引言:
在前面的章节中,我们已经掌握了如何使用 CUDA 编程模型来表达并行性。我们习惯了将一个庞大的计算任务划分为一个线程网格 (Grid) ,并将网格进一步细分为多个线程块 (Block) ,每个块中包含数百个并发执行的线程 (Thread)。这种以数据为中心的软件抽象非常优雅,它让程序员可以摆脱底层硬件的繁文缛节,专注于算法的逻辑。
然而,软件模型只是一个"美好的蓝图"。当我们调用内核函数(Kernel Launch)时,这些成千上万、甚至数以百万计的虚拟线程,必须被映射到真实存在的、物理资源有限的硅片上。理解这一映射过程,是区分"能写出并行代码的程序员"和"能写出高性能并行代码的架构师"的关键。
软件抽象与硬件实体的核心对应关系
在 NVIDIA 的 GPU 架构中,有一个极其严谨且巧妙的映射机制。为了最大化吞吐量并隐藏延迟,GPU 采用了有别于传统多核 CPU 的设计哲学。我们要理解的核心映射关系如下:
-
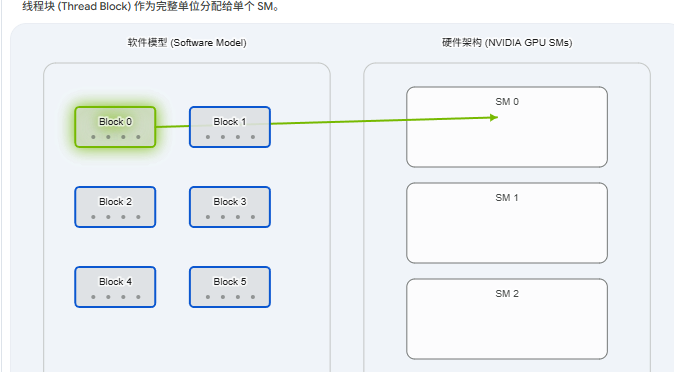
Grid -> GPU 设备:当你启动一个内核(Kernel)时,整个线程网格(Grid)会被发送到整个 GPU 设备上执行。
-
Block -> 流多处理器 (Streaming Multiprocessor, SM) :这是最关键的映射层级。GPU 的调度器会将一个线程块(Block)作为一个不可分割的整体,分配给 GPU 内部的某个流多处理器(SM)。一个 Block 一旦被分配给某个 SM,它的整个生命周期都将在这个 SM 上度过,直到执行完毕。 它不能在半途迁移到其他 SM。
-
Thread -> CUDA 核心 (CUDA Cores) / 执行单元:线程块内的各个线程,最终会被分配到 SM 内部的各个计算核心(如 ALU、FPU)上进行实际的指令运算。(注:在实际调度中,线程是以 Warp 为单位进行发射的,这一点我们将在后文深入探讨)。
为什么这种映射至关重要?
理解这种"Block 分配到 SM"的机制,能够解释我们在实际编程中遇到的很多性能现象:
-
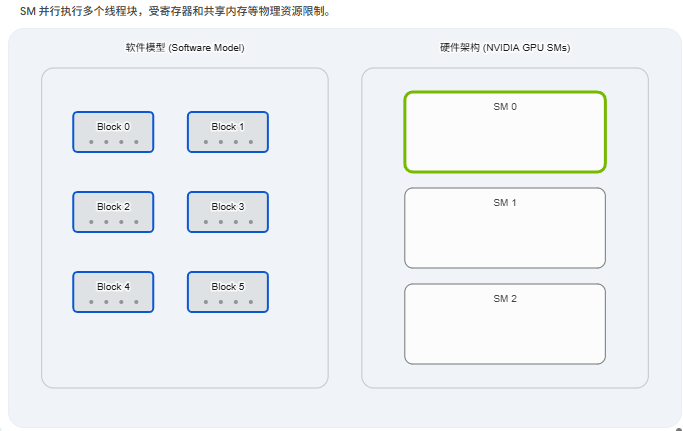
资源受限: 一个 SM 上的寄存器(Registers)和共享内存(Shared Memory)是有限的物理资源。如果你的一个 Block 需要消耗大量的共享内存,那么一个 SM 能同时接纳的 Block 数量就会大大减少,从而降低了并行度。
-
同步范围: 为什么
__syncthreads()只能同步同一个 Block 内的线程,而不能同步整个 Grid?因为不同的 Block 可能被分配到了不同的 SM 上,甚至有些 Block 还在队列中等待,它们在物理上并没有共享快速的同步路径。
第一节: SIMT 执行模型与 Warp(线程束)
在上一节中,我们知道了线程块(Block)会被分配到 SM 上执行。但是,SM 内部并不是为每一个虚拟线程分配一个独立的物理核心和独立的指令指针。为了在有限的硅片面积上塞入成千上万个计算核心,GPU 必须在控制逻辑上做出极大的精简。
NVIDIA 解决这个问题的方案是 SIMT(Single Instruction, Multiple Threads,单指令多线程) 架构。而 SIMT 架构在硬件上落地的最小执行单位,就是 Warp(线程束)。
注:在 AMD GPU 架构中,类似的概念被称为 Wavefront,通常包含 32 或 64 个线程。这里以 NVIDIA 架构的 32 线程 Warp 为例进行讲解。
1 什么是 Warp?
