理解多元微积分和优化理论中的核心概念确实需要一些时间,因为它们在刚接触时会显得有些抽象。不过不用担心,我们将Hessian矩阵(海森矩阵)拆解开来看,它其实就是一元函数中"二阶导数"在多元函数里的直接推广。
简单来说,如果一阶导数(梯度)告诉我们"下坡的方向",那么Hessian矩阵就告诉我们"地面有多弯曲"。
以下是对Hessian矩阵的详细介绍:
什么是Hessian矩阵?
在数学中,Hessian矩阵是一个由多变量实值函数的二阶偏导数构成的方阵。它主要用于描述函数的局部曲率(Curvature)。
- 常见误区纠正 :初学者有时会混淆Hessian矩阵和Jacobian矩阵(雅可比矩阵)。请记住:Jacobian矩阵是由一阶偏导数 组成的(常用于向量值函数),而Hessian矩阵是由二阶偏导数组成的(专用于标量值函数)。
严格的数学定义
假设有一个多元函数 f(x1,x2,...,xn)f(x_1, x_2, \dots, x_n)f(x1,x2,...,xn),如果它的所有二阶偏导数都存在,那么该函数的Hessian矩阵 HHH(有时也记作 ∇2f\nabla^2 f∇2f)是一个 n×nn \times nn×n 的方阵,其第 iii 行第 jjj 列的元素定义为:
Hi,j=∂2f∂xi∂xjH_{i,j} = \frac{\partial^2 f}{\partial x_i \partial x_j}Hi,j=∂xi∂xj∂2f
把它完全展开,矩阵的形式如下:
H=∂2f∂x12∂2f∂x1∂x2⋯∂2f∂x1∂xn∂2f∂x2∂x1∂2f∂x22⋯∂2f∂x2∂xn⋮⋮⋱⋮∂2f∂xn∂x1∂2f∂xn∂x2⋯∂2f∂xn2 H = \begin{bmatrix} \frac{\partial^2 f}{\partial x_1^2} & \frac{\partial^2 f}{\partial x_1 \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_1 \partial x_n} \\ \frac{\partial^2 f}{\partial x_2 \partial x_1} & \frac{\partial^2 f}{\partial x_2^2} & \cdots & \frac{\partial^2 f}{\partial x_2 \partial x_n} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial^2 f}{\partial x_n \partial x_1} & \frac{\partial^2 f}{\partial x_n \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_n^2} \end{bmatrix} H= ∂x12∂2f∂x2∂x1∂2f⋮∂xn∂x1∂2f∂x1∂x2∂2f∂x22∂2f⋮∂xn∂x2∂2f⋯⋯⋱⋯∂x1∂xn∂2f∂x2∂xn∂2f⋮∂xn2∂2f
重要性质(对称性) :根据克莱罗定理(Clairaut's theorem),如果在该点附近二阶偏导数是连续的,那么求导的顺序不影响结果(即 ∂2f∂xi∂xj=∂2f∂xj∂xi\frac{\partial^2 f}{\partial x_i \partial x_j} = \frac{\partial^2 f}{\partial x_j \partial x_i}∂xi∂xj∂2f=∂xj∂xi∂2f)。因此,Hessian矩阵在绝大多数实际应用中都是一个对称矩阵。
几何意义与直观理解
在一元函数 y=f(x)y = f(x)y=f(x) 中,二阶导数 f′′(x)f''(x)f′′(x) 决定了曲线是"向上凹"(像个碗,极小值)还是"向下凸"(像把伞,极大值)。
