🌈个人主页: 秦jh__https://blog.csdn.net/qinjh_?spm=1010.2135.3001.5343
🔥 系列专栏: https://blog.csdn.net/qinjh_/category_13079918.html

目录
[Set 集合](#Set 集合)
[Zset 有序集合](#Zset 有序集合)
前言
💬 hello! 各位铁子们大家好哇。
今日更新了Redis相关内容
🎉 欢迎大家关注🔍点赞👍收藏⭐️留言📝
Set 集合
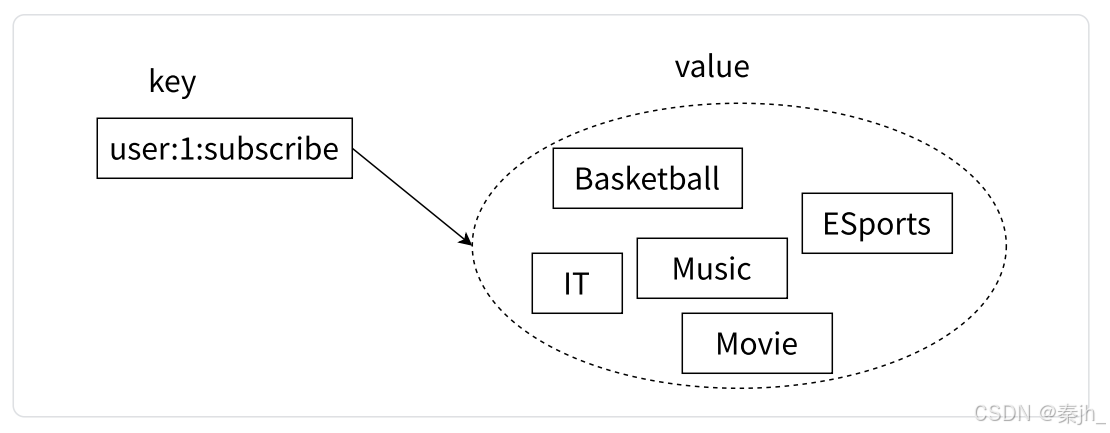
集合类型也是保存多个字符串类型的元素的,但和列表类型不同的是,集合中 1)元素之间是无序 的 2)元素不允许重复,如下图。一个集合中最多可以存储 2^32-1个元素。Redis 除了支持 集合内的增删查改操作,同时还支持多个集合取交集、并集、差集,合理地使用好集合类型,能在实 际开发中解决很多问题。
普通命令
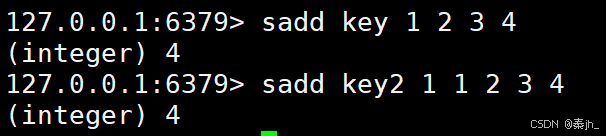
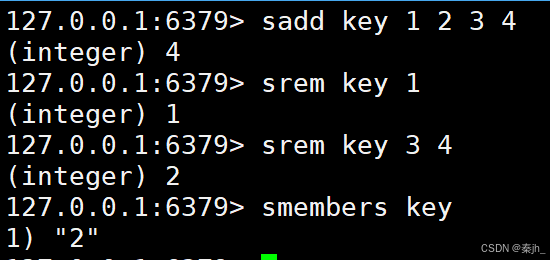
SADD
将一个或者多个元素添加到 set 中。注意,重复的元素无法添加到 set 中。
语法:
SADD key member member ...
返回值:本次添加成功的元素个数。
示例:
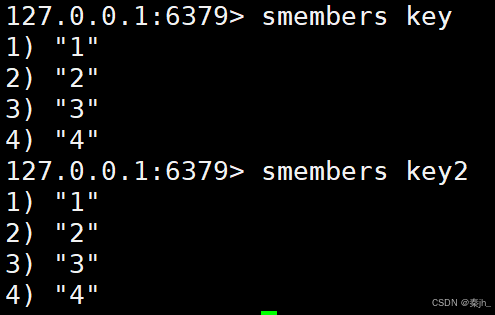
SMEMBERS
获取一个 set 中的所有元素,注意,元素间的顺序是无序的。
语法:
SMEMBERS key
返回值:所有元素的列表。
示例:
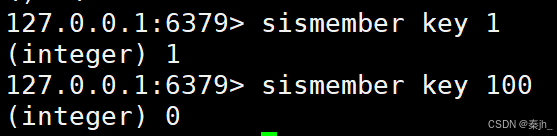
SISMEMBER
判断一个元素在不在 set 中。
语法:
SISMEMBER key member
返回值:1 表示元素在 set 中。0 表示元素不在 set 中或者 key 不存在。
示例:
SCARD
获取一个 set 的基数(cardinality),即 set 中的元素个数。
语法:
SCARD key
返回值:set 内的元素个数。
示例:
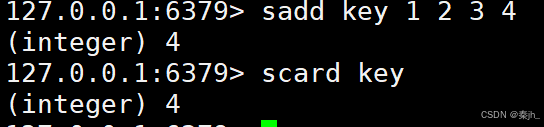
SPOP
从 set 中删除并返回一个或者多个元素。注意,由于 set 内的元素是无序的,所以取出哪个元素实际是 未定义行为,即可以看作随机的。
语法:
SPOP key count
count:删除的个数,不写默认是1
返回值:取出的元素。
示例:
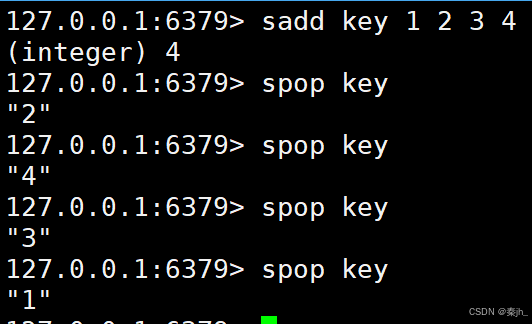
srandmember
随机获取值
语法:
srandmember key count
示例:
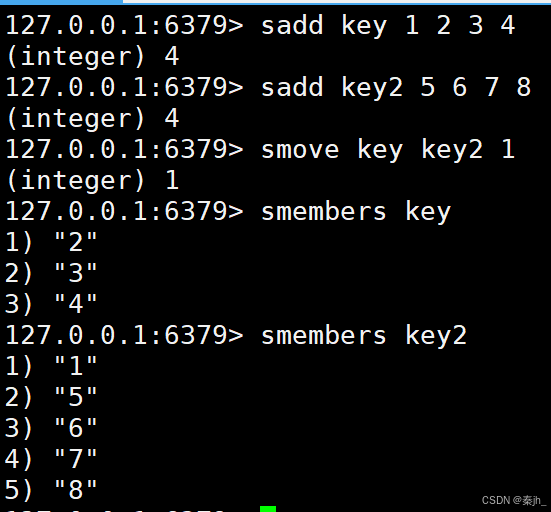
SMOVE
将一个元素从源 set 取出并放入目标 set 中。
语法:
SMOVE source destination member
返回值:1 表示移动成功,0 表示失败。
示例:
SREM
将指定的元素从 set 中删除。
语法:
SREM key member member ...
返回值:本次操作删除的元素个数。
示例:
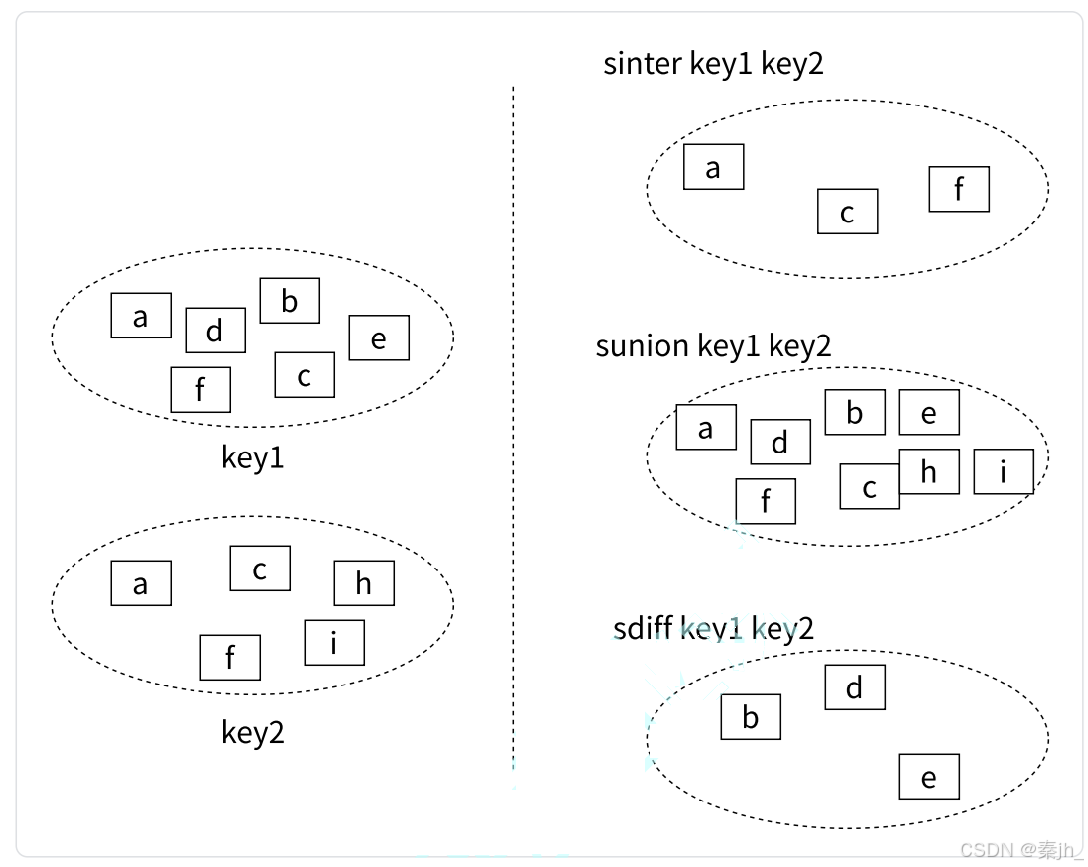
集合间操作
交集(inter)、并集(union)、差集(diff)的概念如下图
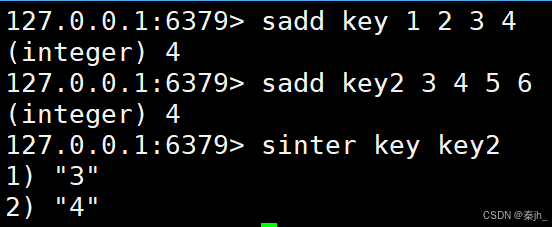
SINTER
获取给定 set 的交集中的元素。
语法:
SINTER key key ...
