1.核心角色:Q,K,V到底在干什么?
在 Multi-Head Attention (MHA) 机制中,每一个词(比如"中医")都会通过线性变换生成三个身份:
-
Q(Query - 查询): "我想找什么?"。它代表当前词主动去探寻其他词的意愿。
-
K(Key - 键): "我有什么标签?"。它代表当前词被其他词检索时的特征。
-
V(Value - 值): "我具体的内容"。它代表这个词真正携带的信息。
MHA是什么?
多头注意力机制,是Transformer架构的核心"大脑"。如果说注意力机制(Attention)是让模型学会"抓重点",那么Multi-Head(多头)就是让模型同时从多个不同的维度去抓重点。
通俗类比:
想象你在一个技术交流会上(一句话里的所有词都在这)。
-
你(当前词)拿着你的名片(Q),去对比全场所有人的名片(所有词的 K)。
-
通过对比 Q 和 K 的相似度,你发现某个人(比如"脉诊")和你最聊得来(权重高)。
-
于是你决定花更多精力去听他说话的内容(提取他的 V)。
最后,你把自己听到的所有内容(加权后的V)整合起来,就得到了这个词在当前语境下的新含义。
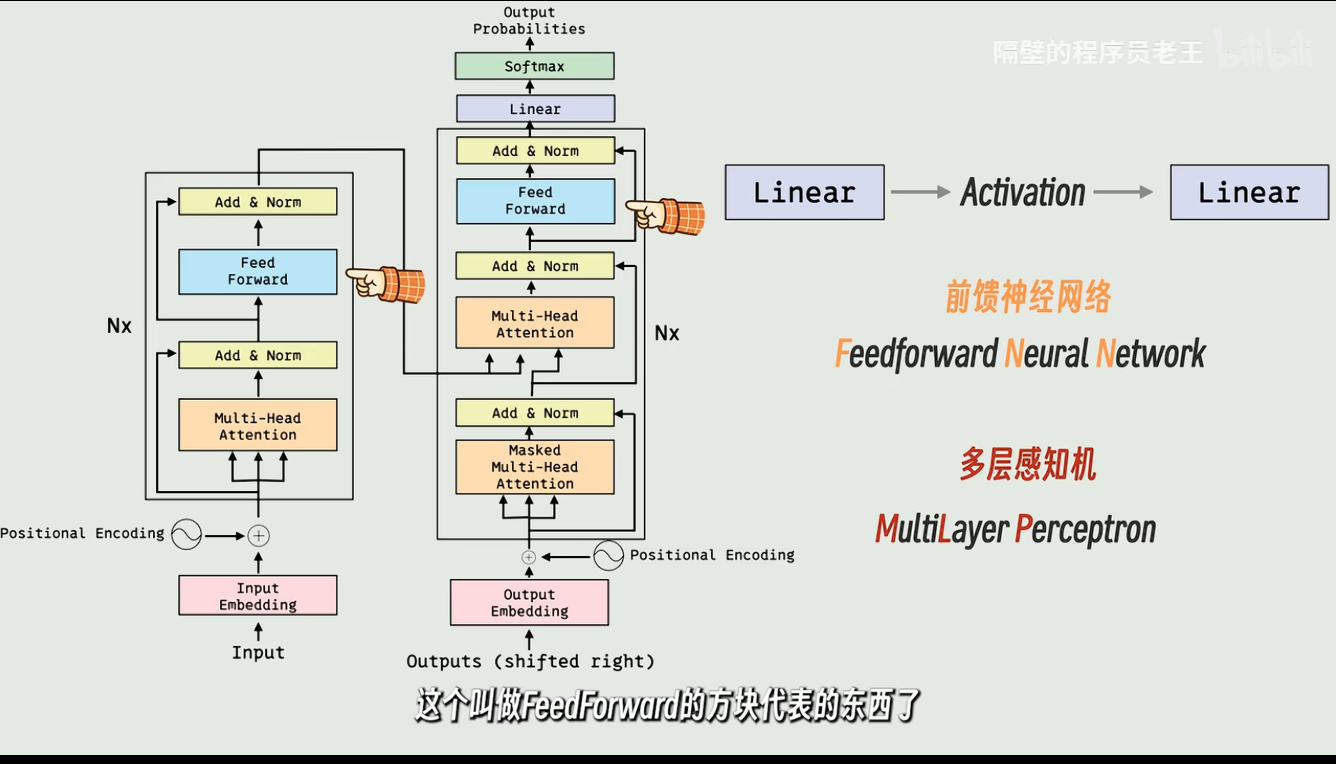
2.结构组建:Transformer是如何跑起来的?
一个典型的Transformer结构可以看作是一个"特征加工流水线":
-
输入层 (Input): 文字变数字(初始 Embedding)+ 给每个字贴上位置标签(Positional Encoding)。
-
编码层 (Encoder):
-
自注意力 (Self-Attention): 通过 Q, K, V 让每个字看清自己在句子里的关系。
-
残差连接与归一化 (Add & Norm): 防止模型层数太深导致信息丢失。
-
前馈网络 (Feed Forward): 进一步对每个词的特征进行非线性变换。
-
-
解码层 (Decoder): 逻辑类似,但多了一个"关注编码器输出"的过程,用于生成下一个词。
3.关键区分:Transformer Embedding vs. RAG Embedding
这是初学者最容易混淆的地方。虽然都叫"嵌入",但它们的**"生存环境"**完全不同:
| 特性 | Transformer 中的 Embedding | RAG 中的 Embedding (Vector DB) |
|---|---|---|
| 位置 | 模型的第一层输入 | 存在外部数据库(如 ChromaDB)中 |
| 生命周期 | 瞬时的,进入模型内部后会被 QKV 反复修改 | 静态的,存入库后通常不再变动 |
| 作用 | 字词的起点。让模型知道"苹果"这个词的基本含义。 | 检索的索引。把整段话压缩成一个点,方便快速对比相似度。 |
| 维度含义 | 捕捉语法、词性、基础语义。 | 捕捉整段话的主题和核心意图。 |
深度对比总结:
-
Transformer 的 Embedding 像是"词典里的解释":它只是一个基础定义。进入 MHA(多头注意力)后,它会根据 QKV 变成"语境中的意思"。
-
RAG 的 Embedding 像是"图书馆的索引号":当你问一个关于"舌诊"的问题时,RAG 会把你的问题转成一个 Embedding,然后去数据库里找那个"索引号"最接近的知识块,塞给模型。
Embedding是什么?
在人工智能和自然语言处理(NLP)领域,Embedding(嵌入) 是将离散的数据(如单词、句子、图像)转换为连续的、多维的向量(Vector/数值列表)的技术。
你可以把它理解为一种"翻译官":它将人类的语言翻译成计算机能够理解、计算的数学语言。
1. 核心概念:为什么要用 Embedding?
计算机无法直接理解"苹果"或"红色"这些词,它只能处理数字。
-
传统做法(One-Hot Encoding): 给每个词分配一个唯一的编号。这种方法的问题是:向量极其稀疏,且无法体现词与词之间的联系(比如,"猫"和"狗"在计算机眼中完全无关)。
-
Embedding 的优势: 它将物体映射到一个高维空间(Embedding Space) 。在这个空间里,语义相似的内容,其向量距离也会更近。
2. 直观理解:语义空间中的距离
想象一个二维平面:
-
"国王"和"王后"的向量位置非常接近。
-
"猫"和"狗"的向量位置也比较接近。
-
"国王"和"冰箱"的距离则非常远。
通过数学运算,甚至可以进行神奇的推理(这是经典的 Embedding 例子):
{向量("国王")} - {向量("男人")} + {向量("女人")} 约等于{向量("王后")}
3. Embedding 的工作原理
Embedding 通常是通过神经网络训练出来的(如 Word2Vec、GloVe,或现在的 Transformer 模型)。
-
输入: 海量的文本数据。
-
训练: 模型通过上下文来预测单词(例如:在一个句子中,"苹果"经常出现在"吃"或"水果"附近)。
-
输出: 每个单词被赋予一串固定长度的数值向量(例如 768 维或 1536 维)。这些数字捕获了单词的语法特征、语义含义和情感色彩。
4. 为什么它对你的研究(RAG 系统)至关重要?
