开篇介绍:
hello 大家,我们长话短说,在前面几篇博客里,我们完成了对vim的了解,以及make、Makefile自动化编译的掌握,那么对于我们Linux基础开发工具的介绍,便是剩下git版本控制器和cgdb调试器了,那么这两个也是较为重要的东西,cgdb就如它的名字,是用来调试的,调试的用处,我们都知道,不言而喻,而git版本控制器,就更是我们不可或缺的工具,github,gitee等等,都是git的延伸,是我们一定要掌握的,所以,在本篇博客中,我就将对这两个工具进行解析。
git:
在讲解如何使用git之前,我们先来了解了解git这个工具:
git的介绍:
Git 是目前全球最主流的分布式版本控制系统,专为高效管理各类文件(尤其是软件开发中的源代码)的版本迭代和多人协作而设计。以下从核心概念、工作原理、核心优势、基本操作及协同逻辑等方面详细介绍:
一、核心解决的问题
在没有版本控制器时,人们通过复制文件(如 "报告 - v1""代码 - final")管理版本,但存在三大痛点:
- 版本混乱:版本过多时,无法清晰记录每个版本的修改内容("v3 比 v2 改了哪里?");
- 恢复困难:误操作后,难以精准回滚到之前的正确版本;
- 协作低效:多人同时修改同一文件时,容易覆盖他人内容,冲突难以解决。
Git 通过一套标准化的机制,彻底解决了这些问题:它能记录文件的每一次修改(包括修改人、时间、内容),支持随时回滚到任意历史版本,并高效处理多人并行开发的冲突。
二、核心概念与工作流程
Git 的核心是 "追踪文件变化",其工作流程围绕四个关键区域展开,理解这些区域是掌握 Git 的基础:
| 区域 | 定义 | 作用 |
|---|---|---|
| 工作区(Working Directory) | 你正在编辑的文件所在的目录(即电脑中能看到的文件夹) | 临时存放当前正在修改的文件,修改未被 Git 正式跟踪 |
| 暂存区(Staging Area) | 位于 .git 目录内的临时存储区(也叫 "索引") |
暂存已修改的文件,相当于 "待提交清单",可批量确认要保存的修改 |
| 本地仓库(Local Repository) | 位于 .git 目录内的数据库,存储所有版本历史和元数据 |
永久保存已提交的版本,是 Git 本地数据的核心,包含完整的历史记录 |
| 远程仓库(Remote Repository) | 托管在服务器上的仓库(如 GitHub、GitLab) | 用于多人协作时同步代码,是本地仓库的 "共享备份中心" |
基本工作流程(单个文件从修改到存档的过程):
- 在工作区修改文件(如编辑
main.py); - 通过
git add将修改从工作区添加到暂存区(确认 "要保存这些修改"); - 通过
git commit将暂存区的修改提交到本地仓库(生成一个新的版本,记录修改内容); - (多人协作时)通过
git push将本地仓库的版本推送到远程仓库,供他人获取; - (获取他人修改时)通过
git pull从远程仓库拉取最新版本到本地。
三、Git 的核心优势(为何成为主流?)
Git 能取代传统版本控制工具(如 SVN),核心源于其分布式设计 和高效性能,具体优势包括:
-
完全分布式每个开发者的本地都有完整的仓库(包含所有历史版本),不依赖中心服务器。即使远程服务器故障,本地仍能正常提交、查看历史,恢复后可通过本地仓库同步数据,极大提高了可靠性。
-
速度极快多数操作(如提交、查看历史、创建分支)都在本地完成,无需网络交互,速度远超依赖中心服务器的集中式工具(如 SVN)。同时,Git 对数据采用高效压缩算法,存储占用小。
-
强大的非线性开发支持支持 "分支(Branch)" 功能,可轻松创建多个并行开发线(如 "开发分支""修复分支""发布分支"),不同功能 /bug 修复可在独立分支开发,完成后再合并到主分支,避免相互干扰。例如:
- 用
git branch feature/login创建 "登录功能" 分支; - 在该分支独立开发,不影响主分支;
- 完成后用
git merge合并到主分支。
- 用
-
数据完整性 Git 对所有文件和版本都通过 SHA-1 哈希算法生成唯一校验值,任何修改(包括误操作)都会改变校验值,确保历史记录无法被篡改,且能快速检测数据损坏。
-
支持超大规模项目从设计之初就以管理 Linux 内核(超千万行代码、数万贡献者)为目标,能高效处理海量代码和频繁的版本迭代。
四、Git 简史:从 "危机" 到 "标杆"
Git 的诞生与 Linux 内核开发密切相关:
- 2002 年前,Linux 内核开发依赖人工管理补丁,效率低下;
- 2002-2005 年,使用商业分布式版本控制工具 BitKeeper,解决了部分问题;
- 2005 年,BitKeeper 收回免费授权,Linux 创始人 Linus Torvalds 基于 BitKeeper 的经验,用 10 天开发出 Git 原型,核心目标是:速度快、分布式、支持大规模协作。
- 此后,Git 逐步成熟,成为全球开发者的首选版本控制工具,支撑了 GitHub(全球最大代码托管平台)等生态的崛起。
git的使用:
OK大家,了解了git之后,我们知道,git是个非常好使,非常重要的工具,所以,我在这里就讲解一下git的使用方法,还有就是说明一下,我在本篇博客讲的git使用只是我们比较常用的,对于git还有更加详细的使用,这个我们会放在后面讲,在这里我们先会用就行,进一步了解等以后我们有空了再谈。
创建仓库:
OK大家,这个其实是个很简单的操作,其实在网上大家随便一搜,就有很多的操作,但是在这里,我觉得还是得有一定的讲解,那么我就实操的带大家创建一个仓库,那么大家要注意,对于仓库,我们一般是选择在gitee或者github里面创建,但是呢,由于某种因素,所以我们一般是选择gitee来进行,接下来我就以gitee为例,去创建一个存放我们Linux内容的仓库:
首先我们要打开gitee:工作台 - Gitee.com,没有注册过的会提醒大家注册,注册的流程再简单不过了,我这里就不多余赘述,我们直接进入创建仓库,
鼠标放在加号处,会自动弹出下面一堆选项,我们选择新建仓库: 可以看到就进入了这个界面,然后我们就可以填写信息:
可以看到就进入了这个界面,然后我们就可以填写信息:
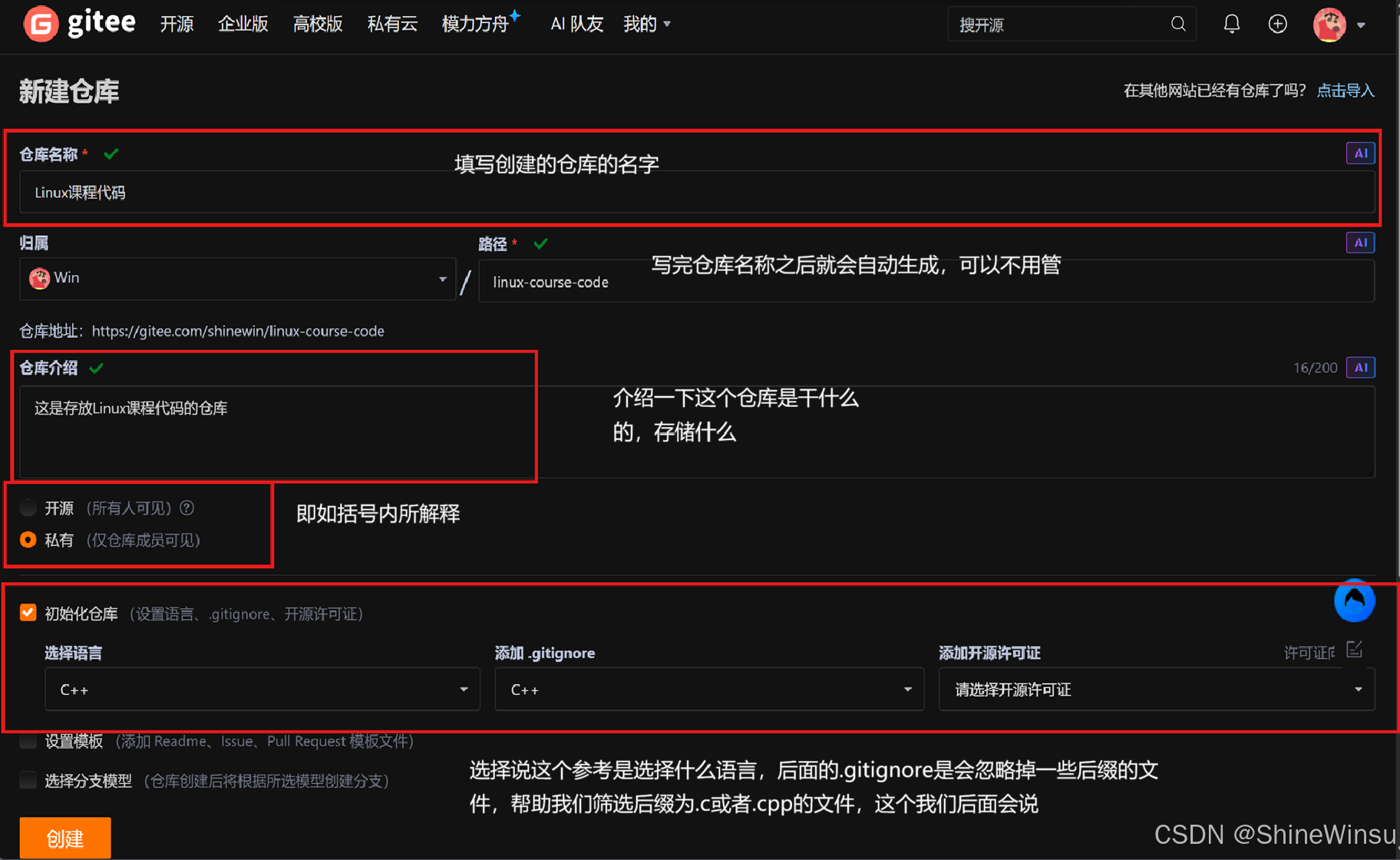

大家按照我里面写的就知道了,但是在这里提一嘴对于gitnore这一个,大家可以不要,我们后面会给大家提供一个好用的,很简单,最后我们点击创建就行了:
这样子就代表创建成功了。
将gitee仓库克隆到本地:
OK大家,那么其实我们在gitee或者github创建的仓库都只能算是远程仓库,而我们知道,对于git,我们还需要一个本地仓库,然后使用git三板斧去将我们的文件先存到本地仓库,然后存到远程仓库,也就是gitee或者giehub里面,所以,接下来我们要做的就是将gitee仓库克隆到本地,其实操作也很简单。
首先,我们要在Linux系统里面安装git,这个就很简单了,
bash
sudo apt install -y git 这就代表创建成功了,很简单吧各位。
这就代表创建成功了,很简单吧各位。
然后我们就要克隆一下我们刚才在gitee创建的仓库了,这个需要仓库的地址, 即红框内的,然后我们选择HTTPS,按照里面的操作即可。
即红框内的,然后我们选择HTTPS,按照里面的操作即可。
而后,我们就要在Linux里面输入
bash
git clone 仓库链接的指令,但是大家要注意,我们最好是把这个仓库创建在家目录里,这样子以后也方便寻找,
| 知识点 | 说明 |
|---|---|
git clone 作用 |
复制远程仓库的完整历史记录、文件结构到本地,生成与远程仓库关联的本地仓库,支持后续的拉取(git pull)、推送(git push)操作。 |
| 仓库地址类型 | Gitee 仓库地址分HTTPS(图中形式,无需密钥,适合快速克隆)和SSH(需配置 SSH 密钥,克隆命令为git clone git@gitee.com:xxx/xxx.git,更安全且推送无需重复输密码)两种形式。 |
| 存储路径建议 | 推荐将仓库放在家目录(如~下),便于后续查找和管理,是高效的本地仓库组织方式。 |
然后就是在我们git clone 仓库链接之后,终端会要求我们输入该仓库所有人的username和password,那么大家要注意,username可不是自己gitee的昵称,
如何查看自己的 username
- 网页端操作 :
- 登录 Gitee 后,点击右上角头像 → 选择 "个人设置";
- 在 "账号设置" 页面中,"用户名" 一栏即为你的 Gitee username。
- URL 提取 :访问自己的个人主页,地址栏中
gitee.com/后的字符串就是 username(例如https://gitee.com/zhangsan中的zhangsan)。
