从轨迹到网络:广州休闲步行空间格局刻画 | 论文全解析与方法论拆解
原文:From trajectories to network: Delineating the spatial pattern of recreational walking in Guangzhou》
一、论文核心概览:摘要与关键词
1.1 核心摘要解析
本文的核心内容可拆解为5个核心模块,完整覆盖了研究的全链条逻辑:
- 研究背景:休闲步行已成为城市居民日常生活的核心组成部分,网络结构是刻画其活动模式的关键工具,但现有方法在构建休闲步行网络时,缺乏对空间异质性的考虑,无法精准识别网络「节点」与构建「链接」。
- 研究方法:针对现有研究缺口,修正了网络构建全流程,纳入休闲活动的「自组织」特征,借鉴推荐算法的「资源分配」方法,构建了全新的休闲步行网络分析框架。
- 研究案例:以广州中心城区为研究区,通过修正后的框架,成功捕捉到步行活动显著的空间异质性。
- 核心发现:网络节点呈现出极强的秩规模效应,加权聚类系数极低;通过社区检测识别出7个独立的休闲步行社区,完整勾勒出活动的宏观空间结构。
- 研究价值:验证了该网络分析方法可直接用于编制规划专题图,同时能提升城市规划方案的事前评估能力。
1.2 关键词解读
结合论文研究内容,对5个核心关键词的内涵进行精准解读:
- Recreational walking(休闲步行):本文中特指以锻炼、休闲游憩为目的的步行行为,本质由多个目的地(节点)和目的地间的步行路径(链接)组成,具有强自组织、非强制性的特征。
- Movement trajectory(移动轨迹):本文的核心数据源,为带时间戳的步行GPS轨迹,属于志愿地理信息(VGI),是提取节点、构建链接的基础。
- Spatial configuration(空间构型):特指休闲步行活动在空间上的分布、聚集与关联特征,核心体现为空间异质性,是本文方法重点适配的核心属性。
- Network analysis(网络分析):本文的核心研究方法,基于复杂网络理论,从局部、全局、社区三个维度,完整刻画休闲步行网络的结构特征。
- Planning practice(规划实践):本文的核心落地目标,将网络分析结果转化为可直接应用于城市规划的工具与策略,填补了现有研究理论与实践脱节的缺口。
二、引言:研究背景与核心科学问题
2.1 研究背景与意义
休闲步行早已成为城市规划领域的核心关注方向。自上世纪80年代以来,城市居民休闲时间大幅增加,对休闲活动的需求快速提升,休闲步行逐渐成为居民日常生活的重要组成部分,也推动了绿道等线性休闲空间的规划建设。
从本质上看,单次休闲步行行为可被抽象为一个极简网络:节点对应休闲目的地(广场、公园等),链接对应目的地之间的步行路径,而休闲步行网络,就是无数单次行为网络的集合表征。基于这一本质,复杂网络等网络理论与方法,成为研究休闲步行行为的核心量化工具,能帮助研究者深度挖掘步行行为的空间特征,为规划决策提供支撑。
2.2 现有研究的三大核心缺陷
论文通过梳理现有休闲活动网络相关研究,精准指出了传统框架的三大核心缺陷,也是本文的核心立论基础:
- 节点定义的缺陷:传统方法采用「自上而下」的模式,基于官方或平台推荐的景点列表定义网络节点。但休闲活动本质具有「自组织」特征,居民可自主决定休闲的时间、地点与方式,具有极强的自由性与不确定性。传统方法极易遗漏那些小众但居民实际高频使用的休闲节点,导致后续网络分析结果失真。
- 链接定义的缺陷:现有研究普遍采用「共现法」定义链接,即单条轨迹经过两个节点,就在节点间建立一条权重+1的链接。但该方法存在致命逻辑漏洞:单条轨迹经过的节点越多,生成的链接越多,该轨迹对网络的总贡献就越大,违背了「每条轨迹对网络的贡献应完全平等」的基本原则,导致链接权重计算严重失真。
- 实践应用的缺陷:现有研究大多聚焦于网络的空间分布与形态刻画,部分研究通过回归、机器学习等方法探索网络格局的形成机制,或用于路线推荐,但极少有研究探讨休闲步行网络在实际规划项目中的落地应用,导致理论研究与规划实践脱节,限制了该领域的后续发展。
2.3 研究问题与核心贡献
基于上述研究缺口,论文提出了核心研究问题:如何科学合理地构建休闲步行网络?该网络分析结果能通过哪些方式应用于城市规划实践项目?
围绕这一问题,论文形成了两大核心贡献:
- 方法层面:突破传统框架,构建了一套优化的休闲步行网络构建框架,修正了节点与链接定义流程的核心缺陷,同时兼顾了休闲活动的「自组织」特征与轨迹间的「资源分配」公平性。
- 实践层面:以广州中心城区为案例,不仅挖掘了休闲步行网络的核心特征,还系统阐述了网络分析结果在城市规划项目中的实际应用路径,实现了理论研究与规划实践的深度融合。