既然你在开发基于 LangChain + ChromaDB 的 RAG(检索增强生成)系统,Embedding 是其中的灵魂:
-
知识库向量化: 当你把 TCM(中医)文档存入 ChromaDB 时,系统会通过 Embedding 模型将文档段落转化为向量。
-
语义检索: 当用户提问时,系统会先将"用户的问题"也转化成向量。然后,在 ChromaDB 中计算"问题向量"与"文档向量"的余弦相似度(Cosine Similarity)。
-
精准匹配: 系统不会死板地匹配关键词,而是匹配含义。即便用户问法不同,只要语义一致,系统就能检索到相关的中医文献。
以下是视频学习笔记:
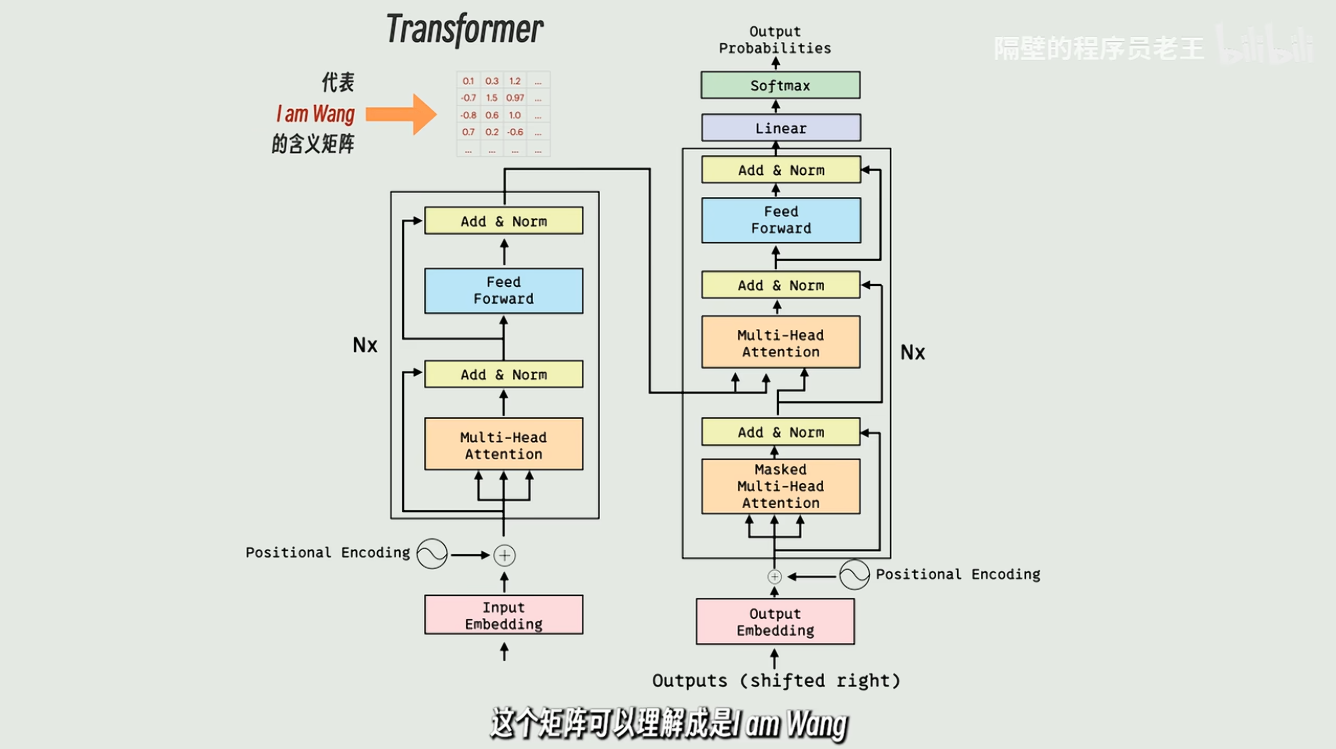
transformer最初做的是文本翻译 例如将"I am Wang"翻译成"我是王"
先将I am Wang输入到左边编码器,输出一个更高阶的数字矩阵表示
所以我们将左边这个过程程序叫做"编码器"Encoder

这里的Nx说明进行了N次相同结构的运算,最终才得到含义矩阵
是相同结构不是相同,因为每次运算的参数是不一样的
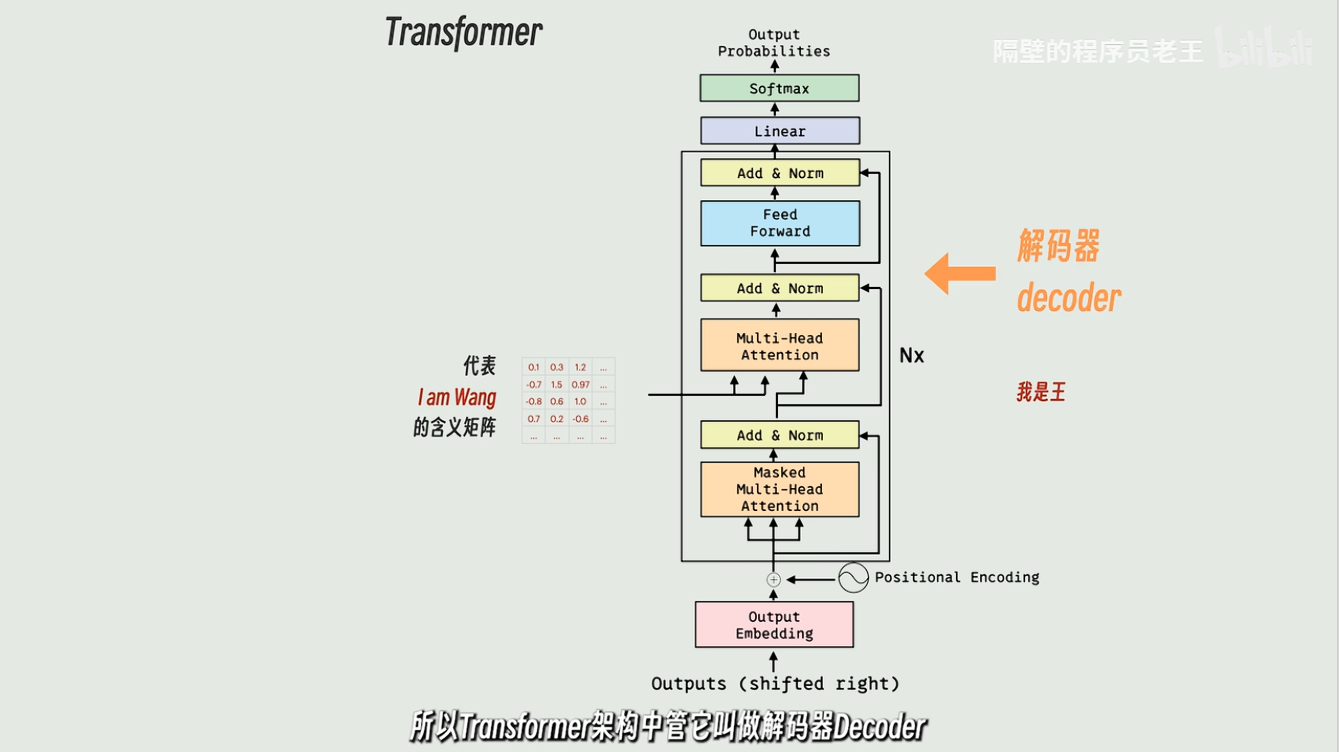
右边这部分就将含义矩阵,转换回人类看得懂的语言
编码器和解码器不太一样
编码器是一下生成整句话的含义矩阵
解码器是一个字一个字的翻译的
解码器有两个输入一个是含义矩阵,另一个是已经翻译好的文本
一开始我们是没有翻译好的文本,我们传入开始标记
最后输出的内容翻译后的第一个词的分布概率!!
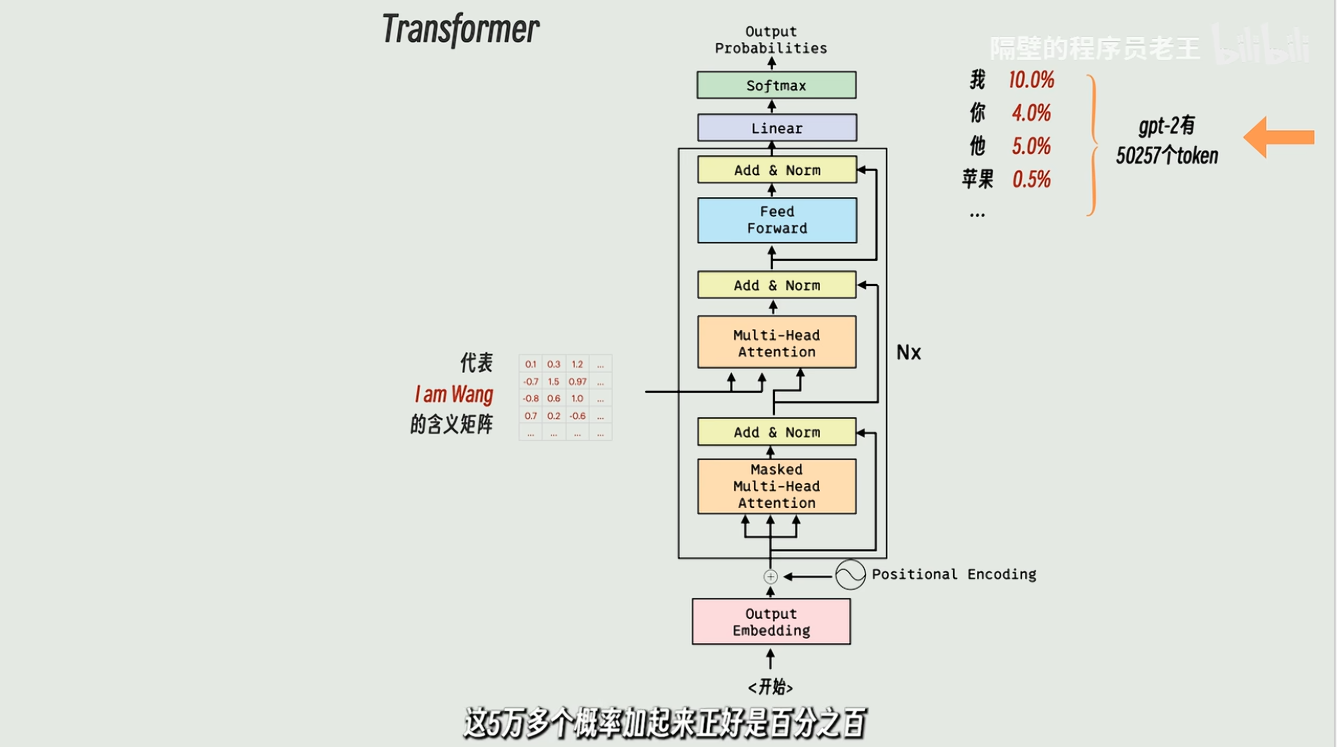
每一个概率就是一个概率,加起来是100%,这个每一个就是一个token!