返回值:交集的元素。
示例:
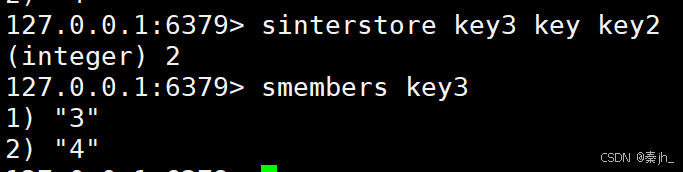
SINTERSTORE
获取给定 set 的交集中的元素并保存到目标 set 中。
语法:
SINTERSTORE destination key key ...
返回值:交集的元素个数。
示例:
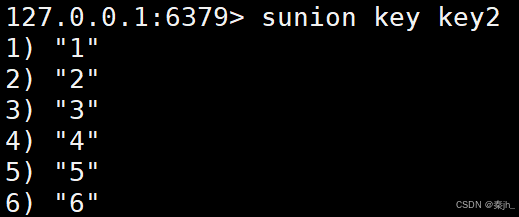
SUNION
获取给定 set 的并集中的元素。
语法:
SUNION key key ...
返回值:并集的元素。
示例:
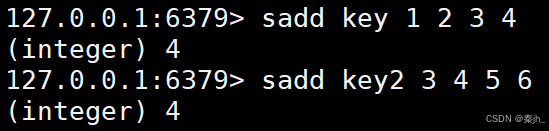
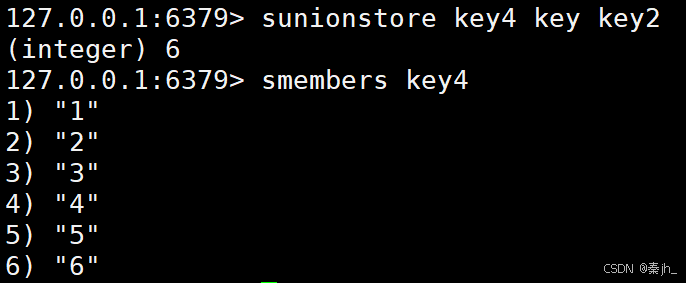
SUNIONSTORE
获取给定 set 的并集中的元素并保存到目标 set 中。
语法:
SUNIONSTORE destination key key ...
返回值:并集的元素个数。
示例:
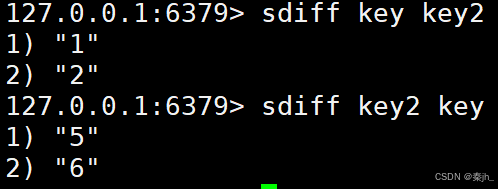
SDIFF
获取给定 set 的差集中的元素。
语法:
SDIFF key key ...
返回值:差集的元素。
示例:
SDIFFSTORE
获取给定 set 的差集中的元素并保存到目标 set 中。
语法:
SDIFFSTORE destination key key ...
返回值:差集的元素个数。
示例:
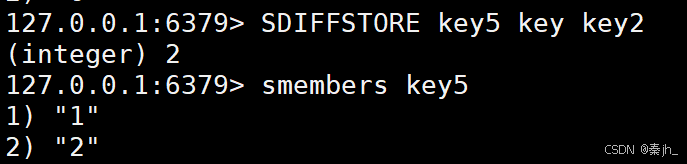

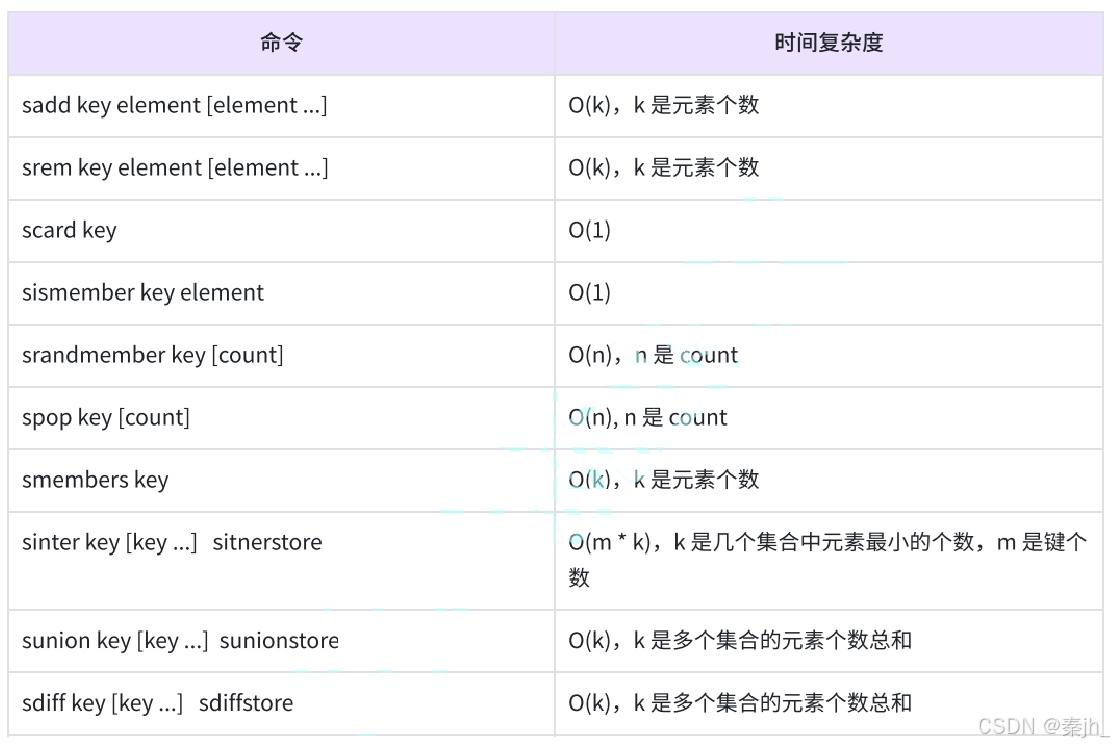
命令小结
内部编码
集合类型的内部编码有两种:
- intset(整数集合):当集合中的元素都是整数并且元素的个数小于 set-max-intset-entries 配置 (默认 512 个)时,Redis 会选用 intset 来作为集合的内部实现,从而减少内存的使用。
- hashtable(哈希表):当集合类型无法满足 intset 的条件时,Redis 会使用 hashtable 作为集合 的内部实现。