在多元函数 z=f(x,y)z = f(x, y)z=f(x,y) 中,我们面对的是一个三维空间中的曲面。Hessian矩阵不仅告诉我们各个单一方向上的曲率(对角线元素),还告诉我们交叉方向上的扭曲程度(非对角线元素)。它完整地刻画了曲面在某一点的"碗状"或"马鞍状"特征。
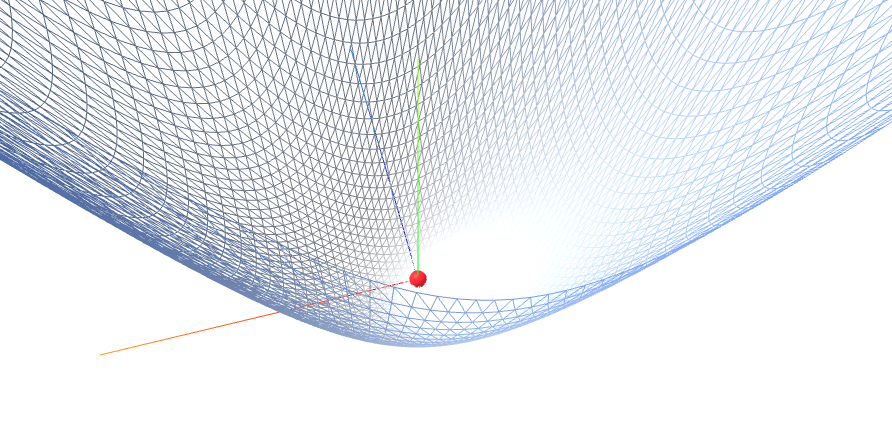
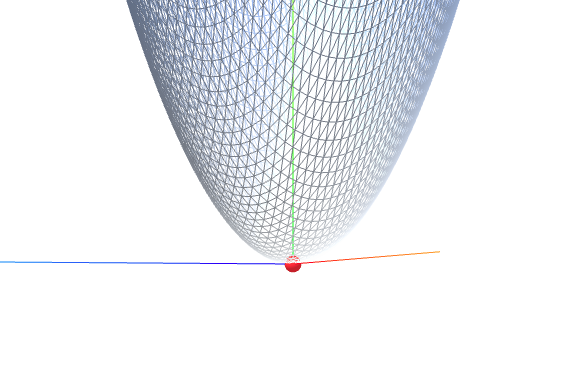
f(x,y) = x^2 + y^2
f(x,y) = x^2 - y^2
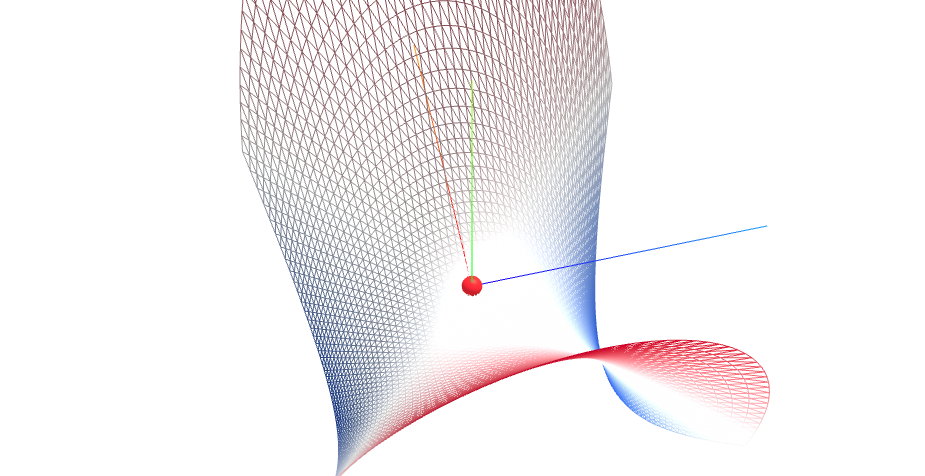
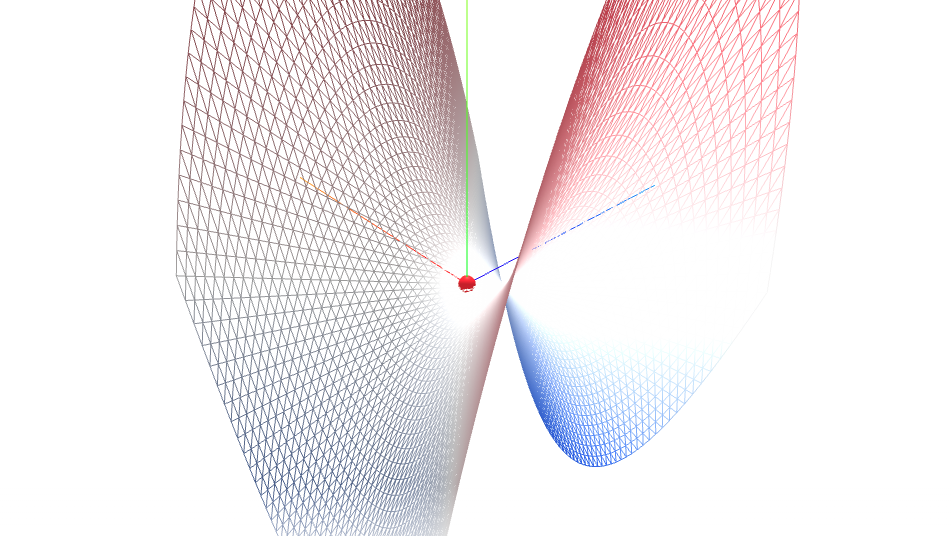
我们将通过两个非常经典的二维函数来演示整个过程:一个是"碗状"的 f(x,y)=x2+y2f(x,y) = x^2 + y^2f(x,y)=x2+y2,另一个是"马鞍状"的 f(x,y)=x2−y2f(x,y) = x^2 - y^2f(x,y)=x2−y2。
找极值点的标准流程分为三步:
- 求一阶导数(梯度),并令其为0,找到"平坦"的候选点(驻点)。
- 求二阶导数,构建Hessian矩阵。
- 分析Hessian矩阵的特征值,判定该驻点到底是极小值、极大值还是鞍点。
例子 1:寻找"碗底" ------ f(x,y)=x2+y2f(x,y) = x^2 + y^2f(x,y)=x2+y2
第一步:求梯度,找驻点
我们分别对 xxx 和 yyy 求一阶偏导数:
- ∂f∂x=2x\frac{\partial f}{\partial x} = 2x∂x∂f=2x
- ∂f∂y=2y\frac{\partial f}{\partial y} = 2y∂y∂f=2y
令它们都等于 0:
2x=0 ⟹ x=02x = 0 \implies x = 02x=0⟹x=0
2y=0 ⟹ y=02y = 0 \implies y = 02y=0⟹y=0
我们找到了一个唯一的驻点:(0,0)(0, 0)(0,0)。
第二步:计算二阶偏导数,构建Hessian矩阵
现在我们对上面的一阶导数继续求导:
- 对 xxx 再求导:∂2f∂x2=2\frac{\partial^2 f}{\partial x^2} = 2∂x2∂2f=2
- 对 yyy 再求导:∂2f∂y2=2\frac{\partial^2 f}{\partial y^2} = 2∂y2∂2f=2
- 交叉求导(先对 xxx 后对 yyy,或先对 yyy 后对 xxx):∂2f∂x∂y=0\frac{\partial^2 f}{\partial x \partial y} = 0∂x∂y∂2f=0,∂2f∂y∂x=0\frac{\partial^2 f}{\partial y \partial x} = 0∂y∂x∂2f=0
将这些值填入Hessian矩阵:
H=2002H = \begin{bmatrix} 2 & 0 \\ 0 & 2 \end{bmatrix}H=2002
第三步:分析特征值,得出结论
这是一个对角矩阵,它的特征值就是对角线上的元素,即 λ1=2\lambda_1 = 2λ1=2,λ2=2\lambda_2 = 2λ2=2。
- 因为所有特征值都大于 0 ,所以这个Hessian矩阵是正定矩阵(Positive Definite)。
- 结论 :驻点 (0,0)(0, 0)(0,0) 是一个局部极小值(Local Minimum)。从几何上看,这个函数在原点处向所有方向都是"向上弯曲"的,形状像一个碗。
例子 2:典型的"马鞍" ------ f(x,y)=x2−y2f(x,y) = x^2 - y^2f(x,y)=x2−y2
第一步:求梯度,找驻点
- ∂f∂x=2x\frac{\partial f}{\partial x} = 2x∂x∂f=2x
- ∂f∂y=−2y\frac{\partial f}{\partial y} = -2y∂y∂f=−2y
令它们都等于 0,同样得到唯一的驻点:(0,0)(0, 0)(0,0)。