一个一个词生成token的概率
每次选择高概率的token,最后组成最后的翻译输出"我是王"
输出时每生成一个token都要重新跑一次decoder
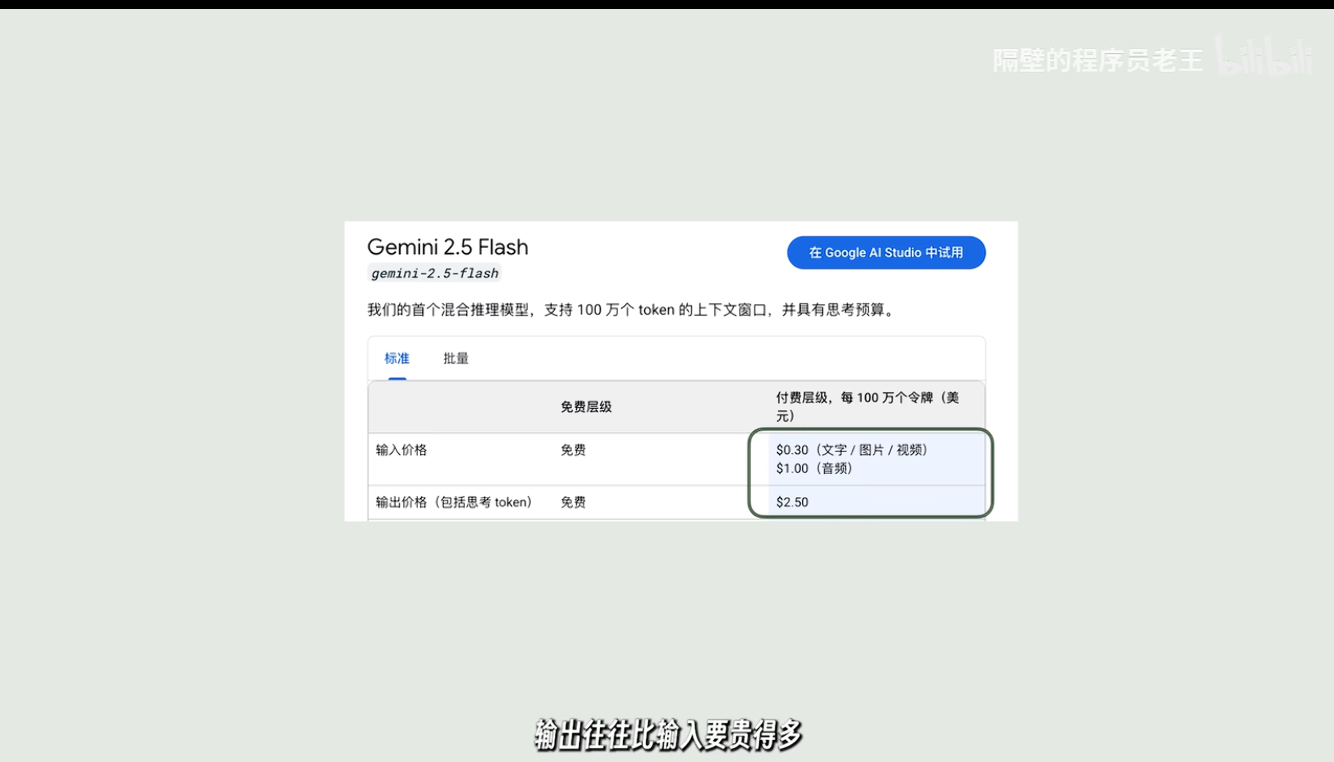
因此大模型api收费时输出比输入贵得多
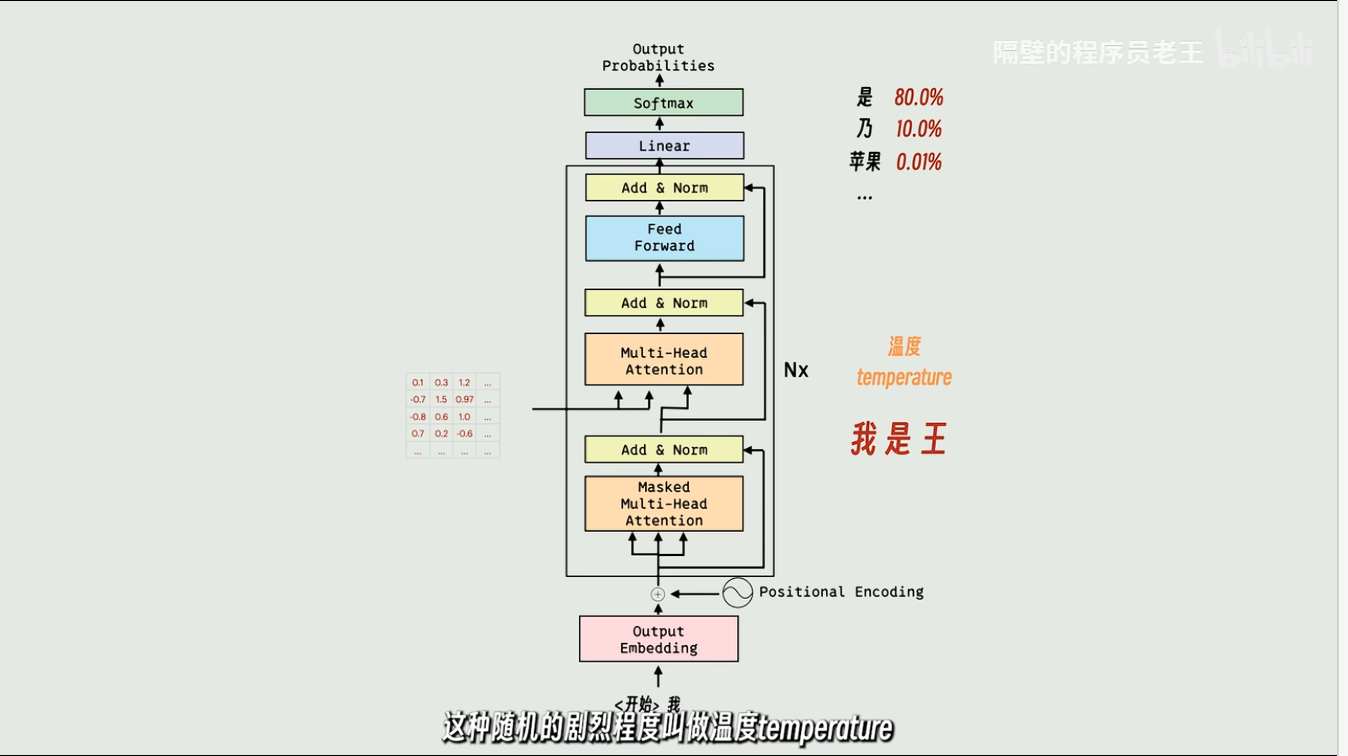
为了增加创造性,我们可以加一个随机的参数,叫做temperture(温度),温度越高随机程度越强,温度为0时,只会输出概率最高的token了。
很多模型的Top-K就是一个参数,就是从前K个概率最高的token中进行选择,等于1就是只选概率最高的。
那是怎么学会这一切的?
