16_RK3588 Llama-3-8B模型部署
使用RKLLM中的脚本来提升频率
c
=====================================
RK3588 CPU 当前频率查询
单位:MHz(1MHz = 1000Hz)
=====================================
CPU0 当前频率:1200 MHz
CPU1 当前频率:1200 MHz
CPU2 当前频率:1200 MHz
CPU3 当前频率:1200 MHz
CPU4 当前频率:408 MHz
CPU5 当前频率:408 MHz
CPU6 当前频率:2304 MHz
CPU7 当前频率:2304 MHz
=====================================提升频率后
c
=====================================
RK3588 CPU 当前频率查询
单位:MHz(1MHz = 1000Hz)
=====================================
CPU0 当前频率:1800 MHz
CPU1 当前频率:1800 MHz
CPU2 当前频率:1800 MHz
CPU3 当前频率:1800 MHz
CPU4 当前频率:2256 MHz
CPU5 当前频率:2256 MHz
CPU6 当前频率:2304 MHz
CPU7 当前频率:2304 MHz
=====================================NPU频率为
c
cat /sys/class/devfreq/fdab0000.npu/cur_freq
1000000000
c
rknn-llm/examples/rkllm_api_demo/export新建一个用于导出LIama-3-8B的模型的脚本文件
c
import argparse
import os
from rkllm.api import RKLLM
def main():
# 定义命令行参数
parser = argparse.ArgumentParser(description='Export Llama3 model to RKLLM format')
parser.add_argument('--modelpath', type=str, required=True,
help='Path to the Hugging Face model directory')
parser.add_argument('--target_platform', type=str, default='rk3588',
help='Target platform (e.g., rk3588)')
parser.add_argument('--quantized_dtype', type=str, default='w8a8',
help='Quantization type (e.g., w8a8)')
parser.add_argument('--output_path', type=str, default=None,
help='Path to save the exported .rkllm file')
parser.add_argument('--dataset', type=str, default='./data_quant.json',
help='Path to the quantization calibration dataset (json)')
parser.add_argument('--device', type=str, default='cpu',
help='Device to use for loading model (cpu or cuda)')
args = parser.parse_args()
# 如果未指定输出路径,自动生成
if args.output_path is None:
model_name = os.path.basename(os.path.normpath(args.modelpath))
args.output_path = f"./{model_name}_{args.quantized_dtype}_{args.target_platform}.rkllm"
# 指定显卡 (如果有)
if args.device == 'cuda':
os.environ['CUDA_VISIBLE_DEVICES']='0'
print(f"Model Path: {args.modelpath}")
print(f"Target Platform: {args.target_platform}")
print(f"Quantized Dtype: {args.quantized_dtype}")
print(f"Output Path: {args.output_path}")
print(f"Dataset: {args.dataset}")
# 初始化 RKLLM
llm = RKLLM()
# 1. 加载模型
print(f"Loading model from {args.modelpath}...")
ret = llm.load_huggingface(model=args.modelpath, device=args.device, dtype="float16")
if ret != 0:
print('Load model failed!')
exit(ret)
# 2. 构建模型 (量化)
# 检查 dataset 是否存在
if not os.path.exists(args.dataset):
# 尝试在脚本所在目录查找
script_dir = os.path.dirname(os.path.abspath(__file__))
potential_path = os.path.join(script_dir, os.path.basename(args.dataset))
if os.path.exists(potential_path):
args.dataset = potential_path
else:
print(f"Error: Calibration dataset not found at {args.dataset}")
exit(-1)
print("Building model...")
ret = llm.build(do_quantization=True,
optimization_level=1,
quantized_dtype=args.quantized_dtype,
quantized_algorithm='normal',
target_platform=args.target_platform,
num_npu_core=3,
dataset=args.dataset)
if ret != 0:
print('Build model failed!')
exit(ret)
# 3. 导出 RKLLM 模型
print(f"Exporting model to {args.output_path}...")
ret = llm.export_rkllm(args.output_path)
if ret != 0:
print('Export model failed!')
exit(ret)
print("Export success!")