使用场景
集合类型比较典型的使用场景是标签(tag)。例如 A 用户对娱乐、体育板块比较感兴趣,B 用户 对历史、新闻比较感兴趣,这些兴趣点可以被抽象为标签。有了这些数据就可以得到喜欢同一个标签 的人,以及用户的共同喜好的标签,这些数据对于增强用户体验和用户黏度都非常有帮助。 例如一个 电子商务网站会对不同标签的用户做不同的产品推荐。
Zset 有序集合
有序集合相对于字符串、列表、哈希、集合来说会有一些陌生。它保留了集合不能有重复成员的 特点,但与集合不同的是,有序集合中的每个元素都有一个唯一的浮点类型的分数(score)与之关 联,这使得有序集合中的元素是可以维护有序性的,但这个有序不是用下标作为排序依据而是用这个 分数。如下图所示,该有序集合显示了三国中的武将的武力。
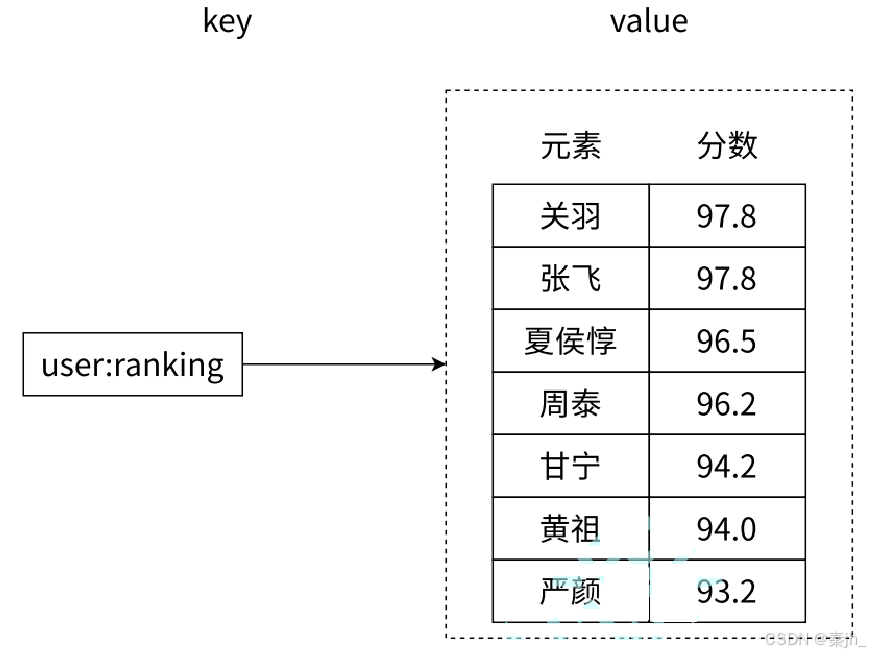
有序集合提供了获取指定分数和元素范围查找、计算成员排名等功能,合理地利用有序集合,可 以帮助我们在实际开发中解决很多问题。
有序集合中的元素是不能重复的,但分数允许重复。类比于一次考试之后,每个人一定有一 个唯一的分数,但分数允许相同。
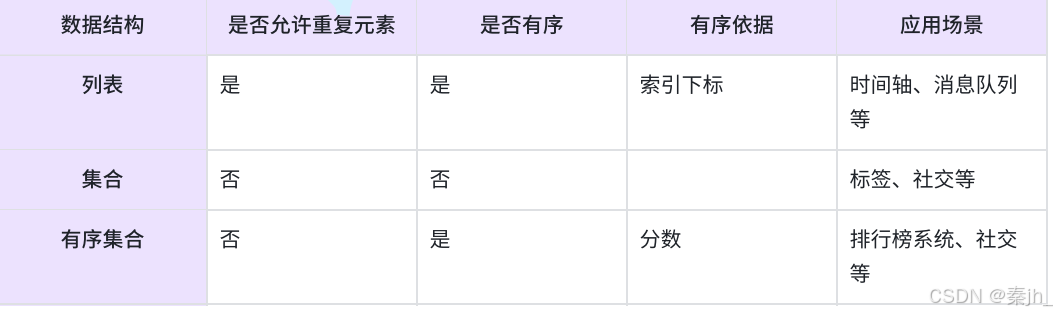
列表、集合、有序集合三者的异同点:
普通命令
ZADD
添加或者更新指定的元素以及关联的分数到 zset 中,分数应该符合 double 类型,+inf/-inf 作为正负 极限也是合法的。
ZADD 的相关选项:
- XX:仅仅用于更新已经存在的元素,不会添加新元素。
- NX:仅用于添加新元素,不会更新已经存在的元素。
- CH:默认情况下,ZADD 返回的是本次添加的元素个数,但指定这个选项之后,就会还包含本次更 新的元素的个数。
- INCR:此时命令类似 ZINCRBY 的效果,将元素的分数加上指定的分数。此时只能指定一个元素和 分数。
- LT:less than,只更新已经存在的元素,如果新的分数比当前分数小,那么更新就成功
- GT:greater than,只更新已经存在的元素,如果新的分数比当前分数大,那么更新就成功