答案是训练。
用来翻译的模型训练起来是比较麻烦的,因为要有成对的翻译文本
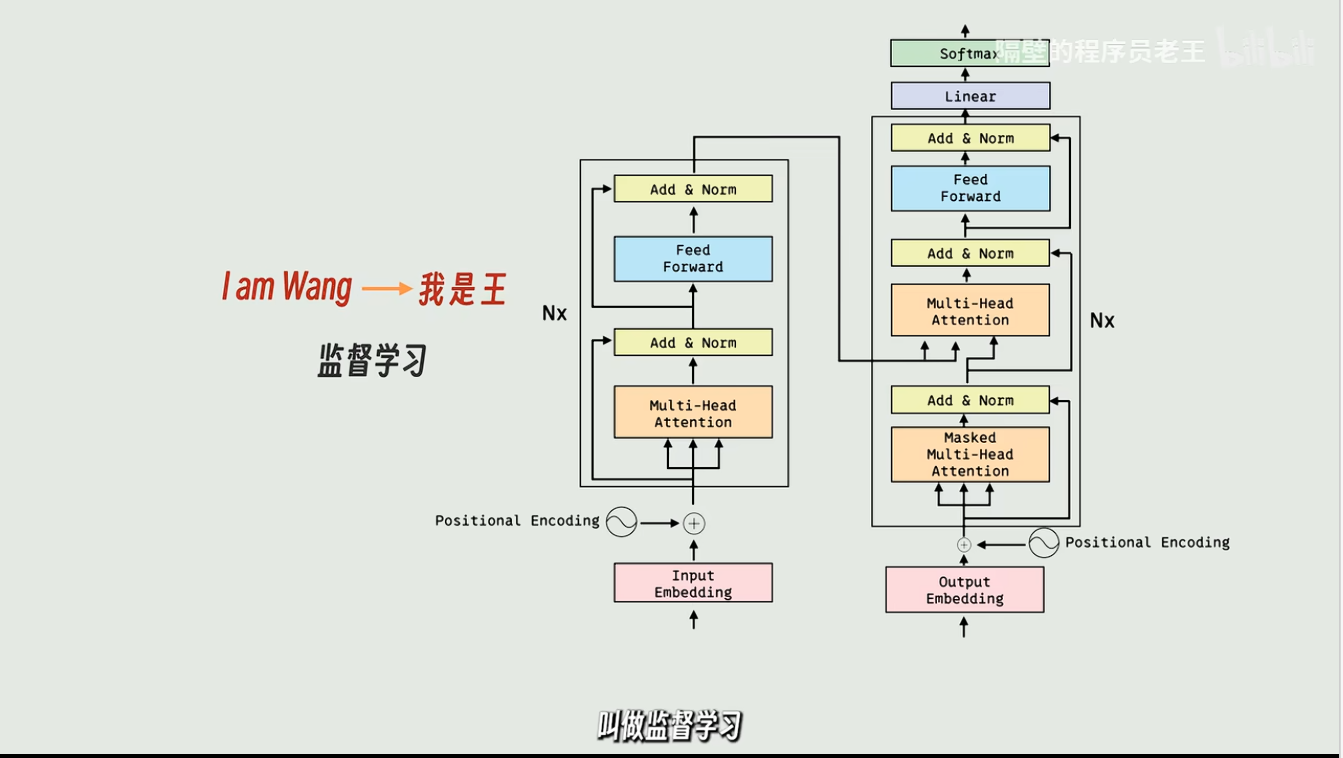
这种同时输入和期望输出的方式叫做"监督学习"
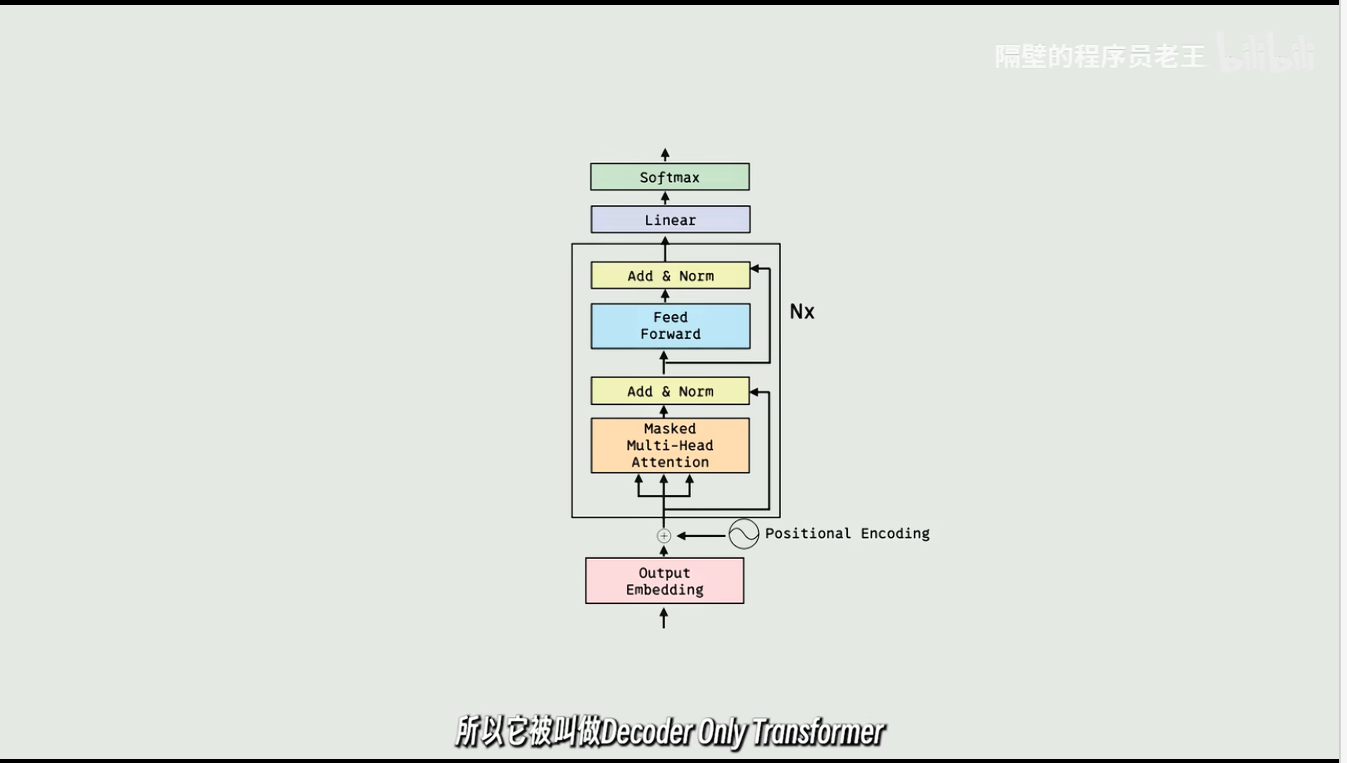
GPT-2的模型结构,特别适合文字接龙,只保留解码器的transformer
绝大多数模型都是这种
可以用任何现成文本进行训练
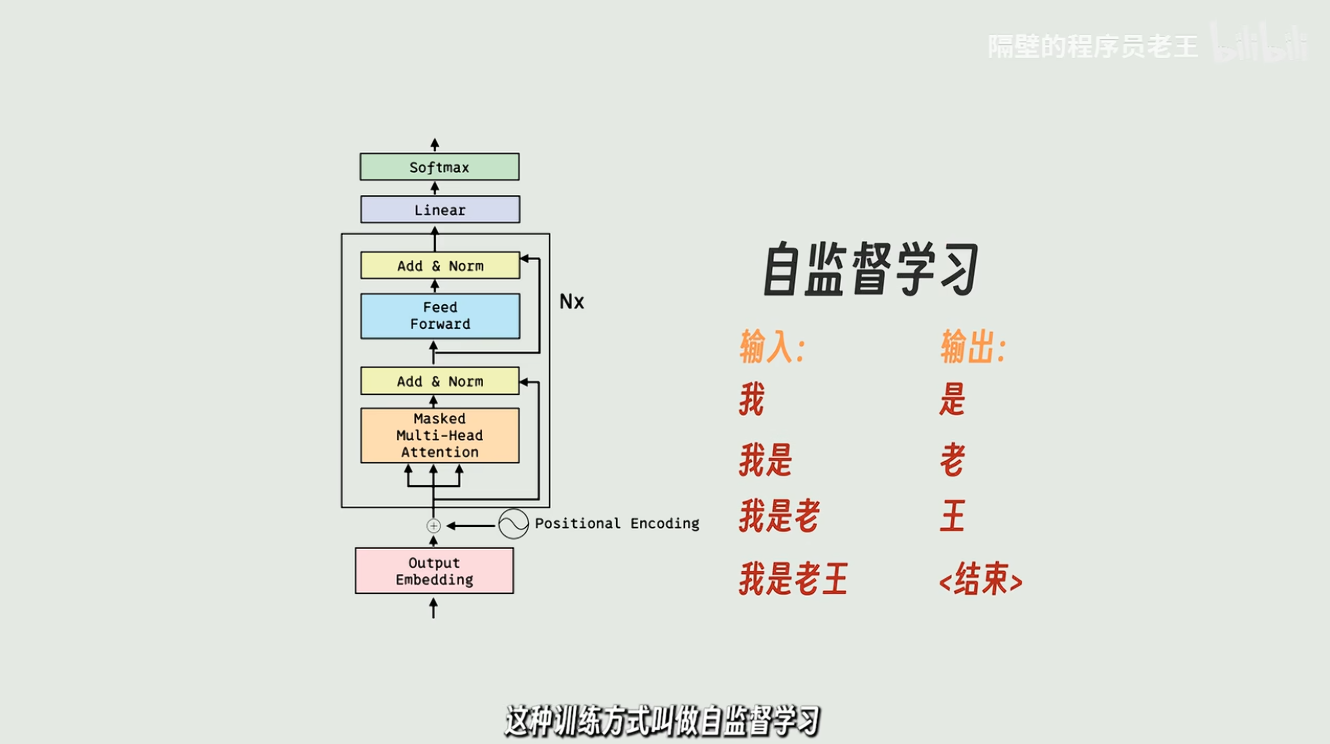