大家可以查看自己的username,然后正常操作就行,我们可以在放置仓库的目录里ll一下:
 即成功。
即成功。
我们看到,里面的内容和我们刚才创建的仓库内容一模一样。
然后我要说明一下,.git 是 Git 版本控制系统的核心目录,隐藏在每个 Git 仓库的根目录下,是 Git 实现版本管理的 "数据中枢"。核心作用说明:
- 存储版本历史:记录仓库中所有文件的每一次修改、提交记录(包括提交人、时间、内容差异),支持随时回滚到任意历史版本。
- 管理分支与标签 :存储所有分支(如
master、dev)和标签(如版本标记v1.0)的指针,实现并行开发与版本标记。 - 维护仓库配置:包含本地仓库的配置信息(如远程仓库地址、用户信息),以及 Git 的行为规则(如忽略文件、合并策略)。
- 支持分布式协作 :记录与远程仓库(如 Gitee、GitHub)的同步状态,实现
git push(推送本地修改)、git pull(拉取远程更新)等协作操作。
那么我们传入仓库的文件其实是在linux-course-code里面的,这个我们也需要知道。
OK,接下来我们就可以开始我们的git三板斧了。
.gitignore文件:
那么大家,我上面说了,我会给大家提供一个.gitignore文件,那么我们先来了解了解它有什么用:
.gitignore 文件是 Git 版本控制系统中用于 ** 指定 "不需要被跟踪的文件 / 目录"** 的配置文件,核心作用是过滤掉那些无需纳入版本管理的内容,以下从功能、价值场景、使用优势三个维度详细说明:
一、核心功能:定义 "忽略规则"
它通过明文规则告诉 Git:这些文件或目录不需要被 git add、git commit 等操作跟踪,常见需忽略的内容包括:
- 编译 / 构建产物 :如 C++ 的
.o目标文件、Java 的.class文件、前端的dist/打包目录。 - 依赖包目录 :如 Python 的
venv/、Node.js 的node_modules/、Java 的target/(这些目录通常体积大且可通过包管理工具重建,无需版本控制)。 - 临时 / 日志文件 :如
.log日志、*.tmp临时文件、系统生成的缓存(如 macOS 的.DS_Store)。 - 本地配置文件 :如 IDE 专属配置(VS Code 的
.vscode/、IntelliJ 的.idea/)、个人开发环境的配置文件(如.env.local)。
二、价值场景:解决版本管理的 "冗余与冲突"
- 减少仓库体积,提升协作效率
- 若不忽略
node_modules/(前端依赖目录,通常数百 MB 甚至 GB),每次提交都会将其纳入仓库,导致仓库体积急剧膨胀,拉取 / 推送速度变慢。 - 通过
.gitignore忽略后,仓库仅跟踪源代码,体积小且同步高效。
- 避免 "无意义的冲突"
- 不同开发者的 IDE 配置(如代码格式化规则、插件设置)若被提交,会因差异产生冲突,且这类冲突对代码逻辑无意义。
- 用
.gitignore忽略 IDE 配置目录后,每个开发者可保留本地个性化配置,互不干扰。
- 保持提交记录 "整洁且聚焦"
- 若不忽略临时文件、日志,提交记录会被大量 "无关修改" 淹没,难以定位真正的功能变更。
- 过滤后,提交记录仅包含源代码的逻辑变更,便于代码 review 和版本回溯。
三、使用优势:规则灵活,层级可控
- 规则语法简洁 :支持通配符(
*匹配任意字符、?匹配单个字符、**匹配多级目录)、注释(#开头)、例外(!开头,如!important.txt表示 "其他规则忽略时,该文件仍需跟踪")。 - 作用范围可控 :
- 仓库根目录的
.gitignore对整个项目生效; - 子目录的
.gitignore仅对当前子目录生效; - 全局
.gitignore(通过git config --global core.excludesfile配置)对当前用户的所有 Git 仓库生效。
- 仓库根目录的
总结
.gitignore 是 Git 版本管理的 "过滤器",它让开发者可以精准控制 "哪些内容需要版本跟踪,哪些内容属于本地冗余",从而优化仓库体积、避免无意义冲突、保持提交记录的聚焦性,是团队协作和个人项目管理中不可或缺的配置文件。
所以,我们是要把.gitignore文件放在我们的仓库目录里的,下面是我个人经常使用的:
bash
# Build and Release Folders
bin-debug/
bin-release/
[Oo]bj/
[Bb]in/
# Other files and folders
.settings/
# Executables
*.swf
*.air
*.ipa
*.apk
#过滤掉不想要文件和文件夹
*.exe
*.sln
*.vcxproj
*.filters
*.user
*.suo
*.db
*.ipch
Debug/
.vs
Release/
# Project files, i.e. `.project`, `.actionScriptProperties` and `.flexProperties`
# should NOT be excluded as they contain compiler settings and other important
# information for Eclipse / Flash Builder.大家把自己仓库里的.gitignore文件改为这个内容即可。
git add:
git add 是 Git 版本控制系统中连接 "工作区" 与 "暂存区"的核心命令,用于将文件的修改从 "工作区"(正在编辑的文件目录)添加到 "暂存区"(待提交的临时存储区),为后续的版本提交(git commit)做准备。以下从作用逻辑、使用场景、进阶操作三个维度详细说明:
一、核心作用与 Git 区域关系
Git 管理文件的三个核心区域:
- 工作区:你在电脑中直接编辑的文件目录(可见的文件夹)。
- 暂存区 :位于
.git目录内的 "待提交清单"(也叫 "索引"),临时存储已确认要提交的修改。 - 本地仓库 :位于
.git目录内的数据库,永久保存已提交的版本历史。
git add 的作用是将工作区的修改 "选中" 并放入暂存区,相当于告诉 Git:"这些修改是我要保存到版本历史的候选内容"。
二、基础用法与场景
- 添加单个文件
作用:将指定文件的修改从工作区添加到暂存区。
git add 文件名.txt # 例如:git add README.md- 添加多个文件
作用:同时将多个文件的修改添加到暂存区。
git add 文件1.txt 文件2.py # 例如:git add main.c utils.h3. 添加整个目录
作用:递归添加指定目录下所有文件的修改(包括子目录)。
git add 目录名/ # 例如:git add src/4. 添加所有修改(常用快捷操作)
作用:添加当前目录下所有新文件、已修改文件(但不包括已删除的文件)。
git add . # 注意:"."表示当前目录- 撤销暂存区的文件(添加后反悔)
若不小心将错误文件加入暂存区,可通过以下命令将其从暂存区撤回到工作区:
git reset HEAD 文件名.txt四、与 git status 配合确认状态
执行 git add 前后,可通过 git status 查看文件状态变化:
- 添加前 :
git status会显示文件处于 "Untracked(未跟踪)" 或 "Modified(已修改)" 状态; - 添加后:文件会进入 "Changes to be committed(待提交)" 状态,说明已成功加入暂存区。
五、核心意义:灵活控制提交范围
暂存区的设计让开发者可以精细控制 "哪些修改要提交"。例如:
- 同一文件的不同修改可分多次
git add+git commit(如 "修复登录 bug" 和 "优化注册逻辑" 可拆分为两个提交); - 临时屏蔽某部分修改(先不
git add,后续再处理)。
总结来说,git add 是 Git 版本管理的 "筛选器"------ 它让你在 "提交所有修改" 和 "完全不提交" 之间,拥有灵活选择提交范围的能力,是实现 "精细化版本控制" 的关键步骤。
git init
所以,我们就要先git add一下,然后我们要注意,如果我们要在你存放这个文件的目录里面进行git add的话,那么由于git add等一系列操作要依靠.git这个目录来完成的,所以如果本目录下没有.git的话,其实是不行的
那么这要怎么处理呢,一种方法是我们去家目录的仓库里,然后通过相对路径或者绝对路径去找到我们要add的文件,
除此之外,我们还可以使用git init指令:
git init 是 Git 中用于初始化新 Git 仓库 的核心命令,其作用是在指定目录下创建 .git 目录(Git 仓库的核心数据目录),使该目录具备 Git 版本管理能力。以下从作用逻辑、使用场景、底层原理三个维度详细说明:
一、为什么需要 git init?
