目 录
-
- 摘要
- [1. 引言:浏览器中的 Python 革命](#1. 引言:浏览器中的 Python 革命)
- [2. WebAssembly 技术原理](#2. WebAssembly 技术原理)
-
- [2.1 什么是 WebAssembly](#2.1 什么是 WebAssembly)
- [2.2 WebAssembly 工作原理](#2.2 WebAssembly 工作原理)
- [2.3 WebAssembly 的应用场景](#2.3 WebAssembly 的应用场景)
- [3. Pyodide 深度解析](#3. Pyodide 深度解析)
-
- [3.1 Pyodide 简介](#3.1 Pyodide 简介)
- [3.2 Pyodide 核心特性](#3.2 Pyodide 核心特性)
-
- [3.2.1 完整的 Python 运行时](#3.2.1 完整的 Python 运行时)
- [3.2.2 动态包管理](#3.2.2 动态包管理)
- [3.2.3 Python ⟺ JavaScript 双向互操作](#3.2.3 Python ⟺ JavaScript 双向互操作)
- [3.2.4 异步执行支持](#3.2.4 异步执行支持)
- [3.3 Pyodide 的限制与约束](#3.3 Pyodide 的限制与约束)
- [4. 快速上手:在浏览器中运行 Python](#4. 快速上手:在浏览器中运行 Python)
-
- [4.1 基础集成](#4.1 基础集成)
- [4.2 加载科学计算包](#4.2 加载科学计算包)
- [4.3 动态安装包](#4.3 动态安装包)
- [5. 前后端同构开发实践](#5. 前后端同构开发实践)
-
- [5.1 什么是前后端同构](#5.1 什么是前后端同构)
- [5.2 同构开发架构设计](#5.2 同构开发架构设计)
- [5.3 共享数据验证逻辑示例](#5.3 共享数据验证逻辑示例)
- [5.4 数据处理逻辑共享](#5.4 数据处理逻辑共享)
- [6. 实战案例:浏览器端数据分析应用](#6. 实战案例:浏览器端数据分析应用)
-
- [6.1 项目概述](#6.1 项目概述)
- [6.2 完整实现](#6.2 完整实现)
- [7. 性能优化与最佳实践](#7. 性能优化与最佳实践)
-
- [7.1 加载优化](#7.1 加载优化)
- [7.2 内存管理](#7.2 内存管理)
- [7.3 异步加载策略](#7.3 异步加载策略)
- [8. 生态与替代方案对比](#8. 生态与替代方案对比)
-
- [8.1 Pyodide 与其他方案对比](#8.1 Pyodide 与其他方案对比)
- [8.2 PyScript 简介](#8.2 PyScript 简介)
- [9. 总结](#9. 总结)
- 参考资料
摘要
本文深入探讨 WebAssembly 技术与 Python 语言的融合实践,重点介绍 Pyodide 这一革命性工具如何将完整的 Python 运行时带入浏览器环境。文章从 WebAssembly 的底层原理出发,详细解析 Pyodide 的架构设计与核心特性,包括 Python ⟺ JavaScript 双向互操作、科学计算栈支持、动态包管理等。通过丰富的代码示例和实战案例,展示前后端同构开发的最佳实践,帮助开发者构建真正跨平台的 Python 应用。无论你是希望将现有 Python 项目迁移到前端,还是探索浏览器端数据科学的新可能,本文都将为你提供全面的技术指导。
1. 引言:浏览器中的 Python 革命
在 Web 开发的历史长河中,JavaScript 一直垄断着浏览器端的编程语言市场。Python 作为数据科学、机器学习、后端开发领域的宠儿,却长期被拒之门外。开发者们不得不维护两套代码库:后端用 Python 处理数据和业务逻辑,前端用 JavaScript 构建用户界面。这种分裂带来了代码重复、技能割裂、维护成本高等诸多问题。
WebAssembly 的出现打破了这一僵局。作为一种新兴的 Web 标准,WebAssembly 提供了一种接近原生的执行速度,让浏览器能够运行 C/C++/Rust 等编译型语言编写的代码。Pyodide 项目正是利用这一技术,将 CPython 解释器编译为 WebAssembly 模块,使得 Python 代码可以直接在浏览器中运行。
这一突破的意义远不止于"在浏览器里跑 Python"。它开启了前后端同构的新范式:同一套 Python 代码可以在服务器端和客户端无缝运行,数据处理逻辑可以就近执行,用户隐私数据无需上传服务器即可完成分析。对于数据科学家和 Python 开发者而言,这意味着他们的技能栈可以延伸到前端领域,而无需重新学习 JavaScript 生态。
2. WebAssembly 技术原理
2.1 什么是 WebAssembly
WebAssembly(简称 Wasm)是一种二进制指令格式,设计目标是为 Web 应用提供接近原生的执行性能。它不是一门新的编程语言,而是一种编译目标------开发者可以用 C、C++、Rust 等语言编写代码,然后编译成 WebAssembly 模块,在浏览器中高效执行。
WebAssembly 的核心特性包括:
| 特性 | 说明 | 优势 |
|---|---|---|
| 二进制格式 | 紧凑的二进制编码,而非文本 | 体积小、解析快 |
| 接近原生速度 | 通过 JIT 编译为机器码执行 | 性能接近 C/C++ |
| 安全沙箱 | 在独立的虚拟机环境中运行 | 内存安全、权限隔离 |
| 可移植性 | 跨平台、跨浏览器支持 | 一次编译,到处运行 |
| 与 JS 互操作 | 可与 JavaScript 无缝调用 | 渐进式迁移 |
2.2 WebAssembly 工作原理
WebAssembly 的执行流程可以概括为以下步骤:

当浏览器加载一个 WebAssembly 模块时,会经历以下阶段:
- 获取(Fetch) :通过网络或缓存获取
.wasm二进制文件 - 编译(Compile):将二进制格式编译为浏览器内部的表示形式
- 实例化(Instantiate):创建模块实例,分配内存和表
- 执行(Execute):调用导出的函数执行代码
WebAssembly 模块与 JavaScript 之间通过共享线性内存进行数据交换。这意味着双方可以访问同一块内存区域,实现高效的数据传递。
2.3 WebAssembly 的应用场景
WebAssembly 的应用场景非常广泛:
- 游戏引擎:Unity、Unreal Engine 导出 Web 版本
- 图像/视频处理:FFmpeg、OpenCV 的 Web 版本
- 科学计算:NumPy、SciPy 等数值计算库
- 加密算法:高性能加密解密操作
- 编程语言运行时:Python(Pyodide)、Ruby、PHP 等
3. Pyodide 深度解析
3.1 Pyodide 简介
Pyodide 是一个将 CPython 编译为 WebAssembly 的开源项目,由 Mozilla 在 2018 年发起,现已发展为独立的社区项目。截至 2024 年,Pyodide 已发布到 0.29.3 版本,支持 Python 3.11,并包含了大量科学计算包的预编译版本。
Pyodide 的核心组成包括:
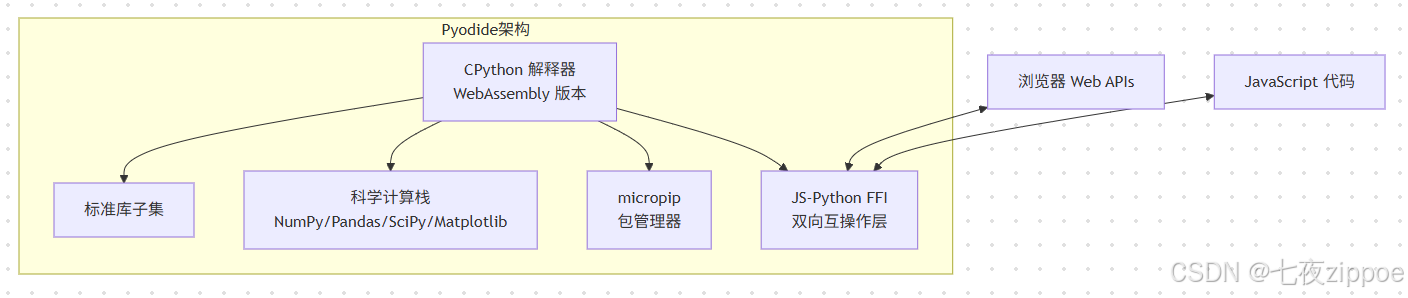
3.2 Pyodide 核心特性
3.2.1 完整的 Python 运行时
Pyodide 不仅仅是 Python 语法的子集实现,而是完整的 CPython 解释器。这意味着:
- ✅ 支持完整的 Python 语法
- ✅ 支持大部分标准库模块
- ✅ 支持异常处理、生成器、装饰器等高级特性
- ✅ 支持 async/await 异步编程
3.2.2 动态包管理
Pyodide 内置了 micropip 包管理器,支持动态安装 PyPI 上的纯 Python 包:
python
import micropip
# 安装纯 Python 包
await micropip.install('markdown')
# 安装特定版本
await micropip.install('numpy==1.24.0')
# 从 URL 安装
await micropip.install('https://example.com/package.whl')对于包含 C/C++ 扩展的包,Pyodide 提供了大量预编译版本,包括:
| 包名 | 用途 | 状态 |
|---|---|---|
| NumPy | 数值计算 | ✅ 完全支持 |
| Pandas | 数据分析 | ✅ 完全支持 |
| SciPy | 科学计算 | ✅ 完全支持 |
| Matplotlib | 数据可视化 | ✅ 完全支持 |
| scikit-learn | 机器学习 | ✅ 完全支持 |
| Pillow | 图像处理 | ✅ 完全支持 |
3.2.3 Python ⟺ JavaScript 双向互操作
Pyodide 提供了强大的 JavaScript 与 Python 互操作能力,这是其最核心的特性之一。
Python 调用 JavaScript:
python
import js
# 访问浏览器 API
js.console.log("Hello from Python!")
# 操作 DOM
document = js.document
element = document.createElement('div')
element.innerHTML = '<h1>Python created this!</h1>'
document.body.appendChild(element)
# 使用 JavaScript 库
js.alert("This is an alert from Python")
# 访问 window 对象
js.window.location.hrefJavaScript 调用 Python:
javascript
// 从 JavaScript 运行 Python 代码
let result = await pyodide.runPythonAsync(`
import math
math.sqrt(16)
`);
console.log(result); // 4.0
// 访问 Python 对象
pyodide.runPython(`
def greet(name):
return f"Hello, {name}!"
`);
let greeting = pyodide.globals.get('greet')('World');
console.log(greeting); // "Hello, World!"3.2.4 异步执行支持
Pyodide 完整支持 Python 的 async/await 语法,并能与 JavaScript 的 Promise 无缝对接:
python
import asyncio
import js
async def fetch_data():
# 使用 JavaScript fetch API
response = await js.fetch('https://api.example.com/data')
data = await response.json()
return data
# 在 Python 中使用
result = await fetch_data()3.3 Pyodide 的限制与约束
虽然 Pyodide 功能强大,但也有一些限制需要注意:
| 限制 | 原因 | 解决方案 |
|---|---|---|
| 启动时间较长 | 需要加载完整的 Python 运行时 | 使用 CDN 加速、预加载 |
