文章目录
- [Redis 对象编码(Object Encoding)](#Redis 对象编码(Object Encoding))
-
- [1. zset(有序集合)](#1. zset(有序集合))
- [2. set(集合)](#2. set(集合))
- [3. hash(哈希)](#3. hash(哈希))
- [4. list(列表)](#4. list(列表))
- [5. string(字符串)](#5. string(字符串))
- 为什么redis中字符串选择64个字节作为分界线
- 编码转换规则
- IO多线程的优化
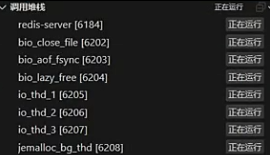
redis的线程
redis的源码用C编写,在vscode启动调试可以发现redis启动了多个线程:
redis-server
bio_close_file
bio_aof_fsync
bio_lazy_free
io_thd_1
io_thd_2
io_thd_3
jemalloc_bg_thd
redis的单线程指的是核心业务命令处理单线程
命令处理单线程
单线程的局限
不能有耗时操作:CPU运算,阻塞IO。
对于redis而言会影响性能。
但是仍然不采用多线程的原因:
加锁复杂,且粒度不好控制,频繁的CPU切换会抵消多线程的优势。
redis对耗时操作的处理
io密集型:
磁盘io:fork子进程,异步刷盘
网络io:多个cli,采用了reactor网络模型,或者数据请求返回的量比较大,开启io多线程
cpu密集型:
根据数据的存储特性有数据结构切换功能,分治的方式,渐进的数据迁移。
冲突
redis以hashtable的形式存储数据,选用的hash函数siphash,能够在原key比较接近的情况下,生成差距较大的hash值,让元素分布更加均匀。
有根据负载因子(used/size)的动态扩容机制
如果负载因子>1,翻倍扩容。
正在进行fork时会阻止扩容(rdb,aof复写等情况)。
若负载因子>5,会立即扩容。
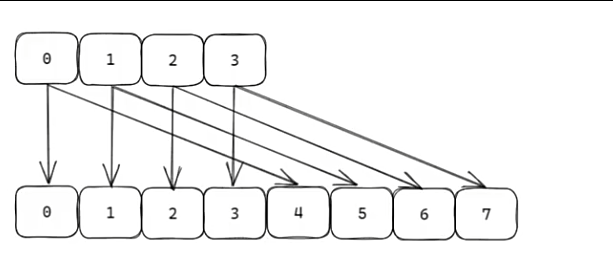
原在0的元素在扩容后要么到0,要么到4。
当负载因子<0.1,会发生缩容,缩容的规则是恰好包含(向上取,10→16)used的2^n。
渐进式rehash
如果原始hashtable的size达到了2g,那么在翻倍扩容时,将会十分耗时。
步骤:将ht0中的元素重新经过hash函数生成64位整数,再对ht1长度取余,映射到ht1。
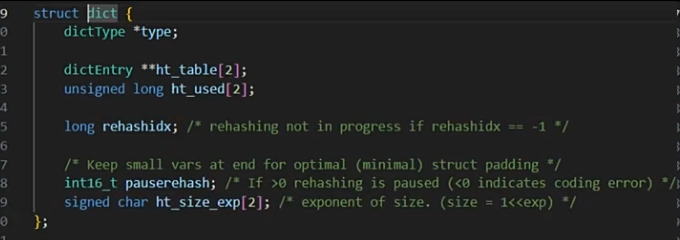
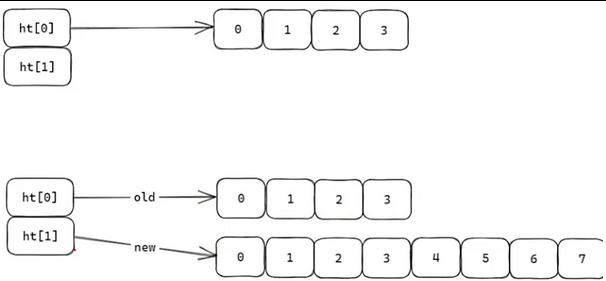
①其中这个迁移过程分摊在增删改查,每有一次请求,伴随指针++,迁移old到new中,直到迁移完毕,释放掉ht0,ht1赋值给ht0,ht1置为nil。
