1.LLM概述
LLM(Large Language Model,大语言模型)是指在海量无标注文本数据上进行预训练得到的大型语言模型。通过学习大规模语料中的语言规律,模型能够理解、生成和推理自然语言文本。
大语言模型的"大"主要体现在三个方面:一是参数量大,模型通常拥有数十亿到上万亿个参数;二是预训练数据量大,涵盖多语言、多领域的庞大语料;三是能力强大,具备跨任务的泛化与生成能力,能够在问答、摘要、翻译、编程等多种场景下展现出类似人类的语言理解和表达水平。
2.LLM发展历程
2.1GPT系列的发展演化
2.1.1概述
自 2018 年 GPT-1 发布以来,GPT 系列模型在 模型规模、训练数据、网络架构以及训练范式 等方面持续演进,不断推动语言模型的能力上限。
2.1.2GPT-1
概述
GPT-1(Generative Pre-trained Transformer-1)是 OpenAI 于 2018 年 6 月 发布的首个生成式预训练语言模型,其研究成果发表于论文《Improving Language Understanding by Generative Pre-Training》。
GPT-1 系统化地验证并推广了"预训练(Pre-training)+ 微调(Fine-tuning)"的训练范式:模型先在大规模无标注语料上进行语言建模预训练,再利用少量有监督数据在特定任务上微调。该方法显著提升了模型的迁移能力,使单一预训练模型能够适配多种自然语言任务。
架构
总体结构
GPT-1 采用了 Transformer Decoder-only 结构
具体结构如下图所示,整个模型可分为输入层、Transformer Block层与输出层三个部分:
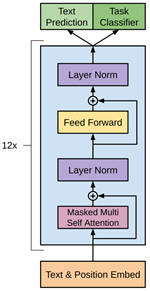
输入层(Text & Position Embedding)
将文本序列映射为词向量,并加入位置嵌入,用于表示词序信息。
Transformer Block
每个Transformer Block包含 Masked Multi-Head Self-Attention 和 Feed Forward Network 两个核心子层,并通过 LayerNorm 与残差连接保持稳定的梯度传播。
输出层
Text Prediction用于在预训练阶段输出下一个词的概率分布;Task Classifier用于在微调阶段适配下游任务。
架构创新
Decoder-only 结构
从 Encoder-Decoder 架构简化为Decoder-only 结构,以适配自回归生成任务。
可学习位置嵌入
使用可学习位置嵌入,取代正弦位置编码,使模型能够在训练过程中自适应地学习词序关系。
权重共享机制
输入嵌入层与输出词表权重共享,减少参数量并提升训练稳定性。
输入嵌入层(Input Embedding)
把文本 token 映射成 d_model 维向量,喂给 Transformer。参数量:Vocab Size × d_model
输出线性层(Output Linear / Unembedding)
把 Transformer 最后一层的隐藏向量,映射回词表维度,做下一个 token 预测。参数量:d_model × Vocab Size
本质:嵌入层的逆操作
主要参数
| 参数项 | 数值 |
|---|---|
| 模型层数(Layers) | 12 |
| 隐藏维度(Hidden Size) | 768 |
| 注意力头数(Attention Heads) | 12 |
| 前馈层维度(FFN Size) | 3072 |
| 参数总量 | 1.17 亿 |
训练
GPT-1 的训练采用了"预训练(Pre-training) + 微调(Fine-tuning)"的两阶段范式。
预训练阶段
在预训练阶段(Pre-training),使用高质量英文语料 BooksCorpus(约 7,000 本小说,约 8 亿词)作为训练数据,以"给定前文预测下一个词(Next-Token Prediction)"为目标,在长篇连续文本中捕捉句法结构、词汇共现和语义依赖等特征,从而获得通用的语言建模能力。这一阶段让模型具备了理解与生成自然语言的基础能力。
微调阶段
在微调阶段(Fine-tuning),通过在模型顶部加入轻量的任务分类层(Task Classifier),并在少量标注数据上进行有监督训练,模型能够快速适应不同任务场景。结果表明,微调后的 GPT-1 在多个 NLP 任务上显著优于从零训练的传统模型,验证了"预训练---微调"范式的有效性与通用性。
能力
尽管规模有限,GPT-1 已在自然语言理解与生成任务上展现出突破性成果。
在理解任务中,GPT-1 经过微调后在文本蕴含(NLI)、问答(QA)、语义相似度(STS)等多个基准测试中显著优于传统监督模型,证明了"预训练---微调"范式的有效性。
在生成任务中,GPT-1 能根据上下文生成语法合理、语义连贯的短文本,初步展现出 Transformer 架构在语言生成方面的潜力。
总体而言,GPT-1 的意义不在性能,而在范式:它首次验证了 Decoder-only 架构 与 预训练---微调模式的有效性,为后续 GPT 系列和整个大语言模型时代奠定了方法论基础。
2.1.3GPT-2
概述
GPT-2是 OpenAI 于 2019 年发布的第二代生成式预训练语言模型,相关研究发表于论文《Language Models are Unsupervised Multitask Learners》。
GPT-2 延续了GPT-1的 Transformer Decoder-only 架构,但参数规模提升了10倍。
GPT-2 首次证明了大型语言模型具备零样本(Zero-shot)任务泛化能力 。模型无需任何下游任务微调,仅凭自然语言提示(Prompt)即可完成问答、翻译、摘要等任务,标志着语言模型开始具备跨任务的通用智能特征。
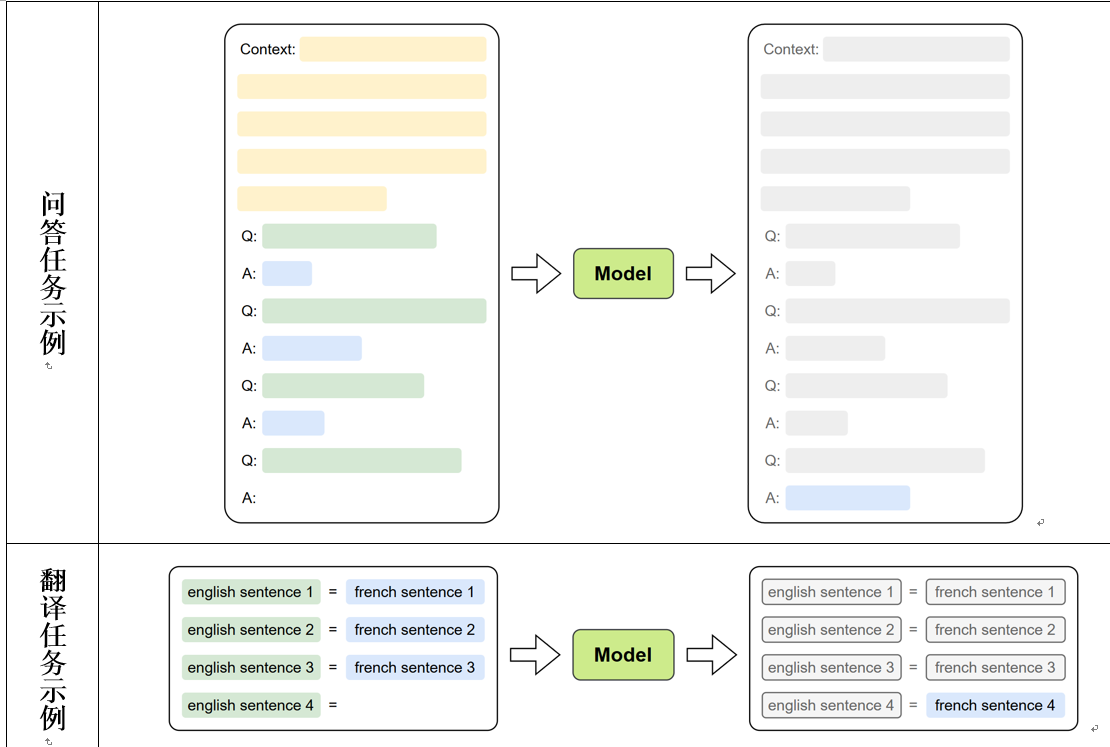
此外,GPT-2 的实验系统揭示了显著的规模效应(Scaling Effect) :随着模型参数与数据规模的增长,模型性能在多种任务上持续提升。这一发现奠定了后续超大规模模型(如 GPT-3 与 ChatGPT)的发展基础。
架构
总体架构
GPT-2 延续了 GPT-1 的 Transformer Decoder-only 架构。
架构创新
规模扩展
参数量相比 GPT-1 提升约十倍,最大模型达到 15.42 亿参数
LayerNorm
采用Pre-LayerNorm,缓解大模型训练中梯度不稳定问题。
主要参数
| 参数项 | 数值 |
|---|---|
| 模型层数(Layers) | 48 |
| 隐藏维度(Hidden Size) | 1600 |
| 注意力头数(Attention Heads) | 25 |
| 前馈层维度(FFN Size) | 6400 |
| 参数总量 | 15.42亿 |
训练
GPT-2 的训练仍采用 自回归语言建模(Autoregressive Language Modeling) 目标,即在给定前文的条件下预测下一个词(Next Token Prediction),以学习文本的语法与语义规律。
模型使用了 OpenAI 构建的 WebText 数据集,规模约 40GB ,包含约 800 万篇网页内容,涵盖新闻、小说、科技、娱乐、社交等多个领域,为模型提供了更广泛的语言风格与知识来源。
能力
GPT-2 的能力主要体现在两个方面:文本生成达到当时最优水平(SOTA),以及展现出早期的零样本(Zero-Shot)泛化能力。
在文本生成方面,GPT-2 能生成语法正确、语义连贯、上下文一致的长文本,语言自然流畅,几乎可以与人类创作相媲美。模型在多项语言建模基准测试中表现突出,在 8 个公开评测任务中有 7 个取得当时的最优成绩,全面刷新了语言模型在文本生成领域的性能上限。
在任务泛化方面,GPT-2 首次展现出零样本学习能力。模型无需针对特定任务进行微调,仅通过自然语言提示(Prompt)即可完成翻译、问答、摘要等多种任务,体现出初步的通用语言理解与迁移能力。但这种能力仍不稳定,在复杂推理和结构化任务中,与经过监督微调的专用模型相比仍存在明显差距。
2.1.4GPT-3
概述
GPT-3是 OpenAI 于 2020 年 5 月发布的第三代生成式预训练语言模型,研究成果发表于论文《Language Models are Few-Shot Learners》。
GPT-3 延续了 Transformer Decoder-only 架构,但参数规模较 GPT-2 提升约百倍,达到了1750亿。
GPT-3 的核心创新在于首次系统提出并验证了"上下文学习(In-Context Learning)" 的概念:模型在使用阶段无需额外训练,仅依靠输入文本中的任务描述及少量示例即可理解并完成任务,如下图所示。

