如今的商业智能(BI)市场,一片蓬勃景象------国外工具声势浩大,国内产品也同样风生水起,各类解决方案层出不穷,呈现出百花齐放的繁荣态势
然而在这繁荣背后,却隐藏着一个行业共同的尴尬:同质化困局正在悄然蔓延
同质化困局
打开这些主流 BI 工具的界面,除了配色方案和图标设计稍有不同,核心功能模块和操作逻辑都惊人地相似:同样的可视化数据连接流程,近乎一致的拖拽式报表构建界面,高度重合的各类图表可视化库,甚至连仪表板的布局逻辑、各种旋转、切片、下钻分析模式都如出一辙,从数据准备、建模到前端展示,每一步操作都像是从一个模子里刻出来的,几乎不可能找到某一个甲有乙没有的功能
这也没办法,BI 发展了数十年,能想到的功能大都也想到了,有 N 年工夫也就都复制出来了,所以只能进入这种同质化时代,很难再靠产品功能本身的特色赢得用户了
而且,除了功能雷同外,这些产品的价格策略也很相似------几万到几十万的授权费用,将许多有 BI 需求的中小企业结结实实的挡在了门外
在这个功能趋同、价格普遍高昂的同质化市场中,杀出重围必须另辟蹊径,因此,润乾 BI 选择------不再做一个同质化的同行者,而是一个打破僵局的搅局者
同质化的东西,干脆开源免费得了
润乾是报表领域的老兵,因为报表 BI 不分家,也常常被拿来当 BI 工具用,但润乾在 BI 领域其实一直不温不火,很少主动参与竞争和宣传,也是因为同质化太严重,想不出什么过人的亮点
如果一直困在高度同质的赛道中内卷竞争,其实意义有限,它既难以推动技术实质性进步,也无法真正降低用户的获取门槛,既然如此,何不主动打破规则?
干脆就免费开源搅个局吧
通过开源与免费的模式,消除技术和商业壁垒,让 BI 不再成为企业的成本负担,而是真正用得起,用的好的数据分析工具
于是,润乾 BI 把大家都有的,同质化的功能,全都开源免费了
清爽简洁的拖拽界面,所见即所得
