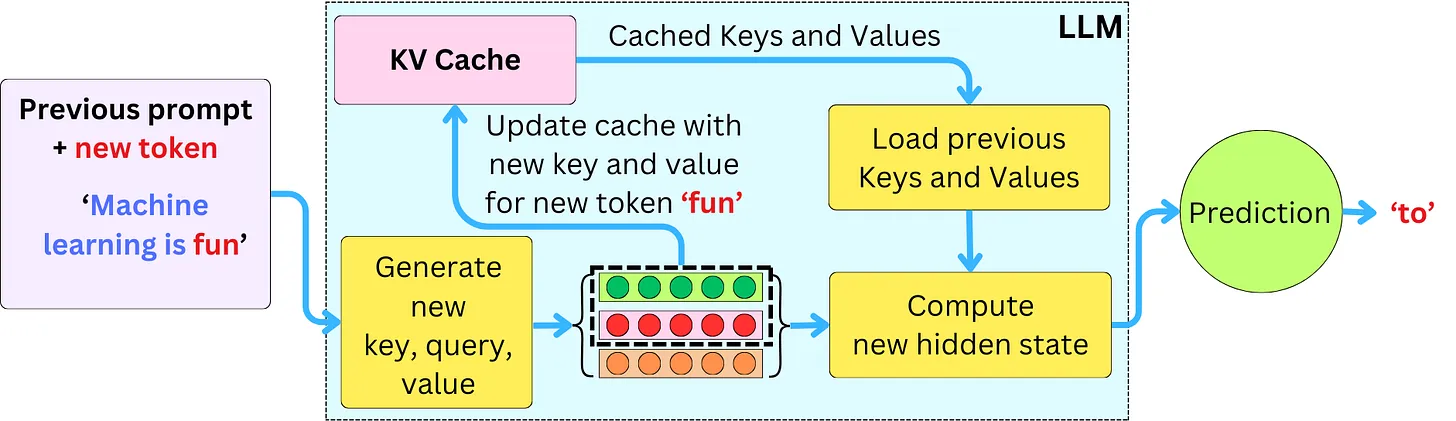
KV Cache 是如何降低大模型的Decode耗时的
flyfish
大模型推理的两个阶段:Prefill(预填充)和 Decode(解码)
大模型推理中 KV Cache为什么没有Q Cache
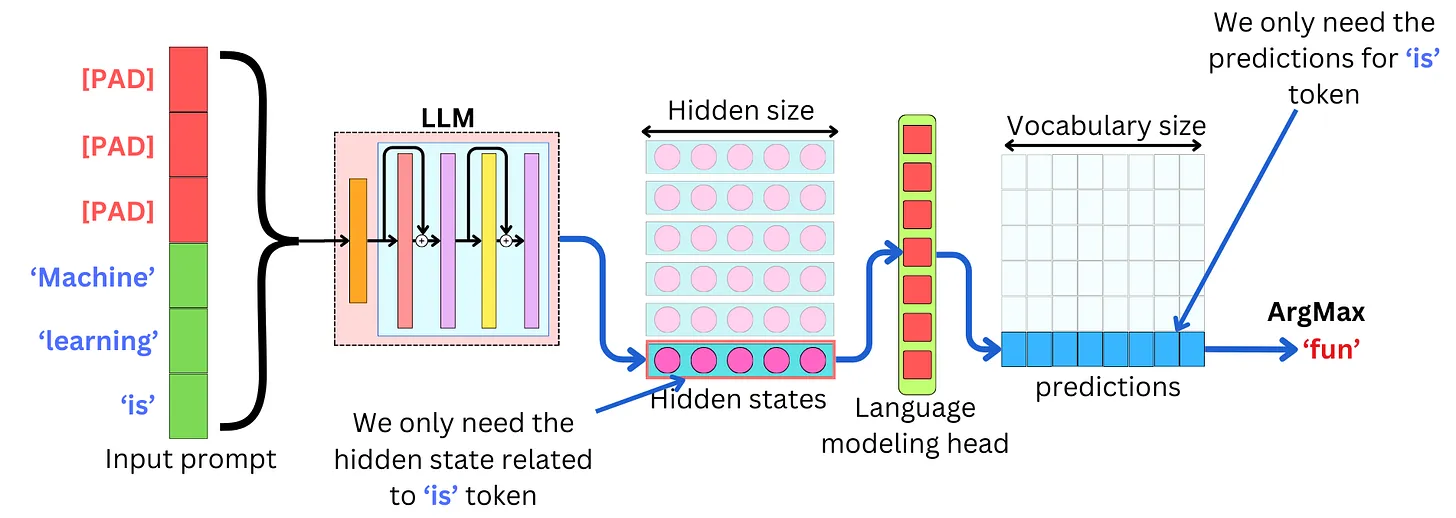
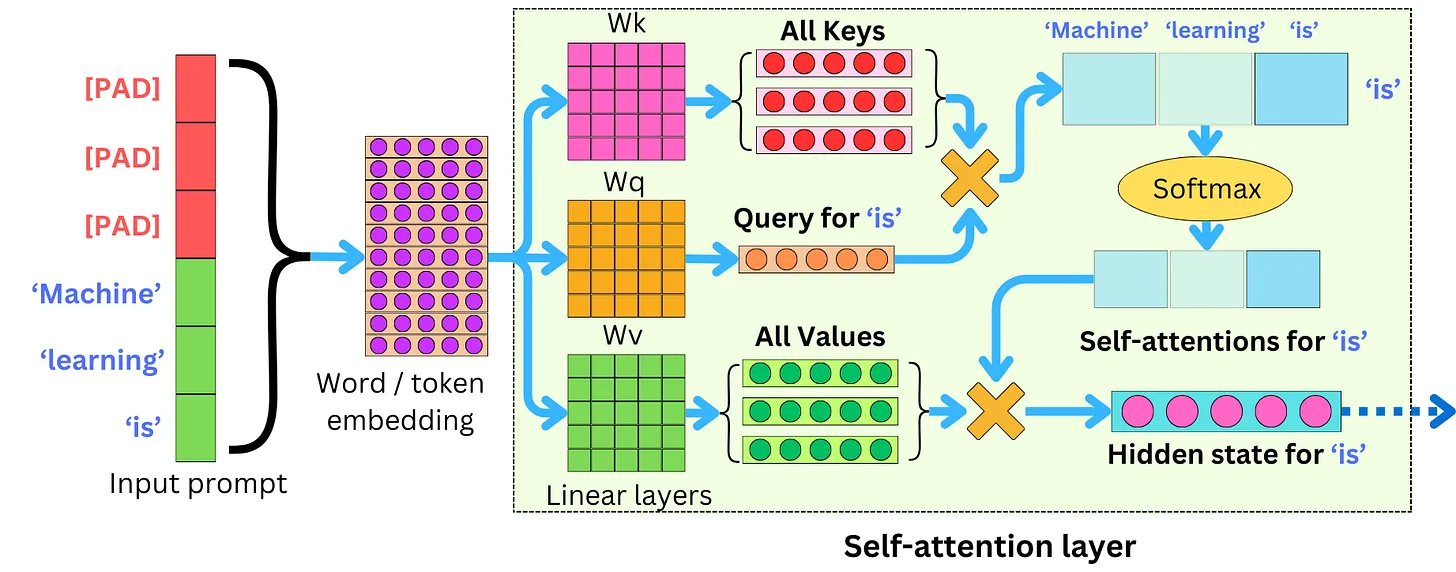
Transformer 的 Self-Attention Layer 在处理输入提示 Machine learning is 时,具体为 'is' 这个 token 计算自注意力的流程
-
输入编码阶段
先把
Input prompt(比如Machine learning is+ 若干[PAD])做 Tokenization,得到一串离散的 Token ID;把这些 Token ID 送入 Token Embedding 层,转换成高维向量,再加上 Positional Encoding(位置编码),得到最终的 Input Embeddings------这是模型能理解的初始输入表示,形状为
[sequence_length, hidden_size]。 -
LLM 计算阶段(多层 Transformer Block 堆叠)
每一层 Transformer Block 都会对 Input Embeddings(或前一层的 Hidden State)做如下计算:
a. Multi-head Self-Attention 计算
把当前输入(Input Embeddings / Hidden State)分别通过 3 个独立线性层,投影得到 Q (Query)、K (Key)、V (Value) 三个张量,形状均为
[sequence_length, hidden_size];计算 Q 和 K 的点积,得到 Attention Scores,再除以
√d_k(d_k 是 Q/K 的维度)做 Scale;对 Attention Scores 做 Softmax 运算,得到 Attention Weights------这是每个 token 对序列中所有其他 token 的注意力权重,代表"当前 token 需要关注其他哪些 token 的信息";
用 Attention Weights 对 V 做加权求和,得到 Attention Output,这是融合了上下文信息后的特征表示。
b. 残差连接与 Layer Norm
把 Attention Output 和原始输入做残差连接(Add),再经过 Layer Norm 层归一化,稳定训练。
c. FFN 计算
把归一化后的结果送入 Feed Forward Network (FFN) 层,做两次线性变换+激活函数(比如 GELU),得到该层的 Hidden State;
再次做残差连接+Layer Norm,作为下一层 Transformer Block 的输入。
所有 N 层 Transformer Block 计算完成后,得到整个输入序列的 Hidden States(形状
