目录
- 索引
-
- 一、索引概述
- 二、索引分类
-
- 聚集索引和二级索引
-
- [以下两条SQL语句,那个执行效率高? 为什么?](#以下两条SQL语句,那个执行效率高? 为什么?)
- 三、经典问题为什么InnoDB存储引擎选择使用B+tree索引结构?
- 四、索引语法
-
- [1. 单列索引](#1. 单列索引)
- [2. 联合索引](#2. 联合索引)
- [3. 覆盖索引](#3. 覆盖索引)
- [4. 前缀索引](#4. 前缀索引)
- 五、索引失效情况
-
- [1. 对索引列做运算 / 函数操作](#1. 对索引列做运算 / 函数操作)
- [2. 字符串不加引号](#2. 字符串不加引号)
- [3. 模糊查询以 `%` 开头](#3. 模糊查询以
%开头) - [4. 使用 `OR`,且只有部分条件有索引](#4. 使用
OR,且只有部分条件有索引) - [5. 不满足最左前缀法则(联合索引)](#5. 不满足最左前缀法则(联合索引))
- [6. 数据分布影响](#6. 数据分布影响)
- [7. 出现范围查询(>,<)](#7. 出现范围查询(>,<))
- 六、索引下推
-
- 1.**核心逻辑:把过滤的工作"推"给索引层**
- [2. 为什么叫"下推"?](#2. 为什么叫“下推”?)
- [3. 使用索引下推的条件](#3. 使用索引下推的条件)
- 参考
索引
一、索引概述
索引就像一本书的目录,能让 MySQL 快速定位数据,避免全表扫描。
除了查得快,索引还能加速排序、分组、连接等操作。
| 优势 | 劣势 |
|---|---|
| 提高数据检索的效率,降低数据库的IO成本 | 索引列也是要占用空间的。 |
| 通过索引列对数据进行排序,降低 数据排序的成本,降低CPU的消耗。 | 索引大大提高了查询效率,同时却也降低更新表的速度, 如对表进行INSERT、UPDATE、DELETE时,效率降低。 |
二、索引分类
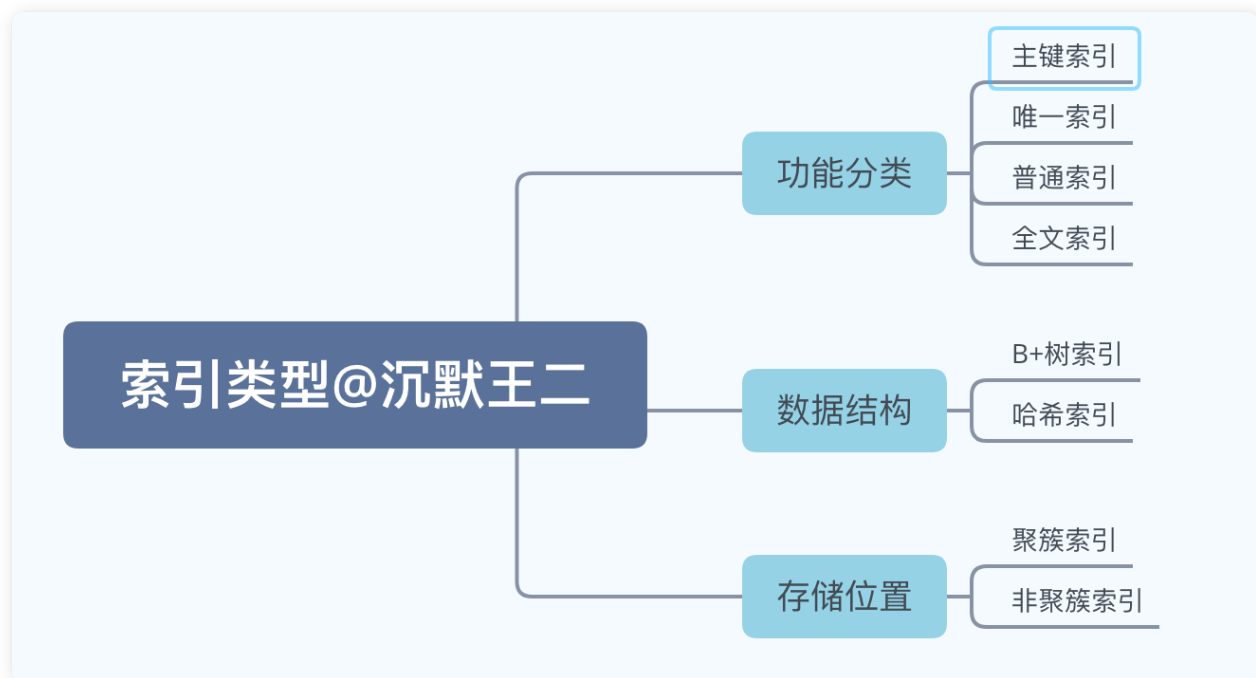
聚集索引和二级索引
