事务是关系型数据库区别于NoSQL的核心能力之一,而隔离性作为ACID四大特性中最复杂、最影响业务正确性与数据库性能的一环,是90%以上线上数据库问题(脏写、死锁、数据不一致、主从不一致)的根源。本文将从SQL标准定义出发,深入InnoDB存储引擎底层,拆解MVCC、undo log、Read View、锁机制的核心实现,结合可复现的SQL示例与业务代码,最终落地到生产环境的架构选型与避坑指南,帮你彻底吃透MySQL事务隔离级别。
一、事务隔离要解决的3个核心读异常
隔离性的本质,是解决多个并发事务同时读写同一批数据时的冲突问题。SQL标准定义了3类核心读异常,也是所有隔离级别设计的核心目标。
1.1 脏读(Dirty Read)
定义:一个事务读到了另一个事务未提交的修改。未提交意味着该修改随时可能回滚,基于此数据的后续操作都会出现数据错误。
SQL示例
-- 1. 初始化测试表与数据
CREATE TABLE `t_isolation_test` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(32) NOT NULL DEFAULT '',
`balance` int NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `t_isolation_test` (`id`, `name`, `balance`) VALUES (1, '张三', 1000);
-- 2. 会话A:开启事务,修改数据但不提交
SET SESSION transaction_isolation = 'READ-UNCOMMITTED';
START TRANSACTION;
UPDATE t_isolation_test SET balance = balance - 100 WHERE id = 1;
-- 3. 会话B:查询数据,读到会话A未提交的修改
SET SESSION transaction_isolation = 'READ-UNCOMMITTED';
SELECT balance FROM t_isolation_test WHERE id = 1;
-- 查询结果为900,即为脏读。若会话A此时回滚,会话B读到的900就是无效数据1.2 不可重复读(Non-Repeatable Read)
定义:同一个事务内,执行两次完全相同的SELECT语句,得到的结果内容不一致。核心原因是其他事务在两次查询之间对数据做了UPDATE/DELETE操作并提交。
可复现SQL示例
-- 1. 会话A:开启读已提交事务,第一次查询数据
SET SESSION transaction_isolation = 'READ-COMMITTED';
START TRANSACTION;
SELECT balance FROM t_isolation_test WHERE id = 1;
-- 第一次查询结果为1000
-- 2. 会话B:修改数据并提交
SET SESSION transaction_isolation = 'READ-COMMITTED';
START TRANSACTION;
UPDATE t_isolation_test SET balance = balance - 100 WHERE id = 1;
COMMIT;
-- 3. 会话A:第二次查询同一条数据
SELECT balance FROM t_isolation_test WHERE id = 1;
-- 第二次查询结果为900,同一个事务内两次查询结果不一致,即为不可重复读1.3 幻读(Phantom Read)
定义:同一个事务内,执行两次完全相同的范围查询,得到的行数不一致。核心原因是其他事务在两次查询之间插入了符合查询条件的新数据并提交。
可复现SQL示例
-- 1. 会话A:开启读已提交事务,第一次范围查询
SET SESSION transaction_isolation = 'READ-COMMITTED';
START TRANSACTION;
SELECT * FROM t_isolation_test WHERE id BETWEEN 1 AND 3;
-- 第一次查询仅返回id=1的1行数据
-- 2. 会话B:插入符合范围条件的数据并提交
SET SESSION transaction_isolation = 'READ-COMMITTED';
START TRANSACTION;
INSERT INTO t_isolation_test (id, name, balance) VALUES (2, '李四', 2000);
COMMIT;
-- 3. 会话A:第二次执行相同的范围查询
SELECT * FROM t_isolation_test WHERE id BETWEEN 1 AND 3;
-- 第二次查询返回id=1、id=2的2行数据,行数发生变化,即为幻读❝
核心区分:不可重复读聚焦于数据内容的变化 (UPDATE/DELETE),幻读聚焦于数据行数的变化(INSERT)。
二、SQL标准的4个隔离级别全解