GPT-3 的成功展示了大规模预训练模型在能力上的显著扩展,为后续更高层次的语言智能研究奠定了重要基础。
架构
总体结构
GPT-3 延续了 Transformer Decoder-only 架构。
架构创新
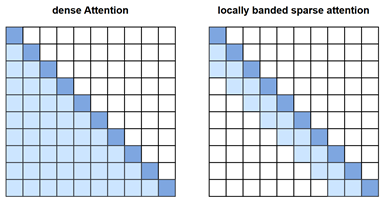
架构方面,与 GPT-2 相比,GPT-3 的主要区别在于在各个 Transformer Block 中交替使用稠密注意力(Dense Attention)和局部带状稀疏注意力(Locally Banded Sparse Attention)模式。
局部带状稀疏注意力是一种仅在局部窗口内计算注意力权重的稀疏化机制,能够显著降低时间和空间复杂度。通过稠密与稀疏注意力的交替使用,GPT-3 能够兼顾全局信息和计算效率。
主要参数
| 参数项 | 数值 |
|---|---|
| 模型层数(Layers) | 96 |
| 隐藏维度(Hidden Size) | 12288 |
| 注意力头数(Attention Heads) | 96 |
| 前馈层维度(FFN Size) | 49152 |
| 参数总量 | 1750 亿 |
训练
GPT-3 依旧采用 自回归语言建模(Autoregressive Language Modeling) 方式进行训练。
训练数据约 570GB,包含约3000亿token,覆盖新闻、百科、文学与学术等领域。
模型在数千块 NVIDIA V100 GPU 上进行分布式并行训练,耗时数周完成。
能力
GPT-3 在规模与训练深度上的突破,使其在语言理解与生成方面展现出前所未有的能力。
(1)语言生成能力
GPT-3 能生成 语法正确、语义连贯、风格自然 的长文本,常常难以与人类写作区分。
(2)上下文学习
模型无需微调,仅通过输入任务描述和少量示例,即可理解任务意图并生成正确输出。在一些测试中,GPT-3的表现接近甚至超过部分微调过的专用模型。
2.1.5InstructGPT
概述
InstructGPT 是 OpenAI 于 2022 年初推出的生成式预训练语言模型,是 GPT-3 的改进版本,也是后续 ChatGPT 的直接前身。其研究成果发表于论文《Training language models to follow instructions with human feedback》。
GPT-3 在自然语言生成方面取得了突破性进展,能够通过精心设计的提示词(Prompt)完成多种任务,但其生成结果并非总能令人满意,常常与用户的真实需求存在偏差,甚至会产生一些不真实、有害或无用的内容。
其根本原因在于,GPT-3 的训练目标仅是在大规模互联网文本上预测下一个单词,模型学习到的是语言的统计规律,而非如何理解和执行人类指令。换言之,模型尚未与人类意图保持一致(Alignment,对齐)。
为解决这一问题,InstructGPT 在 GPT-3 基础上引入指令对齐训练,从而使模型能够更准确地理解并执行人类指令。
架构
总体结构
InstructGPT延续了GPT-3的架构。
架构创新
InstructGPT并未在网络结构上进行新的改动。其主要创新点不在于模型设计,而在于训练范式的变革。
主要参数
| 参数项 | 数值 |
|---|---|
| 模型层数(Layers) | 96 |
| 隐藏维度(Hidden Size) | 12288 |
| 注意力头数(Attention Heads) | 96 |
| 前馈层维度(FFN Size) | 49152 |
| 参数总量 | 1750 亿 |
训练
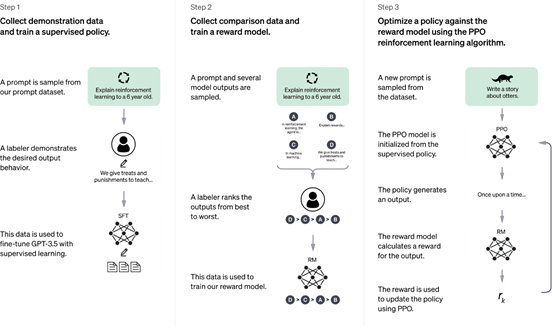
InstructGPT 的训练以GPT-3的预训练语言模型为基础,进一步采用了三阶段训练范式,具体步骤如下图所示:
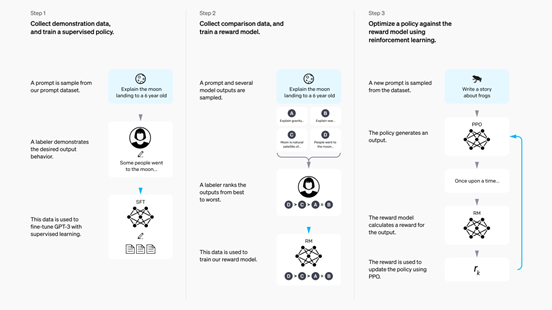
监督微调(Supervised Fine-tuning, SFT)
在第一阶段,OpenAI 收集了由人工标注者撰写的高质量 "指令-回答" 样本,组成训练数据集。这些样本覆盖常见的用户指令及对应的理想响应,具有较高的语言质量。
在训练过程中,模型在这些"指令-回答"对上进行监督微调,训练目标仍为"给定前文预测下一个词"(Next Token Prediction)。
通过该阶段,模型初步具备了理解并执行自然语言指令的能力,能够较好地完成指令驱动的任务响应。
奖励模型(Reward Model, RM)
第二阶段构建奖励模型,用于后续强化学习过程中的反馈评估器。
操作流程如下:
- 使用经过 SFT 微调后的模型,针对同一条指令生成多个候选回答;
- 人工标注者根据回答的质量、相关性、礼貌性、有用性等维度,对这些回答进行排序;
- 利用排序结果训练一个奖励模型,使其能够为任意给定回答输出一个偏好评分。
奖励模型的核心目标是模仿人类的偏好判断,为语言模型的输出提供方向性反馈。
强化学习(Reinforcement Learning from Human Feedback, RLHF)
这一阶段的核心目标是:通过人类偏好引导模型输出更加符合人类意图的回答。它以第二阶段训练好的奖励模型为评分工具,使用强化学习算法(PPO),对第一步经过SFT微调的语言模型进行进一步优化。
具体步骤如下:
指令输入
从预构建的指令数据集中选取一条指令,作为模型输入。
模型生成回答
使用经过SFT微调的模型对指令生成回答。
奖励模型评分
使用奖励模型对生成的回答进行打分。
强化学习优化
模型根据奖励模型打分的结果,调整自身参数,使其更倾向于生成高分回答。优化过程中使用了强化学习算法 PPO(Proximal Policy Optimization),目标是最大化奖励模型的评分。
经过这一阶段的训练,模型能够更准确地理解人类指令,并生成更符合人类偏好、更加真实、有用且安全的回答,从而显著提升了语言模型在实际应用中的表现能力。
能力
经过人类反馈强化学习(RLHF)阶段的训练,InstructGPT 相较于原始的 GPT-3,在多个维度上表现出更优的能力,主要体现在以下几个方面:
- 指令理解能力增强
InstructGPT 能够更准确地识别和执行自然语言中的任务指令,不再依赖复杂或特殊的提示设计,显著提升了模型对普通用户输入的响应能力。
- 输出质量更贴合人类偏好
得益于人类反馈训练,模型生成的回答在有用性、真实性、礼貌性和安全性等方面表现更好。实验结果表明,大多数用户更倾向于 InstructGPT 的回答,而非原始 GPT-3 所生成的内容。
- 无关、虚假或有害内容减少
InstructGPT 在生成过程中更容易规避与事实不符的内容、逻辑混乱的输出或潜在有害信息,提升了模型输出的稳健性与安全性。
- 泛化能力保持优秀
尽管进行了额外的指令对齐训练,InstructGPT 依然保持了 GPT-3 在多任务、多领域上的强泛化能力,能适应问答、写作、摘要、推理等多种场景。
以下是一些InstructGPT和GPT-3的输出对比示例:https://openai.com/zh-Hans-CN/index/instruction-following/ 。
2.1.6ChatGPT
概述
ChatGPT 是 OpenAI 于 2022 年 11 月发布的一种具备对话能力的大型语言模型。它支持连续的自然语言交互,能够回答后续问题、承认错误、质疑用户前提、拒绝不当请求,在用户体验与安全性方面取得显著改进。
架构
ChatGPT 是与 InstructGPT 同一技术路线下的兄弟模型,架构设计与 InstructGPT 类似,但具体细节未公开。
训练
ChatGPT 的训练方法采用与 InstructGPT 相同的人类反馈强化学习(RLHF)策略,其核心区别在于数据集的设计与处理方式。
ChatGPT 使用了特别构建的对话格式数据集。这些数据由标注人员通过模拟用户与 AI 助手的对话生成,内容更加贴近真实交互场景。相比 InstructGPT 所使用的"指令-单轮回答"数据,ChatGPT 所采用的数据具有多轮对话结构,强调上下文保持与连续问答能力。
此外,原有 InstructGPT 的数据也被统一转换为对话格式,与新收集的数据集成混合使用,以增强模型的对话泛化能力。整体数据处理流程重点在于适配对话场景,提升模型的多轮交互表现。
能力
ChatGPT 具备以下关键能力:
连贯对话:能理解上下文并进行多轮交互;
错误应对:可承认自身错误并尝试修正;
逻辑判断:能够识别并质疑错误前提;
安全防护:对不当请求具备拒绝能力。
这些能力使 ChatGPT 在任务执行、语言理解和用户交互方面均展现出较强的综合表现。
总结
GPT 系列的发展推动了现代大语言模型训练范式的逐步成熟,形成了以 "预训练---监督微调---对齐" 为核心的三阶段开发框架。如下:
- 预训练(Pre-training)
基于超大规模无标注语料进行自监督学习,使模型获得通用语言建模能力、广泛的世界知识以及基本的推理与泛化能力。 - 监督微调(Supervised Fine-tuning, SFT)
利用人工构建的指令---响应示例或高质量对话数据对模型进行进一步训练,使其能够更好地理解指令,并输出更加规范、稳定且贴合任务需求的内容。 - 对齐(Alignment)
通过引入人类偏好、行为规范、安全约束与价值观等因素,使模型的行为更符合用户期望。对齐方式包括RLHF(奖励模型 + 强化学习)以及DPO、ORPO、KTO 等无需强化学习的偏好优化方法。对齐阶段的目标是让模型在真实应用场景中表现得更有帮助、更安全、更可靠。
这一"三阶段"开发范式在实践中得到广泛验证,已成为业界主流的大语言模型训练框架。
2.2全球主流LLM体系纵览
2.2.1概述
自ChatGPT 问世以来,全球大语言模型快速进入爆发期,各种模型体系相继涌现,形成了多路线并行发展的"百花齐放"格局。不同模型在推理能力、多模态融合、中文理解、长文本处理、开源生态与成本效率等方面各具特色,共同推动了 LLM 技术的持续演进。
2.2.2主流LLM体系
主流的LLM体系如下表所示:
| 模型体系 | 公司/机构 | 开放策略 |
|---|---|---|
| GPT 系列 | OpenAI | 闭源,主要通过API 接口提供商业服务。 |
| Gemini 系列 | Google DeepMind | 核心模型闭源,但开放部分模型如 Gemma 系列,同时提供强大的 API 服务。 |
| Claude 系列 | Anthropic | 闭源,主要通过 API 接口提供商业服务。 |
| Grok 系列 | x AI | 核心模型闭源,部分模型已开源,要通过 API 接口提供商业服务。 |
| DeepSeek 系列 | DeepSeek | 开源,提供模型权重和代码,并同时提供 API 接口服务。 |
| Qwen 系列 | 阿里巴巴 | 开源,提供绝大部分模型权重和代码,并同时提供 API 接口服务。 |
| Kimi | Moonshot AI | 闭源,通过 API 接口提供服务。 |
| GLM 系列 | 智谱 AI | 核心模型闭源,部分版本已开源,同时提供 API 服务。 |
| Llama 系列 | Meta | 开源,提供模型权重和代码。 |
2.2.3常用LLM 榜单
- LMArena
LMArena 是由加州大学伯克利分校团队创建的一个开放平台,用户可以方便地体验并对比各类主流大模型。平台通过让用户对模型回答进行投票,形成公开排行榜,让大模型能力的差异和进步更加直观、透明,也更贴近真实使用场景。作为一种群众驱动的评测机制,LMArena 已成为当前了解前沿大模型表现的重要参考平台之一。
网址:https://lmarena.ai/leaderboard
- 司南
司南是中国国内由上海人工智能实验室发起的"大模型评测体系",旨在为大语言模型、多模态模型等提供全栈、可复现、开放的评测工具、基准与榜单。
网址:https://opencompass.org.cn/home
3LLM架构
3.1LLM基础架构
大型语言模型(LLM)大多基于 Transformer 架构构建,其中最常见的是 Decoder-only 架构。这一架构最早由 GPT 系列采用,并逐渐成为当前大多数主流模型的标准设计。LLM 的核心能力------理解语言、建模上下文、生成文本,都源于 Transformer 的模块化结构与高度可扩展性。
从整体上看,一个典型的 LLM 可以分为 输入层、Transformer Block 堆叠层和输出层 三个部分,如下所述。
3.1.1输入层
输入层负责将原始文本序列转化为模型可处理的向量表示。文本首先经过分词处理,每个 token 会被映射为对应的词向量(Token Embedding),形成模型的基础语义空间。为了使模型能够感知序列顺序,还需要加入位置编码(Position Encoding)。输入层的作用是为后续 Transformer Block 提供初始的语义与位置信息。
3.1.2Transformer Block
Transformer Block 是大型语言模型的核心计算单元,通常由几十到上百层堆叠而成。每个 Block 内部主要包含自注意力机制和前馈网络两部分:自注意力机制使模型能够在处理当前 token 时参考序列中其他位置的语义信息,从而捕捉长距离依赖关系;前馈网络则对注意力输出进行非线性变换,提高模型的表达能力。为了确保深层结构的训练稳定性,Transformer Block 内部普遍采用残差连接与归一化技术,使梯度能够顺畅传播。大量堆叠的 Block 共同构成了 LLM 的主体结构,是模型理解语言和推理能力的来源。
3.1.3输出层
输出层用于将 Transformer Block 最终生成的隐含向量映射为词表中的概率分布,从而执行下一个 token 的预测。典型做法是使用一个线性投影层将向量映射到词表维度,并通过 Softmax 得到每个 token 的概率。现代模型通常采用输入词向量与输出投影层权重共享的方式,以减少参数规模并提升训练效果。输出层的结果被用于自回归生成,每次输出一个 token 并将其作为下一步的输入,使模型能够逐步生成连贯自然的文本。
3.2LLM架构演进
3.2.1概述
自 ChatGPT 问世以来,各类大语言模型不断涌现,但其主体架构仍然基于 Transformer 的解码器,整体结构并未发生革命性变化。
模型真正的演进主要体现在内部组件层面,包括注意力机制、前馈网络、归一化与残差结构以及位置编码等模块的持续改进。
下面介绍各个组件的改进方向。
3.2.2Attention
概述
注意力机制(Attention)是 Transformer 中最核心的模块,用于刻画序列中不同位置之间的依赖关系,决定模型在生成下一个 token 时应如何利用上下文。其能力直接影响模型的语义理解、长程依赖建模与文本生成质量。
随着模型规模不断扩大、推理序列越来越长,传统的多头注意力的问题逐渐暴露出来。为了解决这些问题,业界提出了一系列改进结构,在保持模型能力的同时显著提升了推理效率。
MHA(Multi-Head Attention)
MHA是Transformer最初采用的注意力机制,其通过将输入分别映射为多组 Query、Key、Value,并在多个注意力头上并行计算注意力分布,使模型能够从不同子空间捕捉序列关系,从而提升表达能力。
尽管 MHA 在早期模型中表现良好,但随着模型规模不断扩大,其结构逐渐暴露出明显的工程瓶颈。要理解 MHA 的限制,需要先明确推理阶段的一个关键概念------KV Cache。
在自回归生成过程中,模型需要逐 token 地生成输出。对于每一个新 token,模型都会与所有历史 token 进行注意力计算。如果每一步都从头计算历史序列的 Key 和 Value,这将造成巨大的重复计算开销,如下图所示:
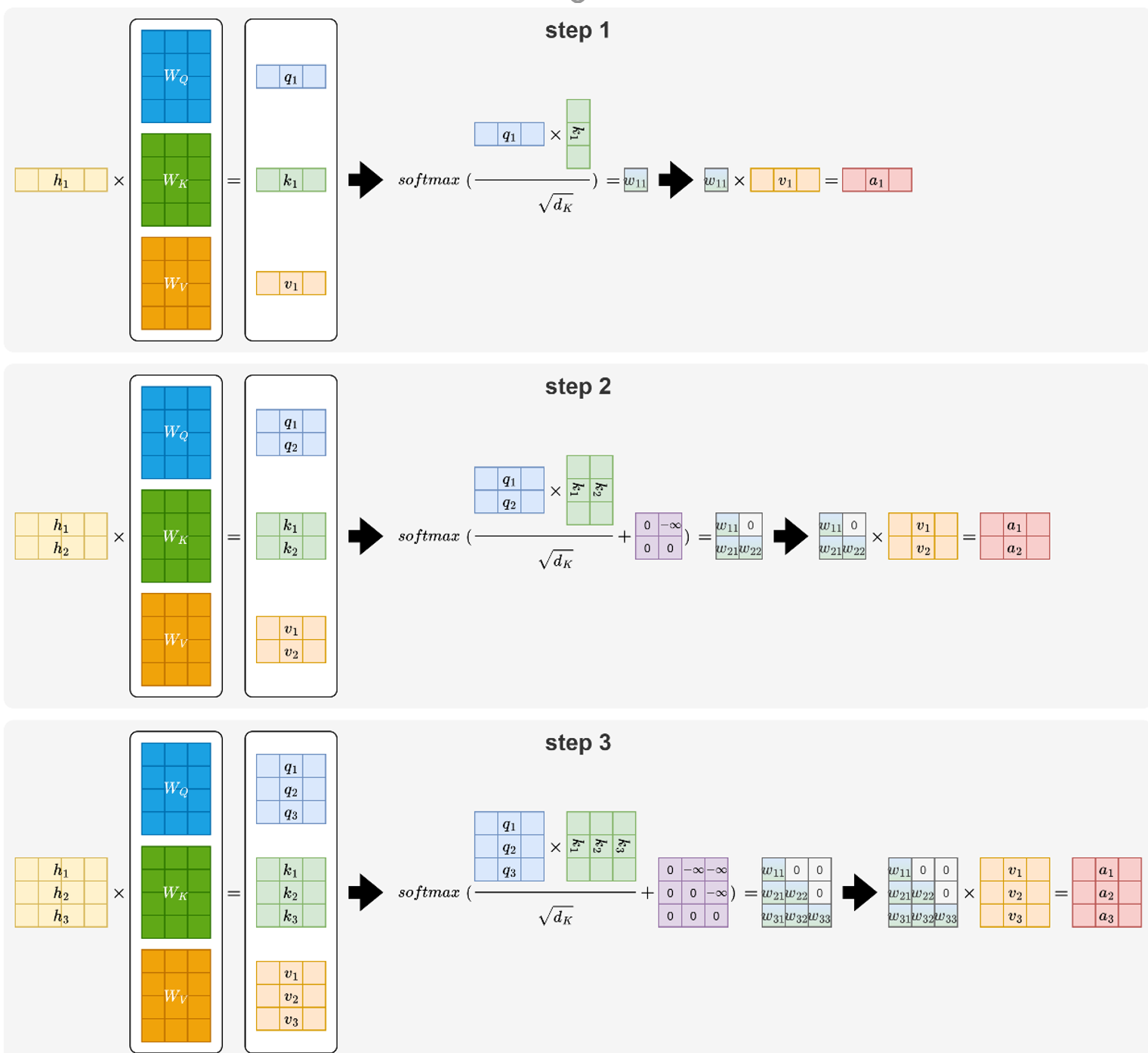
为了避免这种重复计算,模型都会在推理阶段将历史 token 的 Key 和 Value 缓存下来,供后续步骤直接使用。这一机制就是 KV Cache。通过缓存 K/V,模型在生成下一个 token 时只需计算当前 token 的 Q、K、V,再与缓存的 K/V 做一次注意力匹配即可,大幅减少了不必要的计算量,如下图所示:
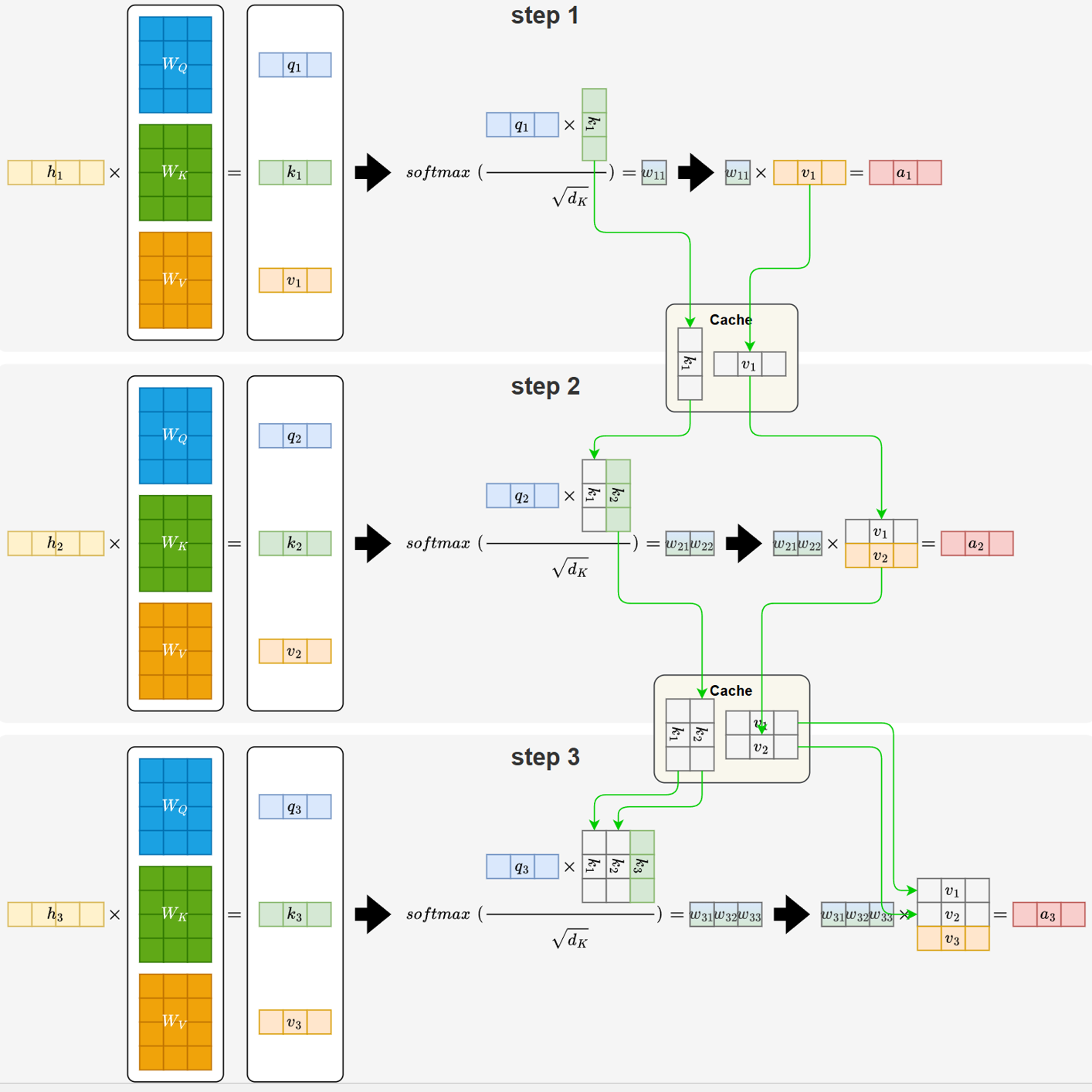
KV Cache 的引入,虽然减少了重复计算,但需要持续保存过往 token 的 Key 和 Value。随着序列变长、模型层数增加,缓存量本身就会不断累积。并且在多头注意力(MHA)中,每个注意力头都会独立生成并存储一组 Key 和 Value,使得缓存规模在原有基础上进一步放大。这也构成了 MHA 在大模型推理中的主要问题。
MQA(Multi-Query Attention)
MQA(Multi-Query Attention,多查询注意力)是一种优化注意力机制的方案,旨在减少推理阶段 KV Cache 的存储与内存带宽开销。由Google于 2019 年 11 月发表在论文《Fast Transformer Decoding: One Write-Head is All You Need》。
MQA 的核心思想是让多个注意力头共享同一套 Key 和 Value,而不是像传统 MHA 那样为每个头分别维护独立的 K/V。如下图所示:
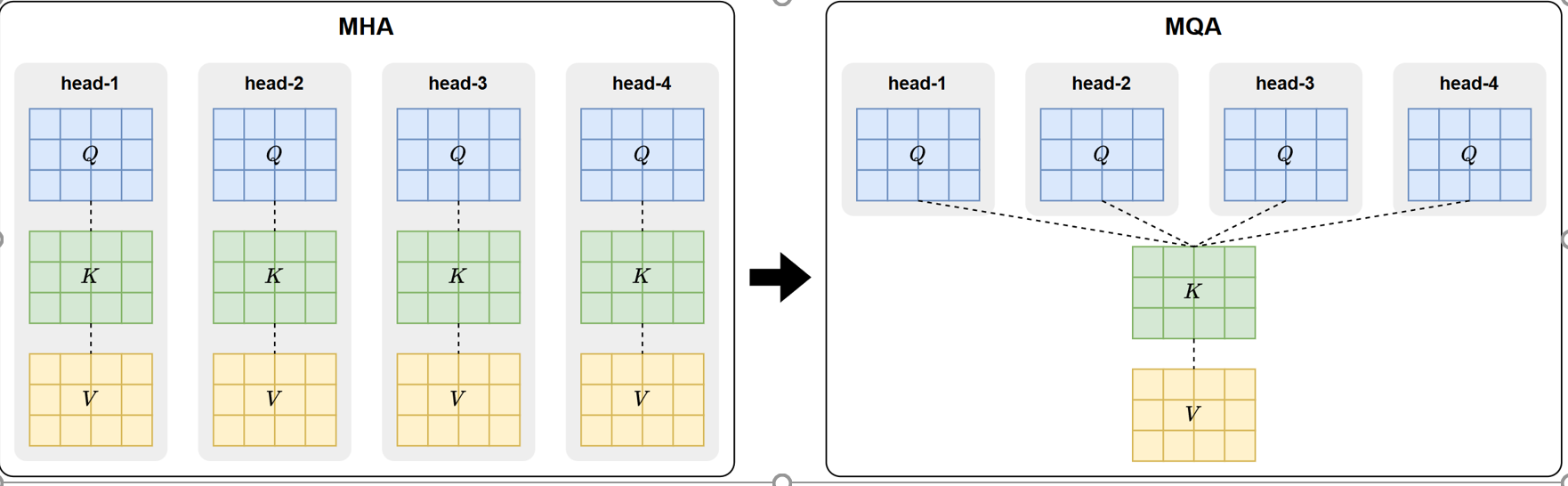
这种共享方式大幅减少了需要缓存和读取的 K/V 张量量级,显著降低存储需求与内存带宽压力,从而大幅提升了推理速度。
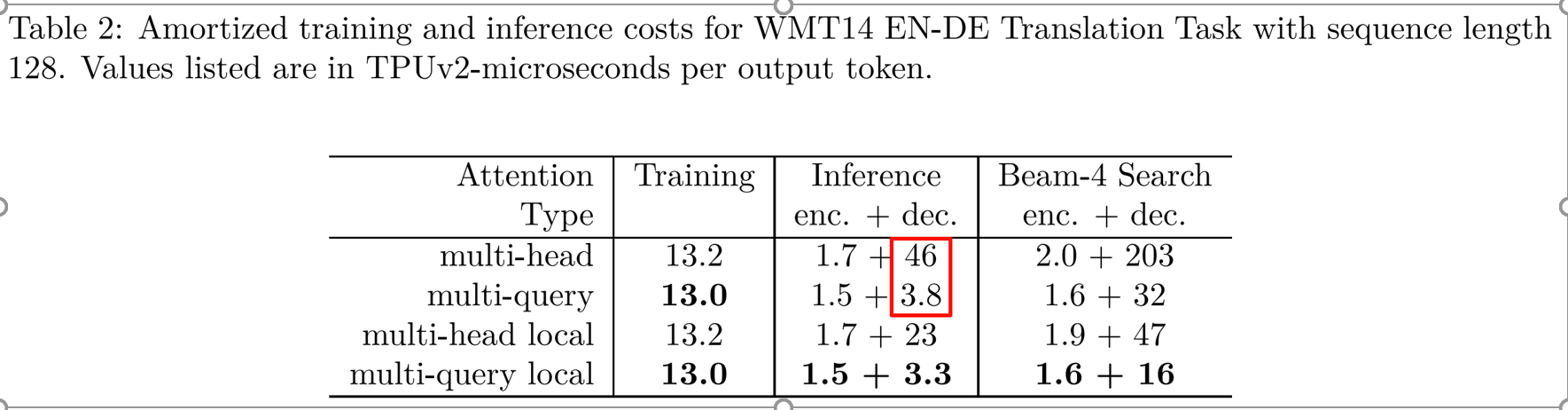
但这种共享机制会略微削弱注意力头的表达能力,使其精度略逊于传统 MHA,但整体损失非常小。
总体来看,MQA 以极小的精度代价换来了巨大的推理效率提升,是现代大模型推理加速的重要基础结构之一。
GQA(Group-Query Attention)
GQA(Group-Query Attention,分组查询注意力)是在 MQA 基础上的进一步改进方案,由 Google 在论文 《GQA: Training Generalized Multi-Query Transformer Layers》中提出。该方法旨在在提升推理效率的同时,弥补 MQA 由于所有注意力头共享同一套 K/V 而造成的表达能力下降问题。
GQA 的核心思想是:将注意力头划分为多个组(Group),每组内部的多个 Query 共享同一套 Key 和 Value,而不同组之间则使用独立的 K/V ,如下图所示:
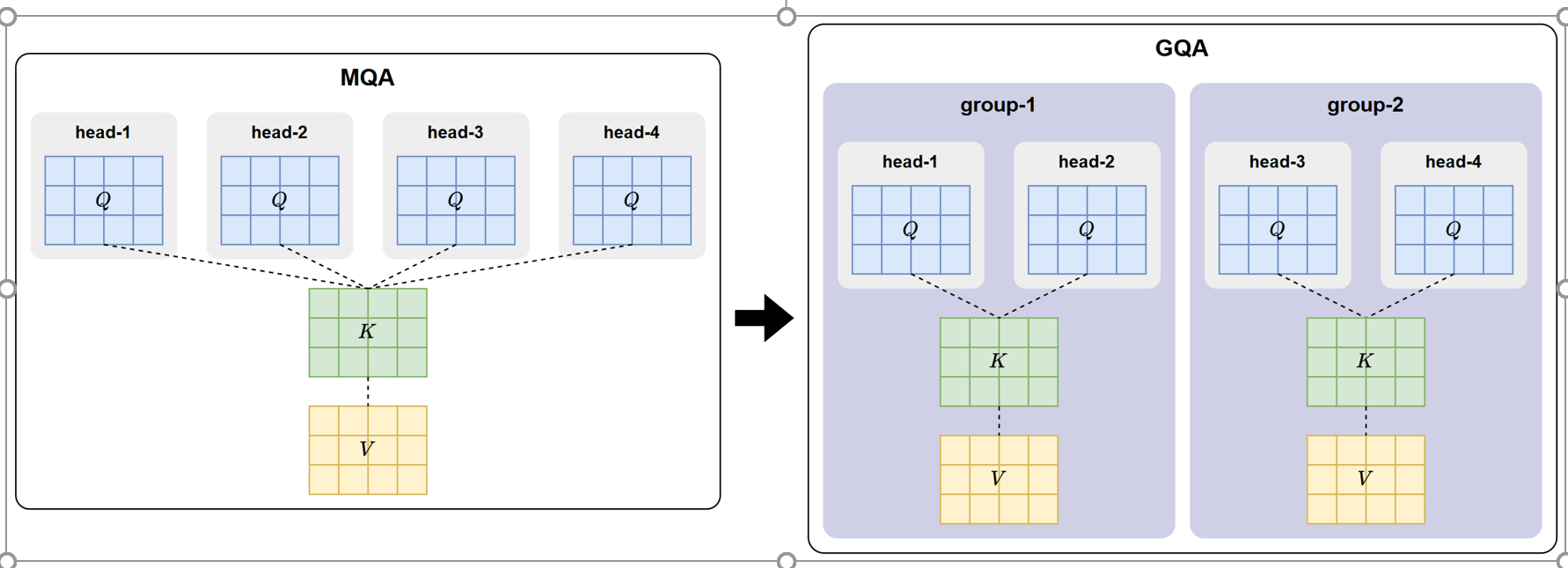
这种结构本质上在 MHA 与 MQA 之间取得了折中:
- 相比 MHA:不再为每个头维护独立 K/V,从而大幅减少 KV Cache 的存储需求与内存带宽压力;
- 相比 MQA:不再所有头共享唯一 K/V,而是分组共享,使注意力头间仍能保持更高的多样性和表达能力。
因此,GQA 在 推理效率 和 表达能力 之间实现了更优平衡。实际应用中,它比 MQA 能更好地处理复杂语义关系,同时仍保持较高的推理速度。
总体来看,GQA 在仅增加极小计算与存储成本的前提下,显著增强了模型能力,因此被LLaMA、Qwen 等主流大模型所采用,在长序列推理和高并发场景中表现极为出色。
MLA(Multi-Head Latent Attention)
MLA(Multi-Head Latent Attention) 由DeepSeek 团队于2024年6月在论文《DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model》中提出,MLA 旨在化解 MQA 与 GQA 在提升效率时出现的性能损失,实现能力与效率的协同优化。
MLA的核心思想是不再直接缓存多头 K/V,而是先把它们压缩到一个共享的低维"潜在向量"里,只缓存这个低维向量,再在需要算注意力时从中恢复出各头的 K/V。如下图所示:
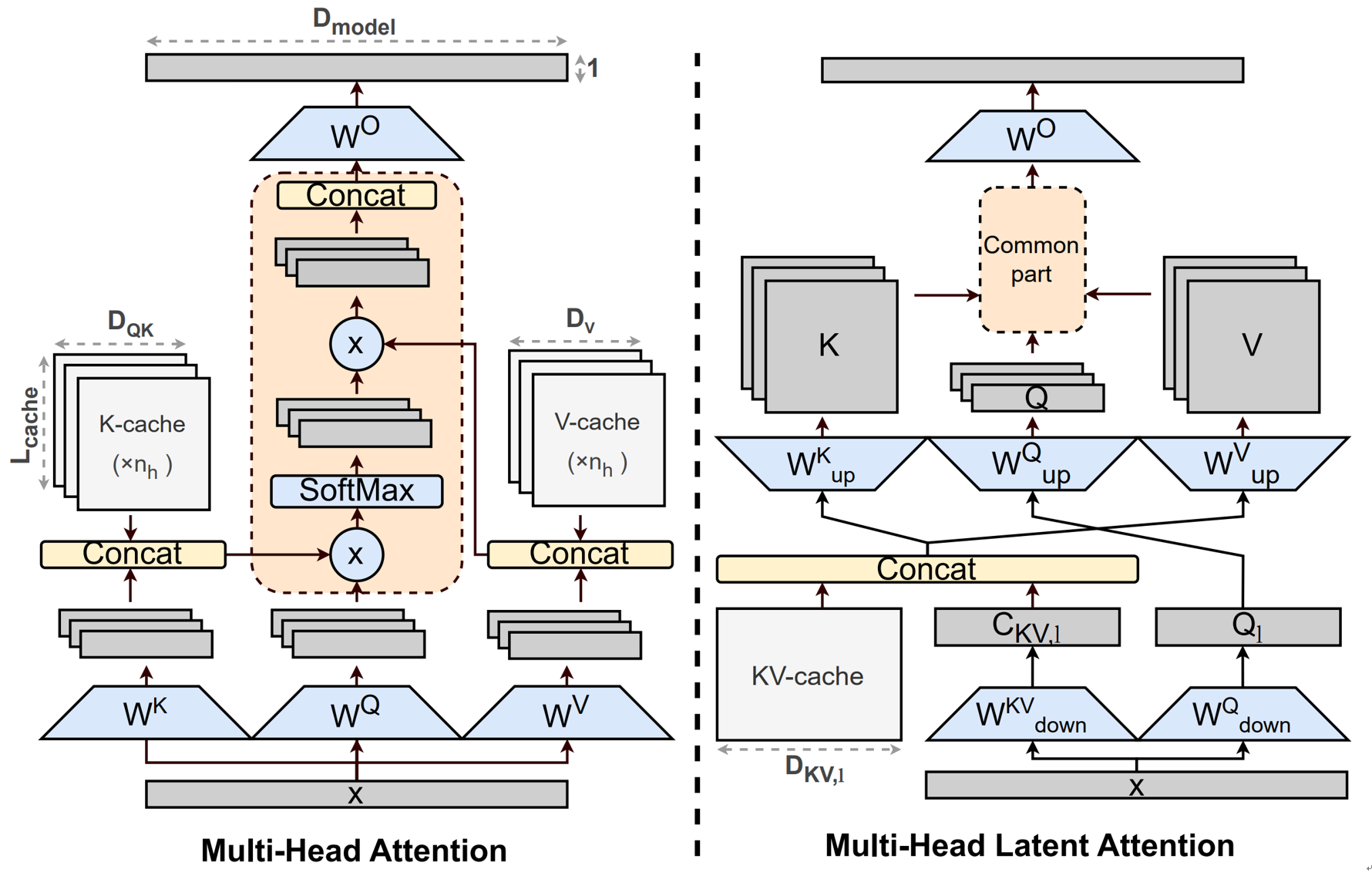
凭借这种结构,MLA 能显著减少推理阶段的 KV Cache,同时保持多头注意力的表达多样性。下表展示了 MLA 与传统 MHA 在多个基准测试上的对比结果,可以看到,在 KV Cache 大幅减少的情况下,MLA 的表现与 MHA 持平,甚至更高。
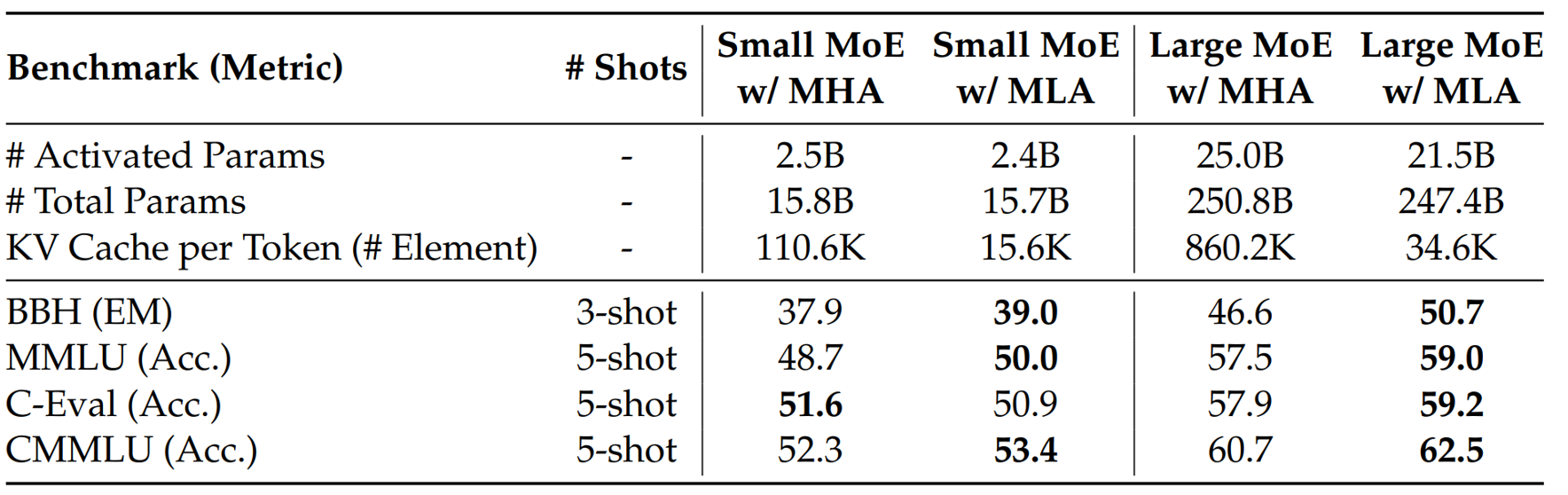
结合实验结果可以看出,MLA 在推理效率与模型性能之间取得了良好平衡,是当前高效注意力结构的重要设计之一。
3.2.3Feed Forward Network
概述
前馈网络(FFN)是 Transformer Block 中继注意力之后的第二大核心组件,用于对 token 表示进行独立的非线性变换。其典型的"升维 → 激活 → 降维"结构,使模型能够在每个位置上学习高维特征,是 Transformer 表达能力的重要来源。
FFN 的演进主要集中在激活函数 和整体结构形式两个方向。
激活函数
激活函数为 FFN 引入非线性,是提升模型表达能力与稳定性的关键模块。随着模型规模不断扩大,激活函数在设计上经历了从简单线性截断到平滑非线性,再到具备门控能力的结构化形式的演进。
ReLU
ReLU(Rectified Linear Unit)是深度学习中最早广泛应用的激活函数之一,其定义非常简单:
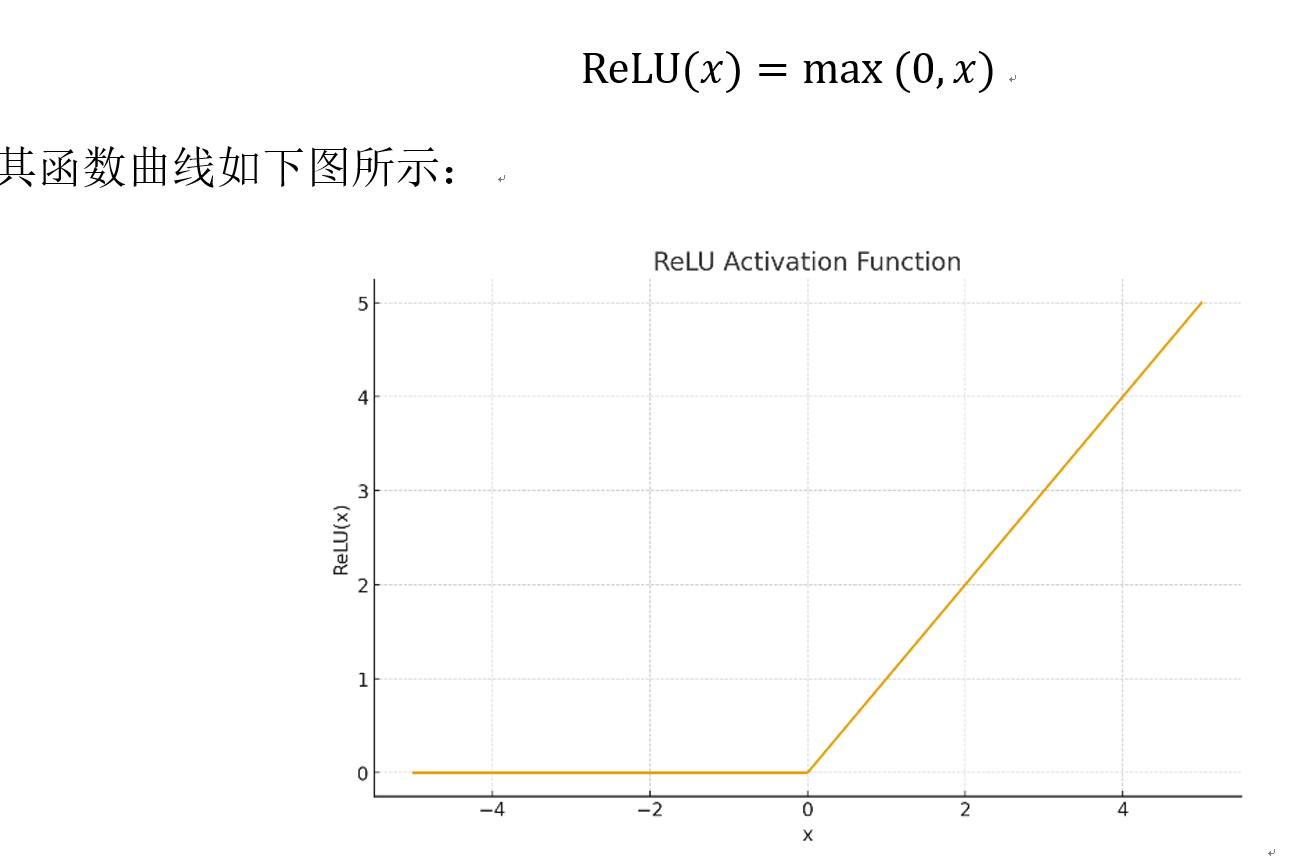
ReLU 在正区间保持恒定梯度,使梯度能够高效传播,大大缓解了早期网络中的梯度消失问题,因而在浅层或中等规模神经网络中表现优异。然而,ReLU 对负区间进行"硬截断",会导致梯度完全为零,从而引发"死亡神经元"现象 ,即神经元在训练过程中一旦进入负区间可能永久失活;此外,其非线性较弱,在深层 Transformer 中无法提供足够的梯度平滑性与稳定性,容易造成训练不稳定。
GELU
GELU(Gaussian Error Linear Unit)是早期Transformer预训练模型(例如Bert、GPT-2/3)中曾广泛采用的平滑非线性激活函数。
GELU的核心思想是:不再进行硬性截断,而是通过一种 随输入大小平滑变化的缩放系数 来柔性控制激活强度,使得输入在负区间、中间区间、正区间分别呈现自然的衰减、过渡与放大。
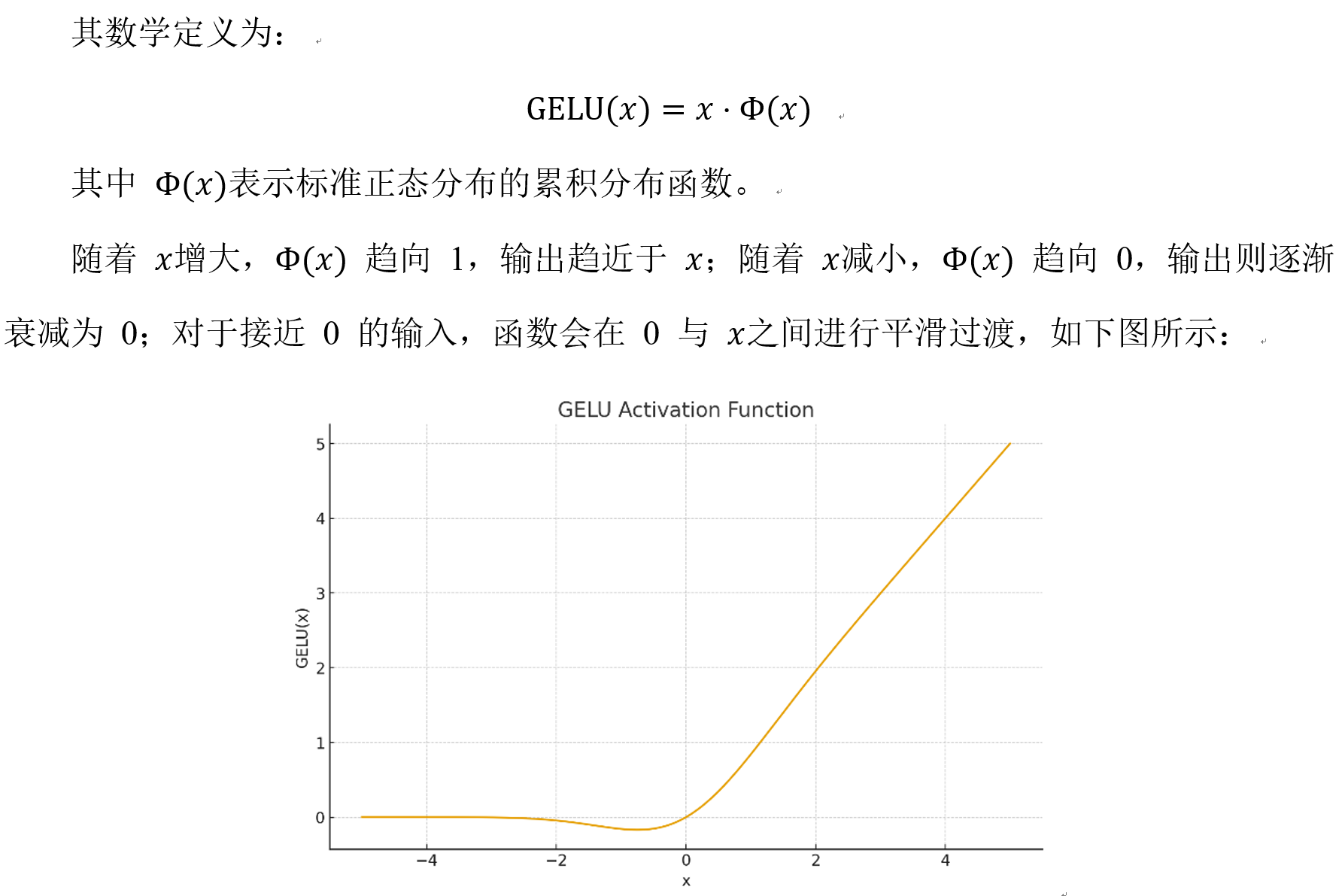
相比 ReLU,GELU 在全域连续可导,能在深层网络中提供更稳定的梯度传播,且不会出现 "神经元死亡"问题,因此曾在中大型 Transformer 中一度成为主流。
SiLU
SiLU(Sigmoid Linear Unit)也是一种连续可导的激活函数,其基本思想是使用 sigmoid 函数对线性输入进行加权,从而得到一种柔和的非线性变换。
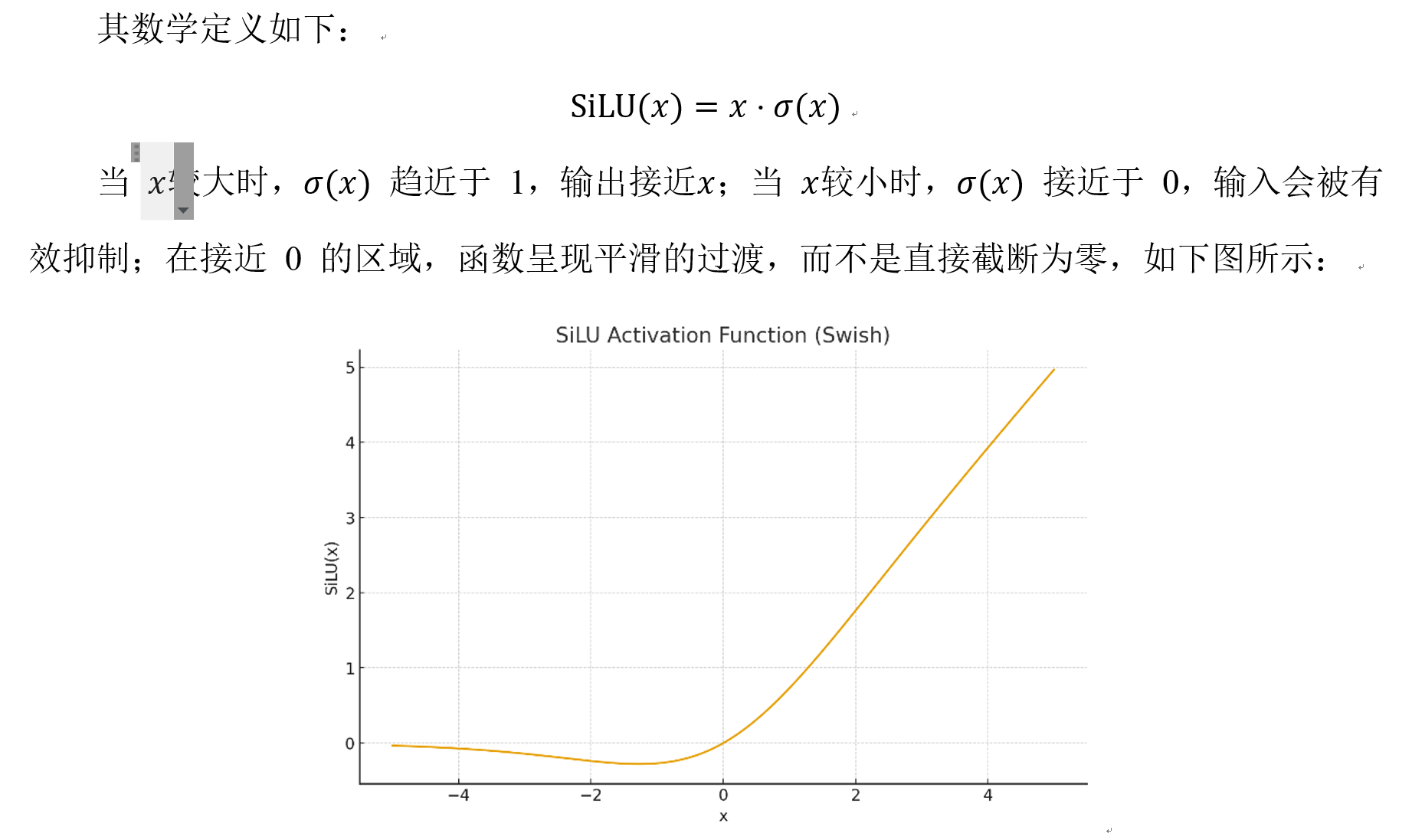
得益于这种连续可导的结构,SiLU 在深层网络训练中同样具有良好的优化稳定性,并在多个任务中表现出与 GELU 相近的经验性能。
Swish
Swish 可视为 SiLU 的一般化形式,其数学定义为:
"Swish"(x)=x⋅σ(βx)
其中 β可以是固定或可学习参数。当 β=1时,Swish 与 SiLU 完全等价。尽管原论文提出让 β可学习,但实际收益有限,并可能带来训练不稳定性,因此主流实现通常将 β固定为 1。
基于这一等价关系,在工程实践中 Swish 与 SiLU 往往混用,不作严格区分。
GLU及其变体
GLU(Gated Linear Unit)及其一系列变体是当前大型语言模型(LLM)中最常用的 FFN 激活结构。与传统 ReLU、GELU 等单路激活不同,GLU 类结构采用 "主分支 × 门控分支" 的双分支设计,通过引入门控机制,使模型能够对信息流进行更加细致的筛选与调控。如下图所示:
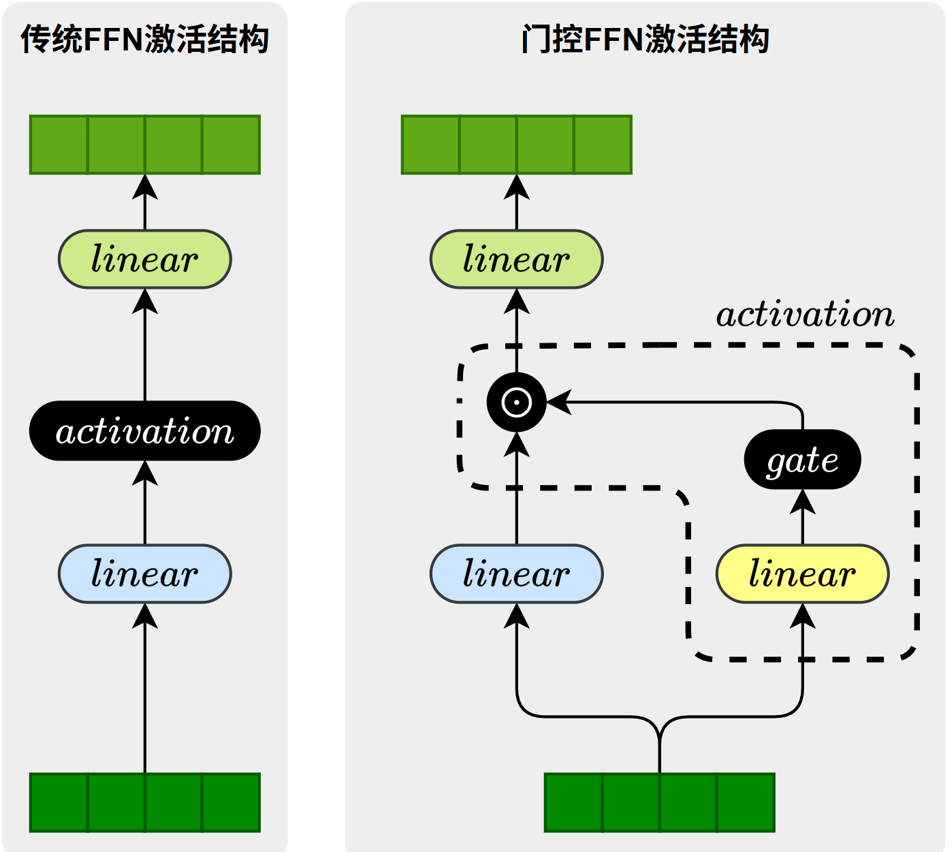
门控结构的关键区别在于 门控分支所采用的门控函数。不同的函数会导致门控行为、梯度特性和最终模型性能的差异,因此形成了多种 GLU 变体。常见的门控结构包括
- GLU:使用 Sigmoid 作为门控函数
- GEGLU:使用GELU作为门控函数
- SwiGLU:使用SiLU作为门控函数
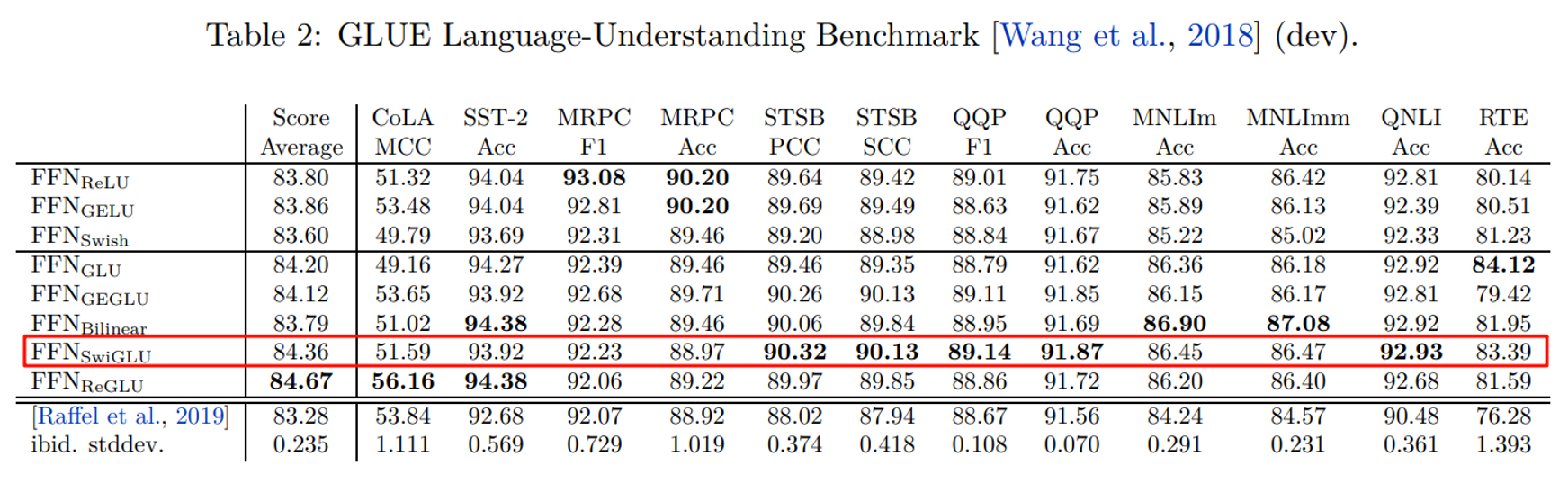
在众多变体中,SwiGLU在性能与训练稳定性方面表现最优,因此成为当前主流 LLM(LLaMA、Qwen、DeepSeek 等)的默认门控结构。
MoE
概述
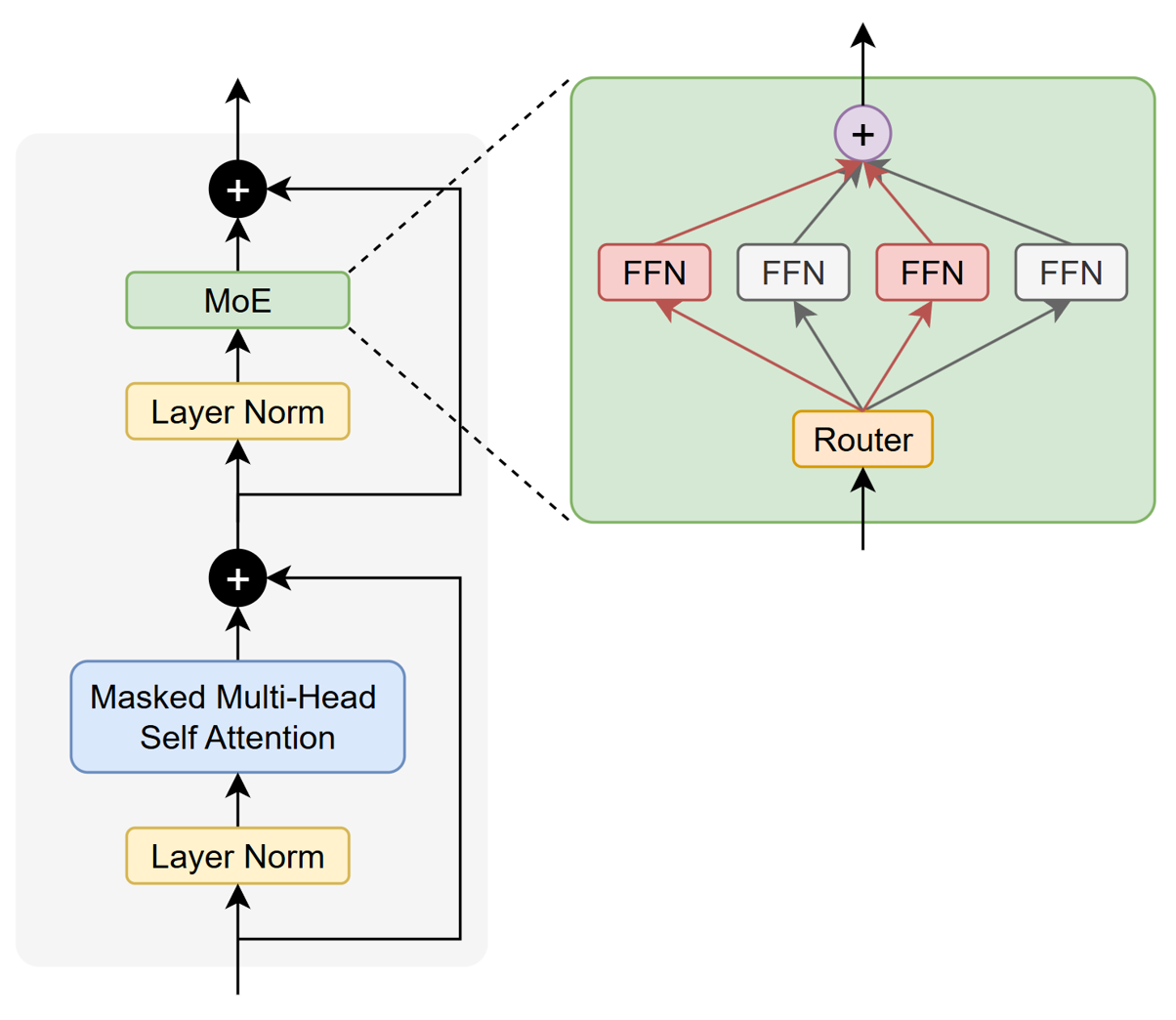
MoE(Mixture of Experts,混合专家模型)是在传统 FeedForward 模块基础上的一种结构扩展。其核心思想是:使用多个并行的 FeedForward 专家替代单一的 FeedForward 层,并通过 Router(路由器)根据输入 Token 的特征选择其中少量最合适的专家参与计算。这样一来,不同类型的输入能够由擅长处理该类模式的专家负责,从而显著增强模型的表达能力与适应性。MoE 已成为当前主流大语言模型(LLM)中广泛采用的、用于提升性能与效率的关键结构之一。
工作流程
MoE的工作流程如下图所示:
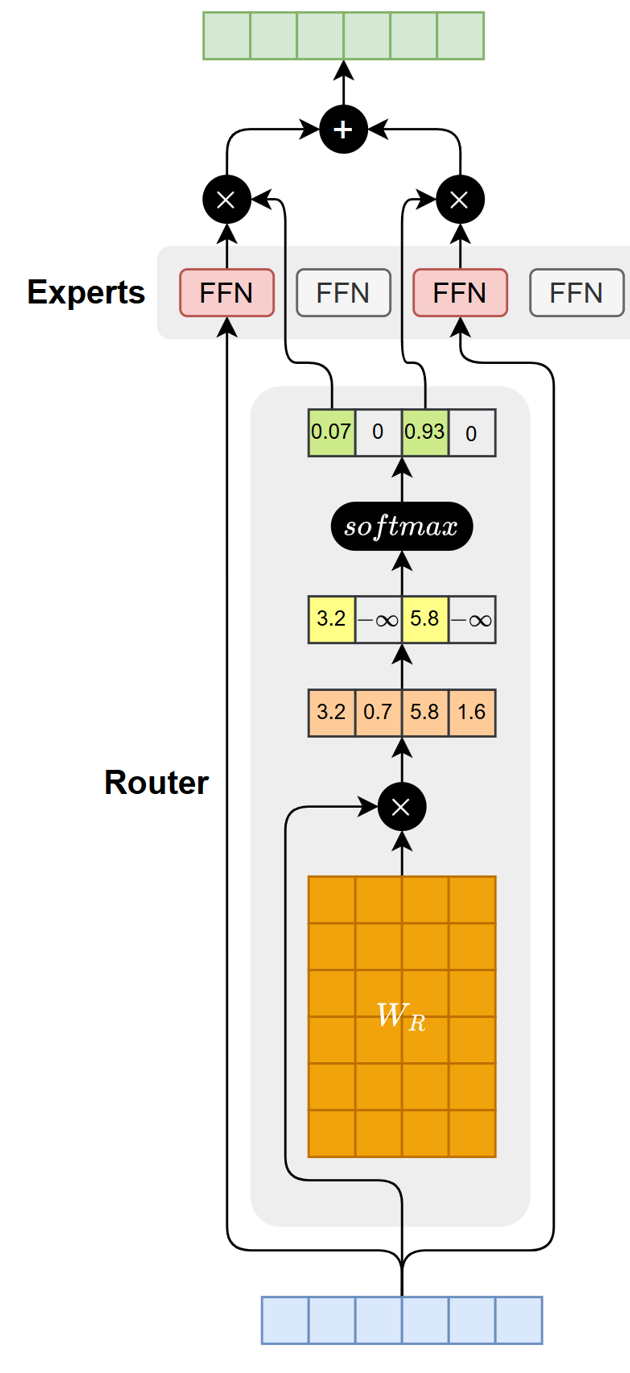
具体步骤如下:
路由得分计算
Router 接收 Token 的隐藏表示,并通过线性映射为所有专家生成一组得分。
选择 Top-k 专家
从得分中选取得分最高的 k 个专家,其余专家在本次计算中不参与处理。
计算路由权重
对被选中的专家得分执行 softmax,得到归一化权重,用于表示各专家在最终输出中的贡献比例。
专家执行前向计算
被激活的专家分别对输入 Token 进行独立计算,生成各自的输出。
加权合并输出
将所有激活专家的输出按照路由权重加权求和,得到 Token 在 MoE 层的最终表示。
能力与优势
MoE 结构通过引入稀疏激活机制,显著提升了模型的能力和效率,主要具备以下三个核心优势:
高容量、低计算的效率结构
MoE 模型通过稀疏激活 机制,使每次前向传播仅有少数个专家参与计算。这种设计在不增加实际计算量的前提下,大幅提升了模型的总参数量(模型容量),实现了高效的"高容量、低计算"结构。
专家分工协作,提升泛化与适应性
通过路由器(Router)机制的动态分配,不同的输入 Token 会被导向最适合处理它们的专家。这种机制促使专家自动形成功能分化 ,每个专家专注于学习特定的模式或数据子集,从而显著增强了模型的表达能力和泛化性能。
天然适合大规模分布式扩展
MoE 结构中的专家模块是相互独立的,这使得专家可以轻松地分布到大规模计算集群的不同设备上并行运行,极大地提升了模型的可扩展性(Scalability)和在大规模环境下的训练与推理效率。
3.2.4残差连接与归一化
概述
残差结构与归一化机制是 Transformer 稳定训练的基础。随着模型深度与规模增加,传统的结构逐渐暴露出梯度路径不稳定的问题。近年来,研究者通过一系列优化改进手段,使模型能够在更高深度、更大参数规模下保持稳定训练。
RMSNorm
RMSNorm(Root Mean Square Normalization,均方根归一化) 是对传统 LayerNorm 的一种简化变体。它去除了均值标准化操作,仅基于输入特征的均方根(RMS)进行缩放,从而在保持归一化效果的同时降低计算复杂度。实践表明,均值项在深层 Transformer 中对稳定性贡献有限,因此去除均值不会影响模型性能,反而带来更稳定、更高效的归一化形式。目前,RMSNorm 已成为主流 LLM 中最常用的归一化方式。