无论你在 CUDA 代码中将一个线程块配置为多少个线程(例如 128、256 或 512 个),当这个线程块被分配到 SM 上时,硬件会自动将其按照线程索引(Thread ID)的线性顺序,划分为若干个包含 32 个连续线程 的组。这个组就被称为一个 Warp。
-
例子:如果你的 Block 有 128 个线程,硬件会将其划分为 4 个 Warp:
-
Warp 0: 线程 0 ~ 31
-
Warp 1: 线程 32 ~ 63
-
Warp 2: 线程 64 ~ 95
-
Warp 3: 线程 96 ~ 127
-
Warp 是 SM 中进行指令获取、调度和执行的绝对最小单位。 硬件甚至"看不到"单个独立的线程,它眼里只有一个个排队的 Warp。
2.Lockstep 执行机制
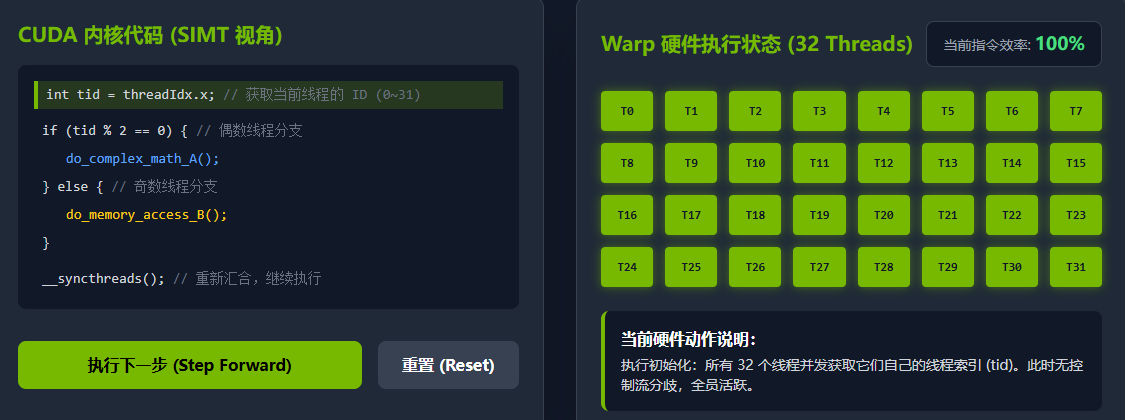
SIMT 架构最核心的法则是:同一个 Warp 内的 32 个线程,共享同一个指令指针(Program Counter, PC)。
这意味着,在任何一个给定的时钟周期内,这 32 个线程必须执行完全相同的一条指令 。它们唯一的区别在于:每个线程拥有自己独立的寄存器状态,因此它们在执行同一条指令时,操作的数据是不同的(这类似于传统的 SIMD 向量化运算,但对程序员来说抽象成了独立的标量线程)。
你可以将 Warp 想象成一支 32 人的仪仗队,指挥官(Warp 调度器)下达一个口令(指令),这 32 个人必须同时做出相同的动作。
3 控制流的代价:分支发散 (Branch Divergence)
既然 Warp 内的 32 个线程必须"同上同下"执行同一条指令,那么当我们的代码中遇到条件判断语句(如 if-else)时,会发生什么?
