推荐直接网站在线阅读:aicoting.cn
在训练神经网络的过程中,我们经常遇到一个让人头疼的问题:训练集上精度高得离谱,测试集却一塌糊涂。
这就是过拟合(Overfitting)。模型在训练集上死记硬背了样本,却没有真正学到可泛化的规律。
要解决这个问题,除了多加数据、做数据增强之外,另一个关键武器就是------正则化(Regularization)。
所有相关文档、源码示例、流程图与面试八股,我也将持续更新在AIHub,欢迎关注收藏!
1. 正则化的目的
一句话总结就是正则化的目标是让模型学得简单一点。
在深度学习中,模型通常拥有成千上万个参数,如果不加约束,它会努力去拟合训练集中的每一个小细节,甚至连噪声都不放过。
正则化通过在损失函数中增加一个惩罚项(Penalty Term),让模型在追求拟合能力的同时,也要为复杂性付出代价。
这种代价的形式可以是参数的大小、变化的平滑程度、网络的稀疏性,甚至结构本身的约束。
形式上,我们通常在原始损失函数  中加入一个正则项
中加入一个正则项  :
:
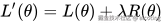
其中:
- :原始损失(比如交叉熵)
- :正则项(约束模型复杂度)
 :权衡系数,决定惩罚强度
:权衡系数,决定惩罚强度
2. 常见的正则化方法
2.1 L1 正则化(Lasso)
L1 正则化的形式是:
它鼓励参数接近 0,从而让模型变得稀疏。
它鼓励参数接近 0,从而让模型变得稀疏。
也就是说,很多不重要的权重会被压成 0,达到特征选择的效果。
L1 正则化适用于希望模型自动筛选特征的场景,比如高维线性回归。
在 PyTorch 中可以直接写为:
scss
loss = loss_fn(output, target)
l1_reg = torch.tensor(0.)
for param in model.parameters():
l1_reg += torch.sum(torch.abs(param))
loss += 1e-5 * l1_reg2.2 L2 正则化(Ridge)
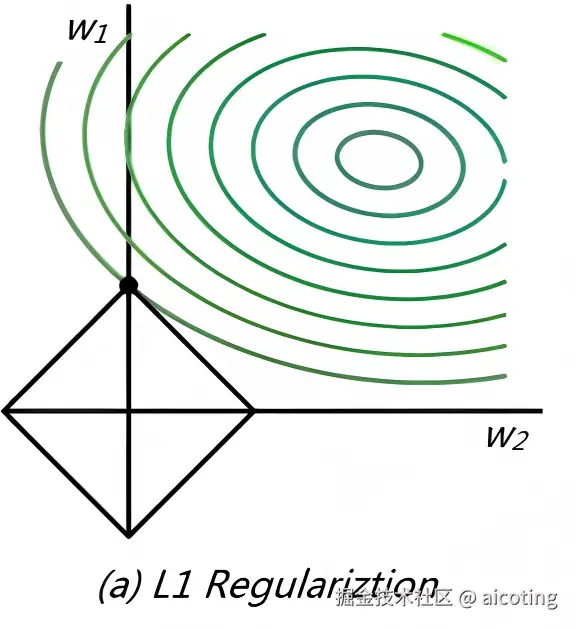
L2 正则化更常见,它的形式是:

L2 会惩罚大的权重值,让所有参数都趋向于较小的范围。它不会让参数直接变成 0,而是整体缩小参数分布。
这有助于提高模型的稳定性;防止梯度爆炸;让模型更平滑。
几乎所有优化器(如 AdamW)都内置了 L2 权重衰减机制(weight decay)。
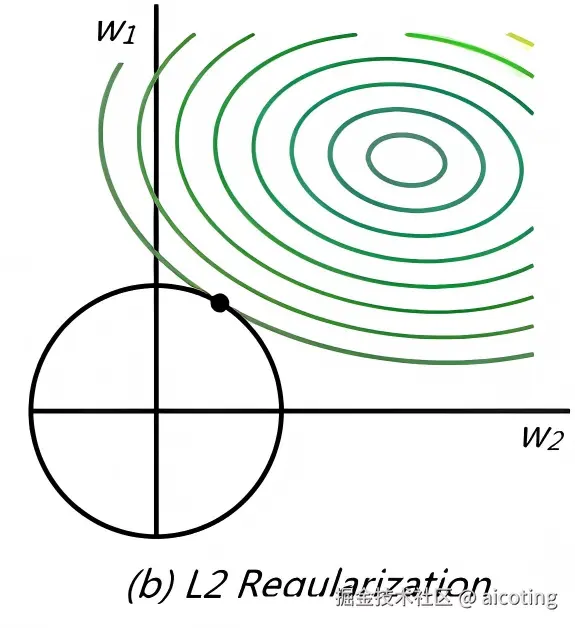