Git 的所有版本管理操作(git add、git commit、git push 等)都依赖于 **.git 目录 **(存储版本历史、分支信息、配置等核心数据)。如果目录中没有 .git,Git 会认为这不是一个仓库,从而导致操作失败(如 fatal: not a git repository 错误)。
git init 的核心价值就是在当前目录生成 .git 目录,让普通目录升级为 Git 仓库,从而支持后续的版本管理操作。
二、使用方法与效果
-
操作步骤 :在需要作为仓库的目录下,执行命令:
git init -
执行效果 :当前目录会生成一个隐藏的
.git子目录,包含 Git 仓库的所有元数据(如对象数据库、分支指针、配置文件等)。此时,当前目录及其子目录的文件可被 Git 跟踪。
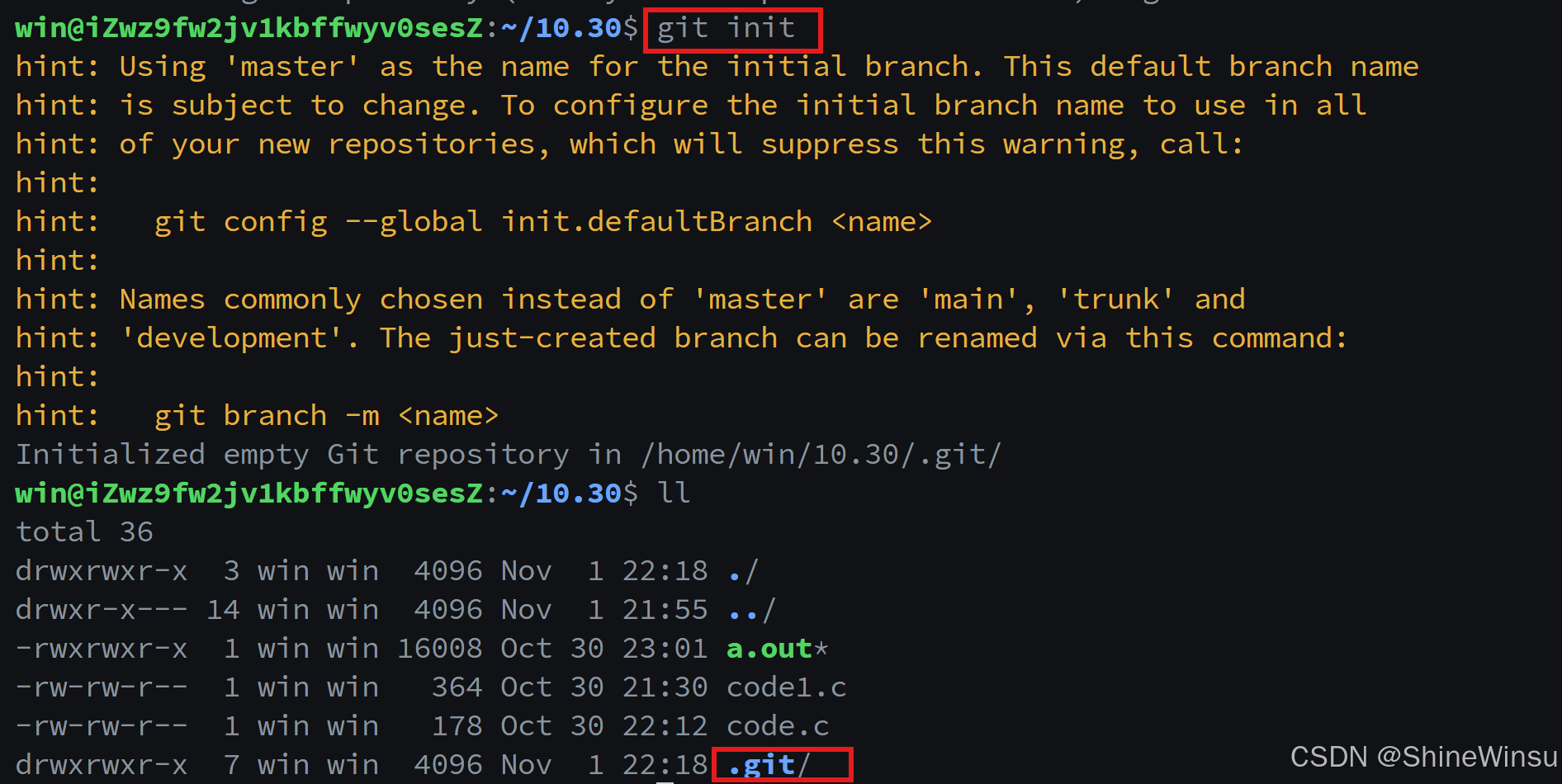
可以看到,这样子我们存文件的目录下就有.git目录了,也就代表我们可以在本目录下直接执行git add等指令了。
 因为有了.gitignore文件,所以我们可以直接使用git add .指令,此时运行完之后,本目录下的该存放在仓库里的文件就已经放在暂存区内了
因为有了.gitignore文件,所以我们可以直接使用git add .指令,此时运行完之后,本目录下的该存放在仓库里的文件就已经放在暂存区内了
git commit:
git commit 是 Git 中将暂存区的修改永久保存到本地仓库 的核心命令,每个提交会生成一个唯一的版本记录(包含修改内容、作者、时间等元数据)。以下从核心作用、使用方法、提交规范、底层原理等维度详细介绍:
一、核心作用
- 固化版本记录:将暂存区(
git add后的待提交内容)的修改永久存储到本地仓库,生成一个不可篡改的版本快照。 - 支持版本回溯 :每个提交对应一个唯一的 SHA-1 哈希值,可通过
git log查看历史提交,并通过git reset回滚到任意历史版本。 - 构建版本历史链:提交之间通过 "父提交指针" 关联,形成清晰的版本演进脉络(如功能迭代、bug 修复的时间线)。
二、基本用法
1. 基础提交(必选提交信息)
git commit -m "提交说明"-m:指定提交信息(必须填写),用于描述本次提交的修改内容(如 "修复登录功能的输入校验 bug""添加用户注册模块的接口")。
-
交互式提交(自动打开编辑器写提交信息)
git commit
- 执行后会自动打开系统默认的文本编辑器(如
vim),需在编辑器中输入提交信息后保存退出,完成提交。
-
追加提交(修改最近一次提交)
git commit --amend -m "新的提交信息"
- 作用:修改最近一次提交(如提交后发现漏加文件、提交信息描述不准确时使用)。
- 操作流程:先
git add 遗漏的文件,再执行git commit --amend,可修改提交信息或补充文件。
-
跳过暂存区(直接提交已跟踪文件的修改)
git commit -a -m "提交说明"
-a:自动将所有已跟踪文件的修改 (未被git add的也包含)添加到暂存区并提交(但不包含新创建的未跟踪文件)。
三、提交规范(高效协作的关键)
良好的提交信息应简洁、明确、可追溯,建议遵循以下规范:
- 格式:
动词 + 范围 + 内容(如修复(登录模块): 处理空用户名的异常)。 - 动词示例:
修复(修复 bug)、添加(新增功能)、优化(性能 / 逻辑优化)、删除(移除冗余代码)等。 - 范围示例:模块名(如
登录模块)、文件名(如userService.js)、功能点(如支付流程)等。
四、底层原理(提交对象的构成)
每次 git commit 会创建一个提交对象(commit object),包含以下核心信息:
- 暂存区快照指针:指向本次提交时暂存区的文件快照(即修改后的文件内容)。
- 作者 / 提交者信息 :本地 Git 配置的
user.name和user.email(可通过git config user.name查看 / 修改)。 - 提交时间:提交执行时的系统时间。
- 父提交指针:指向上一次提交的哈希值(首次提交无父指针)。
这些提交对象通过 "父指针" 形成版本历史链 ,可通过 git log 查看完整的链条结构。
五、注意事项
- 仅提交暂存区内容 :
git commit只提交暂存区 的修改,若工作区有修改但未git add,则不会被包含在此次提交中。 - 提交不可轻易回滚(除非必要) :已推送(
git push)到远程仓库的提交,回滚后需强制推送(git push -f),可能影响协作,因此提交前需仔细确认内容。
所以我们就可以使用git commit -m了:
 这就就代表存放到本地仓库了,我们可以去看一下:
这就就代表存放到本地仓库了,我们可以去看一下:
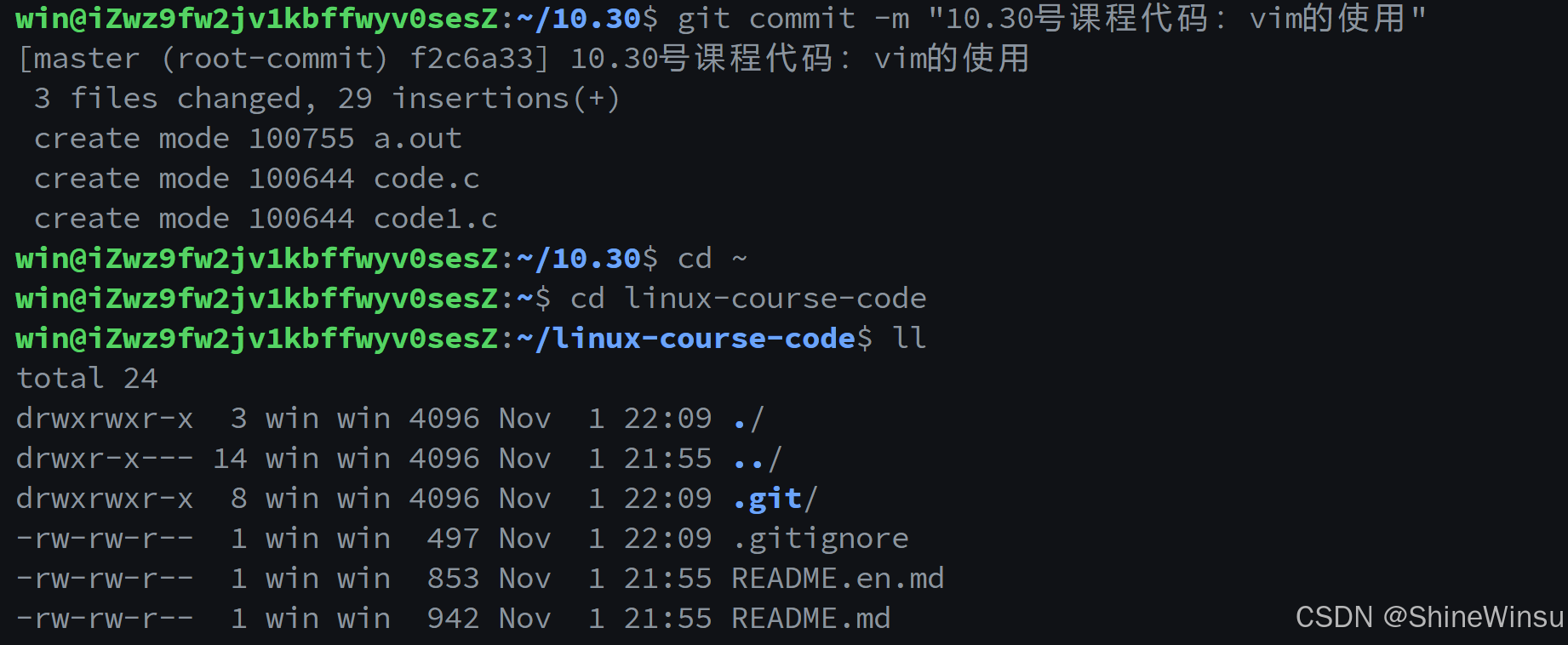 诶,怎么没有呢,哈哈,:
诶,怎么没有呢,哈哈,:
Git 仓库的 "隔离性" 导致视觉差异
Git 中每个仓库是独立的版本管理单元 (由目录下的 .git 目录标识)。你操作的两个目录属于不同仓库:
~/10.30目录:执行了git init,是一个独立的 Git 仓库,提交的文件存储在~/10.30/.git中;~/linux-course-code目录:是另一个独立的 Git 仓库,其版本历史和文件仅存储在~/linux-course-code/.git中。
因此,10.30 仓库的提交不会出现在 linux-course-code 仓库中,这是 Git 仓库 "隔离管理" 的设计,确保不同项目的版本历史互不干扰。
三、验证本地仓库的提交记录
若要确认 ~/10.30 仓库的提交是否成功,可在该目录下执行:
cd ~/10.30
git log此时会看到以 f2c6a33 开头的提交记录,说明文件确实已存入该仓库的本地历史。
git push:
git push 是 Git 中用于将本地仓库的提交推送到远程仓库的核心命令,核心要点如下:
一、核心功能
实现本地与远程仓库的代码同步,将本地开发的新功能、修复等提交,推送到团队共享的远程仓库或个人远程备份仓库。
二、核心用法
| 场景 | 命令 | 说明 |
|---|---|---|
| 推送指定分支到远程 | git push <远程名> <本地分支名> |
如 git push origin master(将本地 master 推到远程 origin 的 master 分支) |
| 首次推送并设置上游 | git push -u <远程名> <本地分支名> |
如 git push -u origin feature-login(推送后设置 "上游跟踪分支",后续可直接 git push) |
| 直接推送(已设上游) | git push |
本地分支已通过 -u 关联远程分支时,可直接执行 |
三、关键选项
-u/--set-upstream:推送时设置上游跟踪分支 ,后续git push/git pull可省略远程和分支,大幅简化操作。--force/-f:强制推送(覆盖远程分支历史),仅在明确需求(如本地变基后同步)时使用,否则易丢失远程提交。
四、核心注意事项
- 冲突处理 :推送前若远程分支有本地未包含的提交,会被拒绝(
rejected)。需先执行git pull拉取并合并远程代码,解决冲突后再推送。 - 远程仓库配置 :若提示
fatal: No configured push destination,需先通过git remote add <名称> <远程地址>配置远程仓库(如git remote add origin https://gitee.com/xxx/xxx.git)。
git pull:
git pull 是 Git 版本控制系统中用于拉取远程仓库的最新代码并合并到本地分支 的核心命令,它是 git fetch(拉取远程提交)和 git merge(合并到本地分支)的组合操作,核心作用是保证本地代码与远程仓库同步。以下是详细介绍:
一、核心功能
将远程仓库的最新提交拉取到本地 ,并自动合并到当前本地分支,解决本地与远程的代码差异,为后续推送(git push)或本地开发提供一致的代码基础,其实主要是因为git要求我们的本地仓库要和远程仓库一样,不难的话是不支持git push的,所以呢,如果两个仓库有差异的话,我们就得去git pull同步两个仓库。
二、基本语法格式
| 格式 | 说明 | 示例 |
|---|---|---|
git pull <远程仓库名> <远程分支名> |
拉取指定远程仓库的指定分支,并合并到当前本地分支 | git pull origin master(拉取远程 origin 的 master 分支,合并到本地当前分支) |
git pull |
若本地分支已跟踪远程分支 (通过 git push -u 或 git branch --set-upstream-to 设置),可直接拉取对应远程分支 |
需先设置上游跟踪,后续可简化操作 |
git pull <远程仓库名> <远程分支名>:<本地分支名> |
拉取远程分支并合并到指定本地分支(本地分支可与远程分支名称不同) |
git个人常用方法总结(看这个就够了):