假设我们有如下代码:
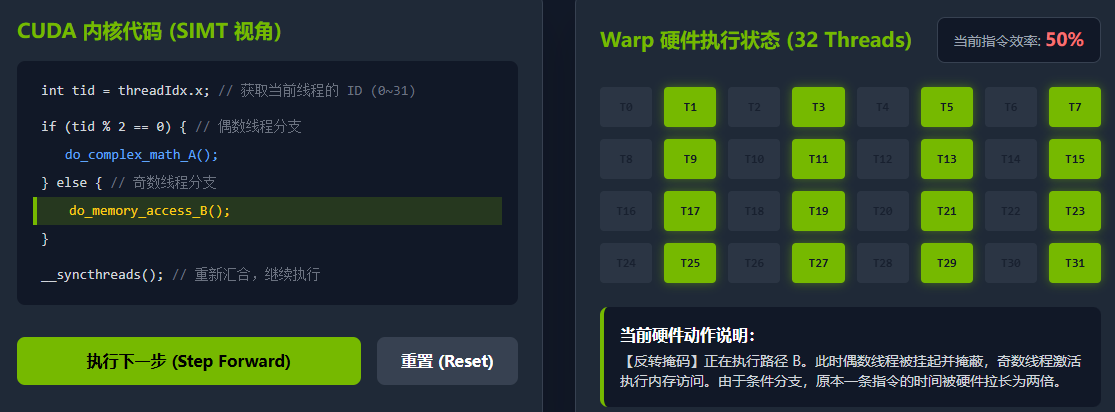
cpp
int tid = threadIdx.x;
if (tid % 2 == 0) {
// 偶数线程执行复杂运算 (路径 A)
do_complex_math();
} else {
// 奇数线程执行访存操作 (路径 B)
do_memory_access();
}在多核 CPU 上,不同的线程有各自的指令指针,偶数和奇数线程会顺畅地各自进入 A 或 B 路径,互不干扰。
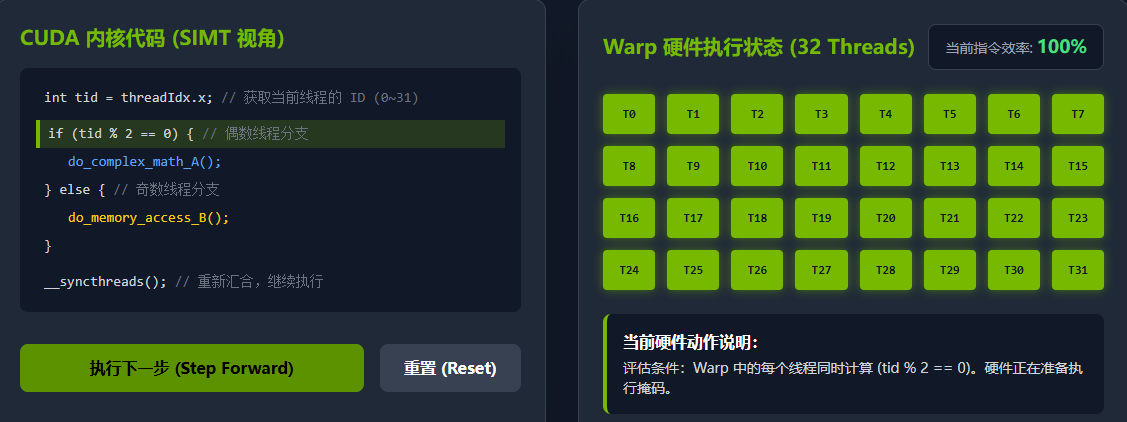
但在 GPU 上,这 32 个线程被捆绑在一个 Warp 中。硬件无法让一半线程去执行路径 A,另一半同时去执行路径 B。GPU 的处理方式是分支序列化(Serialization)与执行掩码(Active Mask):
-
执行路径 A 时 :硬件将满足条件(偶数)的线程标记为活跃(Active),将不满足条件(奇数)的线程静默掩蔽(Mask out / Inactive)。此时,虽然 SM 依然投入了执行这 32 个线程所需的完整物理资源,但只有一半的线程产生了有效的计算结果。我们称此时的 Warp 执行效率降到了 50%。
-
执行路径 B 时:硬件反转掩码状态。偶数线程被挂起,奇数线程变为活跃,执行路径 B。
-
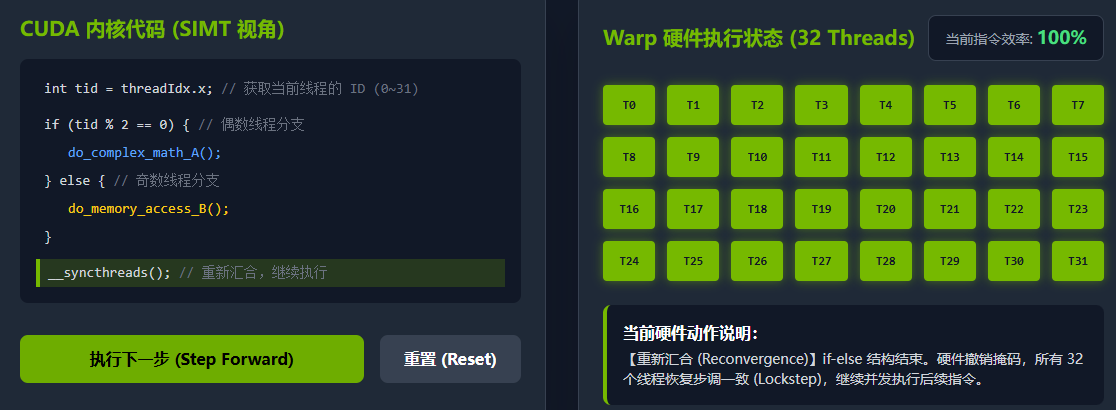
重新汇合(Reconvergence) :当
if-else结构结束后,调度器恢复所有 32 个线程的活跃状态,继续步调一致地向下执行。
性能铁律 :如果一个 Warp 内的线程走向了不同的执行路径,我们就说发生了分支发散 (Branch Divergence) 。发散会导致硬件资源的浪费。因此,在编写 CUDA 代码时,应尽可能让同一个 Warp 内的线程保持相同的控制流走向。

第二节:流多处理器 (SM) 的微架构与资源组织
SM 的内部解剖图
在明确了 Warp(线程束)是 GPU 调度的基本单位之后,我们现在可以剥开 GPU 的外壳,深入考察其实际执行这些 Warp 的物理载体------流多处理器(Streaming Multiprocessor, SM)。
现代 GPU 之所以能实现极致的吞吐量,其核心秘密全在 SM 的数据通路与存储层级设计之中。本节将以奠定现代 GPU 并发基础的 Volta/Turing/Ampere 架构族为例,对其微架构进行"解剖"。
