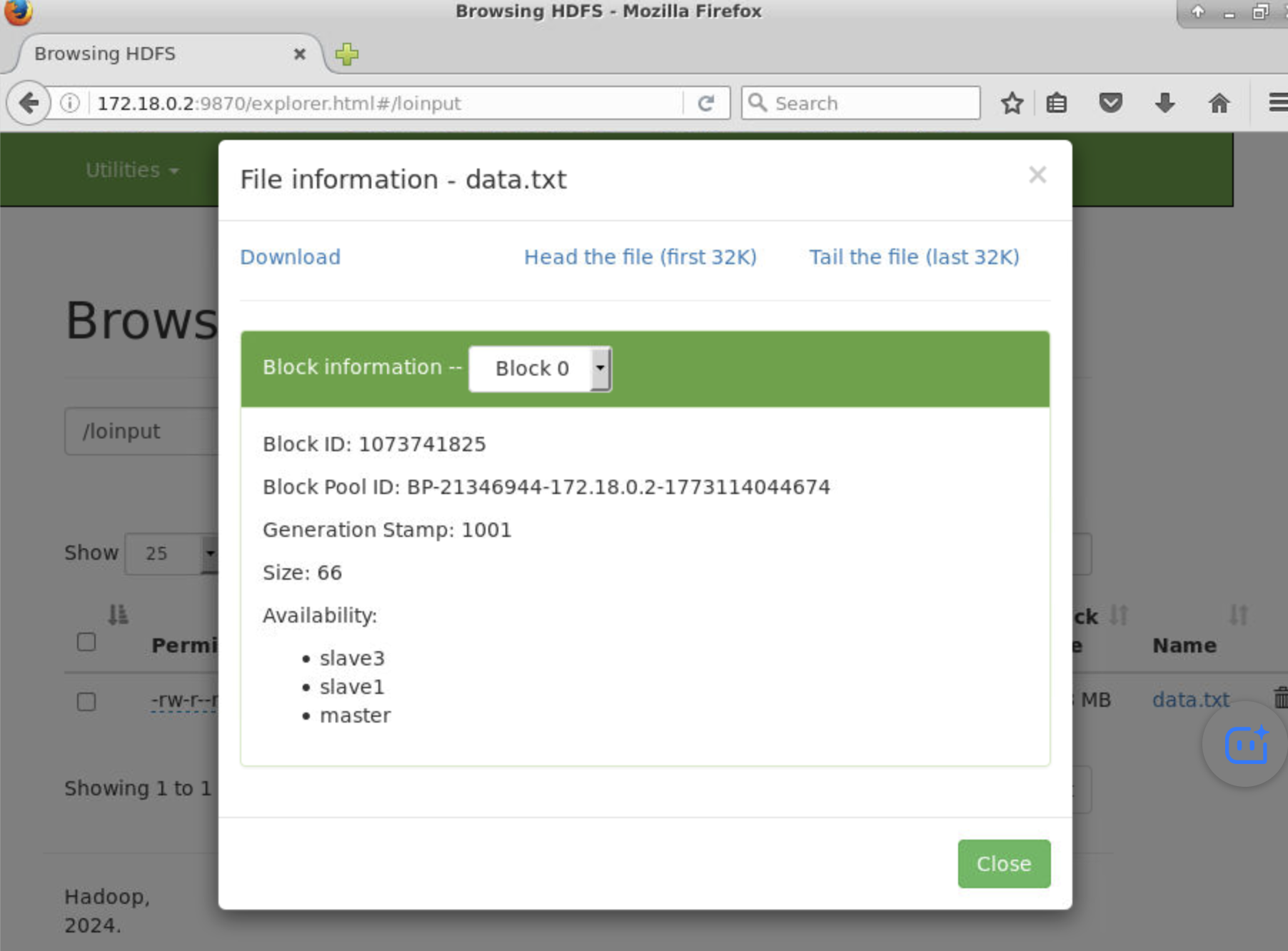
到这个目录下 /usr/local/hadoop/tmp/dfs/data/current/BP-21