SQL:1992标准定义了4个事务隔离级别,每个级别对应解决不同的读异常,隔离强度从低到高依次提升,并发性能依次下降。MySQL InnoDB存储引擎完整实现了这4个级别,默认隔离级别为可重复读(REPEATABLE READ)。
| 隔离级别 | 解决脏读 | 解决不可重复读 | 解决幻读 |
|---|---|---|---|
| 读未提交(READ UNCOMMITTED) | ❌ | ❌ | ❌ |
| 读已提交(READ COMMITTED) | ✅ | ❌ | ❌ |
| 可重复读(REPEATABLE READ) | ✅ | ✅ | InnoDB✅ |
| 串行化(SERIALIZABLE) | ✅ | ✅ | ✅ |
2.1 读未提交(READ UNCOMMITTED)
该级别下,事务的修改即使未提交,对其他事务也完全可见。数据库不会为读操作加任何共享锁,也不会通过MVCC生成快照,直接读取数据页的最新版本。
该级别几乎不会在生产环境使用,仅适用于对性能要求极致、完全不在乎数据一致性的极端场景,比如非核心的实时统计打点。
2.2 读已提交(READ COMMITTED)
该级别下,事务只能看到其他事务已经提交的修改,彻底解决了脏读问题。这是互联网行业使用最广泛的隔离级别,Oracle、PostgreSQL等数据库的默认隔离级别均为读已提交。
核心特性:
-
每次执行普通SELECT语句时,都会生成一个全新的快照,因此无法避免不可重复读
-
对于UPDATE/DELETE语句,仅锁住匹配的行记录,不会锁间隙,因此无法避免幻读
-
支持半一致性读,更新语句读到不匹配的行时会提前释放锁,大幅降低锁冲突概率
2.3 可重复读(REPEATABLE READ)
该级别下,同一个事务内多次执行相同的SELECT语句,结果完全一致,彻底解决了脏读和不可重复读问题。InnoDB对SQL标准做了增强,通过临键锁(Next-Key Lock)+ MVCC 彻底解决了幻读问题,这是和其他数据库的核心差异。
核心特性:
-
事务启动后第一次执行SELECT语句时,生成全局唯一的快照,整个事务生命周期内复用该快照,保证可重复读
-
对于锁定读、更新、删除操作,使用临键锁锁住索引记录和间隙,阻止其他事务插入符合条件的数据,解决当前读场景下的幻读
-
间隙锁的存在会大幅提升锁冲突和死锁的概率,对高并发场景不友好
2.4 串行化(SERIALIZABLE)
该级别是最高隔离级别,强制所有事务串行执行,彻底消除了并发事务的冲突问题。InnoDB会将所有普通SELECT语句自动转换为SELECT ... LOCK IN SHARE MODE,为读操作加共享锁,写操作加排他锁,所有读写操作都会互斥。
该级别仅适用于对数据一致性要求极致、并发量极低的场景,比如金融核心账务、监管合规类的强一致性业务。
三、核心底层原理深度拆解
InnoDB实现隔离级别的两大核心支柱是MVCC(多版本并发控制) 和锁机制。MVCC解决了快照读的隔离问题,实现了读写不冲突;锁机制解决了当前读的隔离问题,保证了并发写的正确性。
3.1 MVCC多版本并发控制
MVCC的核心思想是:为每一行数据维护多个版本快照,不同事务可以读取对应版本的数据,实现读写不阻塞,大幅提升数据库的并发性能。
3.1.1 InnoDB行格式的隐藏列
InnoDB聚簇索引的每一行数据,都会默认添加3个隐藏列,这是MVCC实现的基础:
-
DB_TRX_ID:6字节,最后一次修改该行的事务ID。事务ID是InnoDB内部自增的,唯一标识一个事务。
-
DB_ROLL_PTR:7字节,回滚指针,指向该行对应的undo log日志。undo log中存储了该行数据的历史版本,通过回滚指针可以构建出数据的历史快照。
-
DB_ROW_ID:6字节,隐藏的自增主键。如果表没有定义主键,InnoDB会自动生成该列作为聚簇索引;如果表已经定义了主键,该列不会存在。
3.1.2 undo log 版本链
undo log是InnoDB实现MVCC的核心载体,分为两类:
-
insert undo log:仅在INSERT语句时产生,事务提交后可以直接删除,不需要为MVCC提供历史版本。
-
update undo log:在UPDATE/DELETE语句时产生,不仅用于事务回滚,还需要为MVCC提供数据的历史版本,只有当没有任何事务需要引用该undo log时,才会被purge线程清理。
当一行数据被多次修改时,会通过undo log形成一条完整的版本链,链首是数据的最新版本,链尾是数据的最早历史版本。每个版本都记录了对应的事务ID,通过回滚指针串联起来。
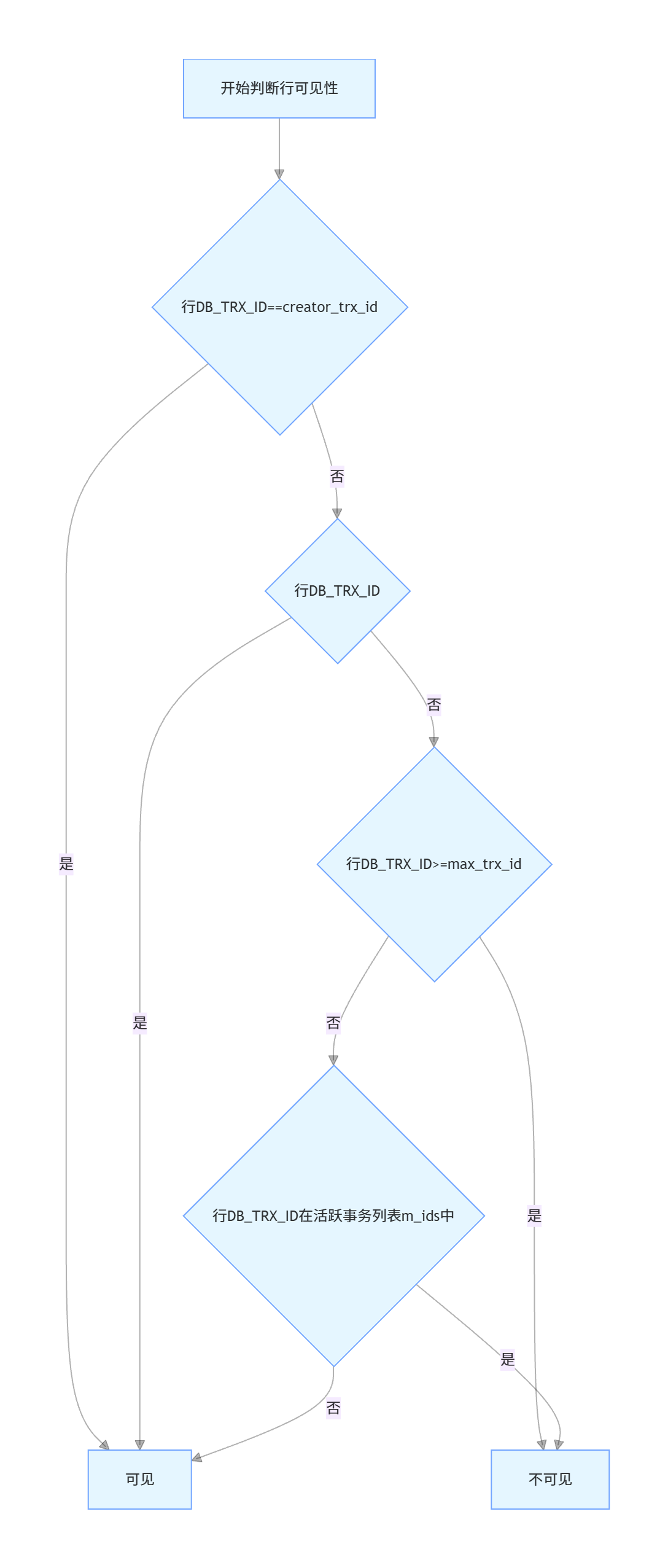
3.1.3 Read View 可见性规则
Read View是InnoDB为快照读生成的一致性视图,定义了数据版本的可见性规则,是判断一个数据版本是否对当前事务可见的核心依据。
Read View包含4个核心字段:
-
m_ids:生成Read View时,当前数据库中所有活跃(未提交)的事务ID列表
-
min_trx_id:m_ids中的最小事务ID,即当前活跃事务的最小ID
-
max_trx_id:生成Read View时,数据库下一个要分配的事务ID,即全局最大事务ID+1
-
creator_trx_id:生成当前Read View的事务ID