1 "分而治之":子核心分区 (Sub-core Partitioning)
如果你打开一个现代 SM 的设计图表,你会发现它并不是一个巨大的、单一的处理器,而是被整齐地划分为 4 个相等的处理块(Processing Blocks,通常称为子核心 / Sub-cores)。
为什么要做这种物理划分? 在早期的架构(如 Fermi)中,一个 SM 共享一个庞大的前端调度器。但随着 SM 内支持的 Warp 数量不断激增,单一调度器在每个时钟周期寻找就绪 Warp 并分发指令的压力太大,成为了性能瓶颈。从 Kepler 架构开始,NVIDIA 将 SM 划分为多个子核心,每个子核心独立拥有自己的调度器和寄存器堆。
在一个典型的现代 SM 中,这 4 个子核心是高度自治的。当一个线程块(Block)被分配到 SM 后,块内的多个 Warp 会被进一步分配到这 4 个子核心上。一个 Warp 一旦绑定到某个子核心,它的整个生命周期都只在这个子核心内部调度。

2 深入子核心:指令调度与执行单元
让我们放大其中一个子核心,看看它的五脏六腑。每个子核心主要包含以下几个关键层级:
1.L0 指令缓存与 Warp 调度器 (Warp Scheduler): 每个子核心包含 1 个(或多个)Warp 调度器。在每个时钟周期,调度器会从它所管理的活跃 Warp 池中,挑选出一个准备就绪(没有在等待内存数据)的 Warp,并将其下一条指令发送给执行单元。
2.海量寄存器堆 (Register File) : 这是子核心内最重要的资源。每个子核心拥有高达 64KB 的 32-bit 寄存器堆 (整个 SM 包含 256KB)。 架构意义 :为什么 GPU 需要这么大的寄存器?因为 GPU 不使用 CPU 那种将上下文保存到内存的切换机制。所有活跃 Warp 的线程变量都物理保留在这 64KB 的阵列中。这就是 GPU 能实现零周期上下文切换(Zero-overhead Context Switch)的硬件保障。
3.核心执行单元 (Execution Units):
调度器下方连接着多条并行的执行流水线。以一个经典的子核心为例:
-
16 个 FP32 核心(单精度浮点) :这里隐藏着一个绝妙的硬件设计。一个 Warp 有 32 个线程,但这里只有 16 个核心。这意味着什么?意味着硬件需要 2 个时钟周期来完成一个 Warp 的一条 FP32 指令(第一周期处理前 16 个线程,第二周期处理后 16 个线程)。这是一种在硅片面积和吞吐量之间取得完美平衡的设计。