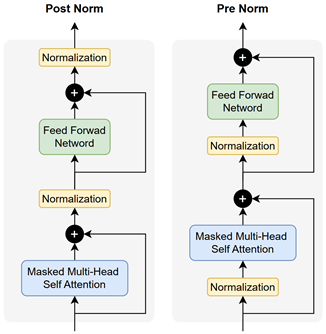
归一化放置位置
在 Transformer 中,归一化层的放置位置会显著影响训练稳定性、梯度传播效率以及模型在更大深度和规模下的可扩展性。随着架构不断演进,研究者在实践中提出了多种归一化布置方式,通过在残差路径内部或模块内部调整 Norm 的位置,以获得更好的数值特性与训练表现。
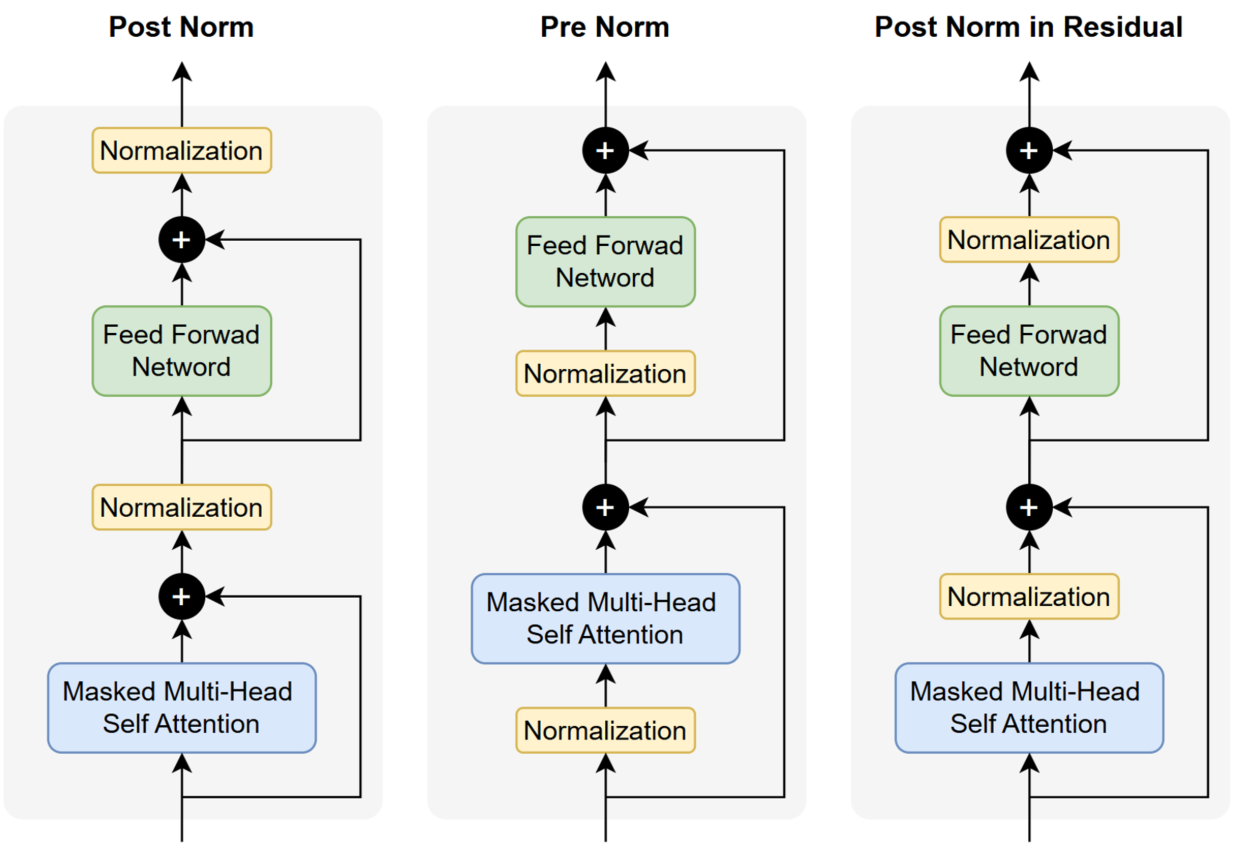
Post Norm
Post Norm 是 Transformer 中最初采用的归一化放置方式,其结构是在子层(如 Self-Attention 或 FFN)计算完成并与残差相加之后,再对结果进行归一化处理
y=Norm(x+F(x))
Post Norm 存在一个核心问题:**它会削弱残差连接中用于稳定训练的那条恒等梯度通道,从而在深层网络中导致梯度回传不稳定。**要理解这一点,需要先回顾残差连接的梯度传播机制。