| 内存占用较大 | WebAssembly 内存模型限制 | 优化数据结构、及时释放 |
| 不支持多线程 | WebAssembly 线程支持有限 | 使用 Web Workers |
| 部分包不兼容 | C 扩展需要专门编译 | 使用替代包或自行编译 |
| 文件系统受限 | 浏览器安全限制 | 使用虚拟文件系统 |
4. 快速上手:在浏览器中运行 Python
4.1 基础集成
最简单的使用方式是通过 CDN 加载 Pyodide:
html
<!DOCTYPE html>
<html>
<head>
<title>Pyodide Demo</title>
</head>
<body>
<h1>Python in Browser</h1>
<textarea id="code" rows="10" cols="50">
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
print(f"Mean: {np.mean(arr)}")
print(f"Std: {np.std(arr)}")
</textarea>
<button id="run">Run Python</button>
<pre id="output"></pre>
<script src="https://cdn.jsdelivr.net/pyodide/v0.24.1/full/pyodide.js"></script>
<script>
let pyodide;
async function initPyodide() {
pyodide = await loadPyodide({
indexURL: "https://cdn.jsdelivr.net/pyodide/v0.24.1/full/"
});
console.log("Pyodide loaded!");
}
document.getElementById('run').addEventListener('click', async () => {
const code = document.getElementById('code').value;
// 重定向 stdout
pyodide.runPython(`
import sys
from io import StringIO
sys.stdout = StringIO()
`);
try {
await pyodide.runPythonAsync(code);
const output = pyodide.runPython('sys.stdout.getvalue()');
document.getElementById('output').textContent = output;
} catch (err) {
document.getElementById('output').textContent = `Error: ${err.message}`;
}
});
initPyodide();
</script>
</body>
</html>上述代码展示了 Pyodide 的基本使用流程。首先通过 CDN 加载 Pyodide 运行时,然后使用 runPythonAsync 方法执行 Python 代码。通过重定向 sys.stdout,我们可以捕获 Python 的输出并显示在页面上。
4.2 加载科学计算包
Pyodide 预装了常用的科学计算包,可以直接导入使用:
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 创建数据
data = pd.DataFrame({
'x': np.linspace(0, 10, 100),
'y': np.sin(np.linspace(0, 10, 100))
})
# 绘制图表
plt.figure(figsize=(10, 6))
plt.plot(data['x'], data['y'])
plt.title('Sine Wave')
plt.xlabel('X')
plt.ylabel('Y')
# 在浏览器中显示
import js
from io import BytesIO
import base64
buf = BytesIO()
plt.savefig(buf, format='png')
buf.seek(0)
img_base64 = base64.b64encode(buf.read()).decode()
# 创建图片元素
img = js.document.createElement('img')
img.src = f'data:image/png;base64,{img_base64}'
js.document.body.appendChild(img)这段代码演示了如何在浏览器中使用 NumPy、Pandas 和 Matplotlib 进行数据处理和可视化。最终生成的图表通过 base64 编码嵌入到 HTML 中显示。
4.3 动态安装包
对于未预装的包,可以使用 micropip 动态安装:
python
import micropip
# 安装并使用 markdown 库
await micropip.install('markdown')
import markdown
html = markdown.markdown("""
# Hello Pyodide
This is **markdown** rendered in the browser!
- Item 1
- Item 2
- Item 3
""")
# 显示渲染结果
import js
div = js.document.createElement('div')
div.innerHTML = html
js.document.body.appendChild(div)5. 前后端同构开发实践