346944-172.18.0.2-1773114044674/current/finalized/subdir0/subdir0
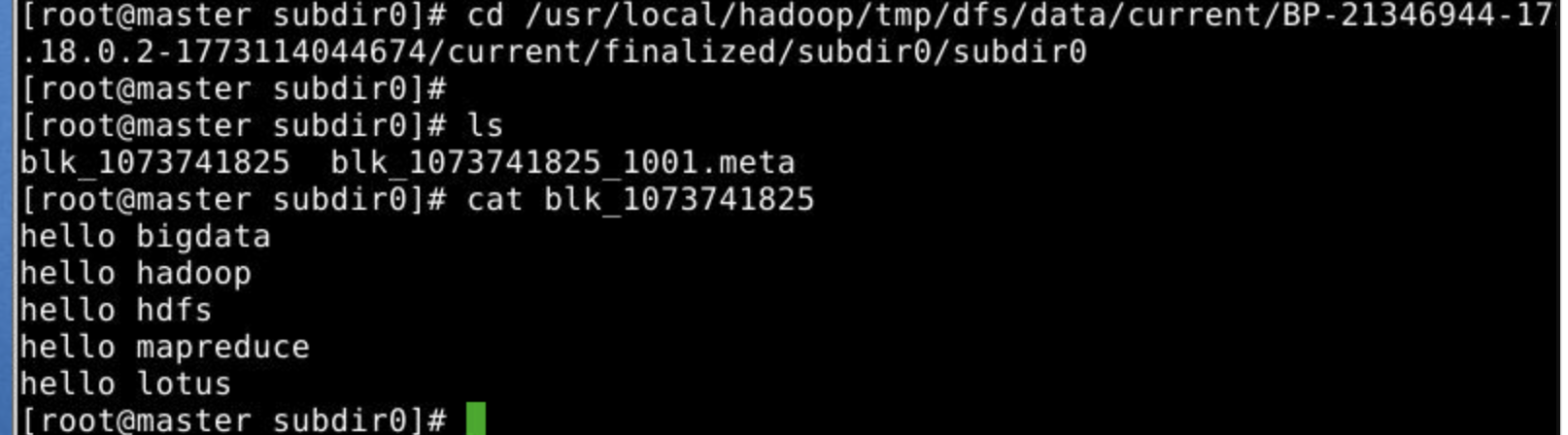