由于归一化操作会对输入进行缩放、标准化等处理,梯度在回流时也会被相应扰动,使原本应保持恒等的梯度路径不再保持为 1,从而削弱了残差连接提供的稳定梯度通道。
在深层 Transformer 中,这种梯度扰动会层层累积,使训练更加不稳定。因此,Post Norm 在现代大规模模型中已基本不再使用。
Pre Norm
Pre Norm 是大多数大语言模型中采用的主流归一化方式。其结构是在进入子层(如 Self-Attention 或 FFN)之前先对输入进行归一化,然后再执行子模块计算并与残差相加:

正因如此,Pre Norm 在现代 LLM 中成为了事实上的标准结构,被广泛采用。
Post Norm in Residual
Post Norm in Residual 是近年来在部分模型中出现的一种归一化放置方式。与传统 Post Norm 的相比,它依然将归一化作用在子层输出之后,但归一化的位置被移动到残差路径内部:

这种方式同样能够提供一条恒等梯度路径:
3.2.5位置编码
概述
由于 Transformer 的自注意力机制(Self-Attention)并不包含序列顺序信息,模型无法仅依靠注意力计算来判断 token 在序列中的相对位置。因此,需要向输入中显式加入位置编码(Position Encoding),以补充序列的位置信息。
随着模型规模扩大与任务需求多样化,位置编码的设计也在不断演进,以适应更长的上下文、更灵活的序列建模方式以及更稳定的训练特性。
正余弦位置编码
概述
正余弦位置编码(Sinusoidal Positional Encoding)是原始Transformer 中采用的位置编码方式,它通过一组预定义的正弦与余弦函数为每个序列位置生成唯一向量:

特点
无需训练
编码由固定函数生成,不引入任何可学习参数,使用简单,不会随训练发生漂移。
可外推
由于编码基于数学函数,不依赖训练语料长度,模型可在推理阶段处理比训练时更长的序列。
隐含相对位置信息
正余弦位置编码的结构使其能够携带 token 之间的相对位置信息。
正余弦位置编码的各维度是按频率成对排列的,每一对由同一频率对应的正弦值和余弦值组成。现在,我们分别从位置 和位置 的位置编码中,任意选取一对频率为 的维度进行观察。如下:

可以看到,这一结果直接反映了位置 与位置 之间的相对位置关系,其他频率的维度也具备相同的形式。因此,可以认为,在采用正余弦位置编码的情况下,两个 token 的注意力评分中会包含相对位置信息。
缺陷
尽管正余弦位置编码具有良好的数学结构,其向量间的内积可直接反映相对位置关系,但在实际的 Transformer 注意力计算中,这种优势并不能完全有效发挥。

其中,仅有最后一项明确体现了位置编码之间的相互作用,因此也是唯一直接与相对位置相关的部分。但由于矩阵A 是可学习参数,会在训练中不断变化,原本正余弦编码所具备的几何结构难以稳定保持。换句话说,模型必须通过额外的学习来重新塑造或校正这种相对位置信息,而这种重建过程往往并不可靠,导致正余弦位置编码在理论上的优势无法在实践中完全体现出来,也影响了训练的稳定性和模型的泛化表现。
可学习位置编码
概述
可学习位置编码(Learned Positional Embedding)是另一种常见的位置编码方式,曾广泛应用于早期的Transformer预训练模型(Bert,GPT-1/2等)中。在这种方法中,模型为序列中的每个位置分配一个独立的可训练向量,这些向量在训练过程中与模型的其他参数一同更新,使模型能够从实际任务数据中自动学习位置表示。
特点
可学习位置编码的主要特点如下:
灵活性高
位置向量完全由数据驱动学习,不受固定数学函数约束,因此能够更贴合训练语料的分布特点。
训练方式简单
其优化方式与词向量一致,实现成本低,不需要额外的结构设计,便于直接集成到 Transformer 中。
缺陷
缺乏长度外推能力
可学习位置编码只在训练过的位置范围内定义,超出最大序列长度的位置没有对应的嵌入,导致模型无法在推理阶段处理更长的输入序列。
参数量随序列长度线性增长
位置向量数量与最大序列长度成正比,当需要支持长上下文时,参数开销迅速增大。
旋转位置编码
概述
旋转位置编码(Rotary Position Embedding,RoPE)由国内研究者苏剑林提出。与传统将位置编码与词向量相加的方式不同,RoPE 直接作用于 q 和 k 向量本身,使注意力计算能够更好地体现 token 之间的相对位置关系。在实践中,RoPE 表现稳定,尤其适用于长序列建模,因此已成为当前 LLM 普遍采用的位置编码方案。
原理
RoPE 的设计目标是让注意力得分能够直接体现 token 之间的相对位置差 。这一目标可以简化表示为:
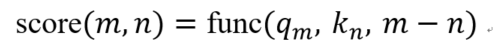
即注意力评分仅依赖于第m个位置的 query 向量 和第n个位置的 key 向量 ,以及两者之间的相对位置关系 。
为实现这一目标,RoPE 将 q 和 k 向量按维度两两分组,把每一对相邻维度视为一个二维子向量,并对每个二维子向量施加与位置及维度相关的旋转。如下图所示:
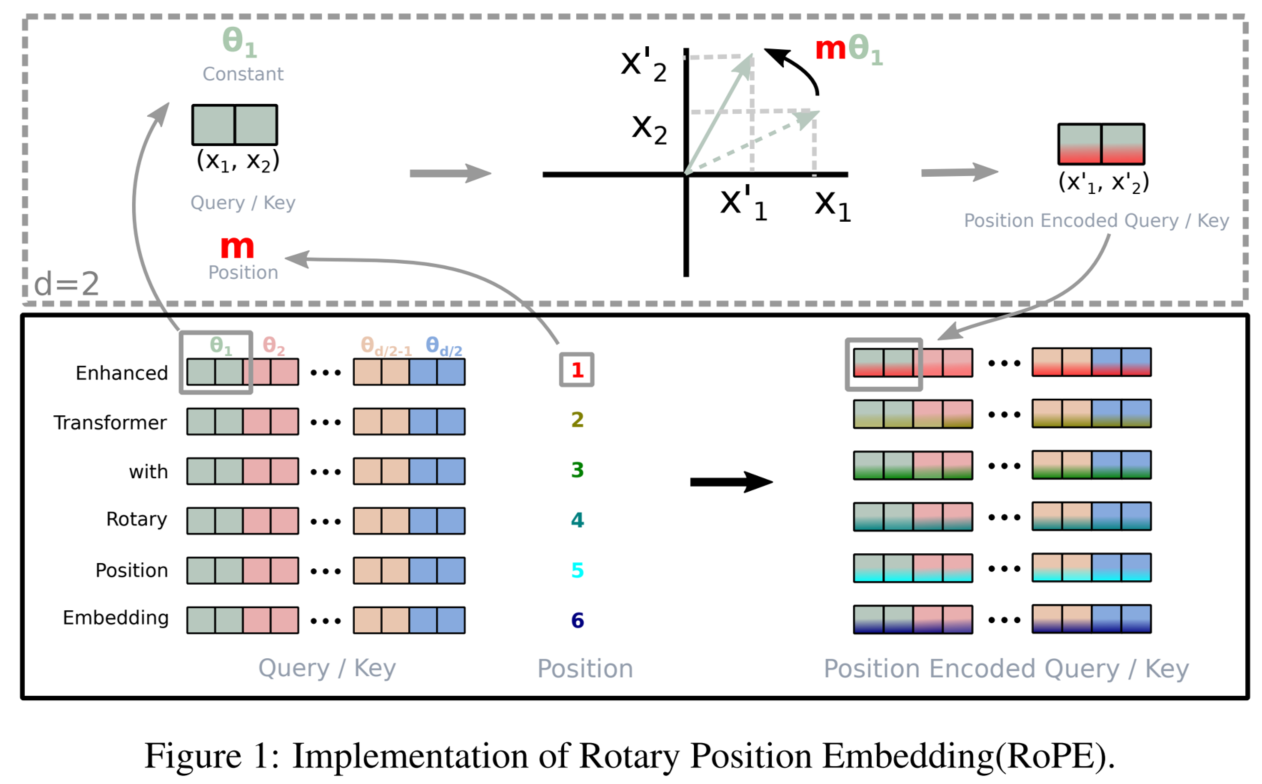

