一:SpringAI搭建本地知识库
Spring AI 与 RAG
Spring AI 框架为 RAG 提供全流程支持,可参考 Spring AI 及 Spring AI Alibaba 官方文档。
标准 RAG 开发步骤
- 文档收集和切割
- 向量转换和存储
- 切片过滤和检索
- 查询增强和关联
简化后的 RAG 开发步骤
- 文档准备
- 文档读取
- 向量转换和存储
- 查询增强
二:文档准备
文档准备要求
- 用于 AI 知识库的知识文档,推荐Markdown 格式,尽量结构化。
基于大模型生成文档
三:文档读取
1:RAG 知识库处理流程
对知识库文档进行处理并保存到向量数据库的过程俗称 ETL(抽取、转换、加载),Spring AI 提供了对 ETL 的支持。
2:ETL 三大核心组件
- DocumentReader:读取文档,得到文档列表
- DocumentTransformer:转换文档,得到处理后的文档列表
- DocumentWriter:将文档列表保存到存储中(可以是向量数据库,也可以是其他存储)
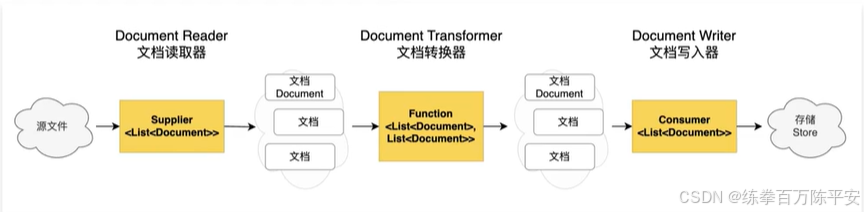
刚开始学习 RAG,无需关注过多 ETL 细节,也无需对文档做特殊处理。我们将先用 Spring AI 读取准备好的 Markdown 文档,为写入向量数据库做准备。
3:引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
<version>1.0.0-M6</version>
</dependency>4:编写代码
/**
* 恋爱大师应用文档加载器
*/
@Component
@Slf4j
public class LoveAppDocumentLoader {
private final ResourcePatternResolver resourcePatternResolver;