第二步:计算二阶偏导数,构建Hessian矩阵
- 对 xxx 再求导:∂2f∂x2=2\frac{\partial^2 f}{\partial x^2} = 2∂x2∂2f=2
- 对 yyy 再求导:∂2f∂y2=−2\frac{\partial^2 f}{\partial y^2} = -2∂y2∂2f=−2
- 交叉求导:∂2f∂x∂y=0\frac{\partial^2 f}{\partial x \partial y} = 0∂x∂y∂2f=0,∂2f∂y∂x=0\frac{\partial^2 f}{\partial y \partial x} = 0∂y∂x∂2f=0
得到Hessian矩阵:
H=200−2H = \begin{bmatrix} 2 & 0 \\ 0 & -2 \end{bmatrix}H=200−2
第三步:分析特征值,得出结论
同样是对角矩阵,特征值为 λ1=2\lambda_1 = 2λ1=2 和 λ2=−2\lambda_2 = -2λ2=−2。
- 因为特征值有正有负 (沿着 xxx 轴方向曲率是正的,沿着 yyy 轴方向曲率是负的),这个Hessian矩阵是不定矩阵(Indefinite)。
- 结论 :驻点 (0,0)(0, 0)(0,0) 是一个鞍点(Saddle Point) 。如果你站在 (0,0)(0,0)(0,0) 点,往前看或往后看,地势是上升的(像马的脖子和尾巴);往左看或往右看,地势是下降的(像骑马时腿放下的地方)。它不是极值点。
通过这套流程,复杂的多元微积分就变成了一套标准的"体检程序":梯度负责找疑似点,Hessian矩阵负责对疑似点进行确诊。
在优化问题中的核心作用(极值判定)
Hessian矩阵最著名的应用是在寻找函数的局部极值(多元函数的二阶导数测试)。
当我们通过令梯度(一阶导数)为零,找到一个驻点(Stationary point)后,我们需要通过计算该点的Hessian矩阵的**特征值(Eigenvalues)**来判断这个点到底是什么:
-
正定矩阵(Positive Definite):
- 条件 :Hessian矩阵的所有特征值都大于 0(H≻0H \succ 0H≻0)。
- 几何意义:曲面在所有方向上都"向上凹"。
- 结论 :该点是一个局部极小值(Local Minimum)。
-
负定矩阵(Negative Definite):
- 条件 :Hessian矩阵的所有特征值都小于 0(H≺0H \prec 0H≺0)。
- 几何意义:曲面在所有方向上都"向下凸"。
- 结论 :该点是一个局部极大值(Local Maximum)。
-
不定矩阵(Indefinite):
- 条件:特征值既有正的也有负的。
- 几何意义:在某些方向上曲面是向上凹的,在另一些方向上是向下凸的。这就像马鞍的形状。
- 结论 :该点是一个鞍点(Saddle Point),不是极值点。
(注:如果Hessian是半正定或半负定,即包含特征值为0的情况,则需要更高阶的导数来判断。)
在机器学习和深度学习中的重要性
- 牛顿法(Newton's Method) :在训练模型求最优解时,通常使用梯度下降法(只用一阶导数)。但牛顿法同时利用了梯度和Hessian矩阵的逆矩阵 H−1H^{-1}H−1。它不仅知道往哪走(梯度),还知道走多远(曲率),因此收敛速度通常比梯度下降快得多(二阶收敛)。不过,由于计算和存储高维Hessian矩阵的代价极大,深度学习中通常使用近似方法(如拟牛顿法 BFGS 或 L-BFGS)。
- 鞍点问题 :在极高维的神经网络损失函数地貌(Loss landscape)中,局部极小值其实很少,真正的优化难点是无数的鞍点。Hessian矩阵的分析帮助研究人员理解了为什么标准的梯度下降在某些情况下会卡住,以及如何设计更好的优化器(如Adam)来逃离这些包含负特征值和正特征值方向的鞍点。
为了更容易理解,我们先打个比方:
假设你被蒙上眼睛放在半山腰,目标是走到谷底(寻找函数的局部极小值)。