三、研究设计:研究区与数据预处理
3.1 研究区概况
本文的研究区为广州中心城区,具体包括天河区、海珠区、越秀区、荔湾区全域,以及白云区的部分区域。
- 广州是中国核心经济中心城市之一,2021年常住人口超1800万,中心城区人口高度集聚,对高品质休闲步行空间的需求极为旺盛,研究具有极强的现实必要性。
- 该区域已有多项步行相关建成环境的研究成果,进一步证明了研究区的典型性与代表性。
3.2 数据源与数据预处理
3.2.1 核心数据源
本文的核心数据来自户外轨迹记录平台2bulu,该平台支持用户记录户外休闲步行轨迹,并上传至开放平台共享。
- 数据时间跨度:2018年1月-2022年12月,共5年;
- 原始数据规模:86543条原始GPS轨迹;
- 数据可靠性:该数据属于志愿地理信息(VGI),已有大量国内外学者将其用于休闲活动相关研究,数据有效性与可靠性已得到充分验证;同时,数据由用户自主上传,能最大程度规避隐私安全问题。
- 数据结构:每条轨迹包含两部分核心内容,一是带时间戳的连续地理坐标点序列,二是轨迹ID、用户ID、轨迹类型等基础属性信息。
3.2.2 数据清洗流程
针对GPS定位固有的精度误差,论文设计了分阶段的严格数据清洗流程,最终得到76460条有效休闲步行轨迹,包含6807226个GPS数据点,单条轨迹平均包含89个地理记录。
- 重复数据剔除:移除同一条轨迹内重复的时间戳与地理记录,解决APP运行报错、手机信号丢失导致的重复数据问题。
- 异常轨迹剔除 :分为空间误差与时间误差两类异常值进行剔除:
- 空间误差:连续GPS点之间出现异常长距离跳变,即非步行可达的不合理轨迹段;
- 时间误差:相邻GPS点之间出现异常长时间间隔,导致数据连续性断裂。
- 非步行轨迹过滤 :通过速度阈值筛选有效步行轨迹,设置平均速度<6km/h、最大速度<8km/h的阈值,剔除骑行等非步行轨迹。
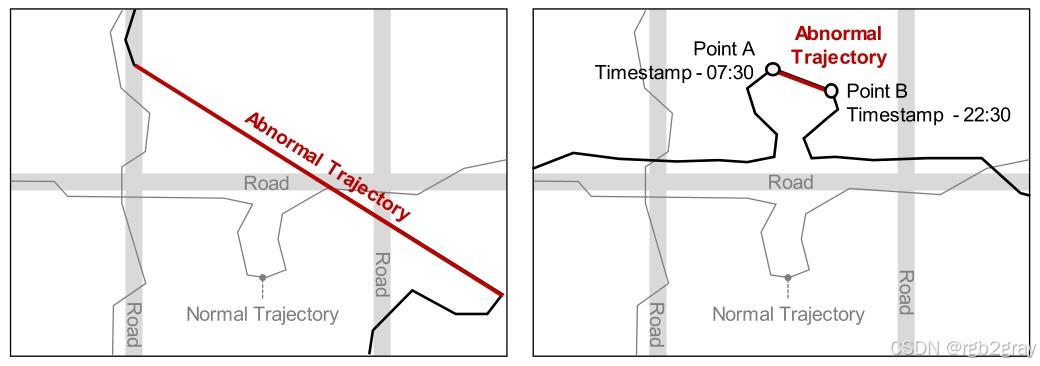
对应图3 轨迹数据的空间与时间误差 解读:
图3直观展示了轨迹数据的两类典型异常场景。左侧的异常轨迹出现了跨道路的长距离坐标跳变,属于典型的空间误差,由GPS定位漂移导致;右侧的异常轨迹在两个坐标点之间出现了从07:30到22:30的超长时间间隔,属于时间误差,由设备休眠、信号中断导致。论文通过严格的清洗规则剔除了这类异常数据,为后续分析奠定了高质量的数据基础。
四、核心方法论:休闲步行网络构建全流程(重点深度拆解)
这是论文的核心创新部分,整体分为三大核心步骤:自下而上的网络节点捕获 、基于资源分配的网络链接定义 、基于复杂网络理论的网络特征分析,最终构建出加权无向的休闲步行网络。
4.1 步骤一:基于GPS轨迹的网络节点捕获
传统方法采用「自上而下」的官方景点/POI列表定义节点,完全忽略了休闲活动的自组织特征。论文采用自下而上的方法,从用户实际步行轨迹中提取节点,核心逻辑是:休闲活动数据密集聚集的区域,就是居民实际选择的休闲热点,即网络的核心节点。
整个节点捕获过程分为两个核心阶段:休闲步行中的停留行为检测 、基于TIN模型的停留行为高密度区域识别。
4.1.1 阶段1:休闲步行中的停留行为检测
停留行为是揭示个体空间偏好的核心指标,论文基于时空预算理论,从空间、时间两个维度定义停留行为,核心是空间范围约束+时间时长约束的双重判定标准。
首先,对单条步行轨迹进行数学定义:
T={p1,p2,p3,...,pn}(1)T=\left\{p_{1}, p_{2}, p_{3}, ..., p_{n}\right\} \tag{1}T={p1,p2,p3,...,pn}(1)
其中,轨迹TTT由nnn个带时间戳的GPS点组成,每个轨迹点pip_ipi的完整结构为:
pi={xi,yi,ti},0<i≤n(2)p_i=\{x_i, y_i, t_i\}, 0<i \leq n \tag{2}pi={xi,yi,ti},0<i≤n(2)
式中,xi,yix_i,y_ixi,yi为轨迹点的地理坐标,tit_iti为该点对应的时间戳。
在此基础上,论文定义了识别停留行为的两大核心准则:
准则1:空间距离约束
Distance(pi,pk)≤Dr,Distance(pi,pk+1)>Dr,0<i<k≤n(3)Distance \left(p_{i}, p_{k}\right) \leq D_{r}, Distance \left(p_{i}, p_{k+1}\right)>D_{r}, 0<i<k \leq n \tag{3}Distance(pi,pk)≤Dr,Distance(pi,pk+1)>Dr,0<i<k≤n(3)