只需提供任意一个有意义的字符串,就可以进行自监督学习
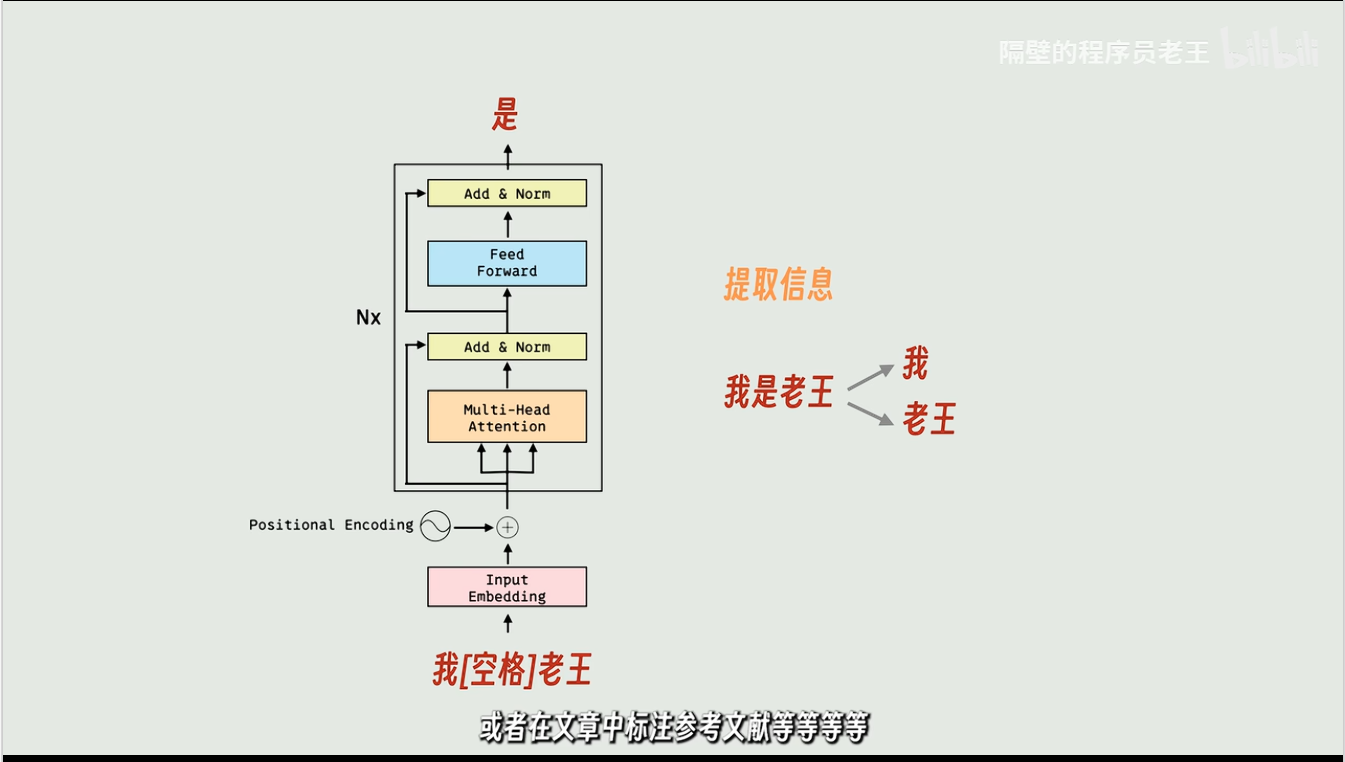
decoder可以用来补全缺失信息
下面是内部原理。
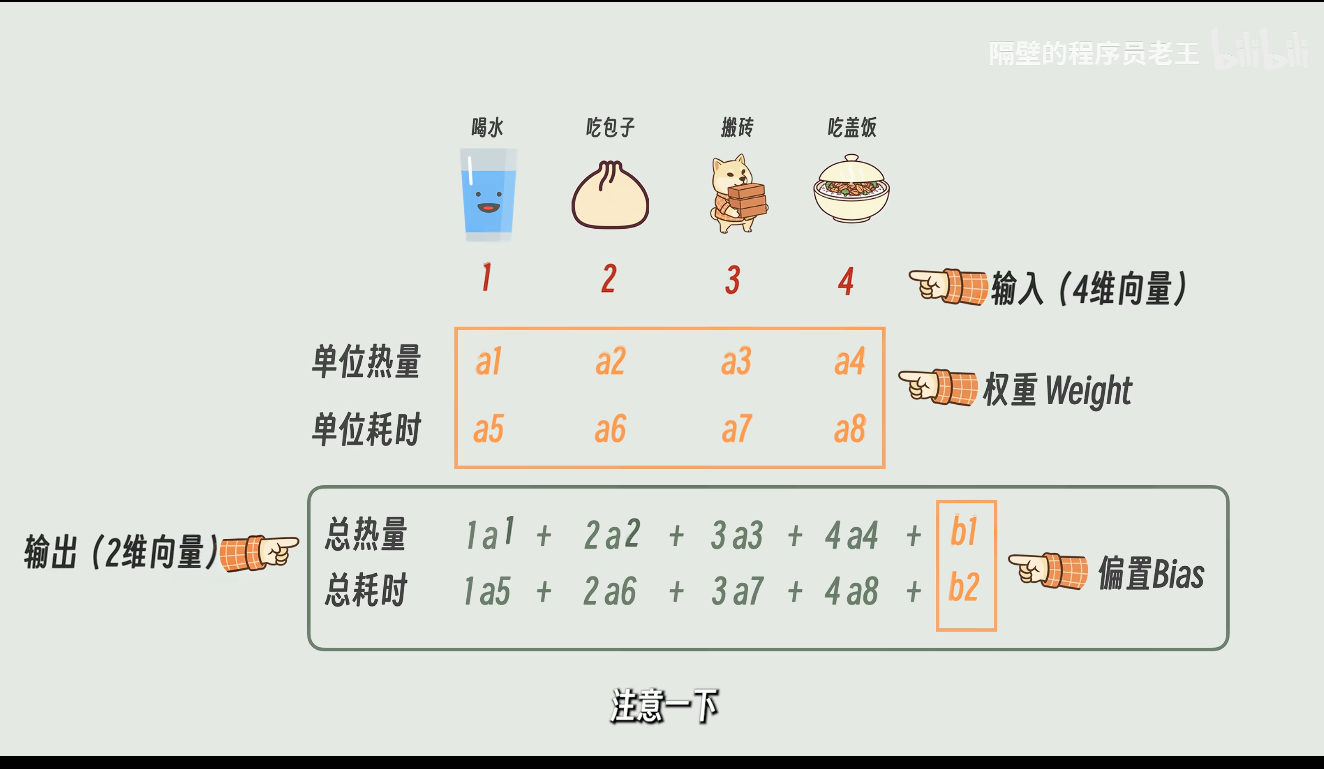
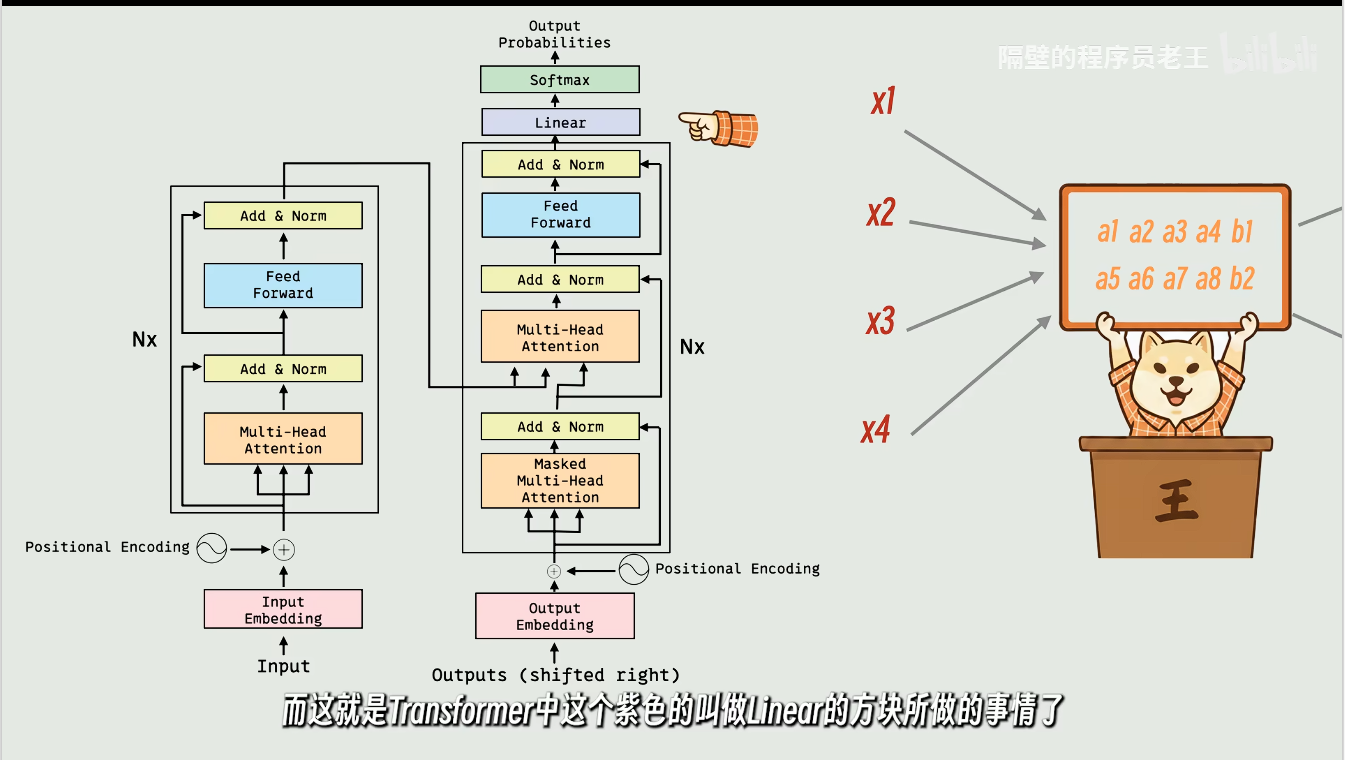
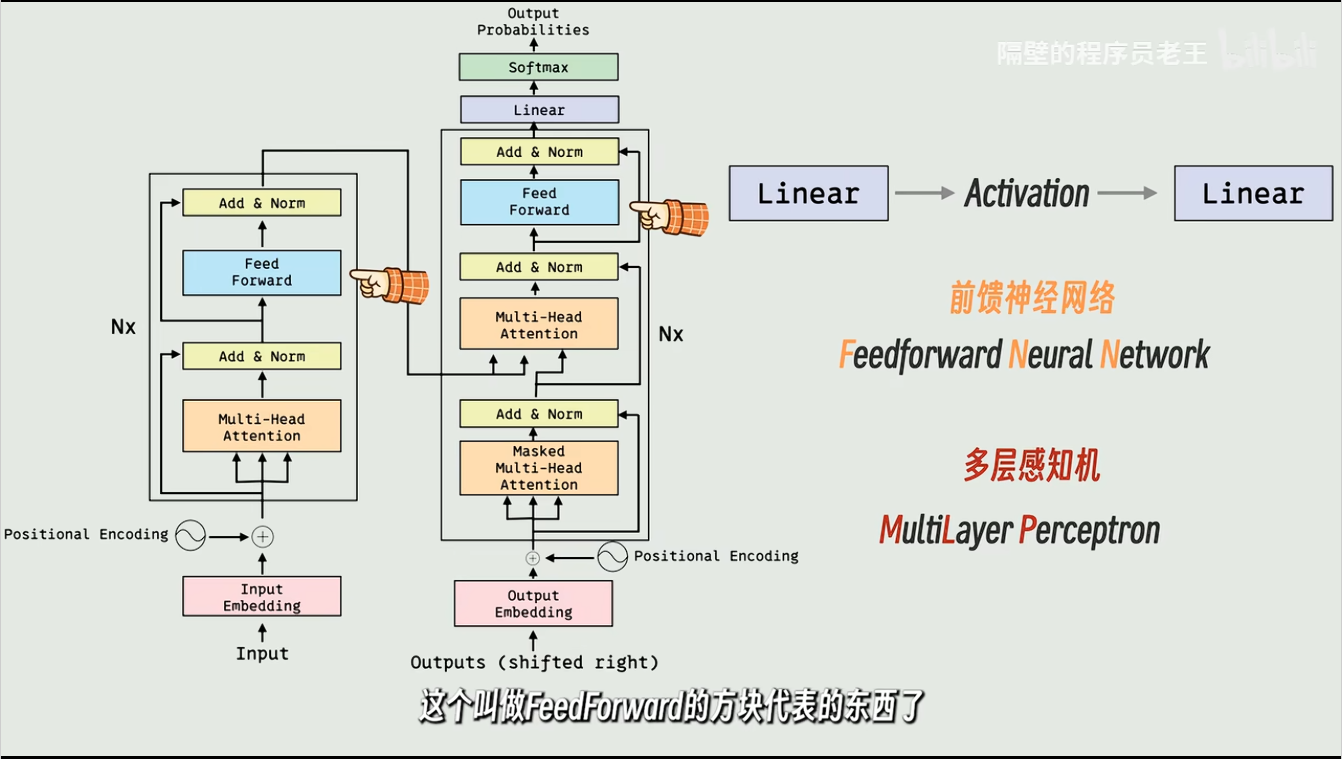