- 梯度下降法(Gradient Descent) :你用脚探一探周围,发现"前方的坡度向下",于是你往前迈了一小步(这一步的大小就是"学习率")。走到新位置后,你再探一探,再走一步。你只知道方向 ,不知道谷底具体有多远。
- 牛顿法(Newton's Method) :你不仅用脚探出了"前方的坡度向下"(梯度),还通过脚底感觉到了"地面的弯曲程度就像一个平缓的碗"(Hessian矩阵)。通过这两种信息的结合,你的大脑瞬间算出了一个抛物线模型,并得出结论:"谷底在正前方 3.2 米处"。于是,你直接跨越 3.2 米,一步到位。
这就是牛顿法的核心魅力:利用二阶导数(曲率)来指导搜索,从而实现极快的收敛。
牛顿法的数学推导(核心思想:用抛物线去逼近)
在任意一点 xkx_kxk,牛顿法并不直接寻找原函数 f(x)f(x)f(x) 的最小值,而是利用**二阶泰勒展开式(Taylor Expansion)**在这个点附近构造一个局部的二次函数(即一个"碗"或者抛物面)来近似原函数:
f(x)≈f(xk)+∇f(xk)T(x−xk)+12(x−xk)TH(x−xk)f(x) \approx f(x_k) + \nabla f(x_k)^T (x - x_k) + \frac{1}{2} (x - x_k)^T H (x - x_k)f(x)≈f(xk)+∇f(xk)T(x−xk)+21(x−xk)TH(x−xk)
其中:
- ∇f(xk)\nabla f(x_k)∇f(xk) 是当前点的一阶导数(梯度向量)。
- HHH 是当前点的二阶导数(Hessian矩阵)。
既然我们要找极小值,最直接的办法就是直接跳到这个近似抛物面的最低点 。对上面这个近似函数求导并令其等于0,我们可以解出下一步的位置 xk+1x_{k+1}xk+1。
这就是牛顿法的参数更新公式 :
xk+1=xk−H−1∇f(xk)x_{k+1} = x_k - H^{-1} \nabla f(x_k)xk+1=xk−H−1∇f(xk)
对比梯度下降:Hessian逆矩阵的神奇作用
让我们把牛顿法和大家最熟悉的梯度下降法放在一起看:
- 梯度下降 :xk+1=xk−α∇f(xk)x_{k+1} = x_k - \alpha \nabla f(x_k)xk+1=xk−α∇f(xk) (其中 α\alphaα 是人为设定的固定标量,即学习率)
- 牛顿法 :xk+1=xk−H−1∇f(xk)x_{k+1} = x_k - H^{-1} \nabla f(x_k)xk+1=xk−H−1∇f(xk)
我们可以把 Hessian矩阵的逆矩阵 H−1H^{-1}H−1 看作是一个**"超级智能、自适应且带有方向感"的学习率**:
- 自适应步长 :如果地面非常平缓(Hessian特征值小),H−1H^{-1}H−1 的值就会很大,算法会聪明地迈出很大的一步;如果地面非常陡峭(Hessian特征值大),H−1H^{-1}H−1 的值就会很小,算法会谨慎地迈出一小步,防止越过谷底。
- 纠正方向 :梯度下降永远垂直于等高线走,如果在"狭长的山谷"(比如椭圆形等高线)中,它会疯狂地呈"之"字形震荡。而 H−1H^{-1}H−1 包含交叉偏导数信息,它能够扭转梯度的方向,让更新路线直接指向真正的谷底中心。
直观对比:牛顿法 vs 梯度下降的寻优路径
为了展示Hessian矩阵是如何消除"震荡"并实现"一步到位"的,生成了一个交互式的 2D 等高线优化可视化工具。可以对比两种算法在一个具有挑战性的"狭长山谷"(椭圆抛物面)中的表现。
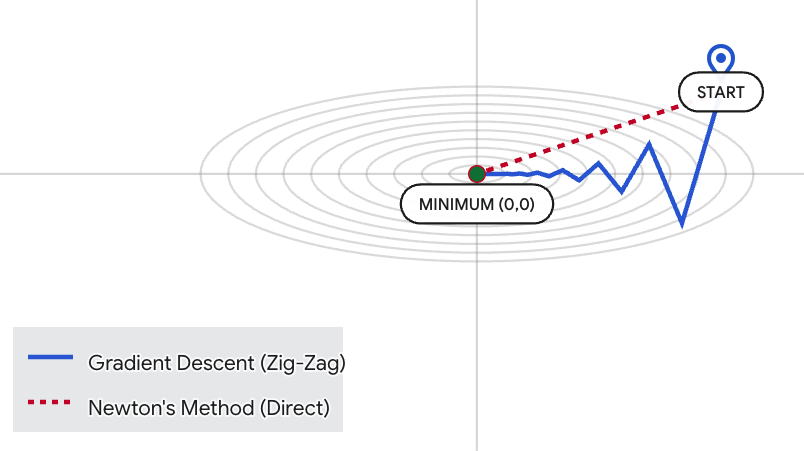
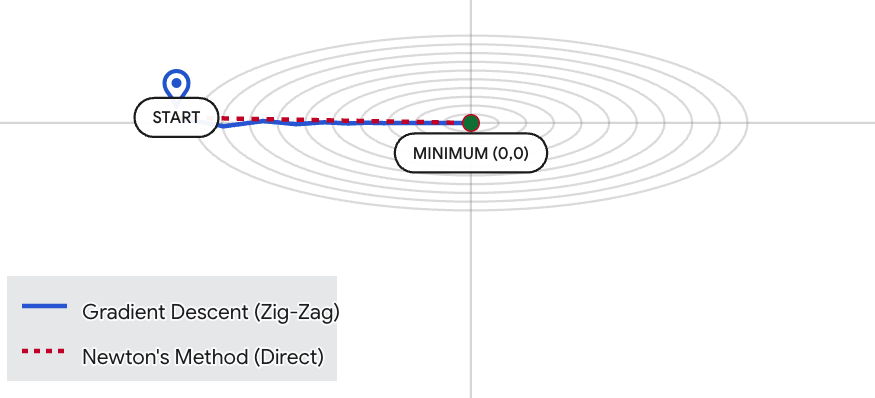
既然牛顿法这么强,为什么深度学习不怎么用它?
既然牛顿法收敛极快(数学上称为二阶收敛),为什么我们在训练 ChatGPT 或其他大模型时,首选的还是 Adam 或 SGD(一阶方法),而不是牛顿法呢?