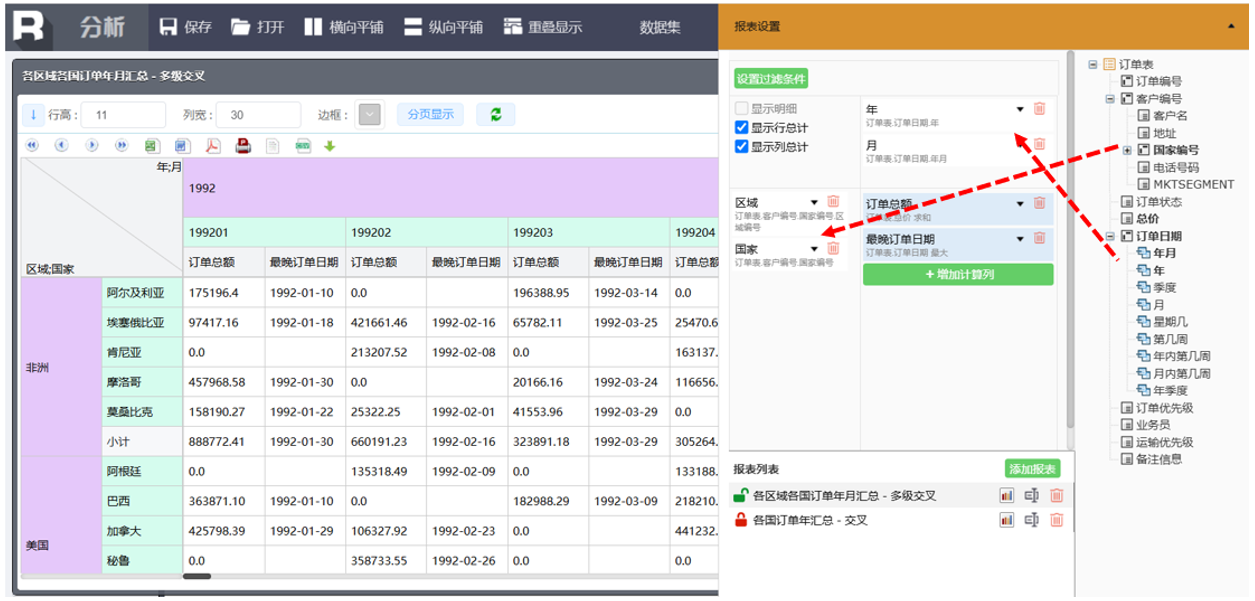
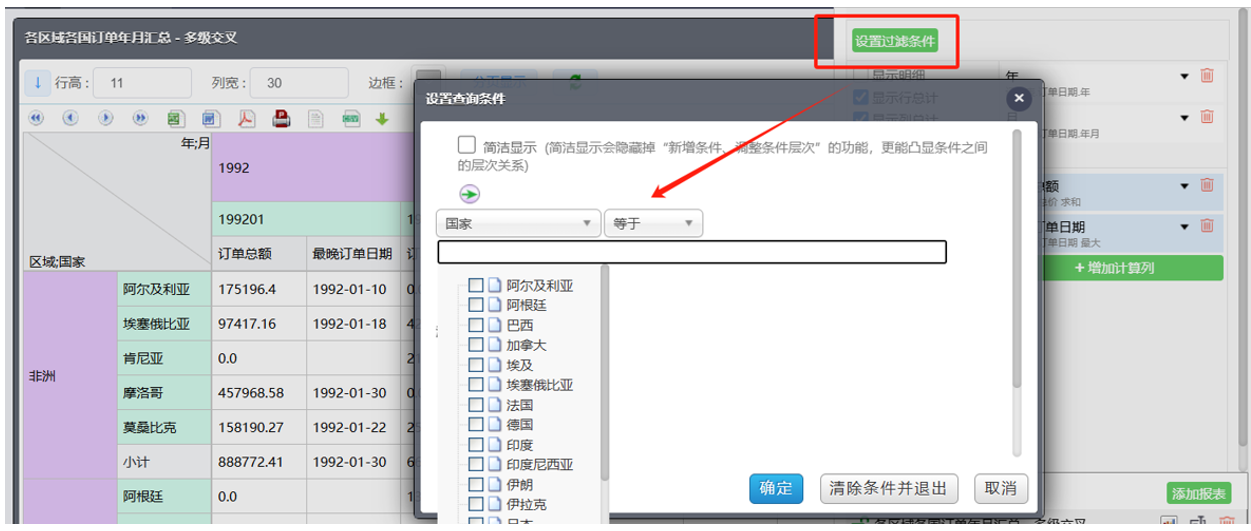
支持切片 / 切块、钻取 / 上卷、旋转等多维分析常见操作
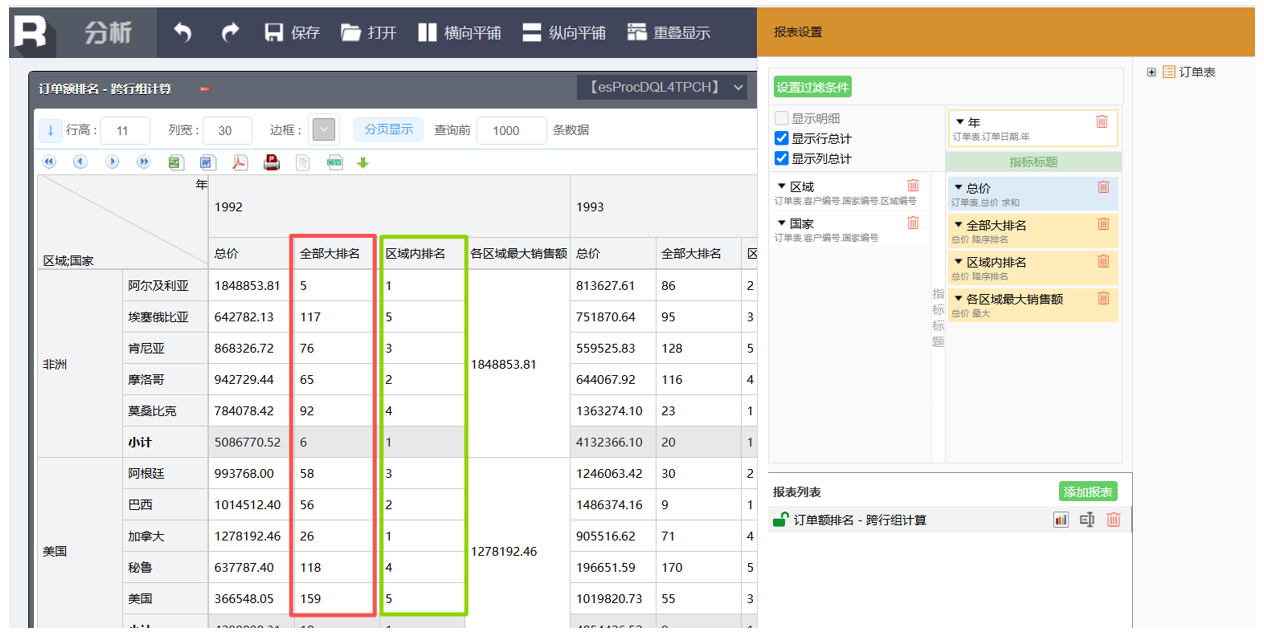
支持同比、环比、排名、占比等复杂跨行组运算
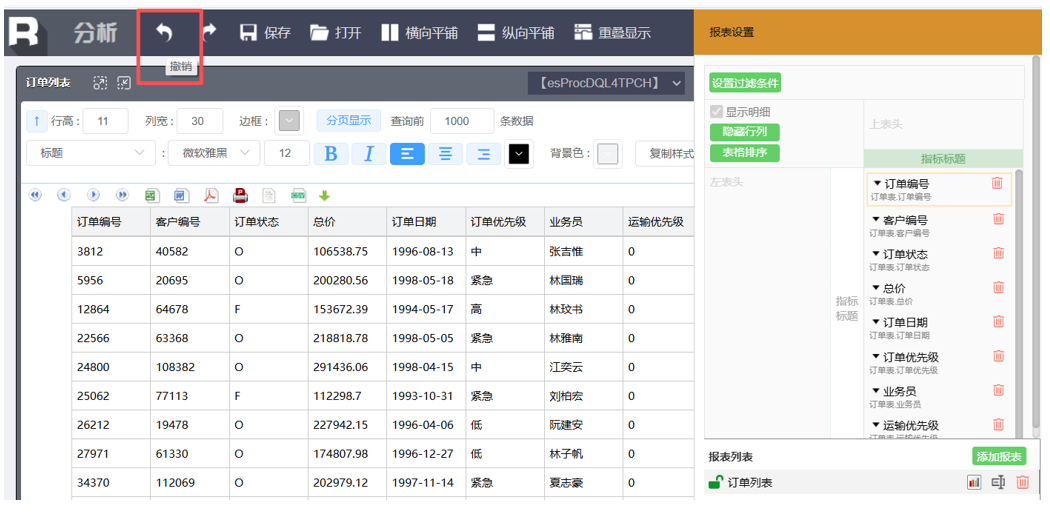
支持 UNDO 撤销功能
内置各种 Echarts 统计图
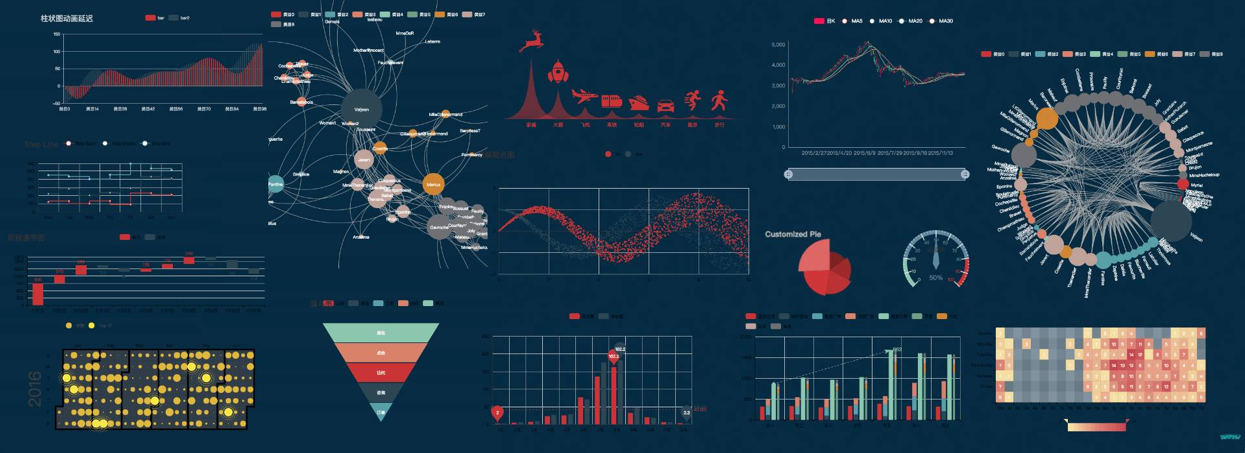
可基于模型分析,也可基于 SQL,文本文件 CSV、Excel、TXT 等进行临时分析
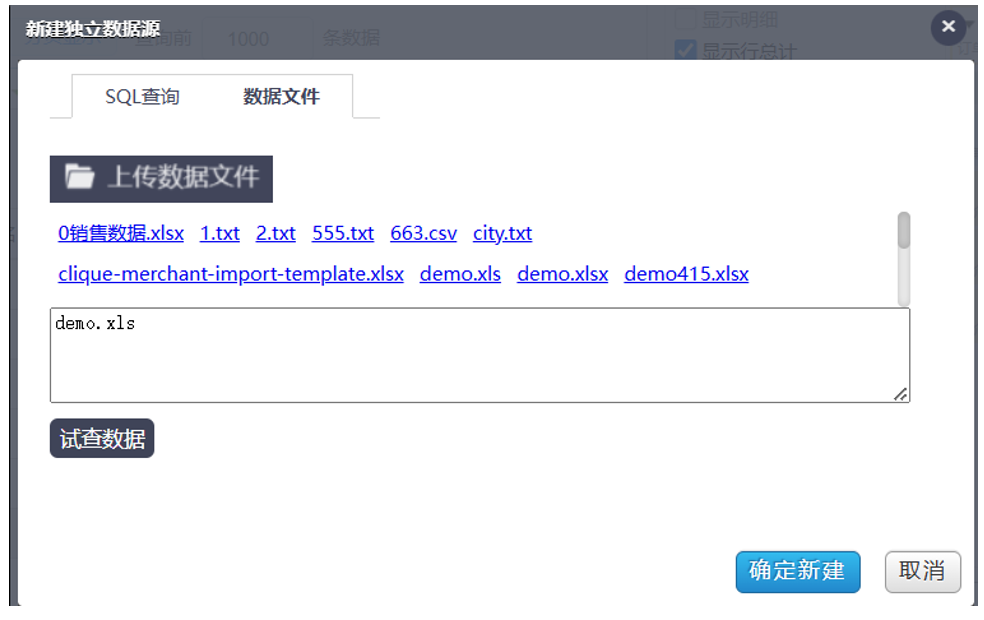
大功能全部包含,细节功能也做的不错,有一些个性化需求,比如这个显示合计值用的合并单元格,很多 BI 工具都不支持,但这对有某些有格式需求的场景还挺重要的,结果经常看到有些 BI 工具再使用其它网格控件来对付
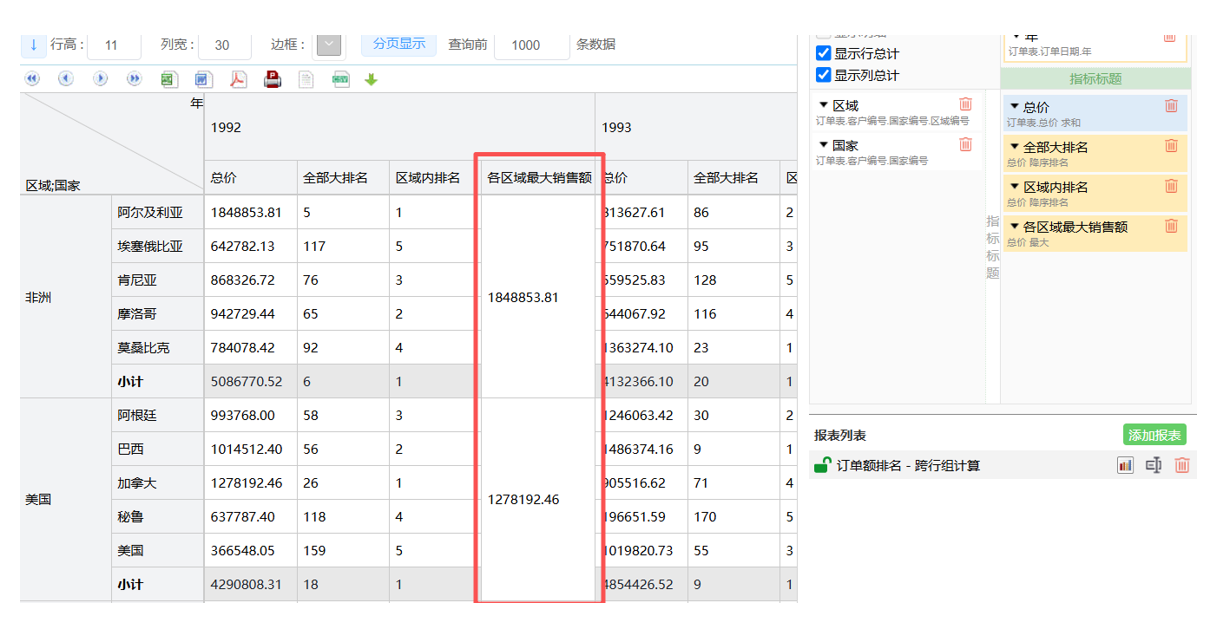
当然,不足也是有的
润乾 BI 界面比较朴素,看起来不够炫,但好在都是开源的,全中文,用户可以根据自己系统风格和需求自行改造
免费却不同质化的大杀器
大家都有的同质化的功能,都开源免费用了,但润乾 BI还有不同质化的内容,那就是:独有的大杀器---DQL 引擎
这部分没开源,但也可以免费用
BI 兴起的原因以及建设 BI 系统的初衷,是希望将数据查询能力赋予业务人员,让数据分析更灵活高效,也让技术团队从繁琐的数据支撑工作中解放出来
然而现实却是:用了 BI,业务部门依然频繁需要技术协助 ------"这个分析没办法拖拽""那个关联我不会做"