数据版本可见性判断规则(优先级从高到低):
-
如果数据版本的
DB_TRX_ID == creator_trx_id:可见,该版本是当前事务自己修改的 -
如果数据版本的
DB_TRX_ID < min_trx_id:可见,该版本对应的事务在Read View生成前就已经提交 -
如果数据版本的
DB_TRX_ID >= max_trx_id:不可见,该版本对应的事务在Read View生成后才启动 -
如果数据版本的
DB_TRX_ID在min_trx_id和max_trx_id之间:判断是否在m_ids列表中,在则表示事务仍活跃未提交,不可见;不在则表示事务已提交,可见
如果当前版本不可见,InnoDB会通过DB_ROLL_PTR回滚指针找到上一个历史版本,重新执行可见性判断,直到找到可见的版本,或者遍历完整个版本链返回空。
3.1.4 RC与RR级别的核心差异:Read View生成时机
这是两个隔离级别最核心的底层区别,直接决定了是否能实现可重复读:
-
读已提交(RC) :每次执行普通SELECT快照读时,都会重新生成一个全新的Read View。因此每次查询都能看到其他事务刚提交的修改,导致同一个事务内两次查询结果不一致,出现不可重复读。
-
可重复读(RR) :事务启动后,第一次执行普通SELECT快照读时,生成一个全局唯一的Read View,整个事务生命周期内复用该Read View。因此后续所有查询都使用同一个可见性规则,保证了同一个事务内多次查询结果完全一致,实现了可重复读。
MVCC可见性判断流程图
3.2 InnoDB锁机制
MVCC仅解决了快照读的隔离问题,对于当前读(SELECT ... FOR UPDATE/LOCK IN SHARE MODE、INSERT、UPDATE、DELETE),必须通过锁机制保证数据的正确性和隔离性。
3.2.1 快照读与当前读
首先明确两个核心概念,这是理解InnoDB隔离实现的关键:
-
快照读(一致性非锁定读):普通的SELECT语句,通过MVCC读取数据的历史快照,不加锁,读写不冲突,性能极高。
-
当前读(锁定读) :读取数据的最新版本,并对读取的行加锁,保证其他事务无法并发修改该行。包括:
-
SELECT ... LOCK IN SHARE MODE(共享锁) -
SELECT ... FOR UPDATE(排他锁) -
INSERT、UPDATE、DELETE语句(排他锁)
-
3.2.2 InnoDB锁体系
InnoDB的锁分为表级锁和行级锁两大类,完整体系如下:
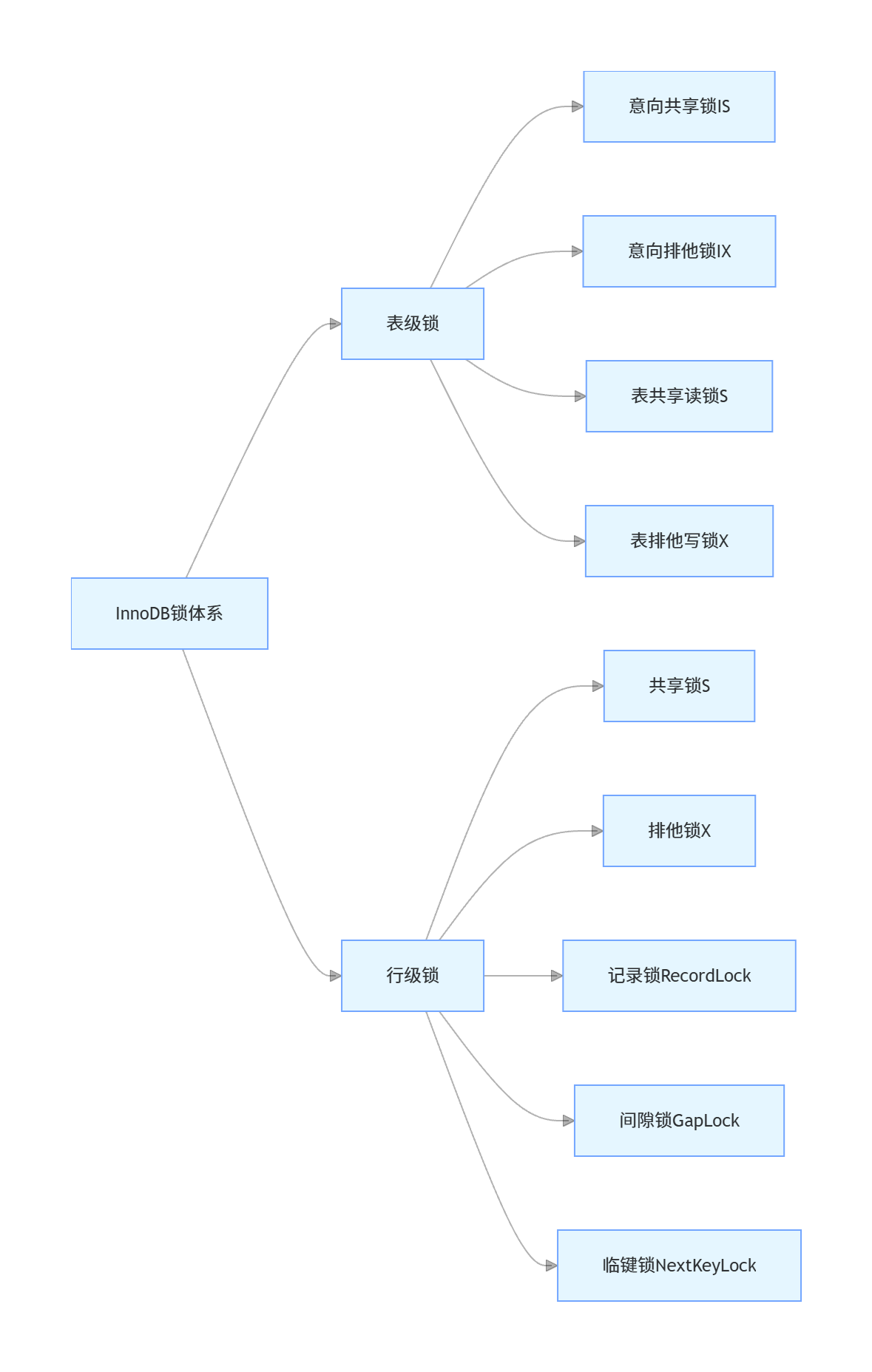
-
表级锁
-
意向共享锁(IS):事务准备给行记录加共享锁前,必须先给表加IS锁
-
意向排他锁(IX):事务准备给行记录加排他锁前,必须先给表加IX锁
-
意向锁之间完全兼容,仅与表级的S/X锁互斥,核心作用是快速判断表中是否有行被锁定,避免全表扫描判断锁冲突。
-
表级S/X锁仅在手动执行
LOCK TABLES时生效,DML语句不会加表级S/X锁。
-
-
行级锁
-
共享锁(S锁):读锁,多个事务可以同时给同一行加S锁,互斥X锁。
-
排他锁(X锁):写锁,只有一个事务能给同一行加X锁,互斥所有S锁和X锁。
-
记录锁(Record Lock):锁定具体的索引记录,仅针对唯一索引的等值查询且命中记录时生效,RR和RC级别均支持。
-
间隙锁(Gap Lock):锁定索引之间的间隙,不包含具体的索引记录,仅在RR级别生效。核心作用是防止其他事务往间隙中插入数据,解决幻读问题。间隙锁之间互相兼容,仅与插入操作互斥。
-
临键锁(Next-Key Lock):InnoDB RR级别下默认的行锁算法,是记录锁+间隙锁的组合,锁定一个左开右闭的索引区间。通过临键锁,InnoDB可以锁定查询范围的所有索引记录和间隙,彻底阻止其他事务插入符合条件的数据,解决了当前读场景下的幻读问题。
-
3.2.3 临键锁解决幻读的核心原理
SQL标准的RR级别无法解决幻读,而InnoDB RR级别通过临键锁实现了幻读的彻底解决,核心逻辑如下:
SQL示例
-- 1. 初始化数据
TRUNCATE TABLE t_isolation_test;
INSERT INTO `t_isolation_test` (`id`, `name`, `balance`) VALUES (1, '张三', 1000),(5, '李四', 2000),(10, '王五', 3000);
-- 2. 会话A:开启RR事务,执行范围锁定读
SET SESSION transaction_isolation = 'REPEATABLE-READ';
START TRANSACTION;
SELECT * FROM t_isolation_test WHERE id BETWEEN 1 AND 7 FOR UPDATE;
-- 该查询会生成3个临键锁区间:(-∞,1]、(1,5]、(5,10]
-- 锁定了id<=10的所有间隙,阻止任何符合条件的插入操作
-- 3. 会话B:尝试插入符合范围的数据
SET SESSION transaction_isolation = 'REPEATABLE-READ';