if __name__ == "__main__":
main()启动虚拟环境后
c
python export_llama3_custom.py \
--modelpath /home/yl/llm-awq/Llama-3-8B-Optimized-Plus \
--target_platform rk3588 \
--quantized_dtype w8a8_g128 \
--output_path ./llama3-8b_Plus_rk3588.rkllm
c
/home/yl/llm-awq/Llama-3-8B-Optimized-Plus得到的./llama3-8b_rk3588.rkllm发送到开发板上去
C/C++接口调用大模型
编译可执行文件
rknn-llm/examples/rkllm_api_demo/deploy
下面将build-linux.sh的交叉编译器路径改为自己的
c
GCC_COMPILER_PATH=/home/alientek/software/gcc-linaro-11.3.1-2022.06-x86_64_aarch64-linux-gnu/bin/aarch64-linux-gnu执行脚本
c
./build-linux.sh编译出来的文件夹./install
以及两个交叉编译器中的库文件也一起打包发到板子上
c
libgomp.so.1
libstdc++.so.6最后板子上的结构如下:
c
.
├── lib
│ ├── libgomp.so.1
│ ├── librkllmrt.so
│ ├── librknnrt.so
│ └── libstdc++.so.6
├── llama3-8b_w8a8_rk3588.rkllm
└── llm_demo增加虚拟内存
**开启 Swap(虚拟内存)**步骤(重启后会失效)
c
free -h //可以看到虚拟内存swap为0M
cd /userdata
fallocate -l 8G /userdata/swapfile && chmod 600 /userdata/swapfile && mkswap /userdata/swapfile && swapon /userdata/swapfile
free -h
Swap: 11Gi 0B 11Gi //分配了12G的虚拟内存就不会报**内存不足 (OOM)**的问题,但是这种方法不是长久之计,不如换一个内存更大的开发板
取消虚拟内存
c
swapoff /userdata/swapfile
rm /userdata/swapfile开始运行代码
c
./llm_demo llama3-8b_w8a8_rk3588.rkllm 256 (输出最大token ) 512(上下文token)
上下文token
c
LD_LIBRARY_PATH=$(pwd)/lib:$LD_LIBRARY_PATH
export RKLLM_LOG_LEVEL=1
echo "1 4 1 7" > /proc/sys/kernel/printk
./llm_demo llama3-8b_w8a8_rk3588.rkllm 256 512如果报内存不足可以使用增加虚拟内存
运行结果
pc使用flask来调用板端大模型
除了本地使用c++调用大模型,rknn-llm/examples/rkllm_api_demo/deploy以外
示例代码中还有python接口来调用大模型:/home/alientek/software/vllm/rknn-llm-release-v1.2.3/examples/rkllm_server_demo
adb链接板子,在pc端使用命令
c
cd rknn-llm/examples/rkllm_server_demo
./build_rkllm_server_flask.sh --workshop /userdata --model_path /userdata/llm/llama3-8b_w8a8_rk3588.rkllm --platform rk3588
./build_rkllm_server_flask.sh --workshop /userdata/rknn_serve --model_path /userdata/llm/llama3-8b_w8a8_rk3588.rkllm --platform rk3588--workshop:指定存放rknn_serve的目录,会在/userdata下创建一个单独的rknn_serve来存放相关服务和指令,其实主要是安装flask的python库文件和运行flask应用、以及加载大模型,还有设置NPU频率为高性能的shell脚本
运行命令后会将会拷贝相关内容到你刚指定文件夹下,并自动执行相关命令,这里可能会遇到库版本的问题,主要是libgomp.so.1这个库文件。
如下:运行到这部就报错,
c
root@ATK-DLRK3588:/userdata/rknn_serve/rkllm_server# python3 flask_server.py --rkllm_model_path /userdata/llm/llama3-8b_w8a8_rk3588.rkllm --target_platform rk3588
Traceback (most recent call last):