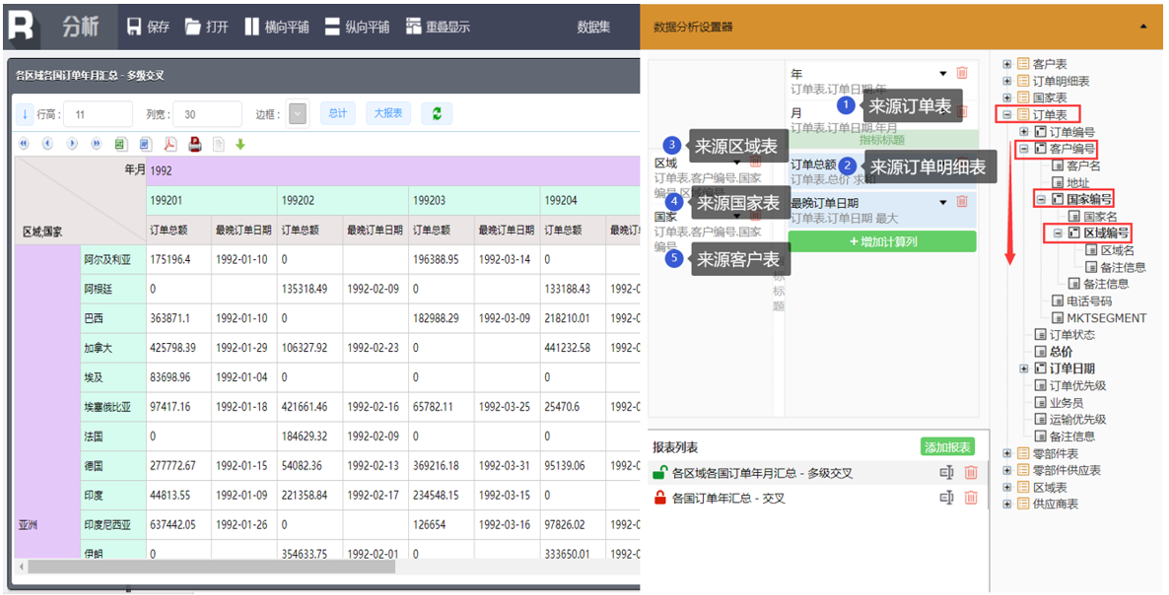
问题的核心在于,传统 BI 方案在处理多表关联时存在天然缺陷 ,比如一个常见的例子:"帮我拉一下北京打往上海的通话记录,要主叫姓名、被叫姓名、通话时长和资费情况",这个查询对应的 SQL 是这样的:
SELECT c.call_id, u1.user_name as caller_name, u2.user_name as callee_name,
c.duration, r.rate_amount, city1.city_name as from_city, city2.city_name as to_city
FROM call_records c
JOIN users u1 ON c.caller_id = u1.user_id
JOIN users u2 ON c.callee_id = u2.user_id
JOIN cities city1 ON u1.city_id = city1.city_id
JOIN cities city2 ON u2.city_id = city2.city_id
JOIN rate_plans r ON c.rate_plan_id = r.plan_id
WHERE city1.city_name = '北京' AND city2.city_name = '上海'SELECT c.call_id, u1.user_name as caller_name, u2.user_name as callee_name, c.duration, r.rate_amount, city1.city_name as from_city, city2.city_name as to_city FROM call_records c JOIN users u1 ON c.caller_id = u1.user_id