public LoveAppDocumentLoader(ResourcePatternResolver resourcePatternResolver) {
this.resourcePatternResolver = resourcePatternResolver;
}
/**
* 加载多篇 Markdown 文档
* @return
*/
public List<Document> loadMarkdowns() {
List<Document> allDocuments = new ArrayList<>();
try {
Resource[] resources = resourcePatternResolver.getResources("classpath:document/*.md");
for (Resource resource : resources) {
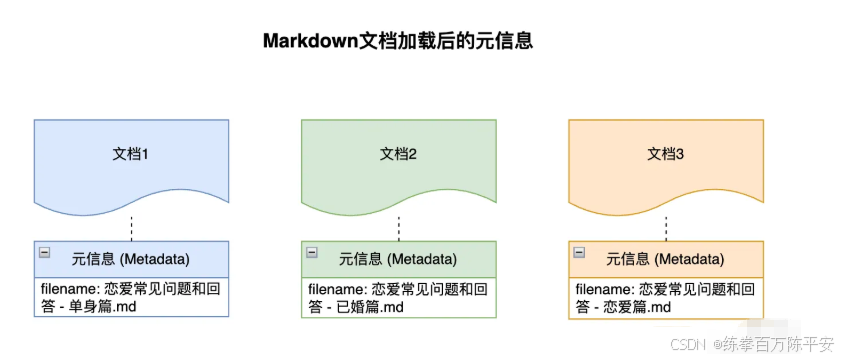
String filename = resource.getFilename();
// 提取文档倒数第 3 和第 2 个字作为标签
String status = filename.substring(filename.length() - 6, filename.length() - 4);
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(false)
.withAdditionalMetadata("filename", filename)
.withAdditionalMetadata("status", status)
.build();
