本文从基础定义到底层算法原理,系统梳理 Flink Checkpoint 机制的完整知识体系,包含架构图、执行流程图、分类对比与生产调优指南。
一、什么是 Checkpoint
Checkpoint(检查点) 是 Apache Flink 容错机制的核心,它在不停止数据处理的前提下,周期性地为整个分布式作业生成一致性全局快照 ,当作业发生故障时,可从最近一次成功的 Checkpoint 恢复,实现 Exactly-Once(精确一次) 语义。
在整个 Flink 体系中,Checkpoint 处于 基础设施层:所有有状态算子(window、keyBy 后的聚合、ProcessFunction 中的 State)都依赖 Checkpoint 实现故障恢复,而 Savepoint、两阶段提交 Sink(2PC)、端到端 Exactly-Once 均以 Checkpoint 为基础。
💡 直觉类比:Checkpoint 就像电子游戏里的存档点------游戏不会暂停,但系统会在后台悄悄把你的状态(血量、装备、位置)保存下来。一旦游戏崩溃,你只需从最近的存档继续,而不用从头开始。
二、整体架构全景图
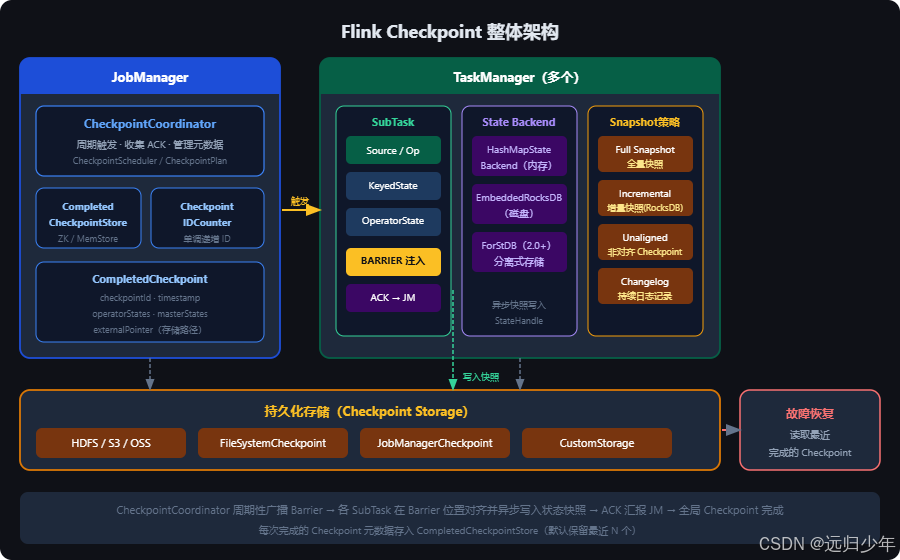
三、核心子概念详解
3.1 Checkpoint Coordinator(检查点协调器)
定义:运行在 JobManager 内的核心控制组件,负责整个 Checkpoint 的生命周期管理。
关键职责:
- 按照配置的时间间隔,向所有 Source 算子广播 CheckpointBarrier
- 跟踪每个 SubTask 对 Barrier 的 ACK 响应
- 在收到全部 ACK 后,将 CompletedCheckpoint 写入元数据存储
- 管理 Checkpoint 超时与失败重试逻辑
java
// 配置 CheckpointCoordinator 的核心参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(60_000L); // 每 60s 触发一次
CheckpointConfig cfg = env.getCheckpointConfig();
cfg.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 精确一次语义
cfg.setCheckpointTimeout(120_000L); // 超时 120s
cfg.setMaxConcurrentCheckpoints(1); // 同时最多 1 个进行中
cfg.setMinPauseBetweenCheckpoints(30_000L); // 两次间最小间隔 30s
cfg.setTolerableCheckpointFailureNumber(3); // 允许连续失败 3 次
// 作业取消后保留 Checkpoint 数据
cfg.setExternalizedCheckpointCleanup(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);3.2 Checkpoint Barrier(检查点屏障)
定义 :一种插入数据流中的 特殊控制消息 ,不携带业务数据,仅用于在各算子间传递"快照边界"的信号。每个 Barrier 携带一个全局唯一的 checkpointId。

3.3 State Backend(状态后端)
定义 :决定算子状态存储在哪里 以及如何序列化/快照的组件。
| 后端 | 工作内存 | 快照目标 | 适用场景 |
|---|---|---|---|
HashMapStateBackend |
JVM 堆内存 | 外部存储(HDFS/S3) | 状态小、延迟敏感 |
EmbeddedRocksDBStateBackend |