这就是Linear方块做的事情
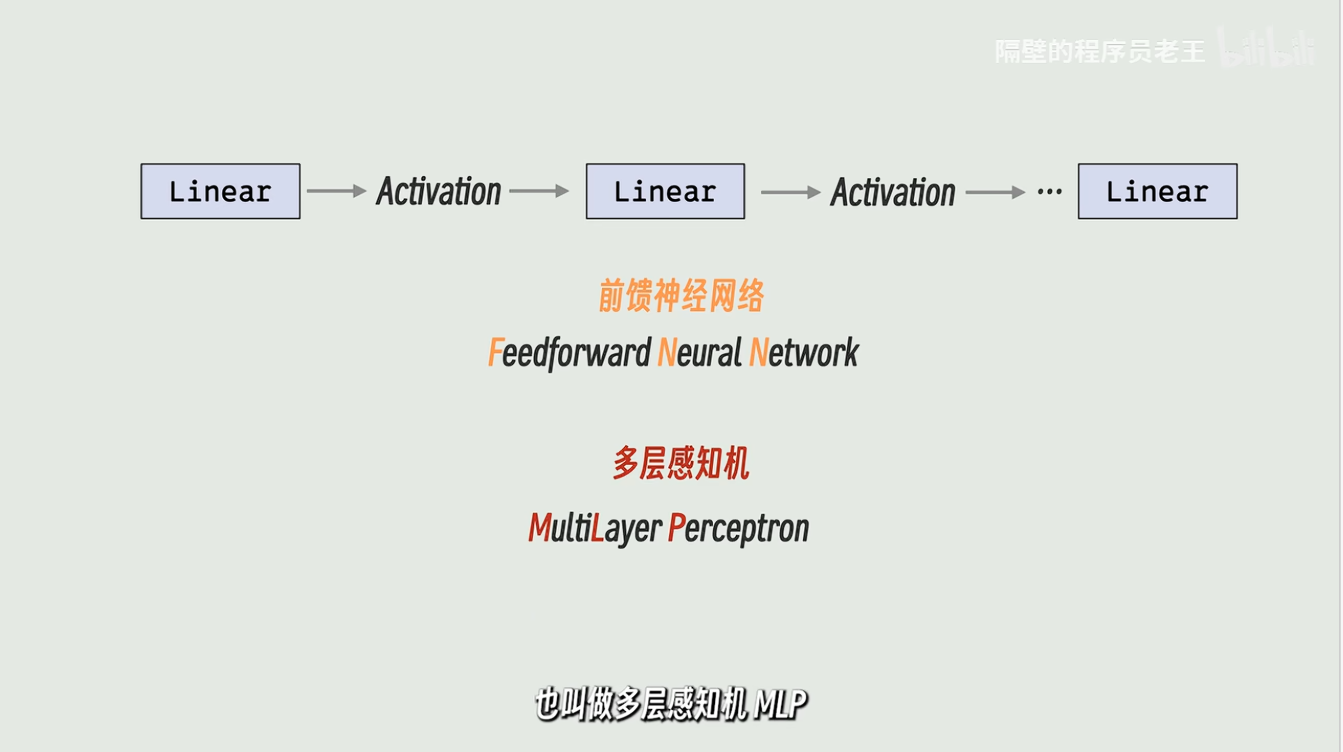
很多线性层加激活函数连接起来再用线性层收尾的,就叫这两个。
Token和Embedding
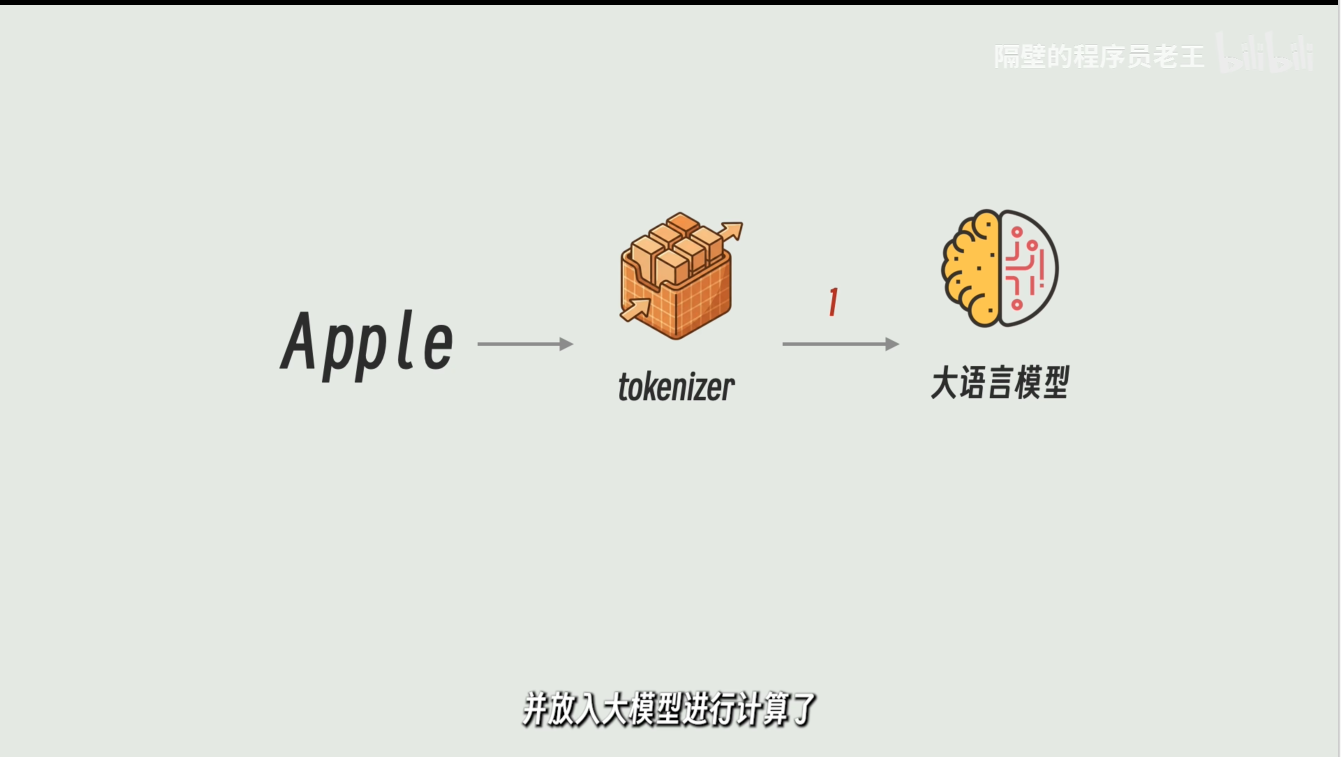
Tokenizer就像一个词典,记录了所有可以适用的Token,这时候就可以放入大模型进行计算了
大模型就是一个大型的连续函数,Token就是输入,输出就是大模型的回复
用多个数字,用多个数字来代表特征
