在医药工业企业的市场部,每到季度复盘或年度BP制定的关键时刻,会议室里总会弥漫着一种微妙的"信息不对称"焦虑。
当PPT投射在屏幕上,展示着漂亮的Sell-in曲线时,老板的一句追问往往能瞬间击穿防线: "发货确实涨了,但终端纯销到底怎么样?竞品在 A 省这个季度突然起量,是在压货还是真的动销?"
大多数时候,只能依靠碎片化的信息来拼凑答案:区域经理的主观反馈、几个重点连锁的局部数据,或者是只有全国总量的宏观报告。
这种"中间黑箱",是困扰无数品牌经理的终极痛点。
在如今这个存量博弈、集采常态化的时代,靠"拍脑袋"和"经验主义"做决策的容错率已近乎为零。现在需要重构对市场的认知逻辑------从宏观的模糊,走向微观的精准。
一、 警惕"平均数陷阱"
中国医药市场最大的特征就是非均质化。
当我们拿到一份"全国零售市场增长5%"的报告时,这数据的参考价值其实非常有限。因为在现实中,可能广东增长了20%,而东北地区萎缩了15%。平均数掩盖了区域市场的真实剧变。
真正的洞察,往往隐藏在颗粒度更细的维度里。
这正是药智数据药品零售数据库试图解决的核心问题。不同于传统的局部抽样,这套数据体系基于全国 11 万 + 家实体药店的真实样本,通过科学建模放大,还原了全国及各省份的真实销售图景。
试想一下,当品牌经理不再只盯着全国大盘,而是能通过全国热力图锁定销售洼地:
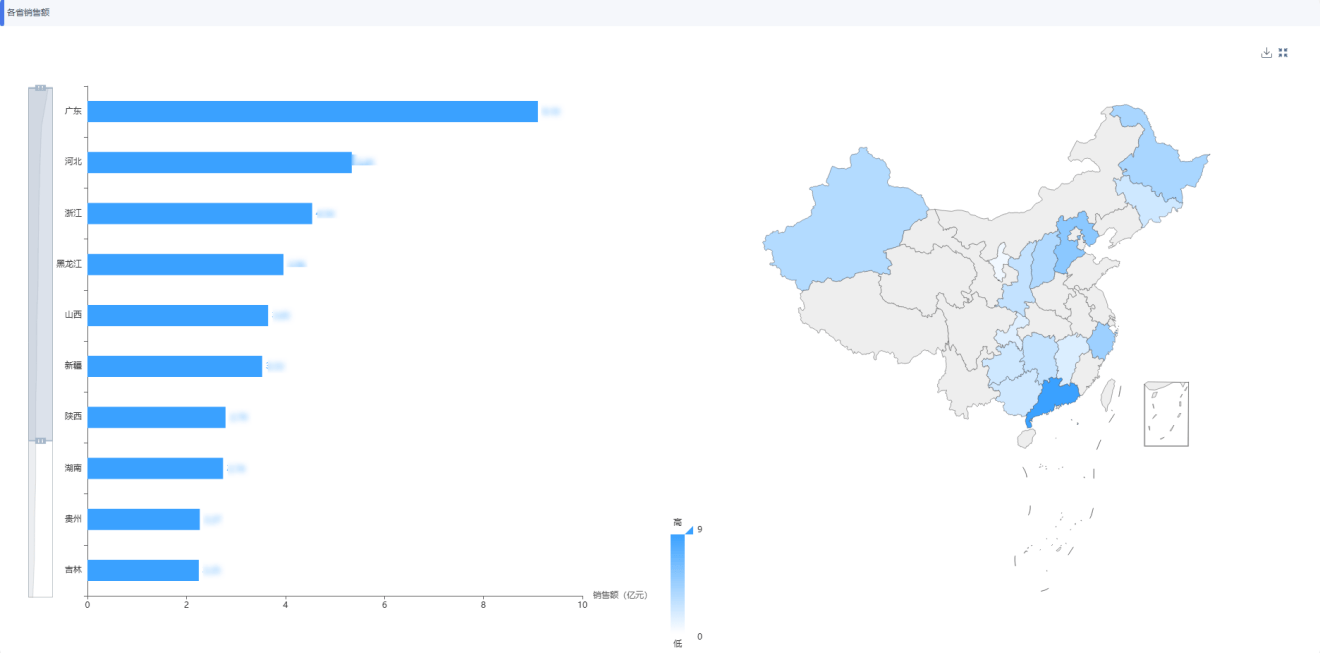
- 发现某款感冒药在南方省份的渗透率远低于北方,是气候原因还是渠道铺设不足?