本地 RocksDB(堆外) | 外部存储(增量可选) | 状态超大(TB 级) |
ForStDB(Flink 2.0+) |
远程分布式存储 | 分离式存储 | 云原生、弹性扩缩容 |
java
// 配置 RocksDB 增量 Checkpoint(大状态必选)
EmbeddedRocksDBStateBackend rocksDB =
new EmbeddedRocksDBStateBackend(true); // true = 开启增量
env.setStateBackend(rocksDB);
// 配置 Checkpoint 存储路径
env.getCheckpointConfig().setCheckpointStorage(
"hdfs://namenode:8020/flink/checkpoints");3.4 CompletedCheckpoint(完成的检查点元数据)
每次 Checkpoint 成功后,JobManager 会持久化一个 CompletedCheckpoint 对象,包含:
checkpointId:全局单调递增的 IDtimestamp:触发时间戳operatorStates:每个算子 SubTask 的状态句柄(StateHandle → 指向存储路径)masterStates:JobManager 侧(如 Kafka offset)的状态
四、Chandy-Lamport 算法与 Barrier 传播完整流程
Flink 的 Checkpoint 机制基于 Chandy-Lamport 分布式快照算法 (1985 年,Leslie Lamport 和 K. Mani Chandy 提出),其核心思想是:在不暂停系统的情况下,通过在通道中插入标记(Marker/Barrier),让各节点在收到标记时记录自身状态,从而得到一致性全局快照。
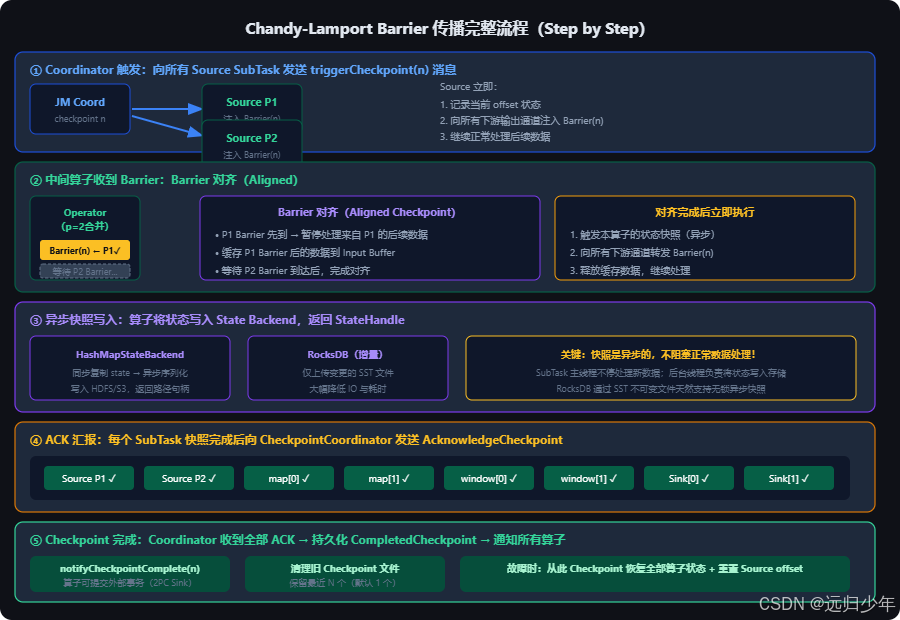
五、三种 Checkpoint 模式对比
5.1 对齐 vs 非对齐 vs Changelog 模式

5.2 三种模式总结对比表
| 维度 | Aligned(对齐) | Unaligned(非对齐) | Changelog |
|---|---|---|---|
| Flink 版本 | 全版本 | 1.11+ | 1.16+(Beta) |
| 语义 | Exactly-Once | Exactly-Once | Exactly-Once |
| Barrier 等待 | 需要对齐 | 无需等待 | 无需等待 |
| 快照大小 | 仅状态 | 状态 + in-flight 数据 | 增量 changelog |
| Checkpoint 耗时 | 与反压正相关 | 与反压解耦 | 几乎为零 |
| 恢复速度 | 中 | 较慢(in-flight 重放) | 快(可配置) |
| 适用场景 | 通用 | 严重反压 | 低 RTO 关键业务 |
六、与其他概念的关联关系
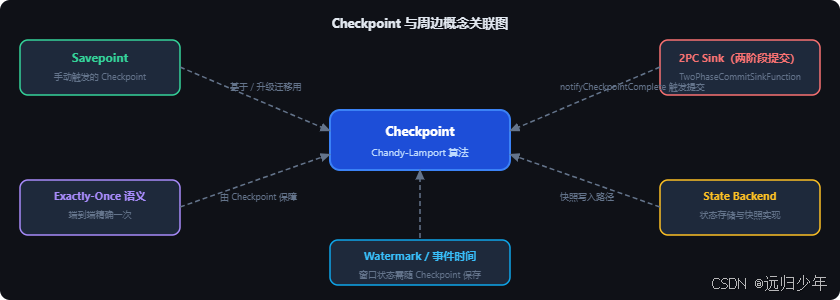
6.1 Checkpoint + 两阶段提交(2PC)实现端到端 Exactly-Once
java
// Kafka → Flink → Kafka 端到端 Exactly-Once
public class ExactlyOnceSinkExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 1. 开启 Checkpoint(2PC Sink 必需)
env.enableCheckpointing(30_000);
env.getCheckpointConfig()
.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 2. Source:KafkaSource 自动在 Checkpoint 时提交 offset