语法:
ZADD key NX \| XX GT \| LT CH INCR score member score member ...
返回值:本次添加成功的元素个数。
示例:
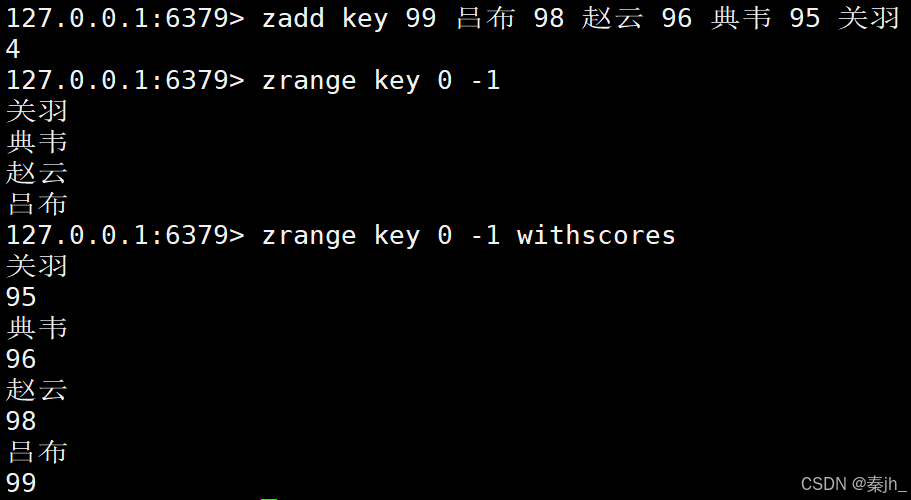
当前查询结果是有序的(升序)
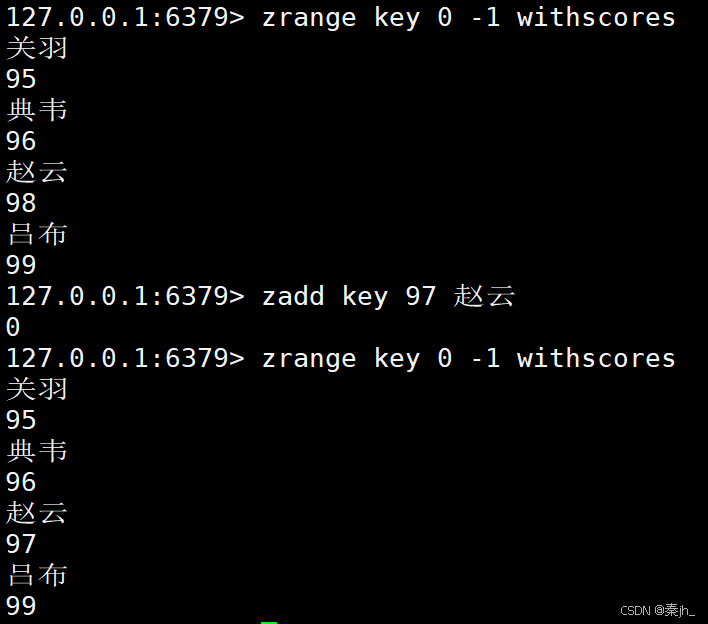
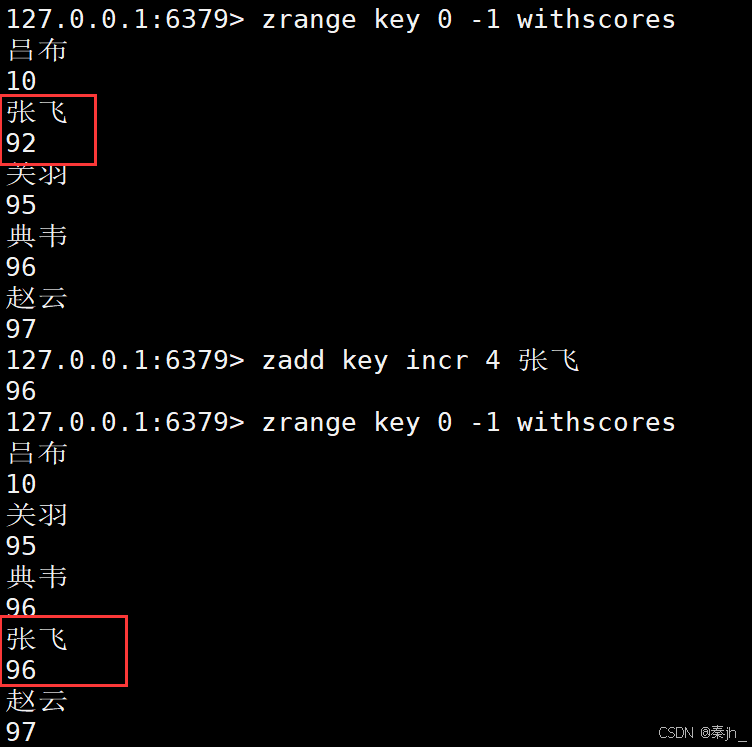
修改赵云的分数
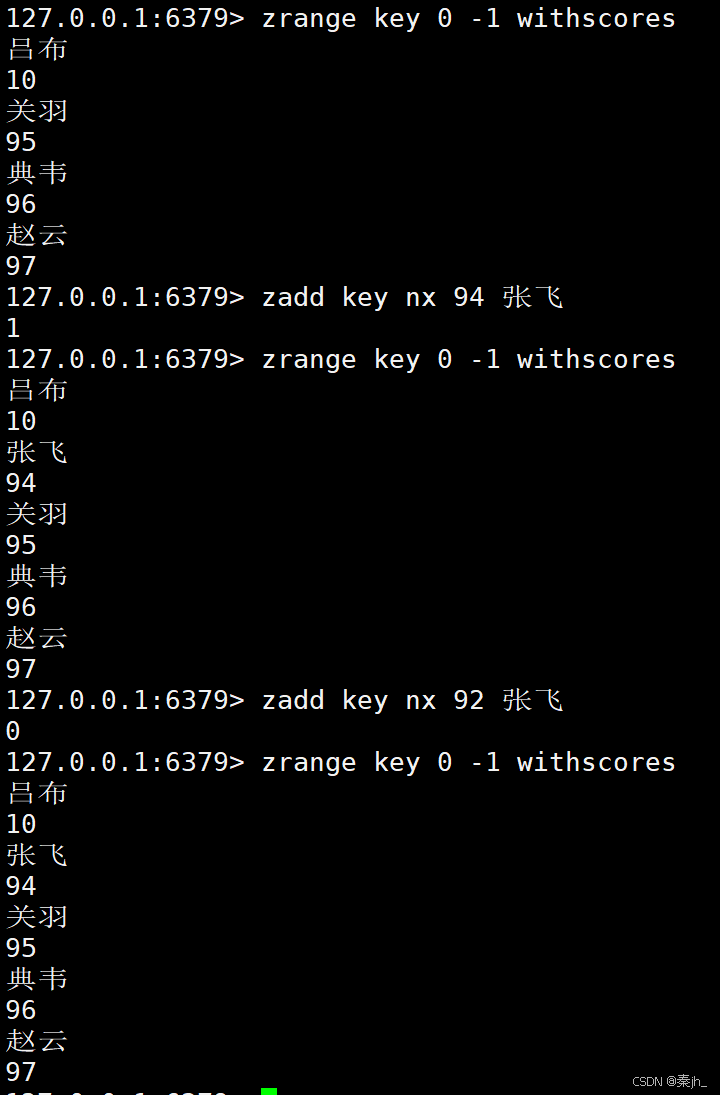
带nx选项,如果不存在就更新。返回值是新增元素的个数
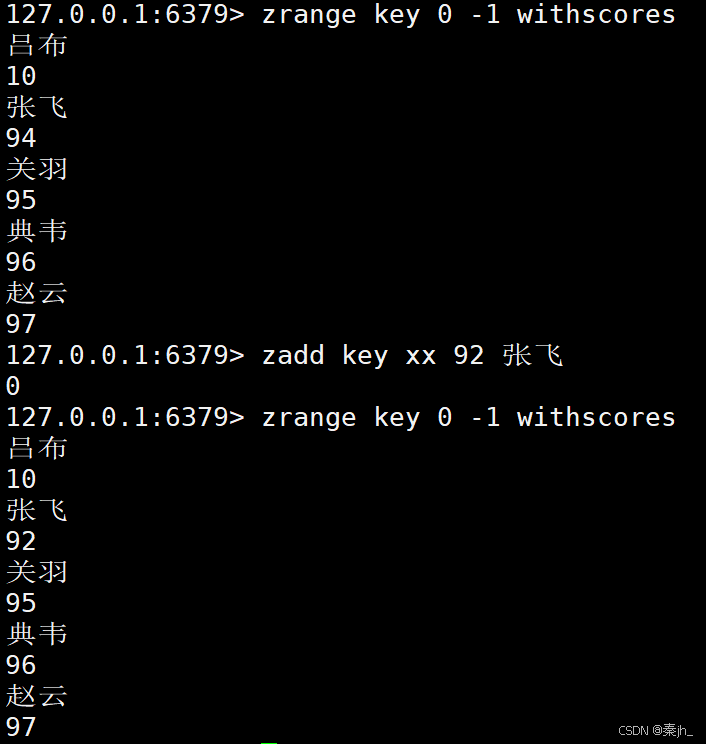
带xx选项,如果存在就修改值,返回值是0,因为没有新增元素,所以是0.
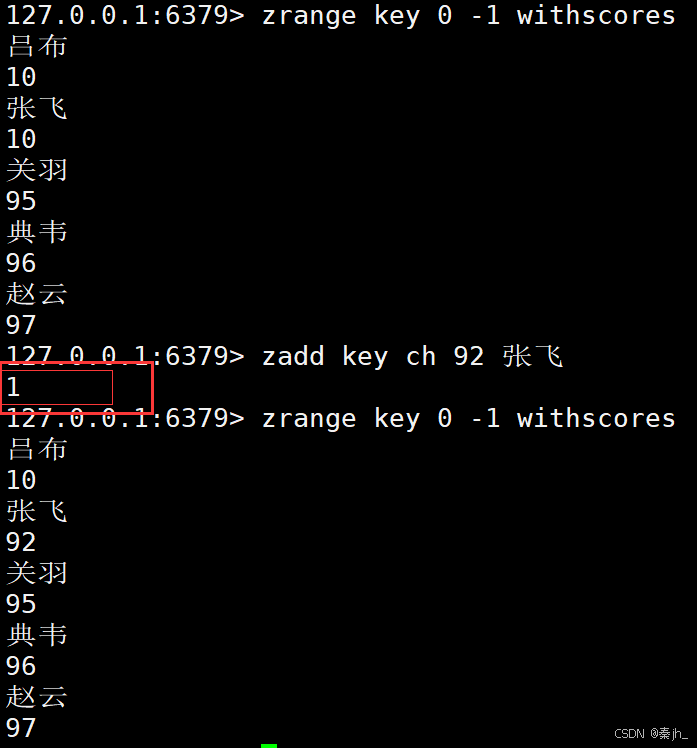
不加ch,默认返回新增的元素个数,带上ch选项,就要再加上修改的元素的个数。
ZCARD
获取一个 zset 的基数(cardinality),即 zset 中的元素个数。
语法:
ZCARD key
返回值:zset 内的元素个数。
示例:
ZCOUNT
返回分数在 min 和 max 之间的元素个数,默认情况下,min 和 max 都是包含的,可以通过 ( 排除。
语法:
ZCOUNT key min max
返回值:满足条件的元素列表个数。
示例:
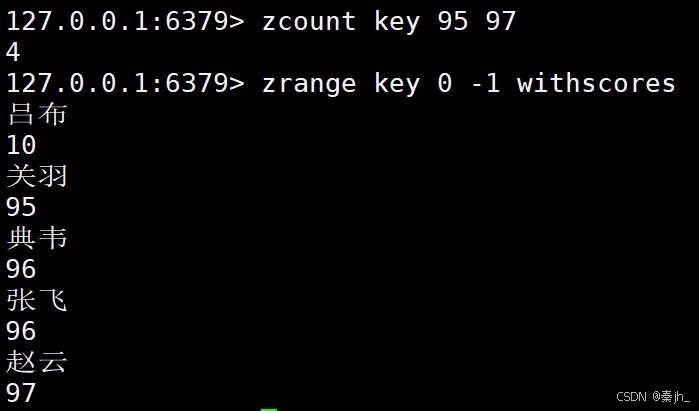
默认是包含边界的
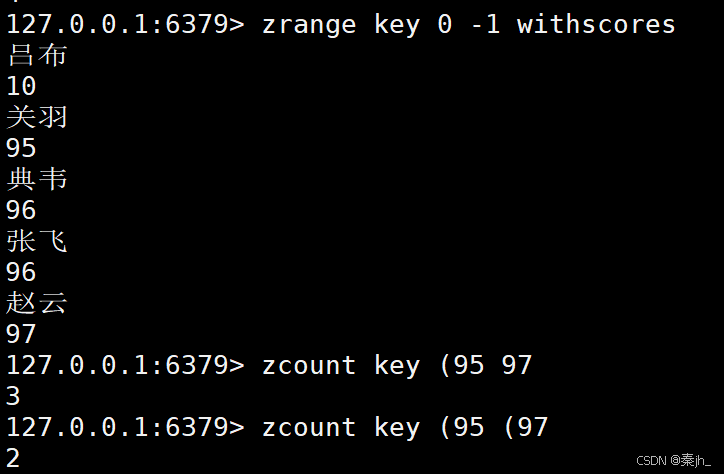
不包含边界的话要加上 (
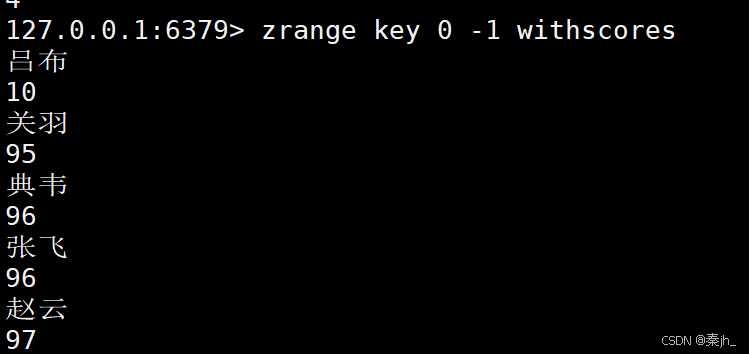
ZRANGE
返回指定区间里的元素,分数按照升序。带上 WITHSCORES 可以把分数也返回。
语法:
ZRANGE key start stop WITHSCORES
此处的 start, stop 为下标构成的区间. 从 0 开始, 支持负数.