OK大家,上面给大家介绍了git的三板斧,那么在这里,我就直接进行一个总结好了,因为说实话,上面的其实也不是足够的详细,并且按照上面的方法去git push,其实是有问题的,大家试了就知道了,当然,也不是说上面的方法就不行了,只是上面的方法就要求更多,这对目前还只是初学阶段的我们来说,有点难了,所以我就给大家总结一下个人的话,我们想要把我们的文件推送到本地仓库和远程仓库的方法。
那么首先,我们依旧是选择在本地家目录里克隆一下远程仓库,这个和我们前面说的一模一样,没有问题。
那么接下来,就是最重要最关键的了,大家可能会选择把自己平时所写的代码也放在家目录里的自己创建的新目录里,但是呢,这个时候,问题也就出现了,因为在仓库目录外的目录里是没有.git的,即使我们使用git init,但也是需要很繁琐的修改和连接才行,说实话,太麻烦了。
所以呢,我建议,大家以后就把自己写的代码文件、目录等等,就建立在仓库目录下,这样子我们再去使用git三板斧,就完全没问题了。
首先git add 目录名,将整个目录都存在暂存区,然后git commit -m "提交信息",最后直接git push,就能成功把我们要传的文件传递到远程仓库了,这个是目前来说,我们最好使用的方法,希望大家注意。
cgdb调试器:
OK大家,那么我们知道呀,我们写完代码之后,不一定就能百分百达到我们的要求和目的,但是呢,我们又不知道是哪里出了问题,所以我们就得借助调试去进行代码的运行,去看看是哪一部分的代码出现问题,那么我们之前基本都是用vs studio进行调试,不得不说,它的调试功能,绝对是目前世界顶级的调试,但是呢,我们也不能光用那个,我们不可能只在windows系统下写代码,所以,在Linux系统终端中,我们要如何调试我们的代码呢?比较常见的,就是gdb和cgdb,当然,还有一些其他的调试器,但是由于设置过于复杂,而且未来我们也会转移到vscode里,所以我们现在没必要去了解那些,我们就用cgdb这种符合vim风格的调试器就行,大家要知道,有时候原始不代表效率低。
那么大家可能会好奇,怎么不使用gdb呢?那我只能说,gdb太low了,它甚至都不把代码显示出来,这还玩什么呢?所以我们就用gdb的升级版,cgdb。
cgdb的介绍:
cgdb 是一款为 GDB(GNU 调试器)提供vim 风格界面的命令行调试工具,将代码浏览与调试功能深度融合,核心信息如下:
一、核心定位
为习惯vim操作的开发者打造,在命令行环境中实现 "源码浏览 + GDB 调试" 的一体化体验,大幅提升 C/C++ 等语言的命令行调试效率。
二、核心功能
| 功能分类 | 具体说明 |
|---|---|
| 源码浏览 | 以vim界面展示源码,支持vim的跳转(如gg/G、标签跳转)、搜索(/正则搜索)、分屏等操作。 |
| GDB 调试集成 | 无缝兼容 GDB 的所有调试命令(如b设断点、n单步执行、p查看变量、c继续运行等),调试命令在右侧交互区执行,源码变化在左侧实时反馈。 |
三、关键特点
- 操作习惯友好 :对
vim用户无额外学习成本,调试时可沿用vim快捷键操作源码(如hjkl移动、dd删除行等)。 - 轻量高效:基于终端运行,无需图形界面,适合远程服务器、无 GUI 环境的开发场景,资源占用极低。
四、适用场景与使用方式
- 适用场景 :C/C++ 项目调试(需依赖 GDB)、习惯
vim的开发者、远程服务器开发环境、嵌入式开发等无图形界面的调试场景。 - 安装与启动 :
- 安装:Linux 发行版可通过包管理器安装,如
apt install cgdb(Debian/Ubuntu)、yum install cgdb(CentOS)。 - 启动:在终端执行
cgdb 可执行文件(注意是debug版本下的可运行代码)(如cgdb a.out),进入界面后左侧为源码区,右侧为 GDB 命令交互区,可直接执行 GDB 命令并同步浏览源码。
- 安装:Linux 发行版可通过包管理器安装,如
通过 cgdb,开发者可在熟悉的vim操作逻辑中完成复杂调试,是命令行环境下高效调试的利器。
调试前的预备:
要使用cgdb(结合vim界面的gdb增强工具)进行高效调试,需先明确程序发布模式(debug/release) 与 -g调试信息选项,以下是核心说明:
一、程序的两种发布模式:debug vs release
| 维度 | debug模式(调试模式) |
release模式(发布模式) |
|---|---|---|
| 用途 | 开发 / 调试阶段,用于定位代码逻辑问题、内存泄漏等 bug | 最终发布阶段,供用户 / 生产环境直接使用 |
| 调试信息 | 包含完整调试信息(源码行号、变量类型 / 作用域、函数调用关系等) | 无调试信息(已被编译器剥离) |
| 编译优化 | 关闭或仅开启轻度优化(如-O0) |
开启深度优化(如-O2/-O3,编译器会重排代码、内联函数以提升效率) |
| 二进制体积 | 较大(因包含调试信息) | 较小(无调试信息,且经优化压缩) |
| 运行效率 | 较低(因未深度优化) | 较高(因编译优化) |
二、Linux gcc/g++的默认模式
Linux 下的gcc(C 编译器)和g++(C++ 编译器)默认生成release模式的二进制程序,即:
- 编译时不嵌入调试信息,仅保留可执行逻辑;
- 隐式开启编译优化(如
-O2),以提升程序运行效率。
例如,执行 gcc main.c -o main,生成的main是 **release版本 **,无调试信息,无法被cgdb进行源码级调试。
三、cgdb调试的关键:-g选项
cgdb是基于gdb的 "vim风格界面增强工具",需程序包含调试信息 才能进行源码级调试 (如在vim风格界面中单步跟踪源码、查看变量值、设置行断点等)。-g选项的作用是让gcc/g++在生成二进制时,嵌入调试信息(如源码行号与二进制指令的映射、变量类型信息等)。
1. 使用方法
编译时显式添加-g选项,生成包含调试信息的debug版本,示例:
# C程序
gcc -g main.c -o main_debug
# C++程序
g++ -g main.cpp -o main_debug2. 与优化选项的兼容性
-g可与编译优化选项(如-O1/-O2)同时使用,例如:
gcc -g -O2 main.c -o main_debug_opt但需注意:过高的优化(如-O3)可能导致 "源码逻辑" 与 "实际执行逻辑" 存在差异(编译器会重排代码、内联函数),调试时需谨慎。
四、未添加-g的后果
程序可以正常编译运行,但无法被cgdb进行源码级调试,具体表现为:
cgdb左侧源码区无法显示源代码:仅显示汇编代码或提示 "无源码信息"。- 无法在源码行设置断点:执行
break 行号会失败,需通过汇编地址设置断点(对普通开发者极不友好)。 - 无法查看变量的源码级信息:执行
print 变量名时,可能显示为内存地址或无意义值(因无调试信息映射)。
简言之,未加-g的程序能正常运行,但cgdb只能进行汇编级调试,无法关联到源代码逻辑。
综上,若需使用cgdb进行源码级调试,必须在编译时添加-g选项 ;而gcc/g++默认生成的release版本(无-g)仅适用于最终发布,不适用于调试阶段。
总结:
其实总结一下就是,我们平时写的代码就是分为release版本和debug版本,那么我们想要调试的话,就要求程序必须是debug版本的,那么由于我们之前使用gcc 源文件 -o 可执行程序文件 其实是直接生成release版本的程序文件,那么这就是肯定不行的,所以呢,我们就要加-g选项生成debug版本的可执行程序文件,那么其实就是把-g加在gcc后面,然后照旧,还是很简单的。
还有一个注意点就是,大家使用cgdb的时候,后面是跟着debug版本的可执行程序文件,可不是源文件奥,希望大家注意。
cgdb的使用:
OK大家,那么接下来我们就可以开始使用cgdb对代码进行调试了
那么大家回车一下: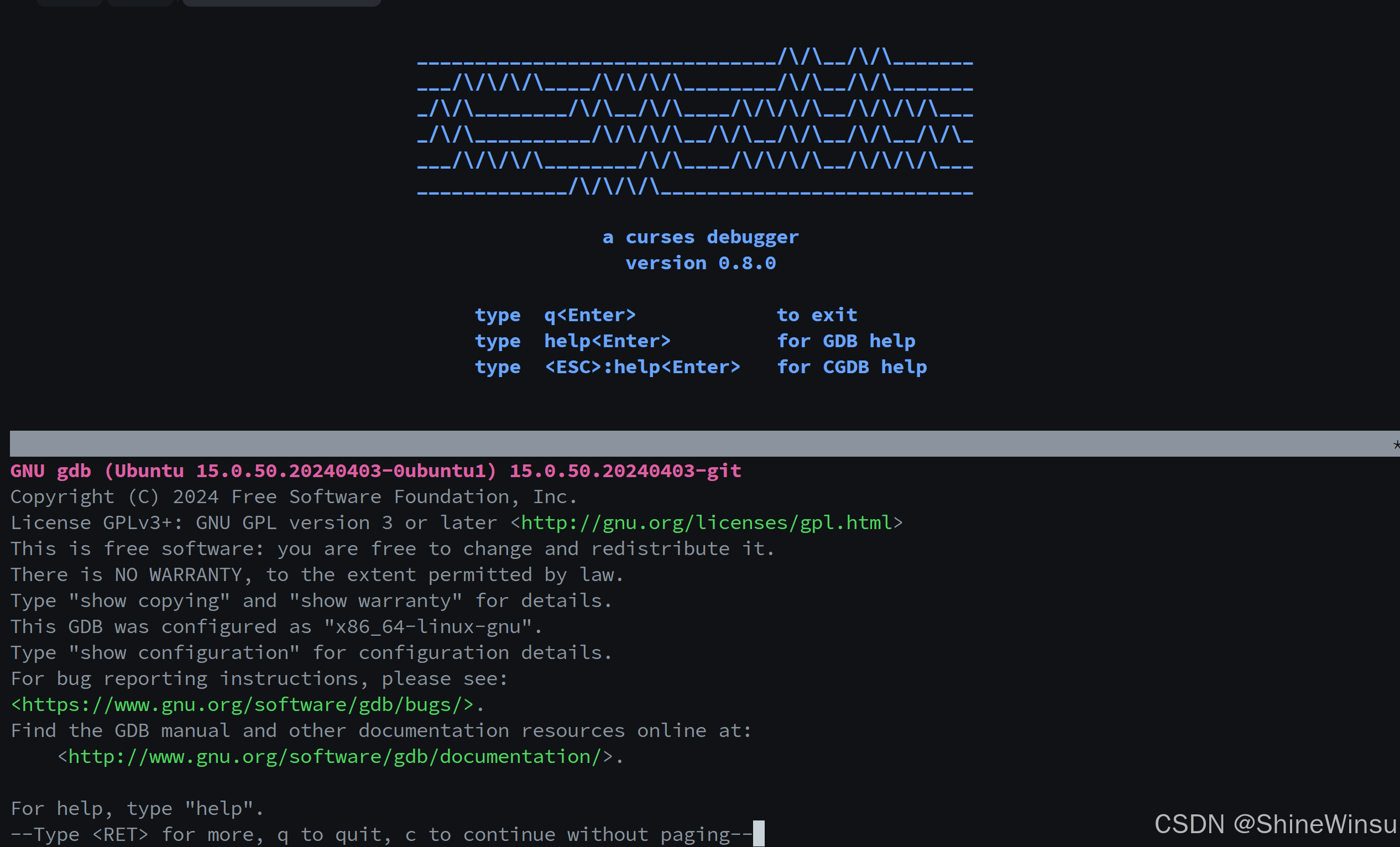 就会进入这个界面,那么大家肯定好奇,诶,代码呢?哈哈,其实我们输入list或者l,就会显示出来:
就会进入这个界面,那么大家肯定好奇,诶,代码呢?哈哈,其实我们输入list或者l,就会显示出来:
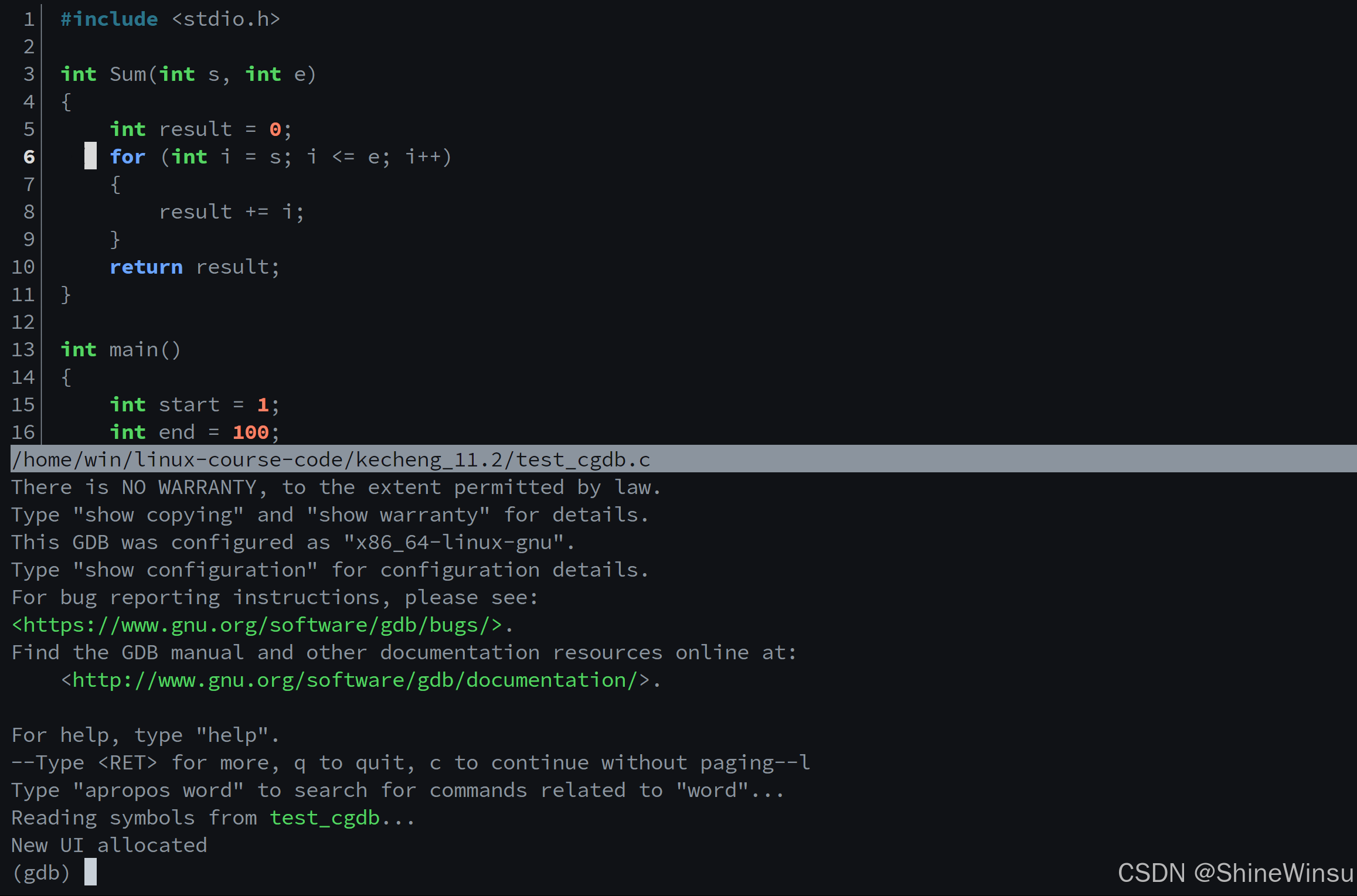
Ok,接下来我来介绍cgdb中常用的一些指令:
将上面的代码进行上下移动:
OK大家,那么大家刚进去使用的时候,会发现,诶,代码怎么就固定在那里了动不了,我们想上下滑动都不行,其实这是因为我们默认进入的是insert模式,即直接进入下面的gdb调试,所以无法移动上面的代码,那么如果我们想移动上面的代码,那么是按esc键退出insert模式,进入normal模式,此时我们就可以使用hjkl或者上下左右键或者鼠标来移动代码,大家可以发现,其实这个就和vim编辑器的使用差不多。
核心前提:示例代码与编译准备
以下所有命令均基于下方求和示例代码演示,编译时需添加 -g 选项生成调试信息:
#include <stdio.h>
// 求和函数:计算[s, e]区间内所有整数的和
int Sum(int s, int e)
{
int result = 0; // 行5:局部变量初始化
for (int i = s; i <= e; i++) // 行6:循环开始
{
result += i; // 行8:累加计算
}
return result; // 行10:返回结果