JOIN users u2 ON c.callee_id = u2.user_id JOIN cities city1 ON u1.city_id = city1.city_id JOIN cities city2 ON u2.city_id = city2.city_id JOIN rate_plans r ON c.rate_plan_id = r.plan_id WHERE city1.city_name = '北京' AND city2.city_name = '上海'
6 个 JOIN 技术人员看着都头晕,更别说让业务人员在界面上自己拖拽实现
结果就是:本想快速灵活进行的分析,却做不了,必须得找技术来协助
面对这种困境,传统 BI 常见的解决方案是宽表,或者和宽表性质相同的 CUBE,有复杂关联需求,就由技术人员来做宽表,宽表的数据冗余,维护困难等弊端我们先不谈,单单是一有复杂关联的分析,就得找技术人员这一点,就把用户所有的耐心都磨光了
一个宽表做好有的要半天,有的要几天,今天要做的分析拖到了明天,这周的拖到了下周,一点时效性没有,体验极其糟糕,被动剥夺了用户的复杂关联分析权利,客户满意度低至冰点
DQL :解决关联分析难题的核武器
润乾 BI 的 DQL(Dimensional Query Language)正是为破解 BI 复杂关联困境而生,其核心目标就是让多表关联查询在 BI 系统中变得像操作单表一样简单直观 ,从而满足业务部门即兴、实时查询分析需求
上面需要工程师去写的 6 个 JOIN 的 SQL 语句,DQL 引擎自动生成的是这样的
SELECT call_id, caller.user_name, callee.user_name,
duration, rate_plan.rate_amount,
caller.city.city_name as from_city,