准则2:时间时长约束
Time(pi,pk)≥Tr,0<i<k≤n(4)Time \left(p_{i}, p_{k}\right) \geq T_{r}, 0<i<k \leq n \tag{4}Time(pi,pk)≥Tr,0<i<k≤n(4)
公式参数详细解释:
- DrD_rDr为空间距离阈值,论文中设置为250m,即连续的轨迹点需全部落在250m半径的空间范围内;
- TrT_rTr为时间时长阈值,论文中设置为20分钟,即用户在该空间范围内的累计停留时长不少于20分钟;
- 同时满足上述两个准则的连续轨迹点集合,即为一次有效停留行为Tstay={pi,pi+1,...,pk}T_{stay}=\{p_i,p_{i+1},...,p_k\}Tstay={pi,pi+1,...,pk};
- 最终将该次停留行为抽象为一个停留点PstayP_{stay}Pstay ,其坐标与时间戳为该次停留行为内所有轨迹点的算术平均值。
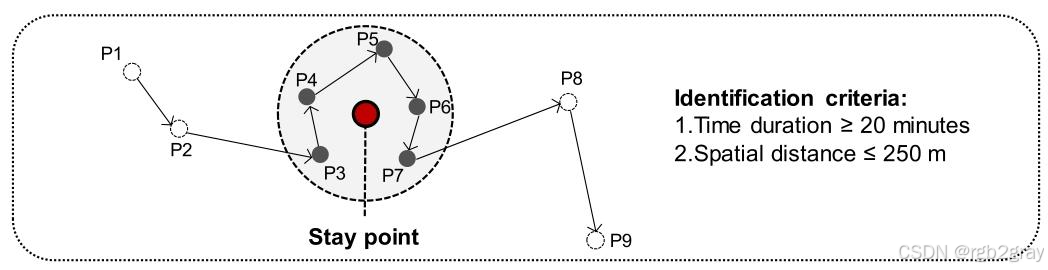
对应图4 从GPS轨迹中捕获停留行为 解读:
图4完整展示了停留行为的检测逻辑与流程。轨迹点P1P_1P1到P8P_8P8中,P3P_3P3到P7P_7P7的连续点满足「250m空间范围约束+20分钟停留时长约束」的双重标准,因此被识别为一次有效停留行为,最终被抽象为一个停留点P9P_9P9。通过该方法,论文将连续的步行轨迹,转化为离散的、代表用户实际休闲停留的空间点位,为后续网络节点识别奠定了核心基础。
4.1.2 阶段2:基于TIN模型的停留行为高密度区域识别
识别出全研究区的停留点后,需要找到停留点的高密度聚集区,即最终的网络节点。传统DBSCAN等聚类算法源于计算机科学,缺乏对地理空间异质性的考虑,聚类参数的确定存在极强的主观性。论文基于自然城市理论 ,采用不规则三角网(TIN)模型完成高密度区域识别,完美适配地理数据的重尾分布与空间异质性特征。
(1)方法的前提假设与验证
自然城市理论的核心是:地理实体的空间密度分布天然呈现重尾分布特征,即低密度区域的数量远多于高密度区域,统计学上表现为幂律分布。只有满足该前提,才能使用基于均值的TIN模型进行聚类。
论文通过两个核心参数验证重尾分布特征:
- 幂律分布的标度指数α\alphaα:采用Clauset等提出的最大似然法计算,若α∈1,3\alpha \in 1,3α∈1,3,则数据符合幂律分布;
- ht-index(头/尾 breaks指数):表征重尾分布的层级结构,若ht-index>3,则数据具有显著的重尾特征。
(2)TIN模型的四步执行流程
论文基于Jiang等提出的TIN模型,设计了四步聚类流程,最终得到有效网络节点:
步骤1:构建不规则三角网
以研究区内所有停留点为顶点,构建Delaunay不规则三角网(TIN),将整个研究区划分为连续的、互不重叠的三角形面片,三角网的边连接了空间上相邻的停留点。
步骤2:过滤短边,生成初始面片
计算所有TIN边的平均长度,过滤掉长度小于均值的边,将保留的短边转换为三角形多边形集合。核心逻辑是:三角网的边长度越短,代表两个停留点的空间距离越近,聚集性越强,因此通过均值阈值筛选出高密度的相邻点对。
步骤3:合并面片,生成初始聚类
将空间上相邻的三角形多边形合并为连续的面片,面片的顶点即为聚集的停留点,由此生成初始的停留点聚类。
步骤4:确定最小点数阈值,生成最终网络节点
引入最小点数阈值MinptsMinptsMinpts,剔除仅包含少量停留点的无效聚类,只有点数≥MinptsMinptsMinpts的初始聚类,才能被认定为最终的网络节点(休闲热点)。
MinptsMinptsMinpts的启发式计算方法参考DBSCAN算法,避免参数设置的主观性:
Minpts≈ln(n)(5)Minpts\approx ln (n) \tag{5}Minpts≈ln(n)(5)
其中,nnn为数据集中所有停留点的总数。该公式为MinptsMinptsMinpts提供了合理的取值参考,同时论文也说明,若有更合理的解释,可对MinptsMinptsMinpts进行灵活调整。
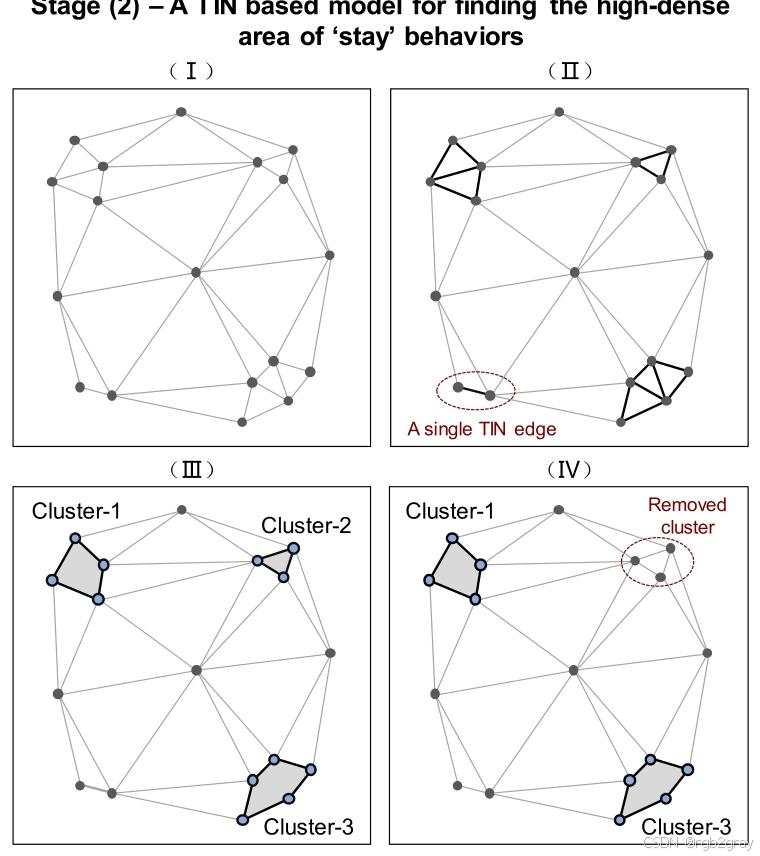
对应图5 TIN模型捕获节点的流程 解读:
图5分四个子图完整展示了TIN模型的执行过程:
(I) 基于所有停留点构建完整的Delaunay TIN三角网;
(II) 计算所有边的平均长度,过滤掉长边,仅保留代表高密度聚集的短边;
(III) 保留的短边形成了多个离散的三角形面片集合,对应3个初始聚类;
(IV) 合并相邻面片,结合MinptsMinptsMinpts阈值筛选,最终得到3个有效的网络节点聚类。