-
16 个 INT32 核心(整型运算):自 Volta 架构起,整型计算和浮点计算的数据通路被分开了。这允许地址计算(整数)和数学计算(浮点)并发执行。
-
2 个 Tensor Cores(张量核心) :专门用于加速深度学习中的
矩阵乘加运算(MMA)。
-
LD/ST(加载/存储单元):负责计算内存地址并向缓存或显存发起读写请求。
3 全局共享:L1 缓存与共享内存
虽然 4 个子核心在计算和调度上是独立的,但它们在底部共享一块极其重要的高速存储器:统一的 L1 数据缓存与共享内存(L1 Data Cache / Shared Memory)。
这块内存(通常为 128KB 或更大)位于 SM 内部,延迟极低,带宽极高。程序员可以通过配置,决定将多少比例划分为硬件自动管理的 L1 缓存,多少比例划分为程序员显式管理的共享内存。
共享内存(Shared Memory) 是同一线程块(Block)内不同 Warp 之间交换数据的唯一片上通道。优化共享内存的访问模式,是 CUDA 高级性能调优的核心课题。
第三节:硬件调度与延迟隐藏
既然我们在上一节已经看到了 SM 内部那极其强悍的计算能力(比如瞬间吞吐大量 FP32 运算的执行单元),现在我们要面临一个并行计算中最经典、最致命的问题:"内存墙 (Memory Wall)"。
当执行单元运算速度极快,但从主存取数据的速度极慢时,硬件难道就只能傻站着等吗?这就是 这一节 要解答的核心问题:GPU 是如何通过极致的多线程调度来"隐藏"这种延迟的。
在计算机体系结构中,计算单元(ALU)的运算速度总是远远快于内存单元(DRAM)的读取速度。执行一条加法指令可能只需要 1 个时钟周期,但从全局显存读取一个数据却需要 400 到 800 个时钟周期。
如果一个处理核心遇到了访存指令,它该怎么办?
-
CPU 的解法:大缓存 (Huge Caches)。 CPU 会占用极大的硅片面积来构建 L1/L2/L3 缓存层级。它试图把你需要的数据提前放在离计算单元最近的地方,从而"缩短"延迟。
-
GPU 的解法:延迟隐藏 (Latency Hiding)。 GPU 认为把宝贵的晶体管用来做缓存太浪费了(它要把面积留给计算核心)。GPU 采取的策略是:我不管延迟有多长,我只需要在等待的时候,有别的事情可做就行!