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚簇索引 | 将数据存储与索引放到一块,索引结构的叶子节点保存了行数据 | 必须有,而且只有一个 |
| 二级索引 | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
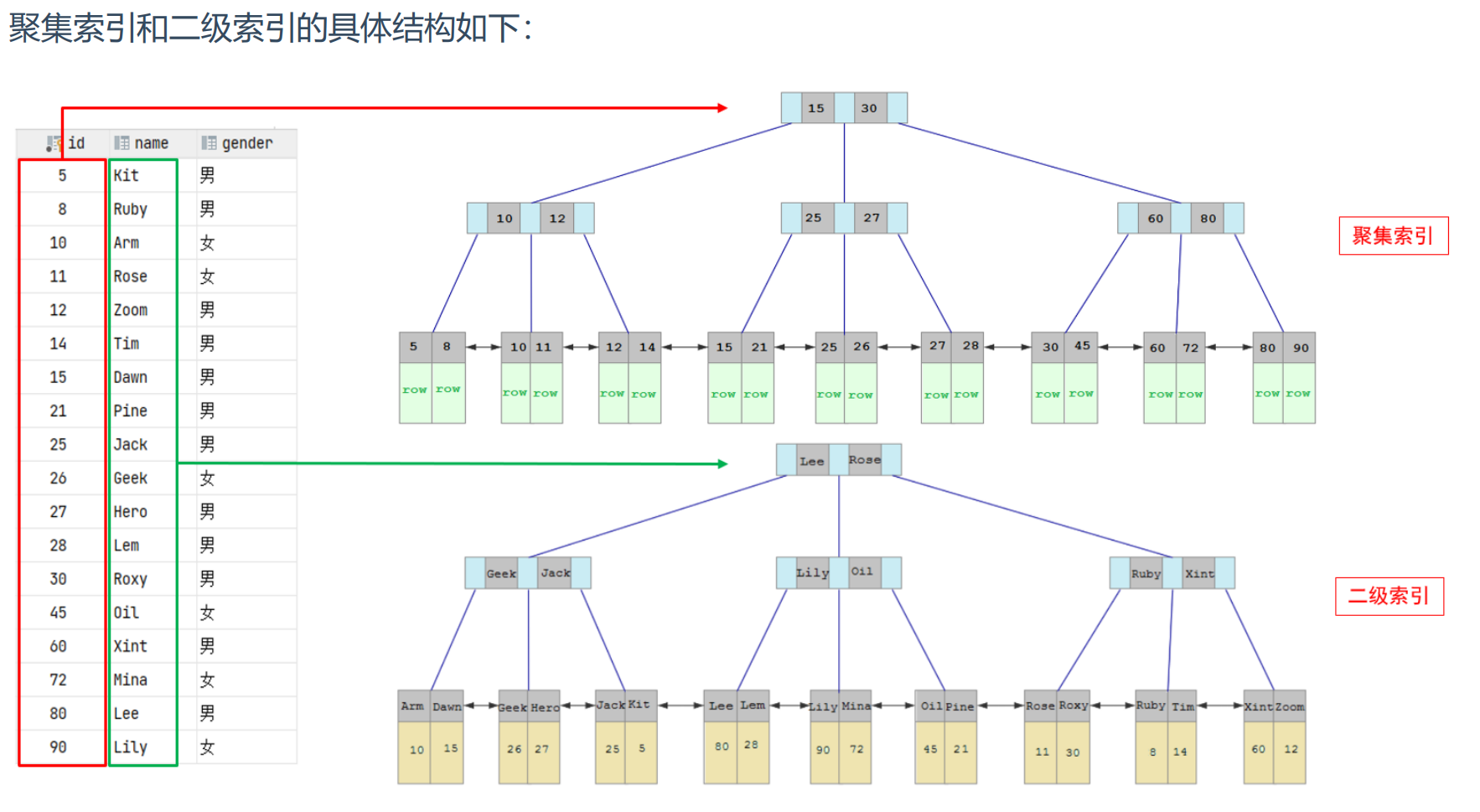
当执行一条SQL语句:
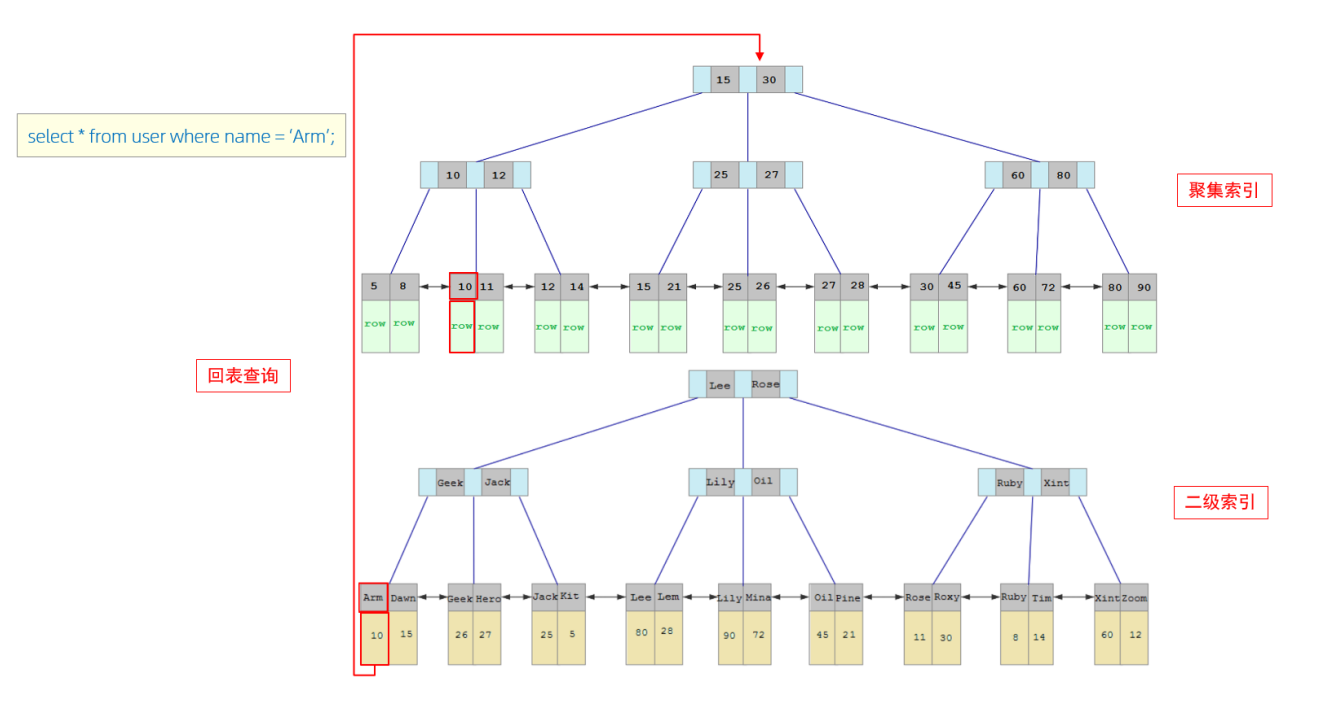
- 由于是根据name字段进行查询,所以先根据name='Arm'到name字段的二级索引中进行匹配查 找。但是在二级索引中只能查找到 Arm 对应的主键值 10。
- 由于查询返回的数据是*,所以此时,还需要根据主键值10,到聚集索引中查找10对应的记录,最终找到10对应的行row。
- 最终拿到这一行的数据,直接返回即可。
回表查询: 这种先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取 数据的方式,就称之为回表查询。
以下两条SQL语句,那个执行效率高? 为什么?