[sequence_length, hidden_size]),每个 token 都对应一个 Hidden State,编码了它在上下文里的完整语义信息。 -
解码阶段
只需要提取最后一个有效 token(比如
is)对应的 Hidden State------因为自回归解码只依赖当前序列末尾的语义信息来预测下一个 token;把这个目标 Hidden State 送入 Language Modeling Head(一个线性层),将维度从
hidden_size映射到vocabulary_size,得到 Predictions------这是词表中每个 token 成为下一个 token 的概率分布;对 Predictions 执行 ArgMax 操作,选出概率值最高的 token(比如
fun),作为本次生成的下一个 token;把新生成的 token 追加到原
Input prompt末尾,形成新的输入序列,重复上述所有流程,直到模型生成结束符(比如<|endoftext|>)或达到预设最大序列长度。第 t 步(生成第 t 个 token 时):
注意力公式
Q = X W Q K = X W K V = X W V Attention ( Q , K , V ) = softmax ( Q K T d k ) V \begin{align} Q &= XW^Q \\ K &= XW^K \\ V &= XW^V \\ \text{Attention}(Q,K,V) &= \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \end{align} QKVAttention(Q,K,V)=XWQ=XWK=XWV=softmax(dk QKT)V

拆开
score old = q t new ( K old ) ⊤ d ← 旧历史部分 score new = q t new ( k t new ) ⊤ d ← 只跟自己比 scores = concat ( score old , score new ) attn = softmax ( scores ) output t = attn ⋅ concat ( V old , v t new ) \begin{align*} \text{score}_\text{old} &\;=\; \frac{ \mathbf{q}t^\text{new} \, (\mathbf{K}^\text{old})^\top }{ \sqrt{d} } &&\qquad \text{← 旧历史部分} \\1.2em \text{score}\text{new} &\;=\; \frac{ \mathbf{q}t^\text{new} \, (\mathbf{k}t^\text{new})^\top }{ \sqrt{d} } &&\qquad \text{← 只跟自己比} \\1.2em \text{scores} &\;=\; \text{concat}(\;\text{score}\text{old},\;\; \text{score}\text{new}\;) \\1.0em \text{attn} &\;=\; \text{softmax}(\text{scores}) \\1.0em \text{output}_t &\;=\; \text{attn} \cdot \text{concat}(\;\mathbf{V}^\text{old},\;\; \mathbf{v}_t^\text{new}\;) \end{align*} scoreoldscorenewscoresattnoutputt=d qtnew(Kold)⊤=d qtnew(ktnew)⊤=concat(scoreold,scorenew)=softmax(scores)=attn⋅concat(Vold,vtnew)← 旧历史部分← 只跟自己比
符号含义
| 符号 | 含义 | 新 / 旧 | 这一步是否计算 | 是否进入下一轮的 cache |
|---|---|---|---|---|
| q _t new | 当前 token 的 query | 新 | 是 | 不进入 cache |
| k _t new | 当前 token 的 key | 新 | 是 | 进入 cache |
| v _t new | 当前 token 的 value | 新 | 是 | 进入 cache |
| K old | 之前所有步的 keys 拼起来的矩阵 | 旧 | 不用重新算 | 已经 在 cache 里 |
| V old | 之前所有步的 values 拼起来的矩阵 | 旧 | 不用重新算 | 已经 在 cache 里 |
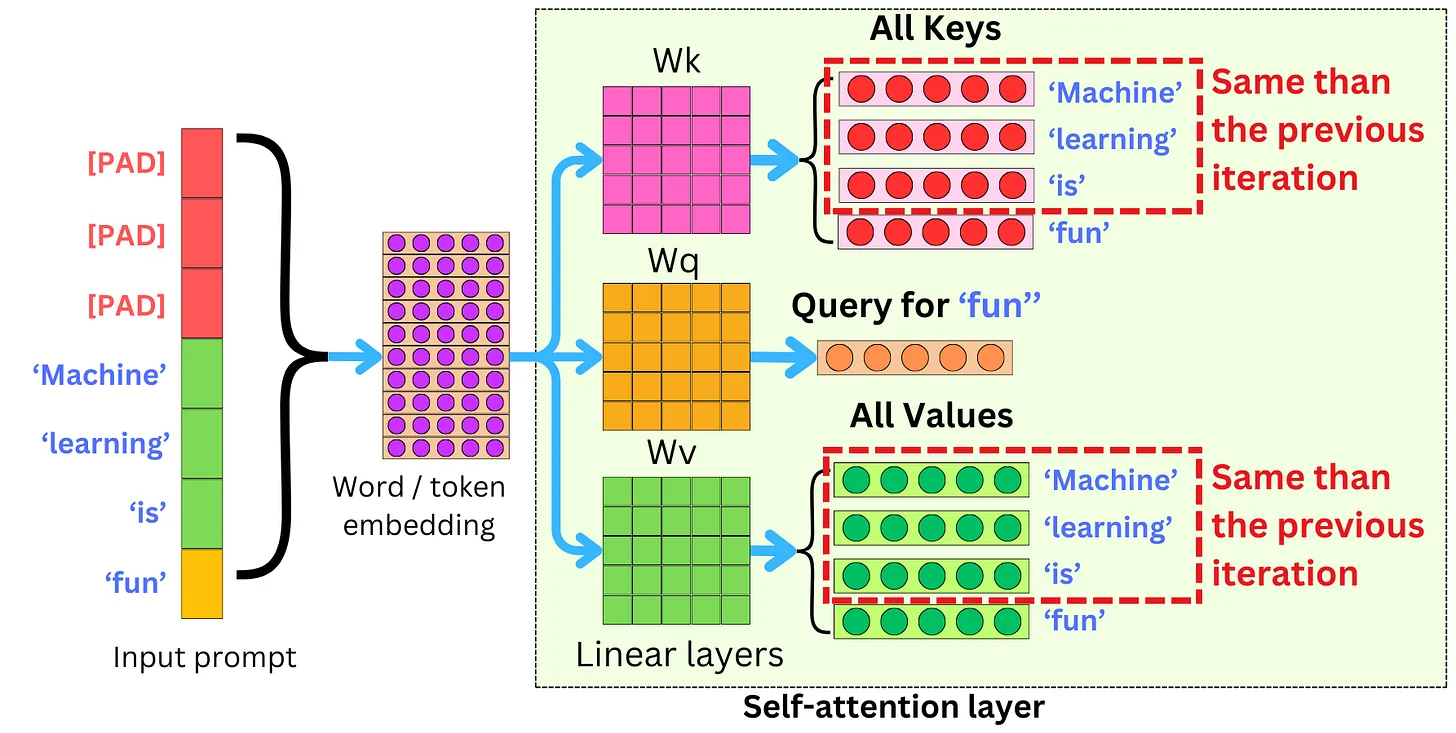
如果没有 KV Cache,每生成一个新 token 就要:
把前面所有已经生成的 token 全部重新过一遍 Transformer 的 self-attention 层
重新算出它们全部的 Key 和 Value
再拿现在的 Query 跟它们全部做 dot-product
加入 KV Cache后
代码
cpp
import torch
import torch.nn.functional as F
# ====================== 注意力函数 ======================
def scaled_dot_product_attention(q, k, v):
# q: (1, d), k/v: (seq_len, d)
d = q.shape[-1]
scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(d, dtype=torch.float32))
attn_weights = F.softmax(scores, dim=-1)
output = torch.matmul(attn_weights, v)
return output
# ====================== 参数与模拟数据 ======================
torch.manual_seed(42) # 保证可复现
head_dim = 64
seq_len = 5
# 模拟 token embeddings(实际中是 embedding + 各层投影,这里简化 Q=K=V=x)
x_tokens = [torch.randn(head_dim) for _ in range(seq_len)]