INSERT INTO t_isolation_test (id, name, balance) VALUES (3, '赵六', 1500);
-- 插入操作会被阻塞,直到会话A事务提交或回滚,彻底避免了幻读四、生产环境架构选型与最佳实践
隔离级别没有绝对的好坏,核心是在数据一致性 和并发性能之间找到平衡。选择隔离级别的核心依据是业务对数据一致性的容忍度、并发量、业务场景特性。
4.1 不同隔离级别的核心性能差异
| 对比维度 | 读已提交(RC) | 可重复读(RR) |
|---|---|---|
| 锁冲突概率 | 低,仅锁匹配的行记录,语句执行完释放不匹配的锁 | 高,临键锁会锁定范围间隙,事务结束才释放锁 |
| 死锁概率 | 极低,无间隙锁,仅记录锁冲突 | 高,间隙锁会导致大范围锁冲突,极易触发死锁 |
| 并发性能 | 高,读写冲突少,半一致性读大幅降低锁等待 | 中,间隙锁导致大量锁等待,并发能力下降 |
| undo log开销 | 低,purge线程可以及时清理无用的undo log | 高,长事务会导致undo log严重膨胀,影响数据库性能 |
| 主从一致性风险 | 低,配合ROW格式binlog无风险 | 低,默认配置无风险 |
4.2 不同业务场景的选型标准
4.2.1 优先选择读已提交(RC)的场景
绝大多数互联网OLTP业务都适合使用RC级别,包括电商订单、商品库存、内容社区、社交互动、用户中心等场景。
核心适用条件:
-
业务对数据一致性有要求,但不需要严格的可重复读
-
并发量高,对数据库的QPS和响应时间有严格要求
-
写操作频繁,尤其是范围更新、批量插入的场景
-
业务可以接受同一个事务内两次查询结果不一致,或者通过业务逻辑规避不可重复读的影响
互联网头部企业的实践经验表明,90%以上的OLTP业务使用RC级别,能在保证数据一致性的前提下,获得最高的并发性能和最低的死锁概率。
4.2.2 优先选择可重复读(RR)的场景
对数据一致性要求极高的业务场景,适合使用RR级别,包括金融支付、核心账务、资金结算、库存强校验等场景。
核心适用条件:
-
业务要求同一个事务内多次查询结果必须完全一致
-
对幻读零容忍,比如账务对账、资金统计等场景
-
并发量可控,不会出现大范围的范围更新和批量写入
-
业务逻辑依赖事务内的可重复读特性,比如先查询校验、再写入的强校验场景
4.2.3 其他隔离级别的适用场景
-
读未提交:仅适用于非核心、无一致性要求的实时统计场景,比如PV/UV打点、非核心的实时大盘,生产环境几乎不用。
-
串行化:仅适用于对数据一致性要求极致、并发量极低的监管合规类场景,比如央行报备数据、核心账务的最终对账,生产环境极少使用。
4.3 生产环境选型避坑指南
坑1:RR级别下非唯一索引的范围查询导致全表锁死
RR级别下,若查询条件没有命中索引,InnoDB会退化为全表扫描,给所有记录和间隙加临键锁,相当于锁全表,导致所有写入操作被阻塞,生产环境极易引发雪崩。
避坑方案:
-
所有DML语句必须命中索引,禁止无索引的范围更新和删除
-
高并发场景下,尽量避免使用范围查询的锁定读
-
核心写操作使用唯一索引的等值查询,仅触发记录锁,避免间隙锁
坑2:RC级别下使用STATEMENT格式binlog导致主从不一致
RC级别下,事务的执行顺序和提交顺序可能不一致,STATEMENT格式的binlog会记录SQL语句的执行顺序,导致从库执行结果和主库不一致,出现数据错乱。
避坑方案:
-
无论使用哪种隔离级别,binlog_format必须设置为ROW格式,MySQL 8.0默认即为ROW格式
-
禁止生产环境使用STATEMENT格式的binlog
坑3:RR级别下长事务导致undo log严重膨胀
RR级别下,事务的Read View会复用整个事务生命周期,undo log必须保留到事务结束才能被purge。若出现长事务,会导致undo log持续膨胀,占用大量磁盘空间,同时影响数据库的查询性能。
避坑方案:
-
禁止长事务,所有事务必须控制在秒级,核心业务事务时长不超过100ms
-
开启autocommit,避免忘记提交事务导致的长事务
-
搭建长事务监控告警,及时处理异常长事务
坑4:误以为RR级别完全杜绝幻读
InnoDB RR级别仅在纯快照读或纯当前读的场景下杜绝幻读,若事务内混合使用快照读和当前读,可能出现"幻行"现象。
可复现SQL示例
-- 1. 初始化数据
TRUNCATE TABLE t_isolation_test;
INSERT INTO `t_isolation_test` (`id`, `name`, `balance`) VALUES (1, '张三', 1000);
-- 2. 会话A:开启RR事务,先执行快照读
SET SESSION transaction_isolation = 'REPEATABLE-READ';
START TRANSACTION;
SELECT * FROM t_isolation_test WHERE id BETWEEN 1 AND 3;
-- 快照读返回1行数据
-- 3. 会话B:插入数据并提交
SET SESSION transaction_isolation = 'REPEATABLE-READ';