}
int main()
{
int start = 1; // 行14:起始值
int end = 100; // 行15:结束值
printf("I will begin\n"); // 行17:提示信息
int n = Sum(start, end); // 行18:调用求和函数
printf("running done, result is: [%d-%d]=%d\n", start, end, n); // 行19:输出结果
return 0; // 行21:程序退出
}编译命令(生成带调试信息的可执行文件 main_debug):
gcc -g sum.c -o main_debug # C语言编译
# g++ -g sum.cpp -o main_debug # C++语言编译(若文件为.cpp后缀)一、启动与退出命令
1. gdb binFile(启动 GDB 并加载程序)
- 命令格式:
gdb [选项] 二进制文件名 - 核心作用:启动 GDB 调试器,并将指定的二进制程序加载到调试环境中,建立源码与二进制指令的映射(依赖调试信息)。
- 样例:
- 加载当前目录下的
main_debug程序:gdb ./main_debug - 带参数启动(如修改求和区间为 5,20):
gdb --args ./main_debug 5 20(等价于后续执行run 5 20)
- 加载当前目录下的
- 注意事项:
- 必须加载带调试信息的程序:编译时需加
-g(如上述gcc -g sum.c -o main_debug),否则无法进行源码级调试(仅能查看汇编)。 - 二进制文件必须存在且可执行:若文件路径错误(如
gdb ./nonexist),会提示 "Cannot access `./nonexist': 没有那个文件或目录"。 - 支持 "后续加载":若直接输入
gdb启动,可通过file binFile命令后续加载程序(如(gdb) file ./main_debug)。
- 必须加载带调试信息的程序:编译时需加
2. quit 或 Ctrl + d(退出 GDB)
- 命令格式:
quit或快捷键Ctrl + d - 核心作用:终止 GDB 调试会话,退出调试环境。
- 样例:
- 输入命令退出:
(gdb) quit - 快捷键退出:直接按
Ctrl + d
- 输入命令退出:
- 注意事项:
- 程序运行中退出:会提示 "程序正在运行。退出调试器?(y 或 n)",输入
y强制退出(程序会被终止)。 - 未加载程序时:可直接退出,无额外提示。
- 程序运行中退出:会提示 "程序正在运行。退出调试器?(y 或 n)",输入
二、代码浏览命令(list/l)
用于在 GDB 中查看源代码,依赖调试信息中的 "源码路径 + 行号映射"。
1. list/l(默认浏览)
- 命令格式:
list或l - 核心作用:从 "上次浏览的结束位置" 开始,每次显示 10 行源代码(首次执行从程序入口附近开始)。
- 样例:
-
首次执行:
(gdb) list→ 显示main函数附近的 10 行代码,输出如下:11 } 12 13 int main() 14 { 15 int start = 1; 16 int end = 100; 17 18 printf("I will begin\n"); 19 int n = Sum(start, end); 20 printf("running done, result is: [%d-%d]=%d\n", start, end, n); -
连续执行:再次输入
list→ 显示下 10 行代码(后续未显示的程序结尾部分)。
-
- 注意事项:
- 无调试信息(未加
-g):会提示 "没有可用于列出的源码",或直接显示汇编指令(如0x400526 <main+3> mov %edi,-0x14(%rbp))。 - 文件结束:当浏览到文件末尾时,会提示 "到达文件末尾;从第 1 行重新开始?",输入
y从头显示。
- 无调试信息(未加
2. list/l 行号(按行号浏览)
-
命令格式:
list 行号或l 行号 -
核心作用:以 "指定行号" 为中心,显示其前后共 10 行源代码(行号在中间位置)。
-
样例:
-
显示第 6 行(
for循环行)附近代码:(gdb) list 6→ 输出如下(围绕行 6 展开):1 #include <stdio.h> 2 3 int Sum(int s, int e) 4 { 5 int result = 0; 6 for (int i = s; i <= e; i++) 7 { 8 result += i; 9 } 10 return result;
-
-
注意事项:
- 行号超出文件范围:若示例代码共 21 行,输入
list 35,会提示 "行号 35 超出文件 sum.c 的范围(1-21)",并显示最后 10 行(12-21 行)。 - 行号为 0 或负数:会自动调整为第 1 行,显示 1-10 行。
- 行号超出文件范围:若示例代码共 21 行,输入
3. list/l 函数名(按函数浏览)
-
命令格式:
list 函数名或l 函数名 -
核心作用:显示 "指定函数" 的源代码,从函数定义开始,每次 10 行(连续执行可显示完整函数)。
-
样例:
-
显示
Sum函数代码:(gdb) list Sum→ 输出如下(从函数定义开始):3 int Sum(int s, int e) 4 { 5 int result = 0; 6 for (int i = s; i <= e; i++) 7 { 8 result += i; 9 } 10 return result; 11 } 12
-
-
注意事项:
- 函数名不存在或拼写错误:如函数为
Sum却输入list sum(小写),会提示 "未找到函数 sum 的定义"(GDB 区分大小写)。 - 库函数无调试信息:如
list printf,会提示 "无源码信息"(系统库函数未带-g编译)。
- 函数名不存在或拼写错误:如函数为
4. list/l 文件名:行号(多文件浏览)
- 命令格式:
list 文件名:行号或l 文件名:行号 - 核心作用:在多文件项目中,显示 "指定文件" 的 "指定行号" 附近代码(解决单文件命令无法跨文件的问题)。
- 样例:
- 若项目含
utils.c(假设其中有max函数),显示utils.c第 8 行附近代码:(gdb) list utils.c:8
- 若项目含
- 注意事项:
- 文件未编译进程序:若
utils.c未参与编译(如编译命令仅为gcc -g sum.c -o main_debug),会提示 "无法找到文件 utils.c"。 - 文件名需完整(含扩展名):如
list utils:8(缺.c)可能匹配不到(除非有同名无扩展名文件)。
- 文件未编译进程序:若
三、执行控制命令
控制程序运行状态(启动、单步、连续执行等),依赖程序处于 "已加载且可运行" 状态。
1. run/r(启动程序)
- 命令格式:
run [命令行参数]或r [参数] - 核心作用:从程序入口(通常是
main函数)开始执行,直到遇到断点、程序结束或手动暂停(Ctrl + c)。 - 样例:
-
无参数启动(计算 1,100 求和):
(gdb) run→ 输出如下(无断点时直接执行完毕):Starting program: /home/user/main_debug I will begin running done, result is: [1-100]=5050 [Inferior 1 (process 12345) exited normally] -
带参数启动(计算 5,15 求和):
(gdb) run 5 15→ 需修改main函数接收参数(示例代码可扩展为start = atoi(argv[1]); end = atoi(argv[2]);),执行后输出求和结果。
-
- 注意事项:
- 程序已在运行:会提示 "程序已在运行。是否要杀死它并重新启动?(y 或 n)",输入
y则终止当前运行并重启。 - 未加载程序:会提示 "没有可执行文件被指定"(需先通过
gdb binFile或file binFile加载)。 - 启动后无断点:程序会直接运行到结束,显示 "程序正常退出"。
- 程序已在运行:会提示 "程序已在运行。是否要杀死它并重新启动?(y 或 n)",输入
2. next/n(逐过程单步)
-
命令格式:
next或n -
核心作用:单步执行当前语句,不进入函数内部(将函数调用视为 "一个步骤"),执行后暂停在下一行。
-
样例:
-
先通过
break 18在main函数第 18 行(int n = Sum(start, end);)设断点,执行run启动程序并命中断点后:(gdb) next # 执行Sum函数(不进入),直接暂停在第19行 19 printf("running done, result is: [%d-%d]=%d\n", start, end, n);
-
-
注意事项:
- 程序未启动或已终止:会提示 "没有正在运行的程序"(需先
run启动)。 - 执行到程序末尾:若当前是第 21 行(
return 0;),执行next会让程序结束,显示 "程序正常退出"。
- 程序未启动或已终止:会提示 "没有正在运行的程序"(需先