该方法完全基于数据本身的空间分布特征,无需人为预设聚类半径,完美适配了休闲活动的空间异质性。
4.2 步骤二:基于资源分配的共现方法定义网络链接
节点确定后,需要定义节点之间的链接(边)。传统方法采用共现法,即单条轨迹经过两个节点,就在两个节点之间建立一条链接,权重+1。但该方法存在核心缺陷:单条轨迹经过的节点越多,生成的链接越多,该轨迹对网络的贡献就越大,违背了「每条轨迹对网络的贡献平等」的基本原则。
论文借鉴推荐算法中的资源分配思想,对传统共现法进行了系统性改进,核心逻辑是:为每条轨迹分配总权重为1的「资源」,资源按照轨迹在各个节点内的长度占比进行分配,再基于分配后的资源计算节点间的链接权重,保证每条轨迹对网络的总贡献恒为1。
4.2.1 传统共现法的核心缺陷
用论文中的典型示例说明传统方法的逻辑漏洞:
- 轨迹α经过节点A、B、C,传统方法生成A-B、A-C、B-C三条链接,每条权重+1,轨迹α对网络的总贡献为3;
- 轨迹β仅经过节点A、B,传统方法生成A-B一条链接,权重+1,轨迹β对网络的总贡献为1;
- 两条轨迹的贡献完全不对等,轨迹α的影响力被无理由放大了3倍,最终导致节点间的链接权重计算严重失真。
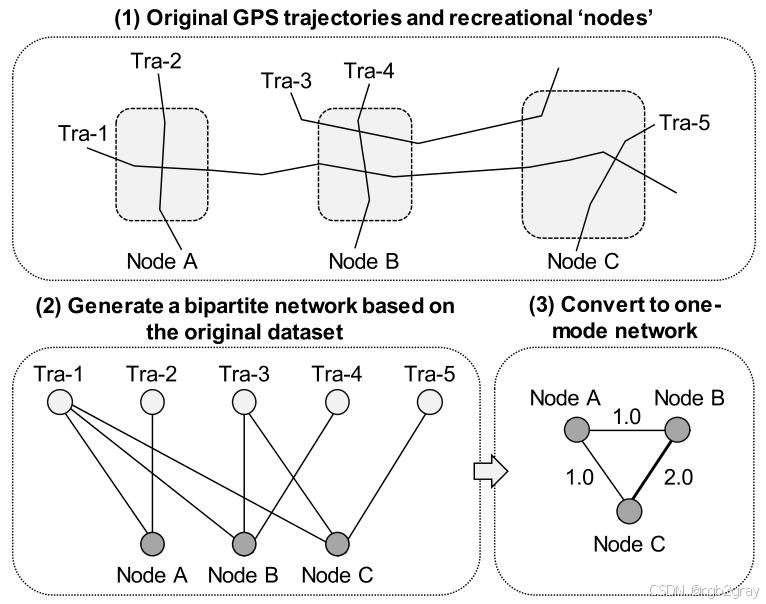
对应图6 传统共现法定义网络链接的流程 解读:
图6展示了传统共现法的三步执行逻辑:
- 输入原始GPS轨迹与预定义的休闲节点;
- 基于轨迹与节点的关联关系,构建「轨迹-节点」二分网络;
- 将二分网络投影为「节点-节点」的一模网络,节点间的链接权重由共同经过的轨迹数量决定。
该方法流程简单、计算便捷,但完全忽略了轨迹间的平等性,是论文重点修正的核心问题。
4.2.2 改进的资源分配共现法
论文的改进方法分为两大核心步骤,从根本上解决了传统方法的缺陷:
步骤1:构建「轨迹-节点」二分网络矩阵
首先,统计每条轨迹在每个节点范围内的轨迹长度,构建「轨迹-节点」二分网络矩阵,如下表所示:
| 轨迹\节点 | Node-1 | Node-2 | ... | Node-m |
|---|---|---|---|---|
| Trajectory-1 | L1,1L_{1,1}L1,1 | L1,2L_{1,2}L1,2 | ... | L1,mL_{1,m}L1,m |
| Trajectory-2 | L2,1L_{2,1}L2,1 | L2,2L_{2,2}L2,2 | ... | L2,mL_{2,m}L2,m |
| ... | ... | ... | ... | ... |
| Trajectory-n | Ln,1L_{n,1}Ln,1 | Ln,2L_{n,2}Ln,2 | ... | Ln,mL_{n,m}Ln,m |
其中,Li,aL_{i,a}Li,a表示第i条轨迹在第a个节点范围内的长度 ,∑mLi,m\sum_{m} L_{i,m}∑mLi,m表示第i条轨迹在所有节点范围内的累计总长度。
步骤2:基于资源分配计算节点间链接权重
首先,计算单条轨迹iii对节点aaa和节点bbb之间链接的贡献值:
Lab,i=Li,a∑mLi,m×Li,b∑mLi,m(6)L_{a b, i}=\frac{L_{i, a}}{\sum_{m} L_{i, m}} × \frac{L_{i, b}}{\sum_{m} L_{i, m}} \tag{6}Lab,i=∑mLi,mLi,a×∑mLi,mLi,b(6)
公式核心逻辑解读:
- 为每条轨迹iii分配总权重为1的资源,资源按照轨迹在各节点内的长度占比Li,a∑mLi,m\frac{L_{i,a}}{\sum_{m} L_{i,m}}∑mLi,mLi,a,分配给各个节点;
- 节点aaa和节点bbb之间的链接权重,由两个节点获得的资源占比相乘得到,本质是两个节点在该条轨迹中的关联强度;
- 单条轨迹iii对所有链接的总贡献之和恒≤1,从根本上保证了所有轨迹对网络的贡献平等,解决了传统方法的权重失真问题。
在此基础上,节点aaa和节点bbb之间的最终链接权重,为所有轨迹对该链接贡献值的总和:
Lab=∑i=1nLab,i(7)L_{a b}=\sum_{i=1}^{n} L_{a b, i} \tag{7}Lab=i=1∑nLab,i(7)
其中,nnn为有效轨迹的总数。通过该方法,论文最终构建出加权无向的休闲步行网络。
4.3 步骤三:休闲步行网络特征分析体系
论文基于复杂网络理论,从局部特征参数 、全局特征参数 、社区检测三个维度,构建了完整的网络分析体系,全面刻画休闲步行网络的结构特征。
4.3.1 局部特征参数:节点重要性评价