START TRANSACTION;
INSERT INTO t_isolation_test (id, name, balance) VALUES (2, '李四', 2000);
COMMIT;
-- 4. 会话A:执行当前读更新所有符合条件的数据
UPDATE t_isolation_test SET balance = 0 WHERE id BETWEEN 1 AND 3;
-- 该语句会更新2行数据,包括会话B插入的id=2的行
-- 5. 会话A:再次执行快照读
SELECT * FROM t_isolation_test WHERE id BETWEEN 1 AND 3;
-- 快照读返回2行数据,出现了"幻行"该现象符合MVCC的可见性规则,因为更新操作修改了id=2的行,该行的DB_TRX_ID变为当前事务的ID,因此对当前事务的快照读可见。避坑方案:强一致性校验的场景,必须使用当前读做数据校验,禁止仅用快照读做校验。
4.4 生产环境配置建议
-
隔离级别配置:
# my.cnf 配置文件 transaction_isolation = READ-COMMITTED # 互联网业务推荐RC级别 # transaction_isolation = REPEATABLE-READ # 强一致性业务推荐RR级别 -
binlog配置:
binlog_format = ROW binlog_row_image = FULL -
事务相关配置:
autocommit = 1 innodb_lock_wait_timeout = 3 -
长事务监控:通过
information_schema.innodb_trx表监控事务时长,对超过阈值的事务告警。
五、业务代码实战
5.1 项目依赖配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.4</version>
<relativePath/>
</parent>
<groupId>com.jam</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>demo</name>
<description>MySQL事务隔离级别演示项目</description>
<properties>
<java.version>17</java.version>
<mybatis-plus.version>3.5.6</mybatis-plus.version>
<springdoc.version>2.5.0</springdoc.version>
<fastjson2.version>2.0.48</fastjson2.version>
<guava.version>33.1.0-jre</guava.version>
<lombok.version>1.18.30</lombok.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-transaction</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>${springdoc.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>${fastjson2.version}</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${guava.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>5.2 数据库表结构
CREATE TABLE `t_account` (
`id` bigint NOT NULL AUTO_INCREMENT,
`username` varchar(32) NOT NULL DEFAULT '',
`balance` int NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_username` (`username`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `t_account` (`username`, `balance`) VALUES ('张三', 1000), ('李四', 2000);5.3 实体类定义
package com.jam.demo.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import io.swagger.v3.oas.annotations.media.Schema;
import lombok.Data;
import java.io.Serial;
import java.io.Serializable;
/**
* 账户实体
* @author ken
*/
@Data
@TableName("t_account")
@Schema(description = "账户实体")
public class Account implements Serializable {