5.1 什么是前后端同构
前后端同构(Isomorphic/Universal)是指同一套代码可以在服务器端和客户端运行的开发模式。这种模式的优势包括:

| 优势 | 说明 |
|---|---|
| 代码复用 | 数据处理、业务逻辑只需编写一次 |
| SEO 友好 | 服务端渲染提供完整的 HTML 内容 |
| 首屏性能 | 服务端渲染减少客户端计算压力 |
| 开发效率 | 一套技术栈,减少上下文切换 |
| 类型一致 | 前后端使用相同的数据类型定义 |
5.2 同构开发架构设计
以下是一个典型的前后端同构 Python 项目架构:
project/
├── shared/ # 共享代码
│ ├── models.py # 数据模型
│ ├── validators.py # 验证逻辑
│ ├── utils.py # 工具函数
│ └── api_client.py # API 客户端
├── server/ # 服务端代码
│ ├── main.py # FastAPI 入口
│ ├── routes.py # 路由定义
│ └── templates.py # 模板渲染
├── client/ # 客户端代码
│ ├── index.html # 入口页面
│ ├── app.py # 前端应用逻辑
│ └── components.py # UI 组件
└── pyproject.toml # 项目配置5.3 共享数据验证逻辑示例
以下示例展示如何在前后端共享数据验证逻辑:
python
# shared/validators.py
from dataclasses import dataclass
from typing import List, Optional
import re
@dataclass
class ValidationResult:
is_valid: bool
errors: List[str]
class UserValidator:
"""用户数据验证器 - 前后端共用"""
@staticmethod
def validate_email(email: str) -> ValidationResult:
errors = []
if not email:
errors.append("邮箱不能为空")
elif not re.match(r'^[\w\.-]+@[\w\.-]+\.\w+$', email):
errors.append("邮箱格式不正确")
return ValidationResult(len(errors) == 0, errors)
@staticmethod
def validate_password(password: str) -> ValidationResult:
errors = []
if len(password) < 8:
errors.append("密码长度至少8位")
if not re.search(r'[A-Z]', password):
errors.append("密码需包含大写字母")
if not re.search(r'[a-z]', password):
errors.append("密码需包含小写字母")
if not re.search(r'\d', password):
errors.append("密码需包含数字")
return ValidationResult(len(errors) == 0, errors)
@staticmethod
def validate_username(username: str) -> ValidationResult:
errors = []
if len(username) < 3 or len(username) > 20:
errors.append("用户名长度需在3-20位之间")
if not re.match(r'^[a-zA-Z0-9_]+$', username):
errors.append("用户名只能包含字母、数字和下划线")
return ValidationResult(len(errors) == 0, errors)服务端使用:
python
# server/routes.py
from fastapi import FastAPI, HTTPException
from shared.validators import UserValidator
app = FastAPI()
@app.post("/api/register")
async def register(user_data: dict):
# 使用共享验证器
email_result = UserValidator.validate_email(user_data.get('email', ''))
password_result = UserValidator.validate_password(user_data.get('password', ''))
username_result = UserValidator.validate_username(user_data.get('username', ''))
errors = []
if not email_result.is_valid:
errors.extend(email_result.errors)
if not password_result.is_valid:
errors.extend(password_result.errors)
if not username_result.is_valid:
errors.extend(username_result.errors)
if errors:
raise HTTPException(status_code=400, detail=errors)