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("localhost:9092")
.setTopics("input-topic")
.setGroupId("flink-group")
// EARLIEST + Checkpoint 配合保证不重不漏
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(
source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3. Sink:FlinkKafkaProducer 实现了 TwoPhaseCommitSinkFunction
// Checkpoint 完成时才真正 commit 事务到 Kafka
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers("localhost:9092")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("output-topic")
.setValueSerializationSchema(new SimpleStringSchema())
.build())
// EXACTLY_ONCE 模式需配合 Checkpoint
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.setTransactionalIdPrefix("flink-txn-")
.build();
stream.map(String::toUpperCase).sinkTo(sink);
env.execute("Exactly-Once Demo");
}
}七、进阶特性与底层原理
7.1 增量 Checkpoint(Incremental Checkpoint)
全量快照在状态超大时(GB ~ TB 级)耗时极长。RocksDB 的 SST 文件不可变特性天然支持增量快照:只上传自上次 Checkpoint 以来新增的 SST 文件。

7.2 Checkpoint 超时与反压的恶性循环分析
反压(Backpressure)会导致 Barrier 在 Input Buffer 中积压,无法及时传播到下游,从而拉长 Checkpoint 时间甚至超时。解决路径:
反压 → Barrier 传播慢 → Checkpoint 超时
↓
检查根因:
├── 算子逻辑慢 → 优化计算逻辑 / 增加并行度
├── 状态访问慢(RocksDB 未命中) → 调整 Block Cache 大小
├── 网络带宽瓶颈 → 增加 TaskManager 网络内存
└── 数据倾斜 → 二阶段聚合 / 随机前缀
↓
短期应急:切换为 Unaligned Checkpoint7.3 Flink 2.0 分离状态存储(Disaggregated State Storage)
传统架构中,状态存储在 TaskManager 本地(RocksDB),Checkpoint 时再拷贝到远程。Flink 2.0 引入 ForStDB,将状态直接存储在远程 DFS(如 S3),实现计算与存储分离,使 TaskManager 变成无状态节点,从而支持真正的弹性扩缩容。
八、生产实践与调优指南
8.1 常见问题排查表
| 问题现象 | 根本原因 | 解决方案 |
|---|---|---|
| Checkpoint 超时(Timeout) | 反压严重 / 状态过大 / IO 慢 | 切换 Unaligned;增大超时;用增量 Checkpoint |
| Checkpoint 频繁失败 | 并发 Checkpoint 冲突 | setMaxConcurrentCheckpoints(1) |