callee.city.city_name as to_city
FROM call_records
WHERE caller.city.city_name = '北京'
AND callee.city.city_name = '上海'SELECT call_id, caller.user_name, callee.user_name, duration, rate_plan.rate_amount, caller.city.city_name as from_city, callee.city.city_name as to_city FROM call_records WHERE caller.city.city_name = '北京' AND callee.city.city_name = '上海'
FROM 后面只有一个表,没有任何关联
但这些技术原理其实和用户也没有关系,这些都是后台自动生成的,不需要用户了解,用户在前端看到的就是这样的清晰的树状结构:
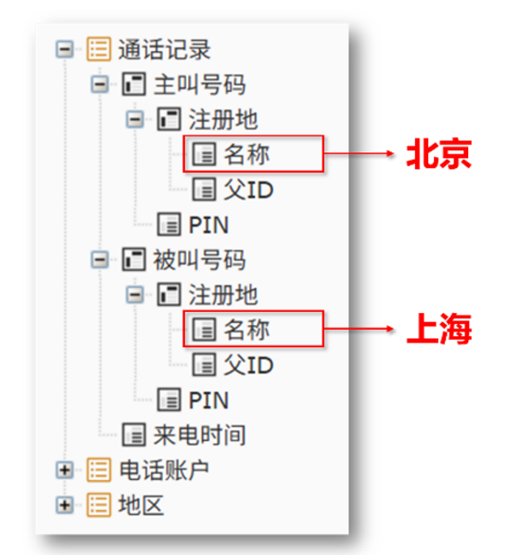
查询分析流程也极其简单:
-
选择 "通话记录" 作为查询主体
-
勾选需要的字段:主叫用户. 所在城市. 城市名称、被叫用户. 所在城市. 城市名称、通话时长、资费方案. 资费金额
-
设置过滤条件:主叫用户. 所在城市. 城市名称 ='北京' AND 被叫用户. 所在城市. 城市名称 ='上海'
这就查询完了,不需要再提交需求给技术人员费时去做宽表,自己轻轻松松就搞定了
更核心的一点是:
DQL 引擎,不仅能让复杂关联变的简单,而且也不需要每次都设置,它只要定义一次元数据,就能应对所有想到和没想到的关联,不管有多少复杂的关联需求,用户也可以自由、及时,灵活无死角的进行分析了
更多详情请参考:千问 BI 取数:为什么总是要做宽表?