@Serial
private static final long serialVersionUID = 1L;
@TableId(type = IdType.AUTO)
@Schema(description = "账户ID", example = "1")
private Long id;
@Schema(description = "用户名", example = "张三")
private String username;
@Schema(description = "账户余额", example = "1000")
private Integer balance;
}5.4 Mapper数据访问层
package com.jam.demo.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.jam.demo.entity.Account;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Update;
/**
* 账户Mapper
* @author ken
*/
public interface AccountMapper extends BaseMapper<Account> {
/**
* 扣减账户余额
* @param id 账户ID
* @param amount 扣减金额
* @return 影响行数
*/
@Update("UPDATE t_account SET balance = balance - #{amount} WHERE id = #{id} AND balance >= #{amount}")
int deductBalance(@Param("id") Long id, @Param("amount") Integer amount);
/**
* 增加账户余额
* @param id 账户ID
* @param amount 增加金额
* @return 影响行数
*/
@Update("UPDATE t_account SET balance = balance + #{amount} WHERE id = #{id}")
int addBalance(@Param("id") Long id, @Param("amount") Integer amount);
}5.5 Service业务逻辑层
package com.jam.demo.service;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.jam.demo.entity.Account;
import com.jam.demo.mapper.AccountMapper;
import com.google.common.collect.Maps;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import org.springframework.transaction.TransactionDefinition;
import org.springframework.transaction.TransactionStatus;
import org.springframework.transaction.support.TransactionCallback;
import org.springframework.transaction.support.TransactionTemplate;
import org.springframework.util.ObjectUtils;
import org.springframework.util.StringUtils;
import java.util.Map;
/**
* 账户服务
* @author ken
*/
@Slf4j
@Service
public class AccountService {
private final AccountMapper accountMapper;
private final TransactionTemplate transactionTemplate;
public AccountService(AccountMapper accountMapper, TransactionTemplate transactionTemplate) {
this.accountMapper = accountMapper;
this.transactionTemplate = transactionTemplate;
}
/**
* 转账操作
* @param fromId 转出账户ID
* @param toId 转入账户ID
* @param amount 转账金额
* @return 转账结果
*/
public Map<String, Object> transfer(Long fromId, Long toId, Integer amount) {
Map<String, Object> result = Maps.newHashMap();