返回值:区间内的元素列表。
示例:
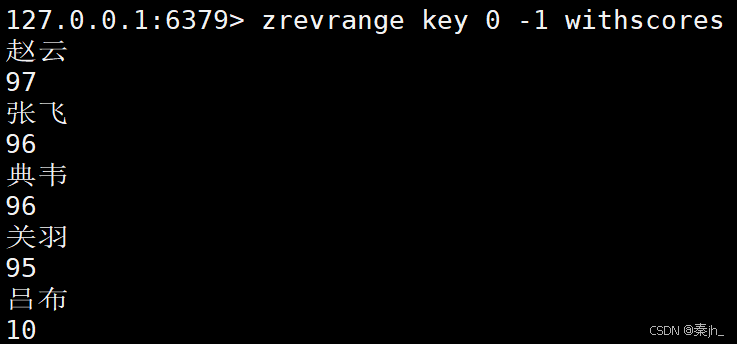
ZREVRANGE
返回指定区间里的元素,分数按照降序。带上 WITHSCORES 可以把分数也返回。
备注:这个命令可能在 6.2.0 之后废弃,并且功能合并到 ZRANGE 中。
语法:
ZREVRANGE key start stop WITHSCORES
返回值:区间内的元素列表。
示例:
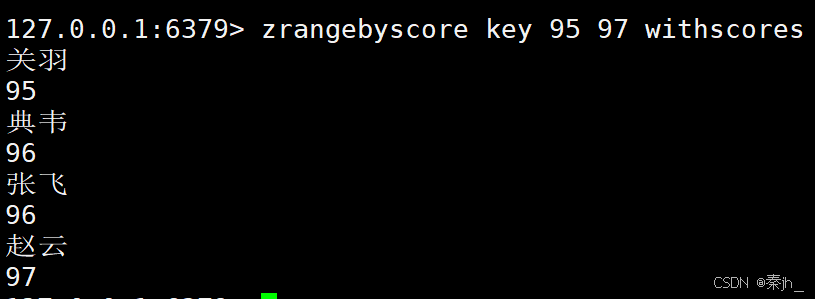
ZRANGEBYSCORE
返回分数在 min 和 max 之间的元素,默认情况下,min 和 max 都是包含的,可以通过 ( 排除。
备注:这个命令可能在 6.2.0 之后废弃,并且功能合并到 ZRANGE 中。
语法:
ZRANGEBYSCORE key min max WITHSCORES
返回值:区间内的元素列表。
示例:
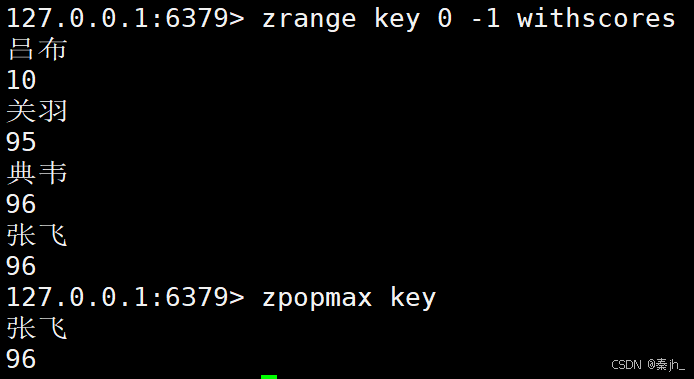
ZPOPMAX
删除并返回分数最高的 count 个元素。
语法:
ZPOPMAX key count
返回值:分数和元素列表。
示例:
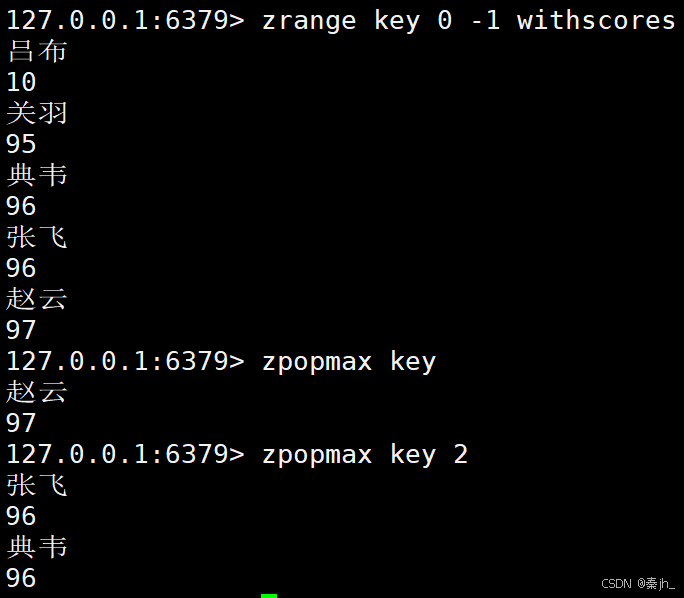
如果存在多个元素,他们的分数相同,同时为最大值,zpopmax删的时候,仍然只删除其中一个元素!
BZPOPMAX
ZPOPMAX 的阻塞版本。
语法:
BZPOPMAX key key ... timeout
返回值:元素列表。
示例:

刚开始key里没有数据,就会阻塞,插入元素后,就会立即返回
ZPOPMIN
删除并返回分数最低的 count 个元素。
语法:
ZPOPMIN key count
返回值:分数和元素列表。
示例:
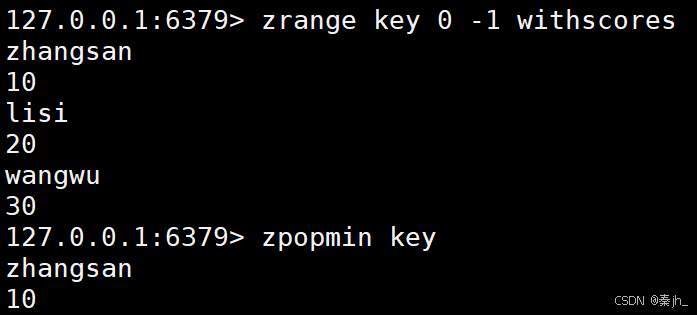
BZPOPMIN
ZPOPMIN 的阻塞版本。
语法:
BZPOPMIN key key ... timeout
返回值:元素列表。
ZRANK
返回指定元素的排名,升序。
语法:
ZRANK key member
返回值:排名。
示例:

ZREVRANK
返回指定元素的排名,降序。
语法:
ZREVRANK key member
返回值:排名。
ZSCORE
返回指定元素的分数。
语法:
ZSCORE key member
返回值:分数。
示例:
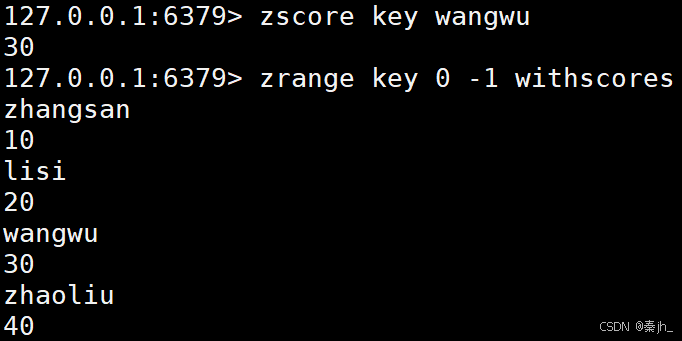
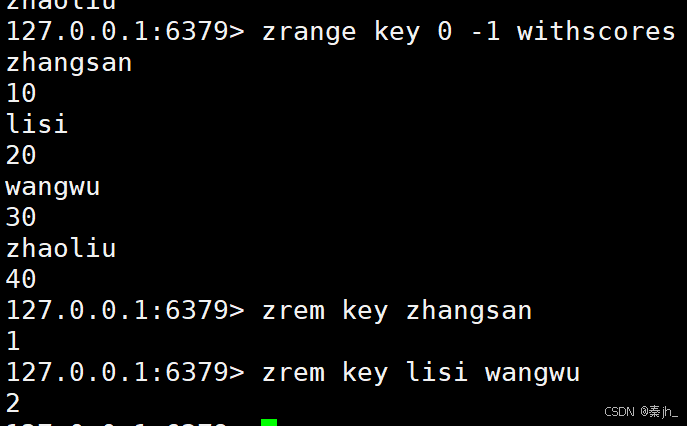
ZREM
删除指定的元素。
语法:
ZREM key member member ...