tokenizer里面的数字变成高维的向量,Token就是一串数字了,这就是Embedding,这里面数字的多少就是d_model和n_embd
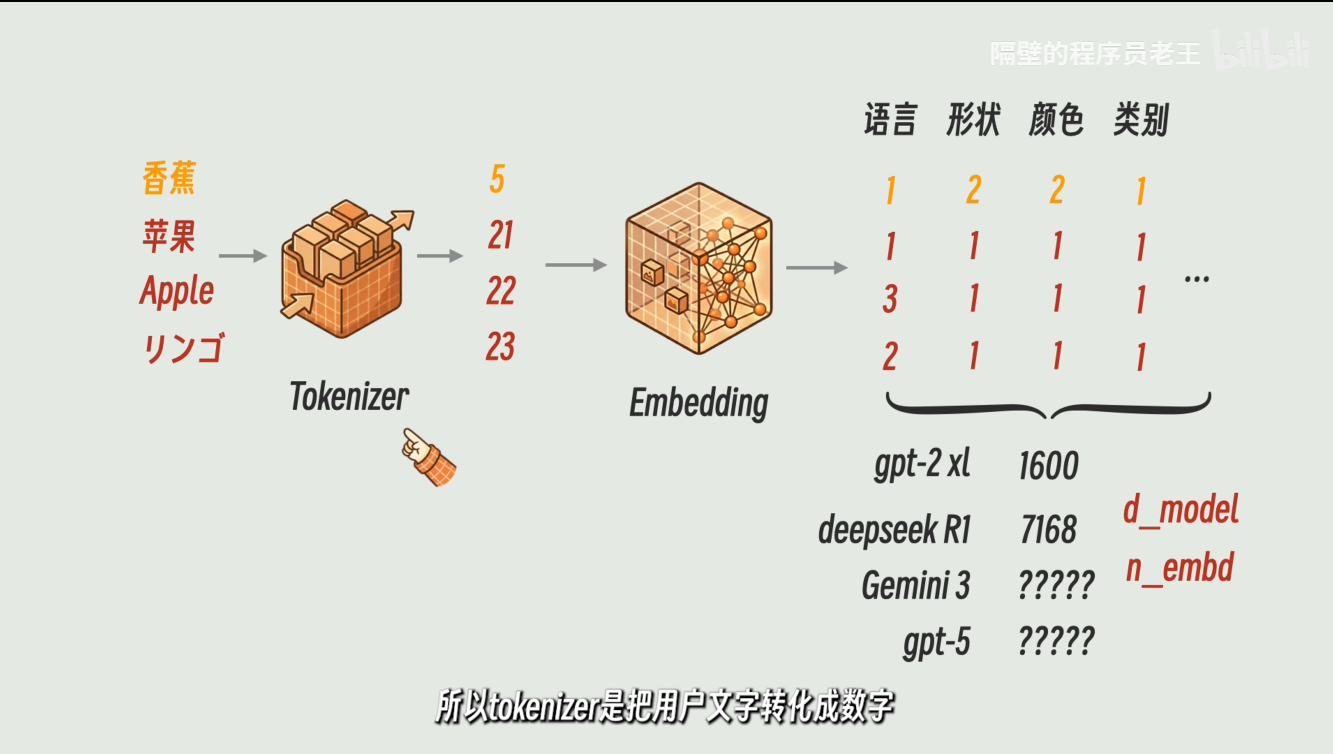
Tokenizer是把用户文字转化为数字,而embedding是把Token转化为向量
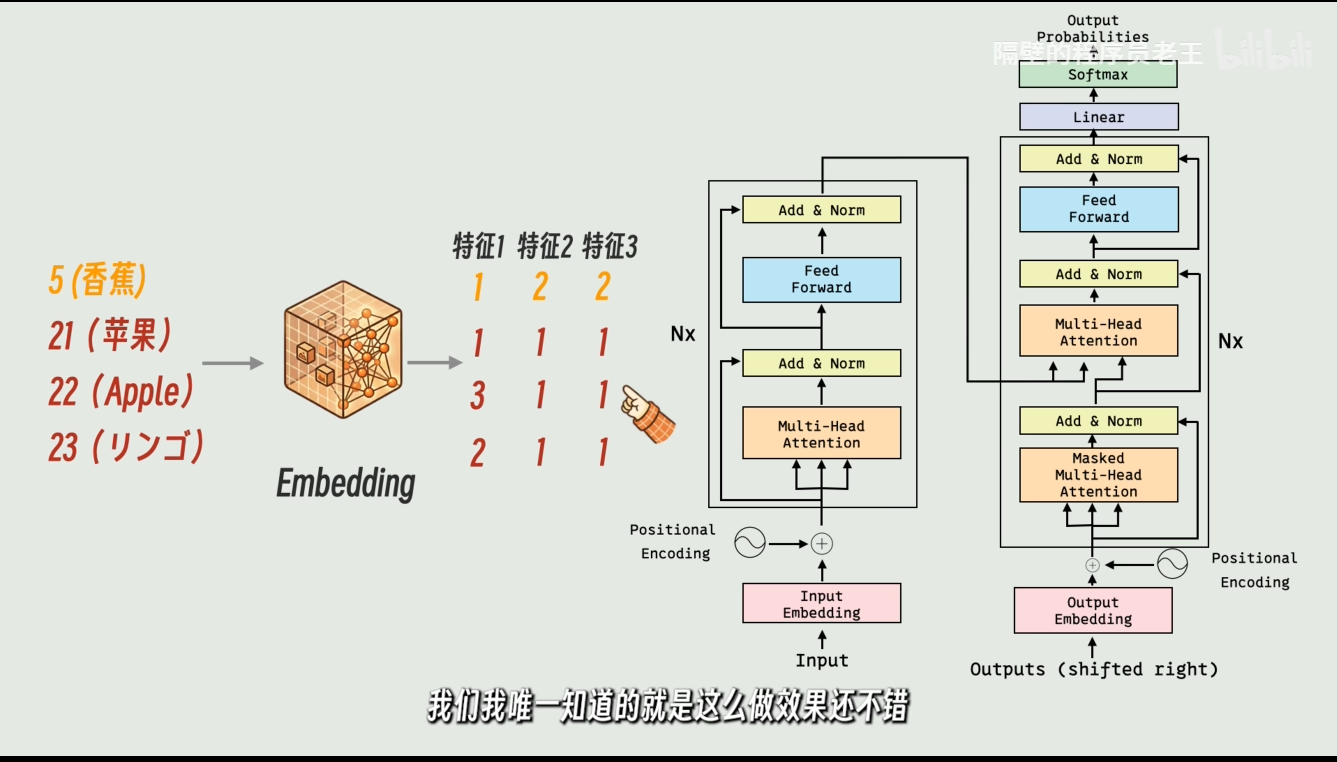
不知道这个数字是什么。这是知道这样搞还不错。