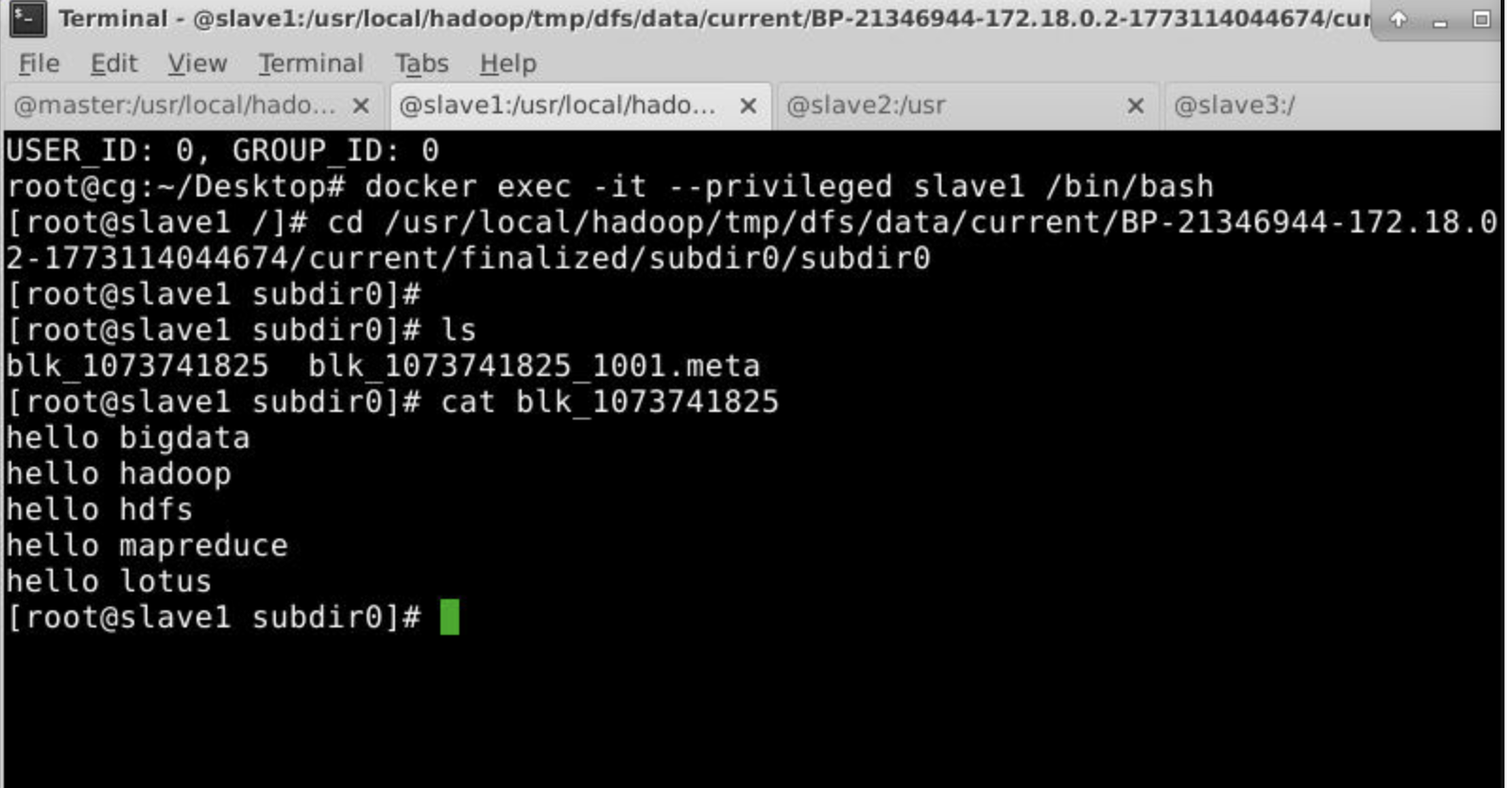
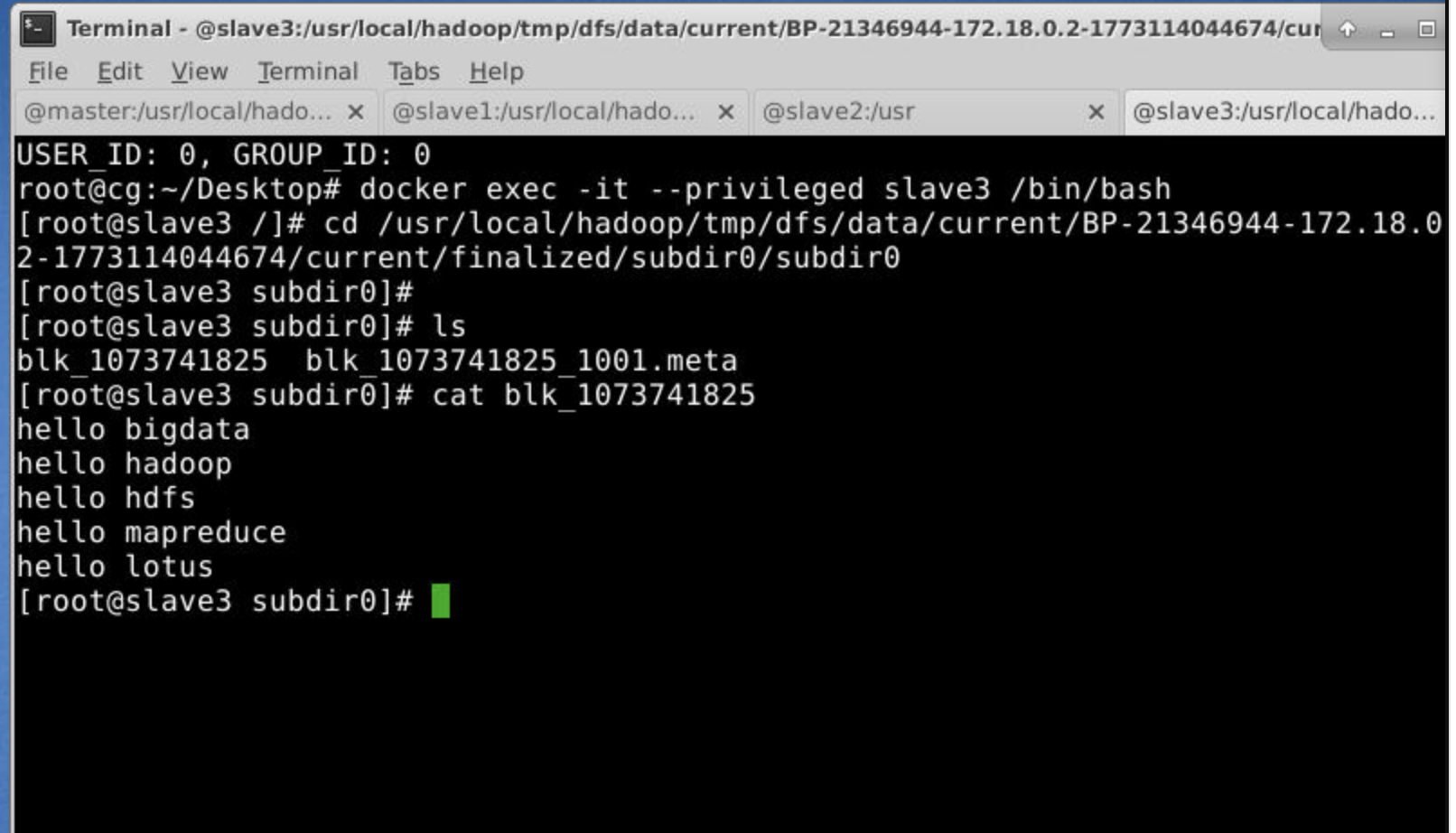