商业思考:全面拥抱 AI
当整个业界都在谈论 AI 大模型、ChatBI 时,润乾回过头来先把 BI 开源免费了,看似做了一件"不合时宜"的事
这不是对 AI 热潮的漠视,恰恰相反,这是为迎接真正的智能时代,铺设的更重要的一条路,因为在追逐 AI 的高层楼阁之前,必须先让 BI 工具本身,触及更多有需求的用户,搭建牢固的用户基础,否则没有 BI 的普及,ChatBI 将只能是空中楼阁
润乾 BI 更不是在 AI 上无所作为,恰恰相反,在喧嚣之外,润乾早已备好了一套更准确、更全面、优势更多的 AI 方案------润乾商业版中的 "全链路 ChatBI"
更准确
当前,多数 ChatBI 产品依赖大模型生成 SQL,在实际应用中会暴露出一个致命问题:"幻觉"
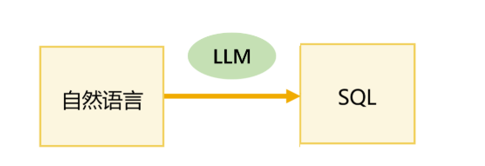
大模型本质上是概率模型,其训练目标是生成流畅文本,而非精确的数据查询,无论用户的问题是否可查,大模型几乎总会给出一个结果,它可能生产语法正确但语义错误的 SQL,而业务人员无法看懂 SQL,也就无法发现和纠正错误,在企业决策场景中,一个错误的数据可能导致严重的后果
为应对大模型幻觉问题,有的产品引入中间层方案:先由 LLM 将自然语言转换为结构化中间语言(如 MQL),再用规则引擎转成 SQL 执行
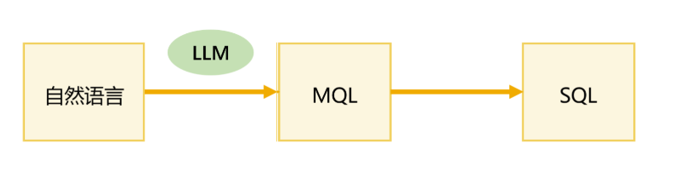
但这样做准确性并未有实质提升------LLM 不熟悉中间语言语法,反而可能产生更严重的幻觉,为了准确性,不得不将中间层设计得极其简单,也就是对查询能力进行"降智"------原本复杂的多表关联、嵌套查询、指标计算,要么被简化处理,要么直接被限制,结果是:准确性虽然有限提升,但复杂查询能力严重下降, 用户能问的,只剩下那些"简单问题"
同时,中间层结果和 SQL 一样,对业务用户仍是"天书",无法有效确认查询意图,准确性问题未能根除
润乾 ChatBI 选择了一条完全不同的技术路径------不依赖大模型,而是基于精密的"规则引擎",构建了一套确定性的自然语言理解与执行系统(NLQ 自然语言查询系统)
润乾 NLQ:"输入汉语,直接出数据"的智能问数功能
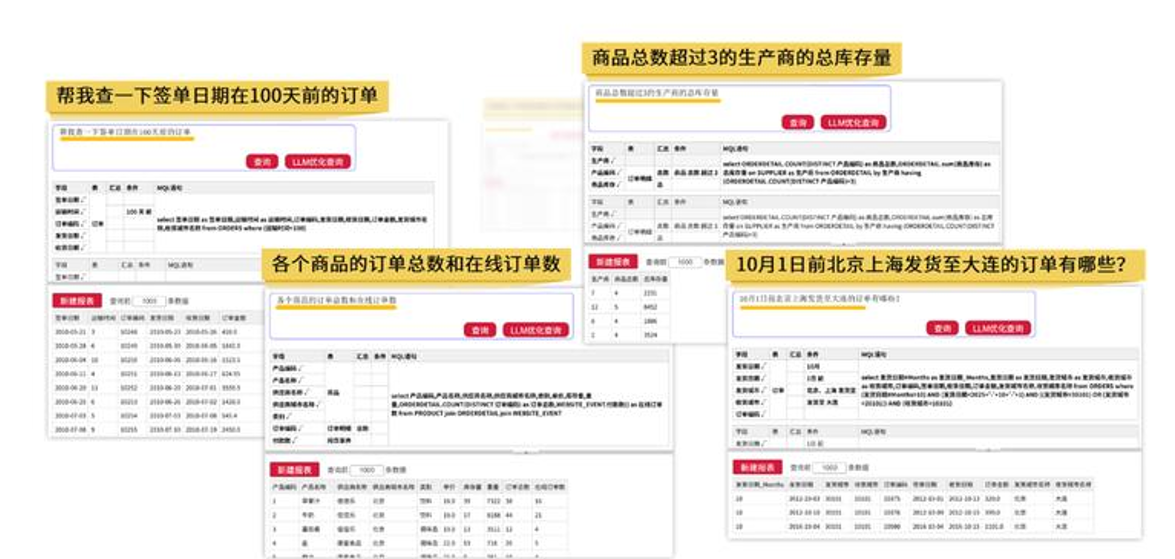
它预先将数据模型、业务术语、指标口径、常用查询模式等知识,结构化地录入规则词典,
并以 "规范文本" 作为人机中介语言