# ====================== 1. 无 Cache 的全量计算 ======================
print("=== 无Cache的全量计算(每次重新算整个序列)===")
full_outputs = []
for i in range(seq_len):
full_seq = torch.stack(x_tokens[:i+1]) # (curr_len, d)
q = x_tokens[i].unsqueeze(0) # (1, d)
k = full_seq
v = full_seq
out = scaled_dot_product_attention(q, k, v)
full_outputs.append(out)
print(f"Token {i} 输出shape: {out.shape}")
# ====================== 2. 使用 KV Cache 的增量推理 ======================
print("\n=== 使用KV Cache的增量推理(只算当前Q,复用历史KV)===")
k_cache = None
v_cache = None
kv_outputs = []
for i in range(seq_len):
current_x = x_tokens[i].unsqueeze(0) # (1, d)
current_q = current_x
current_k = current_x
current_v = current_x
# === 关键:只 append K 和 V,Q 从不缓存 ===
if k_cache is None:
k_cache = current_k
v_cache = current_v
else:
k_cache = torch.cat([k_cache, current_k], dim=0)
v_cache = torch.cat([v_cache, current_v], dim=0)
# 用当前 Q + 历史 KV 计算
out = scaled_dot_product_attention(current_q, k_cache, v_cache)
kv_outputs.append(out)
print(f"Token {i} 输出shape: {out.shape},Cache长度: {k_cache.shape[0]}")
# ====================== 对比验证 ======================
print("\n=== 对比结果(应完全一致)===")
for i in range(seq_len):
max_diff = torch.abs(full_outputs[i] - kv_outputs[i]).max().item()
print(f"Token {i} 最大差异: {max_diff:.2e}")
print("\n结论:KV Cache完全等价于全量计算,但速度更快、显存更省(无需重复算历史KV)")