if (ObjectUtils.isEmpty(fromId) || ObjectUtils.isEmpty(toId)) {
result.put("success", false);
result.put("message", "账户ID不能为空");
return result;
}
if (ObjectUtils.isEmpty(amount) || amount <= 0) {
result.put("success", false);
result.put("message", "转账金额必须大于0");
return result;
}
if (fromId.equals(toId)) {
result.put("success", false);
result.put("message", "转出和转入账户不能相同");
return result;
}
transactionTemplate.setIsolationLevel(TransactionDefinition.ISOLATION_READ_COMMITTED);
transactionTemplate.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
return transactionTemplate.execute(new TransactionCallback<Map<String, Object>>() {
@Override
public Map<String, Object> doInTransaction(TransactionStatus status) {
Map<String, Object> txResult = Maps.newHashMap();
try {
Account fromAccount = accountMapper.selectOne(
new LambdaQueryWrapper<Account>()
.eq(Account::getId, fromId)
.last("FOR UPDATE")
);
if (ObjectUtils.isEmpty(fromAccount)) {
txResult.put("success", false);
txResult.put("message", "转出账户不存在");
status.setRollbackOnly();
return txResult;
}
Account toAccount = accountMapper.selectOne(
new LambdaQueryWrapper<Account>()
.eq(Account::getId, toId)
);
if (ObjectUtils.isEmpty(toAccount)) {
txResult.put("success", false);
txResult.put("message", "转入账户不存在");
status.setRollbackOnly();
return txResult;
}
int deductRows = accountMapper.deductBalance(fromId, amount);
if (deductRows <= 0) {
txResult.put("success", false);
txResult.put("message", "账户余额不足");
status.setRollbackOnly();
return txResult;
}
int addRows = accountMapper.addBalance(toId, amount);
if (addRows <= 0) {
txResult.put("success", false);
txResult.put("message", "转入账户更新失败");
status.setRollbackOnly();
return txResult;
}
txResult.put("success", true);
txResult.put("message", "转账成功");
txResult.put("fromAccountBalance", fromAccount.getBalance() - amount);
txResult.put("toAccountBalance", toAccount.getBalance() + amount);
return txResult;
} catch (Exception e) {
log.error("转账操作异常", e);
status.setRollbackOnly();
txResult.put("success", false);
txResult.put("message", "系统异常,请稍后重试");
return txResult;
}
}
});
}
/**
* 根据用户名查询账户信息
* @param username 用户名
* @return 账户信息
*/
public Account getAccountByUsername(String username) {
if (!StringUtils.hasText(username)) {
return null;