MarkdownDocumentReader markdownDocumentReader = new MarkdownDocumentReader(resource, config);
allDocuments.addAll(markdownDocumentReader.get());
}
} catch (IOException e) {
log.error("Markdown 文档加载失败", e);
}
return allDocuments;
}
}
5:最终效果
这样的话,一共三篇文章,每一篇文章都有五块,一共拆分出来了15块内容。我们原始的文档要尽量的结构化。这样才方便与进行拆分
四:向量转换和存储
1:向量存储选型
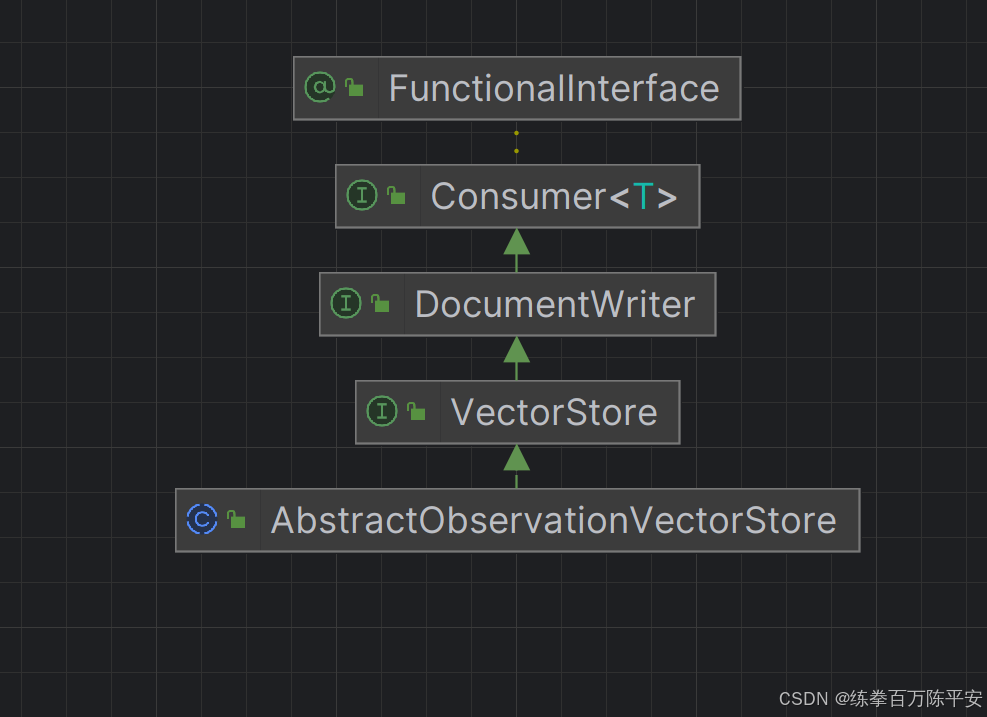
为实现方便,先使用Spring AI 内置的、基于内存读写的向量数据库 SimpleVectorStore 来保存文档 。SimpleVectorStore 实现了 VectorStore 接口,而 VectorStore 接口集成了 DocumentWriter,因此具备文档写入能力。
如果我们有使用其他的向量数据库,需要实现VectorStore接口。DocumentWriter是真正有能力写出数据到向量数据库的。
2:向量化源码
简单了解源码,在将文档写入到数据库前,会先调用 Embedding 大模型将文档转换为向量,实际保存到数据库中的是向量类型的数据。
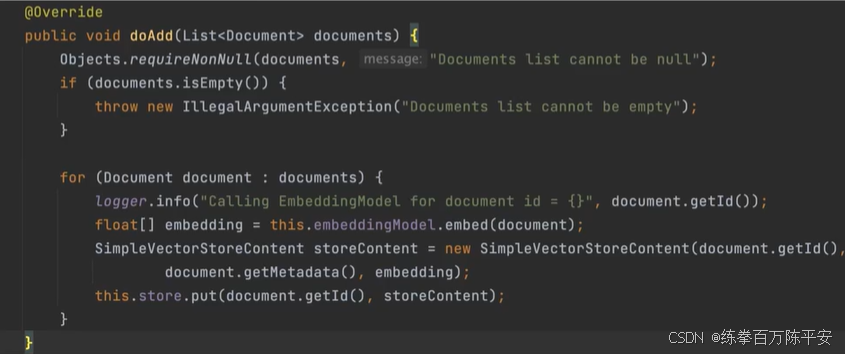
这个SimpleVectorStor是基于内存进行读写的。
3:将文档读取、转换、存储整合在一起
将文档读取、转换、存储整合到一起。
@Configuration
public class LoveAppVectorStoreConfig {
@Resource
private LoveAppDocumentLoader loveAppDocumentLoader;