# 验证通过,继续处理...
return {"status": "success"}客户端使用:
python
# client/app.py
import js
from shared.validators import UserValidator
def on_form_submit(event):
"""表单提交处理 - 前端验证"""
form = js.document.getElementById('register-form')
email = form.email.value
password = form.password.value
username = form.username.value
# 使用相同的验证器
results = [
UserValidator.validate_email(email),
UserValidator.validate_password(password),
UserValidator.validate_username(username)
]
# 显示验证错误
error_div = js.document.getElementById('errors')
error_div.innerHTML = ''
all_valid = True
for result in results:
if not result.is_valid:
all_valid = False
for error in result.errors:
p = js.document.createElement('p')
p.textContent = error
p.className = 'error'
error_div.appendChild(p)
if all_valid:
# 前端验证通过,提交到服务器
submit_to_server(email, password, username)
# 绑定事件
js.document.getElementById('submit-btn').addEventListener('click', on_form_submit)5.4 数据处理逻辑共享
除了验证逻辑,数据处理逻辑也可以前后端共享:
python
# shared/data_processor.py
import numpy as np
from typing import List, Dict, Any
from dataclasses import dataclass
@dataclass
class DataPoint:
timestamp: float
value: float
label: str
class TimeSeriesProcessor:
"""时间序列数据处理器 - 前后端共用"""
@staticmethod
def normalize(data: List[DataPoint]) -> List[DataPoint]:
"""归一化处理"""
values = [d.value for d in data]
min_val, max_val = min(values), max(values)
range_val = max_val - min_val if max_val != min_val else 1
return [
DataPoint(
timestamp=d.timestamp,
value=(d.value - min_val) / range_val,
label=d.label
)
for d in data
]
@staticmethod
def moving_average(data: List[DataPoint], window: int = 5) -> List[DataPoint]:
"""移动平均"""
values = np.array([d.value for d in data])
weights = np.ones(window) / window
smoothed = np.convolve(values, weights, mode='valid')
return [
DataPoint(
timestamp=data[i + window - 1].timestamp,
value=float(smoothed[i]),
label=data[i + window - 1].label
)
for i in range(len(smoothed))
]
@staticmethod
def detect_anomalies(data: List[DataPoint], threshold: float = 2.0) -> List[Dict[str, Any]]:
"""异常检测"""
values = np.array([d.value for d in data])
mean, std = np.mean(values), np.std(values)
anomalies = []
for i, d in enumerate(data):
z_score = abs((d.value - mean) / std) if std > 0 else 0
if z_score > threshold:
anomalies.append({
'index': i,
'timestamp': d.timestamp,
'value': d.value,
'z_score': z_score
})
return anomalies6. 实战案例:浏览器端数据分析应用
6.1 项目概述
下面我们构建一个完整的浏览器端数据分析应用,用户可以上传 CSV 文件,在浏览器中进行数据清洗、分析和可视化,所有计算都在本地完成,数据无需上传服务器。
6.2 完整实现
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>浏览器端数据分析工具</title>
<style>
* { box-sizing: border-box; margin: 0; padding: 0; }
body { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, sans-serif; background: #f5f5f5; padding: 20px; }
.container { max-width: 1200px; margin: 0 auto; }
h1 { text-align: center; margin-bottom: 20px; color: #333; }
.upload-area { background: white; border: 2px dashed #ccc; border-radius: 8px; padding: 40px; text-align: center; margin-bottom: 20px; }
.upload-area.dragover { border-color: #4CAF50; background: #f0fff0; }
.stats-grid { display: grid; grid-template-columns: repeat(auto-fit, minmax(200px, 1fr)); gap: 15px; margin-bottom: 20px; }