这就是现实与理论的碰撞,主要原因有三个:
- 计算和存储成本极高(最致命的弱点) :
假设一个神经网络有 nnn 个参数。它的梯度是一个长度为 nnn 的向量。但它的 Hessian 矩阵是一个 n×nn \times nn×n 的方阵。
对于一个拥有 10 亿参数的现代语言模型,Hessian 矩阵包含 101810^{18}1018 个元素!仅仅把这个矩阵存进内存就需要极其恐怖的显存,更何况牛顿法每一步还需要计算这个巨大矩阵的逆矩阵 H−1H^{-1}H−1 (计算复杂度为 O(n3)O(n^3)O(n3))。这在算力上是完全不现实的。 - 鞍点陷阱(Saddle Point Problem) :
前面我们在讲Hessian时提到过鞍点。在深度学习的超高维空间中,鞍点比局部极小值多得多。如果在鞍点附近,Hessian矩阵是不定矩阵(包含负特征值),此时牛顿法拟合出的局部二次曲面是一个马鞍面。按照牛顿法的更新公式,它可能会主动朝着高处(局部极大值)走去! 只有当Hessian是正定矩阵时,牛顿法才能保证下降。 - 计算二阶导数的困难 :
在复杂的计算图中,通过反向传播计算一次一阶梯度已经需要不小的开销,精确计算所有参数的二阶偏导数(甚至是近似计算)在工程上依然非常繁琐。
小结
牛顿法是优化理论中的一座丰碑。它利用Hessian矩阵提供的曲率信息,完美解决了梯度下降的盲目性问题。但在面对参数量爆炸的现代机器学习任务时,原始的牛顿法显得过于笨重。
为了兼顾"牛顿法的速度"和"梯度下降的轻便",数学家和计算机科学家们发明了一系列拟牛顿法(Quasi-Newton Methods) ,比如著名的 BFGS 和 L-BFGS 算法。
介绍L-BFGS算法(直觉理解)
为了引出 L-BFGS,我们先回到上一次的"蒙眼下山"比喻:
- 梯度下降(只用一阶导):你每走一步都只探脚下的坡度,不仅走得慢,遇到狭长的山谷还会呈"之"字形疯狂震荡。
- 牛顿法(计算真实二阶导) :你拥有一个"上帝视角的雷达",瞬间扫描出整座山的曲率(Hessian矩阵),直接算出一个抛物面,一步跨到谷底。代价是:这个雷达极其笨重,计算和存储它不仅耗尽了你的体力(算力),还塞爆了你的背包(显存)。
那么,有没有一种方法,既能拥有牛顿法的"方向感"和"大步幅",又不需要真正去计算那个极其庞大且昂贵的Hessian矩阵呢?
这就轮到 拟牛顿法(Quasi-Newton Methods) 登场了,而 L-BFGS 正是其中最耀眼的明星。
1. 名字拆解:L-BFGS 是什么?
L-BFGS 的全称非常长:Limited-memory Broyden--Fletcher--Goldfarb--Shanno。
- BFGS:是由四位数学家(Broyden, Fletcher, Goldfarb, Shanno)在1970年各自独立发表的算法。这是目前最流行、最稳定的拟牛顿法。
- L (Limited-memory):代表"有限内存"。这是后来为了解决大数据和高维问题对原始 BFGS 算法进行的极其重要的升级。
2. BFGS 的核心思想:用"历史经验"猜出曲率
既然直接计算 Hessian 矩阵的逆矩阵 H−1H^{-1}H−1 太贵了,BFGS 算法说:"我们不直接算了,我们去近似它!"
直观理解 :
假设你再次蒙眼下山,这次你没有雷达,但你带了一个笔记本。
- 你往前迈了一步。
- 你记录下你的位置变化(往东走了2米,往南走了1米)。
- 你同时记录下你脚下坡度(梯度)的变化(刚才坡度是30度,现在变成了15度)。
- 神奇的事情来了:仅仅通过比对"位置变了多少"和"坡度变了多少",你就可以推断出"地面有多弯曲"!
在数学上,BFGS 算法在每走一步后,都会利用位置差(Δx\Delta xΔx)和梯度差(Δg\Delta gΔg)来更新一个近似矩阵 。随着你走的步数越来越多,这个近似矩阵就会越来越接近真实的 H−1H^{-1}H−1。
结果:你只用了计算一阶导数(梯度)的代价,就白嫖到了二阶导数(曲率)的效果!
3. "L"的魔法:为什么需要"有限内存"?
原始的 BFGS 算法虽然不用直接求二阶导数了,但它仍然需要在内存中维护并更新那个庞大的近似矩阵 。
如果你的神经网络有 1 亿个参数,这个矩阵的大小依然是 1 亿 ×\times× 1 亿,你的内存(显存)照样会瞬间爆炸。
这时候,L-BFGS (Limited-memory BFGS) 提出了一个天才般的改进:扔掉大部分历史记录,只保留最近的记忆。
- 原始 BFGS :需要记住从下山开始的所有信息,并在内存中维持一个巨大的方阵,空间复杂度是 O(N2)O(N^2)O(N2)。
- L-BFGS :它不再存储整个庞大的矩阵,而是只存储最近 mmm 步的位置差和梯度差向量 (通常 mmm 的取值非常小,比如 5 到 20)。每次计算时,利用这 mmm 个小向量通过一套巧妙的公式来临时拼凑出下一步的方向。
- 结果 :内存消耗瞬间从极其恐怖的 O(N2)O(N^2)O(N2) 降到了非常轻量级的 O(m×N)O(m \times N)O(m×N)。
4. L-BFGS 这么神,为什么现在的深度学习不怎么用它?
如果你用过经典的机器学习库(比如 scikit-learn 中的逻辑回归、SVM,或者 SciPy 的优化器),你会发现它们的默认求解器往往都是 L-BFGS,因为它又快又准。
但在深度学习(如训练大语言模型)中,大家用的却都是 Adam 或 SGD,这是为什么呢?