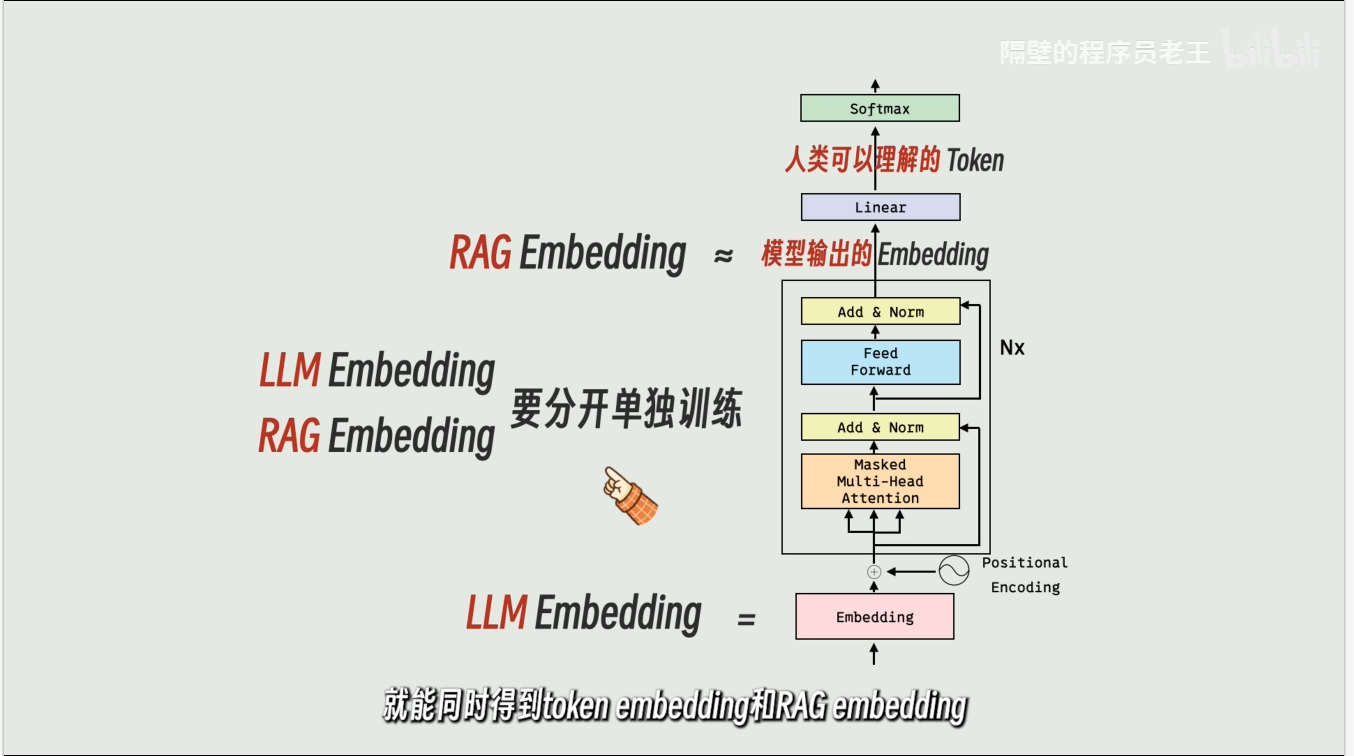
大语言模型最后会将embedding转化回Token
rag embedding也会做后续处理,例如池化
LLM模型训练是文字接龙类似的,而rag模型训练是有类似联想的感觉,类似概括输出。
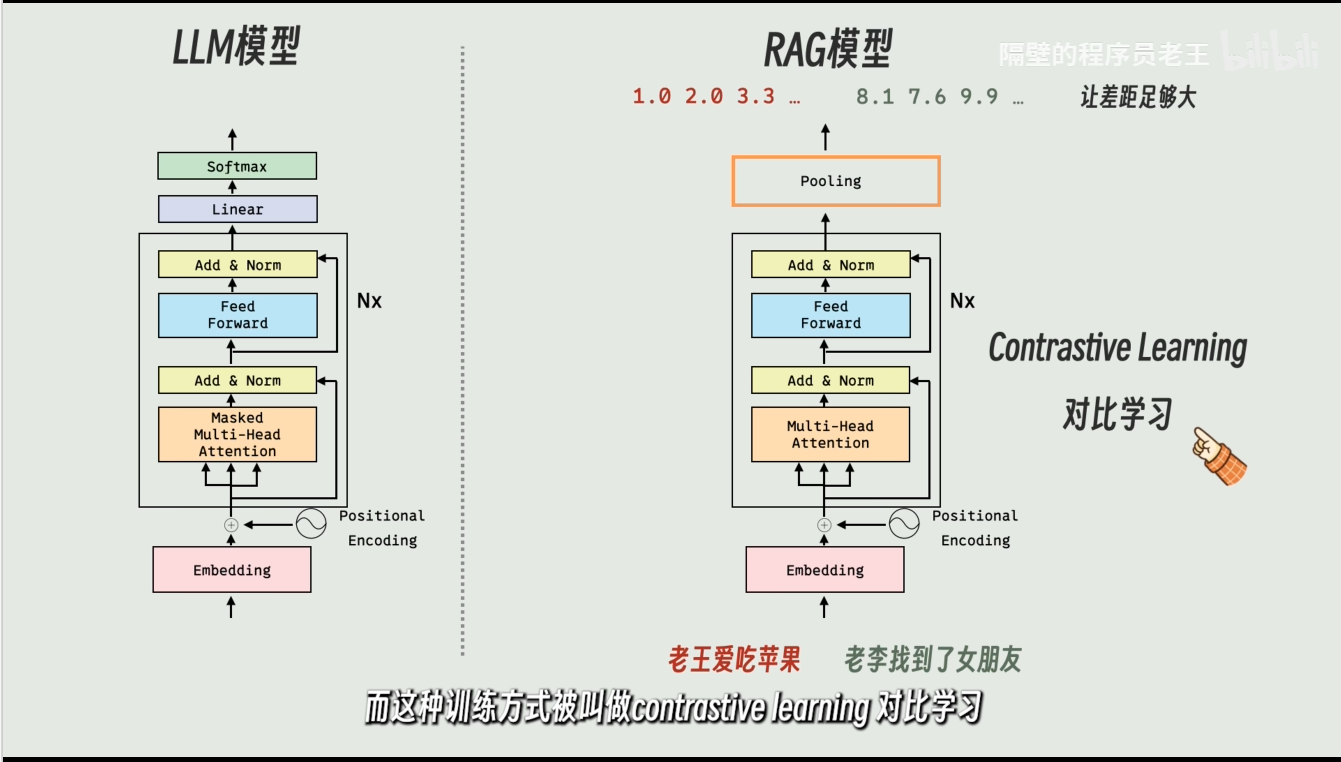
有正样本和负样本,就是对比学习。
to be continue。。。这个老师讲的太好了,推荐大家都去看视频,这是本人的个人笔记。