②redis空闲时,使用定时器。每次rehash 1ms。
scan

就算发生
采用高位进位加法的遍历顺序,rehash后的槽位在遍历顺序上是相邻的。scan的目的是从scan那一时刻开始起已经存在的redis中数据进行遍历,就算发生扩容 ,也不会重复和遗漏。
通过连续地调用 SCAN 并使用前一次返回的游标作为下一次的输入,可以遍历整个数据库中的所有键,而不会因为一次性加载太多数据而导致 Redis 服务卡顿。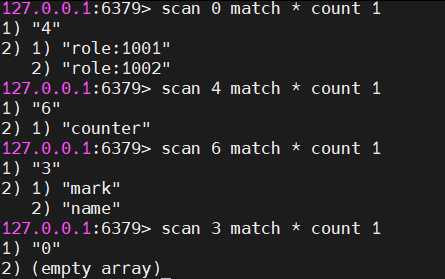
对象编码
Redis 对象编码(Object Encoding)
Redis 为了优化内存使用和性能,对不同数据类型采用不同的底层编码方式。以下是各数据类型的编码规则:
1. zset(有序集合)
| 编码方式 | 条件 |
|---|---|
| skiplist(跳表) | 数量大于 128 或者 有一个字符串长度大于 64 |
| ziplist(压缩列表) | 节点数量小于等于 128(zset-max-ziplist-entries)且 字符串长度小于等于 64(zset-max-ziplist-value) |
理想跳表→概率跳表(1-1/n^2)*Olog2(n)→实践跳表(p = 0.25 n >=128 max_level = 32)
2. set(集合)
| 编码方式 | 条件 |
|---|---|
| intset(整数数组) | 元素都为整数 且 节点数量小于等于 512(set-max-intset-entries) |
| dict(字典) | 元素有一个不为整数 或者 数量大于 512 |
3. hash(哈希)
| 编码方式 | 条件 |
|---|---|
| dict(字典) | 节点数量大于 512 或 字符串长度大于 64 |
| ziplist(压缩列表) | 节点数量小于等于 512(hash-max-ziplist-entries)且 字符串长度小于等于 64(hash-max-ziplist-value) |
4. list(列表)
| 编码方式 | 说明 |
|---|---|
| quicklist(双向链表) | 默认编码方式 |
| ziplist(压缩列表) | 间接使用(作为 quicklist 的节点) |
5. string(字符串)
| 编码方式 | 条件 |
|---|---|
| int | 字符串长度小于等于 20 且 能转成整数 |
| raw | 字符串长度大于 44 |
| embstr | 字符串长度小于等于 44 |
为什么redis中字符串选择64个字节作为分界线
①内存分配器都是按照2^n进行分配的。
②cpu的cache line大小为64字节
为什么string编码方式按44字节来划分?