这说明 RoPE 在数学结构上保证了注意力机制能够自然表达 token 之间的相对位置信息,从而实现其设计目标。
特点
显式编码相对位置信息
旋转后注意力得分天然依赖 ,直接表达相对位置关系。
零参数且训练稳定
无需学习位置向量,结构固定,不随训练破坏几何性质。
强长度外推能力
数学结构不依赖训练长度,可在推理中处理更长序列。
3.3主流开源LLM架构赏析
3.3.1概述
前面介绍了大模型在架构层面的主要原理和演进方向。本节选取开源社区中几款具有代表性的模型,对其架构设计作简要梳理,以便对相关技术形成更完整的整体认识。
DeepSeek V3
DeepSeek V3 是 DeepSeek 团队于 2024/12/26 发布的大规模开源模型,采用 稀疏 Mixture-of-Experts(MoE)架构,总参数规模约 671B,推理时激活约 37B。
其整体结构与关键配置如下图所示:
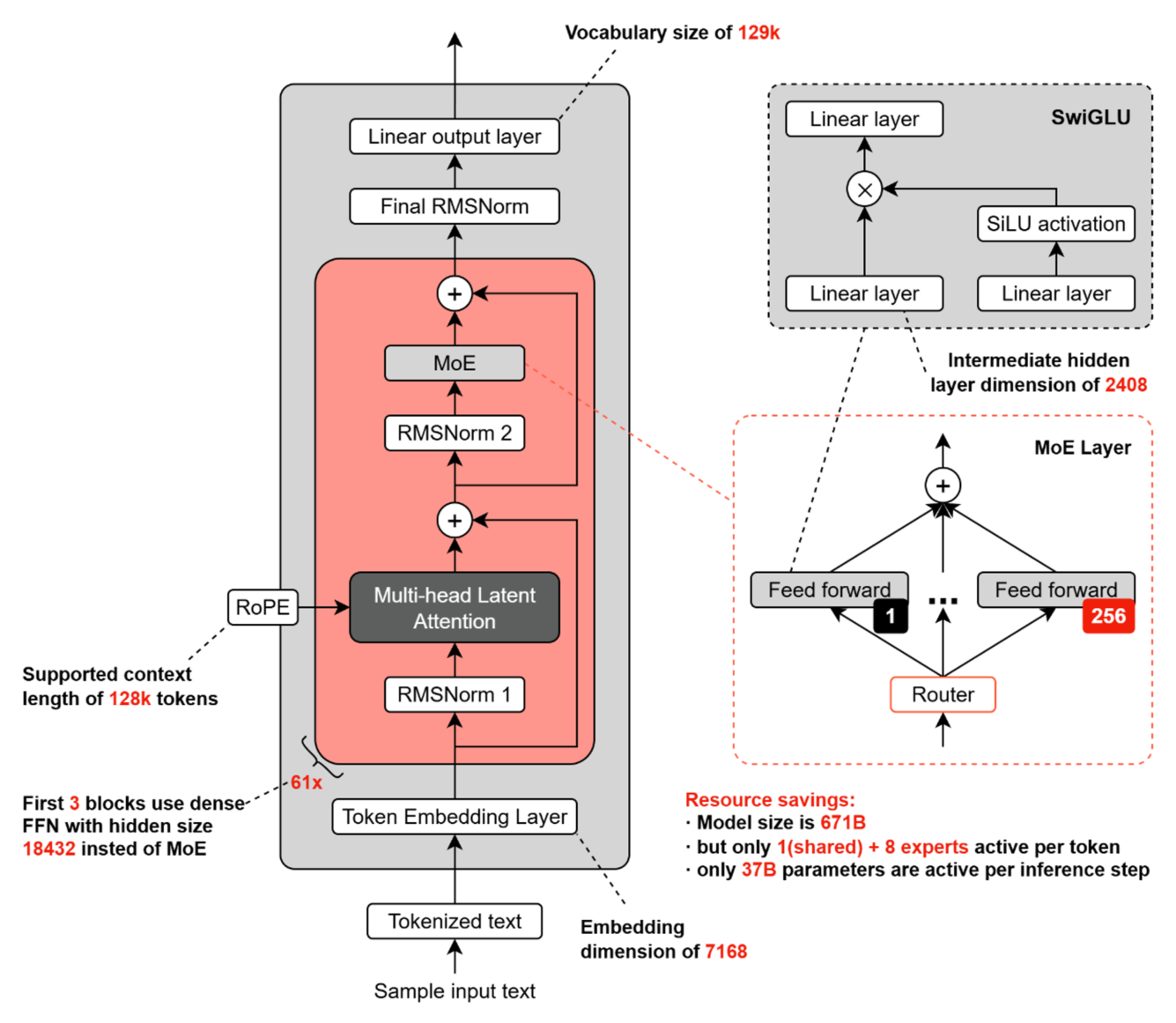
需要注意的是,DeepSeek 的 MoE 结构中包含一个共享专家(shared expert)。共享专家指所有输入都会经过的公共专家,它与路由选出的其他专家共同参与前馈计算。已有研究表明,引入共享专家能够稳定提升整体模型性能。通常认为,这一设计可以让共享专家吸收模型中普遍且反复出现的模式,从而减少各独立专家之间的重复学习,使专门化专家能够将更多容量用于处理差异性更强、结构更复杂的信息,以提升模型的表达效率和稳定性。
Llama 4
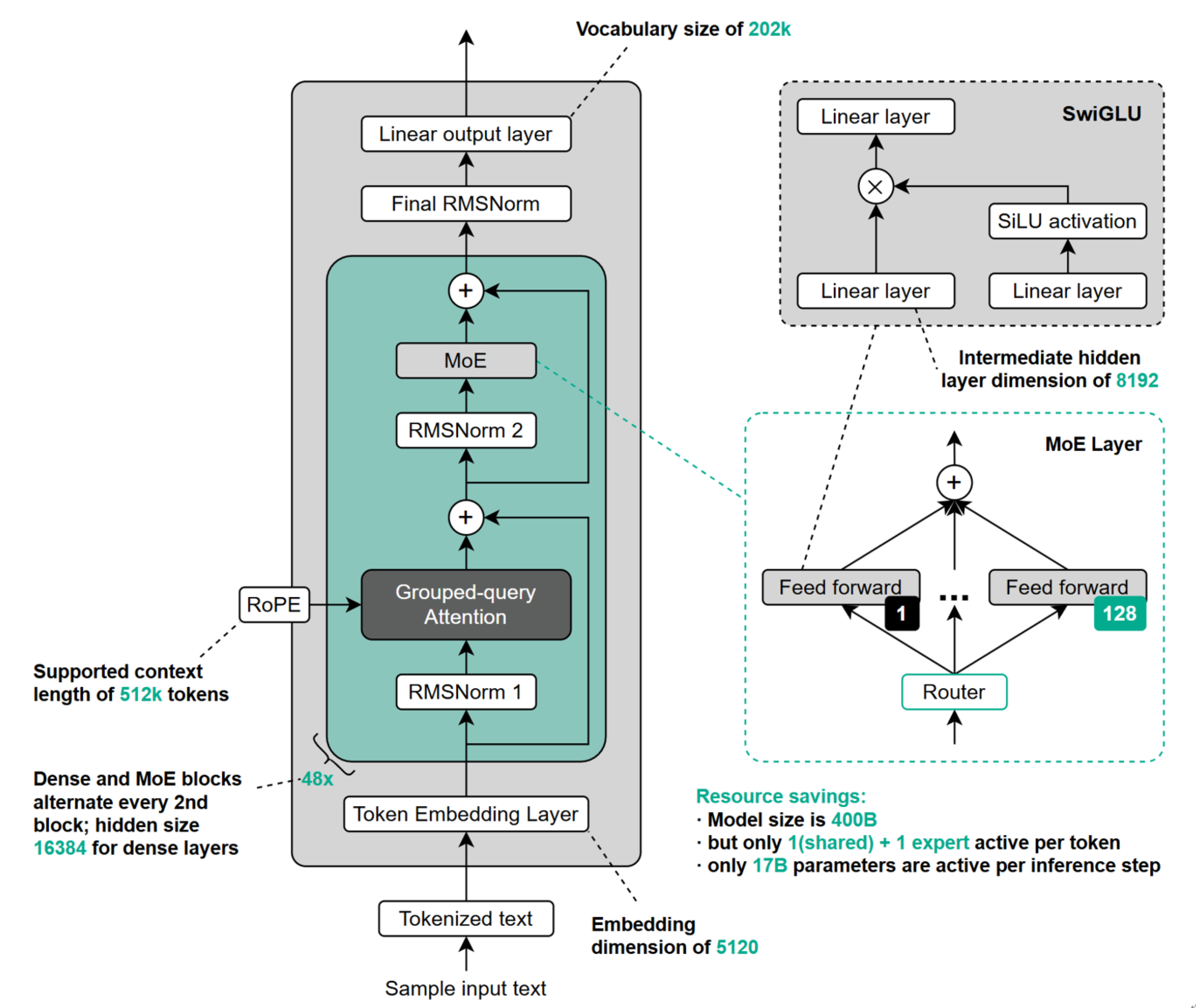
Llama 4 由 Meta 于 2025/04/05 发布,提供 Llama 4 Scout(侦察兵) 与 Llama 4 Maverick(独行侠) 两个版本,两者均采用 MoE 架构。Scout 属于轻量级配置,总参数约 109B 、激活约 1.7B ;Maverick 则在规模与能力上更完整,总参数约 400B 、激活约 17B ,在容量与效率之间取得较佳平衡。下图展示的是 Llama 4 Maverick 的主要结构与关键配置。
Qwen3
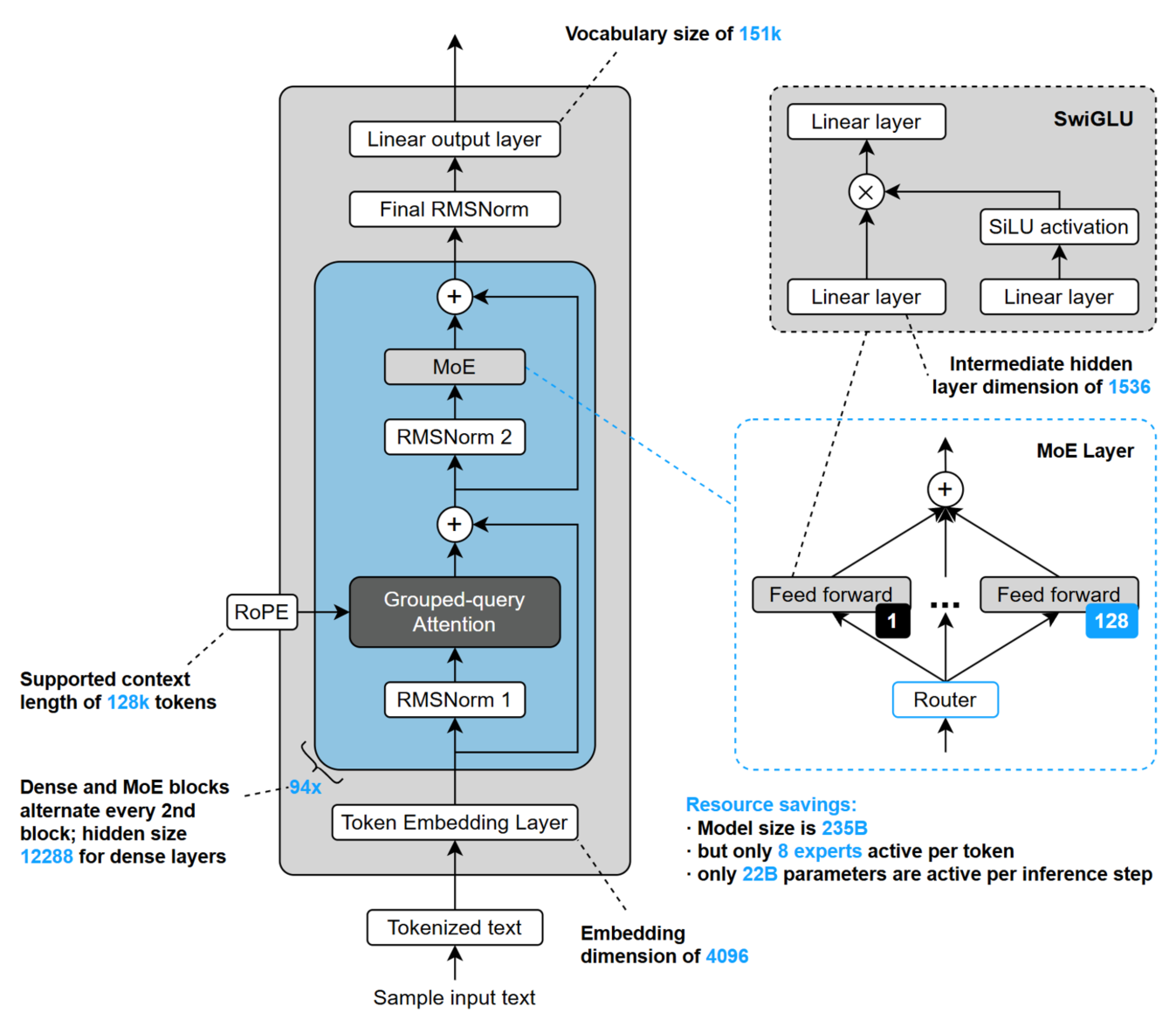
Qwen 3 由阿里巴巴于 2025/04/29 发布,开源了 MoE 和 Dense 两类模型权重 。MoE 系列包括 Qwen3-235B-A22B (总参数约 235B、激活约 22B)和 Qwen3-30B-A3B (总参数约 30B、激活约 3B);Dense 系列则提供 32B、14B、8B, 4B, 1.7B, 0.6B 六个版本,覆盖从大规模推理到轻量级部署的多种需求。下图是Qwen3-235B-A22B 的主要结构与关键配置。
GPT-OSS
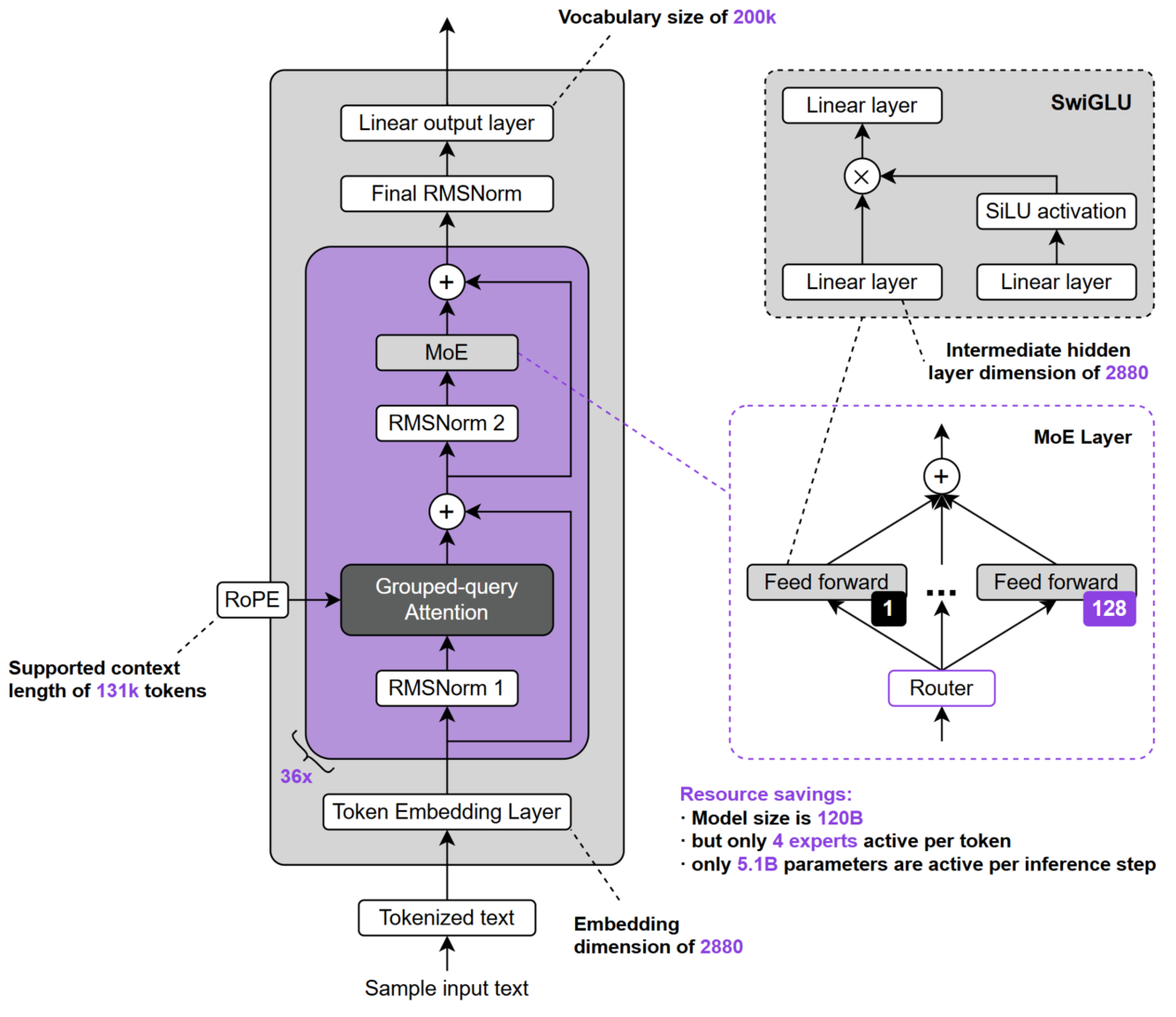
GPT-OSS 是 OpenAI 于 2025/08/05 发布的开源模型系列,包含 gpt-oss-120b 与 gpt-oss-20b 两个版本,均采用稀疏 Mixture-of-Experts(MoE)结构。其中,gpt-oss-120b 的总参数规模约 117B 、激活约 5.1B ;gpt-oss-20b 的总参数规模约 21B 、激活约 3.6B ,适用于更轻量或受限场景的部署需求。下图是gpt-oss-120b 的主要结构与关键配置。
其他
更多开源模型的架构对比与整理可参考这篇优秀的博文 The Big LLM Architecture Comparison。
4.LLM适配方法
4.1概述
当前,大语言模型在通用场景下已展现出强大的语言理解与生成能力。然而,当应用于特定行业、专业任务或独特语境时,其表现可能无法直接满足实际需求。为了提升模型在具体业务场景中的适用性、稳定性与输出质量,需要对其进行针对性的调整与增强。
在实践中常见且具有代表性的适配方法包括:**提示词工程(Prompt Engineering)、微调(Fine-tuning)、检索增强生成(Retrieval Augmented Generation,RAG)以及继续预训练(Continued Pre-training)。**这些方法从不同层面优化模型,各有其适用场景与优势。
4.2 适配方法概览
提示词工程
提示词工程是一种通过精心设计输入指令、示例与结构,以引导大语言模型生成预期输出的技术。该方法的核心优势在于无需调整模型内部参数,仅通过优化提示即可显著改善模型输出的质量、稳定性与可控性。因其成本低、迭代速度快、灵活性高,提示词工程通常是模型适配的首选方案。
在实际应用中,有效的提示词工程关键在于:清晰定义任务目标、严格约束输出格式、提供高质量示例,并最大限度地减少指令的歧义。通过持续的提示迭代与测试,模型在特定任务上的表现会趋于稳定,更贴合实际需求。
然而,提示词工程的效能受限于模型本身的内在能力、上下文窗口长度以及任务的复杂程度。对于专业性要求极高或需要严格行为一致性的场景,仅依赖提示可能无法达到理想效果,通常需要与其他适配方法结合使用。
更系统的提示词技巧可参考:https://www.promptingguide.ai。
微调
微调是指在预训练语言模型的基础上,使用带标注的数据集进一步训练模型,使其输出更贴合任务需求或更符合人类偏好。通过在特定示例上调整模型参数,微调能够让模型在目标任务中表现得更加稳定、一致并具有明确的行为模式。
根据训练目标的不同,微调通常分为两类范式:
- 监督微调(Supervised Fine-tuning):利用包含明确示例和正确输出的标注数据,通过监督学习让模型直接学习任务规则和输出格式。
- 偏好对齐(Preference Alignment) :基于偏好数据调整模型的输出倾向,使其生成更符合人类偏好的回答方式,常用于提升回答质量、一致性或安全性。
微调的效果依赖于标注数据的质量、覆盖范围和任务定义的清晰度。当数据具备代表性和一致性时,模型通常能够在目标任务上获得显著提升;反之,模糊或噪声较高的数据可能会限制微调效果。因此,构建高质量的标注集是微调能否发挥作用的关键。
检索增强生成
检索增强生成是一种在模型推理阶段引入外部知识的方法。其核心思想是,先根据用户问题从外部知识源中检索相关信息,再将检索结果与原始问题一并提供给模型,使其能够在增强的上下文基础上生成回答。由于无需修改模型参数,RAG 特别适用于知识更新频繁或需要处理大量私有知识的场景。
典型流程是:系统首先根据用户问题,从外部知识源(如向量数据库)中检索相关文本片段;随后将这些检索到的内容与原始问题一并输入模型,由模型在增强后的上下文基础上生成回答。
RAG 在企业问答、文档智能、专业咨询等场景中尤为实用,能有效弥补模型静态知识的不足。但其效果高度依赖于外部知识库的质量、检索的准确性以及信息与问题的相关度。因此,构建高质量的知识源和优化的检索流程是 RAG 系统可靠运行的核心保障。
继续预训练
继续预训练是指在大规模通用语料训练得到的基础模型之上,使用特定领域的大规模无标注文本继续进行自监督语言建模训练。通过这种方式,模型能够深入适应目标领域的语料分布,从而在语义理解、术语掌握和行文风格上更贴近该领域。
在行业术语密集、专业风格鲜明或企业内部文档丰富的场景中,继续预训练通常能带来显著提升。模型在经过大量领域语料的训练后,能够更准确地理解和生成相关专业内容。
继续预训练的效果主要取决于领域语料的规模、质量及其与目标任务的相关性。如果语料覆盖全面、风格一致且质量上乘,模型通常能获得坚实的领域能力基础;反之,则可能难以达到预期效果。因此,准备高质量、大规模的领域语料是继续预训练取得成功的基础。
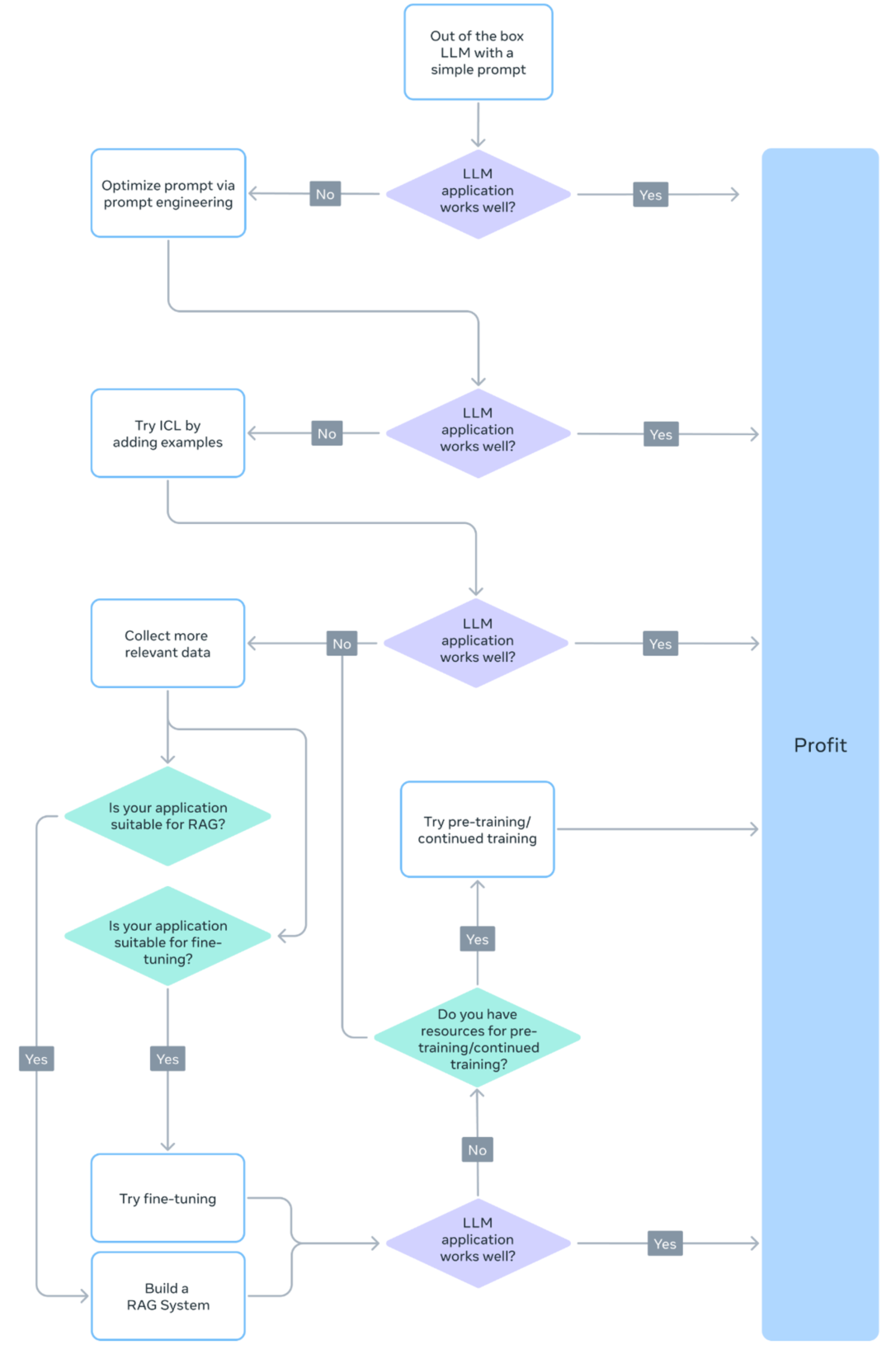
适配方法选择策略
在构建基于大语言模型的应用时,不同适配方法各有其优缺点与适用场景。为实现最佳的投入产出比,需要结合具体任务需求进行系统性决策。下图展示了一个常用的渐进式决策流程,可帮助开发者根据任务特性选择最合适的适配路径:
5.LLM微调
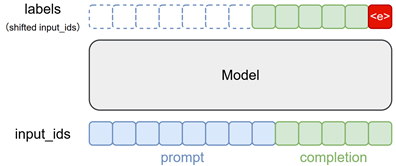
声明 :本章所提到的微调特指监督微调(Supervised Fine-tuning,SFT)。
5.1概述
监督微调(Supervised Fine-tuning, SFT)是将通用大语言模型(Large Language Model, LLM)适配至特定任务的关键技术手段,其核心价值主要体现在以下三个方面:
- 增强任务执行能力:显著提升模型在特定任务上的可靠性与准确性,使其更好地满足实际应用需求。
- 定制输出行为:使模型能够按照预期的语气、格式生成内容,确保输出一致、可靠、符合规范。
- 注入领域知识 :将特定领域的术语、规则或业务逻辑内化至模型参数中,从而增强其在专业场景下的适用性与表现力。
需要强调的是,面对具体任务时,应优先尝试提示工程(Prompt Engineering)等轻量级方法。仅当提示工程无法达到预期效果时,才应考虑采用监督微调。
以下情形可作为采用 SFT 的合理依据: - 模型能力适配不足:基础模型在目标任务上表现不稳定,且通过优化提示、示例引导等方式仍难以满足性能要求。
- 输出一致性要求高:应用场景对输出格式或风格有严格规范,而仅靠提示难以保证长期稳定的输出质量。
- 降低模型使用成本:微调并使用小型专用模型的总体成本(训练、部署、推理时间)显著低于直接使用大型通用模型。
5.2模型使用说明
5.2.1概述
当前主流大语言模型普遍采用"预训练---监督微调---对齐"的三阶段开发范式。一般仅经过预训练得到的模型称为Base Model(例如:Qwen/Qwen3-8B-Base),而经过SFT和对齐之后的模型称为Instruct Model(例如:Qwen/Qwen3-8B)。如下图所示:

对于多数开源模型而言,Base Model 和 Instruct Model 往往都会公开发布,便于研究者和开发者根据需求选择。
其中 Base Model 具备广泛的世界知识和强大的语言生成能力,是模型能力的基础。但由于其训练目标仅是"预测下一个 Token",并未针对任务指令、对话格式或人类偏好进行训练,因此无法可靠地理解或遵循自然语言指令 ,也缺乏稳定的任务执行能力。
而 Instruct Model 则是在 Base Model 的基础上进一步经过监督微调和偏好对齐得到的模型。通过大量高质量的对话数据以及人类偏好信号的训练,Instruct Model 能够更准确地理解用户意图、遵循任务说明,并生成更符合人类期望的响应。
5.2.2选择策略
在进行监督微调(SFT)时,模型起点的选择(Base Model 或 Instruct Model)直接影响微调效果、开发效率与资源投入。推荐采用以下选择策略:
对于绝大多数应用场景(如客服问答、内容生成、结构化输出、多轮对话等),应优先选择Instruct Model 作为微调起点。原因如下:
Instruct Model 已经过指令微调与人类偏好对齐,具备良好的指令遵循能力,因此微调过程只需聚焦于领域知识注入或行为细节调整,无需从零建立指令理解能力,可显著降低数据标注成本(通常数千条)与训练难度。
至于Base Model,则仅在高度定制场景下才考虑使用,例如:
- 任务非常专业或形式极其特殊,Instruct Model的默认行为反而会干扰任务的执行;
- 手头有大量高质量的领域数据(通常数万条),打算从头开始做深度领域适配。
5.2.3注意事项
Instruct Model
在基于Instruct Model进行微调时,需注意:
- 使用一致的 Chat Template
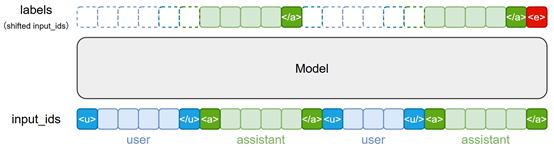
Instruct Model 在 SFT 阶段通常会采用特定的Chat Template(例如ChatML)将结构化的对话或多轮指令-响应数据转换为可训练模型的线性文本序列,如下图所示:
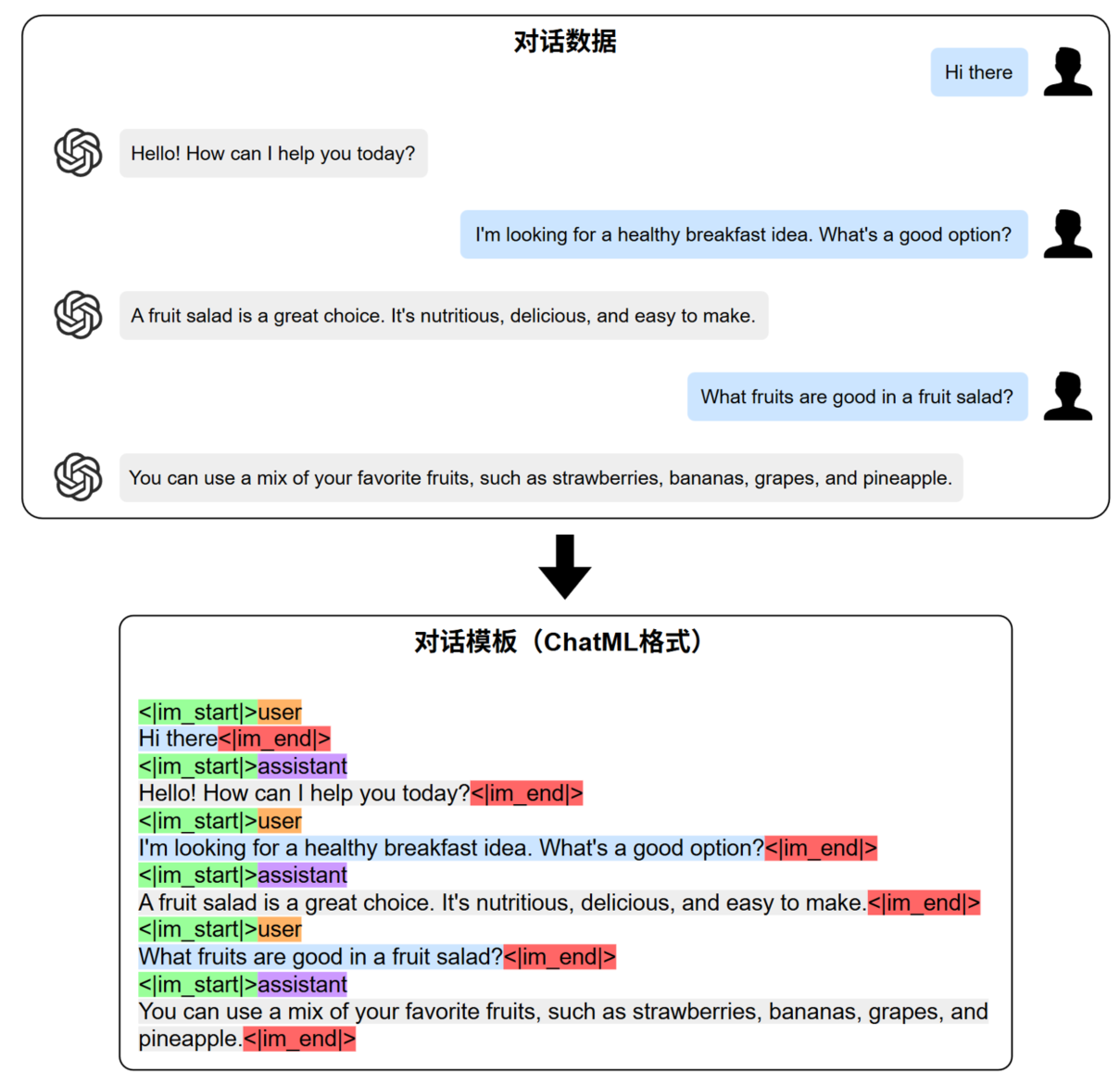
因此,在微调过程中,必须使用与原模型训练时完全一致的 Chat Template 来组织输入数据。若模板不一致,模型可能无法正确识别指令边界与角色信息,从而导致任务理解失败、输出格式混乱,甚至行为退化。 - 采用较低学习率
Instruct Model 已经过 SFT 与人类偏好对齐(如 RLHF)等多阶段优化,其参数已高度收敛,具备稳定的指令遵循与输出生成能力。若微调时使用过高的学习率,极易引发灾难性遗忘------即在学习新任务的同时,遗忘已习得的通用语言能力、指令理解能力或安全对齐行为。
为实现增量适配而非覆盖重训,建议采用较小的学习率(通常为 10⁻⁵ 量级),以在保留模型原有能力的基础上,平稳注入新领域知识或调整输出风格。
Base Model
在基于Base Model进行微调时,需注意:
- 数据质量要求高
Base Model 仅完成通用语言建模预训练,不具备指令理解能力。微调时必须提供大量高质量、结构规范的指令-响应对,才能从零建立起可靠的任务执行能力。 - 微调后通常仍需偏好对齐
SFT 仅教会模型"如何响应指令",但未引导其"如何生成符合人类偏好的回答"。因此,SFT 之后通常还需进行偏好对齐阶段(如 RLHF 或 DPO),以注入安全性、真实性与有用性等人类价值观,使模型行为更可靠、更贴近实际应用需求。
5.3数据集使用说明
5.3.1数据来源
在微调大语言模型时,数据是决定模型性能与适用性的关键因素。模型表现,很大程度上取决于其训练数据的质量。根据数据的来源与可访问性,通常可分为两大类:公共数据源与私有数据源。
公共数据源
公共数据集易于获取,通常是绝佳的起点,常用的数据共享平台有:
- Hugging Face Hub
Hugging Face Hub 是一个不可或缺的资源,它托管了数千个数据集,这些数据集可以通过 datasets 库轻松访问。用户可以根据任务类型(如文本生成、文本摘要等)、语言以及数据集的许可证进行筛选,从而快速找到符合需求的数据。 - Model Scope
ModelScope 是阿里巴巴旗下的模型开放平台,提供了一系列高质量的开源模型与数据集。ModelScope 的数据集覆盖了多个领域,包括但不限于自然语言处理、计算机视觉和多模态任务。
私有数据源
私有数据源是指企业或组织内部拥有的数据集,这些数据可能受到版权保护或隐私限制,仅限于内部使用或特定授权范围内使用。以下是常见的私有数据源:
- 企业内部文档: 包括公司的历史文件、报告、邮件、会议记录等,这些数据可以用来训练模型以更好地理解公司业务流程和专业知识。
- 客户反馈数据: 来自客户的评论、投诉、建议等信息,可以帮助企业改进产品和服务质量。
- 专有数据库: 某些行业可能拥有专门构建的数据库,如医疗健康领域的电子病历、金融领域的交易记录等。
私有数据通常并非专为模型微调而准备,因此在使用前往往需要经过清洗、结构化和标注等预处理步骤。为了构建高质量的领域特定训练集,企业可以根据实际需求,由内部专业团队或外部众包平台对原始数据进行系统化整理与标注。
此外,还可以借助自动化工具提升整体效率,例如使用 Easy Dataset 等开源方案。在人机协同的工作模式下,企业能够更高效地将私有知识转化为高质量的微调数据,从而更有力地支撑模型在特定业务场景中的性能提升。
5.3.2数据集格式
在大型语言模型的监督微调中,数据集的构建格式至关重要,常见的格式可分为两类:指令式 与 对话式。
指令式
指令式数据集用于训练模型执行明确的单轮任务,如翻译、摘要或问答。其典型格式源自斯坦福大学的 Alpaca 项目 ,结构简洁、易于使用。
其每条样本包含三个字段:
- instruction:描述模型需要执行的任务;
- input:任务所需的上下文或附加信息;
- output:模型应生成的正确回答。
例如:
{
"instruction": "将以下英文翻译成中文",
"input": "Large language models are transforming AI.",
"output": "大语言模型正在改变人工智能。"
}
训练时,这些字段通常会通过一个提示模板(prompt template)组合成结构统一的输入字符串,以帮助模型更好的学习任务指令。
指令:
{instruction}
输入:
{input}
回复:
{output}
对话式
对话式数据集用于训练模型进行多轮对话,例如聊天机器人、虚拟助手等。这类数据通常以消息序列的形式组织,强调发言者角色与对话流程。目前广泛采用的格式主要有 ShareGPT 格式 和 OpenAI 格式。
ShareGPT 格式
ShareGPT 格式源于用户在社区中分享的与 ChatGPT 的真实对话记录,常用于保存多轮对话数据集。
每条数据样本由一个名为 conversations 的列表构成,列表中的每个元素代表一次发言,包含两个关键字段:
- from:标识发言者的角色,通常取值为 "human"(表示用户)或 "gpt"(表示模型助手);
- value:该轮对话的具体文本内容。
例如:
{
"conversations": { "from": "human", "value": "你能解释一下什么是机器学习吗?" }, { "from": "gpt", "value": "机器学习是人工智能的一个分支,它允许计算机系统通过数据和经验自动改进其性能。" }, { "from": "human", "value": "它主要有哪些类型?" }, { "from": "gpt", "value": "主要类型包括监督学习、无监督学习、半监督学习和强化学习等。" }
}
OpenAI 格式
OpenAI 格式是 OpenAI 官方在其 API 微调功能中推广的一种通用消息列表格式,兼具灵活性与表达力,可同时支持单轮和多轮对话。
每个训练样本是一个包含 messages 字段的字典,其中 messages 是一个有序列表,每条消息包含以下字段:
- role:发言者角色,常见值包括:system、user和assistant。
- content:消息的具体文本内容。
例如:
{
"messages": { "role": "system", "content": "你是一名专业的营养师。你的回答应基于科学知识,提供务实、健康的建议,并避免提供任何医疗诊断。" }, { "role": "user", "content": "我最近感觉下午很疲惫,有什么健康的零食推荐吗?" }, { "role": "assistant", "content": "下午感到疲惫是常见的现象,选择正确的零食可以帮助稳定能量水平。以下是一些推荐:\\n1. \*\*一把坚果和干果\*\*:提供健康的脂肪、蛋白质和天然糖分,能快速补充能量。\\n2. \*\*希腊酸奶\*\*:富含蛋白质,能提供持久的饱腹感。\\n3. \*\*一个苹果或一根香蕉\*\*:富含维生素和膳食纤维,是方便的天然能量来源。\\n请记得结合充足的水分摄入,因为脱水也会导致疲劳。" }
}
在实际训练中,无论采用哪种原始格式,通常都会通过 Chat Template(例如ChatML)将多轮消息组织成结构统一的字符串,确保模型能够正确解析对话结构并学习交互模式。这一标准化步骤对于提升模型的对话理解与生成能力至关重要。
5.4微调方法
根据是否更新模型全部参数,监督微调(SFT)的方法可分为两类:
- 全参数微调(Full Fine-tuning)
- 参数高效微调(Parameter-Efficient Fine-tuning, PEFT)
5.4.1全参数微调
全参数微调是一种在微调过程中更新模型全部参数的方法。它能最大限度地适配目标任务,通常获得最优性能。
但由于大语言模型参数量庞大(数十亿至数千亿),全参数微调对显存、算力和训练时间要求极高,单设备通常无法承载模型参数、优化器状态与激活值,必须依赖分布式训练技术才能实施。
因此,全参数微调适用于资源充足、对性能要求严苛、且拥有高质量标注数据的场景。在实际应用中,常作为参数高效微调无法满足需求时的高成本备选方案。
5.4.2参数高效微调
概述
参数高效微调(Parameter-Efficient Fine-tuning, PEFT)是一系列微调方法,其核思想是仅更新少量参数或引入少量可训练模块,在显著降低资源消耗的同时,高效适配目标任务。目前,最先进的PEFT方法已经能实现与全参微调相当的性能。
PEFT 的兴起可追溯至 2019 年前后。当时以 BERT、GPT-2 为代表的预训练模型规模迅速扩大,传统全参数微调的资源成本逐渐难以承受。伴随模型规模持续膨胀,这种矛盾愈发凸显,由此推动了 PEFT 技术的快速发展,形成了包括 Prompt Tuning、Prefix Tuning、P-Tuning、Adapter、LoRA 等多条技术路线,如下图所示:
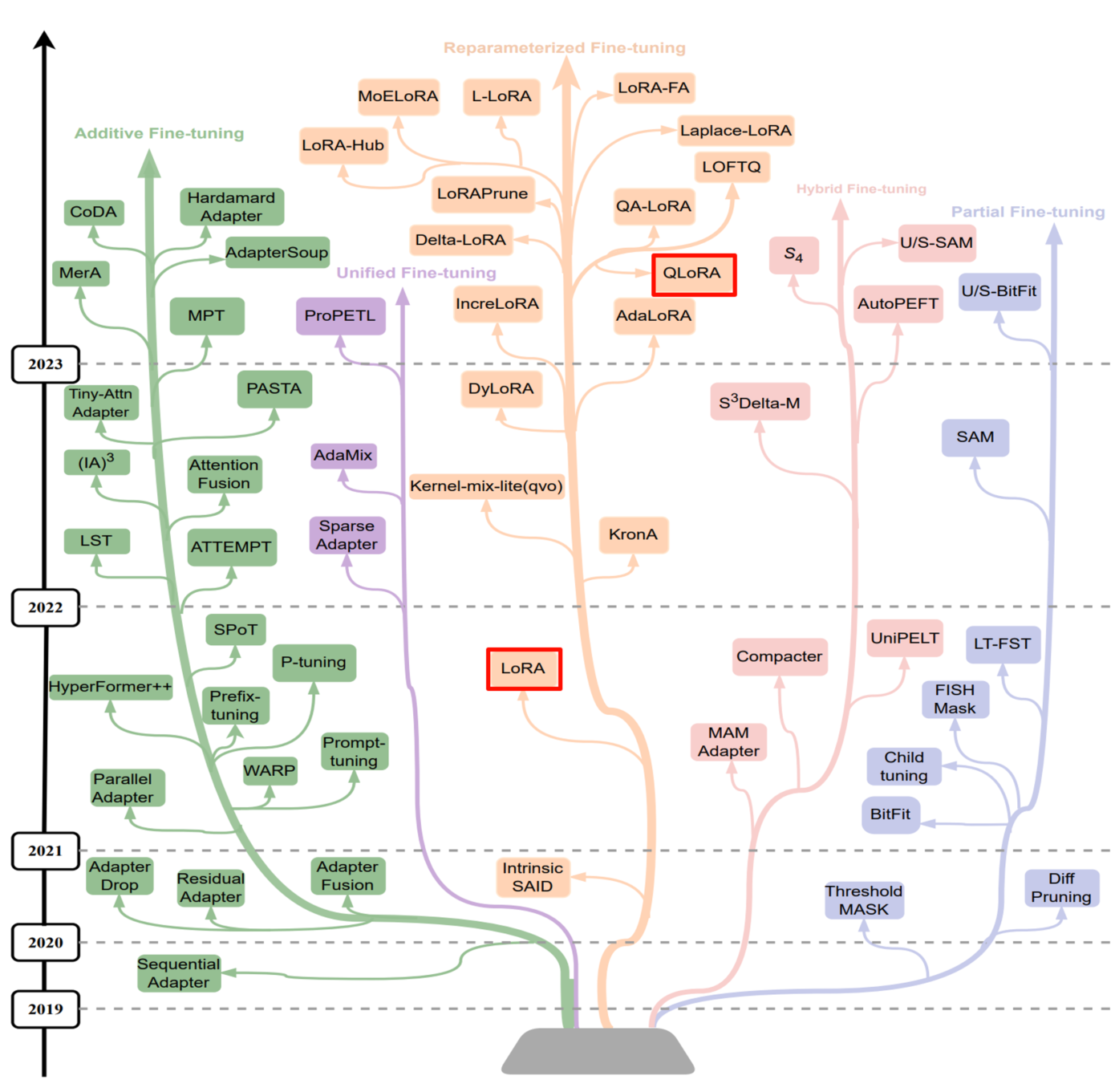
在众多方法中,LoRA(Low-Rank Adaptation)因其结构简洁、训练高效、稳定,已成为当前大语言模型监督微调(SFT)的主流选择;其量化版本 QLoRA (Quantized Low-Rank Adaptation)进一步融合量化技术,将微调门槛降至消费级 GPU 也可运行的水平。相比之下,其他 PEFT 方法因在效率、稳定性或通用性等方面存在局限,已逐渐边缘化。
LoRA
概述
LoRA(Low-Rank Adaptation)是一种高效且广泛使用的参数高效微调方法,由微软研究院于 2021 年提出。因其训练成本低、适配能力强、推理无额外开销等优势,已成为当前大语言模型监督微调(SFT)中最广泛使用的技术。
原理