这是因为 L-BFGS 有一个致命的弱点:它非常讨厌"噪音"。
- 批处理带来的噪音:在传统机器学习中,我们通常把所有数据一起塞进去算梯度(Full-batch),梯度是非常精确的。L-BFGS 可以完美地根据精确的梯度差推算出曲率。
- 深度学习的随机性:深度学习数据量太大了,我们只能每次抽一小批数据(Mini-batch)来算梯度。这就导致每次算出来的梯度都在"乱晃"。
- L-BFGS 会被带偏:如果用带有随机噪音的梯度差去推算曲率,L-BFGS 的"笔记本"里记录的就会是充满矛盾的信息。它推算出的近似 Hessian 矩阵会完全失真,导致算法走向错误的方向,甚至崩溃。
总结一下:
- 当问题是确定性的、没有噪音的(Full-batch),或者需要极高精度的物理模拟时:L-BFGS 是王者,收敛速度远超 Adam。
- 当问题是随机的、充满噪音的(Mini-batch 深度学习)时:Adam 和一阶优化器依然是不可替代的首选。
介绍L-BFGS算法(具体步骤)
深入了解 L-BFGS 的具体步骤,就意味着我们要揭开它最核心的"魔法"------如何在不存储矩阵的情况下,只用几个向量的加减乘除,就能"凭空"捏造出牛顿法的搜索方向。
整个 L-BFGS 算法其实就是一个精妙的循环。为了讲清楚,我们先定义两个极其重要的"记忆向量"(也就是上一节提到的"笔记本"里记录的内容):
- 位置差 sks_ksk :这一步走完后,位置发生了多少变化。sk=xk+1−xks_k = x_{k+1} - x_ksk=xk+1−xk
- 梯度差 yky_kyk :这一步走完后,坡度(一阶导数)发生了多少变化。yk=∇f(xk+1)−∇f(xk)y_k = \nabla f(x_{k+1}) - \nabla f(x_k)yk=∇f(xk+1)−∇f(xk)
L-BFGS 会在内存中保存最近 mmm 步的 (si,yi)(s_i, y_i)(si,yi) 组合(通常 mmm 选 5 到 20 之间)。
下面是 L-BFGS 算法的标准执行步骤:
第 0 步:初始化 (Initialization)
在开始爬山之前,我们需要准备好行囊:
- 选择一个初始起点 x0x_0x0。
- 设定内存大小 mmm(保存最近几步的记忆)。
- 计算初始点的梯度 ∇f(x0)\nabla f(x_0)∇f(x0)。
- 设定一个收敛阈值 ϵ\epsilonϵ(只要梯度足够小,我们就认为到底部了,可以停止)。
第 1 步:计算搜索方向(核心:双循环递归 Two-Loop Recursion)
这是 L-BFGS 最具天才创意的部分。假设我们现在处于第 kkk 步,我们需要计算出一个方向 pkp_kpk,这个方向近似于牛顿法的 −Hk−1∇f(xk)-H_k^{-1} \nabla f(x_k)−Hk−1∇f(xk)。
L-BFGS 不会去构建 Hk−1H_k^{-1}Hk−1,而是拿当前的梯度 q=∇f(xk)q = \nabla f(x_k)q=∇f(xk),扔进一个名为**"双循环递归"**的加工厂里。这个加工厂利用最近 mmm 步的 (si,yi)(s_i, y_i)(si,yi) 记录对 qqq 进行反复打磨:
【双循环递归算法】
1. 初始化: 令 q=∇f(xk)q = \nabla f(x_k)q=∇f(xk)
2. 第一次循环(向后回溯,打磨当前梯度):
对于 i=k−1,k−2,...,k−mi = k-1, k-2, \dots, k-mi=k−1,k−2,...,k−m(从最新的记忆往前倒推):
- 计算一个标量 αi=ρisiTq\alpha_i = \rho_i s_i^T qαi=ρisiTq (其中 ρi=1yiTsi\rho_i = \frac{1}{y_i^T s_i}ρi=yiTsi1 是一个固定的缩放系数)
- 更新 q=q−αiyiq = q - \alpha_i y_iq=q−αiyi
3. 初始中心点猜测:
- 计算 r=Hk0qr = H_k^0 qr=Hk0q (这里 Hk0H_k^0Hk0 通常是一个非常简单的对角矩阵,比如 III 乘以一个常数,相当于给个基础学习率)
4. 第二次循环(向前恢复,生成最终方向):
对于 i=k−m,k−m+1,...,k−1i = k-m, k-m+1, \dots, k-1i=k−m,k−m+1,...,k−1(从最老的记忆顺推回来):
- 计算一个标量 β=ρiyiTr\beta = \rho_i y_i^T rβ=ρiyiTr
- 更新 r=r+si(αi−β)r = r + s_i (\alpha_i - \beta)r=r+si(αi−β)
5. 输出: 最终的搜索方向 pk=−rp_k = -rpk=−r
直观理解 :这堆公式看着吓人,但它的本质就是------拿着当前的梯度,去和过去 mmm 步的经验做对比,把那些"走过弯路"的方向给抵消掉,最后吐出一个直指谷底的"黄金方向"。而且,这里面全都是向量的点乘运算,极其迅速,完全没有矩阵求逆!
第 2 步:线搜索确定步长 (Line Search)
方向 pkp_kpk 找好了,现在要决定在这个方向上走多远(步长 αk\alpha_kαk)。
牛顿法通常直接走 1 步,但在实际情况中为了保证稳定下降,L-BFGS 会进行一次"线搜索"。它通常需要满足 Wolfe 条件(Wolfe Conditions):
- 充分下降:这一步迈出去,函数值必须有实质性的减少(不能原地踏步)。
- 曲率条件:迈出这一步后,那个地方的坡度必须比现在平缓(不能跨过谷底走到对面的陡坡上)。
通过线搜索,我们找到了一个完美的步长 αk\alpha_kαk。
第 3 步:更新位置和梯度 (Update Variables)
既然方向和步长都确定了,我们直接走到新位置:
xk+1=xk+αkpkx_{k+1} = x_k + \alpha_k p_kxk+1=xk+αkpk
到达新位置后,马上环顾四周,计算新的梯度 ∇f(xk+1)\nabla f(x_{k+1})∇f(xk+1)。
第 4 步:更新记忆 (Update Memory) ------ "L"的体现
这是维持"有限内存"的关键一步:
- 计算刚刚这一步的经验:
- sk=xk+1−xks_k = x_{k+1} - x_ksk=xk+1−xk
- yk=∇f(xk+1)−∇f(xk)y_k = \nabla f(x_{k+1}) - \nabla f(x_k)yk=∇f(xk+1)−∇f(xk)
- 存入笔记本 :把这对新的 (sk,yk)(s_k, y_k)(sk,yk) 存进内存。
- 遗忘旧知识 :如果笔记本里的记录超过了 mmm 条,就无情地把最老的一条记录(sk−m,yk−ms_{k-m}, y_{k-m}sk−m,yk−m)扔掉。
这样,算法永远只带着最精简、最新的 mmm 条经验轻装上阵。
第 5 步:检查收敛 (Check Convergence)
判断是否到达了终点。通常我们检查当前的梯度大小:
如果 ∣∣∇f(xk+1)∣∣<ϵ||\nabla f(x_{k+1})|| < \epsilon∣∣∇f(xk+1)∣∣<ϵ,说明脚下已经非常平坦,成功找到了极小值,算法结束!