局部参数聚焦单个节点的特征,论文选取4个核心中心性指标,量化节点在网络中的重要性,所有指标均归一化至0,1区间。
| 参数名称 | 计算公式 | 核心含义 |
|---|---|---|
| 度中心性(Degree centrality, DC) | DCi=LiN−1DC_i = \frac{L_i}{N-1}DCi=N−1Li | 节点iii连接的其他节点数量占总节点数的比例,反映节点的直接连通能力,值越高,节点的直接关联节点越多 |
| 特征向量中心性(Eigenvector centrality, EC) | ECi=k1−1∑jAijxjEC_i = k_1^{-1}\sum_j A_{ij}x_jECi=k1−1∑jAijxj | 不仅考虑节点自身的连接数,还考虑邻接节点的重要性,值越高,节点越容易与网络中的核心节点产生关联 |
| 接近中心性(Closeness centrality, CC) | CCi=1N−1∑j≠i1dijCC_i = \frac{1}{N-1}\sum_{j \neq i} \frac{1}{d_{ij}}CCi=N−11∑j=idij1 | 节点到网络中所有其他节点的最短路径长度的倒数均值,值越高,节点在网络中的可达性越强,越接近网络的几何中心 |
| 介数中心性(Betweenness centrality, BC) | BCi=1N2∑stnstigstBC_i = \frac{1}{N^2}\sum_{st} \frac{n_{st}^i}{g_{st}}BCi=N21∑stgstnsti | 网络中所有节点对的最短路径中,经过节点iii的路径占比,反映节点的桥梁作用,值越高,节点对网络中流量的控制能力越强 |
公式参数说明:
- NNN为网络中总节点数,LiL_iLi为节点iii的连接数;
- AijA_{ij}Aij为节点iii和jjj的邻接矩阵,k1−1k_1^{-1}k1−1为邻接矩阵的最大特征值;
- dijd_{ij}dij为节点iii和jjj之间的最短路径长度;
- gstg_{st}gst为节点sss和ttt之间的最短路径总数,nstin_{st}^insti为其中经过节点iii的路径数量。
4.3.2 全局特征参数:网络整体结构评价
全局参数聚焦整个网络的拓扑结构特征,论文选取6个核心指标,对比分析了加权与未加权网络的特征差异。
| 参数名称 | 计算公式 | 核心含义 |
|---|---|---|
| 网络密度(Network density) | 未加权:Δ=2Lg(g−1)\Delta = \frac{2L}{g(g-1)}Δ=g(g−1)2L 加权:Δn=2LLmax\Delta_n = \frac{2L}{L_{max}}Δn=Lmax2L | 反映网络中节点间的连接紧密程度,值越高,网络整体连通性越强。LLL为链接总数/总权重,ggg为节点数,LmaxL_{max}Lmax为加权网络的理论最大总权重 |
| 网络效率(Network efficiency, η) | η=1N(N−1)∑i≠j1dij\eta = \frac{1}{N(N-1)}\sum_{i \neq j} \frac{1}{d_{ij}}η=N(N−1)1∑i=jdij1 | 反映网络中节点间信息/流量传递的效率,值越高,节点间的可达性越好 |
| 传递性(Transitivity, T) | T=3TΔT3T = \frac{3T_\Delta}{T_3}T=T33TΔ | 反映网络中三角形闭合结构的占比,值越高,网络的局部聚集性越强。TΔT_\DeltaTΔ为网络中三角形的数量,T3T_3T3为三元组的数量 |
| 聚类系数(Clustering coefficient, CWSC_{WS}CWS) | 未加权:CWS=1N∑i=1N2NLiDCi×(DCi−1)C_{WS} = \frac{1}{N}\sum_{i=1}^N \frac{2NL_i}{DC_i \times (DC_i - 1)}CWS=N1∑i=1NDCi×(DCi−1)2NLi 加权:基于Onnela等的方法计算 | 反映节点的邻接节点之间相互连接的概率,值越高,网络的局部抱团特征越明显 |
4.3.3 社区检测:网络空间聚类结构识别
论文采用贪婪模块度最大化算法 进行社区检测,该算法是复杂网络社区检测中最经典、应用最广泛的方法之一,核心是通过最大化模块度QQQ,将网络划分为多个「内部连接紧密、外部连接稀疏」的社区。
首先,模块度QQQ的计算公式:
Q=12m∑ij(Aij−kikj2m)δ(ci,cj)(8)Q=\frac{1}{2 m} \sum_{i j}\left(A_{i j}-\frac{k_{i} k_{j}}{2 m}\right) \delta\left(c_{i}, c_{j}\right) \tag{8}Q=2m1ij∑(Aij−2mkikj)δ(ci,cj)(8)
公式参数详细解释:
- mmm为网络中链接的总数;
- AijA_{ij}Aij为节点iii和jjj之间的实际链接权重;
- kikj2m\frac{k_i k_j}{2m}2mkikj为随机网络中节点iii和jjj之间的期望链接权重;
- δ(ci,cj)\delta(c_i,c_j)δ(ci,cj)为克罗内克函数,当节点iii和jjj属于同一个社区时,函数值为1,否则为0;
- 模块度QQQ的取值范围为-1,1,QQQ值越接近1,说明社区划分的效果越好,即社区内部连接越紧密,社区间连接越稀疏。
贪婪算法的核心执行逻辑:
- 初始状态下,每个节点独立为一个社区;
- 迭代尝试将相邻的两个社区合并,计算合并后的模块度变化,选择使模块度增量最大的合并方案;
- 重复迭代过程,直到模块度无法再提升,此时的社区划分即为最终结果。
五、研究结果与可视化分析
论文基于上述方法论,最终构建的广州中心城区休闲步行网络包含109个节点 、3063条链接;链接权重归一化至0-100区间后,均值为0.993,标准差为4.01,呈现出显著的非均匀分布特征。
5.1 重尾分布前提检验
在聚类前,论文首先验证了停留点TIN边长度的重尾分布特征,计算得到α=3.66\alpha=3.66α=3.66,ht-index=8,满足TIN模型的使用前提。
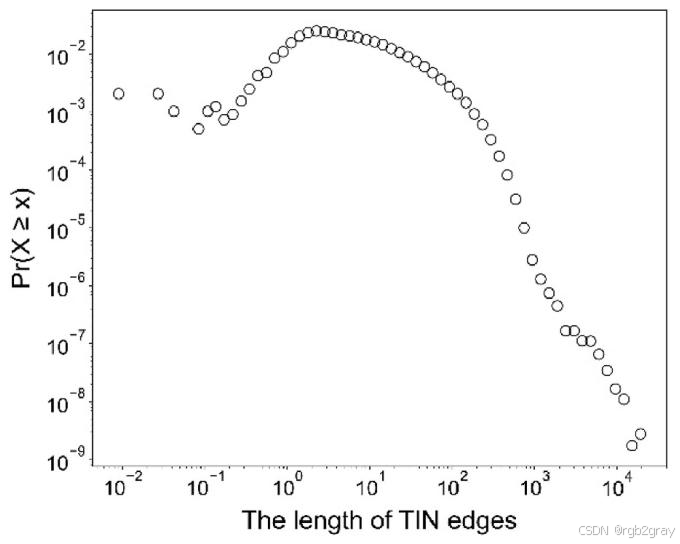
对应图7 TIN聚类模型的前提假设检验 解读:
图7为TIN边长度的双对数坐标分布图,横轴为TIN边的长度,纵轴为对应的频率。从图中可以清晰看到,数据点呈现出显著的线性负相关特征,完美符合幂律分布的统计特征,验证了休闲步行停留行为的空间分布具有强重尾性与空间异质性,为后续TIN聚类提供了扎实的统计基础。
5.2 局部参数分析结果
5.2.1 中心性统计特征
4个核心中心性指标的统计结果如下表所示:
| 参数 | 最小值 | 最大值 | 均值 | 标准差 |
|---|---|---|---|---|
| 度中心性 | 0.0 | 1.0 | 0.143 | 0.156 |
| 接近中心性 | 0.0 | 1.0 | 0.647 | 0.225 |
| 特征向量中心性 | 0.0 | 1.0 | 0.048 | 0.144 |
| 介数中心性 | 0.0 | 1.0 | 0.115 | 0.237 |
核心统计结论:
- 接近中心性的均值和标准差均为最高,说明网络中节点的整体可达性差异较大;
- 特征向量中心性均值最低,说明网络中仅有极少数节点与核心节点强关联,呈现出显著的核心-边缘结构。
5.2.2 秩规模效应检验
论文基于Zipf定律,对4个中心性指标进行了秩规模回归分析,结果如下表:
| 参数 | 调整后R2R^2R2 | 回归系数 | p值 | 截断值 | 截断后样本量 |
|---|---|---|---|---|---|
| 度中心性 | 0.87 | -0.79 | <0.01*** | 0.030 | 82(109) |
| 接近中心性 | 0.75 | -0.16 | <0.01*** | 0.520 | 88(109) |
| 特征向量中心性 | 0.94 | -1.52 | <0.01*** | 0.008 | 41(109) |
| 介数中心性 | 0.85 | -1.19 | <0.01*** | 0.033 | 46(109) |
核心结论:
- 4个中心性指标均呈现出显著的秩规模效应,符合城市人类活动的普遍规律;
- 特征向量中心性的秩规模效应最强(调整后R2=0.94R^2=0.94R2=0.94),回归系数绝对值最大,说明节点的核心度差异最显著,极少数核心节点占据了网络中的主导地位;
- 接近中心性的秩规模效应最弱,说明节点的可达性分布相对均衡。
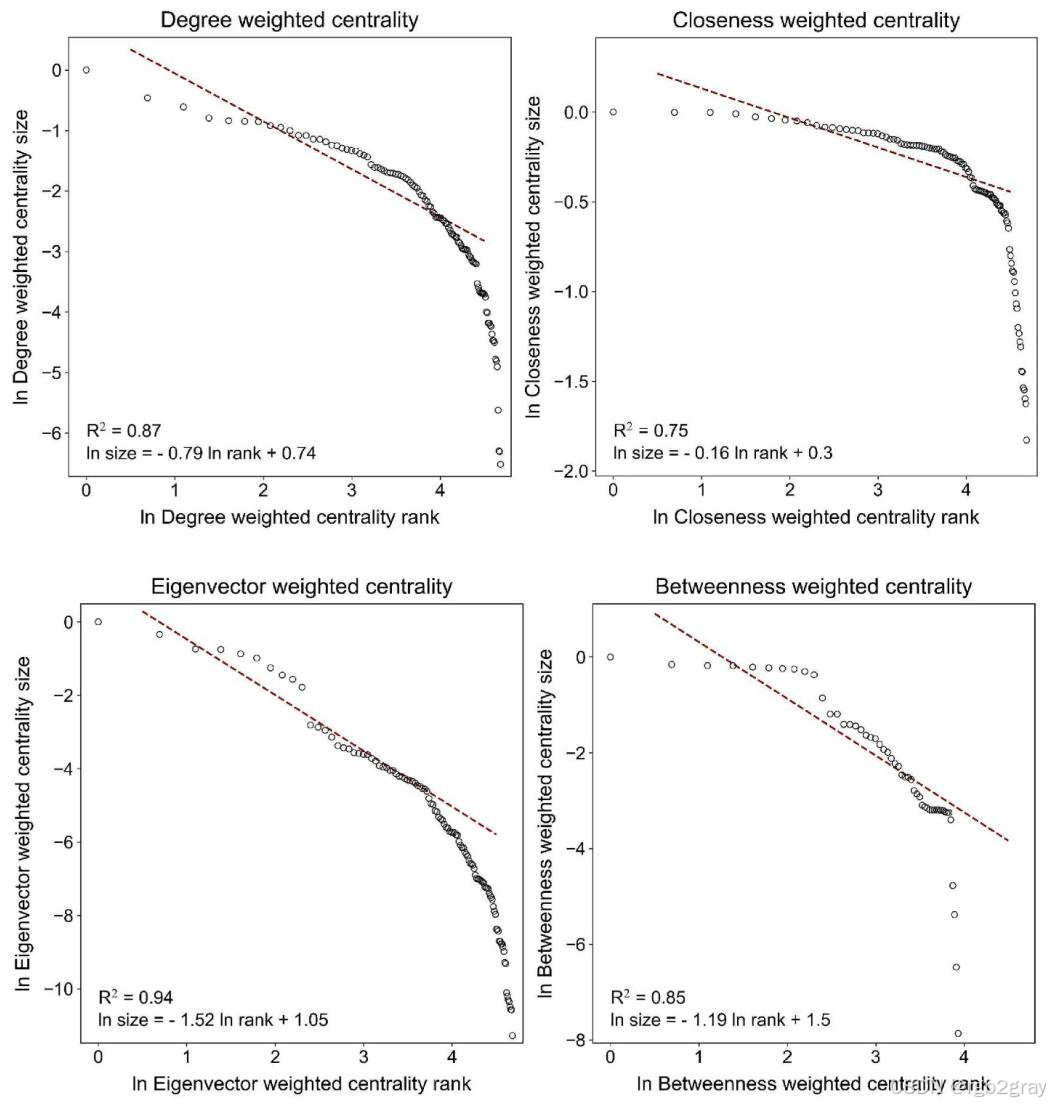
对应图8 局部参数的秩规模效应检验 解读:
图8包含4个子图,分别为4个中心性指标的秩规模双对数回归图。横轴为指标值的对数秩,纵轴为指标值的对数大小,拟合直线的R2R^2R2越高,说明秩规模效应越显著。可以清晰看到,特征向量中心性的拟合直线最贴合数据点,R2R^2R2达到0.94,完美符合Zipf定律;而接近中心性的拟合效果相对较弱,与统计结果完全一致。
5.2.3 度中心性的空间分布特征