返回值:本次操作删除的元素个数。
示例:
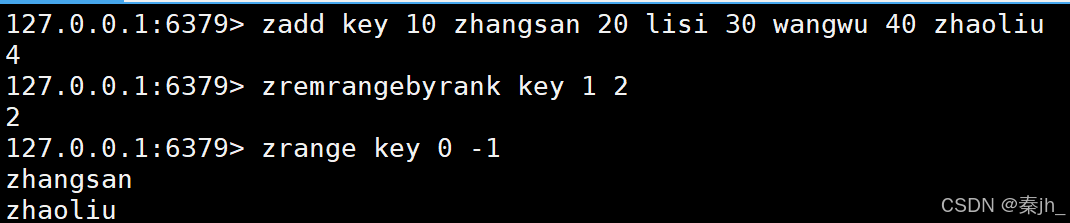
ZREMRANGEBYRANK
按照排序,升序删除指定范围的元素,左闭右闭。
语法:
ZREMRANGEBYRANK key start stop
返回值:本次操作删除的元素个数。
示例:
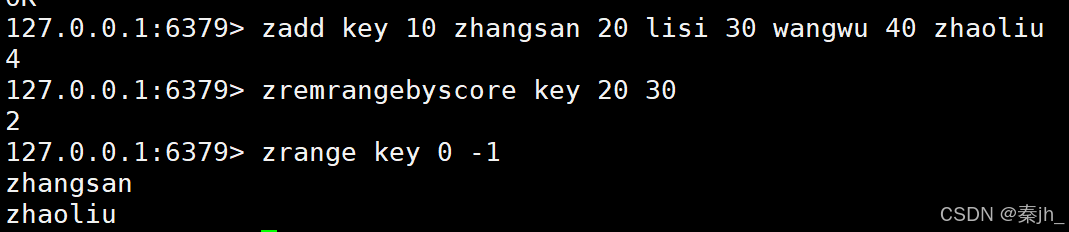
ZREMRANGEBYSCORE
按照分数删除指定范围的元素,左闭右闭,可以用 ( 排除边界值。
语法:
ZREMRANGEBYSCORE key min max
返回值:本次操作删除的元素个数。
示例:
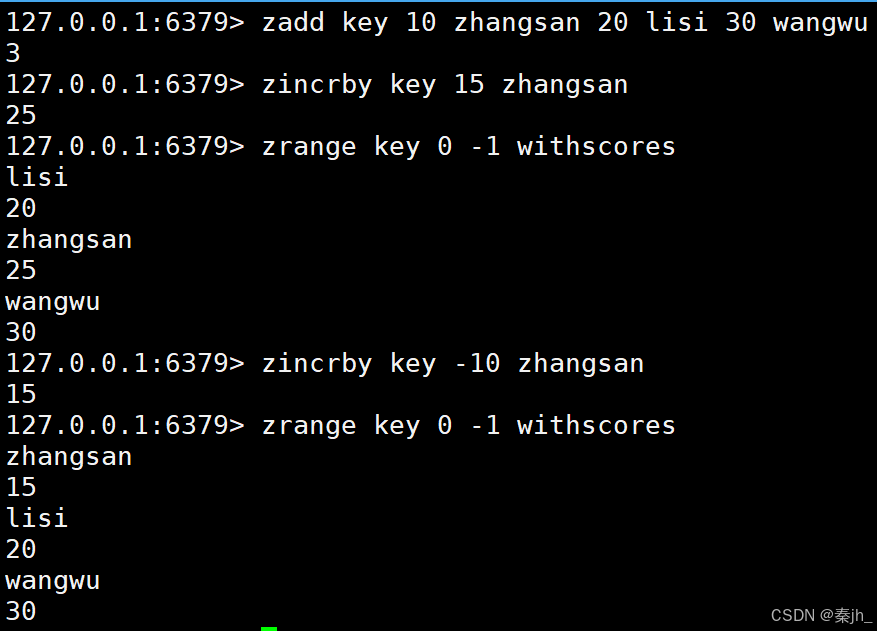
ZINCRBY
为指定的元素的关联分数添加指定的分数值。
语法:
ZINCRBY key increment member
返回值:增加后元素的分数。
示例:
集合间操作
有序集合的交集操作
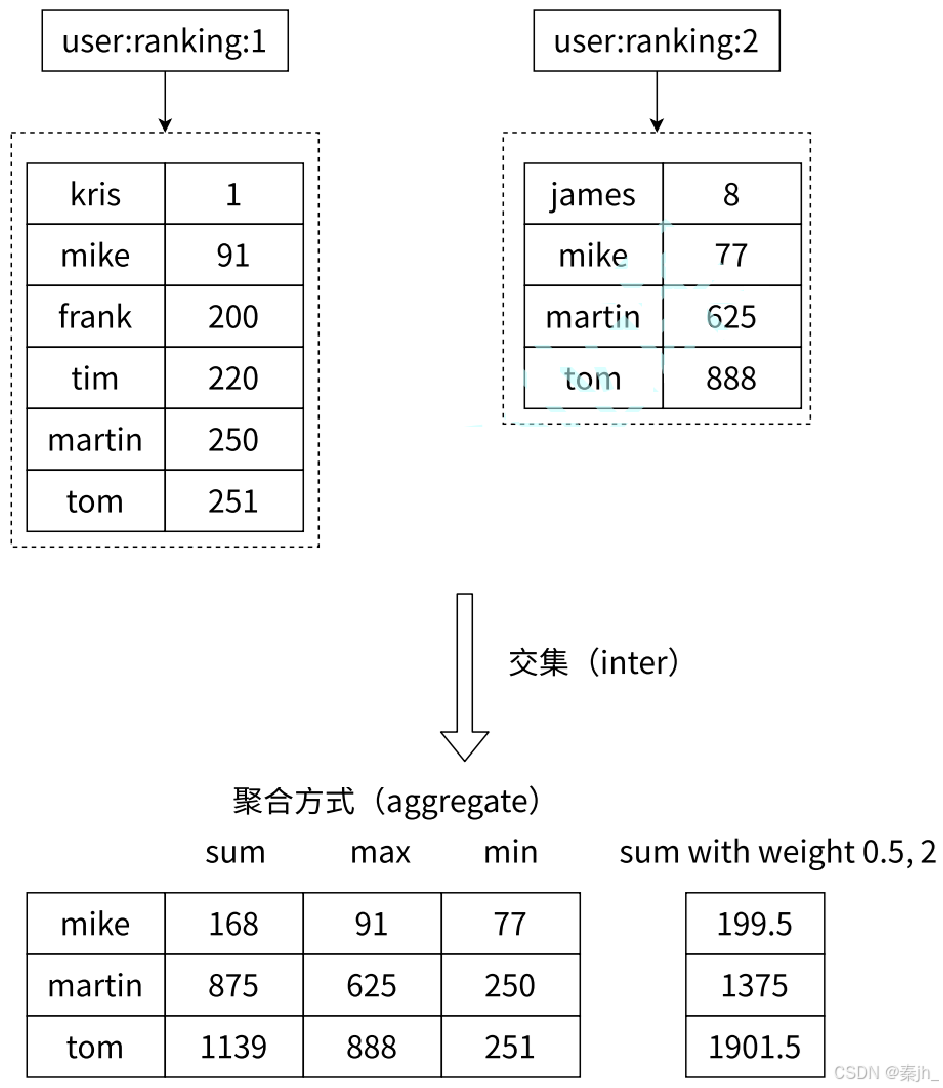
ZINTERSTORE
求出给定有序集合中元素的交集并保存进目标有序集合中,在合并过程中以元素为单位进行合并,元 素对应的分数按照不同的聚合方式和权重得到新的分数。
语法:
ZINTERSTORE destination numkeys key key ... WEIGHTS weight \[weight ...] AGGREGATE \
返回值:目标集合中的元素个数
示例1:

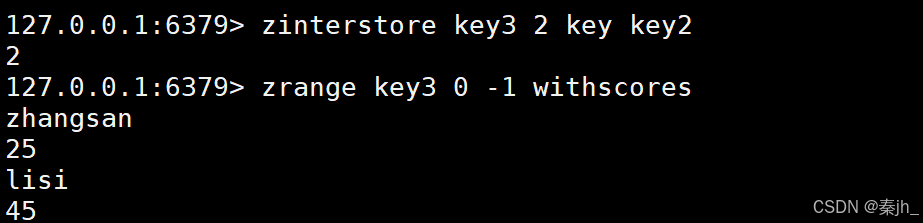
示例2:

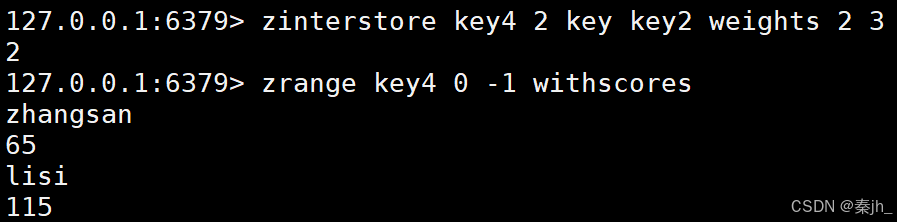
weights后面跟的2和3 就是权重。2是key的,3是key2的,把key里面的元素的分数都乘2,就从10,20,30变成20,40,60.把key2里面的元素的分数都乘3,就变成45,75,105。
返回结果中,交集的zhangsan就是20+45=65
示例3:
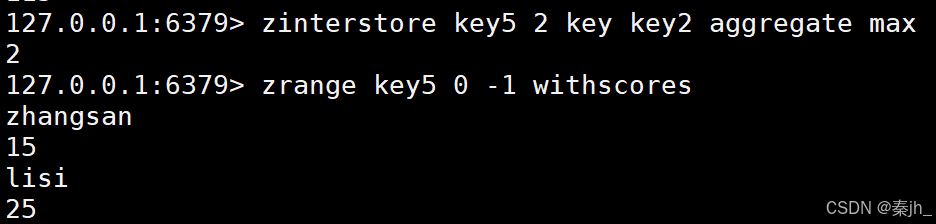
aggregate就是交集分数的聚合方式
有序集合的并集操作
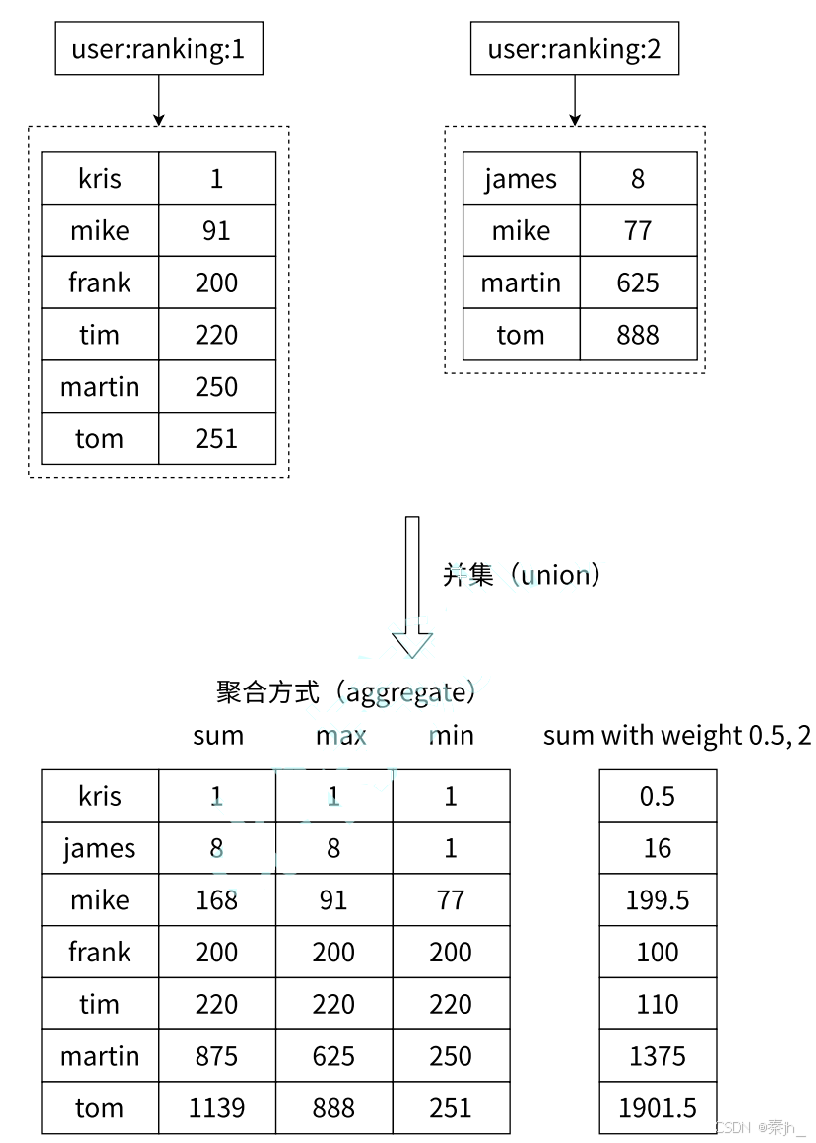
ZUNIONSTORE
求出给定有序集合中元素的并集并保存进目标有序集合中,在合并过程中以元素为单位进行合并,元 素对应的分数按照不同的聚合方式和权重得到新的分数。
语法:
ZUNIONSTORE destination numkeys key key ... WEIGHTS weight \[weight ...] AGGREGATE \
返回值:目标集合中的元素个数
示例1:
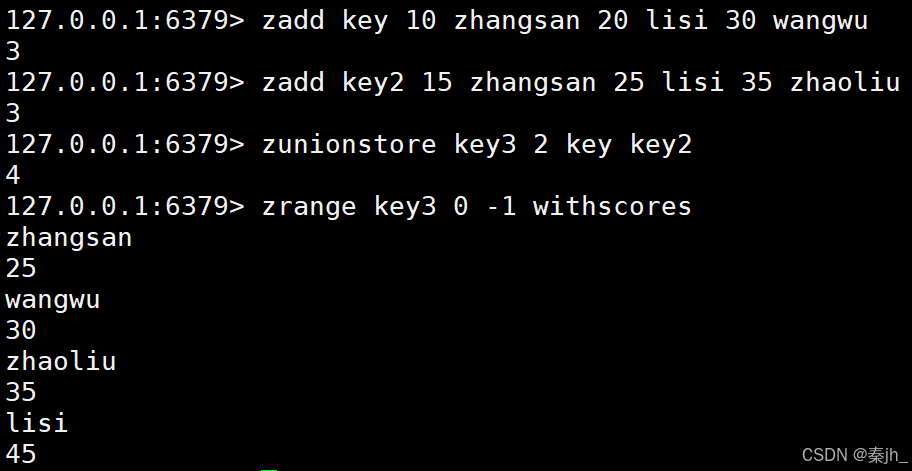
示例2:
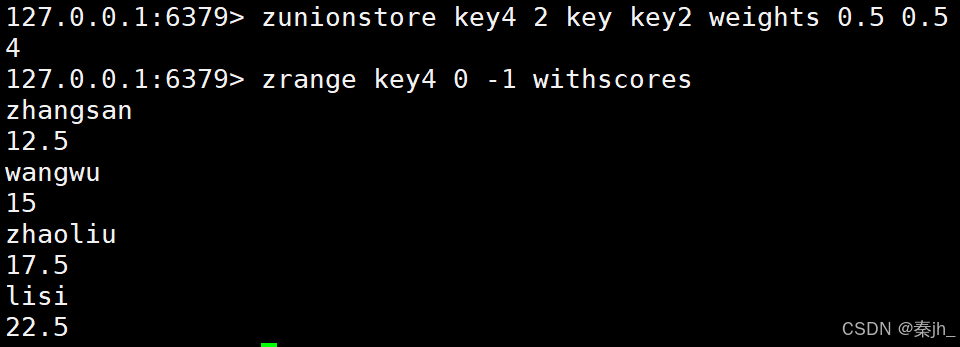
命令小结

内部编码
有序集合类型的内部编码有两种:
- ziplist(压缩列表):当有序集合的元素个数小于 zset-max-ziplist-entries 配置(默认 128 个), 同时每个元素的值都小于 zset-max-ziplist-value 配置(默认 64 字节)时,Redis 会用 ziplist 来作 为有序集合的内部实现,ziplist 可以有效减少内存的使用。
- skiplist(跳表):当 ziplist 条件不满足时,有序集合会使用 skiplist 作为内部实现,因为此时 ziplist 的操作效率会下降。
使用场景
有序集合比较典型的使用场景就是排行榜系统。例如常见的网站上的热榜信息,榜单的维度可能 是多方面的:按照时间、按照阅读量、按照点赞量。
渐进式遍历
Redis 使用 scan 命令进行渐进式遍历键,进而解决直接使用 keys 获取键时可能出现的阻塞问 题。每次 scan 命令的时间复杂度是 O(1),但是要完整地完成所有键的遍历,需要执行多次 scan。整 个过程如下图所示:

- 首次 scan 从 0 开始.
- 当 scan 返回的下次位置为 0 时, 遍历结束.