1 零开销上下文切换 (Zero-overhead Context Switching)
我们在上节提到过,SM 内部拥有极其庞大的寄存器堆(如 256KB)。当一个 Block 分配到 SM 时,它里面所有 Warp 的变量都会被硬连线到这些物理寄存器上。
这意味着什么?在 CPU 上,切换线程通常需要操作系统介入,把当前线程的寄存器状态保存到内存,再把新线程的状态加载进来,这需要成百上千个周期。而在 GPU 的 SM 中,Warp 之间的切换是零时钟周期开销的 (Zero-overhead)。
因为所有 Warp 的状态都已经物理存在于寄存器堆中了,Warp 调度器只需要改变一下内部的指针,下一个时钟周期就能直接发射另一个 Warp 的指令。
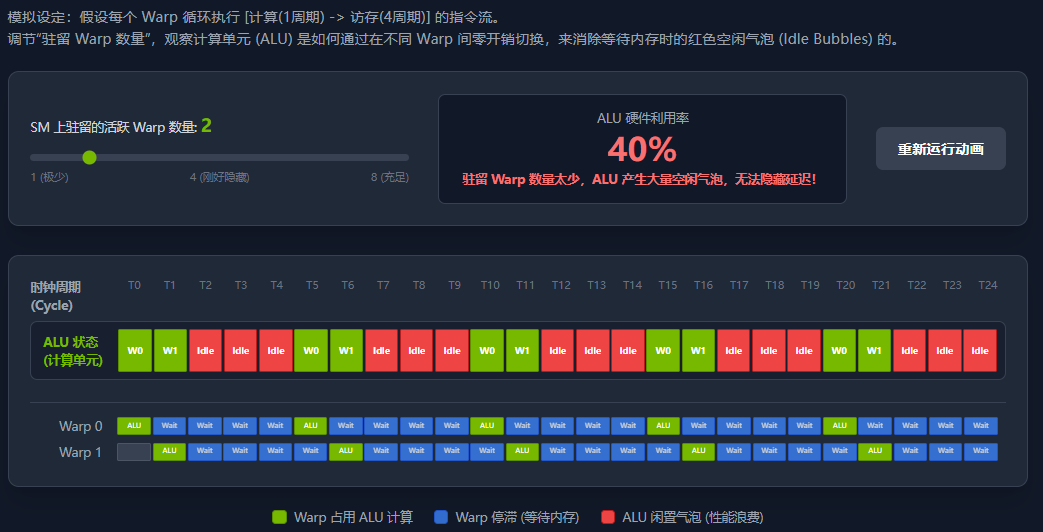
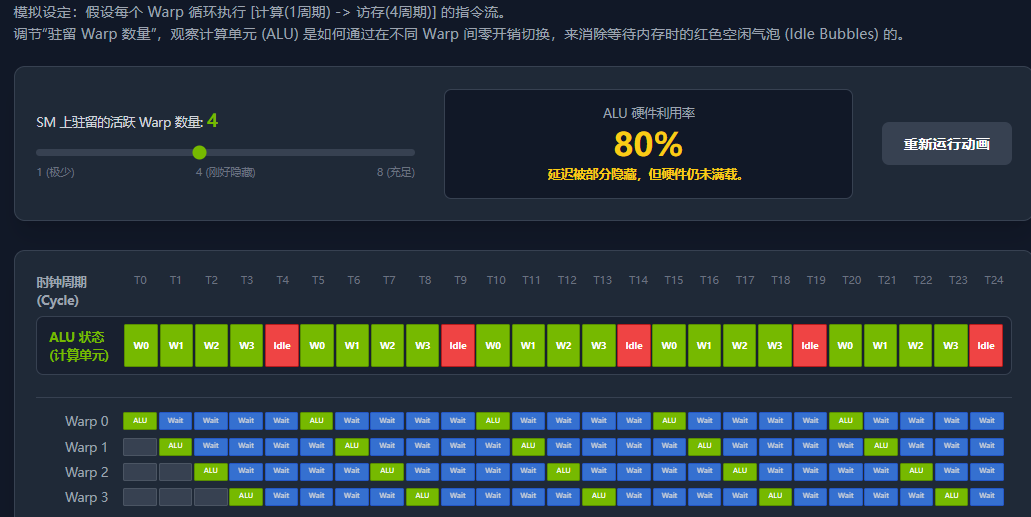
2 如何隐藏延迟?
