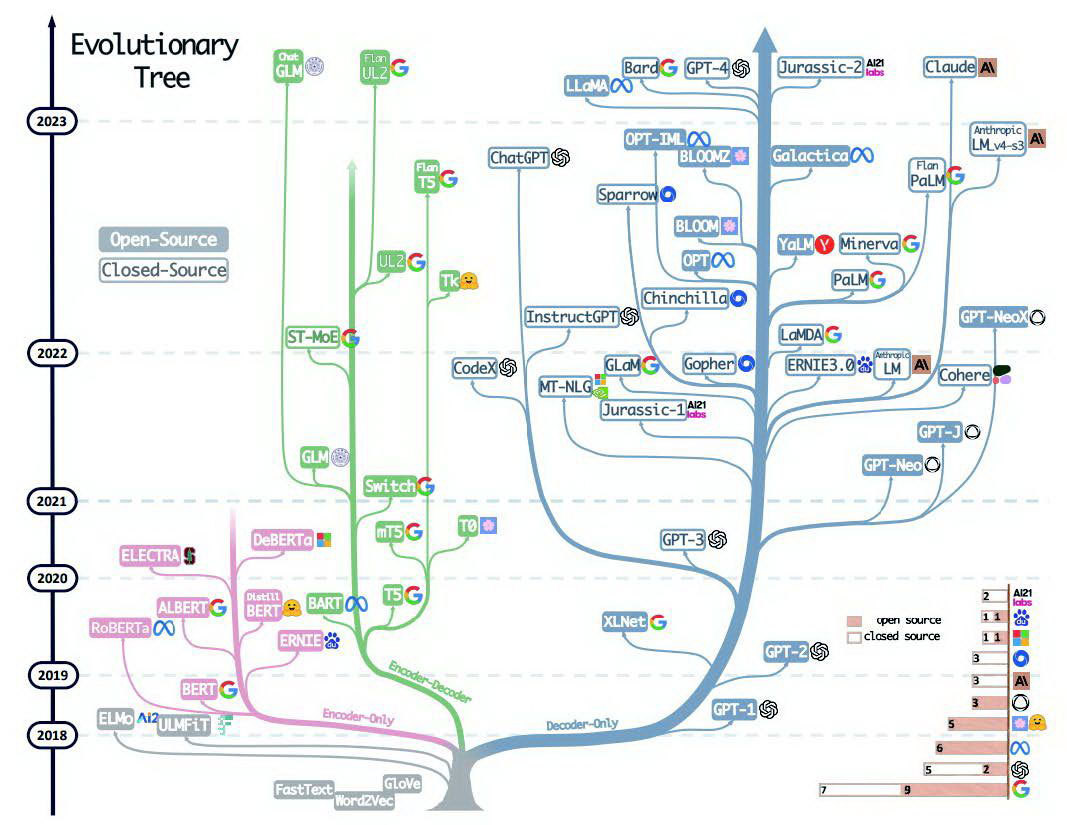
一、Encoder-Only架构
Encoder-Only 架构,也被称为单向架构,仅包含编码器部分。它主要适用于不需要生成序列的任务,只需要对输入进行编码和处理的单向任务场景,如文本分类 、情感分析等。这种架构的代表是 BERT 相关的模型,例如 BERT、RoBERT 和 ALBERT 等。
Encoder-Only 架构的核心思想是利用神经网络对输入文本进行编码,提取其特征和语义信息,并将编码结果传递给后续的处理模块。这种架构的优点是能够更好地理解输入文本的语义和上下文信息,从而提高文本分类和情感分析 等任务的准确性。++缺点是它无法直接生成文本输出,因此在需要生成文本的任务中不太适用。++
Encoder-Only架构的大模型有++谷歌的BERT++ 、智谱AI发布的第四代基座大语言模型++GLM 4等++。其中,BERT是基于Encoder-Only架构的预训练语言模型。GLM 4是智谱AI发布的第四代基座大语言模型,该模型在IFEval评测集上,在Prompt提示词跟随(中文)方面,GLM-4达到了GPT-4 88%的水平。
二、Decoder-Only架构
Decoder-Only 架构,也被称为生成式架构,仅包含解码器部分。它通常用于序列生成任务,如文本生成 、机器翻译等。这种架构的模型适用于需要生成序列的任务,可以从输入的编码中生成相应的序列。同时,++Decoder-Only 架构还有一个重要特点是可以进行无监督预训练++。在预训练阶段,模型通过大量的无标注数据学习语言的统计模式和语义信息。
Decoder-Only 架构的优点是擅长创造性的写作,比如写小说或自动生成文章。它更多关注于从已有的信息(开头)扩展出新的内容。++其缺点是需大量训练数据来提高生成文本的质量和多样性++。
Decoder-Only架构的大模型的代表有++GPT系列++ 、++LLaMA++ 、++OPT++ 、++BLOOM等++。这类模型采用预测下一个词进行训练,常见下游任务有文本生成、问答等,因此被称为ALM(Autoregressive Language Model)。
国内采用Decoder-Only架构研发的大模型有妙想金融大模型、XVERSE-13B大模型等。其中,妙想金融大模型是东方财富旗下自主研发的金融行业大语言模型,目前已经覆盖了7B、13B、34B、66B及104B参数。而XVERSE-13B大模型是由前腾讯副总裁、腾讯AI lab创始人姚星创立的明星独角兽元象研发的,该模型支持40多种语言、8192上下文长度,在多项中英文测评中,性能超过了同尺寸(130亿参数)的LIama2、Baichuan等。
三、Encoder-Decoder架构
Encoder-Decoder 架构,也被称为序列到序列架构,同时包含编码器和解码器部分。它通常用于序列到序列(Seq2Seq)任务,如机器翻译、对话生成等。这种架构的代表是以 Google 训练出来的 T5 为代表的相关大模型。
Encoder-Decoder 架构的核心思想是利用编码器对输入序列进行编码,提取其特征和语义信息,并将编码结果传递给解码器。然后,解码器根据编码结果生成相应的输出序列。这种架构的优点是能够更好地处理输入序列和输出序列之间的关系,从而提高机器翻译和对话生成等任务的准确性。++缺点是模型复杂度较高,训练时间和计算资源消耗较大++。
Encoder-Decoder架构的大模型有很多,例如++Google的T5模型++ 、华为的++盘古NLP++ 大模型等。
其中,华为的盘古NLP大模型首次使用Encoder-Decoder架构,兼顾NLP大模型的理解能力和生成能力,保证了模型在不同系统中的嵌入灵活性。在下游应用中,仅需少量样本和可学习参数即可完成千亿规模大模型的快速微调和下游适配,这一模型在智能舆论以及智能营销方面都有不错的表现。