介绍
Gradio 是一个非常轻量级但强大的工具,可以帮助我们在几行代码内构建 Web Demo。
本文将基于 PyTorch + YOLOv8 + Gradio,实现一个集成:
- 图像分类(ResNet18)
- 目标检测(YOLOv8)
- 语义分割(YOLOv8-Seg)
的机器学习图像分类实战案例。
安装依赖:
pip install gradio torch torchvision ultralytics pillow模型和标签准备
|--------|------------------------|
| 任务 | 模型 |
| 图像分类 | ResNet18(ImageNet 预训练) |
| 目标检测 | YOLOv8 |
| 语义分割 | YOLOv8-Seg |

这三个库不需要单独下载,第一次运行会自动从官方拉取模型,如果网络不行也可以在HuggingFace查询手动下载。
分类标签加载
分类模型使用 ImageNet 的 1000 类标签
https://deeplearning.cms.waikato.ac.nz/user-guide/class-maps/IMAGENET/
可以在这里下载,也可以直接用我的github代码里面附件
https://github.com/zwzhangyu/deep-py-lab
完整代码
# 导入库
from torchvision import transforms
from ultralytics import YOLO
from PIL import Image
import gradio as gr
import torch
# 模型定义
model_seg = YOLO('./yolov8s-seg.pt')
model_detect = YOLO('./yolov8s-oiv7.pt')
model_cls = torch.hub.load(repo_or_dir='pytorch/vision:v0.6.0', model='resnet18', pretrained=True).eval()
# 读标签
file_path = 'labels.txt'
with open(file_path, 'r') as file:
labels = file.readlines()
labels = [label.rstrip() for label in labels]
# 函数定义
def seg(image):
"""
使用 YOLOv8 分割模型对输入图像进行语义分割,并返回可视化结果。
参数:
image (PIL.Image): 输入图像
返回:
PIL.Image: 带有分割结果(mask + 标注)的可视化图像
说明:
- 内部调用 Ultralytics YOLO 模型进行推理
- r.plot() 会自动绘制分割结果
- 返回结果已从 BGR 转换为 RGB 格式
"""
results = model_seg([image])
for r in results:
im_array = r.plot()
img = Image.fromarray(im_array[..., ::-1])
return img
def det(image):
"""
使用 YOLOv8 目标检测模型对输入图像进行检测,并返回可视化结果。
参数:
image (PIL.Image): 输入图像(来自 Gradio,类型为 PIL)
返回:
PIL.Image: 带有检测框(bounding boxes)的可视化图像
说明:
- 内部调用 Ultralytics YOLO 检测模型进行推理
- r.plot() 会自动绘制检测框和类别标签
- 返回结果已从 BGR 转换为 RGB 格式
"""
results = model_detect([image])
for r in results:
im_array = r.plot()
img = Image.fromarray(im_array[..., ::-1])
return img
def cls(image):
"""
使用 ResNet18 分类模型对输入图像进行分类,并返回各类别的置信度。
参数:
image (PIL.Image): 输入图像(来自 Gradio,类型为 PIL)
返回:
dict: 分类结果字典,key 为类别名称,value 为对应的概率(置信度)
说明:
- 输入图像会先转换为 Tensor,并增加 batch 维度
- 使用 softmax 将模型输出转换为概率分布
- labels.txt 提供 1000 个类别标签(对应 ImageNet)