A. select * from user where id = 10 ; B. select * from user where name = 'Arm' ; 备注: id为主键,name字段创建的有索引;
解答: A 语句的执行性能要高于B 语句。 因为A语句直接走聚集索引,直接返回数据。 而B语句需要先查询name字段的二级索引,然后再查询聚集索引,也就是需要进行回表查询
三、经典问题为什么InnoDB存储引擎选择使用B+tree索引结构?
MySQL索引数据结构对经典的B+Tree进行了优化。在原 B+Tree 的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的 B+Tree,提高区间访问的性能,利于排序。
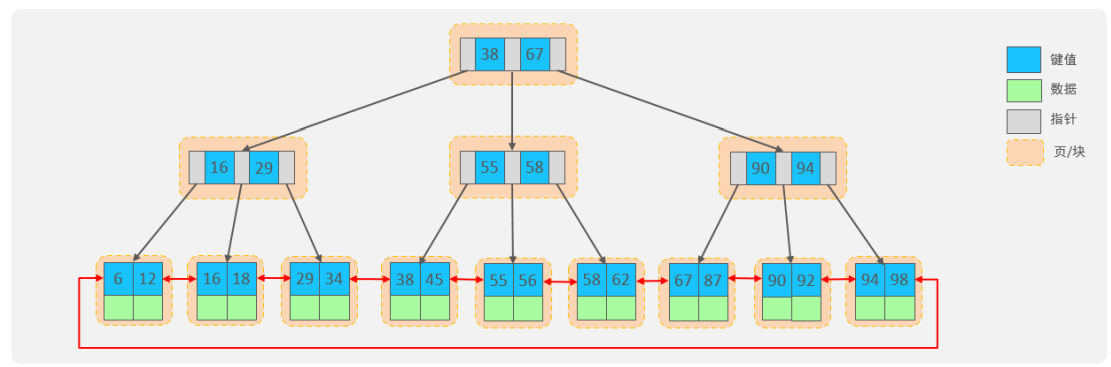
- 相对于二叉树,层级更少,搜索效率高;
- 对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低;
- 相对Hash索引,B+tree支持范围匹配及排序操作
四、索引语法
- 创建语法
mysql
CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name (
index_col_name,... ) ;- 查看索引
sql
SHOW INDEX FROM table_name ;- 删除索引
mysql
DROP INDEX index_name ON table_name ;1. 单列索引
-
定义 :在某张表的 单一列 上建立的索引。
-
特点:
- 一个索引只包含一个列。
- 可以有多个单列索引,但查询时通常只能用到其中一个(优化器可能选择最优的)。
-
例子:
sqlCREATE INDEX idx_name ON user(name);
2. 联合索引
-
定义 :在 多个列 上建立的索引。
-
特点:
- 遵循 最左前缀法则:只有在查询条件中用到了索引最左边的连续列,才能使用到索引。
- 比如
(col1, col2, col3)的索引:WHERE col1 = ?✅ 用到WHERE col1 = ? AND col2 = ?✅ 用到WHERE col2 = ?❌ 不能直接用
-
例子:
sqlCREATE INDEX idx_name_age ON user(name, age);
最左前缀法则:最左前缀法则中指的最左边的列,是指在查询时,联合索引的最左边的字段(即第一个字段)必须存在,与我们编写SQL时,条件编写的先后顺序无关。
3. 覆盖索引
-
定义 :查询所需的字段全部在索引里,不需要回表(去主键索引或数据页再取值)。
-
好处:
- 避免回表 → 提高查询性能。
-
例子:
sql-- 建立索引 CREATE INDEX idx_name_age ON user(name, age); -- 查询只涉及 name 和 age,这些字段已经都在索引中 SELECT name, age FROM user WHERE name = 'Tom';属于覆盖索引,不需要回表。
4. 前缀索引
-
定义 :对 字符串列的前几个字符 建立索引,而不是整个字段。
-
作用:
- 节省存储空间,提升索引效率。
- 但不能用于
ORDER BY、GROUP BY等需要全字段排序的情况。
-