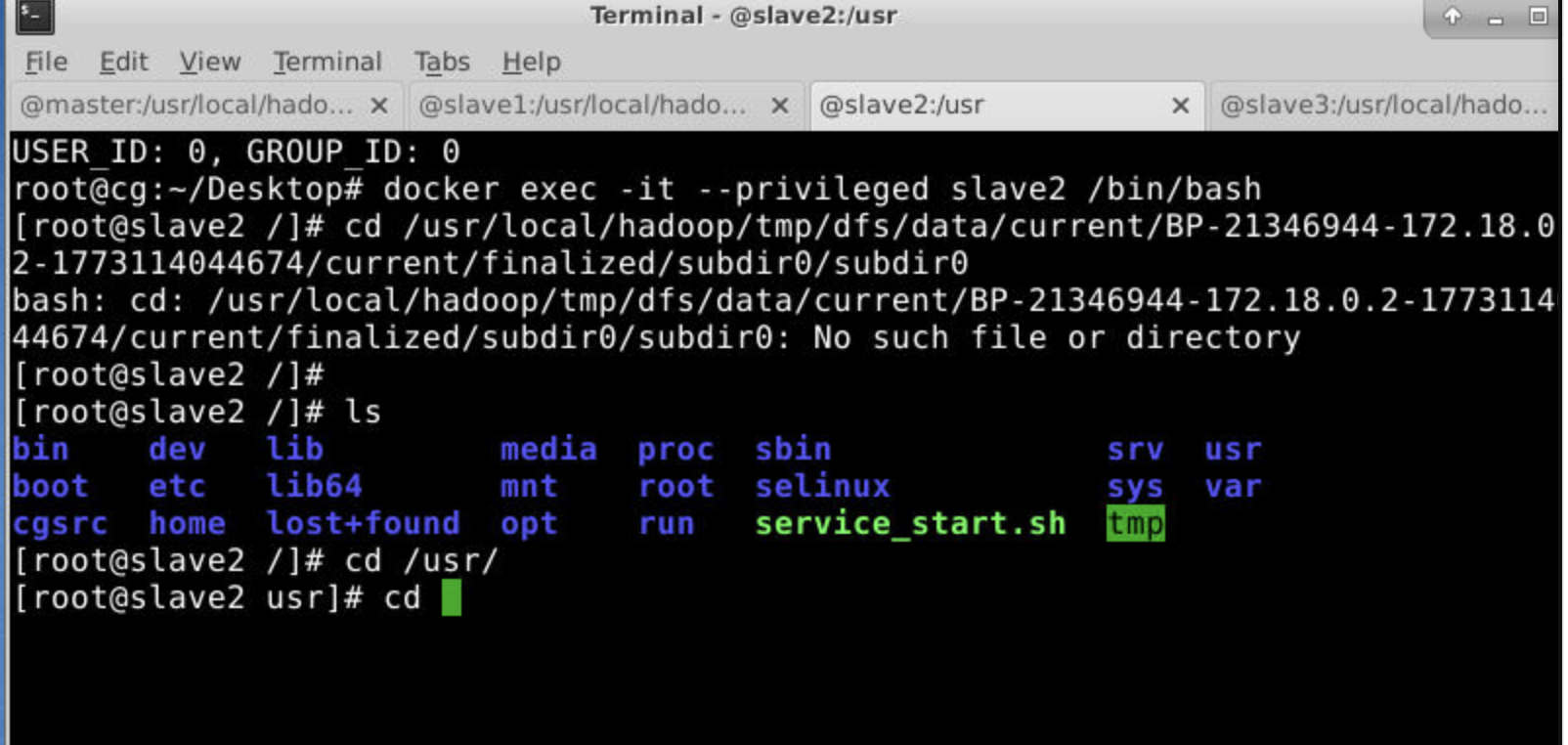
会发现master,slave1,slave3存储了相同的内容,但是slave2没有。对应第一个图