论文采用头/尾 breaks方法,将网络节点按度中心性划分为5个层级,空间分布呈现出显著的组团式聚集特征 ,形成三大核心集群。
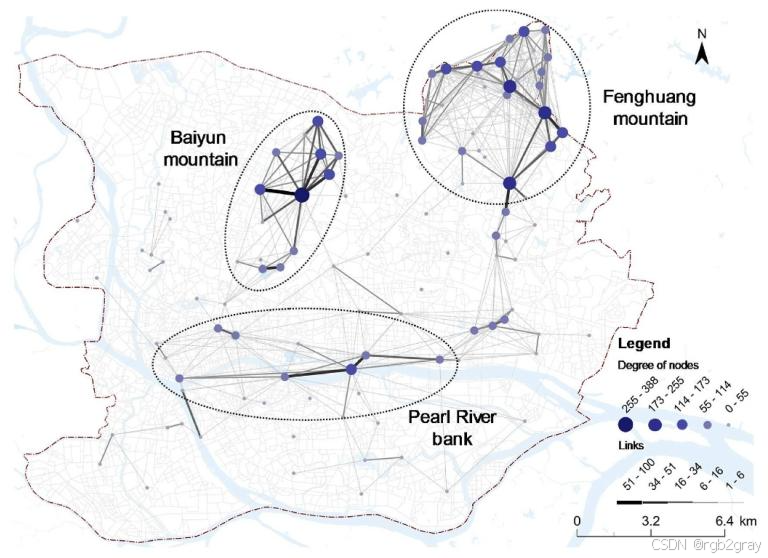
对应图9 休闲步行网络度中心性空间分布图 解读:
图9清晰展示了广州中心城区休闲步行节点的空间分布与层级结构,三大核心集群特征显著:
- 凤凰山集群:节点连通性最好,形成倒U型空间格局,多数节点为高层级节点,层级结构不明显,是广州北部最核心的休闲步行聚集区;
- 白云山集群:节点数量较少,但层级结构最显著,包含网络中唯一的1级核心节点,形成以核心节点为中心的放射状格局,是广州中心城区的顶级休闲核心;
- 珠江岸线集群:节点数量最少,但战略地位显著,沿珠江南北两岸呈线性分布,核心节点集中在珠江新城CBD周边,是广州城市核心区的滨水休闲带。
5.3 全局参数分析结果
论文对比了未加权与加权网络的全局参数,结果呈现出巨大差异,如下表:
| 参数 | 结果 | 理论取值范围 |
|---|---|---|
| 加权网络密度Δ\DeltaΔ | 0.518 | 0<Δ≤1 |
| 未加权网络密度Δn\Delta_nΔn | 0.520 | 0<Δ_n≤1 |
| 网络效率η | 0.757 | 0<η≤1 |
| 传递性T | 0.720 | 0<T≤1 |
| 未加权聚类系数CWSC_{WS}CWS | 0.754 | 0<C_WS≤1 |
| 加权聚类系数CWS−wC_{WS-w}CWS−w | 0.002 | 0<C_WS-w≤1 |
核心结论:
- 从未加权拓扑视角看,网络密度超过0.5,效率、传递性、聚类系数均超过0.7,说明网络整体连通性极强,绝大多数休闲节点之间都有直接拓扑链接;
- 从加权视角看,加权聚类系数从0.754骤降至0.002,说明网络的链接权重分布极度不均,绝大多数链接的权重极低,仅有极少数核心链接承载了主要的休闲步行流量,呈现出极强的空间异质性。
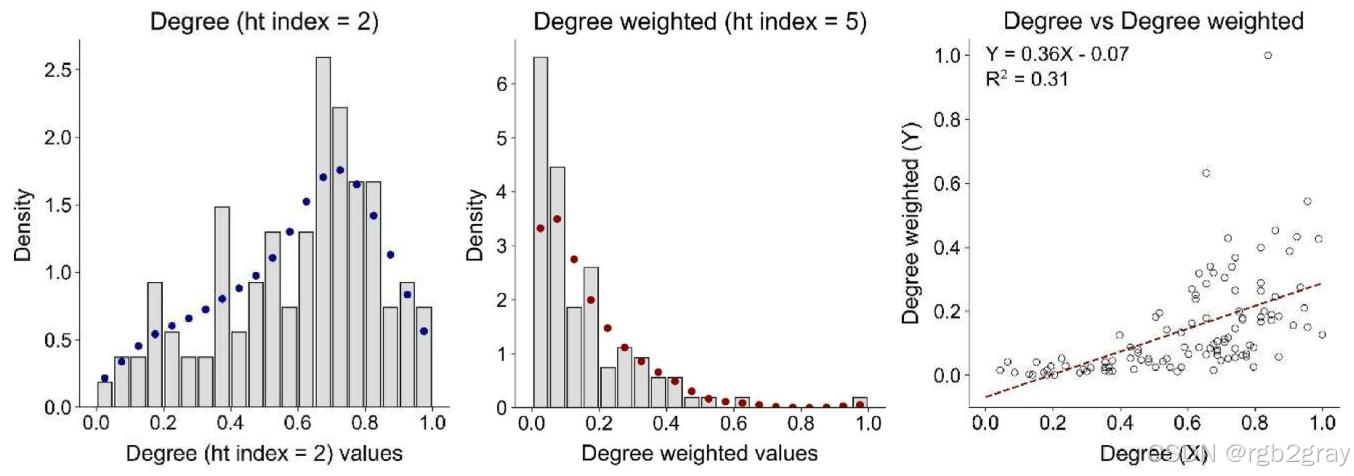
对应图11 未加权与加权度中心性的分布对比 解读:
图11包含三个子图,完整揭示了加权与未加权网络的本质差异:
- 左图:未加权度中心性的分布近似泊松分布,ht-index=2,绝大多数节点的度中心性集中在0.6-0.9区间,说明从拓扑连接上,节点的连通性差异很小;
- 中图:加权度中心性呈现典型的重尾分布,ht-index=5,绝大多数节点的加权度极低,仅有极少数节点具有极高的加权度,说明节点的实际流量承载能力差异巨大;
- 右图:未加权与加权度中心性的拟合R2R^2R2仅为0.31,相关性极弱,进一步证明拓扑连接的多少,完全无法代表节点实际的休闲吸引力强弱。
5.4 社区检测结果
论文通过贪婪模块度算法,最终将网络划分为7个独立的社区 ,从空间尺度从大到小依次为:凤凰山(#1)、白云山(#2)、珠江岸线(#3)、天河东(#4)、麓湖(#5)、白云南(#6)、芳村(#7)。
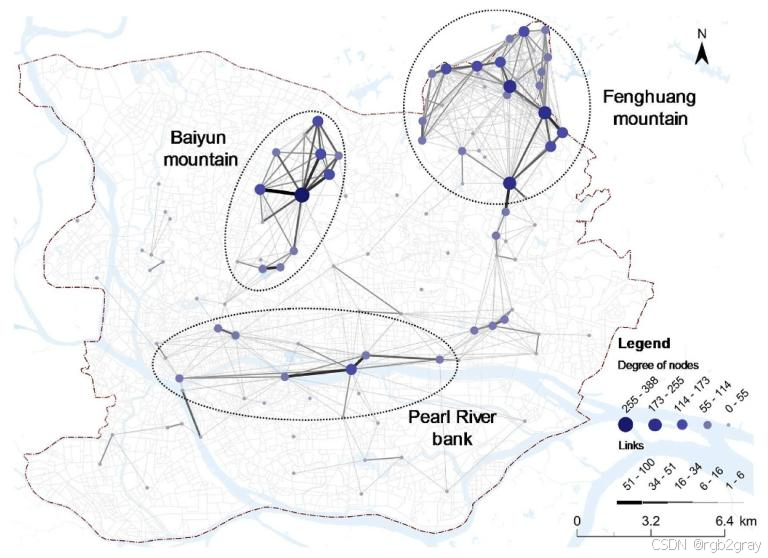
对应图10 休闲步行网络社区检测结果 与表6社区统计数据解读:
图10用不同颜色标注了7个社区的空间范围与节点分布,结合表6的统计数据,可得到核心结论:
- 前三大社区(凤凰山、白云山、珠江岸线)与度中心性分析的三大集群完全对应,实现了定性分析与定量检测的相互验证;
- 天河东社区(#4)是唯一以商业设施为核心的社区,而非传统的蓝绿空间,说明商业休闲也是广州居民休闲步行的重要组成部分;
- 麓湖社区(#5)在空间上紧邻白云山,但被独立划分为一个社区,说明麓湖既是独立的休闲目的地,也是白云山社区的重要入口,具有双重功能;
- 凤凰山社区的节点数量最多(34个),社区内链接数达532条,跨社区链接仅21条,说明其内部连通性极强,是一个高度自洽的休闲步行系统;
- 白云南社区、芳村社区的节点数量少,跨社区链接极少,属于相对孤立的本地休闲组团。
六、讨论:研究的理论贡献与结果印证
6.1 方法论的理论创新
- 节点定义的创新:突破了传统自上而下的节点定义模式,基于用户实际停留行为自下而上提取节点,充分适配了休闲活动的自组织特征,避免了传统方法对小众休闲节点的遗漏,更贴合居民的实际休闲选择。
- 链接定义的创新:将推荐算法中的资源分配思想引入网络构建,解决了传统共现法的轨迹贡献不平等问题,保证了链接权重计算的客观性与准确性,更真实地反映了节点间的实际关联强度。
- 分析框架的完整性:构建了「轨迹预处理-节点提取-链接定义-特征分析-规划应用」的全流程框架,填补了现有研究中理论与实践脱节的空白。
6.2 研究结果的理论印证