例子:
sql-- 对 email 前 10 个字符建立索引 CREATE INDEX idx_email ON user(email(10));
五、索引失效情况
1. 对索引列做运算 / 函数操作
-
示例:
sqlSELECT * FROM user WHERE YEAR(create_time) = 2025; -- ❌ 索引失效 SELECT * FROM user WHERE id + 1 = 10; -- ❌ 索引失效原因:对索引字段做计算,索引树中的有序性被破坏。
2. 字符串不加引号
如果字符串不加单引号,对于查询结果,没什么影响,但是数 据库存在隐式类型转换,索引将失效。
3. 模糊查询以 % 开头
-
示例:
sqlSELECT * FROM user WHERE name LIKE '%abc'; -- ❌ 索引失效 SELECT * FROM user WHERE name LIKE 'abc%'; -- ✅ 走索引原因 :
%在前,无法利用索引的 B+ 树前缀特性。
4. 使用 OR,且只有部分条件有索引
-
示例:
sqlSELECT * FROM user WHERE name = 'Tom' OR age = 18;- 用or分割开的条件, 如果or前的条件中的列有索引 ,而后面的列中没有索引,那么涉及的索引都不会被用到。
- 解决方法:对
age也建索引,或者改写为UNION。
5. 不满足最左前缀法则(联合索引)
6. 数据分布影响
如果MySQL评估使用索引比全表更慢,则不使用索引。
7. 出现范围查询(>,<)
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效。
所以,在业务允许的情况下,尽可能的使用类似于 >= 或 <= 这类的范围查询,而避免使用 > 或 <
六、索引下推
1.核心逻辑:把过滤的工作"推"给索引层
在没有索引下推之前,数据库的执行逻辑是"比较死板"的。
假设你有一张表 users,建立了一个联合索引 (age, name)。 SQL 是:SELECT * FROM users WHERE age = 20 AND name LIKE '%张%';
没有索引下推时(旧版):
- 索引层 :根据
age = 20在索引树中找到所有匹配的记录。 - 回表 :索引层不管
name匹配不匹配,把所有age = 20的 ID 全部交给 Server 层(数据库的上层)。 - Server 层 :拿着这些 ID 去聚簇索引里找整行数据(回表),然后再一个个判断
name是否包含"张"。
痛点: 如果
age = 20的人有 1000 个,但名字带"张"的只有 1 个,数据库也要回表 1000 次!这太浪费了。
2. 为什么叫"下推"?
在数据库架构中,分为 Server 层 (负责 SQL 解析、优化)和 存储引擎层(负责取数据,如 InnoDB)。
- 以前:过滤逻辑在 Server 层(上层)。
- 现在:把过滤逻辑"下推"到了存储引擎层(底层)。
3. 使用索引下推的条件
- 必须是二级索引:聚簇索引不需要下推(因为数据就在叶子节点,查到即得到全部)。
- 只适用于联合索引中的部分过滤 :比如复合索引
(a, b),即使b因为模糊查询(如LIKE '%x%')导致无法利用索引的有序性进行快速定位,它依然可以用来在索引内部做过滤。
参考
沉默王二、黑马程序员