| 恢复后数据重复 | Sink 不支持幂等 / 未用 2PC | 改用 TwoPhaseCommitSinkFunction |
| 恢复后丢失数据 | 使用了 AT_LEAST_ONCE 模式 | 改为 EXACTLY_ONCE |
| Checkpoint 文件越来越大 | 状态 TTL 未设置 | 给所有 State 配置 StateTtlConfig |
| 旧 Checkpoint 文件堆积 | 保留数量配置过多 | setMaxRetainedCheckpoints(3) |
| RocksDB 写放大严重 | Compaction 策略不合理 | 调整 write_buffer_size 与 level compaction |
| 快照写入 S3 慢 | 并发写入数不足 | 调大 s3.upload.max-concurrent-uploads |
8.2 关键配置参数速查
yaml
# flink-conf.yaml(Flink 2.0+ 使用 config.yaml)
# === 基础配置 ===
execution.checkpointing.interval: 60s # Checkpoint 触发间隔
execution.checkpointing.mode: EXACTLY_ONCE # 语义模式
execution.checkpointing.timeout: 120s # 单次超时时间
execution.checkpointing.max-concurrent-checkpoints: 1
execution.checkpointing.min-pause: 30s # 两次间最小暂停
# === 存储配置 ===
state.backend: rocksdb # 或 hashmap
state.backend.incremental: true # 增量快照(RocksDB)
state.checkpoints.dir: hdfs:///flink/ckpts
state.savepoints.dir: hdfs:///flink/savepoints
state.checkpoints.num-retained: 3 # 保留最近 3 个
# === 非对齐 Checkpoint ===
execution.checkpointing.unaligned: true
execution.checkpointing.unaligned.forced: true # 反压时强制开启
# === RocksDB 调优 ===
state.backend.rocksdb.block.cache-size: 256mb
state.backend.rocksdb.write-buffer-size: 64mb
state.backend.rocksdb.thread.num: 48.3 最佳实践
① 状态 TTL 是生产必选项,防止 KeyedState 无限增长:
java
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.hours(24))
.setUpdateType(UpdateType.OnCreateAndWrite)
.setStateVisibility(StateVisibility.NeverReturnExpired)
.cleanupFullSnapshot() // 全量快照时清理过期 state
.cleanupIncrementally(1000, true) // 每次读写时后台清理
.build();
descriptor.enableTimeToLive(ttlConfig);② 大状态作业务必开启增量 Checkpoint,配合 RocksDB,单次快照时间从分钟级降到秒级。