GPU 隐藏延迟的逻辑极其优雅:
-
调度器在当前时钟周期挑选 Warp 0 执行指令。
-
假设这条指令是读取全局内存。Warp 0 发出请求后,必须等待 400 个周期数据才能返回。Warp 0 进入停滞 (Stalled) 状态。
-
如果是传统的单线程处理器,ALU 接下来 400 个周期只能闲置。
-
但在 GPU 中,调度器在下一个周期立刻看向活跃池中的 Warp 1。只要 Warp 1 的数据是就绪的,调度器就把它推给 ALU 执行。
-
Warp 1 执行完也可能遇到访存而停滞,调度器立刻切换到 Warp 2、Warp 3...
-
如果 SM 内部驻留了足够多的 Warp,当调度器轮询完一圈,准备再次调度 Warp 0 时,400 个周期刚好过去了,Warp 0 的数据从内存拿回来了!此时 Warp 0 状态变为就绪,继续执行。
从 ALU 的视角来看,它每个时钟周期都在满负荷运转,完全没有感觉到内存延迟的存在。这就是所谓的"延迟隐藏"。
3 定量分析:利特尔法则 (Little's Law)
那么,一个 SM 内部到底需要驻留多少个活跃的 Warp,才能完美地隐藏掉内存延迟呢?这就需要引入排队论中著名的利特尔法则 (Little's Law)。
在 GPU 并发调度的语境下,利特尔法则的公式可以表述为:
-
N (需要的并发操作数 / Number of active operations):在这里指为了保持流水线满载,所需的活跃 Warp 数量或并发指令数。
-
L (延迟 / Latency):指令执行或内存访问所需的平均时钟周期数。
-
理论计算示例:
假设我们有一个简单的内存拷贝内核。内存访问的延迟 个时钟周期。假设 SM 的访存调度器每个周期可以发射 1 条内存指令(
)。
那么,根据利特尔法则:
条指令。
因为每个 Warp 在同一时间只能有一条指令处于飞行状态(In-flight),这意味着我们至少需要 400 个活跃的 Warp 分配在这个 SM 上,才能完全填满这 400 个周期的等待时间,达到 100% 的内存带宽利用率。如果你的 Block 配置不当,导致 SM 上只驻留了 10 个 Warp,那么大部分时间 ALU 依然处于空闲状态,性能将急剧下降。
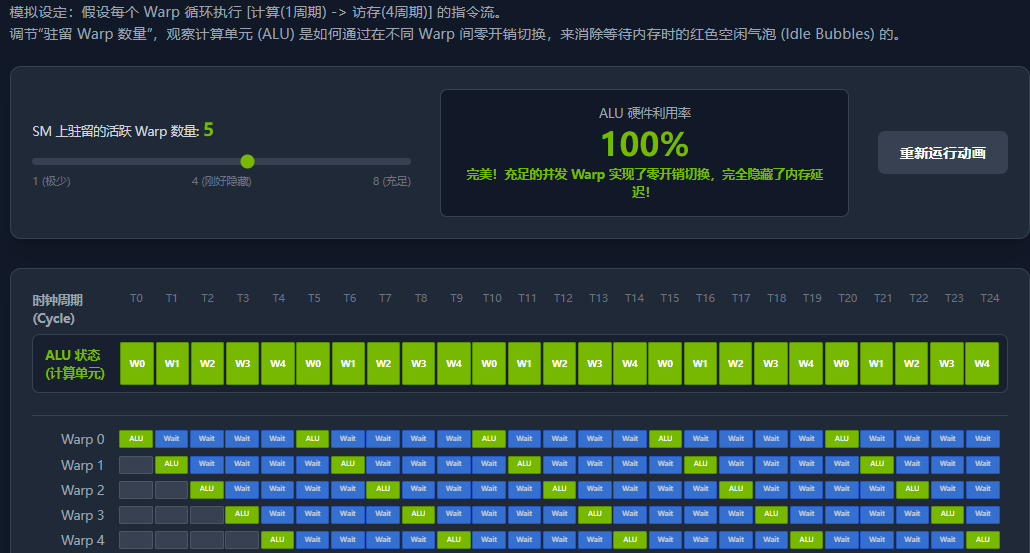
第四节:硬件资源限制与占用率 (Occupancy) 理论
在了解了延迟隐藏机制后,初学者通常会产生一个直觉:既然驻留的 Warp 越多越能隐藏延迟,那我在启动内核时,直接把一个 Block 配置成 1024 个线程,然后发射无数个这样的 Block,让 SM 里永远挤满 Warp 不就好了吗?