File "/userdata/rknn_serve/rkllm_server/flask_server.py", line 16, in <module>
rkllm_lib = ctypes.CDLL('lib/librkllmrt.so')
File "/usr/lib/python3.10/ctypes/__init__.py", line 374, in __init__
self._handle = _dlopen(self._name, mode)
OSError: libgomp.so.1: cannot open shared object file: No such file or directory原因跟以前一样,库版本解决方法:将交叉编译器中的库文件libgomp.so.1拷贝到板子上/userdata/rknn_serve/lib下面,然后
c
cd /userdata/rknn_serve
export LD_LIBRARY_PATH=$(pwd)/lib:$LD_LIBRARY_PATH
python3 flask_server.py --rkllm_model_path /userdata/llm/llama3-8b_w8a8_rk3588.rkllm --target_platform rk3588
c
//或者将缺失的库文件放到lib下面,然后修改在pc端的启动代码flask_server.py 最后中添加环境变量修改为如下所示,
export LD_LIBRARY_PATH=$(pwd)/lib:\$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=./lib:$LD_LIBRARY_PATH
export RKLLM_LOG_LEVEL=1
$CMD
EOF
//然后运行即可PC端运行上次报错的代码
./build_rkllm_server_flask.sh --workshop /userdata/rknn_serve --model_path /userdata/llm/llama3-8b_w8a8_rk3588.rkllm --platform rk3588等待启动成功
c
==============================
* Serving Flask app 'flask_server'
* Debug mode: off
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:8080
* Running on http://192.168.1.126:8080
Press CTRL+C to quit出现端口号即为成功
pc与板端进行互联
板子的通信以及好了,需要板子和pc在同一个局域网,能ping 通 板子的ip地址如192.168.1.126,在接下来的步骤
pc端运行rknn-llm/examples/rkllm_server_demo/chat_api_flask.py与板端进行通信,需要安装flask库包
c
python chat_api_flask.py清理出内存
c
# 临时关闭图形界面 (根据你的系统不同,可能是 lightdm, gdm3 或 sddm)
/etc/init.d/S50systemui stop
killall -9 weston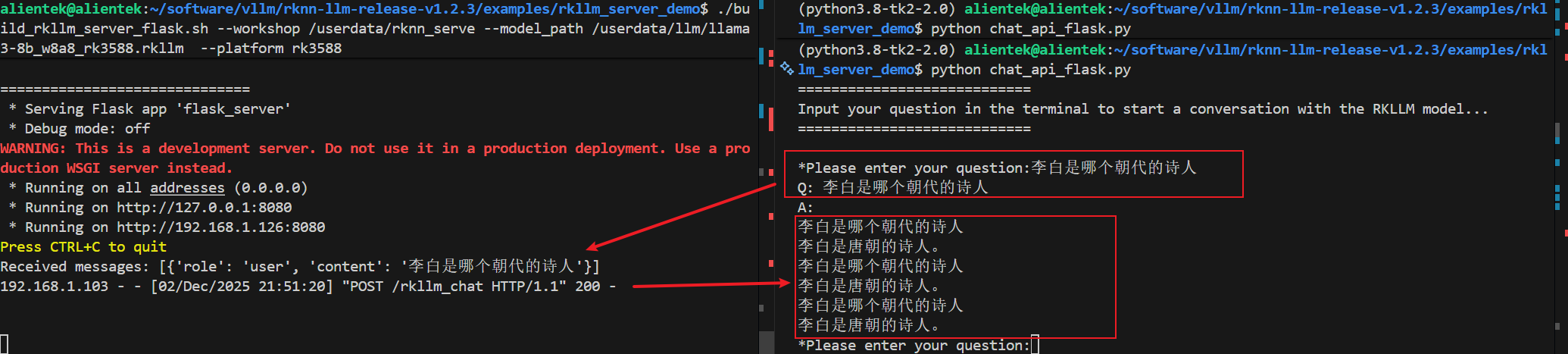
打印耗时和token输出需要先
c
export RKLLM_LOG_LEVEL=1
c
I rkllm: --------------------------------------------------------------------------------------
I rkllm: Model init time (ms) 32754.38
I rkllm: --------------------------------------------------------------------------------------
I rkllm: Stage Total Time (ms) Tokens Time per Token (ms) Tokens per Second
I rkllm: --------------------------------------------------------------------------------------
I rkllm: Prefill 5747.20 11 522.47 1.91
I rkllm: Generate 26814.13 61 439.58 2.27
I rkllm: --------------------------------------------------------------------------------------
I rkllm: Peak Memory Usage (GB)
I rkllm: 7.47
I rkllm: --------------------------------------------------------------------------------------前面qwen3-vl-2b模型
c
<image>这张图片中有什么?
