
🔥小叶-duck:个人主页
❄️个人专栏:《Data-Structure-Learning》《C++入门到进阶&自我学习过程记录》
《算法题讲解指南》--优选算法
《算法题讲解指南》--递归、搜索与回溯算法
《算法题讲解指南》--动态规划算法
✨未择之路,不须回头
已择之路,纵是荆棘遍野,亦作花海遨游
目录
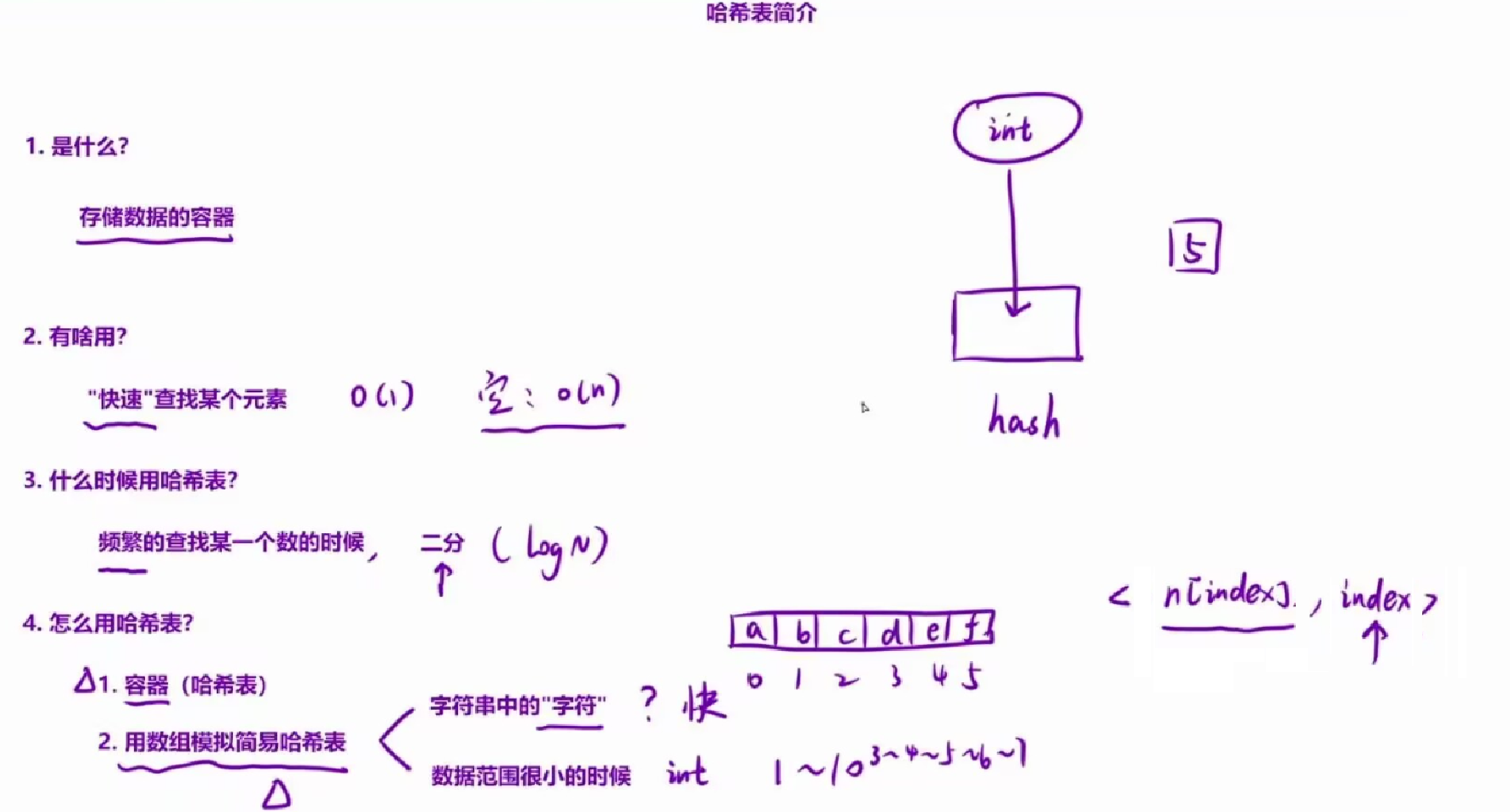
哈希表简介:
56.两数之和
题目链接:
题目描述:

题目示例:

解法(哈希表):
算法思路:
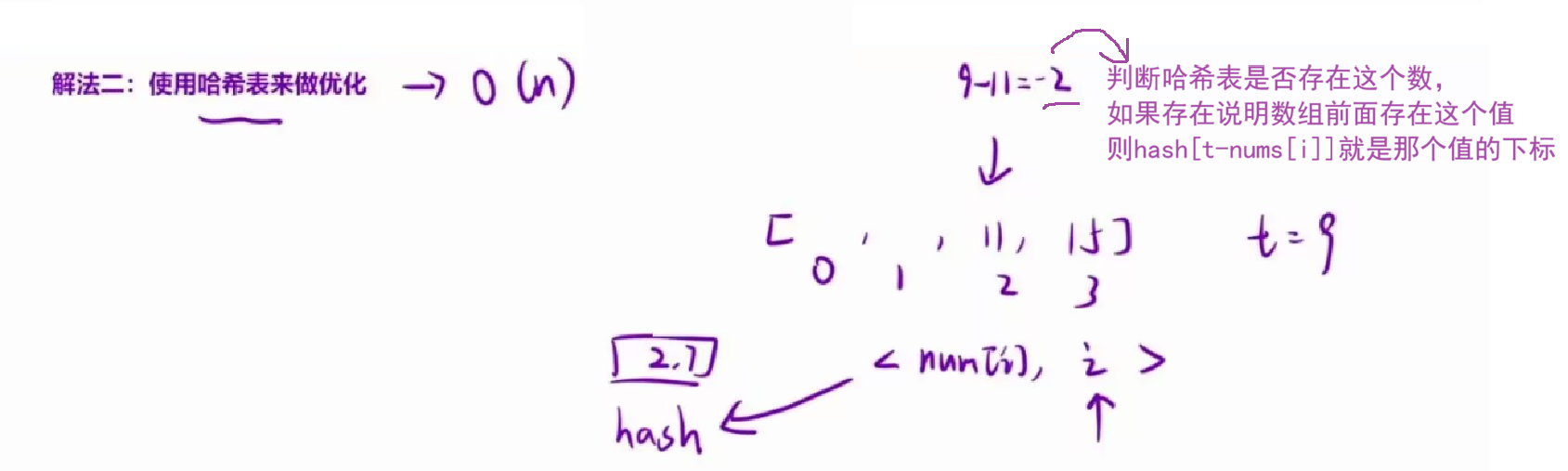
如果我们可以事先将「数组内的元素」和「下标」绑定在一起存入「哈希表」中,然后直接在哈希表中查找每一个元素的target-numsi,就能快速的找到「目标和的下标」。
这里有一个小技巧,我们可以不用将元素全部放入到哈希表之后,再来二次遍历(因为要处理元素、相同的情况)。而是在将元素放入到哈希表中的「同时」,直接来检查表中是否已经存在当前元素所对应的目标元素(即target-numsi)。如果它存在,那我们已经找到了对应解,并立即将其返回。无需将元素全部放入哈希表中,提高效率。
因为哈希表中查找元素的时间复杂度是0(1),遍历一遍数组的时间复杂度为0(N),因此可以
将时间复杂度降到 O(N)。
这是一个典型的「用空间交换时间」的方式。
C++算法代码(暴力枚举):
cpp
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target)
{
//解法一:暴力枚举(时间复杂度:O(N^2) )
int n = nums.size();
for(int i = 0; i < n; i++)
{
for(int j = i + 1; j < n; j++)
{
if(nums[i] + nums[j] == target)
{
return {i, j};
}
}
}
return {};
}
};C++算法代码(哈希表):
cpp
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target)
{
//解法二:哈希表
int n = nums.size();
unordered_map<int, int> hash; //<nums[i], i>
//将数组每个值放入哈希表中,并且对应的值(value)是下标
for(int i = 0; i < n; i++)
{
if(hash.count(target - nums[i]))
{
return {hash[target - nums[i]], i};
//hash[target - nums[i]]对应的就是前面一个值的下标
}
else
{
//为0则说明前面没有值和nums[i]相加为target
//则插入哈希表
hash[nums[i]] = i;
}
}
return {};
}
};算法总结及流程解析:

57.判断是否互为字符重排
题目链接:
题目描述:

题目示例:

解法(哈希表):
算法思路:
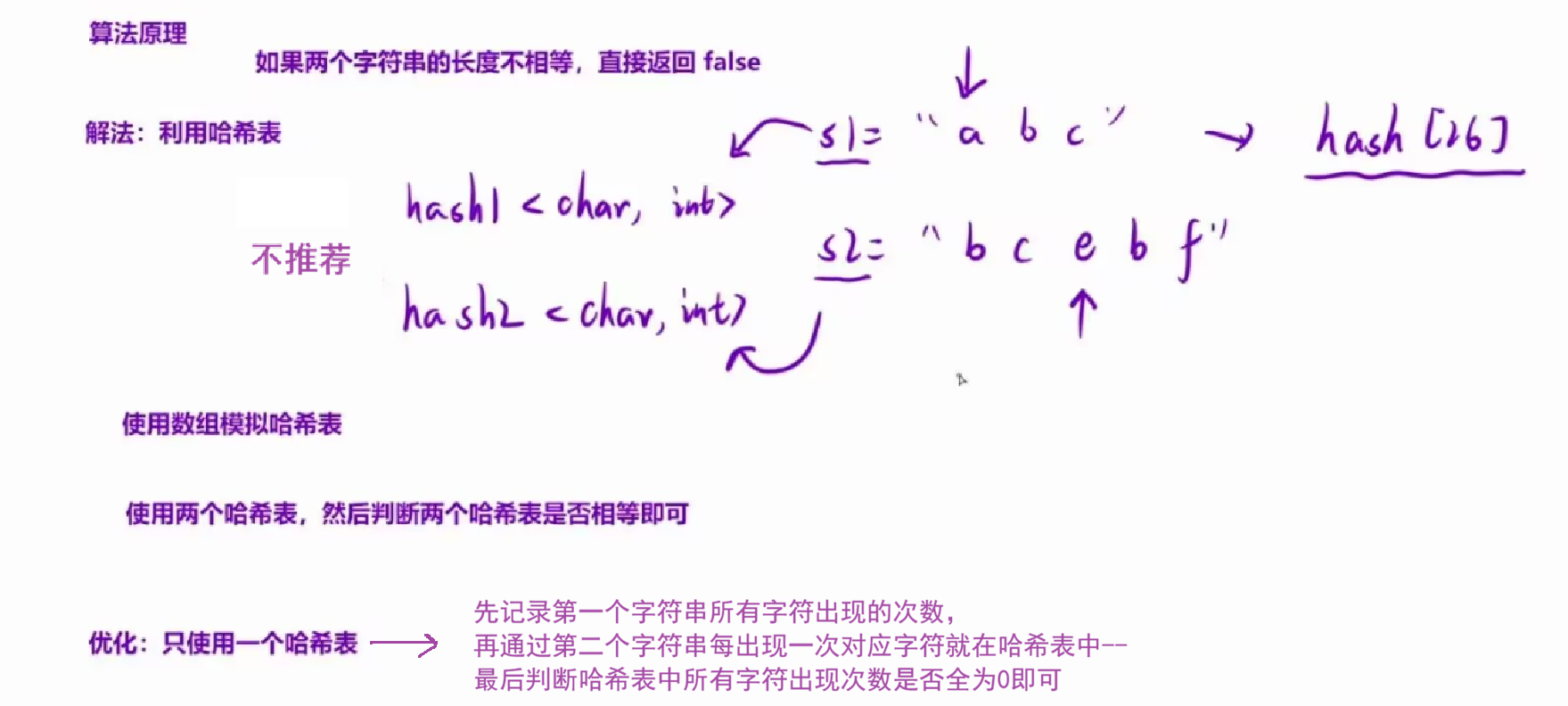
1.当两个字符串的长度不相等的时候,是不可能构成互相重排的,直接返回 false;
2.如果两个字符串能够构成互相重排,那么每个字符串中「各个字符」出现的「次数」一定是相同的。因此,我们可以分别统计出这两个字符串中各个字符出现的次数,然后逐个比较是否相等即可。这样的话,我们就可以选择「哈希表」来统计字符串中字符出现的次数。
C++算法代码(两个哈希表):
cpp
class Solution {
public:
bool CheckPermutation(string s1, string s2)
{
//解法:两个哈希表
int hash1[26] = {0};
int hash2[26] = {0};
for(int i = 0; i < s1.size(); i++)
{
hash1[s1[i] - 'a']++;
}
for(int i = 0; i < s2.size(); i++)
{
hash2[s2[i] - 'a']++;
}
for(int i = 0; i < 26; i++)
{
if(hash1[i] != hash2[i])
{
return false;
}
}
return true;
}
};C++算法代码(优化:一个哈希表):
cpp
class Solution {
public:
bool CheckPermutation(string s1, string s2)
{
//优化:一个哈希表
if(s1.size() != s2.size())
{
return false;
}
int hash[26] = {0};
for(int i = 0; i < s1.size(); i++)
{
hash[s1[i] - 'a']++;
}
for(int i = 0; i < s2.size(); i++)
{
hash[s2[i] - 'a']--;
}
for(int i = 0; i < 26; i++)
{
if(hash[i] != 0)
{
return false;
}
}
return true;
}
};算法总结及流程解析:
结束语
到此,56.两数之和,57.判断是否互为字符重排 这两道算法题就讲解完了。两数之和,对比了暴力枚举(O(n²))和哈希表(O(n))两种解法,后者通过空间换时间优化效率;判断是否互为字符重排,通过统计字符出现次数进行比较,提供了使用两个哈希表和优化为一个哈希表的两种实现方式。希望大家能有所收获!