③redisObject使用16字节
④64字节,需要使用sdshdr8来存储,占用3字节
⑤为了兼容C语言的不安全字符串(strcpy,strlen),预留1字节'/0'
⑥buf可用空间为64 - 16 - 3 - 1
| 参数 | 默认值 | 说明 |
|---|---|---|
zset-max-ziplist-entries |
128 | zset 使用 ziplist 的最大元素数量 |
zset-max-ziplist-value |
64 | zset 使用 ziplist 的最大字符串长度 |
set-max-intset-entries |
512 | set 使用 intset 的最大元素数量 |
hash-max-ziplist-entries |
512 | hash 使用 ziplist 的最大元素数量 |
hash-max-ziplist-value |
64 | hash 使用 ziplist 的最大字符串长度 |
编码转换规则
- 当数据量或字符串长度超过阈值时,会自动从紧凑编码(ziplist/intset/embstr)转换为通用编码(skiplist/dict/raw)
- 转换是单向的,一旦升级为通用编码,不会自动降级回紧凑编码
IO多线程的优化
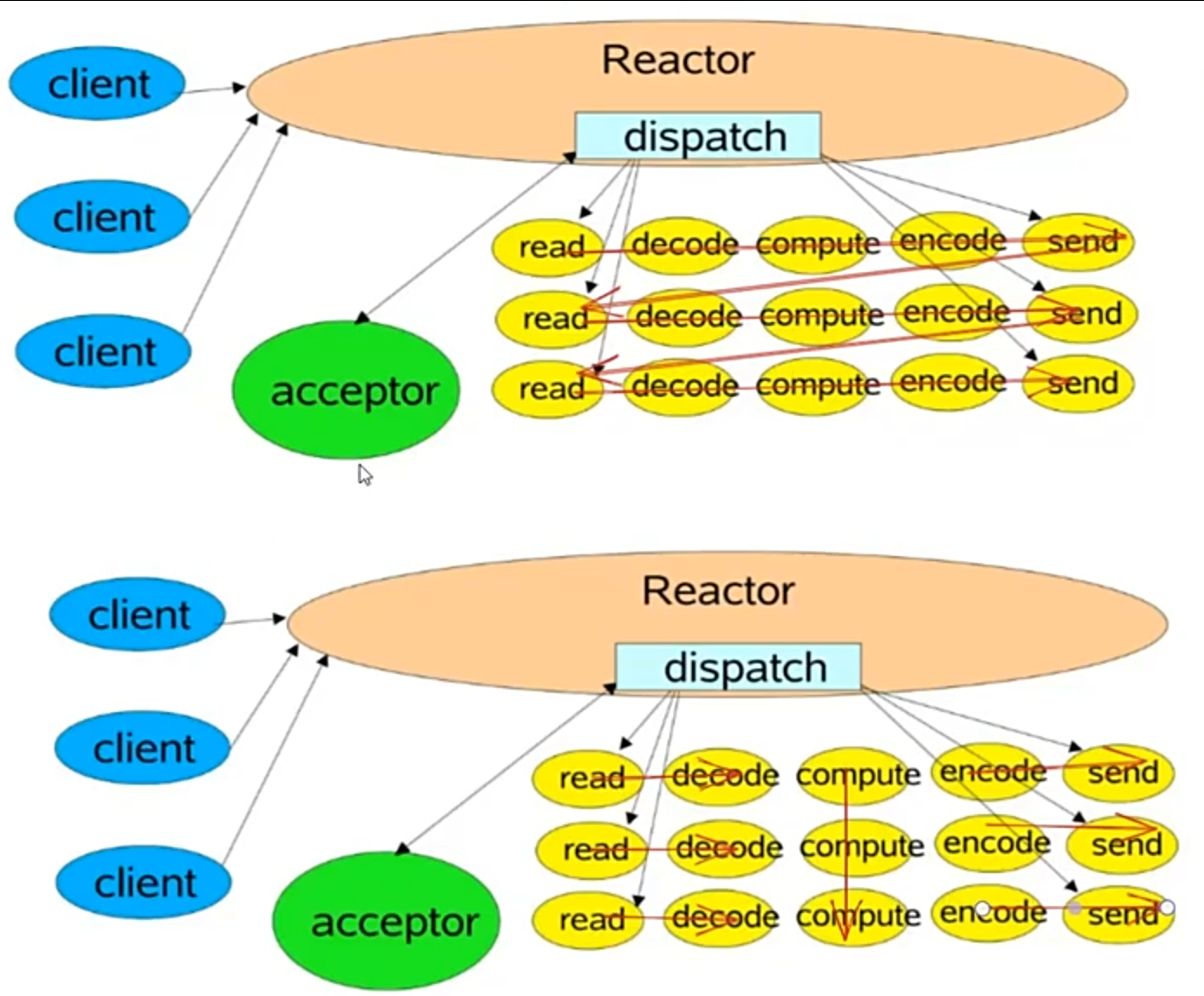
开启IO多线程优化后,所有线程的read→decode视为一个整体串行执行,然后computer(业务逻辑)穿行执行,然后encode→send视为一个整体串行执行