- 研究发现休闲步行网络的加权特征呈现显著的重尾分布与秩规模效应,与Schläpfer等在Nature提出的「人类移动性普遍遵循Zipf定律」的结论完全契合,证明了休闲步行作为人类移动行为的一种,同样符合通用的标度律。
- 未加权网络近似随机网络,而加权网络呈现典型的无标度网络特征,与城市地理领域的大量研究结论一致,进一步证明了地理空间中的人类活动具有天然的空间异质性与层级结构。
七、规划启示:网络分析的落地应用
论文的核心亮点之一,是将休闲步行网络的分析结果,直接落地到城市规划的实际应用中,提出了三大核心规划应用场景,填补了现有研究的应用空白。
7.1 构建休闲步行规划的基础底图
网络分析的结果,本质是对广州中心城区居民实际休闲步行行为的系统性总结,可直接作为未来步行相关规划项目的基础底图。
- 局部中心性分析,明确了不同层级的休闲热点节点的位置、重要性与类型(自然/商业),为规划师提供了精准的节点优先级参考;
- 社区检测结果,划定了7个独立的休闲步行社区,清晰呈现了休闲步行活动的整体空间结构,为片区级休闲空间规划提供了边界与范围参考。
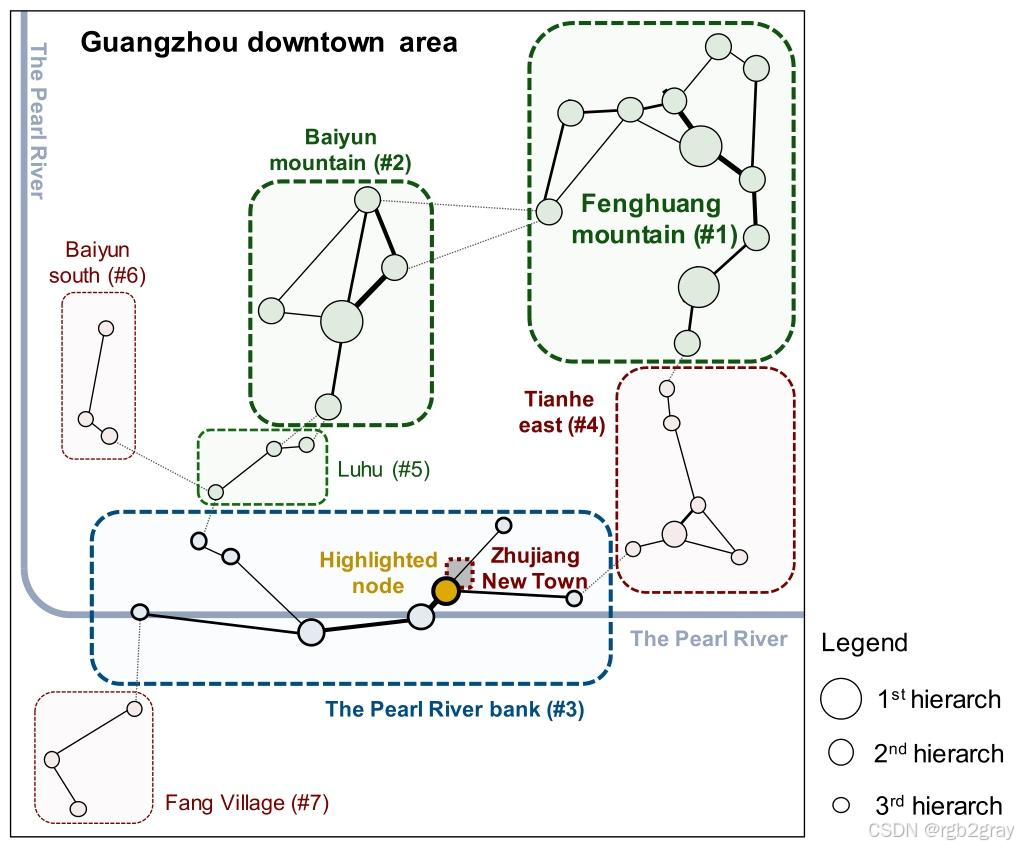
对应图12 休闲步行网络汇总规划图 解读:
图12将网络分析结果转化为了可直接用于规划的专题图,标注了7个休闲社区的边界、节点的层级结构,以及珠江新城周边的高亮核心节点。该图完全基于居民实际步行轨迹生成,具有自下而上的特征,完美响应了休闲活动的自组织性,相比传统的自上而下规划图,更贴合居民的实际需求。
7.2 城市规划方案的事前评估
论文将网络分析结果应用于广州国土空间总体规划的休闲规划方案的事前评估,核心是对比规划方案与居民实际休闲行为的匹配度,识别规划的缺失与不足。
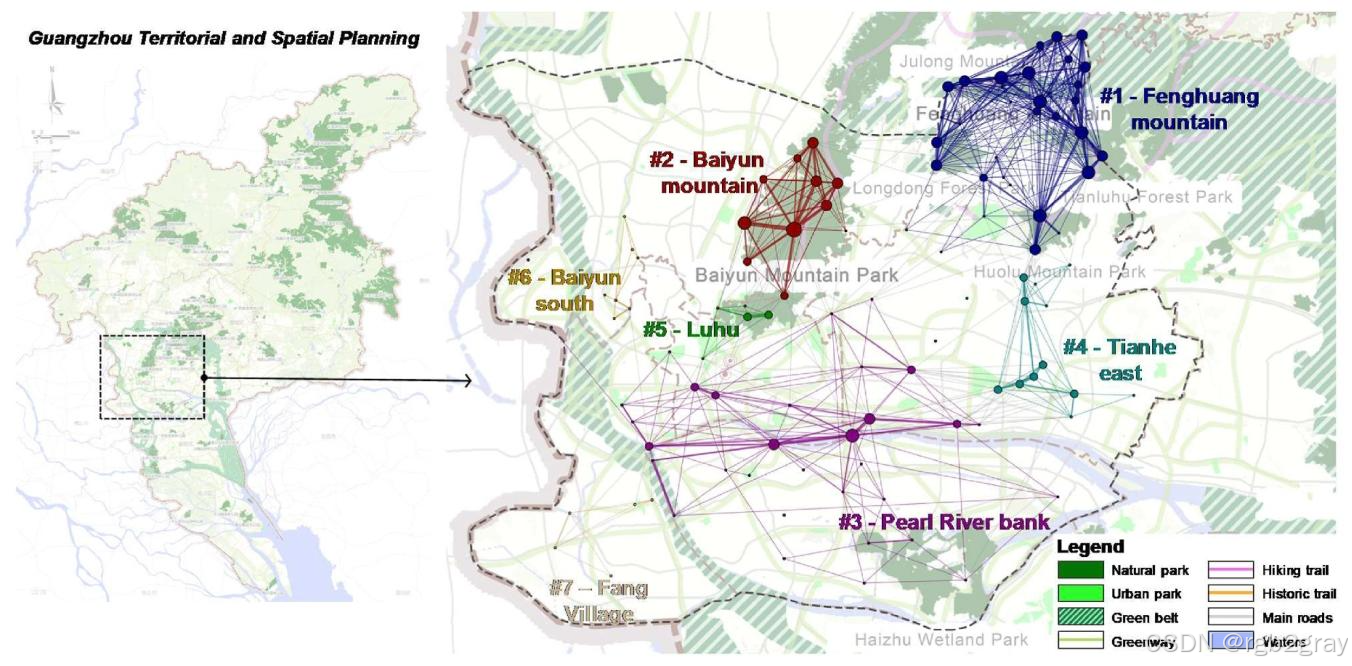
对应图13 社区检测结果与广州国土空间规划的对比图 解读:
图13将7个休闲社区与官方规划方案进行了叠加对比,得到两大核心结论:
- 规划方案与网络分析结果高度契合,凤凰山、白云山、珠江岸线三大核心社区,均被规划认定为关键休闲区,珠江岸线社区的空间结构与规划的滨江绿道完全匹配;
- 规划方案存在明显的缺失,完全未对天河东社区(#4)做出响应。该社区以商业设施为核心,是居民重要的休闲步行目的地,论文据此提出,应在该区域新增公园、绿道等休闲空间,提升步行环境品质,该建议也得到了天河区相关规划方案的印证。
7.3 城市慢行交通基础设施优化
网络分析结果显示,7个休闲社区之间的连接极少,整体呈现「内部紧密、外部孤立」的特征。基于步行性相关研究,连通性良好的步行环境能显著提升步行体验与居民福祉,论文据此提出了慢行基础设施的优化策略:
- 核心策略:在不同社区之间建设自然化的步行与骑行廊道,例如连接凤凰山(#1)与白云山(#2)的休闲廊道,为居民提供更多样化的步行路线选择;
- 配套策略:在廊道沿线整合交通基础设施、城市配套与公共服务,提升廊道的可达性与服务能力;
- 最终目标:构建广州中心城区的环形慢行交通网络,推动居民形成更可持续的生活方式。
对应图14 连通廊道理想建成环境概念设计图 解读:
图14展示了休闲连通廊道的理想建成环境设计,包含步行桥、步行铺装、绿化景观等核心要素,参考了纽约高线公园、哥本哈根自行车系统等成功案例,为规划落地提供了直观的设计参考,实现了从理论分析到设计实践的完整闭环。
八、结论与展望
8.1 核心研究结论
- 方法论层面:论文针对传统休闲网络构建的两大核心缺陷,提出了基于停留行为与TIN模型的自下而上节点提取方法,以及基于资源分配的链接定义方法,构建了一套更适配休闲步行自组织特征的网络分析框架。
- 特征发现层面:广州中心城区休闲步行网络呈现出两大核心特征------从未加权拓扑视角看,网络高度连通;从加权视角看,网络呈现出极度的非均匀性与空间异质性,节点具有显著的秩规模效应,加权聚类系数仅为0.002。
- 空间结构层面:休闲步行网络可划分为7个独立的社区,形成了凤凰山、白云山、珠江岸线三大核心集群,同时识别出了以商业设施为核心的天河东社区等非传统休闲组团。
- 规划应用层面:休闲步行网络分析可直接应用于规划基础底图绘制、规划方案事前评估、慢行基础设施优化三大场景,为城市休闲步行空间规划提供了自下而上的精准支撑。
8.2 研究局限与未来展望
- 数据局限性:研究采用的2bulu VGI数据仅能代表部分休闲人群,无法覆盖全年龄段、全类型的居民,未来可采用手机信令等更高粒度的全样本数据,对研究结果进行验证与补充。
- 应用场景拓展:本文仅探索了3类核心规划应用场景,未来可进一步拓展更丰富、更细化的实践场景,通过实际规划项目的落地反馈,持续优化理论框架。