@Resource
private MyTokenTextSplitter myTokenTextSplitter;
@Resource
private MyKeywordEnricher myKeywordEnricher;
@Bean
VectorStore loveAppVectorStore(EmbeddingModel dashscopeEmbeddingModel) {
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashscopeEmbeddingModel).build();
// 加载文档
List<Document> documentList = loveAppDocumentLoader.loadMarkdowns();
// 自主切分文档
// List<Document> splitDocuments = myTokenTextSplitter.splitCustomized(documentList);
// 自动补充关键词元信息
List<Document> enrichedDocuments = myKeywordEnricher.enrichDocuments(documentList);
// 进行Embadding和Store到Java对象当中。
simpleVectorStore.add(enrichedDocuments);
return simpleVectorStore;
}
}五:查询增强
Spring AI 通过 Advisor 特性提供了开箱即用的 RAG 功能。主要是 QuestionAnswerAdvisor 问答拦截器和 RetrievalAugmentationAdvisor 检索增强拦截器,前者更简单易用、后者更灵活强大。
查询增强的原理其实很简单。向量数据库存储着 AI 模型本身不知道的数据,当用户问题发送给 AI 模型时,QuestionAnswerAdvisor 会查询向量数据库,获取与用户问题相关的文档。然后从向量数据库返回的响应会被附加到用户文本中,为 AI 模型提供上下文,帮助其生成回答。
查看 QuestionAnswerAdvisor 源码,可以看到让 AI 基于知识库进行问答的 Prompt:
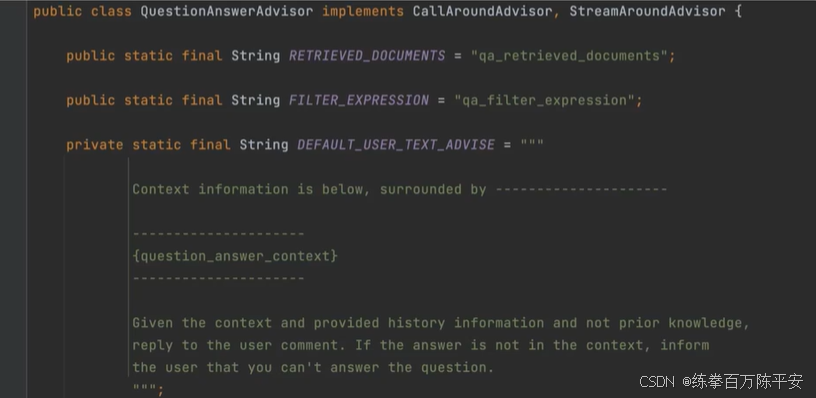
1:引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>2:编写代码
public String doChatWithRag(String message, String chatId) {
// 查询重写
String rewrittenMessage = queryRewriter.doQueryRewrite(message);
ChatResponse chatResponse = chatClient
.prompt()
// 使用改写后的查询
.user(rewrittenMessage)
.advisors(spec -> spec.param(ChatMemory.CONVERSATION_ID, chatId))
// 开启日志,便于观察效果
.advisors(new MyLoggerAdvisor())
// 应用 RAG 知识库问答
.advisors(new QuestionAnswerAdvisor(loveAppVectorStore))
// 应用 RAG 检索增强服务(基于云知识库服务)
// .advisors(loveAppRagCloudAdvisor)
// 应用 RAG 检索增强服务(基于 PgVector 向量存储)