在训练过程中,LoRA 完全冻结原始权重 ,仅对新增的低秩矩阵 A和B 进行优化。这大幅减少了需要更新的参数量,同时也避免了对大规模模型权重的直接修改,使微调过程更加轻量、高效。
在推理阶段,低秩增量 可以无缝合并回原始权重 中,不会引入额外的计算复杂度,因此 LoRA 的高效性不仅体现在训练中,也体现在推理过程中。

个参数,占原始权重的仅约 0.4%。这种数量级的压缩使得在有限资源下微调大模型成为可能,也使得在多个任务之间共享底层模型、仅保存轻量级 LoRA 适配器成为现实。
插入位置
LoRA 通常插入模型中的线性层。在主流 Decoder-only 模型(如 LLaMA、Qwen)中,最常用的是对注意力层的 q_proj 和 v_proj 插入 LoRA,原因如下:
- Query 和 Value 对任务语义最敏感;
- 仅插这两处即可接近全参微调性能;
- 参数和显存开销最小。
如需更强表达能力,也可扩展至 k_proj、o_proj 或 FFN 层,但会增加成本。
工程实现
在工程中实现中,通常会额外加入两个关键组件:
缩放系数(α)
为了控制 LoRA 增量在训练初期的影响力,并在不同秩r 下保持数值稳定性,通常会在增量上加入缩放系数,使前向计算变为:
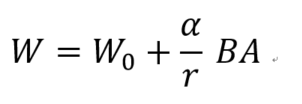
LoRA Dropout
为提升泛化能力,减轻小数据集上的过拟合,通常会对LoRA Layer的输入进行dropout。
QloRA
概述
QLoRA(Quantized Low-Rank Adaptation)是 LoRA 的量化增强版本,由华盛顿大学和微软研究院于 2023 年提出。QLoRA 在 LoRA 的基础上引入 4-bit 量化技术,在几乎不损失性能的前提下,将大语言模型微调的硬件门槛大幅降低,使得数十亿参数级别的模型可在单张消费级 GPU(如 RTX 3090/4090)上完成高效微调。
原理
QLoRA 的核心思想是:先对预训练模型权重进行 4-bit 量化以压缩显存占用,再在其上应用 LoRA 进行参数高效微调。
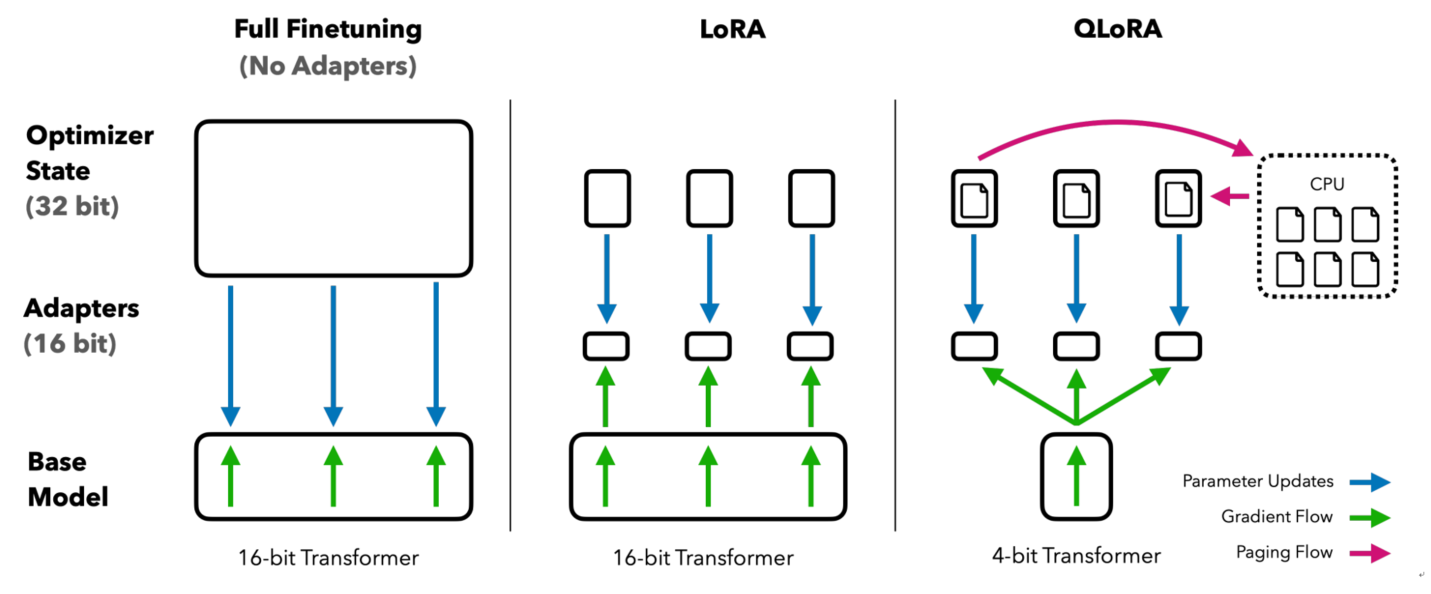
整个流程包含三个关键技术组件:
4-bit NormalFloat(NF4)量化
量化(Quantization) 是一种通过降低数值精度(例如从 16-bit 降至 4-bit)来压缩模型、节省显存的技术。传统 4-bit 量化通常采用如下流程:
- 使用权重的最大绝对值(absmax)将权重归一化到区间 ;
- 将该区间均匀划分为2^4=16个 等距格点;
- 每个权重被映射到最近的格点,并以对应的 4-bit 索引存储。
具体如下图所示:

然而,大语言模型的权重分布并非均匀,而是近似服从标准正态分布(均值为 0,方差为 1)。在这种分布下,传统均匀量化存在明显缺陷:
- 在权重密集的 0 附近,格点相对不足,导致量化误差较大;
- 在权重稀疏的两端,格点又相对冗余,造成信息利用率低下。
为解决这一问题,QLoRA 提出了 4-bit NormalFloat(NF4)量化,专为标准正态分布设计: - 将标准正态分布按累积概率均分为 16 个等概率区间;
- 每个区间选取其中位数作为该区间的量化代表值。
这样得到的量化格点在 0 附近更密集,在两端更稀疏,与权重的实际分布高度匹配,从而显著降低量化误差。
双重量化(Double Quantization)
在权重量化过程中,为了保证精度,通常的做法是让每 64 个权重共享一个 32-bit 的缩放因子(Absmax)。虽然这种方法能有效控制量化误差,但这些大量的缩放因子自身也会带来显著的存储开销。
为缓解这一问题,QLoRA 提出了"双重量化":不仅对模型权重量化,更对这些高精度的缩放因子进行二次量化。其实现方式是,将缩放因子以 256 个为一组,使用 8-bit 数据类型进行二次量化。如此一来,量化所需的辅助存储空间得以大幅减少。
分页优化器(Paged Optimizers)
在微调过程中,优化器状态(如 Adam 的一阶矩、二阶矩)往往比模型权重本身更占显存。即使使用 LoRA 或 QLoRA,大量优化器状态仍可能导致显存不足,尤其是在消费级 GPU 上。
为解决这一瓶颈,QLoRA 使用了 分页优化器(Paged Optimizer) 技术,使优化器状态能够按需加载、按需卸载,从而更加高效地利用显存。
其核心思路是:
- 将优化器状态拆分为多个小块(pages);
- 仅在需要更新某层时,临时把对应 page 载入到显存;
- 更新完成后立即将该 page 写回内存,并从显存中释放;
借助分页机制,显存只需容纳当前正在使用的优化器状态,显存占用随之显著降低。这一技术让大型模型的 QLoRA 微调能够在更低显存环境下高效运行,并最大化消费级 GPU 的可用算力。
5.5分布式训练
5.5.1概述
随着大语言模型(Large Language Model, LLM)的参数量和训练数据规模持续增长,分布式训练已成为现代大模型训练体系中的核心技术。其核心目标在于:
- 提升训练效率:通过将计算任务分配到多个计算设备上并行执行,显著缩短训练时间,加快模型迭代速度;
- 支撑更大模型规模:通过协同多设备的计算与存储资源,使训练超大规模模型成为可能,突破单设备在模型容量上的限制。
主流的分布式训练策略包括: - 数据并行(Data Parallelism)
- 流水线并行(Pipeline Parallelism)
- 张量并行(Tensor Parallelism)、
- 专家并行(Expert Parallelism)
- ZeRO(Zero Redundancy Optimizer)
这些策略从不同维度对计算、通信与存储进行协同调度,在提升训练效率的同时,支撑起千亿甚至万亿参数规模的大模型训练。
5.5.2数据并行
数据并行(Data Parallelism)的核心思想是在多张 GPU 上各放置一份完整的模型副本,并让不同 GPU 并行处理不同的数据子集。这样做的主要目的,是提升训练吞吐量,从而加快整体训练速度。
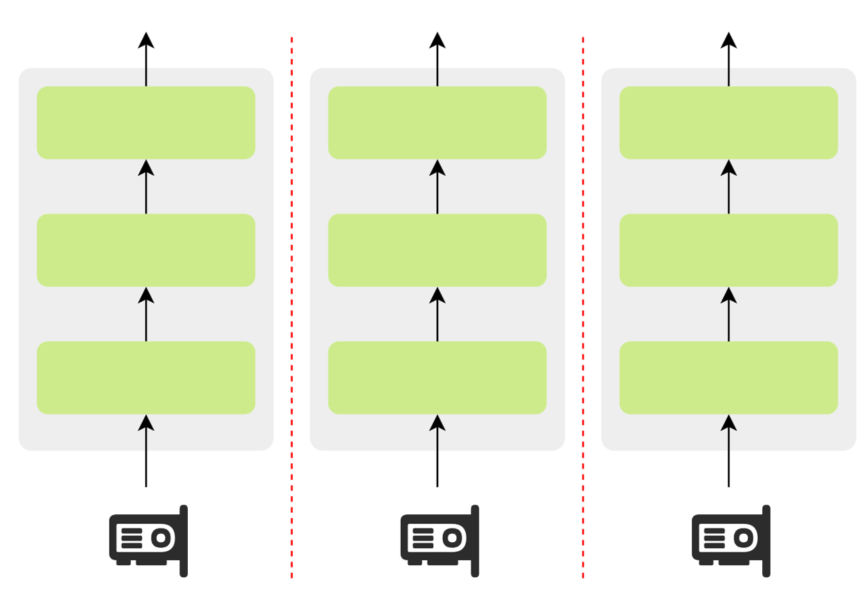
数据并行训练过程中,需要保证各副本参数一致,具体训练流程如下:
- 每个 GPU 独立处理本地数据子集,完成前向计算、反向传播并得到本地梯度。
- 跨 GPU 进行梯度汇总,将所有梯度进行平均,使每个 GPU 获得相同的全局梯度。
- 各 GPU 使用相同的全局梯度独立更新参数 ,从而保证所有模型副本继续保持一致。
其中,步骤 2 涉及大量梯度数据的跨设备传输,尤其在大语言模型(LLM)参数规模庞大时,通信开销可能成为性能瓶颈。因此,为缓解通信压力,这一步骤通常依赖于高效的集合通信算法实现,其中 AllReduce 是目前最主流且有效的实现方式。
5.5.3流水线并行
流水线并行的核心思想是将大语言模型按层纵向切分,把不同层分配到多个设备上,每个设备负责一个模型分段。其目标是降低单设备的显存占用,使超大规模模型能够在有限硬件资源下完成训练。
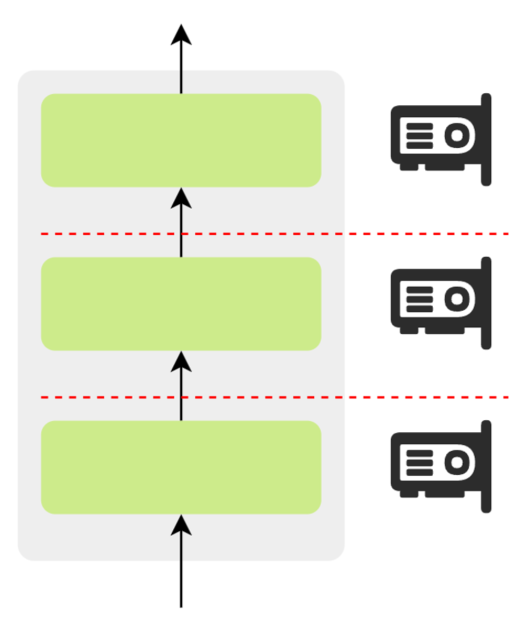
训练过程中,前向计算从第一个设备开始,逐级将中间激活值传递给下一个设备,直到完成整个模型的前向传播;反向传播则以相反顺序依次进行,梯度逐级回传。这种按层接力的执行方式允许多个设备协同工作,但也会导致部分设备在等待上下游计算完成时处于空闲状态,形成"气泡",造成计算资源浪费,如下图所示:
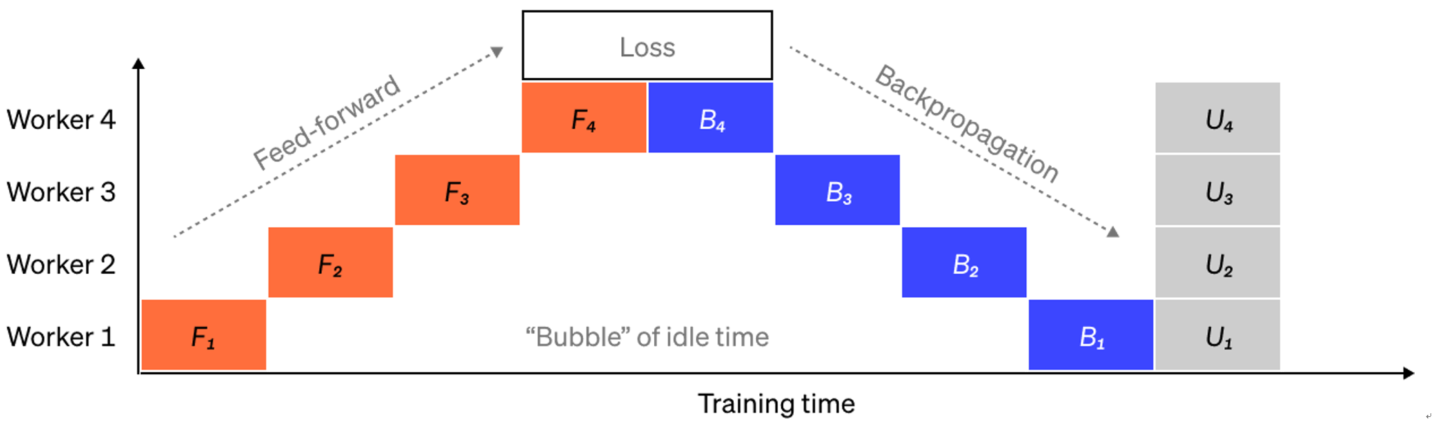
为缓解气泡问题,主流方法是引入 微批次(Micro-batches) 与 流水线调度策略 ,使不同设备在更多时间段内都有计算任务可执行,从而提高流水线利用率。
具体做法是:将原始批次进一步划分为多个更小的微批次。流水线中每个设备在处理完某个微批次后,可立即切换到下一个微批次的计算,不必等待整批数据完成。这种方式使流水线中不同阶段之间能够更紧密地衔接,减少空闲时间。如下图所示:

5.5.4张量并行
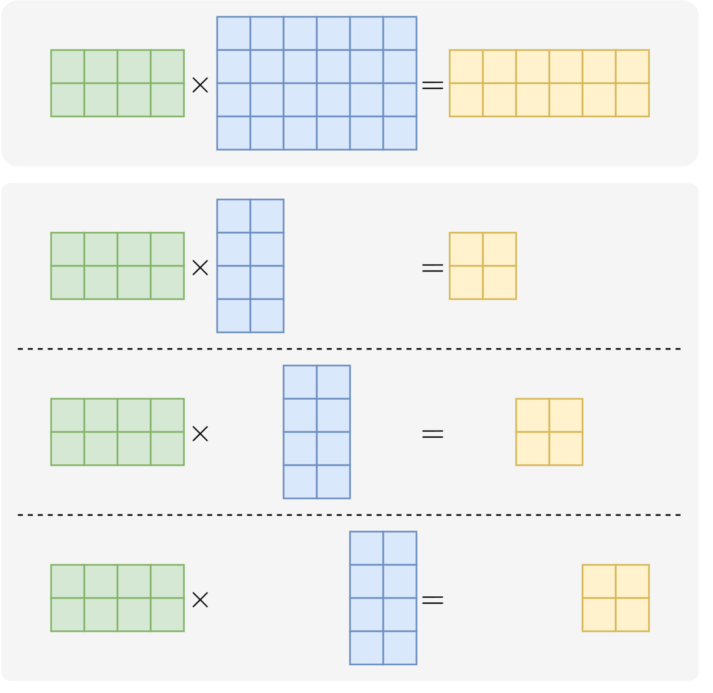
张量并行的做法是将模型单层内部的张量计算拆分到多个设备上并行执行,每个设备仅持有部分权重和中间结果。其目标仍是突破单设备显存和计算能力的限制,使超大模型的单层也能在多设备上协同完成。
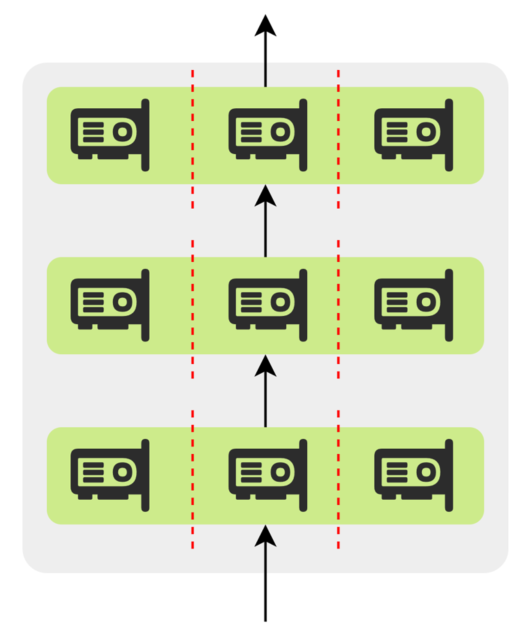
在现代 Transformer 模型中,计算瓶颈通常出现在激活矩阵与大权重矩阵的乘法操作上。由于矩阵乘法可分解为多个独立或可累加的点积运算,因此可以将权重矩阵均匀切分,每个设备仅持有其中一部分,然后将激活数据广播到所有设备,各设备使用本地分片权重独立完成部分矩阵乘法,再通过设备间通信聚合计算结果,得到完整的矩阵乘积。
5.5.5专家并行
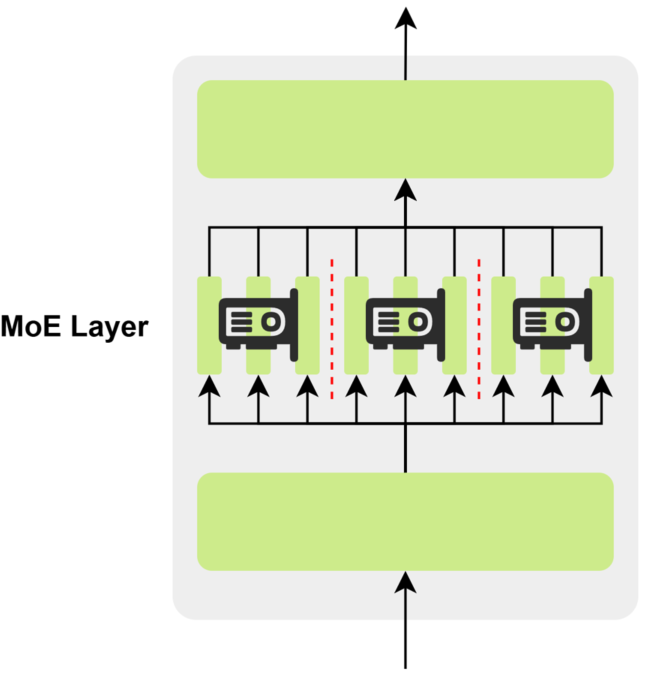
专家并行的做法是将 Mixture-of-Experts(MoE)模型中的多个专家(Expert)分配到不同的设备上,每个设备仅存储和计算部分专家。
MoE 结构天然适合并行化:每个专家本质上是一个独立的前馈网络(FFN),彼此之间没有共享参数或依赖关系,因此可直接将不同专家切分并分布到多个设备上。
5.5.6ZeRO
概述
ZeRO(Zero Redundancy Optimizer)是由微软研究院提出一套分布式训练技术。它可视为对传统数据并行的深度增强。
在标准数据并行中,每个设备都保存完整的模型状态,导致跨设备的冗余存储,并严重限制了可训练模型的规模。
ZeRO 的核心思想是:分片存储、按需加载 。它不再让每块 GPU 都完整保存一整套模型状态,而是将模型状态切分成多个分片,分布式地存储在不同的 GPU 上;在执行某一层的前向或反向传播时,再通过高效的集体通信,按需、临时地从其他设备拉取当前计算所需的分片参数,并在用完后立即释放。
通过这种方式,ZeRO 在保持数据并行高计算效率的前提下:
- 彻底消除了跨设备存储冗余
- 显著减少了每块 GPU 的显存占用
- 使训练的模型规模远超单卡显存限制
因此,ZeRO 成功结合了数据并行的高吞吐与易扩展性和模型并行的内存节省效果,是训练超大规模模型不可或缺的基础技术。
分片策略
训练过程中,需要保存和维护的模型状态主要由以下三部分组成:
➢ 模型参数(Parameters):网络各层的权重与偏置;
➢ 梯度(Gradients):反向传播过程中为更新参数而计算的梯度;
➢ 优化器状态(Optimizer States):如 Adam 的一阶矩、二阶矩等辅助变量。
针对上述部分模型状态,ZeRO 将分片策略划分为三个逐级递进的阶段:
- ZeRO-1:优化器状态分片
- ZeRO-2:优化器状态 + 梯度分片
- ZeRO-3:优化器状态 + 梯度分片 + 模型参数分片
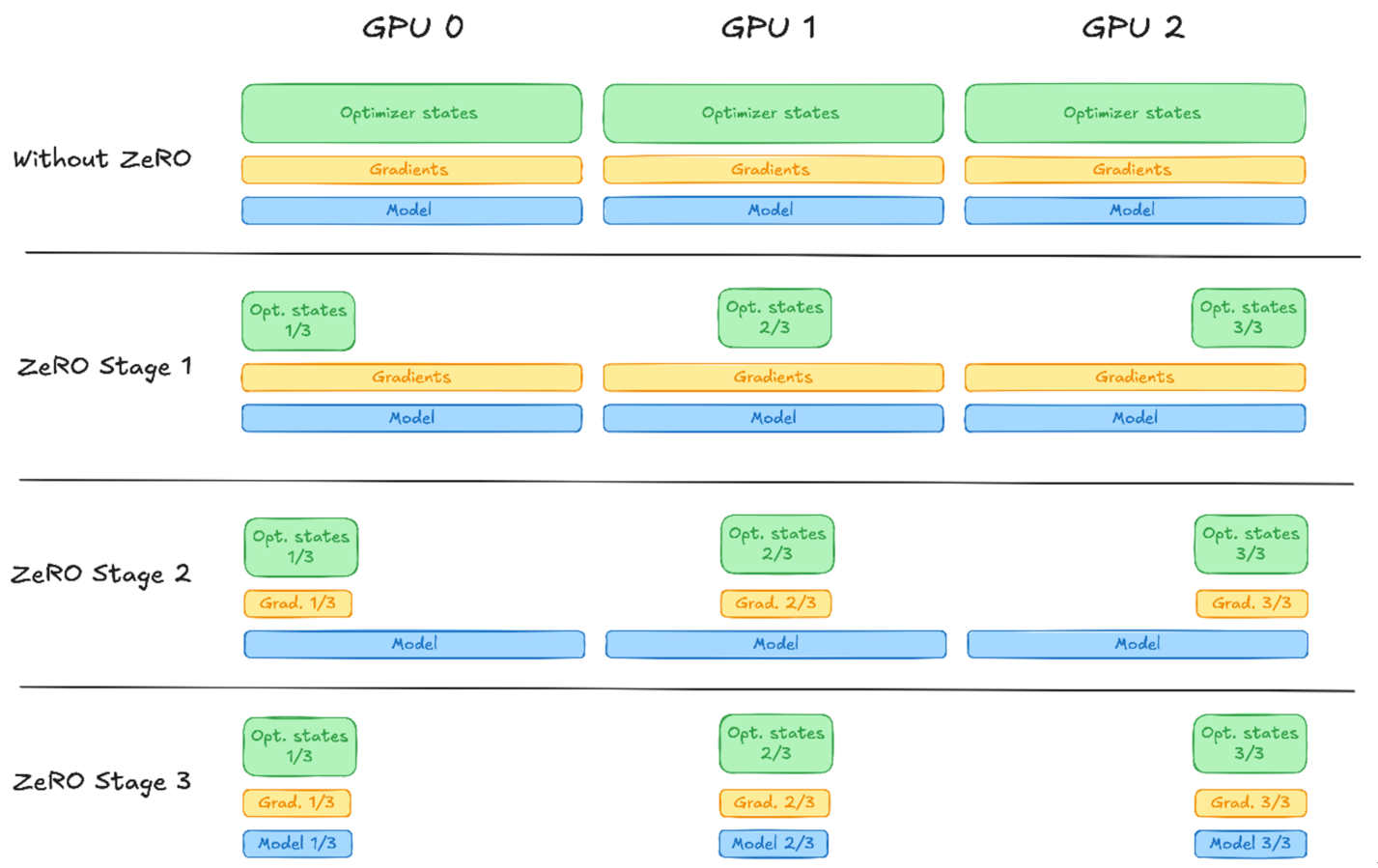
这种分阶段设计的核心意义在于:为显存节省与通信开销之间提供可调节的平衡点。用户可依据硬件资源、模型规模与训练效率等需求,灵活选择不同的分片级别------阶段越高,单卡显存占用越低,但通信成本随之上升;阶段越低,实现更简单、通信压力更小,但显存节省有限。
这种递进式结构使 ZeRO 能够在从中小规模到超大规模的不同训练场景中都保持良好的适配性与扩展性。
实现细节
ZeRO的具体实现细节可参考官方博客。
5.6训练设备选择
训练设备的选择直接决定了微调任务的可行性、效率与成本。本节将介绍主流GPU型号,并提供显存占用的估算方法,以辅助决策。
5.6.1常用GPU型号
当前,大语言模型的训练与微调主要依赖于 NVIDIA 的 GPU,因其具备成熟的 CUDA 生态和高效的计算库。以下是一些常用于 LLM 微调的 GPU 型号:
| 型号 | 显存 | 显存带宽 | Tensor 性能 (BF16/FP16) | 互联带宽 | 发布时间 |
|---|---|---|---|---|---|
| H100 | 80 GB | 3,350 GB/s | 494 TFLOPS | 600 GB/s | 2022 年 3 月 |
| H800 | 80 GB | 1,680 GB/s | 205 TFLOPS | 300 GB/s | 2023 年 3 月 |
| A100 | 40/80 GB | 2,039 GB/s | 156 TFLOPS | 600 GB/s | 2020 年 5 月 |
| A800 | 40/80 GB | 2,039 GB/s | 156 TFLOPS | 300 GB/s | 2022 年 11 月 |
| V100 | 16/32 GB | 900 GB/s | 62.5 TFLOPS | 300 GB/s | 2017 年 5 月 |
| RTX 4090 | 24 GB | 1,008 GB/s | 65 TFLOPS | 无 | 2022 年 10 月 |
| RTX 3090 | 24 GB | 936 GB/s | 35.5 TFLOPS | 无 | 2020 年 9 月 |
5.6.2微调显存估算
说明:由于大型语言模型的内部实现、训练框架的底层优化以及硬件驱动的内存管理机制具有极大的复杂性,任何关于微调所需显存的估算都只能是一个理论上的近似参考,而无法保证精确无误。
显存消耗构成
在对大语言模型(LLM)进行微调时,显存(VRAM)的消耗主要由以下五部分组成:模型参数(Model Weights)、梯度(Gradients)、优化器状态(Optimizer States)、激活值(Activations) 以及 其他运行时开销(Runtime Overhead)。
模型参数(Model Weights)
模型参数指网络中所有可训练权重(如注意力投影矩阵、前馈网络权重等)。在训练过程中,这些参数需常驻显存,用于前向传播与反向传播计算。参数所占显存与模型总参数量和存储精度直接相关。
梯度(Gradients)
在反向传播过程中,每个可训练参数都会计算对应的梯度。梯度张量的形状与参数一致,通常以与参数相同的精度存储,因此其显存占用通常与模型参数相当。
优化器状态(Optimizer States)
现代优化器(如 Adam)为每个可训练参数维护额外的状态变量(例如一阶矩和二阶矩)。这些状态通常以较高精度(如 FP32)存储,显存占用往往是模型参数的数倍,是微调中显存消耗的主要来源之一。
激活值(Activations)
激活值是前向传播中各层输出的中间结果,需在反向传播时用于梯度计算。其显存占用与模型深度、隐藏层维度、输入序列长度、批次大小呈正相关。
其他运行时开销(Runtime Overhead)
包括CUDA 内核临时内存、分布式训练中的通信缓冲区等。
不同微调策略的显存估算
全参微调