- 返回所有类别的概率(Gradio 会自动选取 Top-N 显示)
"""
image = transforms.ToTensor()(image).unsqueeze(0)
with torch.no_grad():
prediction = torch.nn.functional.softmax(model_cls(image)[0], dim=0)
confidences = {labels[i]: float(prediction[i]) for i in range(1000)}
return confidences
with gr.Blocks() as demo:
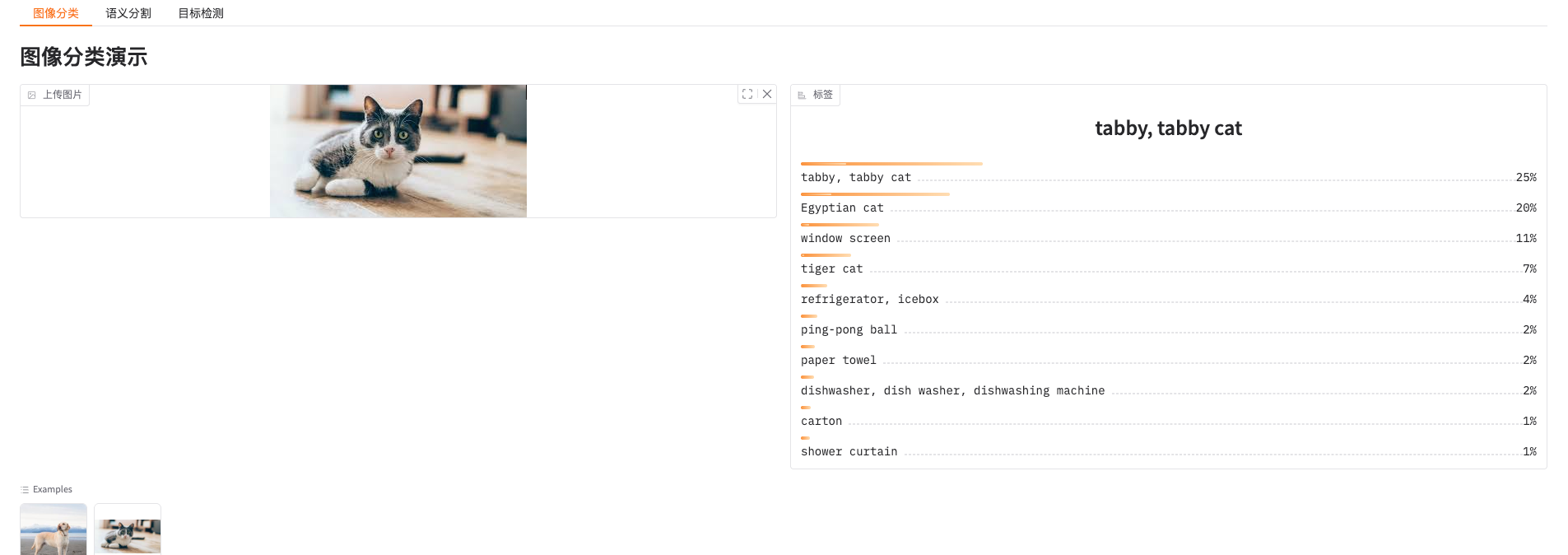
with gr.Tab("图像分类"):
gr.Markdown("# 图像分类演示")
with gr.Row():
input_img = gr.Image(sources=["upload"], label="上传图片", type='pil')
output_label = gr.Label(num_top_classes=10)
gr.Examples(examples=['./dog.png', './cat.png'], inputs=[input_img])
button = gr.Button(value="分类", variant="primary")
button.click(cls, inputs=input_img, outputs=output_label)
with gr.Tab("语义分割"):
gr.Markdown("# 语义分割演示")
with gr.Row():
input_img = gr.Image(sources=["upload"], label="上传图片", type='pil')
output_img = gr.Image(type='pil')
gr.Examples(examples=['./dog.png', './cat.png'], inputs=[input_img])
button = gr.Button(value="分割", variant="primary")
button.click(seg, inputs=input_img, outputs=output_img)
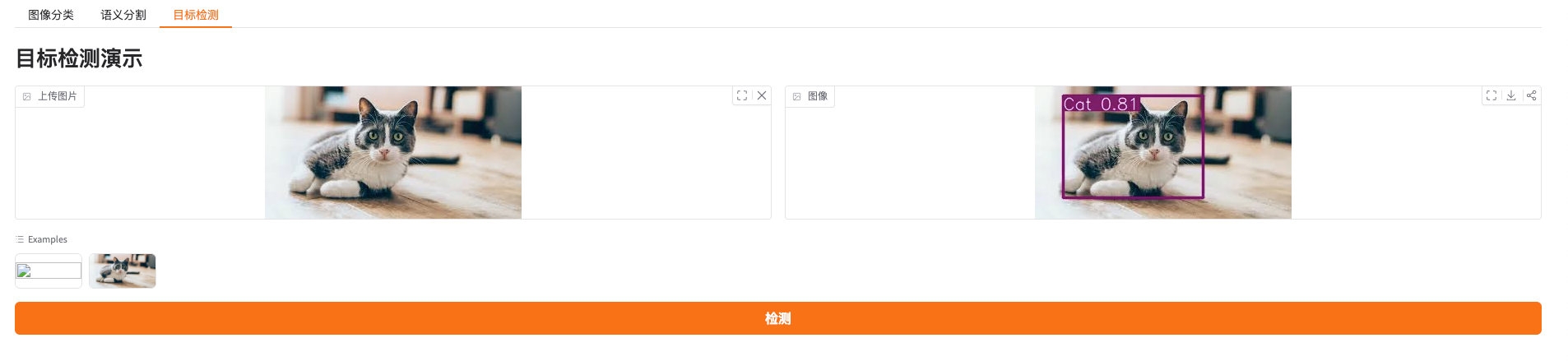
with gr.Tab("目标检测"):
gr.Markdown("# 目标检测演示")
with gr.Row():
input_img = gr.Image(sources=["upload"], label="上传图片", type='pil')
output_img = gr.Image(type='pil')
gr.Examples(examples=['./dog.jpeg', './cat.png'], inputs=[input_img])
button = gr.Button(value="检测", variant="primary")
button.click(det, inputs=input_img, outputs=output_img)
demo.launch()整体逻辑
- 加载模型
初始化三个模型:
-
- YOLOv8 分割模型(
model_seg) - YOLOv8 检测模型(
model_detect) - ResNet18 分类模型(
model_cls)
- YOLOv8 分割模型(
模型在程序启动时加载,提高后续推理效率。
- 读取分类标签
从 labels.txt 文件中读取 ImageNet 的 1000 类标签,用于分类结果映射。
- 实现图像分割函数(seg)
将输入图像送入分割模型,调用 r.plot() 生成带有分割效果的图像,并转换为 PIL 格式返回。
- 实现目标检测函数(det)
将输入图像送入检测模型,自动绘制检测框和类别标签,并返回可视化结果图像。
- 实现图像分类函数(cls)
将输入图像转换为 Tensor 后输入分类模型,通过 softmax 得到各类别概率,并结合标签生成"类别-概率"字典。
- 构建 Gradio 界面
使用 gr.Blocks() 创建整体界面,通过 Tab 划分为:
-
- 图像分类
- 语义分割
- 目标检测
每个模块包含输入组件、输出组件和按钮。
- 绑定交互逻辑
通过 button.click() 将按钮与对应函数绑定,实现"点击按钮 → 执行模型推理 → 返回结果"的流程。
- 提供示例数据
使用 gr.Examples 提供测试图片,方便用户快速体验模型效果。
效果展示