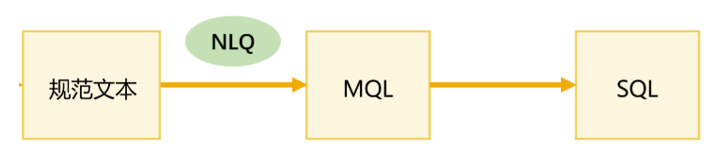
它是一种较为规范的自然语言 形式, 比如:
• 出生日期在 1986 年 1 月至 1986 年 7 月的雇员
• 2023 年北京发往青岛的订单
• 商品单价大于等于 9.5 小于等于 12
当用户输入一句较为规范的自然语言时,系统进行词法分析、语义标注、词典匹配,一步步将自然语言"编译"成精确的查询指令,并得到准确的结果
规范文本 +NLQ 规则引擎 ,这一对组合就可以很好的解决前面提到的幻觉和复杂度问题
首先规范文本虽然也是自然语言,但它有一定的规范性,可以更好的保证需求描述准确, "规范文本" 的设计还能支持复杂查询
其次规则引擎可以进一步保证准确性,它可以有做不到的,但是绝对不会"胡说", 如果用户指令中出现未定义的词,系统会明确提示"无法识别",而不是像 LLM 那样编造一个似是而非的结果,彻底告别不确定的"幻觉"困境
当业务逻辑变化时(如"销售额"的计算规则需要扣除运费),管理员只需在指标词典中修改公式,整个过程像修改配置文档一样清晰可控,这意味着整个转换路径是可解释、可完善的
更全面
市面上大部分 ChatBI 方案,能力往往止步于 Text2SQL------能听懂一句话、查出一张表,可真正的分析才刚刚开始:怎么算增长、怎么排名次、怎么看趋势......这些关键步骤,还得回到传统界面手动操作
也就是只能做到智能问数,做不到智能分析,功能不全面
造成这个现象的原因有两个,一是 前面说的很多工具还没有解决 LLM 的幻觉问题,所以无暇顾及后续分析的环节,二是多维分析是一连串有逻辑依赖的操作:先分组、再汇总、然后排序......市面上缺乏足够的高质量数据来训练大模型驾驭这套"动作序列",实现难度也不小
而润乾 ChatBI 将同样的规则引擎思路延伸至分析阶段,提供了 NLR(自然语言报表)能力:用户可以基于查询得到的数据集,用简洁的汉语指令直接驱动报表完成各种分析动作
润乾 NLR:"输入汉语,直接分析"的智能分析功能
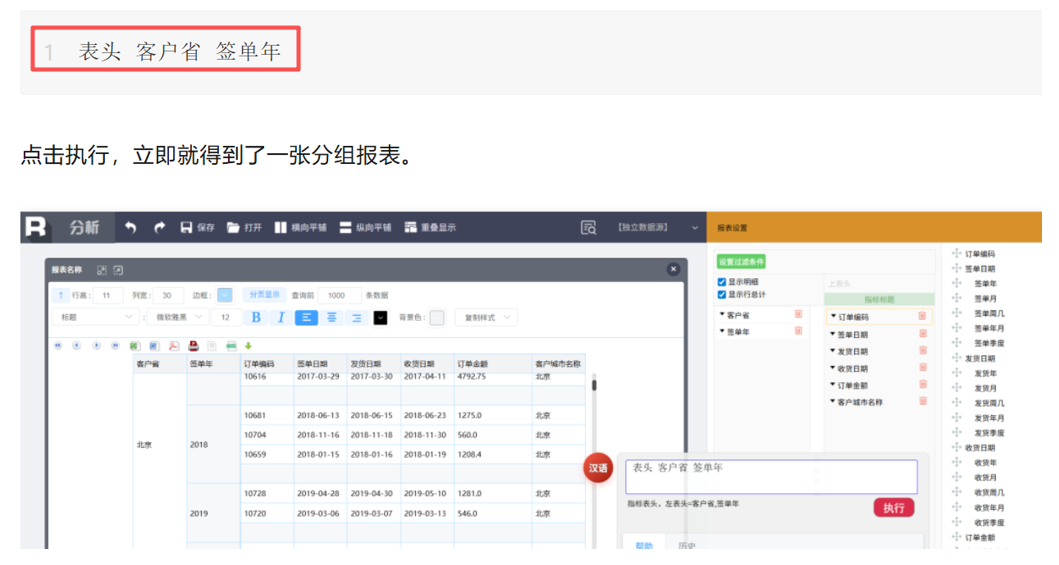
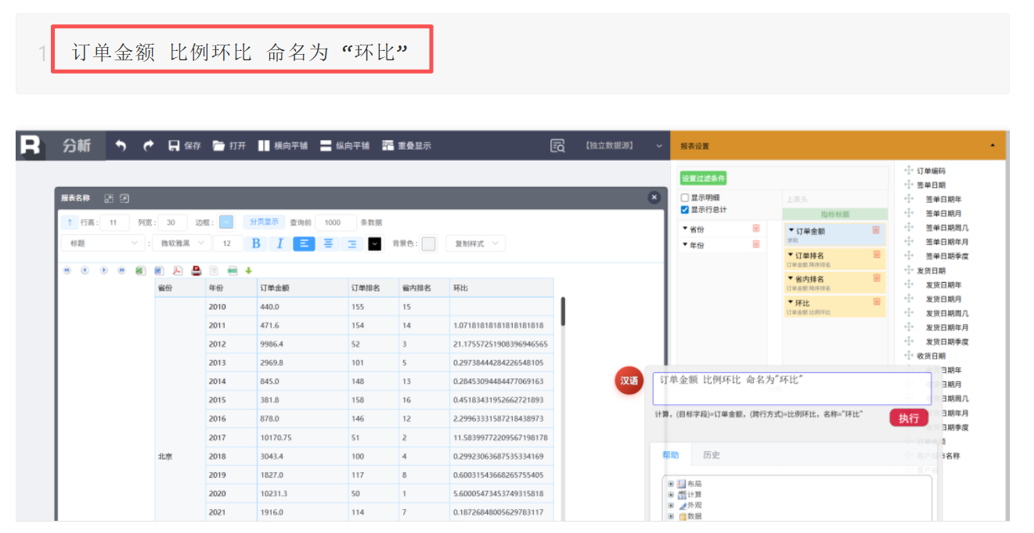
从问到析,全链路贯通,没有幻觉,只有准确的结果
这才是真正的全链 ChatBI
规则引擎具体技术方案请参考:
优势多
不依赖大模型,成本低