遗憾的是,GPU 硬件对此说"不"。SM(流多处理器)内部能够同时驻留(Resident)的 Warp 数量是有物理上限的。这种限制不仅来自于硬件的绝对配额(如最大线程数),更来自于你的内核代码对片上存储资源的消耗。
1 什么是占用率 (Occupancy)?
占用率 (Occupancy) 是衡量 GPU 硬件利用潜力的核心指标。它的定义非常简单:
占用率 = SM 上当前活跃的 Warp 数量 / SM 支持的最大 Warp 数量
例如,如果某代 GPU 的一个 SM 最多能支持 2048 个并发线程(即 64 个 Warp),而你当前启动的内核因为种种原因,只让 SM 驻留了 1024 个线程(32 个 Warp),那么你的占用率就是 50%。
高占用率并不绝对等于高性能(因为如果指令级并行度足够高,较低的占用率也能隐藏延迟),但过低的占用率(如低于 20%)通常意味着灾难性的内存延迟无法被隐藏。
2 决定占用率的三座大山 (资源限制)
当 GPU 调度器试图将一个线程块(Block)分配给 SM 时,它会检查 SM 剩余的物理资源是否足够容纳这个完整的 Block。注意:Block 的分配是"全有或全无 (All-or-Nothing)"的。 如果资源只够容纳 0.9 个 Block,调度器也不会分配,必须等。
限制 Block 驻留的核心物理资源有三个:
-
寄存器堆容量 (Register File Size)
我们在 4.3 节提到,SM 有一个庞大但有限的寄存器堆(例如 Volta 架构每 SM 65,536 个 32-bit 寄存器)。如果在你的 CUDA 代码中,每个线程定义了大量局部变量,编译器就会为每个线程分配很多寄存器。
假设一个 SM 最多支持 2048 个线程。如果每个线程使用 32 个寄存器,总共需要 2048 \\times 32 = 65536,刚好占满,占用率可达 100%。但如果你的代码稍微复杂一点,每个线程用了 64 个寄存器,那么 SM 的寄存器总量只能支撑 1024 个线程,占用率瞬间跌至 50%。
-
共享内存容量 (Shared Memory Capacity)
共享内存是 SM 内部极速的片上内存(如 96KB)。它是按 Block 为单位分配的。
如果一个 SM 拥有 96KB 共享内存,而你的每个 Block 申请了 64KB 共享内存。此时,哪怕 SM 的线程配额和寄存器都绰绰有余,它也只能容纳下 1 个 Block。因为放入第二个 Block 需要
-
硬件架构的绝对硬限制 (Hard Limits)
除了上述动态资源,每代架构都有写死在硅片里的上限。例如:
-
每个 SM 最大并发线程数(如 2048)。
-
每个 SM 最大并发 Block 数量 (如 32 或 16)。如果你把每个 Block 设置积极小(比如只有 32 个线程),即使达到 32 个 Block 的上限,SM 也只有
-
3 悬崖效应 (The Cliff Effect)
在 GPU 资源分配中,存在一种可怕的"悬崖效应"(即阶跃下降)。因为分配是以 Block 为单位的整数分配,资源的微小超支会导致活跃 Block 数量直接减 1。
例如,SM 支持 96KB 共享内存。
-
当每个 Block 使用 48KB 时,SM 刚好可以放入 2 个 Block。
-
如果你仅仅多声明了一个
float数组,导致每个 Block 使用了 48.1KB ,SM 就只能放入 1 个 Block(剩余 47.9KB 被闲置浪费),你的占用率会瞬间暴跌 50%。
这就是为什么高级 GPU 程序员必须像"铁公鸡"一样,对寄存器和共享内存的字节数锱铢必较!