SCAN
以渐进式的方式进行键的遍历。
语法:
SCAN cursor MATCH pattern COUNT count TYPE type
COUNt:后面接数字,表示建议返回几个值,不一定就是指定的个数,但也不会差太多。
返回值:下一次 scan 的游标(cursor)以及本次得到的键。
示例:
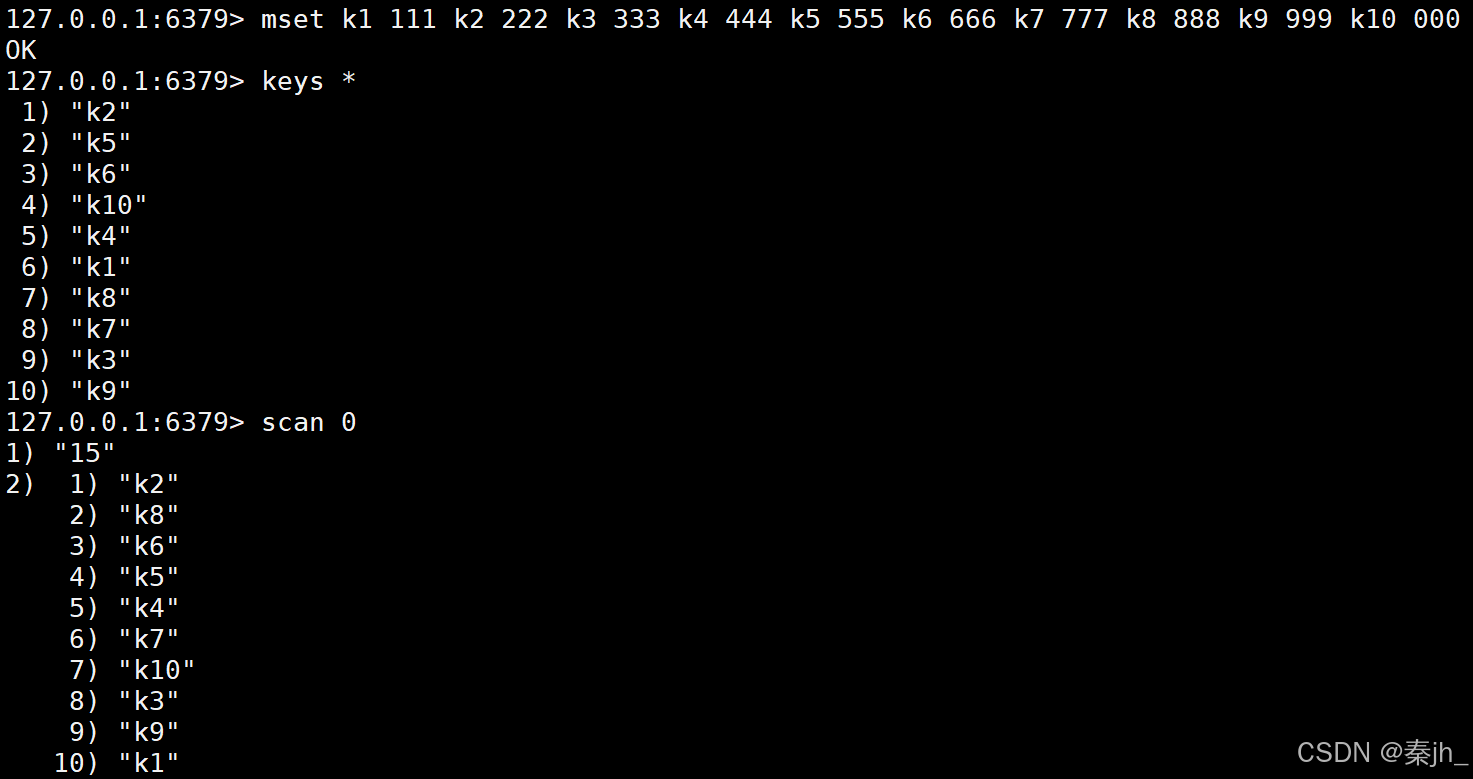
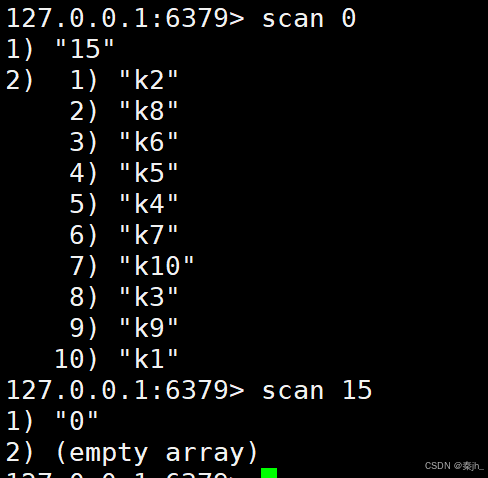
第一次遍历,返回的cursor是15,所以下一次遍历要从15开始。第二次返回的cursor是0,说明遍历已经结束了。
示例2:
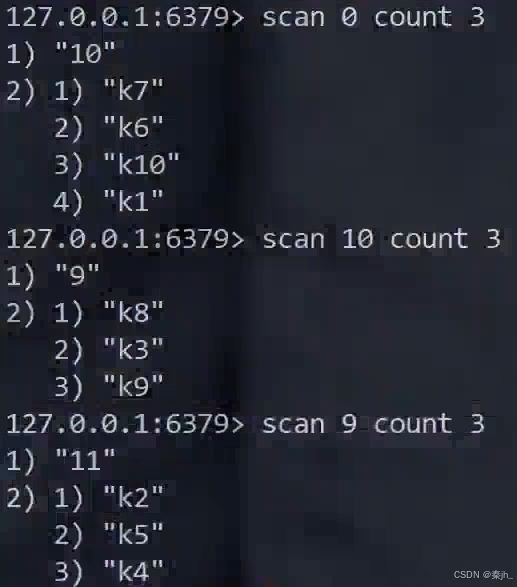
第一次遍历时,count后面是3,结果返回了4个,说明返回的个数不一定就是你指定的个数,只是建议返回几个。
除了 scan 以外,Redis 面向哈希类型、集合类型、有序集合类型分别提供了 hscan、sscan、zscan 命 令,它们的用法和 scan 基本类似
渐进性遍历 scan 虽然解决了阻塞的问题,但如果在遍历期间键有所变化(增加、修改、删 除),可能导致遍历时键的重复遍历或者遗漏,这点务必在实际开发中考虑。
数据库管理
Redis 提供了几个面向 Redis 数据库的操作,分别是 dbsize、select、flushdb、flushall 命令。
切换数据库
select dbIndex
许多关系型数据库,例如 MySQL 支持在一个实例下有多个数据库存在的,但是与关系型数据库用 字符来区分不同数据库名不同,Redis 只是用数字作为多个数据库的实现。Redis 默认配置中是有 16 个数据库。select 0 操作会切换到第一个数据库,select 15 会切换到最后一个数据库。0 号数据库和 15 号数据库保存的数据是完全不冲突的(如下图所示),即各种有各自的键值对。默认情况下,我 们处于数据库 0。
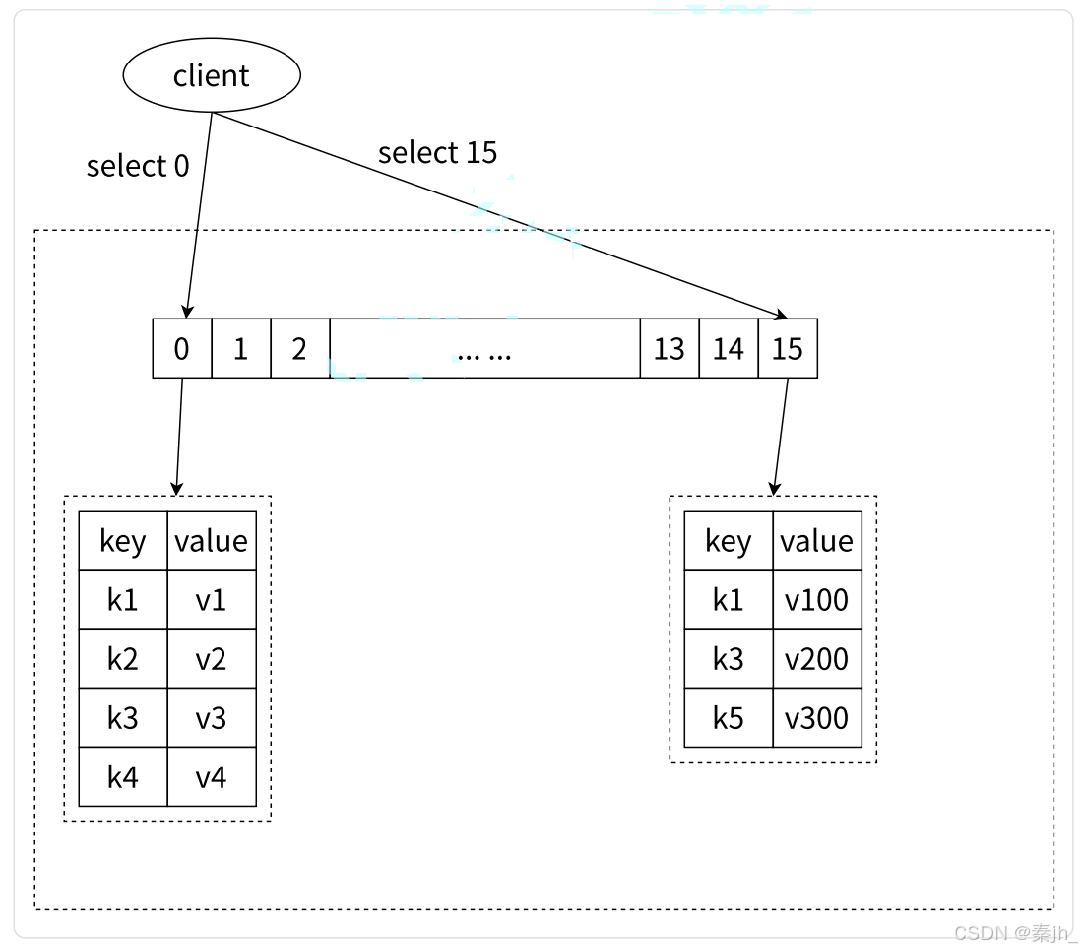
Redis 中虽然支持多数据库,但随着版本的升级,其实不是特别建议使用多数据库特性。如 果真的需要完全隔离的两套键值对,更好的做法是维护多个 Redis 实例,而不是在一个 Redis 实例中维护多数据库。这是因为本身 Redis 并没有为多数据库提供太多的特性,其次 无论是否有多个数据库,Redis 都是使用单线程模型,所以彼此之间还是需要排队等待命令 的执行。同时多数据库还会让开发、调试和运维工作变得复杂。所以实践中,始终使用数据 库 0 其实是一个很好的选择。
示例:
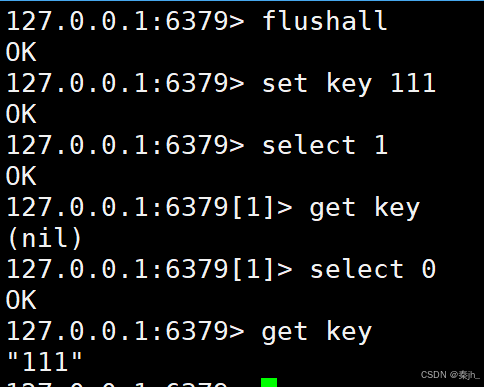
清除数据库
flushdb / flushall 命令用于清除数据库,区别在于 flushdb 只清除当前数据库,flushall 会清楚所有数 据库。
永远不要在线上环境执行清除数据的操作,除非你想体验一把 "从删库到跑路" 的操作。