3. step/s(逐语句单步)
-
命令格式:
step或s -
核心作用:单步执行当前语句,若当前是函数调用,会进入函数内部(停在函数第一行可执行语句)。
-
样例:
-
同样在第 18 行(
int n = Sum(start, end);)命中断点后:(gdb) step # 进入Sum函数,暂停在第5行(函数内第一行可执行语句) Sum (s=1, e=100) at sum.c:5 5 int result = 0;
-
-
注意事项:
- 进入无调试信息的函数:如
step进入printf(系统库函数),会显示汇编代码(如0x7ffff7e36560 <printf> mov %rdi,%rax),无法查看源码。 - 程序未暂停:同
next,未启动或已终止时提示 "没有正在运行的程序"。
- 进入无调试信息的函数:如
4. continue/c(继续执行)
-
命令格式:
continue或c -
核心作用:从当前暂停位置继续执行,直到遇到下一个断点、程序结束或被
Ctrl + c强制暂停。 -
样例:
-
先通过
break 8在Sum函数第 8 行(result += i;)设断点,执行run启动并命中断点(首次循环i=1)后:(gdb) continue # 继续执行到下一次断点(i=2时再次命中第8行) Continuing. Breakpoint 1, Sum (s=1, e=100) at sum.c:8 8 result += i;
-
-
注意事项:
- 无后续断点:若程序未结束且无其他断点,会一直运行到结束(不再暂停)。
- 程序未暂停:如刚启动就执行
continue,会提示 "程序未暂停"(需先命中断点或单步后)。
5. finish(执行到函数返回)
-
命令格式:
finish -
核心作用:从当前函数内部的暂停位置,连续执行到 "函数返回"(即执行完
return语句),然后暂停在调用该函数的下一行。 -
样例:
-
在
Sum函数第 8 行(result += i;)暂停时:(gdb) finish # 执行完所有循环和return,返回main函数 Run till exit from #0 Sum (s=1, e=100) at sum.c:8 0x00005555555551ba in main () at sum.c:18 18 int n = Sum(start, end); Value returned is $1 = 5050 # 显示Sum函数返回值(1-100求和结果)
-
-
注意事项:
- 不在函数内部:如在
main函数外或全局范围,会提示 "不是在函数内部"。 - 函数无返回(无限循环):会一直运行(需按
Ctrl + c强制暂停,此时finish失效)。
- 不在函数内部:如在
6. until 行号(执行到指定行)
-
命令格式:
until 行号(可简写为u 行号) -
核心作用:从当前位置执行,跳过中间语句(包括循环),直接暂停在 "指定行号"(前提是行号在当前执行路径上)。
-
样例:
-
在
Sum函数第 6 行(for循环)暂停时,执行until 10(跳转到第 10 行return result;):(gdb) until 10 # 跳过所有循环迭代,直接暂停在return行 Sum (s=1, e=100) at sum.c:10 10 return result;
-
-
注意事项:
- 行号不在当前执行路径:如当前在
if (start > 0)分支,指定else分支内的行号(如until 25,假设else分支行号),until会失效(程序不会暂停在目标行)。 - 行号小于当前行号:若当前在第 8 行,指定
until 5,会提示 "行号 5 小于当前行号 8",且不会暂停(因程序无法 "回退" 执行)。
- 行号不在当前执行路径:如当前在
四、断点管理命令
控制程序暂停的 "触发点",依赖调试信息和有效代码位置。
1. break/b 文件名: 行号(按行号设断点)
- 命令格式:
break 行号或b 文件名:行号 - 核心作用:在 "指定行号" 设置断点,程序执行到该行时会自动暂停(断点设在行首的可执行指令处)。
- 样例:
- 在当前文件第 6 行(
for循环)设断点:(gdb) break 6→ 输出:Breakpoint 1 at 0x555555555166: file sum.c, line 6. - 在多文件项目中,在
utils.c第 5 行设断点:(gdb) break utils.c:5
- 在当前文件第 6 行(
- 注意事项:
- 行号对应非可执行语句(如注释、空行):若第 7 行是注释,执行
break 7,GDB 会自动调整到第 8 行,提示 "断点 1 在 0x400543: 文件 sum.c,行 8"。 - 未加
-g:无法用行号设断点,需用汇编地址(如break *0x400526),且不显示源码位置。 - 行号超出范围:提示 "无法在该行设置断点"(如示例代码共 21 行,设
break 30)。
- 行号对应非可执行语句(如注释、空行):若第 7 行是注释,执行
2. break/b 函数名(按函数设断点)
- 命令格式:
break 函数名或b 函数名 - 核心作用:在 "指定函数的入口处" 设置断点(即函数第一行可执行语句),程序进入函数时暂停。
- 样例:
- 在
main函数入口设断点:(gdb) break main→ 输出:Breakpoint 1 at 0x55555555518d: file sum.c, line 14.(暂停在第 14 行int start = 1;) - 在
Sum函数入口设断点:(gdb) break Sum→ 输出:Breakpoint 2 at 0x55555555515d: file sum.c, line 5.(暂停在第 5 行int result = 0;)
- 在
- 注意事项:
- 函数名重复(重载函数):如 C++ 中
void func(int)和void func(float),需指定参数(如break func(int)),否则 GDB 会列出所有重载版本供选择。 - 函数未定义:提示 "找不到函数'func'的定义"(检查拼写或是否编译进程序)。
- 函数名重复(重载函数):如 C++ 中
3. info break/b(查看断点信息)
-
命令格式:
info break或info b -
核心作用:显示所有断点的详细信息,包括序号、类型、地址、位置、状态(启用 / 禁用)。
-
样例输出(假设已设 2 个断点):
(gdb) info break Num Type Disp Enb Address What 1 breakpoint keep y 0x000055555555518d in main at sum.c:14 2 breakpoint keep n 0x000055555555515d in Sum at sum.c:5- 说明:
Num是断点序号,Enb是启用状态(y启用,n禁用),What是断点位置(函数 + 行号)。
- 说明:
-
注意事项:
- 无断点时:显示 "没有断点"。
4. delete/d breakpoints n(删除断点)
- 命令格式:
delete breakpoints(删除所有)或delete breakpoints n(删除序号 n 的断点),要注意:n是断点的序号,而不是断点所在行数 - 核心作用:永久删除断点(区别于
disable的临时禁用)。 - 样例:
- 删除所有断点:
(gdb) delete breakpoints - 删除序号 2 的断点(
Sum函数入口断点):(gdb) delete breakpoints 2
- 删除所有断点:
- 注意事项:
- 无断点或序号无效:删除所有时提示 "无断点可删除";删除指定序号(如
delete 5但只有 2 个断点)提示 "断点 5 不存在"。 - 操作不可逆:删除后需重新设置,建议先
disable(临时禁用)再决定是否删除。
- 无断点或序号无效:删除所有时提示 "无断点可删除";删除指定序号(如
5. disable breakpoints n(禁用断点)
- 命令格式:
disable breakpoints(禁用所有)或disable breakpoints n(禁用序号 n 的断点) - 核心作用:临时禁用断点(断点仍存在,但程序执行到此时不会暂停)。
- 样例:
- 禁用所有断点:
(gdb) disable breakpoints - 禁用序号 1 的断点(
main函数入口断点):(gdb) disable breakpoints 1
- 禁用所有断点:
- 注意事项:
- 禁用后状态:
info break中Enb列显示n(禁用)。
- 禁用后状态:
6. enable breakpoints n(启用断点)
- 命令格式:
enable breakpoints(启用所有)或enable breakpoints n(启用序号 n 的断点) - 核心作用:恢复被禁用的断点(使其重新生效)。
- 样例:
- 启用所有断点:
(gdb) enable breakpoints - 启用序号 1 的断点:
(gdb) enable breakpoints 1
- 启用所有断点:
- 注意事项:
- 启用已启用的断点:无副作用(状态不变)。
五、变量操作命令