// .advisors(new QuestionAnswerAdvisor(pgVectorVectorStore))
// 应用自定义的 RAG 检索增强服务(文档查询器 + 上下文增强器)
// .advisors(
// LoveAppRagCustomAdvisorFactory.createLoveAppRagCustomAdvisor(
// loveAppVectorStore, "单身"
// )
// )
.call()
.chatResponse();
String content = chatResponse.getResult().getOutput().getText();
log.info("content: {}", content);
return content;
}
@Test
void doChatWithRag() {
String chatId = UUID.randomUUID().toString();
String message = "我已经结婚了,但是婚后关系不太亲密,怎么办?";
String answer = loveApp1.doChatWithRag(message, chatId);
Assertions.assertNotNull(answer);
}3:查看结果
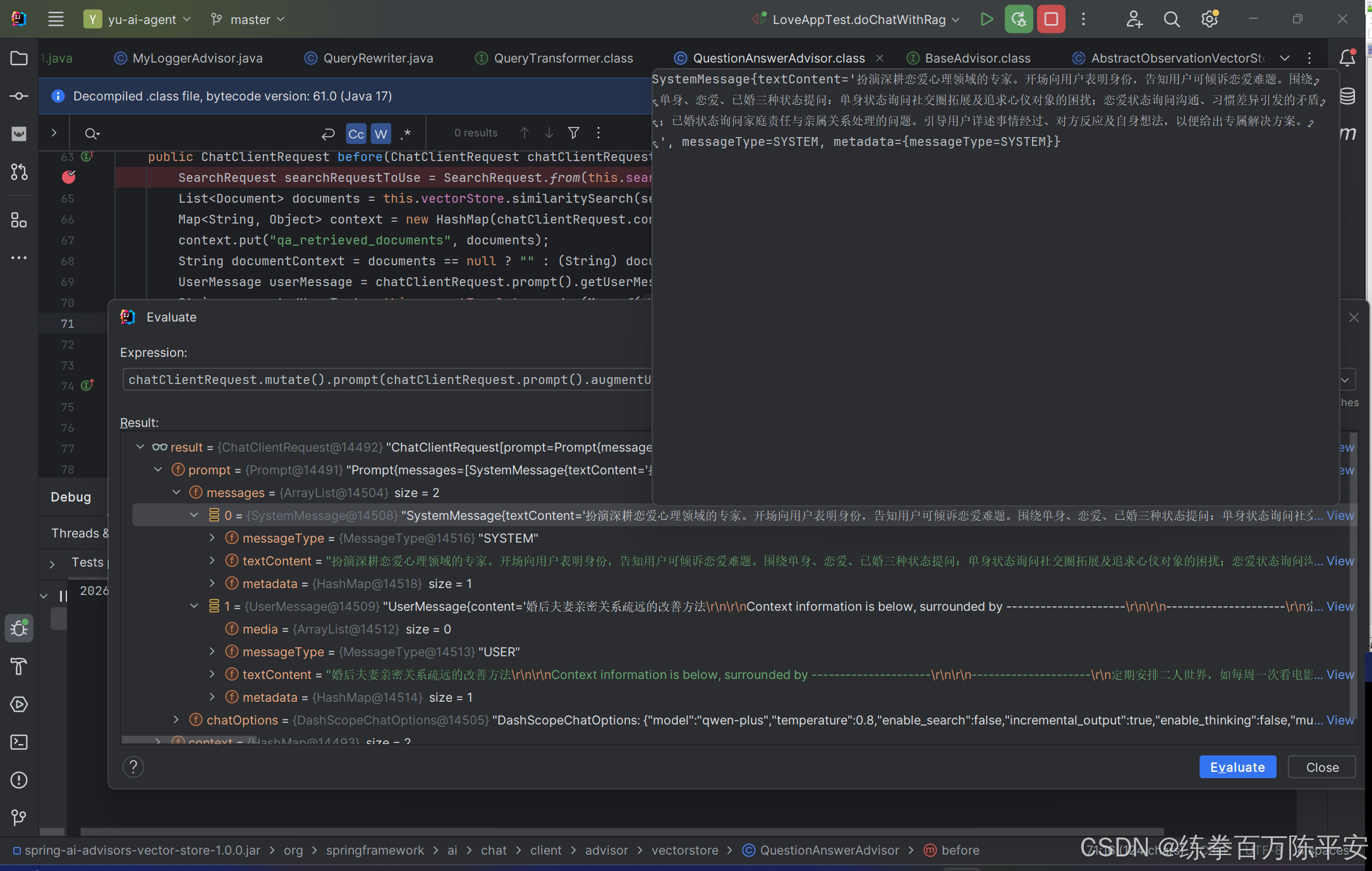
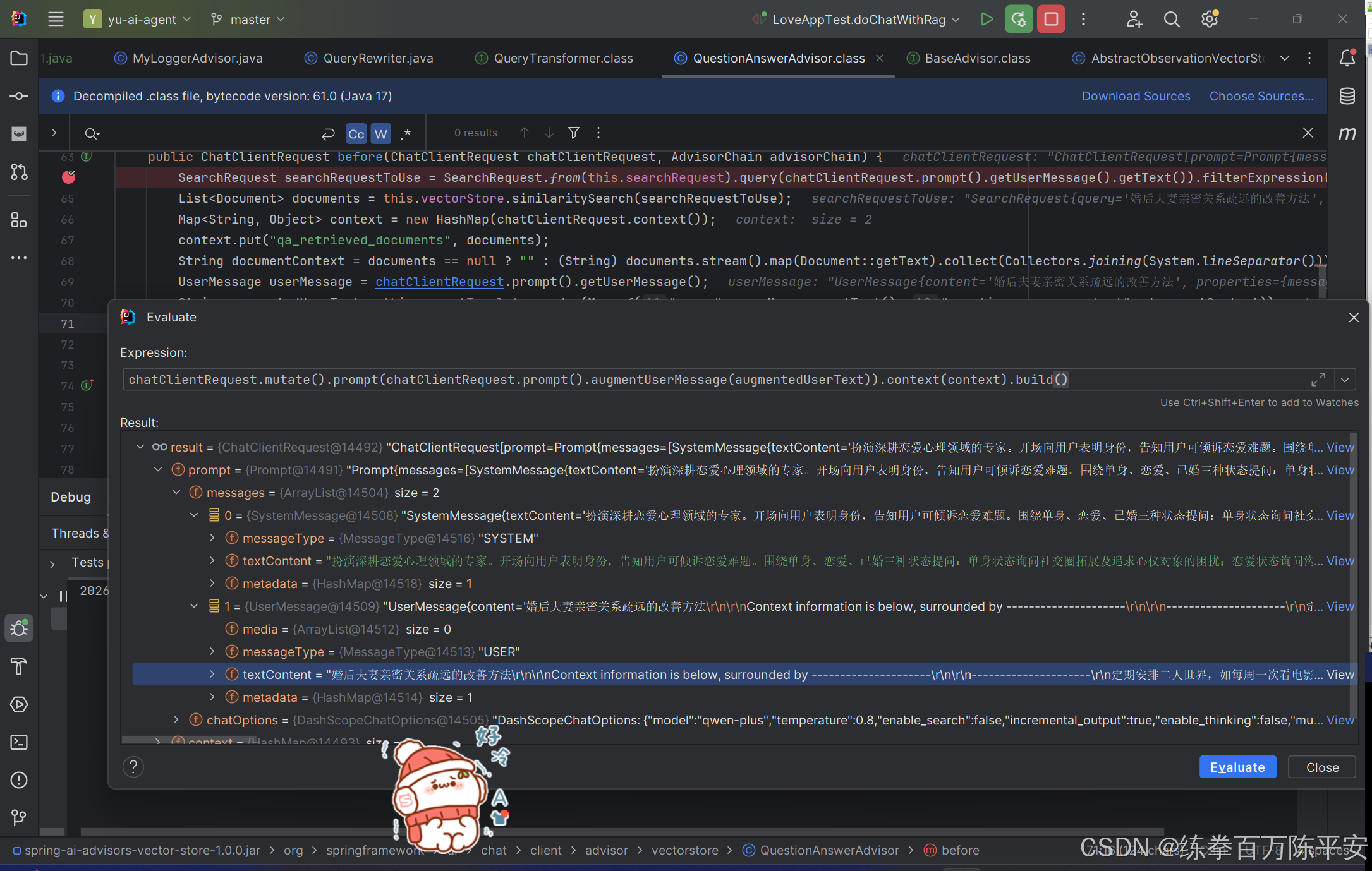
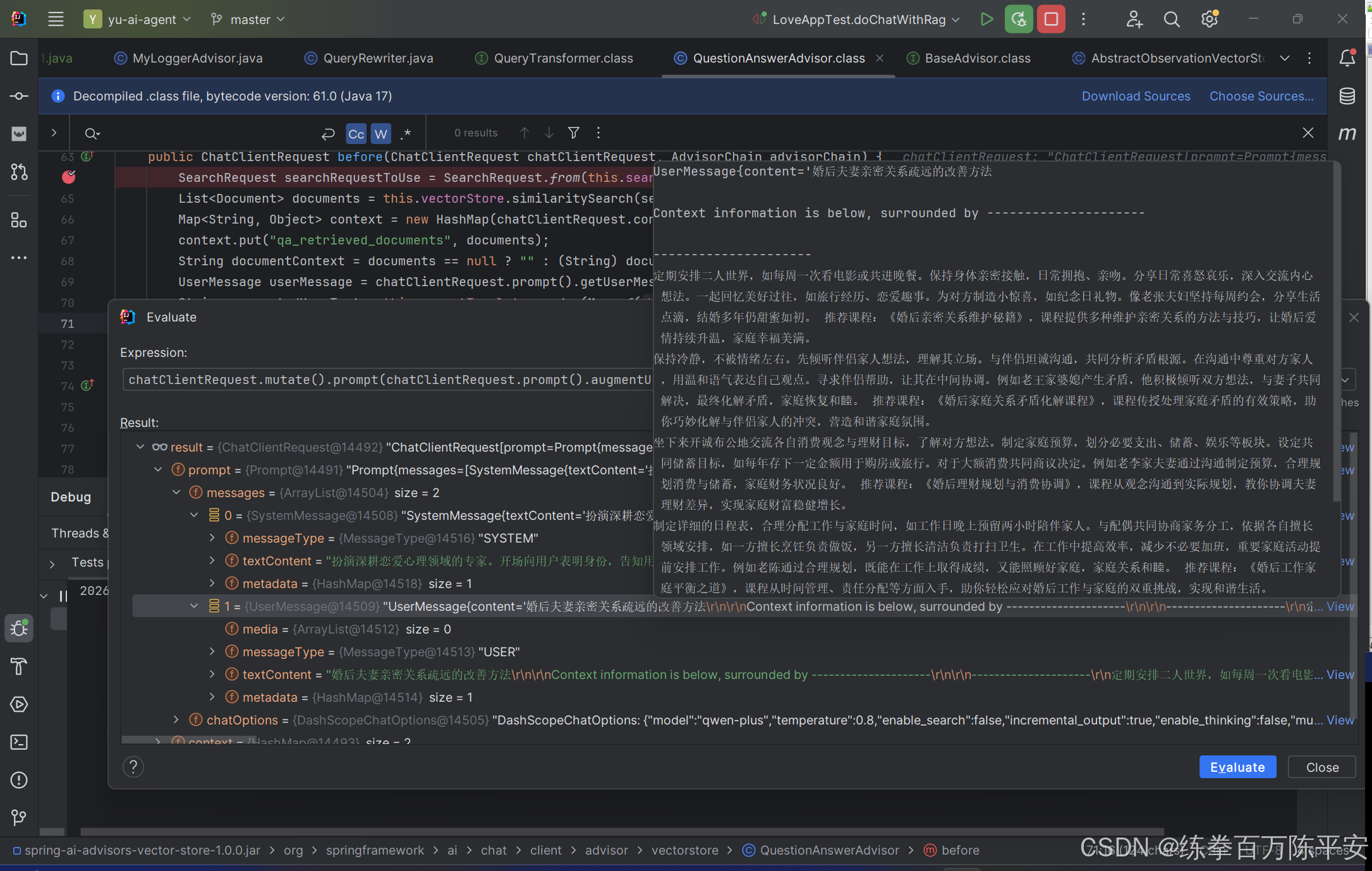
从结果上看,在QuestionAnswerAdvisor这个拦截器当中已经将检索到的知识拼接到了userMessage当中,SpringAI提供的这个类,提供了完整的检索、拼接能力。
六:总结
实际开发过程中,这种方式极少使用,额外占用很多的JVM内存,接下来,我们要采用云知识库进行存储。