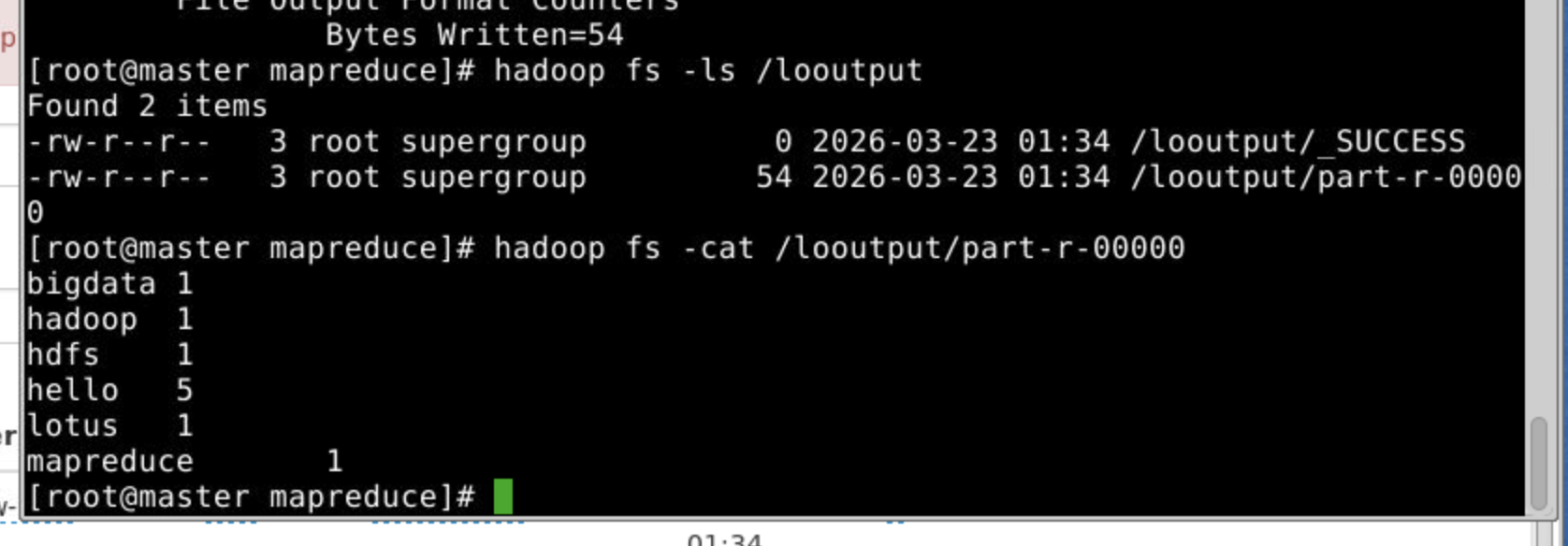
测试wordcount
1.在上面的基础上,运行mapreduce wordcount的例子