LoRA

QLoRA

显存估算工具
可借助一些工具估算显存使用情况,以辅助GPU选型。例如:
https://apxml.com/zh/tools/vram-calculator
5.7微调工具
5.7.1分布式训练
DeepSpeed
DeepSpeed 是微软发布的分布式训练框架,内部集成了多种适用于大规模模型的训练技术。它支持数据并行、流水线并行、张量并行以及专家并行等多种并行方式,并提供 ZeRO 系列优化器,适用于各种规模的训练场景。
Accelerate
Accelerate是 Hugging Face 发布的分布式训练接口,用于对多设备训练过程进行统一封装。它提供一致的训练调用方式,可直接切换 FSDP、DeepSpeed 等不同后端。Accelerate 与 Hugging Face 的 Transformers等工具链天然兼容,可以在多卡或多机环境下快速构建训练流程,简化了分布式训练的实现难度。
5.7.2参数高效微调
PEFT
PEFT 是 Hugging Face 发布的参数高效微调框架,用于在冻结预训练模型主体参数的基础上,通过插入额外的小规模可训练模块来完成微调。框架集成了 LoRA、QLoRA等多种主流的参数高效微调方法,提供统一的调用接口,使这些方法能够方便地应用到各类开源大模型上,显著降低显存和训练资源需求。
unsloth
unsloth 是面向轻量化微调场景的高效训练库,主要针对 LoRA 与 QLoRA 进行了优化实现。它通过内核层面的性能改进与显存管理优化,进一步降低训练过程中的资源占用,并为 Llama、Qwen、Mistral 等开源模型提供了适配与加速支持,使中低显存设备也可以完成参数高效微调任务。该工具可作为 PEFT 的补充,用于实现更高效的微调流程。
5.7.3强化学习与训练工具
TRL
TRL 是 Hugging Face 提供的模型训练库,支持监督微调(SFT)与多种对齐方法(如 DPO、PPO 等)。其与 Transformers、Accelerate、PEFT 无缝集成,可在 Llama、Qwen、Mistral 等开源模型上快速构建微调与对齐流程。该工具在保持灵活性的同时降低了实现难度,适用于 SFT、奖励模型训练与轻量对齐等多类场景。
LLaMA Factory
LLaMA Factory 是一个面向大模型微调的一体化训练框架,提供图形化界面与标准化训练脚本,可显著降低微调流程搭建的复杂度。它支持全参数微调、LoRA/QLoRA 等参数高效微调方法,并集成数据处理、模型加载、训练监控与导出等完整流程。框架适配 Llama、Qwen、Mistral 等主流开源模型,是进行监督微调与轻量化适配的高效工具。
5.8微调实战
略
6.模型部署与评估
6.1vLLM模型部署
6.1.1简介
vLLM 是一个面向大语言模型推理的高性能推理框架,专为大规模并发请求优化,底层基于Pytorch 构建。
vLLM项目主页:https://docs.vllm.ai/en/latest/index.html
Github开源地址:https://github.com/vllm-project/vllm
从各种基准测试数据来看,同等配置下,使用 vLLM 框架与 Transformer 等传统推理库相比,其吞吐量可以提高一个数量级,这归功于以下几个特性:
- 高级 GPU 优化:利用 CUDA 和 PyTorch 最大限度地提高 GPU 利用率,从而实现更快的推理速度。Ollama其实是对CPU-GPU的混合应用,但vllm是针对纯GPU的优化。
- 高级内存管理:通过PagedAttention算法实现对 KV cache的高效管理,减少内存浪费,从而优化大模型的运行效率。
- 批处理功能:支持连续批处理和异步处理,从而提高多个并发请求的吞吐量。
- 安全特性:内置 API 密钥支持和适当的请求验证,不像其他完全跳过身份验证的框架。
- 易用性:vLLM 与 HuggingFace 模型无缝集成,支持多种流行的大型语言模型,并兼容 OpenAI 的 API 服务器。
6.1.2安装
环境要求:
-
OS: Linux
-
Python: 3.9 -- 3.12
创建并激活vllm环境conda create -n vllm_env python=3.11
conda activate vllm_env
安装vllm
pip install vllm -i https://pypi.tuna.tsinghua.edu.cn/simple查看安装信息
pip show vllm6.1.3启动
OpenAI风格API响应模式
启动命令:
vllm serve /root/autodl-tmp/models/Qwen3-8B-sft-all --served-model-name Qwen3-8B-sft-all --max-model-len 32K注意:小写的k,单位是1000;大写的K,单位是1024
如果是基础模型+lora适配器,可加上--enable-lora --lora-modules adapter_v1=<lora目录>
更多选项:https://docs.vllm.ai/en/stable/cli/serve.html#modelconfig
正式运行应后台运行:
nohup vllm serve /root/autodl-tmp/models/Qwen3-8B-sft-all --served-model-name Qwen3-8B-sft-all --max-model-len 32K >vllm.log 2>&1 &6.1.4调用
快速测试
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen3-8B-sft-all",
"messages": [
{"role": "system", "content": "你是个乐于助人的助理。"},
{"role": "user", "content": "我的猫死了,我很难过。"}
]
}'代码调用(openai库)
安装openai库
pip install openai -i https://pypi.tuna.tsinghua.edu.cn/simple测试代码
cpp
from openai import OpenAI
# 连接本地
client = OpenAI(
base_url="http://localhost:8000/v1/",
api_key="none" # 占位符,可忽略
)
# 多轮对话
response = client.chat.completions.create(
model="Qwen3-8B-sft-all", # 指定模型,必须与启动vllm时指定的名字一致
messages=[
# {"role": "user", "content": "我的猫死了,我很难过"}
{"role": "user", "content": "量子计算对RSA加密的威胁与应对策略,请展示你的推理过程在think标签中"}
],
extra_body={
"chat_template_kwargs": {"enable_thinking": False} # 关键参数
}
)
# print(response)
print(response.choices[0].message.content)Langchain调用
安装langchain库
pip install langchain-core langchain-openai -i https://pypi.tuna.tsinghua.edu.cn/simple测试代码
cpp
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
llm = ChatOpenAI(
model="Qwen3-8B-sft-all",
base_url="http://localhost:8000/v1/",
api_key="none",
temperature=0)
# 构建消息(支持多角色)
messages = [
SystemMessage(content="你是一个专业的技术助手,回答需简洁准确"),
HumanMessage(content="LangChain如何调用OpenAI风格的大模型?")
]
# 调用模型获取响应
response = llm.invoke(messages)
print(response.content)6.2EvalScope模型评估
EvalScope 是魔搭社区倾力打造的模型评测与性能基准测试框架,为模型评估需求提供一站式解决方案。
项目官网:https://evalscope.readthedocs.io/zh-cn/latest/index.html
Github地址:https://github.com/modelscope/evalscope
6.2.1安装
创建并激活evalscope环境
conda create -n evalscope python=3.11
conda activate evalscope安装evalscope
pip install evalscope按需安装
pip install 'evalscope[opencompass]' # 安装 OpenCompass backend
pip install 'evalscope[vlmeval]' # 安装 VLMEvalKit backend
pip install 'evalscope[rag]' # 安装 RAGEval backend
pip install 'evalscope[perf]' # 安装 模型压测模块 依赖
pip install 'evalscope[app]' # 安装 可视化 相关依赖
# 或可以直接输入all,安装全部模块
pip install 'evalscope[all]'6.2.2压测
安装压测模块:
pip install 'evalscope[perf]'模型压力测试:
evalscope perf \
--url "http://127.0.0.1:8000/v1/chat/completions" \
--parallel 5 \
--model Qwen3-8B-sft-all \
--number 20 \
--api openai \
--dataset openqa \
--stream参数说明:
- --url 指定被测试的模型服务接口地址。这里是本地(127.0.0.1)8000 端口的 OpenAI 兼容格式聊天接口(vLLM接口)。
- --parallel并发请求数,即同时向模型服务发送请求,用于模拟多用户同时访问的场景。数值越大,压测强度越高。
- --model测试的模型名称(标识用),用于在压测报告中区分不同模型。
- --number总请求数量,本次压测共向模型发送 20 个请求(配合 --parallel 5 时,会分 4 轮发送,每轮 5 个)。
- --api openai 指定接口协议类型为 OpenAI 格式。Evalscope 会按照 OpenAI 的 API 规范(如请求体格式、参数名)构造请求,确保与模型服务兼容。
- --dataset openqa 指定压测使用的数据集。openqa 是开放问答类数据集(如常见的问答对),Evalscope 会从该数据集抽取样本作为输入,向模型发送实际请求(如用问题作为用户输入,测试模型生成回答的性能)。
- --stream 启用流式响应模式。模型会以流的形式逐段返回生成结果(类似 ChatGPT 的打字效果),而非一次性返回完整结果。该参数用于测试模型在流式输出场景下的性能。
压测指标说明:
| 指标项 | 含义 |
|---|---|
| Time taken for tests (s) | 总测试耗时 |
| Number of concurrency | 并发数 |
| Total requests | 总请求数 |
| Succeed requests / Failed requests | 成功与失败数 |
吞吐性能:
| 指标项 | 含义 |
|---|---|
| Output token throughput (tok/s) | 每秒生成 token 数 |
| Total token throughput (tok/s) | 总吞吐(包括输入+输出) |
| Request throughput (req/s) | 每秒处理请求数 |
延迟分析:
| 指标项 | 含义 |
|---|---|
| Average latency (s) | 单次请求平均耗时 |
| Average time to first token (s) | 首 token 延迟 |
| Average time per output token (s) | 每个生成 token 的平均耗时 |
Token分布与批处理
| 指标项 | 含义 |
|---|---|
| Average input tokens per request | 每次输入平均 token 数 |
| Average output tokens per request | 每次输出平均 token 数 |
| Average package latency (s) | 批处理延迟 |
| Average package per request | 每次请求中 token 包含数 |
6.2.3评估
采用了EvalScope专门为Qwen3准备的modelscope/EvalScope-Qwen3-Test数据集进行评测,会围绕模型的推理、指令跟随、代理能力和多语言支持方面能力进行测试,该数据包含mmlu_pro、ifeval、live_code_bench、math_500、aime24等各著名评估数据集。
数据集地址:https://modelscope.cn/datasets/modelscope/EvalScope-Qwen3-Test/summary
也支持用自定义数据集进行评估,参考:https://evalscope.readthedocs.io/zh-cn/latest/advanced_guides/custom_dataset/llm.html#qa
cpp
from evalscope import TaskConfig, run_task
task_cfg = TaskConfig(
model='Qwen3-8B-sft-all', #与vllm启动时指定的模型名一致
api_url='http://127.0.0.1:8000/v1/chat/completions',
eval_type='service',
datasets=[
'data_collection',
],
dataset_args={
'data_collection': {
'dataset_id': 'modelscope/EvalScope-Qwen3-Test',
'filters': {'remove_until': '</think>'} # 过滤掉思考的内容
}
},
eval_batch_size=128,
generation_config={
'max_tokens': 30000, # 最大生成token数,建议设置为较大值避免输出截断
'temperature': 0.6, # 采样温度 (qwen 报告推荐值)
'top_p': 0.95, # top-p采样 (qwen 报告推荐值)
'top_k': 20, # top-k采样 (qwen 报告推荐值)
'n': 1, # 每个请求产生的回复数量
},
timeout=60000, # 超时时间
stream=True, # 是否使用流式输出
limit=200, # 设置为200条数据进行测试
)
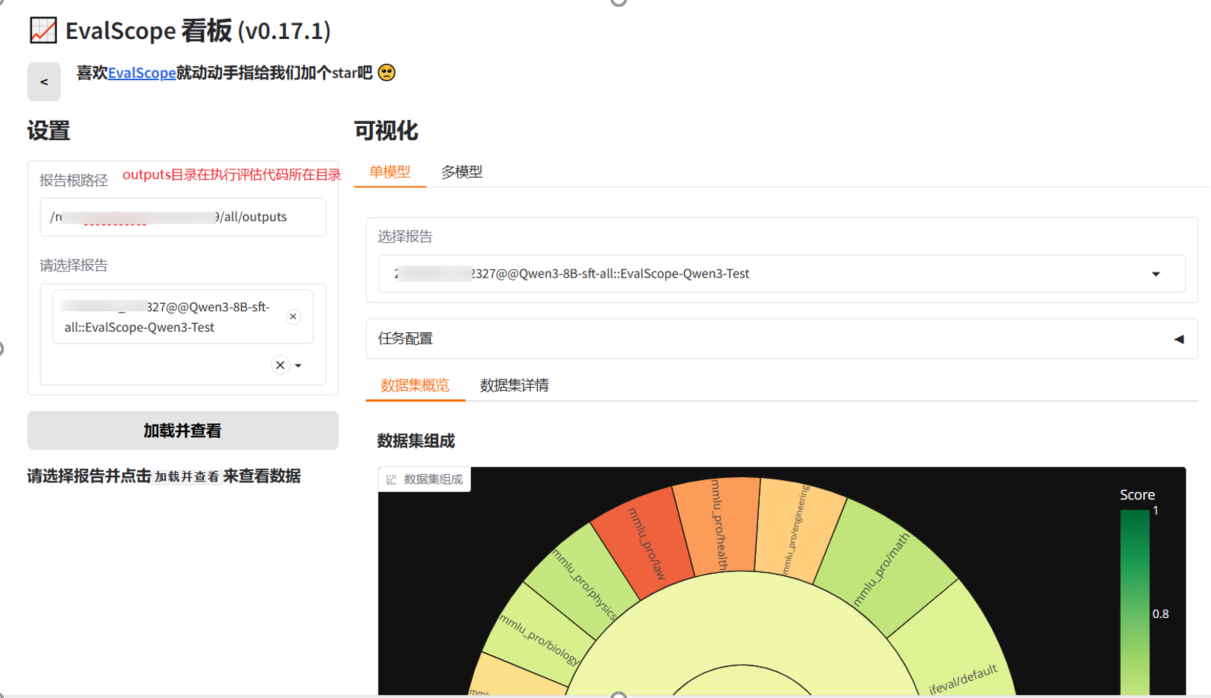
run_task(task_cfg=task_cfg)6.2.4Web查看结果
安装app模块
pip install 'evalscope[app]'启动app模块
evalscope app建立SSH隧道
将6006端口改成evalscope端口即可,windows中执行:
ssh -CNg -L 7860:127.0.0.1:7860 root@connect.bjc1.seetacloud.com -p 30119访问webui:http://localhost:7860
7.附录
7.1RoPE相关公式推导
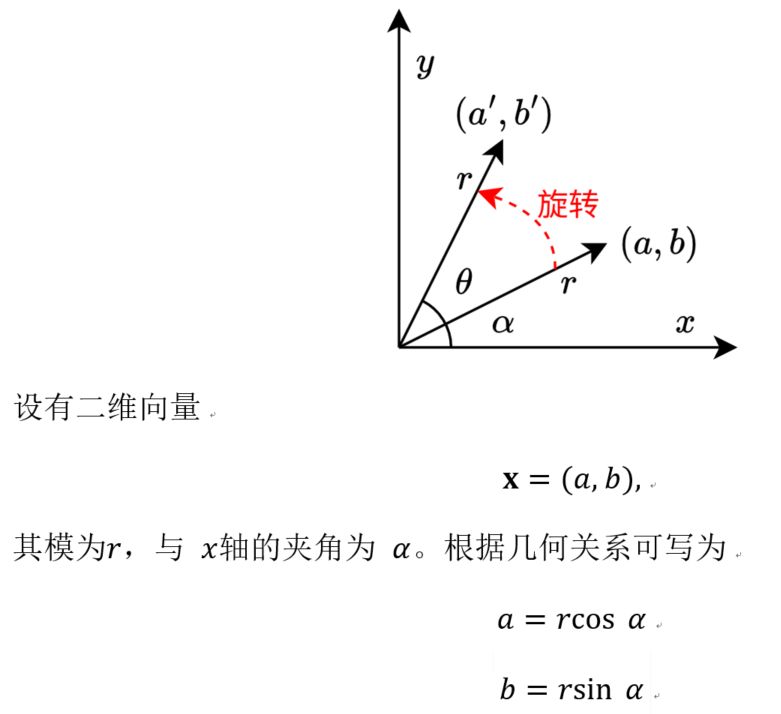
7.1.1旋转矩阵基础
二维向量绕原点的旋转可被视作由特定二维矩阵所描述的线性变换。本节将从向量的几何关系出发,推导这一矩阵的具体结构。

7.1.2旋转矩阵的叠加性

7.1.3旋转矩阵的转置

7.2LoRA相关数学基础
略
矩阵的秩
略
低秩矩阵
略
低秩分解
略