查看、修改、跟踪变量值,依赖变量在当前作用域且有调试信息。
1. print/p 表达式(打印值)
- 命令格式:
print 表达式或p 表达式 - 核心作用:计算并打印 "表达式" 的值(表达式可包含变量、常量、算术运算、函数调用等)。
- 样例:
- 打印
start变量的值(main函数中):(gdb) p start→ 输出:$1 = 1($1是结果编号,可后续引用) - 计算
start + end(start=1,end=100):(gdb) p start + end→ 输出:$2 = 101 - 打印
Sum函数中result变量(需在函数内部暂停时):(gdb) p result→ 输出:$3 = 5(假设当前累加了 1-5)
- 打印
- 注意事项:
- 变量超出作用域:如在
main函数中打印Sum函数的局部变量result,会提示 "'result'未声明"。 - 表达式非法:如
p 1/0,会提示 "被零除";调用未定义函数(如p func())提示 "函数'func'未定义"。 - 未加
-g:变量名无法识别,需通过内存地址访问(如p *(int*)0x7fffffffde6c),且可读性差。
- 变量超出作用域:如在
2. set var 变量 = 值(修改变量)
- 命令格式:
set var 变量名=值 - 核心作用:强制修改 "当前作用域内变量" 的值(无需重新编译,临时改变程序执行逻辑)。
- 样例:
- 在
Sum函数中,将循环变量i从 1 改为 50:(gdb) set var i=50→ 后续累加从 50 开始 - 在
main函数中,将end的值从 100 改为 200:(gdb) set var end=200→ 求和区间变为 1,200
- 在
- 注意事项:
- 变量是
const常量:如const int a=5,执行set var a=10会提示 "无法修改只读变量'a'"。 - 变量超出作用域:同
print,提示 "变量未声明"。 - 类型不匹配:如给
int变量赋字符串,会提示 "类型不兼容"。
- 变量是
3. display 变量名(跟踪变量)
- 命令格式:
display 变量名 - 核心作用:将变量加入 "自动跟踪列表",程序每次暂停时(如命中断点、单步后)会自动打印该变量的值。
- 样例:
- 跟踪
Sum函数中的result变量:(gdb) display result→ 后续每次暂停会显示:1: result = 0(首次)、1: result = 1(执行一次result += i后)等
- 跟踪
- 注意事项:
- 变量超出作用域后:退出
Sum函数后,每次暂停会显示 "1: result = < 错误:无法访问'result'>"(需用undisplay删除)。 - 查看跟踪列表:用
info display,显示所有跟踪项的序号和变量名。
- 变量超出作用域后:退出
4. undisplay 编号(取消跟踪)
- 命令格式:
undisplay 跟踪项编号 - 核心作用:从 "自动跟踪列表" 中移除指定编号的变量,停止自动打印。
- 样例:
- 取消编号 1 的跟踪项(
result变量):(gdb) undisplay 1
- 取消编号 1 的跟踪项(
- 注意事项:
- 编号无效:如
undisplay 5但只有 3 个跟踪项,提示 "没有编号为 5 的显示项"。
- 编号无效:如
六、栈帧与调用链命令
分析函数调用关系和局部变量,依赖程序处于 "暂停状态"。
1. backtrace/bt(查看调用栈)
-
命令格式:
backtrace或bt -
核心作用:显示当前程序的 "函数调用链"(栈帧),从最内层函数(当前执行的函数)到最外层(如
main),包含每个函数的地址和参数。 -
样例输出(在
Sum函数内部暂停时):(gdb) bt #0 Sum (s=1, e=100) at sum.c:8 #1 0x00005555555551ba in main () at sum.c:18- 说明:
#0是当前函数(Sum),参数s=1、e=100;#1是调用Sum的函数(main),调用位置在第 18 行。
- 说明:
-
注意事项:
- 程序未暂停:如刚启动或已结束,提示 "没有当前栈帧"。
- 崩溃时定位问题:如程序出现 "段错误",执行
bt可查看崩溃发生在哪个函数的哪层调用(如#0 0x0000555555555171 in Sum (s=1, e=100) at sum.c:8→ 崩溃在Sum函数第 8 行)。
2. info/i locals(查看局部变量)
-
命令格式:
info locals或i locals -
核心作用:显示 "当前栈帧(当前执行的函数)" 的所有局部变量及其值(不包含全局变量或参数)。
-
样例输出(在
Sum函数中执行,循环执行到i=10时):(gdb) info locals result = 55 # 1+2+...+10=55 i = 10 -
注意事项:
- 不在函数内部:如在
main函数外或全局范围,提示 "不在任何函数内"。 - 无局部变量:如函数内未定义变量,显示 "无局部变量"。
- 不在函数内部:如在
核心前提与通用注意事项
- 调试信息是基础:所有源码级调试命令(
list、break 行号、print 变量等)均依赖编译时的-g选项,否则只能进行汇编级调试(功能大幅受限)。 - 程序状态决定命令有效性:
- 执行控制命令(
next、step、continue等)仅在程序启动且暂停时有效; - 未启动(未
run)或已终止的程序,多数命令会报错 "无运行中的程序"。
- 执行控制命令(
- 作用域与路径限制:
- 变量操作命令(
print、set var)仅对当前作用域内的变量有效; until 行号、break 行号要求目标行在当前执行路径上(否则无效)。
- 变量操作命令(
三个好用技巧:
一、watch:变量变化监视命令
核心作用
- 监视指定变量或表达式的值,当值被读取(rwatch) 、被修改(watch) 或 读写(awatch) 时,程序自动暂停,精准捕捉变量变化时机。
- 区别于
display(仅暂停时显示),watch是 "主动触发暂停",适合跟踪变量异常修改。
命令格式与分类
| 命令类型 | 格式 | 触发条件 |
|---|---|---|
| 写监视 | watch 变量/表达式 |
变量 / 表达式被修改时暂停 |
| 读监视 | rwatch 变量/表达式 |
变量 / 表达式被读取时暂停 |
| 读写监视 | awatch 变量/表达式 |
变量 / 表达式被读或写时暂停 |
实操样例(基于 Sum 函数)
示例代码中,Sum函数的result变量用于累加求和,监视其变化:
-
先加载程序并在
Sum函数入口设断点:(gdb) gdb ./main_debug (gdb) break Sum # 函数入口设断点 (gdb) run # 启动程序,命中断点(停在Sum函数第5行) -
设置
watch监视result变量:(gdb) watch result # 监视result被修改时暂停 Hardware watchpoint 2: result # 提示创建硬件监视点 -
执行
continue,程序会在result每次被修改时暂停:(gdb) continue Continuing. Hardware watchpoint 2: result # 第一次修改(result从0→1) Old value = 0 New value = 1 Sum (s=1, e=100) at sum.c:8 8 result += i; -
再次执行
continue,会持续在result修改时暂停(直到循环结束)。
注意事项
- 必须在程序运行中 设置:未启动程序(未
run)时,watch会报错 "没有正在运行的程序"。 - 变量需在当前作用域:如在
main函数中监视Sum的result,会提示 "变量未声明"(需进入Sum函数后设置)。 - 支持简单表达式:如
watch result + i(监视表达式结果变化),但表达式需合法(无未定义变量)。 - 硬件监视点限制:部分系统对监视变量数量有限制,过多会提示 "无法创建硬件监视点",需简化监视目标。
二、set var:强制修改变量命令
核心作用
- 调试中临时修改变量值,无需重新编译,用于模拟边界条件、跳过无效逻辑或复现异常场景(如强制设置循环变量、修改函数参数)。
- 底层直接修改变量对应的内存地址值,优先级高于源码逻辑。
实操样例(基于 Sum 函数)
场景 1:修改循环变量,跳过部分迭代
-
在
Sum函数第 6 行(for循环)设断点,启动程序并命中:(gdb) break 6 (gdb) run Breakpoint 1, Sum (s=1, e=100) at sum.c:6 6 for (int i = s; i <= e; i++) -
查看当前
i的值,强制改为 50(跳过 1-49 的迭代):(gdb) p i # 查看当前i值(初始为1) $1 = 1 (gdb) set var i=50 # 强制修改i为50 (gdb) p i # 验证修改结果 $2 = 50 -
执行
continue,循环从i=50开始累加,快速验证后续逻辑。
场景 2:修改函数参数,测试边界值
-
在