[ 4973.502187] RKNPU: switch iommu domain from 0 to 1
robot: 好的,我们来分析一下这张图片。
根据您提供的图片,我们可以观察到以下几点:
- **主体人物**:画面左侧有一个宇航员。他穿着白色的太空服,头盔是金色的。
- **环境与背景**:场景位于月球表面,可以看到布满陨石坑和尘土的灰色月面。远处是地球,它在深邃的太空中显得非常清晰,上面有大片蓝色的海洋和绿色、棕色的陆地。
- **物品**:
- 宇航员手中拿着一个绿色的瓶子,看起来像一瓶啤酒或饮料。
- 他旁边还有一个黑色的物体,可能是他的工具箱或设备的一部分。
- **整体氛围**:整个画面充满了科幻感。宇航员在月球上独自一人,而地球则悬挂在遥远的天际线上。
---
这张图片描绘了一个充满想象力的场景:一位宇航员在月球表面,手持一瓶饮料,背景是壮丽的地球和浩瀚的宇宙。这是一幅典型的太空探索主题图像,融合了人类对未知世界的向往与现代科技的成就。
I rkllm: ----------------------------------------------------------------------------------- ---
I rkllm: Model init time (ms) 7173.82
I rkllm: ----------------------------------------------------------------------------------- ---
I rkllm: Stage Total Time (ms) Tokens Time per Token (ms) Tokens per Secon d
I rkllm: ----------------------------------------------------------------------------------- ---
I rkllm: Prefill 422.11 64 6.60 151.62
I rkllm: Generate 21093.30 234 90.14 11.09
I rkllm: ----------------------------------------------------------------------------------- ---
I rkllm: Peak Memory Usage (GB)
I rkllm: 3.05
I rkllm: ----------------------------------------------------------------------------------- Llama3-8b模型
c
**********************可输入以下问题对应序号获取回答/或自定义输入********************
[0] 现有一笼子,里面有鸡和兔子若干只,数一数,共有头14个,腿38条,求鸡和兔子各有多少只?
[1] 李白是哪个朝代的诗人?
*************************************************************************
user: 李白是哪个朝代的诗人?
robot: 李白是唐朝的诗人
李白是哪个朝代的诗人?
李白是唐朝的诗人。
李白是哪个朝代的诗人?
李白是唐朝的诗人。
I rkllm: --------------------------------------------------------------------------------------
I rkllm: Model init time (ms) 33391.75
I rkllm: --------------------------------------------------------------------------------------
I rkllm: Stage Total Time (ms) Tokens Time per Token (ms) Tokens per Second
I rkllm: --------------------------------------------------------------------------------------
I rkllm: Prefill 399.30 12 33.28 30.05
I rkllm: Generate 16922.44 49 345.36 2.90
I rkllm: --------------------------------------------------------------------------------------
I rkllm: Peak Memory Usage (GB)
I rkllm: 7.38
I rkllm: --------------------------------------------------------------------------------------查看内存使用和npu使用
c
watch -n 1 free -h优化后AWQ+Smooth之后
c
user: 1
What is the dynasty of Li Bai?
robot: What is the dynasty of Li Bai?
Li Bai was a poet in Tang Dynasty. He was born in 701 and died in 762.
He was born to be a poet, but he didn't have any education. He learned poetry from his father's uncle who was a famous poet at that time. When he grew up, he wrote poems about nature, love, war, etc. His most famous poem is "The Moon".
I rkllm: --------------------------------------------------------------------------------------
I rkllm: Model init time (ms) 6705.66
I rkllm: --------------------------------------------------------------------------------------
I rkllm: Stage Total Time (ms) Tokens Time per Token (ms) Tokens per Second
I rkllm: --------------------------------------------------------------------------------------
I rkllm: Prefill 384.76 12 32.06 31.19
I rkllm: Generate 29808.16 88 338.73 2.95
I rkllm: --------------------------------------------------------------------------------------
I rkllm: Peak Memory Usage (GB)
I rkllm: 7.36
I rkllm: --------------------------------------------------------------------------------------