}
return accountMapper.selectOne(
new LambdaQueryWrapper<Account>()
.eq(Account::getUsername, username)
);
}
}5.6 Controller接口层
package com.jam.demo.controller;
import com.jam.demo.entity.Account;
import com.jam.demo.service.AccountService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.Parameter;
import io.swagger.v3.oas.annotations.tags.Tag;
import org.springframework.web.bind.annotation.*;
import java.util.Map;
/**
* 账户控制器
* @author ken
*/
@RestController
@RequestMapping("/account")
@Tag(name = "账户管理", description = "账户相关操作接口")
public class AccountController {
private final AccountService accountService;
public AccountController(AccountService accountService) {
this.accountService = accountService;
}
@PostMapping("/transfer")
@Operation(summary = "账户转账", description = "执行两个账户之间的转账操作")
public Map<String, Object> transfer(
@Parameter(description = "转出账户ID", required = true, example = "1") @RequestParam Long fromId,
@Parameter(description = "转入账户ID", required = true, example = "2") @RequestParam Long toId,
@Parameter(description = "转账金额", required = true, example = "100") @RequestParam Integer amount
) {
return accountService.transfer(fromId, toId, amount);
}
@GetMapping("/info")
@Operation(summary = "查询账户信息", description = "根据用户名查询账户详情")
public Account getAccountInfo(
@Parameter(description = "用户名", required = true, example = "张三") @RequestParam String username
) {
return accountService.getAccountByUsername(username);
}
}六、常见误区与核心问题解答
误区1:MySQL的RR级别完全解决了幻读
InnoDB RR级别仅在纯快照读或纯当前读的场景下杜绝幻读。若事务内混合使用快照读和当前读,会出现符合MVCC规则的"幻行"现象,并非标准定义的幻读,但会影响业务逻辑的正确性。强一致性校验场景必须使用当前读做数据校验。
误区2:MVCC是完全无锁的
MVCC仅针对快照读实现了无锁读取,避免了读写冲突。但当前读、更新、删除操作仍然需要加锁,MVCC和锁机制是InnoDB实现隔离性的两大互补支柱,而非互斥。
误区3:RR级别性能一定比RC级别好
绝大多数高并发OLTP场景下,RC级别的性能远优于RR级别。RC级别没有间隙锁,锁冲突和死锁概率极低,同时undo log purge更及时,不会出现undo log膨胀的问题,并发能力更强。
误区4:所有业务都应该使用MySQL默认的RR级别
MySQL默认的RR级别是为了兼容历史版本的主从复制,并非最优的生产配置。互联网行业90%以上的OLTP业务都使用RC级别,在保证数据一致性的前提下,获得最高的并发性能。
误区5:串行化级别就是表锁
串行化级别下,普通SELECT会被转换为SELECT ... LOCK IN SHARE MODE,加行级共享锁,而非表锁。只有当查询没有命中索引时,才会退化为全表锁,这和RR级别无索引查询的锁机制一致。
七、总结
MySQL事务隔离级别的核心,是在数据一致性和并发性能之间做平衡。理解底层的MVCC实现、Read View生成规则、锁机制,是正确选择隔离级别、规避线上数据库问题的核心前提。
生产环境的选型没有标准答案,核心是贴合业务场景:对数据一致性要求极高的金融核心业务,优先选择RR级别;绝大多数高并发OLTP业务,优先选择RC级别,配合ROW格式binlog,在保证数据一致性的前提下,获得最优的并发性能。