main函数第 18 行(int n = Sum(start, end);)设断点,启动并命中:(gdb) break 18 (gdb) run Breakpoint 1, main () at sum.c:18 18 int n = Sum(start, end); -
修改
end的值为 200(原 100),测试更大区间求和:(gdb) set var end=200 (gdb) p end $1 = 200 (gdb) step # 进入Sum函数,参数e已变为200 Sum (s=1, e=200) at sum.c:5 5 int result = 0;
注意事项
- 变量需可修改:
const常量(如const int a=10)无法修改,会提示 "无法修改只读变量"。 - 类型必须匹配:给
int变量赋字符串(set var i="abc")会报错 "类型不兼容",需保持类型一致。 - 避免修改全局 / 静态变量:全局变量修改后影响范围广,可能导致后续逻辑异常,调试后需恢复或重启程序。
- 作用域限制:仅能修改当前作用域内的变量(局部变量)或全局变量,超出作用域的变量无法识别。
三、条件断点:满足条件才触发的断点
核心作用
- 在普通断点基础上添加 "触发条件",只有当条件成立时,程序才暂停,避免无效断点触发(如循环中仅在特定迭代时暂停)。
- 格式:
break 位置 if 条件或 先设断点再用condition 断点序号 条件。
实操样例(基于 Sum 函数)
场景 1:循环中仅当 i=50 时暂停
-
直接设置条件断点(第 8 行
result += i;,仅i=50时触发):(gdb) break 8 if i==50 # 行号+条件 Breakpoint 1 at 0x555555555171: file sum.c, line 8. -
启动程序,执行到
i=50时自动暂停:(gdb) run Starting program: /home/user/main_debug I will begin Breakpoint 1, Sum (s=1, e=100) at sum.c:8 8 result += i; (gdb) p i # 验证条件成立(i=50) $1 = 50
场景 2:修改已有断点的条件
-
先设普通断点,再通过序号添加条件:
(gdb) break 8 # 设普通断点(序号1) (gdb) condition 1 result>1000 # 仅当result>1000时触发 -
启动程序,当
result累加超过 1000 时暂停(对应i=45,1+2+...+45=990,i=46 时 result=1036):(gdb) run Breakpoint 1, Sum (s=1, e=100) at sum.c:8 8 result += i; (gdb) p result $1 = 1036 # 满足result>1000
注意事项
- 条件表达式需合法:使用当前作用域内的变量,语法正确(如
i==50而非i=50,避免赋值错误)。 - 变量需在断点位置可见:如在
main函数断点中使用Sum的i,条件无效(变量未定义)。 - 复杂条件影响性能:如
break 8 if (i%10==0 && result>500),循环次数多时会轻微卡顿,建议简化条件。 - 查看 / 删除条件:用
info break查看条件(What列显示breakpoint 1 at ...: file sum.c, line 8, condition i==50);用condition 断点序号(无条件)删除条件。
注意:
- 条件断点添加常见两种方式:1. 新增 2. 给已有断点追加
- 注意两者的语法有区别,不要写错了。
- 新增: b 行号/文件名:行号/函数名 if i == 30 (条件)
- 给已有断点追加: condition 2 i==30 , 其中2 是已有断点编号,没有if
- Cgbd 分屏操作ESC 进入代码屏, i 回到gdb 屏
结语:以工具为舟,驶向 Linux 开发的星辰大海
亲爱的读者,当你读到这里,想必对 Git 版本控制器和 cgdb 调试器已有了全面的认知。从 Git 的版本管理逻辑到 cgdb 的调试细节,我们走过了一段充满技术趣味的旅程。此刻,我想以最真挚的情感,和你聊聊这两个工具背后的意义,以及它们能为你开启的技术成长之门。
一、Git:不止是版本控制,更是开发思维的重塑
Git 的魅力,远不止于 "提交代码" 这么简单。当你在 Gitee 上创建第一个仓库,用git clone将远程代码拉到本地,再通过git add、git commit、git push完成第一次版本迭代时,你会发现它是时间的 "存档员"------ 每一次提交都是代码状态的 "快照",无论多久后需要回溯历史,Git 都能让你精准 "回到过去"。
在多人协作场景中,Git 更是团队的 "协作中枢" 。通过git branch创建功能分支,你可以在不影响主分支的前提下独立开发;git merge则能将分散的工作成果无缝整合。当你熟练运用git pull拉取远程更新、git push推送本地修改时,会深刻体会到分布式版本控制的强大 ------ 它让团队协作从 "代码冲突的泥潭" 变成 "高效迭代的流水线"。
或许你曾因.gitignore的规则头疼,因合并冲突的解决焦虑,但请相信:这些 "小麻烦" 是掌握 Git 的必经之路。当你能自如地用 Git 管理项目,你会发现自己的开发思维已悄然改变 ------ 你开始习惯 "小步提交、频繁验证",开始重视 "代码历史的可读性",这些思维的升级,才是 Git 送给开发者最珍贵的礼物。
二、cgdb:不是调试的妥协,而是命令行效率的巅峰
cgdb 的出现,为习惯 vim 操作的开发者打造了 "命令行调试的理想国"。它将 GDB 的调试能力与 vim 的操作习惯深度融合,让我们在终端里就能完成 "源码浏览 + 逻辑调试" 的全流程。
还记得我们编译时添加-g生成调试版本,在 cgdb 中用break设断点、next单步执行、print查看变量的过程吗?当你在左侧源码区用hjkl移动光标,右侧 GDB 命令区精准控制程序执行时,会发现调试不再是 "对黑盒的盲目猜测",而是 "对逻辑链条的清晰拆解"。
watch命令对变量的实时监视,让你能捕捉到 "变量何时被异常修改";set var对变量的强制修改,让你能 "强行扭转" 程序逻辑,验证边界场景;条件断点则像 "逻辑的过滤器",帮你在海量循环中精准定位问题。这些功能,让 cgdb 成为我们剖析代码逻辑的 "显微镜"------ 再隐蔽的 bug,在它面前也无处遁形。
别因命令繁多而却步,cgdb 的学习曲线是 "陡峭但回报丰厚" 的。从调试一个简单的求和程序开始,逐步尝试复杂逻辑的断点与变量跟踪,你会发现:cgdb 不仅是调试工具,更是你理解代码执行流程的 "导师"。
三、工具的价值,在 "动手实践" 中绽放
学习 Git 和 cgdb 的过程,也是我对 "技术工具" 认知重塑的过程。我曾以为 "看会教程就是掌握",直到自己动手创建仓库、调试代码时才发现:工具的价值永远在 "实操" 中才能真正释放。
- 学 Git,就自己建一个仓库,提交几次代码,合并一个分支,试试
git reset回滚版本 ------ 只有亲手操作,才能理解 "版本树" 的精妙; - 学 cgdb,就写一个带循环或函数的小程序,故意埋个 bug,用 cgdb 一步步调试 ------ 只有亲身体验 "变量如何变化,逻辑如何跳转",才能掌握调试的精髓。
在 Linux 开发的世界里,"纸上谈兵" 是行不通的。工具的学习没有捷径,唯有 "动手实践、遇到问题、解决问题",才能把工具从 "陌生的命令" 变成 "指尖的本能"。
四、以工具为舟,驶向技术成长的深海
Git 和 cgdb,是你 Linux 开发之旅的 "第一艘船" 和 "第一支桨"。它们或许不是最复杂的工具,但却是最基础、最实用的 ------ 掌握它们,你就拥有了在 Linux 世界里 "航行" 的基本能力。
未来,你会遇到更庞大的项目、更复杂的架构,会接触 Docker、Kubernetes 等容器技术,会学习 Python、Go 等编程语言...... 但请记住:Git 和 cgdb 教会你的 "版本管理思维" 和 "精准调试思维",将是你应对所有技术挑战的底层逻辑。
别害怕 "工具学习的耗时",每一次对工具的掌握,都是你技术护城河的一次加固。当你能自如地用 Git 管理代码,用 cgdb 调试逻辑时,你会发现自己对 Linux 开发的信心已截然不同 ------ 你不再是 "命令的执行者",而是 "技术的掌控者"。
最后:愿你在代码的世界里,永远保持好奇与热爱
亲爱的开发者,技术之路漫长且充满未知,但 Git 和 cgdb 这样的工具,是我们探索未知的 "武器"。它们或许微小,却能在关键时刻为你披荆斩棘。
请保持对技术的好奇,对工具的探索欲。当你在 Git 的版本树里梳理出清晰的开发脉络,在 cgdb 的调试界面中破解每一个逻辑谜题时,你会发现:编程的乐趣,就藏在这些 "工具与思维的碰撞" 里。
愿你以 Git 为笔,书写代码的历史;以 cgdb 为镜,洞察逻辑的真相。在 Linux 开发的星辰大海里,愿你永远有 "扬帆起航" 的勇气,也永远有 "探索未知" 的热情。
加油,开发者!你的代码宇宙,因这些工具的加持,必将更加璀璨。