如果还没到,就令 k=k+1k = k + 1k=k+1,带着更新后的记忆,回到 第 1 步 继续循环。
小结
L-BFGS 巧妙地将昂贵的 n×nn \times nn×n 矩阵运算,降维打击变成了 mmm 个长度为 nnn 的向量点乘。它用极低的内存代价(O(mn)O(mn)O(mn))和计算代价,极其逼近了牛顿法的二阶收敛速度。
L-BFGS代码实现和可视化
为了让 L-BFGS 的威力展现得淋漓尽致,我们在代码中引入一个在优化领域鼎鼎大名的"终极测试"------Rosenbrock 函数(罗森布罗克函数),它也被戏称为"香蕉谷"。它的公式是:f(x,y)=(1−x)2+100(y−x2)2f(x, y) = (1 - x)^2 + 100(y - x^2)^2f(x,y)=(1−x)2+100(y−x2)2为什么选它?这个函数的全局最小值隐藏在一个极其狭长、平缓且弯曲的抛物线形山谷中(最低点在 (1,1)(1, 1)(1,1) 处)。普通的梯度下降法一掉进这个山谷就会开始疯狂震荡,寸步难行;而 L-BFGS 凭借对曲率的敏锐感知,能够顺着弯曲的山谷迅速滑向谷底。下面是使用 SciPy 库和 Matplotlib 的完整 Python 代码。这段代码不仅会调用 L-BFGS 寻找极值,还会把寻找的过程(每一步的落脚点)记录下来并画在等高线图上。Python 代码演示你需要安装 scipy, numpy 和 matplotlib(可以通过 pip install scipy numpy matplotlib 安装)。
python
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import minimize
# 1. 定义目标函数:Rosenbrock 函数
def rosenbrock(X):
x, y = X
return (1 - x)**2 + 100 * (y - x**2)**2
# 2. 定义目标函数的一阶导数(梯度)
# 虽然 SciPy 可以自动用有限差分近似求导,但提供精确的梯度会让 L-BFGS 更快更准
def rosenbrock_gradient(X):
x, y = X
df_dx = -2 * (1 - x) - 400 * x * (y - x**2)
df_dy = 200 * (y - x**2)
return np.array([df_dx, df_dy])
# 3. 记录优化路径的回调函数
path = []
def callback_func(X):
path.append(np.copy(X)) # 把每一步的坐标存下来
# === 开始优化 ===
# 设定一个糟糕的初始起点 (左上角的高地上)
start_point = np.array([-1.5, 2.0])
path.append(start_point) # 记录起点
print("开始使用 L-BFGS 优化...")
# 调用 SciPy 的 minimize 函数,核心就在这里!
result = minimize(
fun=rosenbrock, # 目标函数
x0=start_point, # 初始猜测点
method='L-BFGS-B', # 指定使用 L-BFGS 算法 (B代表支持边界约束,这里没用上)
jac=rosenbrock_gradient, # 提供梯度函数
callback=callback_func, # 每次迭代调用的函数,用于记录轨迹
options={'disp': True} # 打印详细的收敛信息
)
print("\n优化结果:")
print(f"找到的极小值点: (x={result.x[0]:.4f}, y={result.x[1]:.4f})")
print(f"真实极小值点: (x=1.0000, y=1.0000)")
print(f"总迭代次数: {result.nit}")
# === 可视化部分 ===
# 将路径转换为 NumPy 数组方便绘图
path = np.array(path)
# 生成背景的等高线数据
x_grid = np.linspace(-2, 2, 400)
y_grid = np.linspace(-1, 3, 400)
X_mesh, Y_mesh = np.meshgrid(x_grid, y_grid)
Z_mesh = rosenbrock([X_mesh, Y_mesh])
# 绘制等高线图 (使用对数刻度让狭长的山谷更清晰)
plt.figure(figsize=(10, 8))
contours = plt.contour(X_mesh, Y_mesh, Z_mesh, levels=np.logspace(-1, 3, 20), cmap='viridis', alpha=0.8)
plt.colorbar(contours, label='Function Value')
# 绘制 L-BFGS 的优化路径
plt.plot(path[:, 0], path[:, 1], 'r.-', markersize=8, linewidth=2, label='L-BFGS Path')
# 标出起点和终点
plt.plot(start_point[0], start_point[1], 'go', markersize=10, label='Start (-1.5, 2.0)')
plt.plot(1, 1, 'b*', markersize=15, label='Global Minimum (1, 1)')
plt.title('L-BFGS Optimization on Rosenbrock Function')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.6)
plt.show()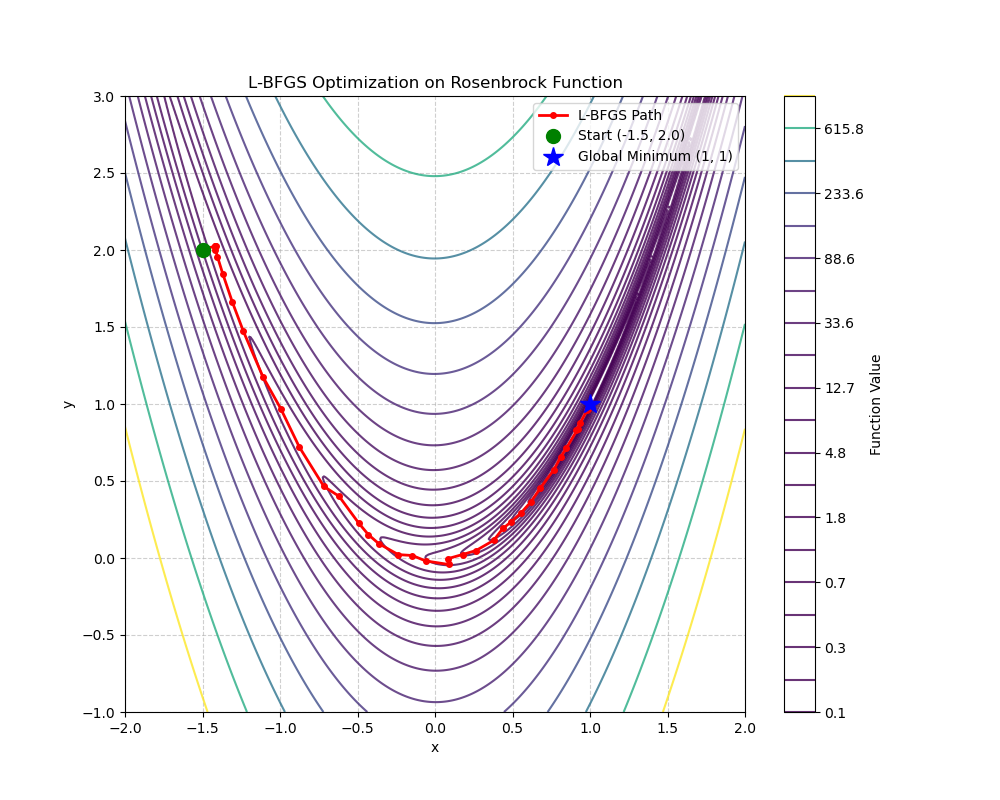
python
开始使用 L-BFGS 优化...