2.3 Dropout
Dropout 可以看作是一种结构上的正则化。
在训练过程中,它会随机地把部分神经元丢弃(设为 0),相当于让网络在每次迭代中训练不同的子网络:
ini
nn.Dropout(p=0.5)
这样做的效果是:
- 防止神经元之间过度协同;
- 提升模型的泛化能力;
- 类似于集成学习思想(每次都是不同子模型)。
在推理阶段(eval 模式)会自动关闭 Dropout,使用所有神经元参与预测。
2.4 Batch Normalization / Layer Normalization
BN(批归一化)和 LN(层归一化)虽然本质是标准化操作,但它们也具备一定的正则化效果。
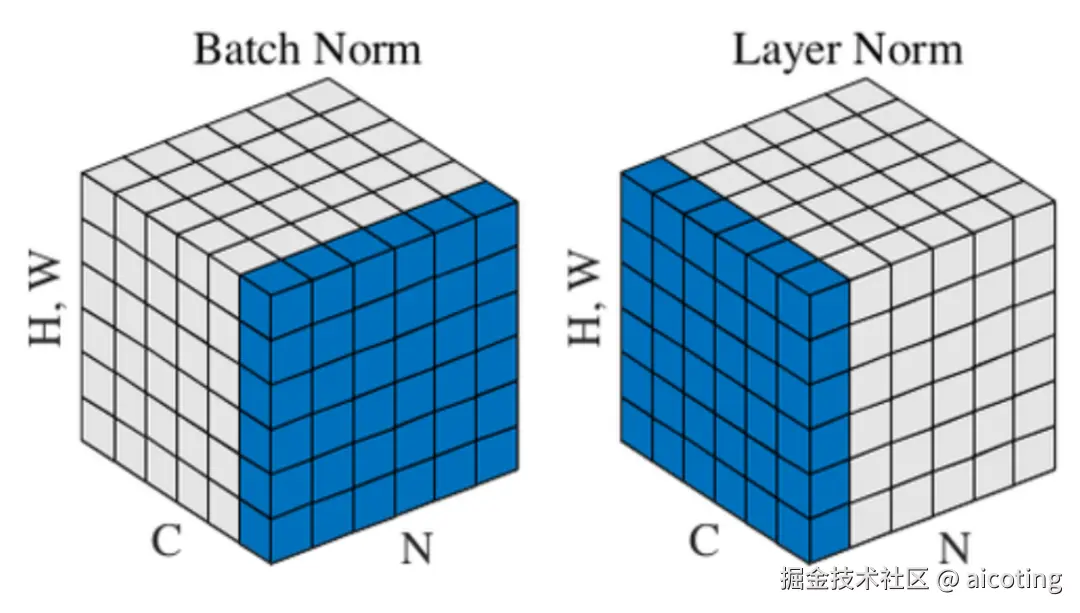
原因是它们在训练中引入了随机性(比如 mini-batch 的统计波动),相当于一种轻量的扰动,能抑制模型过拟合。
2.5 数据增强(Data Augmentation)
严格来说,这不是对参数的正则化,而是对数据的隐式正则化。
通过对输入样本进行随机变换(旋转、裁剪、翻转、加噪声等),模型被迫学习对多样化样本的鲁棒表示,从而降低过拟合风险。
比如图像任务常见的:
scss
transforms.RandomHorizontalFlip()
transforms.ColorJitter()
transforms.RandomResizedCrop()
2.6 Early Stopping
另一个非常实用的技巧。
如果你发现训练集 loss 还在下降,而验证集 loss 开始上升,说明模型开始过拟合 ------ 此时应该立刻停止训练。
在 PyTorch 中可以通过手动监控验证集损失实现,也可以封装在训练循环中:
kotlin
if val_loss > best_val_loss:
patience_counter += 1
if patience_counter > patience:
break从优化角度看正则化的话,正则化其实就是给优化器加上约束。它让梯度下降不再单纯追求损失最小,而是同时考虑模型的简洁性。
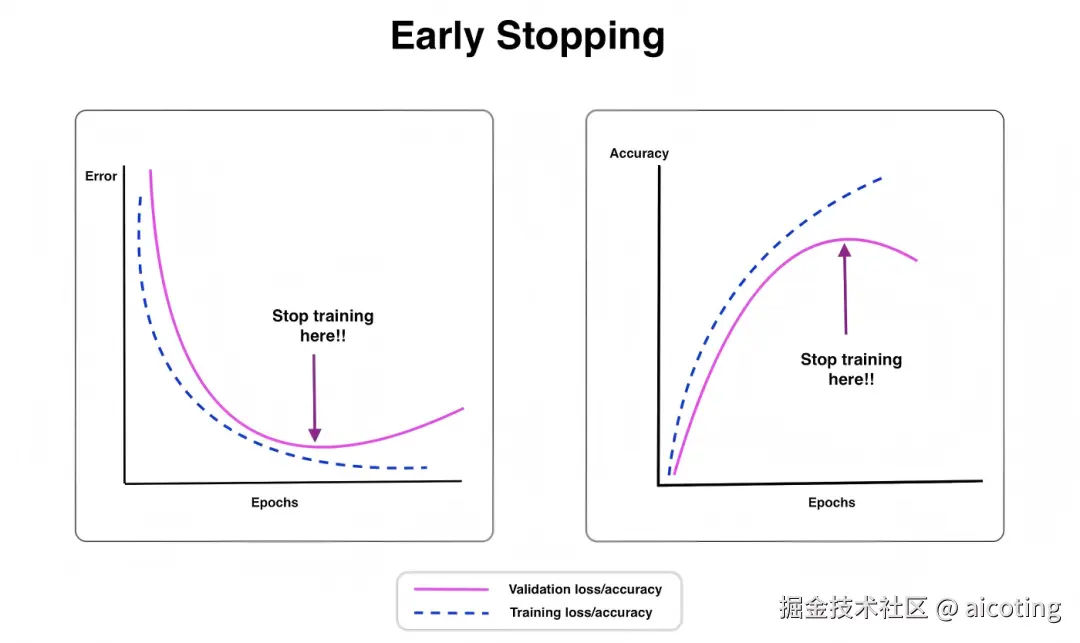
没有正则化时,优化器只管快速到达最低点;有了正则化后,优化器会更倾向于平滑而稳健的谷底,而不是陡峭的深坑。
这就解释了为什么加了正则化的模型,在验证集上表现更好。
📚推荐阅读
最新的文章都在公众号aicoting更新,别忘记关注哦!!!
作者:aicoting
分享是一种信仰,连接让成长更有温度。
我们下次不见不散!