- 看到某竞品在河南的市场份额突然飙升,这不再是一个模糊的感觉,而是数据图表上实实在在的红色预警。
省份维度的数据,让资源投放不再是"撒胡椒面",而是"精确制导"。
二、 用历史数据校准未来
做市场最怕的不是当下的困难,而是对未来的误判。
制定KPI时,如果缺乏对大盘趋势的预判,很容易陷入两个极端:要么目标定得太高,团队累死也完不成;要么目标太低,错失了捡钱的机会。
基于2016年至今的长期数据积累,利用时间序列分析模型,不仅能复盘过去,更能预测未来 3 年的销售走势。
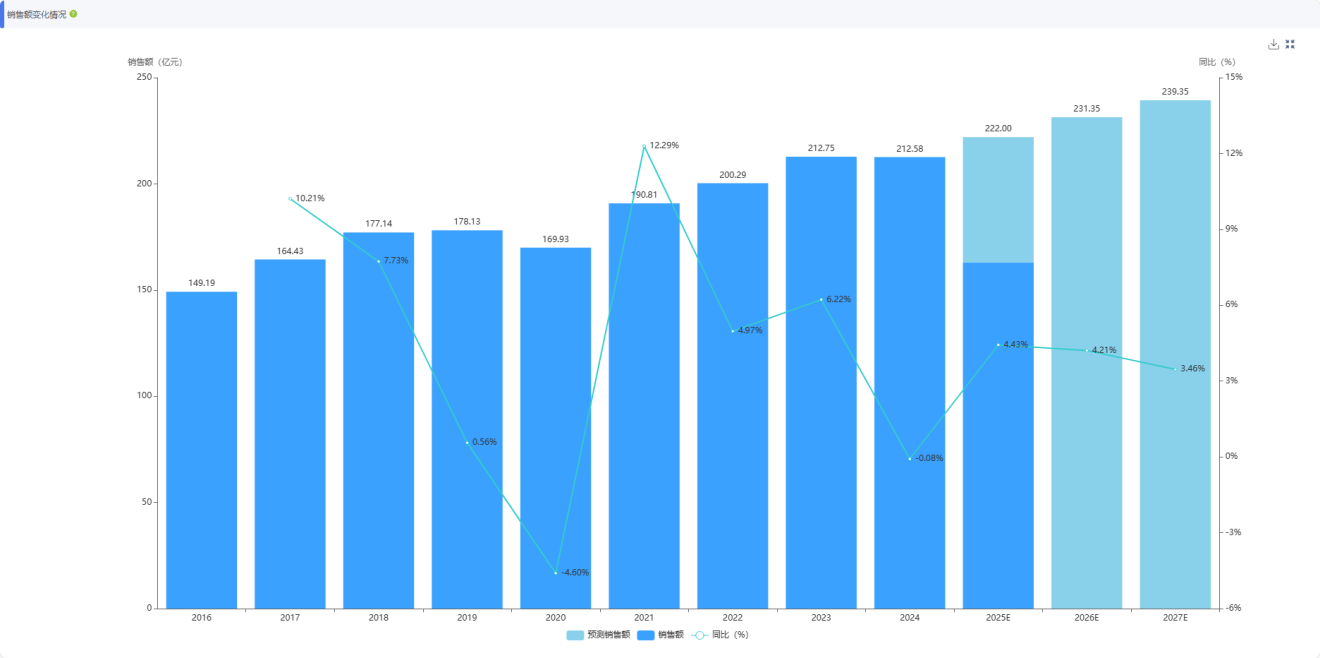
这不是算命,而是基于数理统计的科学推演。当知道某个品类在未来三年处于下行通道时,保住份额就是胜利;当数据显示某个活性成分正处于爆发前夜,激进的投入才是理性的选择。
在医药零售市场,数据本身并不能直接产生销量,但它能赋予决策者一双看透迷雾的眼睛。
药品零售数据背后所代表的,不仅仅是一个查询工具,更是一种"数据驱动决策"的工作方式。它帮助我们将原本零散、滞后的终端信息,转化为系统化、可视化的市场情报。
当其他人在为"为什么销量跌了"而争执不休时,你已经导出了详实的省份热力图和竞品趋势表,在BP中写下了下一个增长点的确切坐标。