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 2 M = 10
At X0 0 variables are exactly at the bounds
At iterate 0 f= 1.25000D+01 |proj g|= 1.55000D+02
At iterate 1 f= 5.89847D+00 |proj g|= 9.86515D+00
At iterate 2 f= 5.86362D+00 |proj g|= 1.78382D+00
At iterate 3 f= 5.86186D+00 |proj g|= 1.44240D+00
At iterate 4 f= 5.85489D+00 |proj g|= 3.17135D+00
At iterate 5 f= 5.83891D+00 |proj g|= 6.58444D+00
At iterate 6 f= 5.79587D+00 |proj g|= 1.23570D+01
At iterate 7 f= 5.70129D+00 |proj g|= 2.07748D+01
At iterate 8 f= 5.55086D+00 |proj g|= 2.95576D+01
At iterate 9 f= 5.32018D+00 |proj g|= 3.24708D+01
At iterate 10 f= 4.75992D+00 |proj g|= 2.89520D+01
At iterate 11 f= 4.02195D+00 |proj g|= 1.21247D+01
At iterate 12 f= 3.72444D+00 |proj g|= 1.97929D+01
At iterate 13 f= 3.19499D+00 |proj g|= 1.76297D+01
At iterate 14 f= 2.65193D+00 |proj g|= 3.51349D+00
At iterate 15 f= 2.25144D+00 |proj g|= 6.05810D+00
At iterate 16 f= 2.15447D+00 |proj g|= 8.54380D+00
At iterate 17 f= 2.00669D+00 |proj g|= 8.30600D+00
At iterate 18 f= 1.64712D+00 |proj g|= 6.83973D+00
At iterate 19 f= 1.31481D+00 |proj g|= 2.58215D+00
At iterate 20 f= 1.17634D+00 |proj g|= 4.51080D+00
At iterate 21 f= 1.07934D+00 |proj g|= 9.93900D+00
At iterate 22 f= 8.55930D-01 |proj g|= 2.26641D+00
At iterate 23 f= 6.84287D-01 |proj g|= 1.80151D+00
At iterate 24 f= 5.86949D-01 |proj g|= 4.32485D+00
At iterate 25 f= 4.68975D-01 |proj g|= 5.73172D+00
At iterate 26 f= 3.15731D-01 |proj g|= 1.10398D+00
At iterate 27 f= 2.63077D-01 |proj g|= 1.33829D+00
At iterate 28 f= 2.20548D-01 |proj g|= 3.09025D+00
At iterate 29 f= 1.78855D-01 |proj g|= 3.82270D+00
At iterate 30 f= 1.08361D-01 |proj g|= 1.50055D+00
At iterate 31 f= 7.67107D-02 |proj g|= 4.11466D+00
At iterate 32 f= 3.54269D-02 |proj g|= 1.69793D-01
At iterate 33 f= 2.50385D-02 |proj g|= 1.11649D+00
At iterate 34 f= 1.79226D-02 |proj g|= 3.87835D+00
At iterate 35 f= 8.31587D-03 |proj g|= 5.46021D-01
At iterate 36 f= 4.04114D-03 |proj g|= 1.68384D-01
At iterate 37 f= 1.45471D-03 |proj g|= 1.34405D+00
At iterate 38 f= 3.47991D-04 |proj g|= 1.10594D-01
At iterate 39 f= 5.12798D-05 |proj g|= 3.33836D-02
At iterate 40 f= 1.60484D-06 |proj g|= 4.62836D-02
At iterate 41 f= 8.45175D-09 |proj g|= 1.37211D-03
At iterate 42 f= 5.40462D-12 |proj g|= 5.53120D-05
At iterate 43 f= 6.36931D-18 |proj g|= 1.55295D-08
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
2 43 53 1 0 0 1.553D-08 6.369D-18
F = 6.3693110799880195E-018
CONVERGENCE: NORM_OF_PROJECTED_GRADIENT_<=_PGTOL
优化结果:
找到的极小值点: (x=1.0000, y=1.0000)
真实极小值点: (x=1.0000, y=1.0000)
总迭代次数: 43