润乾整套 ChatBI 基于轻量规则引擎,普通 CPU 服务器即可流畅运行,无需昂贵的 GPU 集群,也没有 Token 费用。而润乾报表的价格本身也很便宜,,这使得中小企业也能以"平民价格"拥有 AI 能力了
无"幻觉" 稳定可靠
规则引擎的每一步输出都是确定的,不确定的内容就会提示不识别,不会有幻觉产生,引擎词典也可以快速修改和完善,不像 LLM,逻辑如同"黑盒",无论对了还是错了,都很难搞清具体原因,改进效果也无法控制
私有化部署,安全可靠
整个方案可以完全部署在企业内部服务器上,数据无需出域,彻底满足金融、政府、大型企业对数据安全与隐私合规的严苛要求
低延迟,流畅体验
所有指令的解析都在本地毫秒级完成,不会感受到任何网络延迟或 LLM 流式输出的等待,获得的是一种"即问即答"的流畅交互体验,让思考与创作无缝衔接
当然纯规则引擎方案有其局限------它需要相对规范的语言,无法理解"帮我瞅瞅上个月卖得最火的是啥?"这种过于口语化的表达,不够灵活自由,所以润乾 ChatBI 也支持和 LLM 配合使用
搭配 LLM 更灵活而且低成本

引入 LLM 后,可以让它作为"智能前台",将用户随意的口语"翻译"成规范文本指令(如"查询上月销量前十的产品"),再由规则引擎精准执行,这样就可以既享受 LLM 的灵活自由,又能确保查询和分析的准确性了
而且这样的搭配也不会有太高成本 ,因为 LLM 的任务被简化为 "文字规范化",只需要理解自然语言并重新组织成规范的问句,无需理解复杂的数据库 Schema 或业务逻辑,也就是只要摆位,这种相对简单的任务,私有化部署的小参数模型都能胜任,既享受了 LLM 的交互友好性,又保证了极低的部署和运行成本
而且只执行"文字规范化"任务的LLM 输出的中间指令是前面提到的"规范文本",是机器能读懂,人更能看懂的"人话",用户如果发现不对可以立即纠正------这比让 LLM 直接生成难以验证的 JSON 或 SQL 要可靠得多
润乾 BI 的 AI 能力不免费是真的,但功能更好用,更全面,成本极低也是真的, 对于那些希望进一步迈向智能化的用户,提供了一条门槛极低的进阶之路
让 ChatBI 人人都可用
润乾开源 BI 的出现,不是为了在 AI 热潮中再添一个雷同的"智能故事",而是希望为 AI 时代的到来,铺就更广泛的用户基础
无论您的企业规模大小,无论您正处于数据应用的哪个阶段,润乾 BI 都可以胜任,用开源免费的 BI,和极低成本的 AI(ChatBI),共同探索数据的无限价值
让 ChatBI 人人都可用!