③ 生产环境设置 RETAIN_ON_CANCELLATION,防止手动停止作业时 Checkpoint 被清除,丢失恢复点:
java
cfg.setExternalizedCheckpointCleanup(
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);④ 监控 Checkpoint 指标,及时发现问题:
lastCheckpointDuration:上次 Checkpoint 耗时lastCheckpointSize:快照大小numberOfFailedCheckpoints:失败次数numberOfInProgressCheckpoints:进行中数量
⑤ Savepoint vs Checkpoint 用途分离:Checkpoint 用于自动故障恢复;Savepoint 用于计划内操作(版本升级、扩缩容、A/B 测试),两者格式兼容但语义不同。
九、完整生命周期图
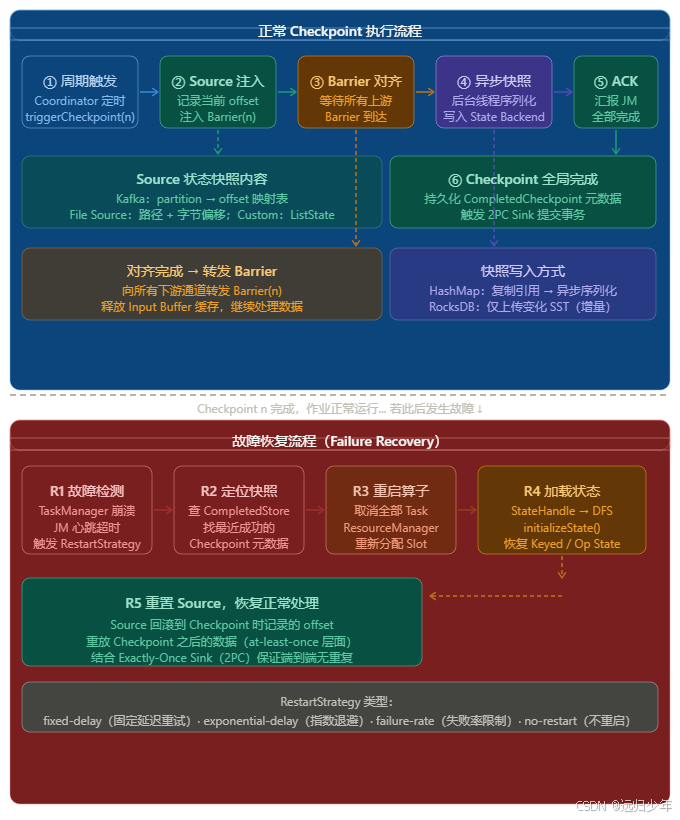
十、总结与学习路线
学习路径树
Checkpoint 基础
└── 理解 Barrier 概念与作用
└── 掌握 Aligned Checkpoint 流程(Chandy-Lamport)
└── 理解 State Backend 与快照存储
└── 掌握 Unaligned Checkpoint(反压场景)
└── 增量 Checkpoint 原理(RocksDB SST)
└── 端到端 Exactly-Once(2PC + Checkpoint)
└── Changelog Checkpoint(低延迟恢复)
└── 生产调优(TTL / 监控 / ForStDB)核心记忆要点
- Checkpoint 不暂停数据处理 --- 通过 Barrier + 异步快照实现"在线备份",这是 Chandy-Lamport 算法的核心贡献
- Barrier 是轻量级控制消息 --- 不携带业务数据,仅携带 checkpointId,插入数据流中传播"快照边界"
- 对齐是精确一次的代价 --- Aligned Checkpoint 等待所有上游 Barrier 是保证一致性快照的关键,也是反压时的性能瓶颈
- Unaligned 用空间换时间 --- 将 in-flight 数据一并纳入快照,消除对齐等待,适用于高反压场景
- RocksDB 增量 Checkpoint 是大状态标配 --- 仅上传变化的 SST 文件,可将快照时间从分钟级降至秒级
- Checkpoint 完成才能触发 2PC Sink 提交 ---
notifyCheckpointComplete是端到端 Exactly-Once 的"最后一公里" - State TTL 是生产必选 --- 未设置 TTL 的 State 会无限增长,最终导致 Checkpoint 超时或 OOM
- Savepoint 是 Checkpoint 的超集 --- 格式兼容,但语义不同:Checkpoint 自动触发用于故障恢复;Savepoint 手动触发用于计划内运维
参考资料
- 官方文档:
nightlies.apache.org/flink/flink-docs-stable/docs/ops/state/checkpoints - Chandy-Lamport 论文:Distributed Snapshots: Determining Global States of Distributed Systems(1985)
- Flink FLIP-76:Unaligned Checkpoints
- Flink FLIP-158:Changelog State Backend
- Flink FLIP-344:Disaggregated State Storage(ForStDB,Flink 2.0)