.stat-card { background: white; border-radius: 8px; padding: 20px; box-shadow: 0 2px 4px rgba(0,0,0,0.1); }
.stat-card h3 { color: #666; font-size: 14px; margin-bottom: 8px; }
.stat-card .value { font-size: 28px; font-weight: bold; color: #333; }
.chart-container { background: white; border-radius: 8px; padding: 20px; margin-bottom: 20px; }
.chart-container img { max-width: 100%; height: auto; }
.loading { text-align: center; padding: 40px; }
.spinner { border: 4px solid #f3f3f3; border-top: 4px solid #3498db; border-radius: 50%; width: 40px; height: 40px; animation: spin 1s linear infinite; margin: 0 auto 10px; }
@keyframes spin { 0% { transform: rotate(0deg); } 100% { transform: rotate(360deg); } }
table { width: 100%; border-collapse: collapse; background: white; border-radius: 8px; overflow: hidden; }
th, td { padding: 12px; text-align: left; border-bottom: 1px solid #eee; }
th { background: #f8f9fa; font-weight: 600; }
tr:hover { background: #f5f5f5; }
</style>
</head>
<body>
<div class="container">
<h1>📊 浏览器端数据分析工具</h1>
<div class="upload-area" id="upload-area">
<p>拖拽 CSV 文件到此处,或点击选择文件</p>
<input type="file" id="file-input" accept=".csv" style="display: none;">
<p style="color: #999; font-size: 12px; margin-top: 10px;">所有数据处理在本地完成,数据不会上传到服务器</p>
</div>
<div id="loading" class="loading" style="display: none;">
<div class="spinner"></div>
<p>正在加载数据分析引擎...</p>
</div>
<div id="results" style="display: none;">
<div class="stats-grid" id="stats-grid"></div>
<div class="chart-container" id="chart-container"></div>
<div style="overflow-x: auto;">
<table id="data-table"></table>
</div>
</div>
</div>
<script src="https://cdn.jsdelivr.net/pyodide/v0.24.1/full/pyodide.js"></script>
<script>
let pyodide;
async function initPyodide() {
document.getElementById('loading').style.display = 'block';
pyodide = await loadPyodide({
indexURL: "https://cdn.jsdelivr.net/pyodide/v0.24.1/full/"
});
await pyodide.loadPackage(['pandas', 'matplotlib']);
document.getElementById('loading').style.display = 'none';
console.log('Pyodide ready!');
}
async function analyzeData(csvContent, fileName) {
const code = `
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from io import StringIO, BytesIO
import base64
import json
# 读取数据
df = pd.read_csv(StringIO("""${csvContent.replace(/"/g, '""')}"""))
# 基础统计
stats = {
'rows': len(df),
'columns': len(df.columns),
'numeric_cols': len(df.select_dtypes(include=[np.number]).columns),
'missing_values': int(df.isnull().sum().sum())
}
# 数值列统计
numeric_df = df.select_dtypes(include=[np.number])
if len(numeric_df.columns) > 0:
stats['mean'] = float(numeric_df.mean().mean())
stats['std'] = float(numeric_df.std().mean())
# 生成可视化
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# 缺失值热图
if df.isnull().sum().sum() > 0:
import seaborn as sns
sns.heatmap(df.isnull(), cbar=True, yticklabels=False, ax=axes[0])
axes[0].set_title('Missing Values Heatmap')
else:
axes[0].text(0.5, 0.5, 'No Missing Values', ha='center', va='center', fontsize=14)
axes[0].set_title('Data Quality')
# 数值列分布
if len(numeric_df.columns) > 0:
numeric_df.iloc[:, :5].hist(ax=axes[1], bins=20, edgecolor='black')
axes[1].set_title('Distribution of Numeric Columns')
else:
axes[1].text(0.5, 0.5, 'No Numeric Columns', ha='center', va='center', fontsize=14)
axes[1].set_title('Distribution')
plt.tight_layout()
# 保存图表
buf = BytesIO()
plt.savefig(buf, format='png', dpi=100)
buf.seek(0)
chart_base64 = base64.b64encode(buf.read()).decode()
# 获取前10行数据
preview = df.head(10).to_dict('records')
result = {
'stats': stats,
'chart': chart_base64,
'columns': list(df.columns),
'preview': preview
}
result
`;
const result = await pyodide.runPythonAsync(code);
return result.toJs();
}
function displayResults(data) {
// 显示统计卡片
const statsGrid = document.getElementById('stats-grid');
const statsHtml = \`
<div class="stat-card">
<h3>总行数</h3>
<div class="value">\${data.stats.rows.toLocaleString()}</div>
</div>
<div class="stat-card">
<h3>总列数</h3>
<div class="value">\${data.stats.columns}</div>
</div>
<div class="stat-card">
<h3>数值列</h3>
<div class="value">\${data.stats.numeric_cols}</div>
</div>
<div class="stat-card">
<h3>缺失值</h3>
<div class="value">\${data.stats.missing_values}</div>
</div>
\`;
statsGrid.innerHTML = statsHtml;
// 显示图表
const chartContainer = document.getElementById('chart-container');
chartContainer.innerHTML = \`<img src="data:image/png;base64,\${data.chart}" alt="数据分析图表">\`;
// 显示数据表格
const table = document.getElementById('data-table');
let tableHtml = '<thead><tr>';
data.columns.forEach(col => {
tableHtml += \`<th>\${col}</th>\`;
});
tableHtml += '</tr></thead><tbody>';
data.preview.forEach(row => {
tableHtml += '<tr>';
data.columns.forEach(col => {
const value = row[col];
tableHtml += \`<td>\${value !== null ? value : '<em style="color:#999">null</em>'}</td>\`;
});
tableHtml += '</tr>';
});
tableHtml += '</tbody>';
table.innerHTML = tableHtml;
document.getElementById('results').style.display = 'block';
}
// 文件上传处理
const uploadArea = document.getElementById('upload-area');
const fileInput = document.getElementById('file-input');
uploadArea.addEventListener('click', () => fileInput.click());
uploadArea.addEventListener('dragover', (e) => {
e.preventDefault();
uploadArea.classList.add('dragover');
});
uploadArea.addEventListener('dragleave', () => {
uploadArea.classList.remove('dragover');
});
uploadArea.addEventListener('drop', async (e) => {
e.preventDefault();
uploadArea.classList.remove('dragover');
const file = e.dataTransfer.files[0];
if (file && file.name.endsWith('.csv')) {
const content = await file.text();
const result = await analyzeData(content, file.name);
displayResults(result);
}
});
fileInput.addEventListener('change', async (e) => {
const file = e.target.files[0];
if (file) {
const content = await file.text();
const result = await analyzeData(content, file.name);
displayResults(result);
}
});
// 初始化
initPyodide();
</script>
</body>
</html>上述代码实现了一个完整的浏览器端数据分析工具,主要功能包括:
- 文件上传:支持拖拽上传和点击选择 CSV 文件
- 数据统计:自动计算行数、列数、缺失值等基础统计
- 数据可视化:生成缺失值热图和数值分布直方图
- 数据预览:以表格形式展示前 10 行数据
所有数据处理都在浏览器本地完成,用户数据不会上传到任何服务器,保护了用户隐私。
7. 性能优化与最佳实践
7.1 加载优化
Pyodide 的主要性能瓶颈在于初始加载时间。以下是一些优化策略:

使用 Service Worker 缓存:
javascript
// service-worker.js
const PYODIDE_VERSION = '0.24.1';
const PYODIDE_CACHE = 'pyodide-cache-v1';
self.addEventListener('install', (event) => {
const filesToCache = [
`https://cdn.jsdelivr.net/pyodide/v${PYODIDE_VERSION}/full/pyodide.js`,
`https://cdn.jsdelivr.net/pyodide/v${PYODIDE_VERSION}/full/pyodide.asm.wasm`,
`https://cdn.jsdelivr.net/pyodide/v${PYODIDE_VERSION}/full/pyodide.asm.data`,
`https://cdn.jsdelivr.net/pyodide/v${PYODIDE_VERSION}/full/python_stdlib.zip`,
];
event.waitUntil(
caches.open(PYODIDE_CACHE).then((cache) => {
return cache.addAll(filesToCache);
})
);
});
self.addEventListener('fetch', (event) => {
if (event.request.url.includes('pyodide')) {
event.respondWith(
caches.match(event.request).then((response) => {
return response || fetch(event.request);
})
);
}
});7.2 内存管理
WebAssembly 的内存是线性且有限的,需要注意内存管理:
python
# 及时释放大对象
import gc
def process_large_data(data):
# 处理数据
result = heavy_computation(data)
# 显式释放
del data
gc.collect()
return result
# 使用生成器处理大数据
def batch_process(data, batch_size=1000):
for i in range(0, len(data), batch_size):
yield process_batch(data[i:i+batch_size])7.3 异步加载策略
对于复杂应用,可以采用异步加载策略:
javascript
// 先加载核心运行时,再按需加载包
async function initPyodideLite() {
pyodide = await loadPyodide({
indexURL: CDN_URL,
packages: [] // 不预加载任何包
});
}
async function loadPackageOnDemand(packageName) {
showLoadingIndicator();
await pyodide.loadPackage(packageName);
hideLoadingIndicator();
}
// 用户触发特定功能时再加载
document.getElementById('analyze-btn').addEventListener('click', async () => {
await loadPackageOnDemand('pandas');
await loadPackageOnDemand('matplotlib');
// 执行分析...
});8. 生态与替代方案对比
8.1 Pyodide 与其他方案对比
| 方案 | 运行方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Pyodide | WebAssembly | 完整 Python、支持科学计算栈 | 加载慢、体积大 | 数据分析、科学计算 |
| PyScript | 基于 Pyodide | 更简单的 API、组件化 | 依赖 Pyodide | 快速原型开发 |
| Brython | 编译为 JS | 轻量、加载快 | 不支持 C 扩展 | 简单交互 |
| Transcrypt | 预编译为 JS | 性能好、体积小 | 需要构建步骤 | 生产环境 |
| Skulpt | JS 实现 | 纯 JS、易集成 | 功能有限 | 教育场景 |
8.2 PyScript 简介
PyScript 是 Anaconda 推出的基于 Pyodide 的上层框架,提供了更简洁的 API:
html
<!DOCTYPE html>
<html>
<head>
<link rel="stylesheet" href="https://pyscript.net/releases/2024.1.1/core.css">
<script type="module" src="https://pyscript.net/releases/2024.1.1/core.js"></script>
</head>
<body>
<py-config>
packages = ["numpy", "pandas"]
</py-config>
<py-script>
import numpy as np
import pandas as pd
# 直接在 HTML 中写 Python
df = pd.DataFrame({
'A': np.random.rand(5),
'B': np.random.rand(5)
})
print(df.describe())
</py-script>
</body>
</html>9. 总结
WebAssembly 与 Python 的结合为 Web 开发开辟了新的可能性。Pyodide 作为这一领域的先行者,让 Python 开发者能够将他们的技能和代码带到浏览器端,实现了真正的前后端同构开发。
本文的核心要点如下:
-
WebAssembly 原理:作为一种二进制指令格式,WebAssembly 提供了接近原生的执行性能,让编译型语言能够在浏览器中高效运行。
-
Pyodide 核心特性:完整的 CPython 运行时、动态包管理、Python ⟺ JavaScript 双向互操作、科学计算栈支持,使其成为浏览器端 Python 的首选方案。
-
前后端同构实践:通过共享数据验证、数据处理等逻辑,减少代码重复,提高开发效率,同时保证了前后端行为的一致性。
-
性能优化策略:使用 Service Worker 缓存、按需加载包、合理的内存管理,可以有效缓解 Pyodide 加载慢的问题。
-
实战应用:构建了完整的浏览器端数据分析工具,展示了 Pyodide 在实际项目中的应用价值。
思考题
- 在你的项目中,有哪些数据处理逻辑可以提取为前后端共享代码?
- 对于需要处理敏感数据的应用,浏览器端计算是否能满足安全需求?
- 如果要将现有的 Python 后端服务迁移到浏览器端,需要考虑哪些限制?