cd /usr/local/hadoop/share/hadoop/mapreduce/
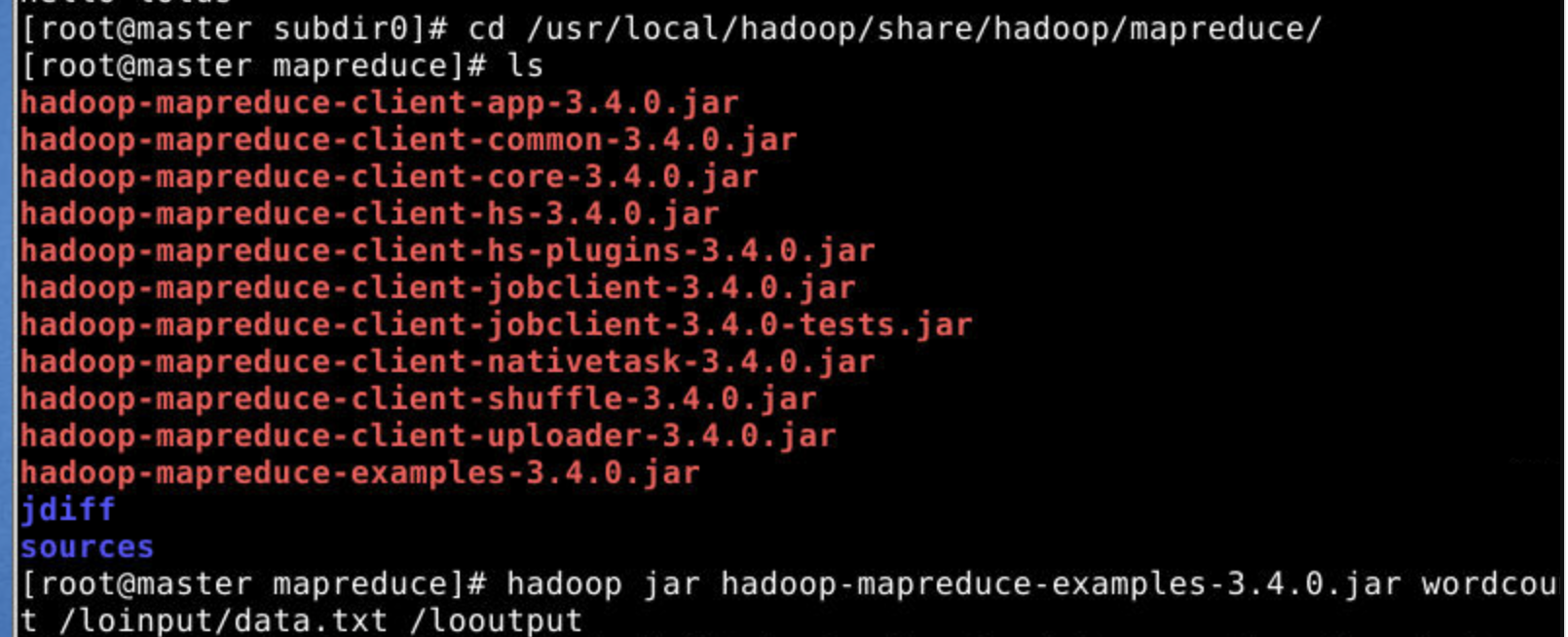
2.查看运行结果